【入门必备】深度学习中的「维度」的核心含义与用处
深度学习里的维度(Dimension,简称 dim),是描述数据核心载体张量(Tensor) 的核心指标,本质分为两层核心含义,所有用处都围绕这两层定义展开:
-
第一层:张量的「轴数 / 秩」,即常说的「几维张量」,代表张量有多少个独立的信息组织轴;
-
第二层:单轴的「维度大小 / 元素数量」,即常说的「特征维度 256」,代表某一个轴上能承载的元素 / 特征数量。
例如在COTR 论文中 EVT 生成的 OCC 特征shape=[32, 200, 200, 16],它是4 维张量(轴数 = 4),4 个维度的大小分别是 32(通道维度)、200(X 空间维度)、200(Y 空间维度)、16(Z 高度维度)。
一、从低维到高维:张量维度的基础知识
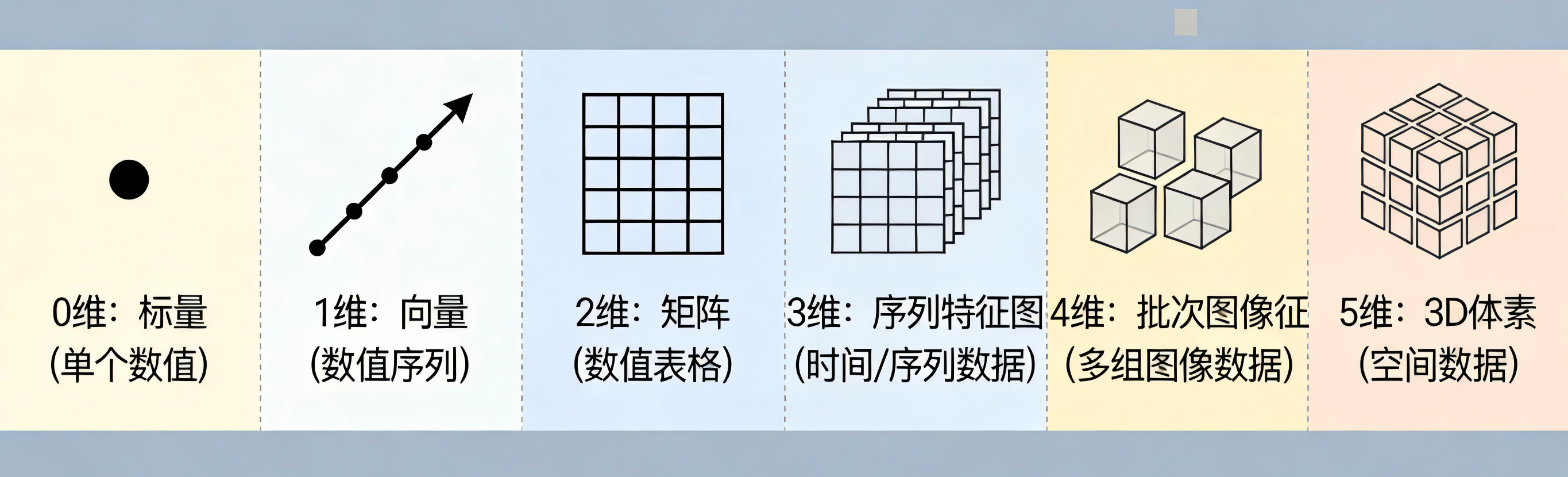
深度学习中所有数据都以张量存储,维度决定了张量的基础形态,从低维到高维的典型场景如下:
| 张量维度 | 别名 | 典型 shape | 核心含义与深度学习场景 |
|---|---|---|---|
| 0 维 | 标量 | 单个数字(如 loss 值、准确率) | 单值输出,用于记录训练指标、最终分类置信度 |
| 1 维 | 向量 | [D](如 [128]、[17]) | 单样本特征向量、分类任务的类别输出(17 分类对应 shape=[17]) |
| 2 维 | 矩阵 | [B, D](如 [32, 128]) | 批次化特征:32 个样本,每个样本 128 维特征,是全连接层的标准输入格式 |
| 3 维 | 序列 / 单张特征图 | [B, Seq_len, D](NLP)/ [C, H, W](单张图片) | NLP 中存储批次文本序列;CV 中存储单张 RGB 图片 / 特征图 |
| 4 维 | 批次图像特征 | [B, C, H, W](如 [8, 3, 256, 256]) | CV 最核心的输入格式:8 张 RGB 图片,是 CNN、2D Transformer 的标准输入 |
| 5 维 | 3D 体素 / 视频序列 | [B, C, X, Y, Z](如 COTR 的 OCC 特征)/ [B, C, T, H, W] | 3D 视觉中存储批次 3D 体素数据;视频任务中存储时序图像序列 |
二、不同场景下,维度的具体含义与专属用处
2.1 计算机视觉(CV)
| 维度名称 | 含义 | 核心用处 | COTR 中的对应设计 |
|---|---|---|---|
| 批次维度(B) | 一次前向传播的样本 / 帧数量 | 批次化训练,提升 GPU 利用率、稳定梯度更新,是深度学习并行训练的基础 | 训练时批次设为 8/16,同时处理多帧环视图像 |
| 通道维度(C) | 也叫特征维度,每个体素 / 像素的特征数量 | 存储颜色、纹理、边缘、语义、几何等核心特征,通道数越大,特征表达能力越强 | 下采样后把通道从 32 提升到 256,用通道维度的特征丰富度,弥补空间下采样的细节损失 |
| 空间维度(X/Y/Z/H/W) | 图像 / 3D 空间的分辨率,每个轴对应物理空间的一个方向 | 决定感知的精细度,空间维度越大,能捕捉的几何细节越丰富 | 原始 OCC 空间维度 200×200×16,下采样到 50×50×16 构建紧凑 OCC,平衡细节感知与计算量 |
