Python强化学习入门
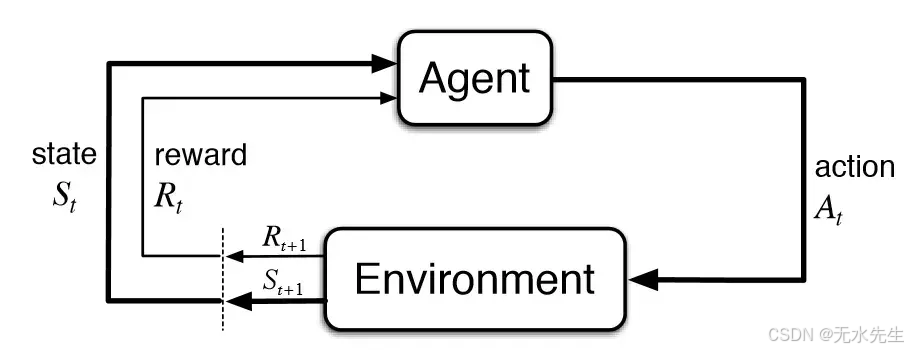
强化学习(RL)是机器学习的一个分支,它不同于监督学习和无监督学习。事实上,“强化”一词指的是一种基于奖励的学习方式,它能够解决决策问题,在这种学习方式中,智能体通过反复试错,自主地与所处环境进行交互。
一、说明
强化学习(RL)是机器学习的一个分支,它不同于监督学习和无监督学习。事实上,“强化”一词指的是一种基于奖励的学习方式,它能够解决决策问题,在这种学习方式中,智能体通过反复试错,自主地与所处环境进行交互。
与监督式或无监督式方法不同,强化学习基于迭代学习过程,其中智能体通过奖励和惩罚系统进行学习。
二、概述
举个例子:假设我们要第一次训练我们的四脚朋友(名叫小红),我们希望它在我们慢慢远离它的时候保持静止。小红正确执行指令时会得到奖励,但每次它未经允许试图站起来时都会受到惩罚。
这个学习过程与我们和其他动物的学习过程完全相同:通过与环境的互动,我们学会如何行动以实现期望的结果。同样,强化学习(RL)利用奖励和惩罚系统作为积极和消极的行为信号。强化学习的特点是其基于互动的方法,因此目标是学习一种策略,即最大化奖励的最优策略。
2.1 基本概念
强化学习(RL)的目标是识别一个合适的模型,使智能体能够最大化其可获得的总奖励。让我们了解理解强化学习基本原理所需的关键术语:
• 环境——智能体运作的空间
• 状态——智能体所处的状态
• 奖励——从环境中获得的积极反馈
• 策略——定义智能体的动作
• 价值——智能体执行特定动作将获得的未来奖励
环境代表智能体运作的物理或虚拟背景,而状态描述智能体在某一时刻所处的状况。智能体采取的每个动作都会影响环境,并通过奖励系统进行评估。
该策略定义了基于当前状态应采取的行动,而价值则表示通过执行特定行动可获得的未来奖励的估计值。这些元素协同工作,引导智能体做出最优决策。然而,要确定最佳行动,智能体必须面对一个关键挑战:探索新状态的同时,最大化预期奖励。
2.2 探索与利用
探索与利用之间的权衡是强化学习中的一个核心概念,对智能体的学习至关重要。
探索指的是允许智能体尝试不同的动作,即使这些动作并非最优,以获取关于环境的新信息。换句话说,智能体旨在扩展其知识,以潜在地发现可能在未来带来更高回报的动作。尽管存在无法获得最大即时回报的风险,但探索对于长期改进智能体的策略是必不可少的。
另一方面,利用是指利用已获取的信息,在特定时刻最大化奖励。在此阶段,智能体倾向于选择过去已产生最佳结果的动作,从而降低无效动作的风险。这两种方面的权衡在于智能体必须维持的平衡。如果智能体过度探索,可能会错失即时奖励,但或许能发现未来更有效的策略。相反,如果智能体专注于利用而忽视探索阶段,则可能错失学习新策略、更盈利策略的机会。
让我们暂时回到我们心爱的红。如果像例子中的狗那样,它犯了错误并受到纠正(一种训斥),这并不意味着学习过程是负面的!每一次错误都是通向更深入理解“保持原地”含义的一步。在这种情况下,“训斥”成为学习过程的一部分,它将引导狗在未来,在充分探索环境并理解正确行为后,执行正确的动作。在强化学习中,这相当于智能体收集经验,即使这些经验并非总是立即带来奖励,也是为了优化其未来的决策并最大化总体奖励。
因此,最优学习策略必须动态整合探索与利用,以适应环境的演变以及智能体所获取的信息。
2.3 马尔可夫决策过程
强化学习的理论支柱之一是马尔可夫决策过程(MDP),它为需要进行序列决策的问题提供了数学基础。
• 状态:它们代表智能体在环境中可能遇到的所有情况。每个状态描述智能体的当前状况。
