深度解析BP神经网络:从万能逼近到工业实战
BP神经网络的全称是基于误差反向传播算法(Back Propagation)的多层前馈神经网络。前馈(Feed-Forward):信号从输入层进入,经过隐含层的逐层处理,最终从输出层产生结果,这是一个单向传播的过程。反向传播(Back Propagation):当输出结果与期望值不符时,计算两者之间的误差,并将该误差从输出层反向传播回输入层。在回传过程中,根据误差来调整各层神经元之间的连接权重。厂
引言
在人工智能的璀璨星空中,BP神经网络无疑是一颗经典而明亮的恒星。自20世纪80年代重新被Rumelhart、Hinton等人提出以来,基于误差反向传播(Back Propagation,简称BP)算法的神经网络一直是机器学习领域的中流砥柱。即便在深度学习大行其道的今天,BP神经网络因其结构简单、理论基础坚实、适应性强等特点,依然在工业控制、数据挖掘、模式识别等领域占据着举足轻重的地位。据统计,在人工神经网络的实际应用中,80%-90%的模型采用BP网络或其变化形式。
本文将带你从零开始,深入理解BP神经网络的数学原理,剖析其实现细节,并探讨它在现代工业与科研中的前沿应用。
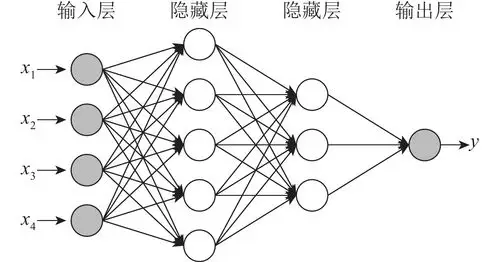
一、BP神经网络的核心思想
1.1 什么是BP神经网络?
BP神经网络的全称是基于误差反向传播算法(Back Propagation)的多层前馈神经网络。这个命名非常巧妙,它直接揭示了该网络的两大核心特征:
-
前馈(Feed-Forward) :信号从输入层进入,经过隐含层的逐层处理,最终从输出层产生结果,这是一个单向传播的过程。
-
反向传播(Back Propagation) :当输出结果与期望值不符时,计算两者之间的误差,并将该误差从输出层反向传播回输入层。在回传过程中,根据误差来调整各层神经元之间的连接权重。
我们可以用一个通俗的类比来理解这个过程:厂商生产产品(信号前向传播) 投放到市场,根据消费者的反馈(误差反向传播) 对产品进行升级优化,如此循环往复,直到生产出令市场满意的产品。
1.2 模拟大脑的神经元模型
BP神经网络的设计灵感来源于生物神经元。生物神经元通过树突接收信号,经过细胞体的加工(判断是否超过阈值),再通过轴突将信号传递给下一个神经元。
图1:典型神经元模型结构
数学化的神经元模型将这个生物过程抽象为三个步骤:
-
加权求和:输入信号 $x_i$ 乘以对应的连接权重 $w_i$,并求和。
-
叠加偏置:加上一个偏置项 $b$(相当于生物神经元的阈值电位)。
-
非线性激活:将总输入送入激活函数 $f$,得到最终的输出 $a$。
公式表达为:
a=f(∑i=1nwixi+b)a=f(∑i=1nwixi+b)
二、深入数学原理(进阶篇)
理解BP神经网络的关键在于掌握其数学本质——利用链式法则求导,通过梯度下降法优化参数。
2.1 变量符号约定
为了严谨地推导,我们需要定义一套清晰的符号。假设我们讨论的是一个包含输入层、一个隐含层和一个输出层的三层网络。
-
层数标记:输入层为第0层($l=0$),隐含层为第1层($l=1$),输出层为第2层($l=2$)。
-
$w_{jk}^{[l]}$:表示从第 $l-1$ 层的第 $k$ 个神经元,连接到第 $l$ 层的第 $j$ 个神经元的权重。
-
$b_j^{[l]}$:表示第 $l$ 层的第 $j$ 个神经元的偏置。
-
$z_j^{[l]}$:表示第 $l$ 层的第 $j$ 个神经元的加权输入,即 $z_j^{[l]} = \sum_k w_{jk}^{[l]} a_k^{[l-1]} + b_j^{[l]}$。
-