2.2 自然语言处理(NLP)
| 维度名称 | 含义 | 核心用处 |
|---|---|---|
| 批次维度(B) | 一次处理的句子数量 | 同 CV,实现批次化并行训练 |
| 序列长度维度(Seq_len) | 句子的 token 数量 | 控制输入文本的长度,适配模型的上下文窗口 |
| 隐藏层维度(D) | 每个 token 的特征维度 | 存储 token 的语义、上下文信息,维度越高,语义表达能力越强(如 BERT-base 为 768 维) |
三、维度在深度学习中的核心作用
3.1 规范数据格式,适配模型的输入输出要求
维度是深度学习数据的「通用格式标准」,只有维度匹配,模型才能正确读取和处理数据。
比如:
-
CNN 要求输入 4 维张量
[B,C,H,W],3D 占用预测的 Transformer 要求输入 5 维体素张量[B,C,X,Y,Z]; -
17 分类的 3D 占用预测任务,输出维度必须是
[17, X, Y, Z],才能对应每个体素的 17 类语义概率。
3.2 承载信息,决定特征的表达能力
每个维度对应一类信息的编码:
通道维度承载语义特征,空间维度承载几何 / 位置特征,时序维度承载动态特征。
维度大小直接决定了信息承载上限:256 维特征比 64 维能存储更丰富的语义信息,200×200 的空间维度比 50×50 能捕捉更精细的几何细节,这也是 COTR 中高分辨率 OCC 能保留更多目标轮廓的核心原因。
3.3 平衡精度与效率,控制计算量和模型复杂度
张量的计算量和维度大小强相关:比如卷积计算量和通道数C、空间尺寸H/W的平方成正比。COTR 的核心优化就是通过维度调整实现效率提升:把 OCC 的 X/Y 空间维度从 200 降到 50,IVT 模块的计算量直接降到原来的 1/16,在几乎不损失精度的前提下,大幅降低了算力开销。
同时,维度也决定了模型参数量,维度越大,模型容量越强,但也越容易过拟合、推理速度越慢。
3.4 支撑深度学习的核心算子,实现特征变换
深度学习的核心操作(卷积、注意力、池化、全连接),本质都是对张量的不同维度做针对性操作:
-
卷积 / 池化:对空间维度做局部特征提取 / 降维;
-
自注意力:对序列 / 空间维度做全局特征交互;
-
全连接层:对特征维度做线性映射和语义变换;COTR 中的 3D 空间交叉注意力,核心就是对 OCC 特征的 X/Y/Z 空间维度做自适应采样和特征交互,实现稀疏区域的特征补全。
四、常见的维度操作与核心目的
| 操作类型 | 典型方法 | 核心目的 | COTR 中的对应设计 |
|---|---|---|---|
| 降维 | 池化、下采样、特征压缩 | 减少计算量、扩大感受野、避免维度灾难 | 把 200×200 的空间维度下采样到 50×50,降低 IVT 的计算开销 |
| 升维 | 上采样、通道扩充、unsqueeze | 恢复空间细节、补充特征信息、适配算子输入 | 把 50×50 的紧凑特征上采样回 200×200,恢复几何细节用于最终预测 |
| 维度变换 | transpose、reshape | 调整轴顺序,适配不同算子的输入格式 | 调整 OCC 特征的轴顺序,适配 3D 注意力和卷积的输入要求 |
| 维度拼接 | concat | 融合多分支 / 多尺度特征,补充信息 | U-Net 架构中,把下采样的多尺度特征和上采样特征拼接,恢复下采样丢失的细节 |
五、关键误区与注意点