• 动作:它们是智能体在每个状态下可选择的选项。在每种情况下,智能体可以从各种动作中选择,以决定其下一步行动。
• 奖励:对于在给定状态下采取的每个动作,智能体都会收到正反馈或负反馈,这表示该选择与目标的相关有用性。这种反馈指导智能体的学习。
• 状态转移:它们代表状态之间的联系。当智能体在一个状态下执行动作时,会转移到新状态。转移描述了这种状态转换发生的方式以及发生的概率。
该框架为强化学习旨在解决的问题提供了清晰的定义,并为开发能够解决这些问题的算法提供了有用的结构。大多数强化学习问题都可以建模为马尔可夫决策过程(MDP),使其成为接触这一领域的人们的基本工具。
2.4 阶段性任务与连续性任务
马尔可夫决策过程(MDPs)中的一个核心概念是“任务”,即智能体必须达成的目标。任务主要分为两类:
• 阶段性任务:这类任务具有起点和终点。智能体执行一系列动作以完成一个“回合”(episode),即一系列步骤,最终达到一个终止状态。例如,在国际象棋游戏中,当一方玩家获胜或游戏以平局结束时,回合便告终结。
• 连续性任务:在这些任务中,过程没有明确的终点,智能体必须持续与环境交互而不会进入终止状态。例如,工业工厂的控制系统没有预定的终点,但必须持续优化生产流程。
区分 episodic 任务和 continuous 任务很重要,因为它会影响学习算法的设计方式。在 episodic 任务中,奖励会在 episode 结束时进行分析,以改进未来的决策。而在 continuous 任务中,智能体必须持续更新其策略,以实时适应环境。这种区分为理解强化学习的各种方法提供了概念基础,并有助于定义所要解决的问题类型。
2.5 确定最优策略的方法
在马尔可夫决策过程(MDP)中,目标是确定最优策略,即一种能最大化长期累积奖励的策略。训练智能体实现这一目标主要有两种方法:
- 基于策略的方法:这些方法直接专注于策略学习,即识别在每个状态下应采取的最佳行动。智能体被训练直接将状态映射到行动,而无需构建状态价值的显式表示。这种方法在具有连续动作空间的问题中尤为有用。
- 基于价值的方法:在这些方法中,智能体学习状态或动作的价值(通过价值函数),并选择能最大化这些价值的行动。其目标是准确估计处于给定状态或执行特定动作在预期未来奖励方面的“好坏”程度。
两种方法的选择取决于问题的性质和环境的特点。
三、最著名的算法和方法
Q-Learning 和 SARSA 是强化学习中两种基础且广泛使用的算法,两者均旨在学习一种能最大化累积奖励的最优策略。然而,它们在处理探索和学习的方式上存在差异。
3.1 Q-Learning:离线策略学习
Q-Learning 是一种离线策略算法,这意味着 Q 值的更新并不直接依赖于智能体在探索过程中采取的动作。换句话说,Q-Learning 假设智能体始终执行最佳可能动作(即价值最高的动作),即使在现实中它可能选择了其他动作。
这种方法使算法能够更专注于利用长期最优策略,而不受探索阶段所用策略的束缚。得益于这一特性,Q学习即使在智能体以平衡探索与利用的策略探索环境时,也能特别有效地学习到最优策略。因此,Q学习的主要优势在于其能够学习到最优策略,而无需考虑探索过程中实际采取的动作,这使其成为一种积极进取且注重结果的算法。
3.2 SARSA:同策略学习
与Q学习不同,SARSA是一种同策略算法,这意味着Q值的更新基于智能体在探索过程中实际选择的动作。在这种情况下,智能体在更新Q值时会同时考虑当前状态以及根据其当前策略将要选择的下一个动作。