$a_j^{[l]}$:表示第 $l$ 层的第 $j$ 个神经元的激活输出,即 $a_j^{[l]} = \sigma(z_j^{[l]})$,其中 $\sigma$ 是激活函数。
2.2 信息的前向传播
前向传播是网络进行计算的过程。给定输入样本 $X$,信息通过网络层层传递,最终产生预测值 $\hat{Y}$。
1. 从输入层到隐含层
假设输入层有 $d$ 个特征,隐含层有 $q$ 个神经元。隐含层的第 $h$ 个神经元的输入为:
αh=∑i=1dvihxi+θhαh=∑i=1dvihxi+θh
其中 $v_{ih}$ 是输入层到隐含层的权重,$\theta_h$ 是隐含层的阈值。
其输出为 $b_h = \sigma_1(\alpha_h)$,其中 $\sigma_1$ 是隐含层的激活函数(如Sigmoid或ReLU)。
2. 从隐含层到输出层
假设输出层有 $l$ 个神经元。输出层的第 $j$ 个神经元的输入为:
βj=∑h=1qwhjbh+θjβj=∑h=1qwhjbh+θj
其中 $w_{hj}$ 是隐含层到输出层的权重,$\theta_j$ 是输出层的阈值。
其最终输出为 $\hat{y}_j = \sigma_2(\beta_j)$,其中 $\sigma_2$ 是输出层的激活函数(回归问题通常用线性函数,分类问题用Softmax或Sigmoid)。
2.3 误差的计算
当网络产生输出 $\hat{y}$ 后,我们将其与真实的标签 $y$ 进行比较。为了衡量差距,我们定义一个损失函数。最常用的是均方误差(MSE):
E=12∑k=1l(yk−y^k)2E=21∑k=1l(yk−y^k)2
这里的 $\frac{1}{2}$ 是为了后续求导时的方便,可以消去平方项求导后的系数2。
2.4 误差的反向传播(梯度下降与链式法则)
这是BP算法的核心。我们的目标是让误差 $E$ 尽可能小,因此需要调整权重和偏置。调整的原则是沿着误差函数的负梯度方向进行,即所谓的最速下降法。
以调整隐含层到输出层的权重 $w_{hj}$ 为例,我们需要求出误差 $E$ 对 $w_{hj}$ 的偏导数 $\frac{\partial E}{\partial w_{hj}}$。
根据微积分的链式法则,这个梯度可以拆解为:
∂E∂whj=∂E∂y^j⋅∂y^j∂βj⋅∂βj∂whj∂whj∂E=∂y^j∂E⋅∂βj∂y^j⋅∂whj∂βj
让我们一步步拆解:
-
第一项:$\frac{\partial E}{\partial \hat{y}_j} = \frac{\partial}{\partial \hat{y}_j} \left( \frac{1}{2}(y_j - \hat{y}_j)^2 \right) = -(y_j - \hat{y}_j)$。
-
第二项:$\frac{\partial \hat{y}_j}{\partial \beta_j}$,这实际上是输出层激活函数 $\sigma_2$ 的导数。例如,如果 $\sigma_2$ 是Sigmoid函数,其导数为 $\sigma_2(\beta_j)(1-\sigma_2(\beta_j))$。
-
第三项:$\frac{\partial \beta_j}{\partial w_{hj}}$,由 $\beta_j = \sum_{h} w_{hj} b_h + \theta_j$ 可得,该项就是隐含层神经元的输出 $b_h$。
将三项相乘,我们就得到了 $w_{hj}$ 的梯度。然后,我们设置一个学习率 $\eta$(步长),对权重进行更新:
whjnew=whjold−η⋅∂E∂whjwhjnew=whjold−η⋅∂whj∂E
这个过程会从输出层开始,逐层向后计算每一层的梯度并更新权重。这也就是“反向传播”名称的由来。
图2:算法流程图
三、激活函数与优化技巧
3.1 为什么需要非线性激活函数?
