强化学习与物理信息神经网络(PINN)重磅结合!硬核思路就是好上分
最近刷了不少PINN相关的论文,发现个明显的变化,越来越多的工作开始结合强化学习搞创新。以前我们都是关注如何更精确、更高效地求解一个特定的物理方程,得到问题的静态答案,也就是求解。现在因为AI4S强劲的发展势头,对模型动态、高维的序列决策能力要求更高,而这正是强化学习的专长。于是“PINN+强化学习”这方向开始热起来了,paper也肉眼可见地密集。今天我们就简单做个盘点,梳理一波这方向近期有代表性
最近刷了不少PINN相关的论文,发现个明显的变化,越来越多的工作开始结合强化学习搞创新。
以前我们都是关注如何更精确、更高效地求解一个特定的物理方程,得到问题的静态答案,也就是求解。现在因为AI4S强劲的发展势头,对模型动态、高维的序列决策能力要求更高,而这正是强化学习的专长。
于是“PINN+强化学习”这方向开始热起来了,paper也肉眼可见地密集。今天我们就简单做个盘点,梳理一波这方向近期有代表性的研究,帮助大家掌握领域前沿动态和发展趋势,以便按方向继续深挖,目前更新到9篇,需要自取。
全部论文+开源代码需要的同学看文末
Physics-Informed Neural Networks-Based Adaptive Optimized Control and Its Application to Automated Surface Vessels
研究方法:论文提出基于PINNs与强化学习融合的自适应优化控制方法,通过PINNs整合物理定律与在线数据建模系统动力学,借助自动微分特性辅助自适应动态规划迭代逼近连续时间哈密顿-雅可比-贝尔曼方程解,结合Actor-Critic框架优化控制策略,实现对仿射系统的高效、稳定自适应控制。
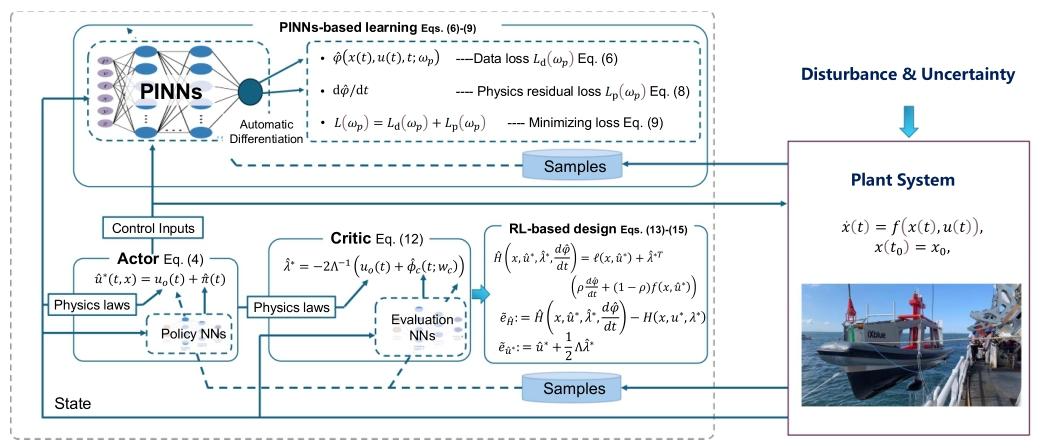
创新点:
-
将PINNs与自适应动态规划(ADP)深度结合,利用PINNs的自动微分特性直接近似连续时间系统的哈密顿-雅可比-贝尔曼方程解,无需离散化处理。
-
设计基于PINNs的Actor-Critic架构,由PINNs建模系统动力学并逼近价值函数,强化学习策略网络输出控制律,实现物理约束与数据驱动的端到端优化。
-
