动手学深度学习(李沐)笔记:Softmax 回归(多分类的线性模型)

线性回归解决的是回归(输出一个连续值)。
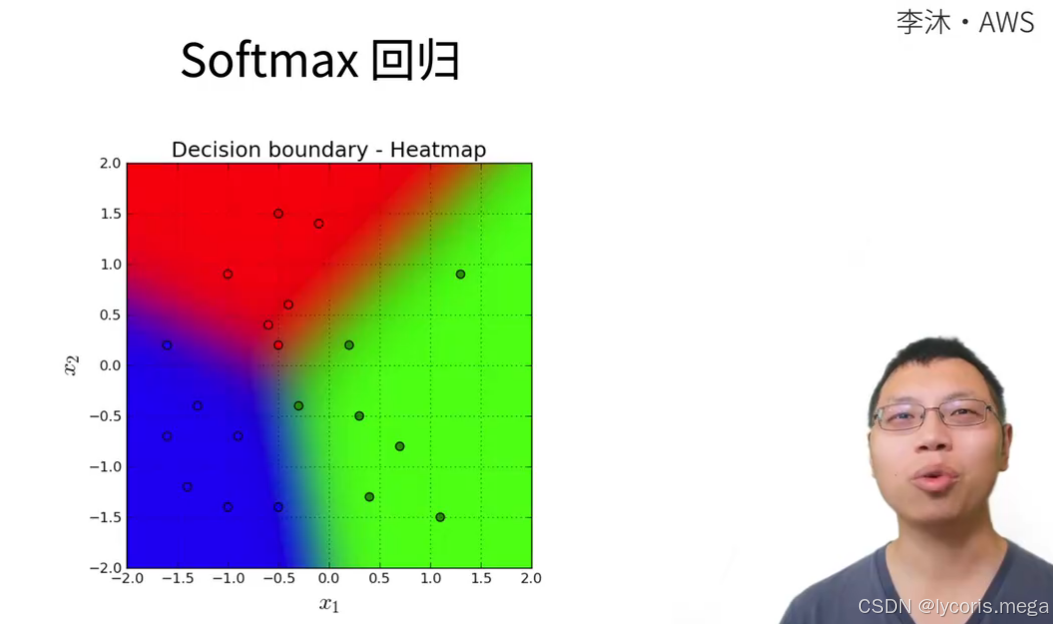
Softmax 回归解决的是多分类(输出属于每个类别的概率),可以理解为“分类版线性回归”:
-
仍然是线性模型:(o = XW + b)
-
但输出不直接当结果,而是先变成概率:

-
损失函数换成:交叉熵(cross-entropy)
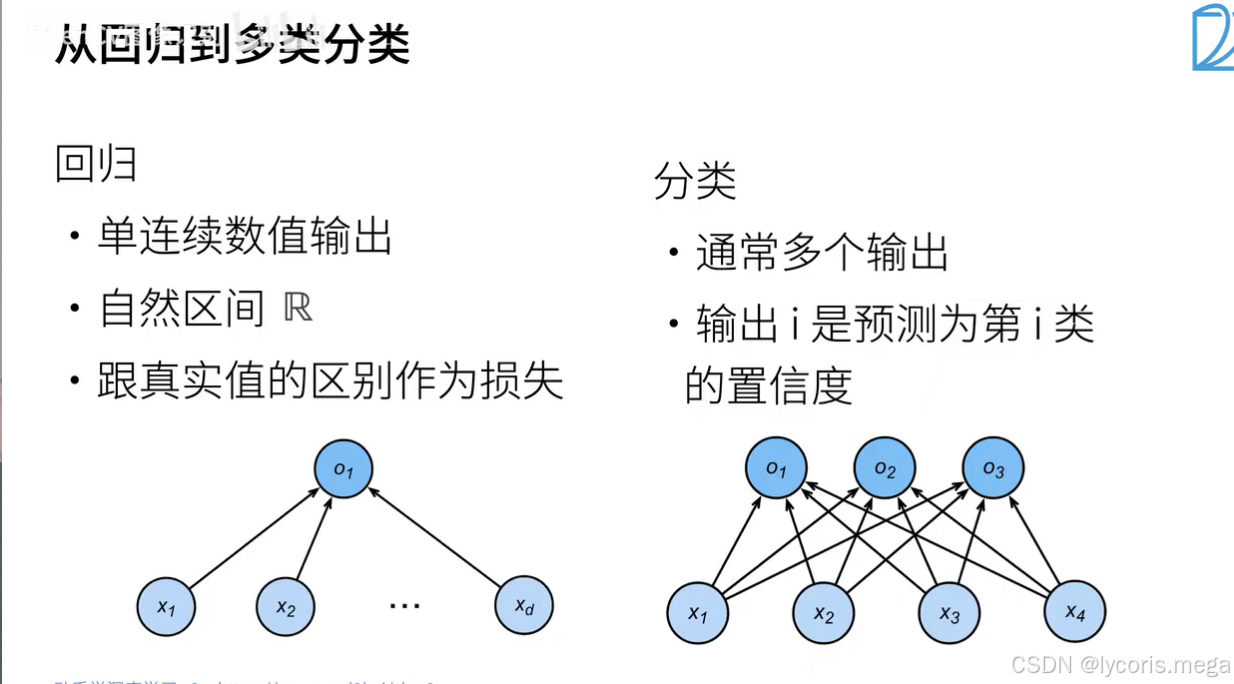
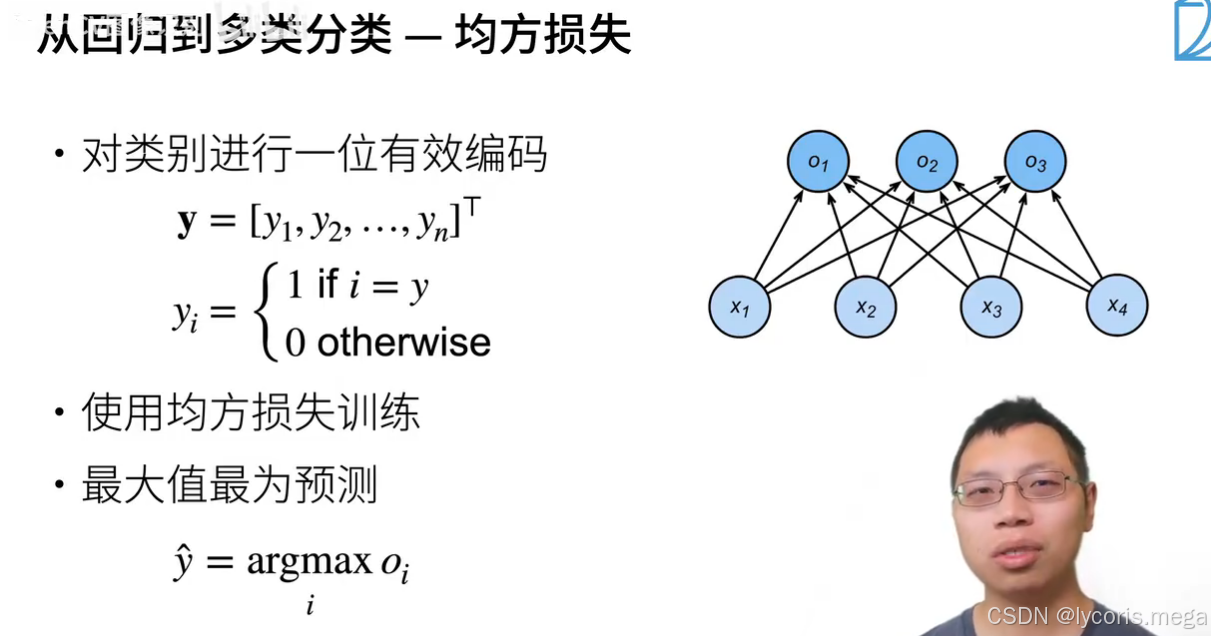
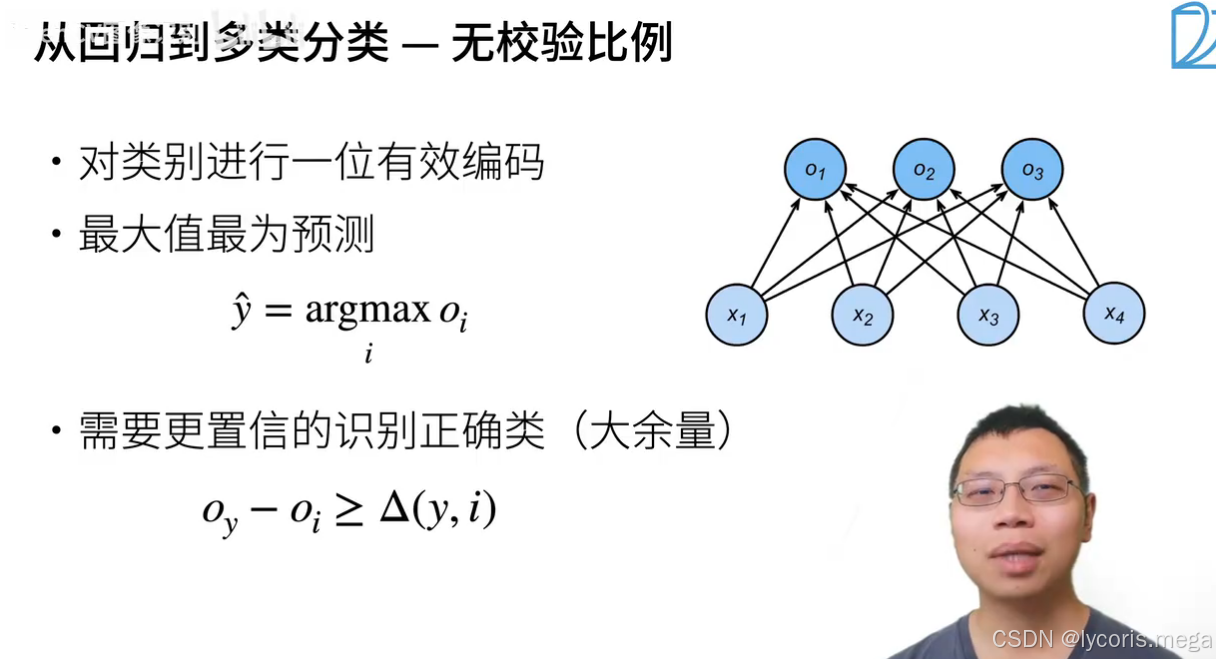
1. 从线性输出到概率:Softmax
对一个样本,模型先输出 K 维 logits(未归一化分数):
性质:
-
每个分量 (\in (0,1))
-
总和为 1(可解释成概率)
数值稳定性(非常重要)

2. 模型形式:多分类线性层

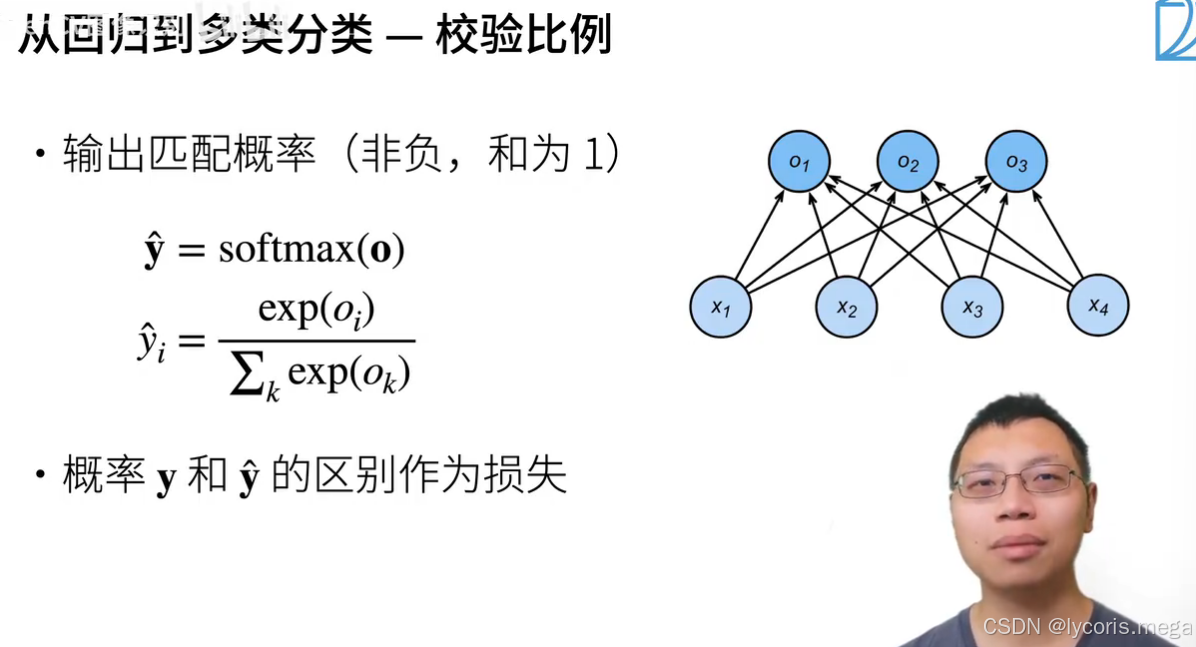
3. 损失函数:交叉熵(分类的“平方损失”替代品)


4. 从零实现(核心逻辑看透版)
下面代码演示:softmax + 交叉熵 + 训练循环(不依赖 nn.CrossEntropyLoss,更“李沐从零”)。
4.1 准备一个小型多分类数据(合成)
import torch
torch.manual_seed(0)
# 造一个三类问题:每类一个簇
n_per_class = 200
K = 3
d = 2
X0 = torch.randn(n_per_class, d) + torch.tensor([2.0, 2.0])
X1 = torch.randn(n_per_class, d) + torch.tensor([-2.0, -2.0])
X2 = torch.randn(n_per_class, d) + torch.tensor([2.0, -2.0])
