【浅显易懂理解强化学习】(五):Actor-Critic与A3C,多线程的完全胜利
本期我们介绍了Actor-Critic与 A3C,AC → 改进 Policy Gradient,稳定策略训练,A3C → 多线程 + Advantage + n-step 回报 → 更快、更稳定训练
·
前言
- 本系列讲究浅显易懂,所以尽量讲的简单并减少数学公式的解释加强实际运用。
- 上一期我们提到了
Policy-based(基于策略)的代表算法,它直接学习“应该采取什么动作的概率”,相比Value-based方法更加灵活,但也存在 训练不稳定、方差较大 的问题。 - 那么本期要介绍的
Actor-Critic,就兼顾了二者的优点,既能保持 Policy-based 的灵活性,又能利用 Value-based 的稳定性 。
1 Actor-Critic
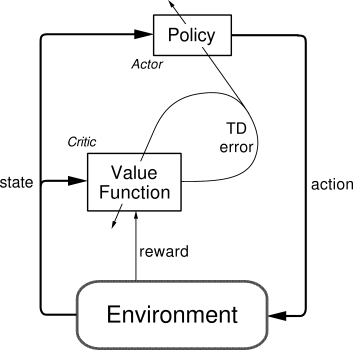
1-1 什么是Actor-Critic
- Actor-Critic 是一种 同时学习策略函数和价值函数的强化学习框架。
- 说人话我们从这个算法的名字出发:
- Actor(演员):负责决定动作(策略)
- Critic(评论员):负责评价这个动作好不好(价值)
- 两者互相配合,让强化学习训练得更稳定、更高效。
1-2 为什么需要Actor-Critic
- 我们在上一节的3-6中提到过
Policy Gradients的局限性:由于策略更新依赖采样到的回报,而回报本身具有随机性,这会导致一个明显的问题也就是:- 训练方差(variance)很大。
- 上一期:【浅显易懂理解强化学习】(四):Policy Gradients玩转策略采样-CSDN博客
- 说白了就是同样一个动作,
- 有时候奖励高,有时候奖励低,强依赖于当前奖励而忽视了实际的长期奖励
- 导致策略更新方向经常摇摆不定,陷入局部最优甚至无法收敛。
- 因此在
Actor-Critic中我们不直接用reward来更新策略,而是先 估计这个动作到底好不好。 - 这样策略更新就变成:
- 好于预期 → 增加概率
- 差于预期 → 减少概率
1-3 Actor(策略函数)
- Actor 表示策略: π θ ( a ∣ s ) π_θ(a∣s) πθ(a∣s)
- 其中:
- s s s:状态
- a a a:动作
- θ \theta θ:策略网络参数
- 而
Actor的作用是:- 根据状态
s生成动作概率分布。(这一点和上一节我们学习到的Policy-based的Policy Gradients思路一致)
- 根据状态
1-4 Critic(价值函数)
- Critic 用来估计价值函数,例如: V w ( s ) V_w(s) Vw(s)
- 其中:
- w w w 是价值网络参数
- Critic 的作用是:
- 评估当前状态(或状态-动作)的长期回报期望。(这一点和之前我们学习到的
Value-based的DQN思路一致)
- 评估当前状态(或状态-动作)的长期回报期望。(这一点和之前我们学习到的