提出针对仿射非线性系统的自适应控制框架,通过PINNs实时融合物理先验与在线数据,提升模型在模型不确定性和外部扰动下的控制稳定性与泛化能力。
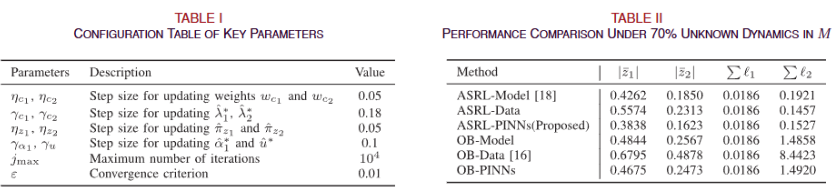
研究价值:研究提出的PINN与强化学习融合框架,为仿射非线性系统提供了无需离散化的连续时间自适应控制新范式,在保障物理约束与学习稳定性的同时,显著提升了复杂环境下的控制精度与抗扰动能力。
Physics-informed multi-agent reinforcement learning for distributed multi-robot problems
研究方法:论文提出物理信息多智能体强化学习方法,将PINN(物理信息神经网络)的端口-哈密顿结构与强化学习结合,通过自注意力机制建模机器人间时变交互,依托软演员-评论员算法训练分布式控制策略,在尊重物理系统能量守恒特性的同时,实现多机器人系统的可扩展、高效协同控制。
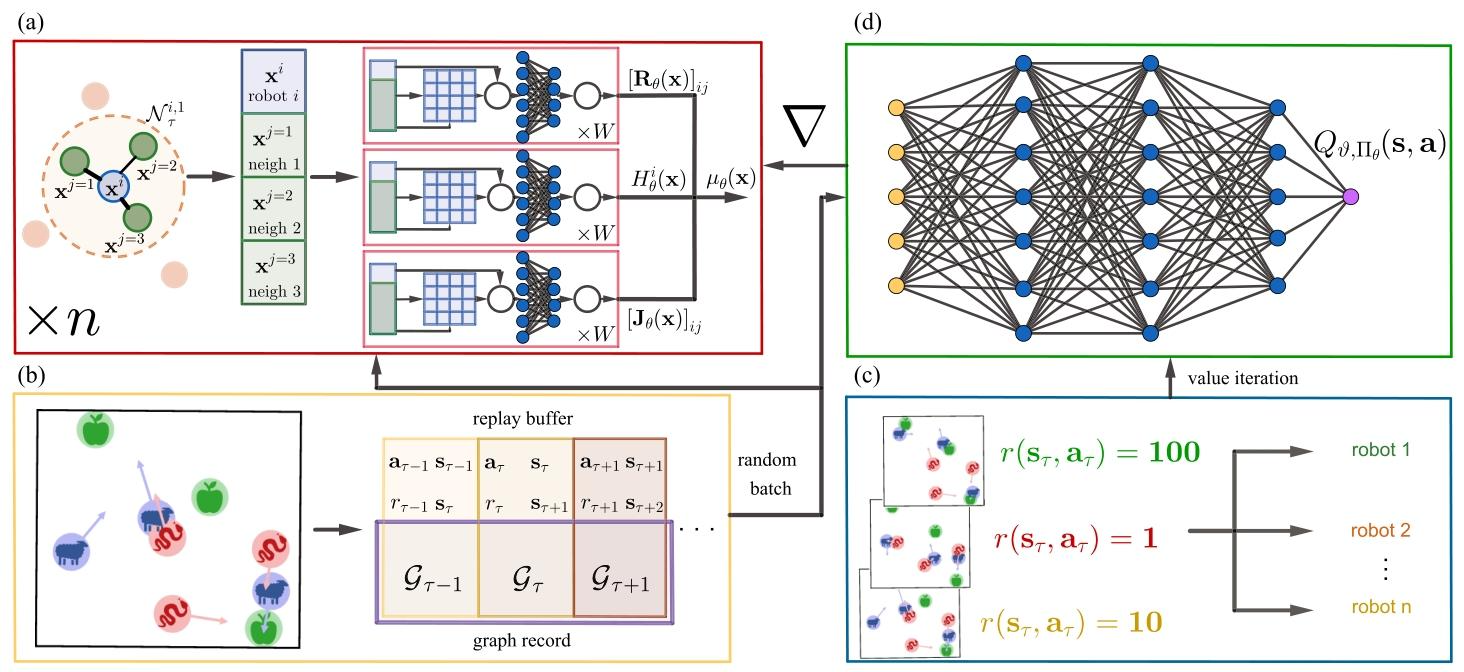
创新点:
-
将PINN的端口-哈密顿结构融入多智能体强化学习,让策略学习过程严格遵循能量守恒等物理先验,提升系统控制的物理合理性与稳定性。
-
引入自注意力机制建模多机器人间的时变交互关系,精准捕捉动态协作中的关键关联,突破传统方法在多智能体规模扩展上的瓶颈。
-
结合软演员-评论员算法设计分布式控制策略,实现多机器人系统的去中心化协同,在保证探索效率的同时,提升控制策略的鲁棒性与落地性。
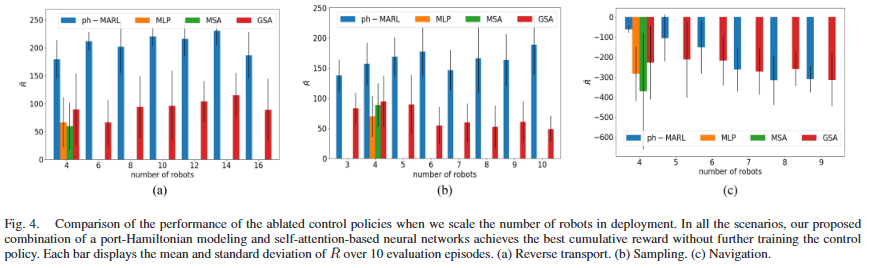
研究价值:研究将PINN的物理先验与强化学习结合,为多机器人系统提供了兼顾物理合理性、规模可扩展性与控制鲁棒性的协同控制新方案,有效推动了物理约束下分布式智能控制的落地应用。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“222”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 17
17 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)