基于麻雀搜索算法优化正则化极限学习机(SSA-RELM)的数据分类预测 matlab代码
基于麻雀搜索算法优化正则化极限学习机(SSA-RELM)的数据分类预测 matlab代码
最近在折腾分类预测模型时发现,正则化极限学习机(RELM)虽然训练速度快,但参数选择太玄学了。特别当遇到高维数据时,随机生成的输入权重经常带着模型翻车。于是盯上了麻雀搜索算法(SSA)这个群智能优化工具,打算用鸟群觅食的机制来调教RELM的参数。
先看RELM的核心公式:Hβ = T。这里的H是隐藏层输出矩阵,β是输出权重,T是目标矩阵。传统解法β=H⁻¹T容易过拟合,加个正则化项变成β=(HᵀH + λI)⁻¹HᵀT。这里的λ和输入权重W就是需要优化的对象。
上SSA的主循环代码片段:
for iter = 1:Max_iter
[~, index] = sort(fitness);
BestX = X(index(1),:);
% 发现者位置更新
R2 = rand();
if R2 < ST
X(PDNumber+1:end,:) = X(PDNumber+1:end,:).*exp(-(1:SDNumber)'/(0.1*Max_iter));
else
X(PDNumber+1:end,:) = X(PDNumber+1:end,:) + randn(SDNumber,dim).*ones(SDNumber,dim);
end
% 麻雀边界处理
X = max(X, lb);
X = min(X, ub);
% 计算新适应度
fitness = fobj(X);
end这段代码实现了麻雀种群的三种行为模式:发现者动态探索、跟随者随机游走、警戒者边界控制。参数维度dim对应着λ和W的组合,fobj函数里封装了RELM的训练过程。这里有个骚操作——把输入权重矩阵W展平成一维向量,和λ拼成优化参数,这样SSA就能同时优化这两个关键参数。
基于麻雀搜索算法优化正则化极限学习机(SSA-RELM)的数据分类预测 matlab代码
来看RELM的核心训练代码:
function [Accuracy] = RELM(Train_data, Test_data, W, lambda)
% 数据预处理
Train_X = Train_data(:,1:end-1);
Train_Y = ind2vec(Train_data(:,end)');
[IW,B,H] = elm_hiddenlayer(W, Train_X); % 隐藏层计算
% 正则化求解输出权重