-
不是维度越高越好:维度过高会引发维度灾难—— 高维空间中数据分布会极度稀疏,模型难以学习有效特征,同时会导致计算量、参数量爆炸,极易过拟合;
-
区分「轴数」和「维度大小」:常说的「128 维特征向量」,是1 维张量(轴数 = 1),只是这个轴的大小是 128,不要混淆「几维张量」和「单轴的维度大小」;
-
维度设计必须贴合任务场景:比如自动驾驶近场危险区域需要更大的空间维度保证细节,远场背景可以压缩维度降低无效计算。
六、常见维度报错原因
在深度学习中,不同维度的张量交互计算时发生报错的核心原因是张量的维度不满足算子的计算规则——每个算子(卷积、注意力、矩阵乘法、拼接等)都有明确的匹配要求,一旦触发就会报错维度不兼容错误❌️
6.1 最常见的报错原因:维度形状不匹配
核心逻辑
算子执行时需要张量在指定轴上的尺寸完全一致,比如矩阵乘法要求 A 的列数 = B 的行数,拼接要求除拼接轴外其他轴尺寸一致。
典型场景(COTR 相关)
-
3D 注意力计算报错:IVT 模块中掩码查询
Qm的特征维度是[N_q, 256],而紧凑 OCC 特征Oc的通道维度误设为[50,50,16,128],3D-SCA 算子要求两者通道维度一致,触发size mismatch错误; -
U-Net 特征拼接报错:下采样的紧凑 OCC 特征是
[B,256,50,50,16],上采样分支特征是[B,256,100,100,16],直接 concat 拼接时,X/Y 空间维度(50 vs 100)不匹配,报错dimension 3 mismatch; -
矩阵乘法报错:全连接层输入是
[B, 200*200*16](恢复的 OCC 特征),但权重维度设为[200*200*8, 17],因输入最后一维(64000)≠权重第一维(32000),触发mat1 dim 1 must match mat2 dim 0。
解决思路
-
先通过
print(tensor.shape)确认所有交互张量的维度; -
用
reshape/transpose调整轴顺序,或用nn.Linear/1x1x1卷积统一通道维度; -
拼接前用
interpolate(上 / 下采样)对齐空间维度(如 COTR 中 U-Net 通过上采样把 50×50 恢复到 200×200)。
6.2 易忽略的报错原因:轴(维度)顺序不匹配
核心逻辑
深度学习算子对「轴的语义」有固定要求(比如 CV 中默认[B,C,H,W],而非[B,H,W,C]),轴顺序错误会导致算子读取维度的语义错位,看似尺寸一致仍报错。
典型场景(COTR 相关)
-
3D 卷积计算报错:COTR 的 OCC 特征默认是
[B,C,X,Y,Z],但误处理为[B,X,Y,Z,C],输入 3D 卷积层(要求输入为[B,C,D1,D2,D3])时,会因通道轴(C)位置错误,触发expected 5D tensor with size [B,C,D1,D2,D3], got [B,D1,D2,D3,C]; -
注意力维度展平报错:把
[B,C,X,Y,Z]的 OCC 特征展平时,误按[B,X,Y,Z,C]展平为[B, X*Y*Z*C],后续和掩码查询交互时,因特征维度语义错位导致尺寸不匹配。
解决思路
-
牢记不同任务的标准轴顺序:CV 图像
[B,C,H,W]、3D 体素[B,C,X,Y,Z]、NLP 序列[B,Seq_len,D]; -
用
