基于深度学习的人脸检测与识别系统
核心逻辑是:先处理并提取 “已知人脸” 的特征向量,再对 “测试图片” 进行人脸检测,逐一提取测试图片中每个人脸的特征向量并与已知人脸比对,最终在测试图片上绘制识别结果(匹配 / 不匹配、距离值),同时显示和保存结果图片,是 FaceNet 人脸识别流程的完整落地实现。,专门适配 FaceNet 人脸识别模型的输入要求,核心实现三大功能:图片格式标准化处理、人脸图像预处理(缩放 / 归一化)、人脸
1.技术栈
Python, OpenCV, MTCNN, FaceNet-PyTorch, PyTorch
2.代码展示
1.导库
import cv2
import numpy as np
from mtcnn import MTCNN
from tensorflow import keras
from PIL import Image
2.加载模型
1.代码
#1.人脸检测器(MTCNN:专门找脸在哪里)
#作用:输入一张图->输出所有脸的框坐标
detector = MTCNN()
#2.人脸识别模型(FaceNet:把人脸变成128维特征向量)
#作用:把人脸变成一串数字,两个人脸的数字越相近,就是同一个人
#这里我们直接用训练好的模型结构
def create_facenet_model():
#这是简化版FaceNet模型结构
#整体逻辑:
#输入(160×160×3的人脸图)→ 卷积+池化(提取人脸特征)→ 展平(变成一维)→
#归一化(生成可对比的特征向量)→ 输出(128维特征)
model = keras.models.Sequential([
#第一层卷积
#Conv2D:卷积层,人脸识别的核心特征提取模块,专门从图片里抠关键信息(比如人脸的眼睛、鼻子、轮廓)
#32:这一层会生成 32 个「特征图」(可以理解为 32 个不同的 “滤镜”,每个滤镜抓一种人脸特征)
#(3,3):卷积核的大小(用 3×3 的小窗口在图片上滑动找特征);
#activation='relu':激活函数,让网络能学习复杂的人脸特征(非直线关系),没有它网络只能学简单规律;
#input_shape=(160,160,3):规定输入图片的尺寸(160 宽 ×160 高 ×3 通道,RGB 彩色图)。
keras.layers.Conv2D(32,(3,3),activation = 'relu',input_shape = (160,160,3)),
#第一层池化
#MaxPooling2D:最大池化层,核心作用是 “降维”;
#(2,2):把特征图的尺寸缩小一半(比如 160×160→80×80),既减少计算量,又能保留关键特征(比如只留每个 2×2 区域里最亮的像素);
#类比:把一张高清图缩小成缩略图,虽然像素少了,但你还能认出是同一个人。
keras.layers.MaxPooling2D((2,2)),
#第二层卷积:提取更细的特征,经过这一层后,特征图尺寸还是80*80(池化前)
keras.layers.Conv2D(64,(3,3),activation = 'relu'),
#第二层池化,继续降维,再次把特征图缩小一半(80×80→40×40),特征图数量还是 64。
keras.layers.MaxPooling2D((2,2)),
#第三层卷积,提取高阶特征,池化前尺寸还是40*40
keras.layers.Conv2D(128,(3,3),activation = 'relu'),
#第三层池化,最终降维特征图尺寸缩小到 20×20(40×40→20×20),特征图数量 128;此时特征图的总像素:20×20×128 = 51200 个。
keras.layers.MaxPooling2D((2,2)),
#展平层,将2D转化成1D
#Flatten:展平层,把 20×20×128 的三维特征图,变成一维数组;计算:20×20×128 = 51200 个元素的一维向量;
keras.layers.Flatten(),
#输出可对比的128维特征向量
keras.layers.Dense(128),
# 把51200维的向量压缩到128维(核心!)
#Lambda:自定义层,用来执行 Keras 内置层做不到的操作;
#keras.backend.l2_normalize:L2 归一化,把特征向量的 “长度” 缩放到 1(不改变方向,只调整大小);
#axis=1:对每一行(每个样本)做归一化。
#为什么要做这个?