1-5 TD Error(时间差分误差)
Actor-Critic的本质仍是误差修正模型,因此时间差分误差同样是Actor-Critic的关键: δ = r + γ V ( s ′ ) − V ( s ) δ = r + γV(s') − V(s) δ=r+γV(s′)−V(s)- 含义是:
- δ δ δ=实际奖励 + 下一状态价值 − 当前状态价值
- 当:
- δ δ δ > 0 → 动作比预期好
- δ δ δ< 0 → 动作比预期差
- 这个误差会同时用于:
- 更新 Critic(让价值估计更准确)
- 更新 Actor(调整策略)
- 注意:(更新见1-6)
- Actor用δ乘策略梯度更新
- 而Critic直接用δ更新价值函数。
1-6 Actor-Critic 如何训练
- 整个训练流程其实很简单,结合了
Policy-based和Value-based的优点
- Actor 根据当前策略 π ( a ∣ s ) \pi(a|s) π(a∣s)选择一个动作。 s t a t e → A c t o r → a c t i o n state → Actor → action state→Actor→action
- 执行动作后环境返回
reward和next_state - Critic 计算 TD error δ = r + γ V ( s ′ ) − V ( s ) δ = r + γV(s') − V(s) δ=r+γV(s′)−V(s),可以理解为
实际获得的回报 − Critic 之前的预期 - 更新 Critic,让价值函数估计更加准确: w ← w + β δ ∇ w V w ( s ) w←w+βδ∇wVw(s) w←w+βδ∇wVw(s),也就是说:
- 如果 δ > 0 → 说明状态价值被低估
- 如果 δ < 0 → 说明状态价值被高估
- 更新 Actor,根据 Critic 的评价调整策略:
- δ > 0 :说明这个动作比预期好 → 提高该动作概率
- δ < 0 :说明这个动作比预期差 → 降低该动作概率
- 更新的核心形式为 θ ← θ + α δ ∇ θ l o g π θ ( a ∣ s ) θ←θ+αδ∇_θlogπ_θ(a∣s) θ←θ+αδ∇θlogπθ(a∣s)
- 整个循环概况为
Actor 负责行动
↓
Critic 负责评价
↓
Actor 根据评价改进策略
↓
Critic 根据结果修正判断
1-7 Actor-Critic 的优点
- 相比之前介绍的强化学习算法,
Actor-Critic同时结合了Policy-based与Value-based的优点:
| 方法 | 特点 |
|---|---|
| Value-based | 训练稳定,但不适合连续动作 |
| Policy-based | 策略灵活,但训练方差大 |
- 而 Actor-Critic 通过引入价值函数来评价策略,使得训练更加稳定。
- 因此它具有以下优点:
- 降低策略梯度的方差,训练更加稳定
- 能够处理连续动作空间