这使得SARSA相比Q学习更加“谨慎”,因为它考虑的是智能体实际做出的决策,而不是对理想最优行为进行假设。这一特性使其更适合探索可能涉及风险的场景,例如动态或不熟悉的环境,在这些环境中,错误的选择可能会带来负面影响。
3.3 Q-Learning 与 SARSA 的主要区别
• 学习方法:Q-Learning 的学习过程独立于探索阶段所采用的策略,而 SARSA 则直接依赖于智能体采取的动作。
• 探索策略:Q-Learning 倾向于更具侵略性,以最优行为为导向;而 SARSA 采用更为保守的策略。
• 应用场景:Q-Learning 更适用于静态且可预测的环境,在此类环境中探索不会带来显著风险。相反,SARSA 在动态或不确定的环境中表现更佳,在这些环境中考虑探索相关风险至关重要。
尽管这两种算法都非常实用且易于应用,但它们存在一个共同的局限性:难以推广到尚未访问过的状态。在实际应用中,它们会为每一种可能的状态和动作组合存储Q值,这使得它们在具有非常大或连续状态空间的环境中效率低下。这一问题出现在机器人控制或复杂视频游戏等场景中,在这些场景中可能的状态数量可能极高。为解决这些局限性,已开发出更先进的算法。例如:
• 深度Q网络(DQN):利用神经网络近似Q值,从而能够处理非常大且连续的状态空间。
• SARSA Lambda:引入了一种泛化机制以提高效率。
• 优势-批评家(Actor-Critic):结合了策略学习和基于价值的学习元素,增强了解决复杂问题的能力。
得益于这些进步,现在可以将强化学习应用于现实且复杂的场景,这些场景超出了传统方法的能力范围。然而,Q学习和SARSA仍然是该领域的基础支柱,为理解和开发更复杂的算法提供了基础。
3.4 深度Q网络与深度确定性策略梯度
在强化学习领域,深度Q网络(DQN)和深度确定性策略梯度(DDPG)等算法标志着一个转折点,它们能够克服基于Q学习或基于策略方法的传统方法的诸多局限。事实上,这些算法整合了神经网络的能力来解决复杂问题。
3.5 深度Q网络
深度Q网络(DQN)将Q学习与神经网络相结合,用于估计Q值,这些Q值代表在特定状态下采取特定动作的预期价值。这种方法在状态空间过大而无法明确表示的场景中已被证明特别有效。神经网络通过将状态映射到最优动作来实现学习的泛化,而无需探索所有可能的组合。
DQN的一项关键创新是使用单独的目标网络来稳定训练。此外,该算法实现了称为经验回放的过程,即将过去的经验(以状态、动作、奖励和下一状态的形式)存储在缓冲区中,并重新利用这些经验来更新网络权重。这种机制降低了数据之间的相关性,
3.6 深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)
专为具有连续动作空间的环境设计,在这些环境中DQN难以直接应用。它基于Actor-Critic原理,其中两个神经网络协同工作:
• Actor网络:直接学习确定性策略,将每个状态映射到特定动作。
• Critic网络:采用基于Q学习的方法,评估Actor建议的动作价值。
DDPG的一个显著特点是使用探索性噪声,通过向动作添加扰动来鼓励智能体探索新策略。这在具有复杂动态和高维动作空间的环境中尤为有用。
3.7 先进算法的应用
这些算法代表了强化学习领域的最先进技术,并广泛应用于各个行业。例如,在机器人领域,DDPG算法使机器人能够在三维环境中学习精确的动作,如抓取物体或在拥挤空间中导航。在游戏行业,DQN算法已被用于在各种雅达利视频游戏中超越人类记录,展示了其在处理复杂和动态环境方面的有效性。
采用此类算法不仅能够解决高计算复杂度的问题,还能探索强化学习可能产生决定性影响的新领域。
四、Python 示例
现在让我们使用 OpenAI Gymnasium 包来看一个 Python 应用程序。
