【浅显易懂理解强化学习】(三):DQN:当查表法装上大脑
本节我们介绍了DQN是如何通过引入神经网络代替Q表,同同时利用 “经验池”和评估网络来进行强化学习的。以及我们补全了两个DQN的进化分支Double DQN和Dueling DQN
·
前言
- 本系列讲究浅显易懂,所以尽量讲的简单并减少数学公式的解释加强实际运用。
- 前两期我们提到的两个算法,
Q-Learning和Sarsa算法,其实他俩本质上都是查表法,只是保守与否的区别。 - 聪明的你一定发现了:当面临连续的状态输入的时候,记录下来的Q表将变得无限大,表的维护和查询将会变得无比困难,也就是我们不得不承认:
- 查表法是有上限的。
- 而本期我们要介绍的
DQN,用一句话来概括就是:- 用神经网络代替 Q 表。
1 前置知识:神经网络
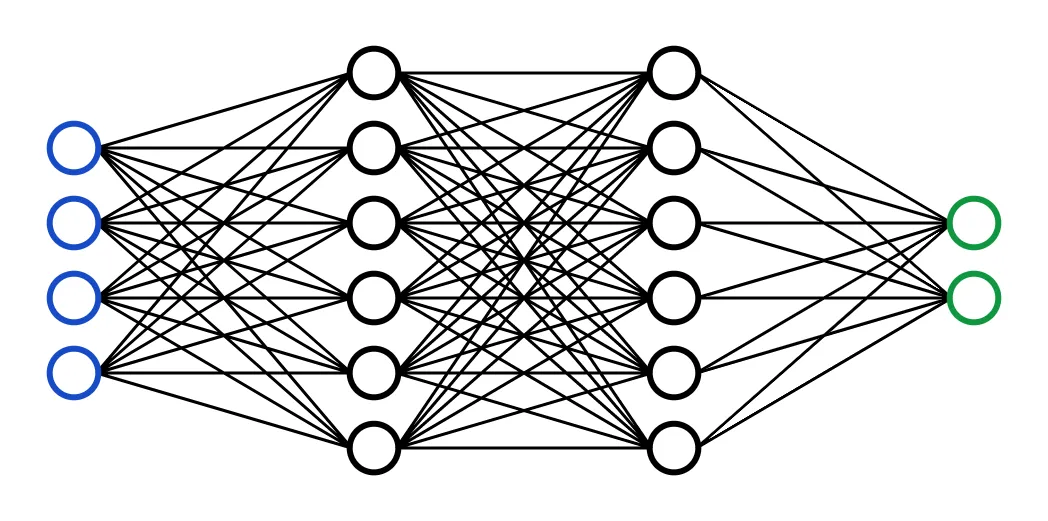
1-1 什么是神经网络(Neural Network)
- 是一类受生物神经系统启发构建的 参数化非线性函数逼近模型, 由多个神经元节点按照层级结构连接组成,通过数据驱动方式学习输入到输出之间的映射关系。
- 它在形式上可以表示为 f ( x ; θ ) f(x;θ) f(x;θ)
- 其中:
- x x x:输入向量
- θ \theta θ:模型参数(权重与偏置)
- f f f:由多层线性变换与非线性映射构成的复合函数
- 说人话就是:
- 神经网络 = 一个可以自动学习
输入和输出关系的函数机器。
- 神经网络 = 一个可以自动学习
- 你给它数据,它自己总结规律。
1-2 神经网络的结构
-
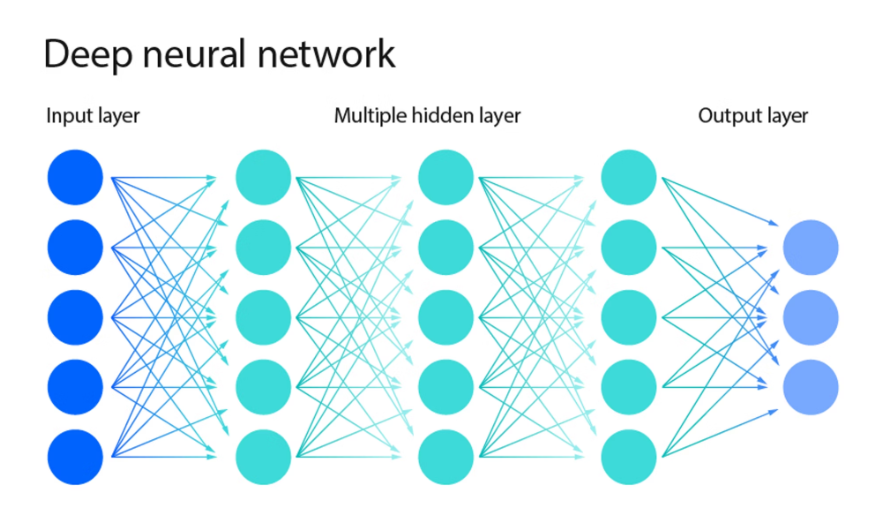
基本的神经网络结构非常简单:输入层 → 隐藏层✖n → 输出层
-
而每一层中,都在做
加权求和(1-3)+激活函数(1-4) -
别急我们一个个看
1-3 加权求和
- 你可以理解为在给定输入和输出的前提下,神经网络将根据已有是所有一一对应的数据,自己计算出一个可以转换二者关系的网络,用于未来预测新的输入对应的输出。
- 我们来看一个最简单的神经元
加权求和的计算公式: z = w 1 ∗ x 1 + w 2 ∗ x 2 + b z=w_1*x_1+w_2*x_2+b z=w1∗x1+w2∗x2+b- x 1 x_1 x1, x 2 x_2 x2:输入数据
- w 1 w_1 w1, w 2 w_2 w2:权重(表示每个输入的重要程度)
- b b b:偏置(可以理解为基础修正值)
- z z z:加权求和后的结果