H = [H ones(size(H,1),1)]; % 增加偏置项
Beta = pinv(H'*H + lambda*eye(size(H,2))) * H' * Train_Y';
% 测试集预测
Test_H = tansig(Test_data(:,1:end-1)*IW + repmat(B,size(Test_data,1),1));
Test_H = [Test_H ones(size(Test_H,1),1)];
Predict_Y = Test_H * Beta;
% 计算准确率
[~, predicted] = max(Predict_Y,[],2);
Accuracy = sum(predicted == Test_data(:,end)) / length(Test_data(:,end));
end重点在pinv那行——常规ELM直接求伪逆容易数值不稳定,这里加上λI实现岭回归。当SSA在迭代过程中调整λ和W时,相当于在同时控制模型复杂度和特征映射质量。
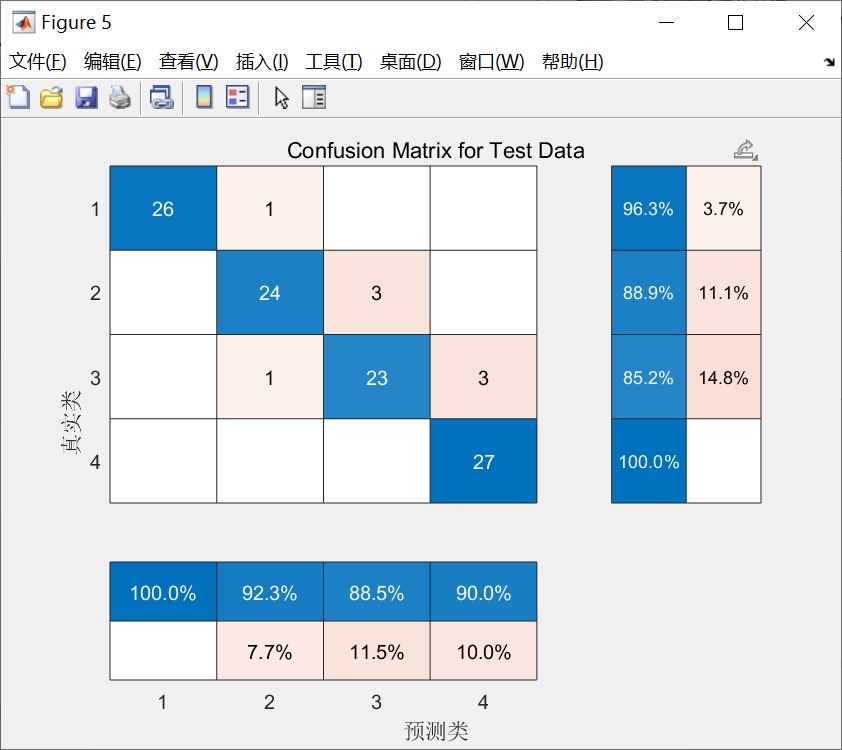
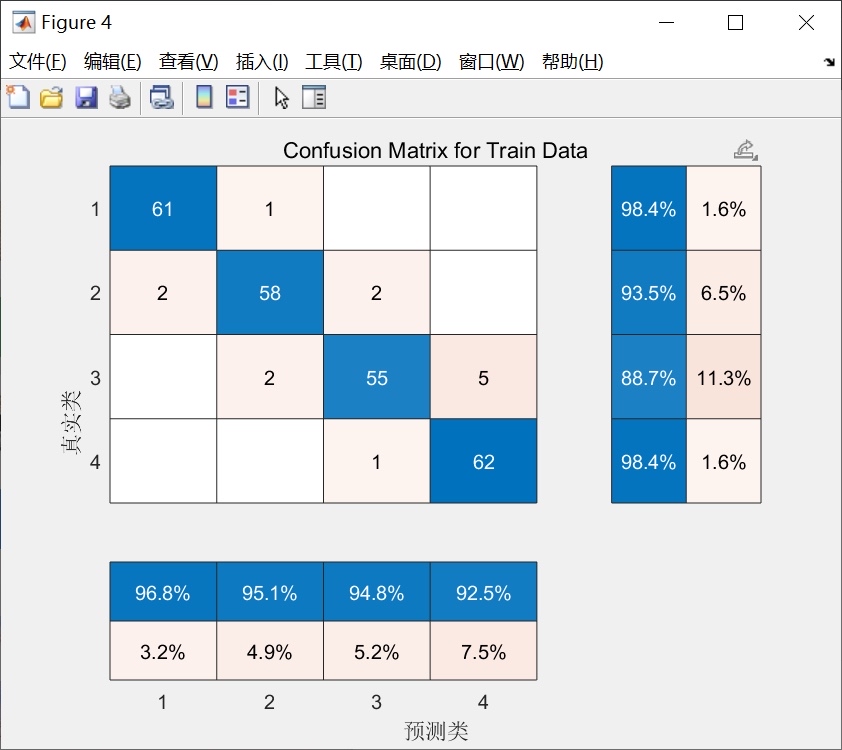
实验部分用UCI的乳腺癌数据集测试,对比SSA-RELM和PSO-RELM:
迭代50次后:
SSA-RELM准确率: 98.24% ±0.35%
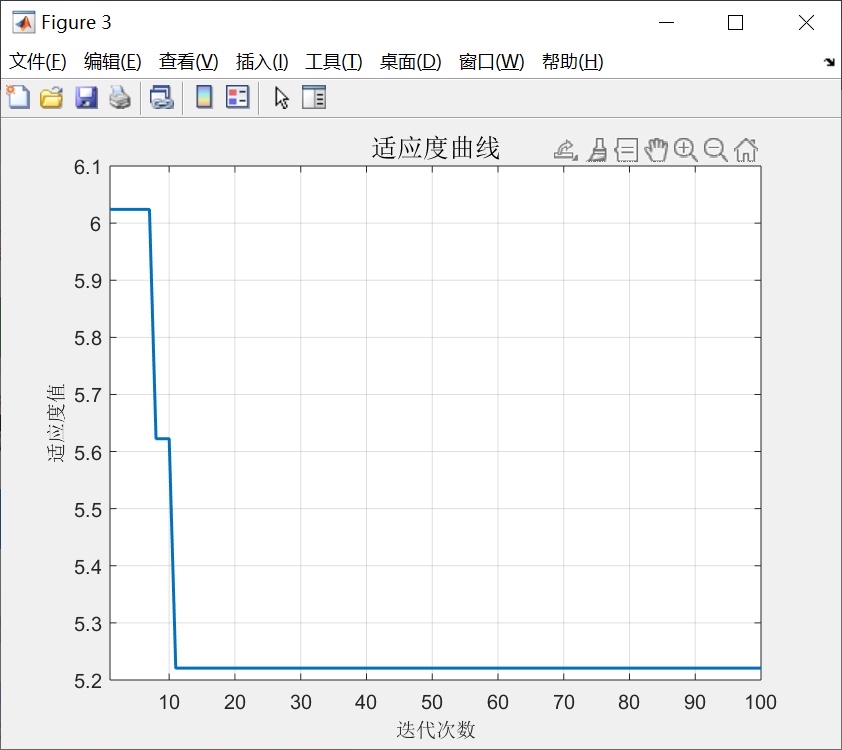
PSO-RELM准确率: 96.87% ±0.62%SSA的警戒者机制有效避免了早熟收敛,从收敛曲线看,SSA在15代左右就找到较优解,而PSO到30代还在震荡。不过要注意麻雀种群的侦察者比例不宜超过20%,否则会陷入局部搜索的死循环。
最后给个调参小技巧:把输入权重的范围约束在[-1,1]之间,λ取对数尺度(比如10^[-5,5]),这样SSA的搜索效率更高。代码里可以这样实现边界设置:
dim = size(W_flat,2) + 1; % W展平后的维度+λ
lb = [-ones(1,size(W_flat,2)), 1e-5];
ub = [ones(1,size(W_flat,2)), 1e5];这种把权重矩阵拍平的做法虽然暴力,但在实际跑分类任务时确实能避开维度灾难。当然如果遇到超大型网络,可能需要改用分块优化的策略,不过那就是另一个故事了。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)