Gymnasium的主要特点之一是提供种类丰富的预配置环境,每个环境具有不同的复杂程度,并针对强化学习算法的训练和测试具有特定用途。其中,MountainCar环境是一个经典的入门问题,可用于探索强化学习的基本概念。
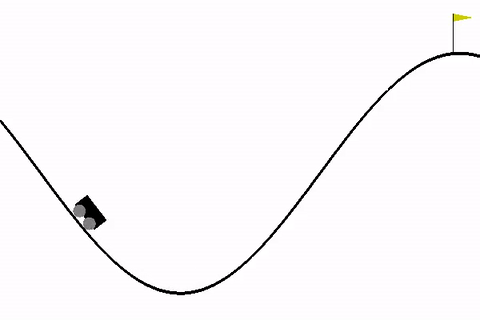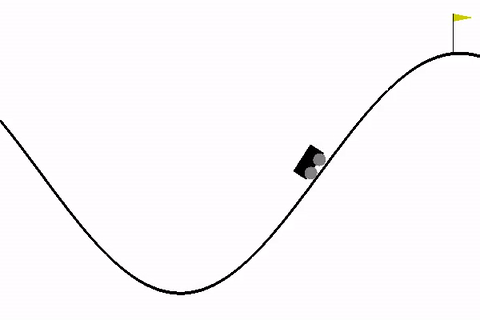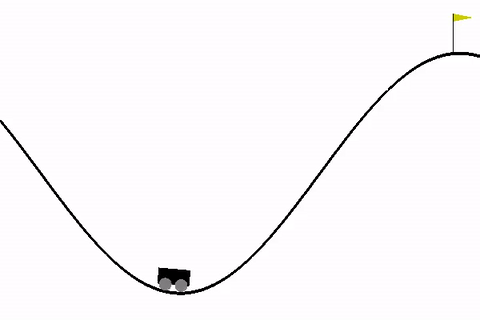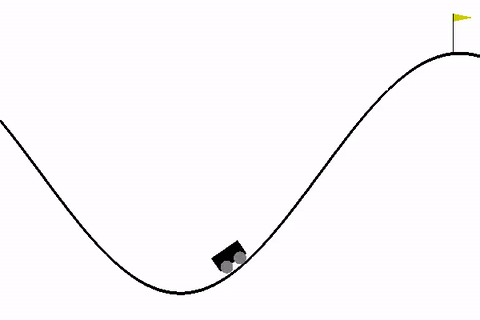
在使用强化学习环境(如MountainCar)时,理解观测空间和动作空间的结构至关重要,它们定义了智能体可以采取的可能状态和动作。
• 观测空间(observation_space):以MountainCar为例,环境返回的是Box类型空间。这种空间用于表示连续值(例如MountainCar中汽车的位置和速度)。MountainCar的Box形状为(2,),这意味着观测是一个包含两个值的向量,一个对应汽车的位置,另一个对应汽车的速度。
• 汽车位置:数组中的第一个值表示汽车沿山谷的位置,范围从-1.2(左端)到0.6(右端)。
• 汽车速度:数组中的第二个值表示汽车速度,其范围为-0.07至0.07。
Box函数通过上下限约束这些值,这意味着系统返回的任何观测结果都将是落在这些限制范围内的向量。例如,初始状态中位置为-1.2、速度为0.0是一个有效的组合。
2. 动作空间(action_space):环境定义了一个Discrete(3)动作空间,即存在三种可能的动作。这些动作是离散的,对应如下:
• 0:向左加速。
• 1:不加速(保持静止)。
• 2:向右加速。
在山地汽车(MountainCar)问题中,智能体必须在这三个动作中进行选择,以尝试将汽车开上山。不存在其他动作或组合,这使得动作成为一个有限选择的离散集合。
import time
# Number of steps you run the agent for
num_steps = 1500
obs = env.reset()
for step in range(num_steps):
# take random action, but you can also do something more intelligent
# action = my_intelligent_agent_fn(obs)
action = env.action_space.sample()
# apply the action
obs, reward, done, info = env.step(action)
# Render the env
env.render()
# Wait a bit before the next frame unless you want to see a crazy fast video
time.sleep(0.001)
# If the epsiode is up, then start another one
if done:
env.reset()
# Close the env
env.close()
type(env.observation_space)
#OUTPUT -> gym.spaces.box.Box
print("Upper Bound for Env Observation", env.observation_space.high)