- 举个例子我们要做一个预测房价的神经网络,而影响到房价的因素往往包含房子年份,房子平方数,房子地理位置等等,那么在这个例子中:
- x 1 x_1 x1, x 2 x_2 x2:房子年份,房子平方数,房子地理位置等等因素
1-4 激活函数
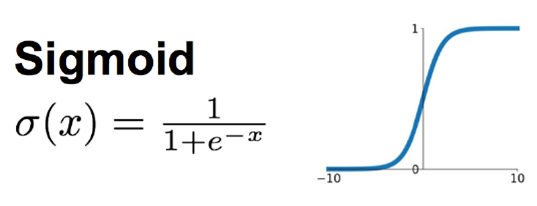
- 上面算出来的只是 z z z,但神经网络还会再做一步: a = σ ( z ) a=σ(z) a=σ(z)
- 这里的 σ \sigma σ 就是激活函数,比如:
- ReLU
- Sigmoid
- Tanh
- 这里不多介绍,但是你只要记住它的作用只有一个:
引入非线性 - 如果没有激活函数,无论叠多少层,最后都等价于一层线性模型,因此激活函数是神经网络“强大”的关键。
1-5 神经网络学习的学习过程
- 回到我们刚刚1-2举的例子: z = w 1 ∗ x 1 + w 2 ∗ x 2 + b z = w_1*x_1 + w_2*x_2 + b z=w1∗x1+w2∗x2+b
- 可以看出,上述例子中的神经网络关键在于:
- 权重 w 1 w_1 w1, w 2 w_2 w2, b b b 是可以被调整的。
- 那么我们的训练流程就变成了:
- 输入数据
- 得到预测结果
- 和真实答案比较
- 计算误差
- 用
“反向传播”调整权重和偏差
- 上述过程不断重复,直到最后权重会变成能让误差最小的一组值。
- 详细的过程诸如
“反向传播”等其他细节这里不再赘述,感兴趣的朋友们可以自行查阅资料。 - 总之神经网络学习的本质就是:自动调整参数,让预测更准。
2 Deep Q Network[DQN]
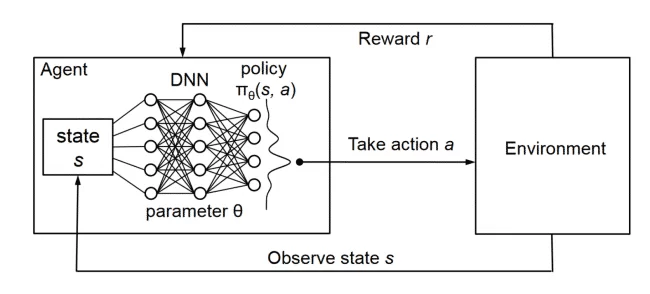
2-1 DQN介绍
- DQN(Deep Q-Network)全称为 深度 Q 网络,是将 Q-Learning 与深度神经网络结合的一种值函数逼近方法。
- DQN 的核心思想非常暴力:不存 Q 表了,用神经网络直接预测 Q 值
- 我们回忆一下第一节提到的Q表:
| 状态 s | 动作 a1 | 动作 a2 | 动作 a3 |
|---|---|---|---|
| s1 | 1.2 | 0.3 | -0.5 |
| s2 | 2.1 | 1.8 | 0.4 |
| s3 | -1.0 | 0.2 | 3.5 |
- Q-learning的本质核心就是在已知状态的情况下,
- 查表找到对应状态的行 → 选Q值最大值对应的动作
- 那么DQN训练出来的神经网络职责也很简单
- 输入:状态 s
- 输出:每个动作的 Q 值