X = torch.cat([X0, X1, X2], dim=0) # (600,2)
y = torch.cat([
torch.zeros(n_per_class, dtype=torch.long),
torch.ones(n_per_class, dtype=torch.long),
torch.full((n_per_class,), 2, dtype=torch.long)
], dim=0) # (600,)
4.2 softmax(带稳定)
def softmax(X):
X_shift = X - X.max(dim=1, keepdim=True).values
exp = torch.exp(X_shift)
return exp / exp.sum(dim=1, keepdim=True)
4.3 交叉熵(用“索引取正确类概率”实现)
def cross_entropy(y_hat, y):
# y_hat: (batch, K), y: (batch,)
return -torch.log(y_hat[torch.arange(y_hat.shape[0]), y])
4.4 模型 + 参数
W = torch.normal(0, 0.01, size=(d, K), requires_grad=True)
b = torch.zeros(K, requires_grad=True)
def net(X):
return X @ W + b
4.5 训练(手写 SGD)
def sgd(params, lr, batch_size):
with torch.no_grad():
for p in params:
p -= lr * p.grad / batch_size
p.grad.zero_()
batch_size = 64
lr = 0.5
epochs = 20
def data_iter(batch_size, X, y):
idx = torch.randperm(X.shape[0])
for i in range(0, X.shape[0], batch_size):
j = idx[i:i+batch_size]
yield X[j], y[j]
def accuracy(logits, y):
pred = logits.argmax(dim=1)
return (pred == y).float().mean().item()
for epoch in range(epochs):
for Xb, yb in data_iter(batch_size, X, y):
logits = net(Xb)
y_hat = softmax(logits)
l = cross_entropy(y_hat, yb).mean()
l.backward()
sgd([W, b], lr, Xb.shape[0])
with torch.no_grad():
train_acc = accuracy(net(X), y)
train_loss = cross_entropy(softmax(net(X)), y).mean().item()
print(f"epoch {epoch+1}, loss {train_loss:.4f}, acc {train_acc:.4f}")
你会观察到:loss 下降、acc 上升,说明“多分类线性模型”学会了分界面。
5. 简洁实现(工程默认写法)
工程上你几乎总是用:
-
nn.Linear(d, K)输出 logits -
nn.CrossEntropyLoss()直接吃 logits 和整数标签
注意:CrossEntropyLoss 的输入是 logits,不要先 softmax!
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
dataset = TensorDataset(X, y)
loader = DataLoader(dataset, batch_size=64, shuffle=True)
net = nn.Sequential(nn.Linear(d, K))
