深度学习篇---Batch Normalization(批归一化)概念
BatchNorm:深度学习的稳定神器 BatchNorm(批归一化)通过标准化网络各层的输入分布(均值为0、方差为1),并引入可学习的缩放参数γ和平移参数β,有效解决深度神经网络中的“内部协变量偏移”问题。其核心作用包括:稳定梯度流动、加速训练、允许更大学习率、缓解梯度消失/爆炸,并附带轻微正则化效果。训练时使用当前批次的统计量,推理时则依赖全局统计量。类比恒温烤箱,BatchNorm让网络专注
Batch Normalization(批归一化)概念
如果说训练神经网络是烤蛋糕,那么BatchNorm就是恒温烤箱——不管外面天气如何,烤箱内部总能保持合适温度,让蛋糕受热均匀,不会烤焦或夹生。
一、BatchNorm是什么?
1.1 最直观的理解
BatchNorm = 数据标准化 + 可学习的缩放平移
# 伪代码:BatchNorm的本质
def batch_norm(x):
# 第1步:标准化(变成均值为0,方差为1的分布)
x_normalized = (x - 均值) / 标准差
# 第2步:缩放和平移(让网络自己决定最好的分布)
y = γ × x_normalized + β
return y通俗比喻:
-
标准化:把所有学生的成绩都转换成标准分(不管原始试卷多难)
-
缩放平移:老师可以根据需要调整(想难一点就缩小,想简单就放大)
1.2 数学定义
import torch
import torch.nn as nn
# 对一个batch的数据做BN
def manual_batch_norm(x, eps=1e-5):
"""
x: [batch_size, channels, height, width]
"""
# 计算当前batch的均值和方差
batch_mean = x.mean(dim=(0, 2, 3), keepdim=True) # 对[N,H,W]求平均
batch_var = x.var(dim=(0, 2, 3), keepdim=True, unbiased=False)
# 标准化
x_norm = (x - batch_mean) / torch.sqrt(batch_var + eps)
# γ和β(可学习参数)
gamma = torch.ones(x.size(1), device=x.device).view(1, -1, 1, 1)
beta = torch.zeros(x.size(1), device=x.device).view(1, -1, 1, 1)
# 缩放和平移
out = gamma * x_norm + beta
return out
# PyTorch中的BN
bn = nn.BatchNorm2d(64) # 64是通道数二、为什么需要BatchNorm?
2.1 核心问题:内部协变量偏移

生活类比:
-
没有BN:你每天上班的路都在变化,今天封路,明天改道,每天都要重新适应
-
有BN:修了一条高速公路,每天路况都一样,你可以专心开车
2.2 为什么要做标准化?
import numpy as np
import matplotlib.pyplot as plt
def visualize_distribution_shift():
"""可视化分布偏移问题"""
# 模拟没有BN的情况:各层分布不断变化
layers_without_bn = [
np.random.randn(1000) * 2 + i * 0.5 # 每层分布不同
for i in range(5)
]
# 模拟有BN的情况:各层分布稳定
layers_with_bn = [
np.random.randn(1000) # 都是标准正态分布
for _ in range(5)
]
fig, axes = plt.subplots(2, 1, figsize=(10, 8))
# 没有BN
for i, layer in enumerate(layers_without_bn):
axes[0].hist(layer, bins=50, alpha=0.5, label=f'Layer {i+1}')
axes[0].set_title('没有BN:各层分布差异大')
axes[0].legend()
axes[0].axvline(x=0, color='r', linestyle='--')
# 有BN
for i, layer in enumerate(layers_with_bn):
axes[1].hist(layer, bins=50, alpha=0.5, label=f'Layer {i+1}')
axes[1].set_title('有BN:各层分布稳定')
axes[1].legend()
axes[1].axvline(x=0, color='r', linestyle='--')
plt.tight_layout()
plt.show()
# 分布不稳定带来的问题:
# 1. 激活函数容易进入饱和区(梯度=0)
# 2. 参数更新方向不稳定
# 3. 需要小心翼翼调学习率2.3 为什么需要可学习的γ和β?
def why_gamma_beta():
"""为什么需要缩放和平移"""
# 情况1:只标准化,不学习
x_norm = (x - mean) / std # 强制变成N(0,1)
# 问题:可能不是最优分布
# 比如ReLU激活函数,最好让部分值为负(产生稀疏性)
# 情况2:标准化 + 学习
# γ和β让网络自己决定:
# - 如果γ>1,β>0:分布更宽,偏右
# - 如果γ<1,β<0:分布更窄,偏左
# - 如果γ=1,β=0:就是标准正态
# 网络通过学习,找到最适合当前任务的分布
return "让网络自己决定最好的分布"三、BatchNorm为什么有效?