- 然后我们根据选Q值最大值对应的动作执行即可
2-2 DQN 不一定收敛
- 我们在第一期提到过,在有限状态和动作空间下,经典 Q-learning 理论上是可以收敛到最优解的。但当我们用神经网络替代表格时,收敛性就不再有严格保证。
- 贝尔曼最优方程(Bellman Optimality Equation): Q ∗ ( s , a ) = r + γ max a ′ Q ∗ ( s ′ , a ′ ) Q^*(s,a) = r + \gamma \max_{a'} Q^*(s', a') Q∗(s,a)=r+γa′maxQ∗(s′,a′)
- 因此为了保证收敛性,DQN 加了两个关键稳定机制。
- 经验回放(Replay Buffer)
- 目标网络(Target Network)
2-3 经验回放(Replay Buffer)
2-3-1 问题描述
- 在传统 Q-Learning 中,我们是:
- 与环境交互一步 → 立刻用这一步数据更新 Q 表。
- 但当我们用神经网络时,如果仍然按时间顺序更新,就会出现一个严重问题:
数据强相关 - 强化学习的数据是“连续产生”的:
(s1,a1,r1,s2)
(s2,a2,r2,s3)
(s3,a3,r3,s4)
- 可以看到:
- 下一条数据和上一条高度相关
- 神经网络会在某一段数据分布上来回震荡
- 梯度方向可能非常不稳定
- 这会导致网络在局部区域疯狂抖动,难以收敛。
2-3-2 “经验池”(Replay Buffer)的引入
- 因此DQN 引入一个“经验池”(Replay Buffer):
- 每一步交互得到的数据都存进一个大数组中
- 训练时从这个经验池里随机抽取一批数据
- 用这批数据一起训练神经网络
- 一句话总结:
- 经验回放 = 把“边走边学”变成“攒一批一起学”。
2-4 目标网络(Target Network)
2-4-1 问题描述
- 区别于传统神经网络的监督式学习有提前给定好的已经标记的数据集,DQN是没法从给定好已标记的数据集学习的
- 因此即使有经验回放,问题仍然存在:
- 目标值来自网络自己。
- 我们回忆一下
Q-learning的更新公式: Q ( s , a ) ← r + γ m a x Q ( s ′ , a ′ ) Q(s,a)←r+γmaxQ(s^′,a^′) Q(s,a)←r+γmaxQ(s′,a′) - 那么在 DQN 中:
- 左边是当前网络预测
- 右边也是当前网络预测
- 这相当于,用一个不断变化的模型去追逐自己。
- 说人话:
- 你一边改试卷,一边改答案标准。(屋檐了!!)