loss_fn = nn.CrossEntropyLoss()
opt = torch.optim.SGD(net.parameters(), lr=0.5)
for epoch in range(20):
for Xb, yb in loader:
logits = net(Xb) # (batch,K)
loss = loss_fn(logits, yb) # yb 是 long 的类别索引
opt.zero_grad()
loss.backward()
opt.step()
with torch.no_grad():
acc = (net(X).argmax(dim=1) == y).float().mean().item()
print(f"epoch {epoch+1}, acc {acc:.4f}")
6. 本节最常见坑(强烈建议你博客里单独标红)
-
把 softmax 后的概率喂给 CrossEntropyLoss(错)
✅ 正确:CrossEntropyLoss(logits, y)
因为它内部做了log_softmax,你自己 softmax 会让数值更不稳定。 -
标签 y 的 dtype 不对
CrossEntropyLoss需要y是torch.long且形状(batch,),不是 one-hot。 -
维度理解错
logits 必须是(batch, K);argmax(dim=1)才是取类别。 -
学习率太大/太小
SGD 对 lr 更敏感;Adam 作为 baseline 更省心。
7. 小结:Softmax 回归学到什么程度算“过关”?
-
你能写出:
logits = X @ W + b -
你理解:softmax 把 logits 变成概率
-
你会用:
CrossEntropyLoss(logits, y)(记住别手动 softmax) -
你能用
argmax做预测,用 accuracy 验证训练有效


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)