#人脸识别的核心是 “对比特征”:比如你的人脸特征向量是[0.1,0.2,...],别人的是[0.8,0.3,...],
#归一化后,两个向量的「欧式距离」就能直接反映相似度(距离越小,越像同一个人)。
keras.layers.Lambda(lambda x: keras.backend.l2_normalize(x, axis=1))
])
return model
facenet = create_facenet_model()2.这几层代码的核心作用
1.用「卷积 + 池化」从人脸图里层层提取关键特征(从基础轮廓到精细五官);
2.用「展平 + 全连接」把二维特征转成 128 维一维向量;
3.用「L2 归一化」把向量标准化,让不同人脸的特征能直接对比相似度。
3.工具函数
1.代码
def preprocess_face(face_img):
"""
预处理人脸:缩放到160*160,归一化,符合FaceNet输入要求
输入:从图片截出来的人脸区域
输出:可以直接送进模型的人脸
参数:
face_img (np.ndarray): 从原始图片中裁剪出的人脸区域(RGB格式,shape为(H,W,3))
返回:
np.ndarray: 预处理后的人脸数据,shape为(1,160,160,3),可直接送入FaceNet模型
"""
#1.缩放到FaceNet固定输入尺寸160*160(模型训练时使用的标准尺寸)
face = cv2.resize(face_img,(160,160))
#2.归一化到0-1:将像素值从0-255(uint8)转换为0.0-1.0(float32)
# 原因:FaceNet模型训练时使用了归一化输入,需保持数据分布一致
face = face.astype('float32') / 255.0
# 3. 增加批次维度:模型输入要求为(batch_size, height, width, channels)
# 单张人脸时batch_size=1,因此从(160,160,3)变为(1,160,160,3)
face = np.expand_dims(face,axis = 0)
return face
def get_embedding(face_img):
"""
提取人脸的128维特征向量(Embedding):人脸识别的核心步骤
FaceNet模型的核心输出是128维向量,该向量具有“同人脸距离近、不同人脸距离远”的特性
参数:
face_img (np.ndarray): 从原始图片中裁剪出的人脸区域(RGB格式,shape为(H,W,3))
返回:
np.ndarray: 128维人脸特征向量,shape为(128,),用于后续相似度比对
"""
# 第一步:将原始人脸区域预处理为模型可输入的格式
face = preprocess_face(face_img)
# 第二步:使用FaceNet模型预测,得到特征向量
# verbose=0:关闭预测过程中的进度输出,避免冗余信息
embedding = facenet.predict(face,verbose = 0)
# 第三步:去除批次维度(预测结果shape为(1,128)),返回纯128维向量
return embedding[0]
def compare_embeddings(emb1,emb2,threshold = 0.3):
"""
比对两个人脸特征向量的相似度,判断是否为同一个人
核心逻辑:计算特征向量间的欧氏距离,距离越小表示人脸越相似
参数:
emb1 (np.ndarray): 第一个人脸的128维特征向量
emb2 (np.ndarray): 第二个人脸的128维特征向量
threshold (float): 相似度阈值(默认0.25),距离小于该值则判定为同一个人
(阈值可根据实际场景调整:值越小判断越严格,误判率越低)
返回:
tuple: (bool, float)
- bool:True=同一个人,False=不同人
- float:两个特征向量的欧氏距离值
"""
# 计算欧氏距离:衡量两个128维向量的空间距离
distance = np.linalg.norm(emb1 - emb2)
#距离<阈值 ->同一个人
return distance < threshold,distance
def process_image_path(img_path):
"""
读取图片并标准化格式:解决不同图片通道数、色彩空间不一致的问题
核心目标:将任意格式的图片转换为FaceNet流程可用的RGB格式3通道图片
参数:
img_path (str): 图片文件的路径(绝对路径/相对路径)
返回:
tuple:
- np.ndarray/None:原始BGR格式图片(用于后续人脸检测),读取失败则为None
- str/np.ndarray:读取失败时返回错误信息,成功则返回RGB格式3通道图片(uint8)
"""
#1.读取图片:(IMREAD_UNCHANGED:保留原始通道数,不自动转换)
img = cv2.imread(img_path,cv2.IMREAD_UNCHANGED)
# 检查图片是否读取成功(路径错误/文件损坏/格式不支持都会导致img为None)
if img is None:
return None, f"路径错误或文件不存在:{img_path}"
#2.处理4通道(RGBA:RGB+透明通道)->3通道(RGB)
# 简单方案:直接舍弃Alpha通道,仅保留RGB三通道
if img.shape[-1] == 4:
#去除Alpha通道,或混合RGB,简单方案,直接取前三通道
img = img[...,:3]
#3.处理单通道(灰度图)->3通道(RGB)FaceNet要求输入为3通道)
# COLOR_GRAY2RGB:将单通道灰度值复制到R/G/B三个通道
elif len(img.shape) == 2:
img = cv2.cvtColor(img,cv2.COLOR_GRAY2RGB)
#4.转换维RGB格式(Opencv默认读取BGR格式) + 标准化unit8
img_rgb = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img_rgb = img_rgb.astype(np.uint8)
# 成功时返回:原始BGR图片(用于人脸检测裁剪)+ 标准化RGB图片(用于后续预处理)
return img, img_rgb2.代码核心功能
1.这段代码是一套完整的人脸预处理与特征比对工具函数,专门适配 FaceNet 人脸识别模型的输入要求,核心实现三大功能:图片格式标准化处理、人脸图像预处理(缩放 / 归一化)、人脸特征向量提取与相似度比对,是 FaceNet 人脸识别流程中从原始图片到最终身份判断的核心环节。
2.格式标准化:process_image_path 解决了图片通道数(1/3/4 通道)、色彩空间(BGR/RGB)不一致的问题,是后续处理的基础;
3.模型适配:preprocess_face 严格匹配 FaceNet 的输入要求(160*160 尺寸、0-1 归一化、4 维张量),确保模型能正常推理;
4.核心逻辑:get_embedding 提取 128 维特征向量,compare_embeddings 通过欧氏距离比对特征,是人脸识别的核心(距离越小,人脸相似度越高)。
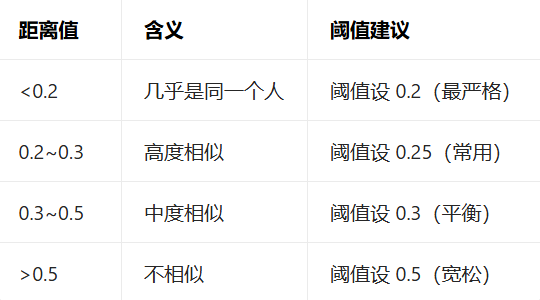
5.阈值 0.25 为经验值,实际使用时需根据数据集调整(如场景要求严格则降低阈值,要求宽松则提高)。
6.看距离数调整阈值
4.主函数
1.代码
"""
注:需提前初始化依赖组件(根据实际使用的检测器调整)
示例1:使用MTCNN人脸检测器(推荐)
from mtcnn import MTCNN
detector = MTCNN()
示例2:使用OpenCV Haar级联检测器(轻量但精度低)
detector = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
"""
def face_detect_and_recognize(test_img_path, known_img_path):
"""
人脸检测与识别主函数:对比已知人脸和测试图片中的人脸,输出识别结果
核心流程:已知人脸处理→测试图片人脸检测→逐个人脸特征比对→绘制/保存/显示结果
参数:
test_img_path (str): 待检测的测试图片路径(可能包含多张人脸)
known_img_path (str): 已知身份的人脸图片路径(建议仅含一张清晰正脸)
返回:
None: 无返回值,直接显示结果窗口并保存结果图片到当前目录
"""
# =========================处理已知人脸=======================
# 1. 读取并标准化已知人脸图片(解决通道/色彩空间问题)
known_img, known_rgb = process_image_path(known_img_path)
#检查图片读取是否失败
if known_img is None:
print(f"❌ {known_rgb}")
return
# 2.检测已知人脸(detector需提前初始化,如MTCNN)
known_faces = detector.detect_faces(known_rgb)
#检查是否检测到人脸
if not known_faces:
print("❌ 已知图片中未检测到人脸,请更换清晰正脸照片")
return
#3. 截取已知人脸区域(取第一张脸)
# MTCNN检测结果中,'box'字段为[x1, y1, width, height]
x1, y1, w1, h1 = known_faces[0]['box']
# 边界校验:避免坐标为负数导致裁剪越界(如人脸靠近图片边缘时)
y1, y2 = max(0, y1), max(0, y1 + h1) # y轴起始/结束坐标
x1, x2 = max(0, x1), max(0, x1 + w1) # x轴起始/结束坐标
# 从RGB格式图片中裁剪出人脸区域(用于后续特征提取)
known_face = known_rgb[y1:y2, x1:x2]
# 4. 提取已知人脸的128维特征向量
known_emb = get_embedding(known_face)
# =====================处理测试图片===================
#1.读取并标准化测试图片
test_img, test_rgb = process_image_path(test_img_path)
if test_img is None:
print(f"❌ {test_rgb}")
return
# 2.检测测试图片中的人脸
test_faces = detector.detect_faces(test_rgb)
if not test_faces:
print("❌ 测试图片中未检测到人脸")