3.1 五大核心作用
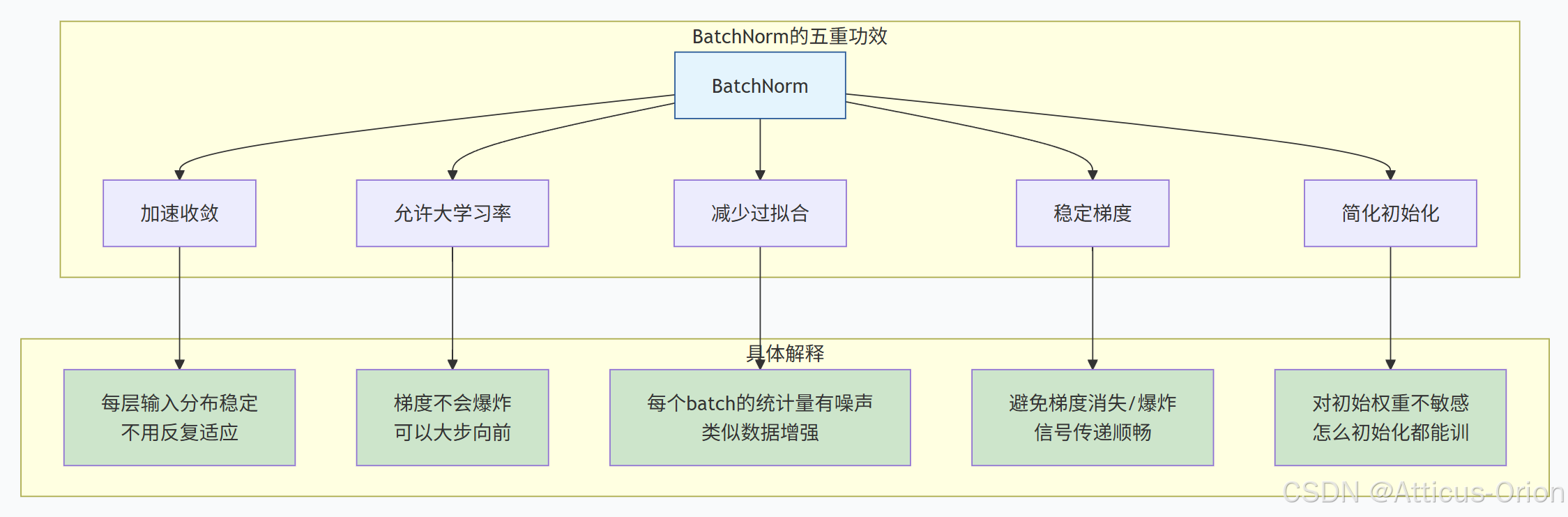
3.2 对梯度的影响
def bn_effect_on_gradient():
"""BatchNorm如何影响梯度"""
# 没有BN时
# ∂L/∂x = ∂L/∂y × ∂y/∂x
# 如果x很大,sigmoid的梯度接近0,梯度消失
# 有BN时
# 1. x被标准化到合理范围,激活函数工作在非饱和区
# 2. 梯度经过BN层时,会自动缩放
# 3. 整体梯度更稳定
# 数学上:BN让损失函数的Landscape更平滑
# 就像把崎岖的山路修成平缓的坡道四、BatchNorm的工作机制
4.1 训练时 vs 推理时
class BNTrainVsInference:
"""BatchNorm在训练和推理时的区别"""
def __init__(self):
self.bn = nn.BatchNorm2d(64)
# BN内部维护的变量
self.bn.running_mean # 训练集全局均值
self.bn.running_var # 训练集全局方差
self.bn.num_batches_tracked # 统计的batch数
def training_forward(self, x):
"""训练时"""
# 1. 用当前batch计算mean和var
batch_mean = x.mean(dim=(0,2,3))
batch_var = x.var(dim=(0,2,3))
# 2. 更新全局统计量(滑动平均)
# running_mean = momentum × running_mean + (1-momentum) × batch_mean
self.bn.running_mean = (0.9 * self.bn.running_mean +
0.1 * batch_mean)
# 3. 用batch的统计量归一化
x_norm = (x - batch_mean) / torch.sqrt(batch_var + 1e-5)
# 4. 缩放平移
return self.bn.weight * x_norm + self.bn.bias
def inference_forward(self, x):
"""推理时"""
# 直接用训练集的全局统计量
x_norm = (x - self.bn.running_mean) / torch.sqrt(self.bn.running_var + 1e-5)
return self.bn.weight * x_norm + self.bn.bias4.2 数学推导为什么有效
def mathematical_insight():
"""
BatchNorm的数学洞察
"""