2-4-2 两个网络
- 因此DQN引入二个网络:
- 评估网络(Evaluation Network)
- 负责学习
- 每一步都更新参数
- 目标网络(Target Network)
- 只负责计算目标 Q 值
- 每隔一段时间复制评估网络参数
- 评估网络(Evaluation Network)
- 也就是在训练中每隔一定步数: θ t a r g e t ← θ e v a l θ_{target} ← θ_{eval} θtarget←θeval
2-4-3 为什么两个网络能缓解?
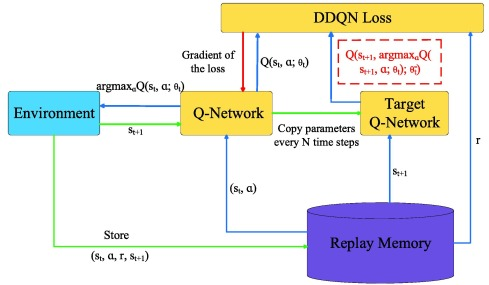
- 我们来看看DQN修改的公式 y = r + γ max a ′ Q θ − ( s ′ , a ′ ) y = r + \gamma \max_{a'} Q_{\theta^-}(s', a') y=r+γa′maxQθ−(s′,a′)
- 其中:
- θ θ θ:评估网络(更新)
- θ − θ⁻ θ−:目标网络(冻结一段时间)
- 现在:
- 左边
Q(s,a)用θ - 右边
y用θ⁻(固定)
- 左边
- 也就是说在这段时间内: y 是常量 y是常量 y是常量
- 这就变成一个标准监督学习问题: min θ ( y − Q θ ) 2 \min_{\theta}( {y-Q_\theta})^2 θmin(y−Qθ)2
- 优化目标稳定 → 梯度方向稳定 → 更接近经典 Q-learning 的收敛条件。
- 说人话原来的单网络相当于
- 你一边改试卷,一边改答案标准。(你永远追不上的正确答案)
- 现在引入两个网络后就是:
- 固定一份标准答案(目标网络)
- 你专心按照这份标准改试卷(更新评估网络)
- 改一段时间后
- 再把“新的试卷水平”升级为新的标准答案
- 再继续固定标准答案改试卷
2-6 DQN实际的更新过程
- 第一步:初始化
- 初始化评估网络参数
- 复制一份作为目标网络
- 创建经验池
- 第二步:与环境交互
- 循环执行:
- 根据 ε-greedy 选择动作
- 执行动作,获得:
- 当前状态 s
- 动作 a
- 奖励 r
- 下一个状态 s’
- 将 (s,a,r,s’) 存入经验池
- 循环执行:
- 第三步:开始训练
- 当经验池数据足够时:
- 随机抽取一批数据(batch)
- 用目标网络计算目标值: y = r + γ max Q t a r g e t ( s ′ ) y = r + \gamma \max Q_{target}(s') y=r+γmaxQtarget(s′)
- 用评估网络预测当前 Q 值: Q e v a l ( s , a ) Q_{eval}(s,a) Qeval(s,a)
- 计算两者误差(通常用均方误差)
- 反向传播更新评估网络参数
- 当经验池数据足够时:
- 第四步:定期更新目标网络
- 每隔 C 步: θ t a r g e t ← θ e v a l θ_{target} ← θ_{eval} θtarget←θeval
- 介绍完DQN,我们再来看两个进阶的DQN变种。
- Double DQN
- Dueling DQN
3 Double DQN
3-1 问题背景
- 我们回忆一下,在 DQN 中,目标值计算使用了 y = r + γ max a ′ Q t a r g e t ( s ′ , a ′ ) y = r + \gamma \max_{a'} Q_{target}(s',a') y=r+γa′maxQtarget(s′,a′)