如果没有激活函数,或者激活函数是线性的,那么无论神经网络有多少层,最终的输出都只是输入的线性组合。线性模型的表达能力有限,无法解决非线性可分问题(如异或问题XOR)。因此,引入非线性激活函数是构建深层网络的关键。
3.2 常见激活函数对比
-
Sigmoid函数:$\sigma(z) = \frac{1}{1+e^{-z}}$
-
优点:输出映射在(0,1)之间,适合二分类输出层。
-
缺点:容易导致梯度消失(因为其导数最大仅为0.25),且输出非零中心,收敛慢。
-
-
Tanh函数:$\tanh(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}}$
-
优点:输出是零中心的(在-1到1之间)。
-
缺点:依然存在梯度消失问题。
-
-
ReLU函数:$ReLU(z) = max(0, z)$
-
优点:计算简单,在正区间梯度恒为1,能有效缓解梯度消失问题,收敛速度快。
-
缺点:存在“神经元死亡”现象(一旦进入负半区,梯度恒为0,神经元无法恢复)。
-
3.3 超参数设置与过拟合
训练BP网络不仅是调整权重,还需要预设一批“超参数”:
-
学习率($\eta$):决定了权重更新的步长。太小则收敛极慢,太大则会在最优值附近震荡甚至发散。一般设置在0.01到0.1之间进行尝试。
-
隐含层神经元个数:神经元太少,网络欠拟合;神经元太多,网络可能过拟合,记住了噪声而非规律。通常可以根据经验公式(如 $ \sqrt{n_{in} + n_{out}} + \alpha$)进行尝试。
-
防止过拟合:可以采用早停法(当验证集误差上升时停止训练)或正则化(在损失函数中加入对权重的惩罚项)。
四、BP神经网络的应用实战
BP神经网络的应用领域极其广泛,从金融预测到工业故障诊断,都能见到它的身影。
4.1 经典应用场景
根据科普中国的总结,BP网络主要应用于四大领域:
-
函数逼近:用输入矢量和相应的输出矢量训练一个网络,逼近任意复杂的函数。
-
模式识别:用一个特定的输出矢量将输入矢量与类别联系起来(如手写数字识别、人脸识别)。
-
分类:把输入矢量以所定义的合适方式进行分类(如信用评估中的好客户/坏客户分类)。
-
数据压缩:减少输出矢量维数以便于传输或存储。
4.2 前沿改进案例(解决BP的固有缺陷)
尽管理论优美,但传统的BP算法存在两个致命短板:收敛速度慢和容易陷入局部极小值。针对这些问题,近年来学术界和工业界提出了大量改进方案,将BP与优化算法结合是主流趋势。
-
案例1:基于遗传算法(GA)改进的输电线路山火监测
在贵州电网的研究中,科研人员利用皮尔逊相关分析筛选出导致山火的关键因子(如CO浓度、温度等),并建立了BP神经网络进行预测。然而传统BP随机初始化容易陷入局部最优。他们引入遗传算法(GA) 对BP的初始权值和阈值进行全局寻优。-
效果:GA-BP模型的平均收敛迭代次数仅为 88.2次,而传统BP需要 175.2次,训练时间缩短了近一半,同时预测精度显著提升。
-
-
案例2:基于粒子群(PSO)改进的阀冷却系统控制
在高澜节能技术的工业应用中,针对阀冷却系统的阀门开度预测问题,研究人员构建了PSO-BP模型(粒子群算法优化BP神经网络)。粒子群算法同样用于搜索最优的初始权重。-
效果:PSO-BP模型对阀门开度的分类预测准确率达到了惊人的 100%,表现远超传统BP模型,为工业智能控制提供了可靠的解决方案。
-
-
案例3:大坝边坡变形预测
在龙滩水电站的左岸坝肩边坡监测中,研究人员使用GA-BP模型预测岩石变形。结果表明,GA-BP模型仅用 12次迭代 就达到了 $2.46 \times 10^{-6}$ 的精度,而传统BP需要 161次迭代 才能达到较低的精度。
这些案例清晰地表明,虽然BP神经网络本身存在一些理论上的局限,但通过结合遗传算法、粒子群算法等全局优化技术,可以极大地提升其性能,使其在工业4.0时代依然焕发着强大的生命力。
五、总结与展望
BP神经网络作为连接早期感知机与现代深度学习的桥梁,其核心思想——通过链式法则计算梯度,利用梯度下降优化模型——至今仍是训练深度神经网络(如CNN、RNN)的基础。
尽管在当前的视觉和自然语言处理领域,更复杂的网络结构(如Transformer)占据了主导地位,但BP神经网络凭借其结构简单、易于理解、在小样本数据上表现良好的优势,依然在工业控制、特定行业的预测建模中扮演着不可替代的角色。
正如我们在山火监测和工业阀门控制中看到的那样,“BP神经网络 + 智能优化算法” 的组合模式,为解决非线性、小样本的实际工程问题提供了一条经典而有效的路径。对于初学者而言,掌握BP神经网络,不仅是在学习一个具体的算法,更是在理解现代人工智能大厦最坚实的基石。
参考文献及资料:
-
一文搞定BP神经网络——从原理到应用(原理篇)
-
科普中国-反向传播网络
-
基于遗传算法改进BP神经网络的输电线路山火监测预警技术
-
百度百科- BP神经网络
-
科普中国-神经网络结构
-
基于PSO-BP的阀冷却系统阀门开度分类预测模型
-
知乎:一文搞懂BP神经网络——从原理到应用
-
科普中国-反向传播算法
-
Prediction of Slope Deformation at the Dam Inlet Based on GA-BP Neural Network
-
BP神经网络算法与MATLAB程序详解视频

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)