return
# =============================遍历检测到的人脸并对比====================
for face in test_faces:
#1.获取当前人脸的边界框坐标
x, y, w, h = face['box']
# 边界校验,防止坐标越界
y_min, y_max = max(0, y), max(0, y + h)
x_min, x_max = max(0, x), max(0, x + w)
#2.裁剪当前人脸区域
current_face = test_rgb[y_min:y_max, x_min:x_max]
current_emb = get_embedding(current_face)
#3.提取当前人脸的特征向量
# 4.与已知人脸特征对比,判断是否为同一个人
is_same, dist = compare_embeddings(known_emb, current_emb)
# 5.绘制结果(注意:test_img是BGR格式,适配OpenCV绘制)
#匹配则画绿色框,不匹配画红色框
color = (0, 255, 0) if is_same else (0, 0, 255)
# 标签:显示匹配状态和欧氏距离(保留2位小数)
label = f"Match ({dist:.2f})" if is_same else f"Unmatch ({dist:.2f})"
# 绘制人脸边界框:参数(图片, 左上角, 右下角, 颜色, 线条宽度)
cv2.rectangle(test_img, (x_min, y_min), (x_max, y_max), color, 2)
# 绘制文本标签:参数(图片, 文本位置, 字体, 字体大小, 颜色, 线条宽度)
cv2.putText(test_img, label, (x_min, y_min - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 2)
#============ 显示与保存结果===============
# 显示结果窗口(窗口标题:Face Recognition Result)
cv2.imshow("Face Recognition Result", test_img)
# 保存结果图片到当前目录,文件名为result.jpg
cv2.imwrite("result.jpg", test_img) # 自动保存结果到当前目录
# 等待用户按下任意键后关闭窗口(0表示无限等待)
cv2.waitKey(0)
# 销毁所有OpenCV创建的窗口,释放资源
cv2.destroyAllWindows()
2.核心功能
1.这段代码是完整的人脸检测 + 人脸识别主函数,核心逻辑是:先处理并提取 “已知人脸” 的特征向量,再对 “测试图片” 进行人脸检测,逐一提取测试图片中每个人脸的特征向量并与已知人脸比对,最终在测试图片上绘制识别结果(匹配 / 不匹配、距离值),同时显示和保存结果图片,是 FaceNet 人脸识别流程的完整落地实现。
2.代码中detector.detect_faces()是 MTCNN 检测器的调用方式,返回结果为包含box字段的字典列表;若使用 OpenCV Haar 级联检测器,需修改检测逻辑(返回值为坐标数组),示例:
# Haar检测器适配代码(替换原检测逻辑)
gray = cv2.cvtColor(known_rgb, cv2.COLOR_RGB2GRAY)
known_faces = detector.detectMultiScale(gray, 1.1, 4) # 返回(x,y,w,h)数组
if len(known_faces) == 0:
print("❌ 未检测到人脸")
return
x1, y1, w1, h1 = known_faces[0]3.坐标体系说明:
- OpenCV 图片坐标以左上角为原点,x 轴向右,y 轴向下,因此裁剪区域为
[y_min:y_max, x_min:x_max](先 y 后 x); - 边界校验
max(0, ...)是为了避免人脸靠近图片边缘时,检测出的坐标为负数导致裁剪失败
4.总结
- 核心流程:已知人脸(读取→检测→裁剪→提特征)→ 测试图片(读取→检测→逐脸提特征→比对)→ 绘制结果→ 显示 / 保存;
- 关键处理:边界校验防止坐标越界、区分 RGB/BGR 格式适配不同环节(特征提取用 RGB,OpenCV 绘制用 BGR);
- 交互逻辑:识别结果可视化(绿框 = 匹配、红框 = 不匹配),同时保存结果图片,等待用户操作后关闭窗口。
5.运行
if __name__ == "__main__":
#已知人脸(你的照片)
KNOWN_FACE = r"D:\AI_study\py_code\face_test\known_face.jpg"
# 要检测的图片(合照)
TEST_IMAGE = r"D:\AI_study\py_code\face_test\test_face.jpg"
# 开始检测 + 识别
face_detect_and_recognize(TEST_IMAGE, KNOWN_FACE)3.结果展示
已知人脸:

测试人脸:

识别效果还不错,但是距离也挺相似,后续将会优化算法再进行更精准的人脸识别!
敬请关注下篇!!!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)