- 虽然我们引入了两个网络避免自己追自己无法收敛的情况,但是这里有两个问题:
- 选择动作和计算价值用的是同一个最大操作。
max操作容易偏向那些暂时估计高的动作 → 高估 Q 值。
3-2 Double DQN 的核心思想
- Double DQN 的核心理念是:“选动作和算价值用不同的网络”,避免自己给自己吹牛。
- 用评估网络(Evaluation Network)选动作 a ∗ = arg max Q e v a l ( s ′ , a ′ ) a^* = \arg\max Q_{eval}(s',a') a∗=argmaxQeval(s′,a′)
- 这里确定哪个动作看起来最好。
- 用目标网络(Target Network)算价值 y = r + γ Q t a r g e t ( s ′ , a ∗ ) y = r + \gamma Q_{target}(s',a^*) y=r+γQtarget(s′,a∗)
- 这里再去算这个动作的真实 Q 值。
- 用评估网络(Evaluation Network)选动作 a ∗ = arg max Q e v a l ( s ′ , a ′ ) a^* = \arg\max Q_{eval}(s',a') a∗=argmaxQeval(s′,a′)
- 两个网络结构是一模一样的(层数、节点数、激活函数都一样),唯一的区别就是参数不同,以及我们选用的内容不一样。
- 这样就把“选择”和“评价”分开:
- 评估网络帮你决定动作
- 目标网络帮你计算这个动作的价值
- 避免了 DQN 自己给自己打高分
- 说人话:
- 普通 DQN: “我觉得哪张卷子最高分,就拿它当标准答案” → 容易自我膨胀。
- Double DQN: “先问朋友哪张卷子看起来最好 → 再去查评分标准给它打分” → 更真实,更稳。
3-4 Double DQN 更新流程(简化版)
- 与环境交互,存储
(s,a,r,s')到经验池。 - 从经验池随机抽取 batch 数据。
- 选动作:用评估网络 a ∗ = arg max Q e v a l ( s ′ , a ′ ) a^* = \arg\max Q_{eval}(s',a') a∗=argmaxQeval(s′,a′)
- 算目标 Q 值:用目标网络 y = r + γ Q t a r g e t ( s ′ , a ∗ ) y = r + \gamma Q_{target}(s', a^*) y=r+γQtarget(s′,a∗)
- 计算误差并更新评估网络参数: L = ( y − Q e v a l ( s , a ) ) 2 L = (y - Q_{eval}(s,a))^2 L=(y−Qeval(s,a))2
- 每隔一段时间,把评估网络参数复制到目标网络。
4 Dueling DQN
4-1 问题背景
- 我们来思考一个问题
- 在某些状态下,动作真的那么重要吗?
- 举个例子:
- 游戏角色已经站在安全区域
- 左走一下、右走一下的奖励几乎一样
- 那这时候游戏角色可能就卡在原地左右摇摆
- 换句话说有些状态的好坏,主要由“状态本身”决定 ,而不是由“动作差异”决定
4-2 Dueling DQN 核心思想
- Dueling DQN 做了一件非常聪明的事情:
- 把 Q(s,a) 拆成两部分来学习。
- V ( s ) V(s) V(s):这个状态本身的价值,不考虑具体动作。
- A ( s , a ) A(s,a) A(s,a):在这个状态下,某个动作比“平均动作”好多少?