print("Lower Bound for Env Observation", env.observation_space.low)
OUTPUT:
Upper Bound for Env Observation [0.6 0.07]
Lower Bound for Env Observation [-1.2 -0.07]
代码的第一步是创建和初始化环境,环境代表智能体将要运行的世界。在此案例中,环境为“山地小车”(MountainCar),小车需要从山谷被推到山顶。环境会被重置,回到初始状态,此时小车位于两座山之间。重置后立即关闭环境,但此步骤仅在更广泛的上下文中(例如更复杂的模拟)用于释放资源。
环境具有一个“观测空间”,用于描述智能体能够感知的内容。以“山地小车”为例,智能体可以观测到小车的位置和速度。每次智能体观察环境时,都会收到这些数值的更新。这些数值是有限的,因此环境为位置和速度这两个变量分别设定了“上限”和“下限”。例如,位置的范围是从-1.2(山谷中非常靠左的位置)到0.6(小车开始爬山的位置),速度的范围则限定在-0.07到0.07之间。
一旦环境初始化完成且智能体能够获取相关信息,它便进入与环境的持续交互循环。智能体必须采取行动以探索环境。该循环的每个“步骤”代表一次迭代,在此过程中智能体执行以下操作:
• 选择动作:在此情况下,智能体并非基于智能策略做决策,而是随机选择动作,例如向左加速、保持不动或向右加速。其目的是通过随机测试环境,收集汽车在不同情况下的行为数据。
• 应用动作:选择动作后,智能体将该选择应用于环境。例如,若选择的动作是“向右加速”,汽车便会向右移动。
观察结果:每当智能体执行一个动作时,环境会返回一个新的状态,其中包含汽车的新位置和速度,以及一个“奖励值”,该奖励值表示该动作在实现目标(爬山)方面的有用程度。
• 渲染环境:执行动作后,环境会被“渲染”(即可视化),以展示当前发生的情况。智能体可以看到汽车移动并尝试爬山。
• 短暂等待:为防止模拟运行过快(以便用户能跟上进度),代码会在各个步骤之间引入一个小的延迟。
• 检查回合是否结束:如果汽车到达山顶,或者由于其他原因回合结束,环境将被重置,并开始新的回合。
该循环持续预定数量的步骤(此处为1500步)。每一轮从汽车位于山谷开始,结束于汽车到达目标(爬上山)或步骤数用尽。一轮结束后,环境会重置,循环再次开始。
智能体通过随机行动探索“山地小车”环境。起初,智能体不知道如何到达目标,因此会随机执行动作。然而,这种随机探索至关重要,因为它使智能体能够收集数据,这些数据将用于后续改进其决策,最终应用更先进的强化学习算法,基于先前经验优化动作。
本质上,这一循环代表了智能体对环境进行迭代探索的行为,通过积累经验逐步改进其动作,这是开发能够有效解决“山地小车”问题的强化学习智能体的关键步骤。
五、结论
总而言之,
• 强化学习的核心在于累积奖励的最大化。
• 为了优化策略,我们有两种选择:基于策略的方法直接优化策略,以及基于价值的方法间接优化策略。
• 强化学习的关键术语包括智能体、状态、动作和奖励。
强化学习是人工智能领域中最引人入胜且强大的方法之一。其应用范围从视频游戏到机器人技术,再到复杂系统的优化,为解决自主学习和适应至关重要的问题提供了独特的机会。
在本指南中,我们介绍了关键概念、主要算法和基本技术,这些将帮助你迈出强化学习领域的第一步。强化学习是一个不断发展演变的领域,你的好奇心是探索新前沿的最佳伙伴。持续进行实验,检验你的知识,并永不停止学习。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)