卷积神经网络(CNN)核心机制详解:卷积核、池化与参数共享
从数学上讲,卷积核是一个小的二维权重矩阵,通常尺寸为 3x3、5x5 或 7x7。例如,一个 3x3 的卷积核看起来就像这样:这些 ww 就是网络需要学习的权重参数。在 CNN 的前向传播过程中,这个小的矩阵会在输入图像上从左到右、从上到下地滑动。在每一个停留的位置,卷积核与其覆盖的局部图像像素进行逐元素相乘后求和,输出的结果就构成了新的一层——特征图(Feature Map)。卷积神经网络的成功
前言
在深度学习的广阔星空中,卷积神经网络(Convolutional Neural Network, CNN)无疑是一颗最为璀璨的恒星。它主导了计算机视觉领域十余年的发展,从简单的手写数字识别到复杂的自动驾驶感知,从人脸识别到医学影像分析,CNN的身影无处不在。与标准的全连接神经网络相比,CNN能够以极少的参数量,捕捉到数据中的空间层级结构信息。
那么,CNN究竟是如何实现这种“四两拨千斤”的效果的?其核心秘密就藏在卷积核、池化与参数共享这三大机制中。本文将深入浅出地为你详细剖析这三大核心机制的原理、数学基础、设计思想以及它们是如何协同工作,共同构成了现代人工智能的视觉基石。
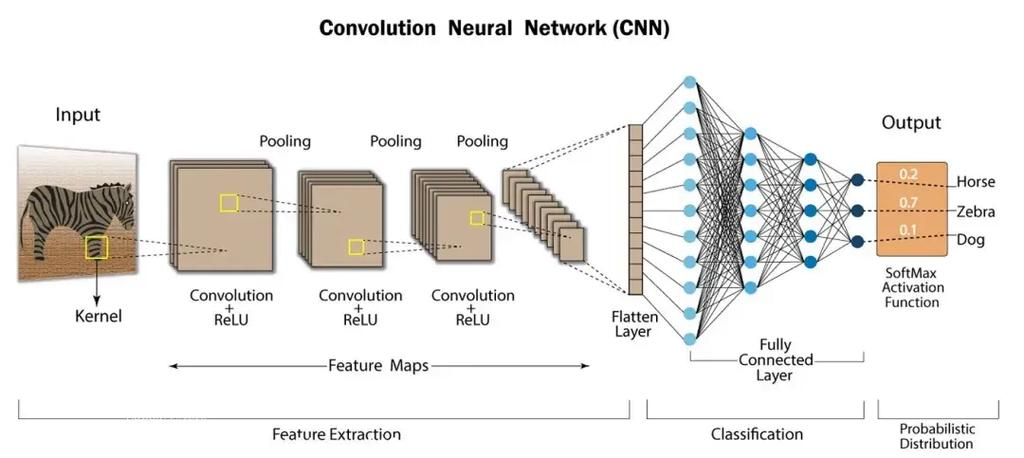
第一章:从全连接网络的困境说起
在理解CNN的精妙之前,我们先来看看传统的全连接神经网络(Fully Connected Neural Network)在处理图像时面临的挑战 。
假设我们有一张非常小的图片,尺寸仅为 100x100 像素,并且是彩色的(RGB三个通道)。对于全连接网络来说,输入层的神经元数量就是 100 * 100 * 3 = 30,000 个。假设第一层隐藏层也有 30,000 个神经元,那么仅仅这一层之间的连接权重数量就是 30,000 * 30,000 = 9 亿个。这是一个天文数字,不仅计算极其困难,而且如此庞大的参数量极易导致模型过拟合 。
更重要的是,全连接层破坏了图像的空间结构。当我们将图片展开成一个长向量时,原本在空间上相邻的像素(比如构成一只猫耳朵的像素点)在向量中可能相隔甚远,网络无法直接利用这种天然的空间局部相关性 。
为了解决这些问题,CNN 引入了两个核心的架构理念:局部连接和权值共享,而它们的物理实现,正是 卷积核。
第二章:卷积核——特征提取的“探测器”
如果说CNN是一座精密的仪器,那么卷积核(Convolution Kernel),也叫滤波器(Filter),就是这台仪器最核心的探头。它的作用是在输入图像上滑动,每次只关注一小块区域,并从中提取特定的视觉模式。
2.1 什么是卷积核
从数学上讲,卷积核是一个小的二维权重矩阵,通常尺寸为 3x3、5x5 或 7x7。例如,一个 3x3 的卷积核看起来就像这样:
K=[w11 w12 w13; w21 w22 w23; w31 w32 w33]
这些 w 就是网络需要学习的权重参数。在 CNN 的前向传播过程中,这个小的矩阵会在输入图像上从左到右、从上到下地滑动。在每一个停留的位置,卷积核与其覆盖的局部图像像素进行逐元素相乘后求和,输出的结果就构成了新的一层——特征图(Feature Map) 。
2.2 卷积计算过程详解
假设我们有一张 5x5 的单通道灰度图,和一个 3x3 的卷积核,步长(Stride)设为1,无填充(Padding)。
计算过程示例 :
当卷积核覆盖在图像左上角第一个局部区域(称为感受野)时:
图像局部区域卷积核[0 1 2; 2 4 5; 4 7 8]⊙[1 0 −1; 1 0 −1; 1 0 −1]=(0∗1)+(1∗0)+(2∗(−1))+(2∗1)+(4∗0)+(5∗(−1))+(4∗1)+(7∗0)+(8∗(−1))=0+0−2+2+0−5+4+0−8=−9图像局部区域024147258⊙111000−1−1−1=(0∗1)+(1∗0)+(2∗(−1))+(2∗1)+(4∗0)+(5∗(−1))+(4∗1)+(7∗0)+(8∗(−1))=0+0−2+2+0−5+4+0−8=−9卷积核
这个 -9 就会出现在输出特征图的第一个位置上。随后,卷积核向右滑动步长个像素(本例步长为1),继续计算下一个值。最终,我们会得到一个 (5-3+1)=3 大小的输出特征图。