transpose/permute调整轴顺序(如occ_feat.permute(0,4,1,2,3)把[B,X,Y,Z,C]转为[B,C,X,Y,Z])。
6.3 隐性报错原因:批次维度 / 广播机制不兼容
核心逻辑
-
批次维度缺失:部分算子要求必须有批次轴(B),单样本张量(如
[C,X,Y,Z])直接输入批次化训练的模型,会因维度数不足报错; -
广播机制失效:PyTorch/TensorFlow 的广播规则要求「从后往前匹配维度,尺寸要么相等,要么其中一个为 1」,不满足则无法广播,触发维度错误。
典型场景(COTR 相关)
-
单样本推理报错:训练时用
[8,C,X,Y,Z](批次 8),推理时直接输入单帧 OCC 特征[C,X,Y,Z],模型因缺少批次轴,报错expected 5D tensor, got 4D tensor; -
损失计算广播报错:语义分组解码器的掩码损失
mask_loss是[B,N_q,X,Y,Z],类别损失cls_loss是[B,N_q],若误把cls_loss转为[B,X,Y,Z,N_q],从后往前维度不匹配(Z vs N_q),无法广播,触发could not broadcast input array from shape (B,N_q) into shape (B,X,Y,Z,N_q)。
解决思路
-
单样本推理时,用
unsqueeze(0)增加批次轴(如occ_feat.unsqueeze(0)把[C,X,Y,Z]转为[1,C,X,Y,Z]); -
广播前用
reshape/unsqueeze对齐维度(如把[B,N_q]的cls_loss转为[B,N_q,1,1,1],即可和[B,N_q,X,Y,Z]的mask_loss广播计算)。
6.4 进阶场景报错:维度数(秩)不匹配
核心逻辑
算子对张量的「维度数(轴数)」有固定要求,比如 2D 卷积要求 4 维张量([B,C,H,W]),3D 卷积要求 5 维张量([B,C,X,Y,Z]),维度数不符直接报错。
典型场景(COTR 相关)
-
把 3D 体素当 2D 特征输入:把 COTR 的 5 维 OCC 特征
[B,C,X,Y,Z]直接输入 2D 卷积层(要求 4 维),报错expected 4D input for 4D weight, got 5D input; -
展平过度导致维度数不足:把
[B,C,X,Y,Z]展平为[B, C*X*Y*Z](2 维),输入 3D 注意力模块(要求 5 维),触发维度数错误。
解决思路
-
核对算子要求的维度数:2D 卷积→4 维、3D 卷积→5 维、全连接层→2 维(
[B,D]); -
维度数不足时用
reshape恢复(如把展平的 2 维特征[B,D]恢复为[B,C,X,Y,Z],需确保D=C*X*Y*Z)。
6.5 总结
维度交互计算报错的核心可归纳为 3 点:
-
尺寸错:关键轴的数值大小不匹配(如通道数、空间分辨率);
-
顺序错:轴的语义顺序不符合算子要求(如 C 轴位置错误);
-
数量错:维度数(轴数)或批次轴缺失,不满足算子基础要求。
排查时先打印所有交互张量的shape,确认「维度数→轴顺序→关键轴尺寸」三步,90% 的维度报错都能快速定位;对于 COTR 这类 3D 感知模型,重点核对[B,C,X,Y,Z]的轴顺序和通道 / 空间维度的一致性即可。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)