- 最终 Q 值计算为: Q ( s , a ) = V ( s ) + ( A ( s , a ) − 1 ∣ A ∣ ∑ a ′ A ( s , a ′ ) ) Q(s,a) = V(s) + \left(A(s,a) - \frac{1}{|A|}\sum_{a'} A(s,a') \right) Q(s,a)=V(s)+(A(s,a)−∣A∣1a′∑A(s,a′))
- 使用平均值的原因是让优势函数的平均值为 0
- V 专门负责“状态整体价值”
- A 专门负责“动作之间的差异”
- 说人话就是
- 先判断这个场景值不值钱,再判断动作之间谁更好
4-3 Double Dueling DQN更新流程(简化版)
- Dueling DQN + Double DQN 的组合
- 与环境交互
- 执行动作,获得
(s, a, r, s'),存入经验池。
- 执行动作,获得
- 从经验池抽取数据
- 随机抽取一批数据(batch),打破时间相关性。
- 计算当前 Q 值
- 用 Dueling 网络的 V(s) 和 A(s,a) 计算当前状态-动作 Q 值: Q e v a l ( s , a ) = V ( s ) + ( A ( s , a ) − 1 ∣ A ∣ ∑ a ′ A ( s , a ′ ) ) Q_{eval}(s,a) = V(s) + \left(A(s,a) - \frac{1}{|A|}\sum_{a'} A(s,a') \right) Qeval(s,a)=V(s)+(A(s,a)−∣A∣1a′∑A(s,a′))
- 计算目标 Q 值
- Double Dueling DQN 风格:
- 用评估网络选动作 a ∗ = arg max Q e v a l ( s ′ , a ′ ) a^* = \arg\max Q_{eval}(s',a') a∗=argmaxQeval(s′,a′)
- 用目标网络计算该动作的 Q 值 y = r + γ Q t a r g e t ( s ′ , a ′ ) y = r + \gamma Q_{target}(s', a') y=r+γQtarget(s′,a′)
- Double Dueling DQN 风格:
- 计算误差并更新参数
- 均方误差: L = ( y − Q e v a l ( s , a ) ) 2 L = (y - Q_{eval}(s,a))^2 L=(y−Qeval(s,a))2
- 反向传播,更新评估网络参数,包括 V 分支和 A 分支。
- 定期更新目标网络
- 每隔一定步数,把评估网络参数复制到目标网络: θ t a r g e t ← θ e v a l θ_{target} ← θ_{eval} θtarget←θeval
- Dueling DQN 本质上就是把“状态价值”和“动作优势”分开学,更新流程和普通 DQN 类似,但计算 Q 值时多了一步分支合并。
- 可以和 Double DQN 结合 → Double Dueling DQN,同时减少高估问题和提升学习效率。
小节
- 我们用一个表格来总结这三个DQN
| 特性 | DQN | Double DQN | Dueling DQN |
|---|---|---|---|
| 核心思想 | 用神经网络代替 Q 表,直接预测每个动作的 Q 值 | 解决 DQN Q 值高估问题:用评估网络选动作,用目标网络算价值 | 把 Q ( s , a ) Q(s,a) Q(s,a) 拆成 V ( s ) V(s) V(s) + A ( s , a ) A(s,a) A(s,a),分开学状态值和动作优势 |
| 动作选择 | 直接用 Q 值最大动作 | 用评估网络选动作 | 用评估网络选动作 |
| 目标 Q 值计算 | m a x Q t a r g e t ( s ′ , a ′ ) max Q_{target}(s',a') maxQtarget(s′,a′) | 用目标网络算 Q t a r g e t ( s ′ , a ∗ ) Q_{target}(s', a^*) Qtarget(s′,a∗)(a* 来自评估网络) | 用目标网络算 Q t a r g e t ( s ′ , a ∗ ) Q_{target}(s', a^*) Qtarget(s′,a∗) |
| 高估问题 | 容易高估 | 减少高估 | 减少高估(结合 Double DQN 还能进一步改进) |
| 状态-动作分离 | 不分离 | 不分离 | 分离: V ( s ) V(s) V(s)学状态价值, A ( s , a ) A(s,a) A(s,a) 学动作优势 |
| 适用场景 | 状态空间较小,动作差异明显 | 状态空间较小/中等,防止高估 | 状态空间大,动作差异小/不重要的状态多 |
| 学习效率 | 中等 | 较高 | 高(尤其在状态影响大、动作影响小的情况下) |
| 收敛稳定性 | 有一定波动 | 更稳定 | 更稳定,更快收敛 |
- 本节我们介绍了DQN是如何通过引入神经网络代替Q表,同同时利用 “经验池”和评估网络来进行强化学习的。以及我们补全了两个DQN的进化分支Double DQN和Dueling DQN
- 下一期我们讲解Policy Gradients算法
- 希望文章对你有帮助,如有错误,欢迎指出。
参考

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)