2.3 多通道卷积与多个卷积核
现实中的图像通常是多通道的(如RGB三通道)。这时,卷积核也需要相应地扩展深度,即卷积核的通道数必须与输入数据的通道数一致 。
例如,对于 32x32x3 的彩色图像,一个 3x3 的卷积核实际尺寸是 3x3x3。它在滑动时,会同时覆盖所有通道的对应区域,计算时也是将所有通道的对应元素相乘后求和,最后得到一个数值。因此,无论输入有多少个通道,使用一个卷积核进行卷积,输出结果都是一个二维的特征图 。
如果我们想提取多种不同的特征(比如边缘、纹理、角点等),就需要使用多个卷积核。如果有 N 个卷积核,那么输出的深度就是 N,形成一个由 N 个特征图堆叠而成的三维张量 。
2.4 1x1卷积的妙用
不要被“1x1”的小尺寸所迷惑,它在现代网络架构(如GoogLeNet、ResNet)中扮演着重要角色。1x1卷积并不提取空间上的相邻特征(因为它只关注一个点),它的核心作用是跨通道的信息融合与维度变换 。它可以在不改变特征图空间尺寸的情况下,自由地增加或减少通道数,这通常被称为“瓶颈层”,能极大地减少计算量。
第三章:参数共享与局部连接——降低参数量的两大法宝
正是由于卷积核的独特工作方式,才衍生出了CNN最核心的两个特性:局部连接和参数共享。这两者共同构成了CNN参数量远少于全连接网络的基础 。
3.1 局部连接:感受野的哲学
在卷积层中,神经元(即特征图上的每一个点)并非与上一层的所有神经元相连,而只与卷积核覆盖的那一小块局部区域的神经元相连。这个局部区域的大小就是感受野(Receptive Field) 。
这背后的设计理念来自于对图像数据的深刻洞察:图像中相邻的像素关联性强,而相距较远的像素关联性弱 。因此,让神经元首先学习局部的特征(如边缘、弧线),然后在更高层将这些局部特征组合成全局特征(如眼睛、嘴巴),是一种更符合视觉信息处理逻辑的方式。这种稀疏的连接结构,使得参数量相比于全连接层呈指数级下降 。
3.2 参数共享:平移不变性的基石
这是CNN最具革命性的思想。所谓参数共享,指的是一个特定的卷积核在滑过整张图片的每一个位置时,其内部的权重参数是固定不变的 。
试想一下,如果一个能够检测“水平边缘”的卷积核在图片左上角学习到了“水平边缘”的特征,那么它应该也能在图片右下角检测到类似的“水平边缘”。与其在图片的每一个位置都单独学习一个检测器,不如让这一个检测器“共享”到所有位置。
参数共享带来的好处是显而易见的:
-
极大地减少了参数量:无论输入图片有多大,一个卷积核的参数量仅由卷积核尺寸决定(如3x3=9个参数 + 1个偏置)。
-
赋予了网络平移等变性 :如果输入图像中的目标平移了几个像素,那么输出的特征图也会相应地平移相同的像素,但特征本身的数值不变。这意味着无论目标出现在画面的哪个位置,卷积核都能识别出来,极大地增强了模型的泛化能力。
3.3 量化对比:CNN vs 全连接
让我们回到开头的例子:输入 100x100x3 的图像。
-
全连接层:如果第一层有1000个神经元,参数量约为 30,000 * 1000 = 3e7(三千万)。
-
卷积层:假设第一层有32个卷积核,每个尺寸为 3x3x3,参数量为 (3*3*3) * 32 + 32(偏置)= 896个参数 。
参数量从三千万锐减到不到一千,这就是局部连接和参数共享机制的惊人威力。
第四章:池化层——降维与抽象的艺术
通过卷积层提取特征后,我们得到了特征图。但此时的数据量依然庞大,且对位置过于敏感。这时,就需要池化层(Pooling Layer)登场了 。
池化层本质上是一种下采样操作,它同样用一个窗口在特征图上滑动,但与卷积核不同,它不包含需要学习的参数,只进行固定的计算 。
4.1 池化的两种主要形式
1. 最大池化(Max Pooling)
这是最常用的池化方式。它取池化窗口覆盖区域中所有像素的最大值作为输出。其理念是:只要在这个局部区域内检测到了某种特征(最大值很大),就记录下这个特征,而忽略它的具体位置。
例如,对一个 2x2 的区域进行最大池化:
[1 5; 3 2]最大池化→5
2. 平均池化(Average Pooling)
平均池化取池化窗口内所有像素的平均值作为输出。它更多地用于保留背景信息,或者在网络的最后,全局平均池化常用于替代全连接层。
对上例进行平均池化:
[1 5; 3 2]平均池化→(1+5+3+2)/4=2.75
4.2 池化的核心作用
-
降低维度,减少计算量:池化层最常见的设置是 2x2 的窗口,步长为2。这会将特征图的高度和宽度直接减半,使后续层的参数量和计算量降低75% 。
-
扩大感受野:随着特征图尺寸的减小,后续卷积层即使使用同样大小的卷积核,其覆盖的原始图像区域也变得更大,从而能够学习到更高层级的抽象特征。
-
引入平移不变性 :这是池化层最重要的作用。由于池化输出的是局部区域的统计值,因此即使输入图像发生微小的平移,只要特征仍然在池化窗口内,池化的输出就可能保持不变。这使得模型对输入的微小扰动更加鲁棒。
小结:卷积层负责“找什么”(特征提取),而池化层负责“在哪找”(位置抽象)。
第五章:三大机制协同作战
在典型的CNN架构(如LeNet-5, AlexNet, VGG)中,这三个核心机制被巧妙地组合在一起,形成了一种经典的层次化结构 。
一个典型的卷积块通常包含:
-
卷积层(Conv Layer):利用多个卷积核提取局部特征。这里应用了局部连接和参数共享。
-
激活函数(Activation Function):通常使用ReLU,引入非线性。
-
池化层(Pooling Layer):进行下采样,降低维度,增加平移不变性。
这种“卷积-激活-池化”的组合被反复堆叠。在网络的浅层,卷积核学习到的通常是简单的边缘、颜色、纹理等低级特征 。随着网络的加深和特征图尺寸的减小,深层卷积核开始组合这些低级特征,形成“车轮”、“眼睛”、“嘴巴”等中级特征。最终,这些特征被送入全连接层,完成最终的分类或回归任务 。
以VGG16为例,它包含了13个卷积层和5个最大池化层。正是通过不断地用卷积核提取特征,用池化层压缩特征,VGG16才能在ImageNet数据集上取得优异的成绩。
第六章:机制的进化与变体
随着研究的深入,围绕卷积核和池化也衍生出了许多高效的变体,进一步丰富了CNN的内涵。
6.1 不一样的卷积
-
空洞卷积(Dilated Convolution) :在卷积核的像素之间插入“空洞”,使得在不增加参数量的情况下,极大地扩大了感受野。这在语义分割等需要密集预测的任务中非常有用。
-
深度可分离卷积(Depthwise Separable Convolution) :将标准卷积分解为“深度卷积”(对每个通道单独卷积)和“逐点卷积”(1x1卷积融合通道)。这种分解能极大幅度地减少计算量,是MobileNet等轻量级网络的基石。
-
转置卷积(Transposed Convolution) :通常被称为反卷积,但它并不是卷积的逆运算。它主要用于上采样,将小的特征图恢复到大分辨率,广泛应用于图像分割和生成对抗网络(GAN)中。
6.2 池化的替代与进化
近年来,一些新的架构开始尝试减少甚至替代传统的池化层。
-
步长卷积(Strided Convolution):直接将卷积的步长设为2,也可以达到下采样、缩小特征图尺寸的目的。在ResNet等现代网络中,这种做法比单独使用池化层更为普遍 。
-
全局平均池化(Global Average Pooling) :在网络的最后,对整个特征图的每个通道取平均值,得到一个向量直接用于分类。它完全替代了Flatten操作和部分全连接层,极大地减少了参数量,并防止过拟合。
总结
卷积神经网络的成功绝非偶然。它通过精巧的结构设计,将人类对于视觉世界的先验知识——空间局部性和平移不变性——直接融入到了网络的血液中。
-
卷积核作为智慧的探针,通过局部连接关注细节,通过参数共享实现权重复用,以极小的代价高效地提取出丰富的视觉特征。
-
池化层则扮演着抽象家的角色,不断对特征图进行浓缩和提炼,丢弃冗余的位置信息,保留本质的语义信息,同时为网络带来了宝贵的鲁棒性。
正是这三大核心机制的紧密配合,使得CNN能够从海量的像素中,一层层地构建出对世界的理解。从“看到”边缘,到“认出”物体,再到“理解”场景。掌握了这些底层逻辑,你不仅能够更好地使用现成的模型,更能在未来面对新的问题时,设计出属于自己的、更强大的神经网络架构。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 34
34 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)