# 1. 让激活函数的输入落在梯度大的区域
# 对于sigmoid: 当|x|>3时,梯度≈0
# BN让x≈0,梯度≈0.25
# 2. 对梯度的梯度有约束
# ∂BN/∂x 和 ∂BN/∂γ 都有界
# 3. 损失函数变得凸性更好
# 优化路径更直接,不会绕远路
# 4. 有轻微正则化效果
# 因为每个batch的统计量有噪声
# 类似Dropout,防止过拟合五、BatchNorm为什么这么重要?
5.1 历史意义
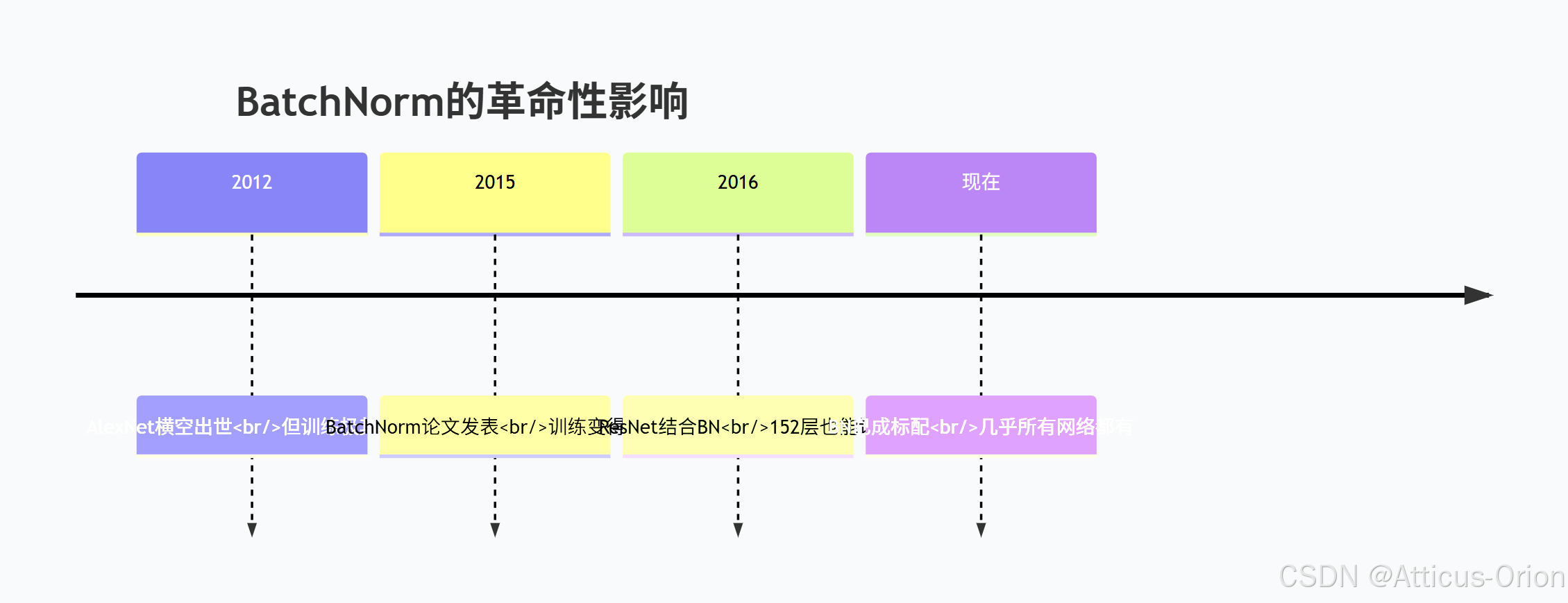
5.2 如果没有BatchNorm
def without_bn_problems():
"""没有BN会怎样"""
problems = {
'训练速度': '慢10倍以上',
'最大深度': '很难超过20层',
'学习率': '必须0.01以下',
'初始化': '必须精心设计',
'梯度问题': '容易消失/爆炸'
}
# 举个例子:要训练一个50层的网络
# 有BN:用0.1的学习率,100轮收敛
# 无BN:用0.01的学习率,可能1000轮还不收敛
return problems六、直观理解总结
6.1 生活比喻大全
| 概念 | 生活比喻 |
|---|---|
| 内部协变量偏移 | 厨师每次做菜,食材新鲜度、火候都不一样 |
| BatchNorm | 标准化菜谱+自动控温的智能厨具 |
| 标准化 | 把各种单位都换算成国际标准单位 |
| γ和β | 根据不同菜系,微调料汁比例 |
| 训练/推理不同 | 练习时用当前手感,比赛时用积累的经验 |
6.2 一句话总结
BatchNorm就是给神经网络的每一层都装上"自动调节器",让输入分布始终保持稳定,网络只需要专注于学习特征,不用分心去适应不断变化的输入分布。
七、终极回答
BatchNorm是什么?
-
是一个让神经网络训练更稳定的"神器"
-
对每一层的输入做标准化,再学习最优的缩放和平移
为什么需要BatchNorm?
-
为了解决"内部协变量偏移"——每层输入分布总在变
-
让网络训练更快、更稳、更容易
它为什么这么有效?
-
它让每层都看到"标准"的输入
-
它让梯度流动更顺畅
-
它让损失函数更容易优化
-
它自带轻微的正则化效果
记住这句话:在深度学习中,稳定压倒一切。BatchNorm就是那个让一切变得稳定的基石!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 23
23 0
0- 0



 已为社区贡献190条内容
已为社区贡献190条内容

所有评论(0)