- 策略学习与价值评估同时进行,学习效率更高
- 不过
Actor-Critic仍然存在一个问题:- 训练效率不够高
- 那么有没有办法让训练 更快 呢?
- 有的兄弟有的------A3C如是说也
2 A3C(Asynchronous Advantage Actor-Critic )
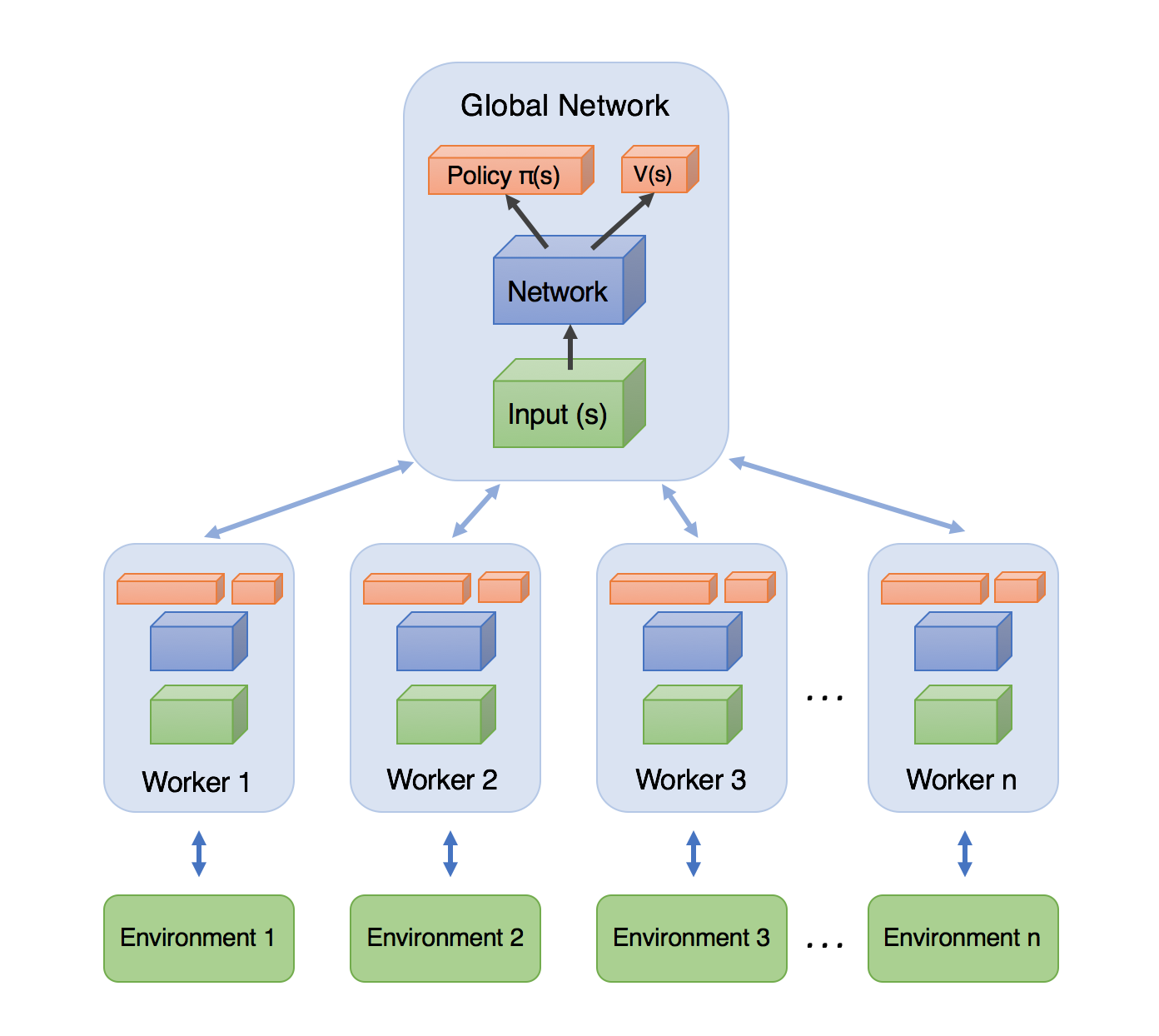
2-1 什么 A3C
- A3C(Asynchronous Advantage Actor-Critic)是一种 基于 Actor-Critic 框架的并行强化学习算法。
- 它通过 多个 Agent 同时与环境交互,并将学习到的梯度 异步更新到一个全局网络,从而提高训练效率并减少样本之间的相关性。
- 说人话A3C 本质上就是:
Actor-Critic+ 多线程并行训练(这下听懂了)
2-2 为什么用A3C
- 在传统强化学习中,通常只有 一个 Agent 与环境交互: A g e n t → E n v i r o n m e n t → 收集数据 → 更新网络 Agent → Environment → 收集数据 → 更新网络 Agent→Environment→收集数据→更新网络
- 这种方式存在两个明显问题:
- 训练速度慢
- 数据相关性强(因为相邻时间步的数据往往是非常相似的,还记得我们在第三期
DQN2-3提到的经验回放也是在解决这个问题) - 【浅显易懂理解强化学习】(三):DQN:当查表法装上大脑-CSDN博客
- 而 A3C 的解决方案非常直接:
- 让多个 Agent 同时探索环境。
- 整体的结构大致长这样:
Global Network
▲
┌────────┼────────┐
│ │ │
Worker1 Worker2 Worker3
│ │ │
Environment Environment Environment
- 每个 Worker:
- 拥有自己的环境
- 与环境独立交互
- 计算梯度
- 更新全局网络
- 这种方式带来了两个重要好处:
| 优点 | 作用 |
|---|---|
| 并行探索 | 训练速度大幅提升 |
| 数据更加多样 | 减少样本相关性 |
- 因此 A3C 能够 更快、更稳定地训练强化学习模型。
2-3 Worker
- 每个 Worker 拥有独立的环境和网络(Actor + Critic),它的职责包括:
- 环境交互
- Worker 根据当前策略 Actor 选择动作
- 执行动作,环境返回奖励
reward和下一状态next_state
- 状态特征提取
- Actor 和 Critic 可以共享底层特征提取层(共享卷积层或MLP前几层)
- 减少内存开销,提高计算效率
- 计算梯度
- Critic 计算 n-step 回报 → 得到 TD error / Advantage
- Actor 使用 Advantage 指导策略更新
- Critic梯度更新 w w w,Actor梯度更新 θ θ θ,得到梯度 ∇ θ ∇_θ ∇θ 和 ∇ w ∇_w ∇w(策略网络与价值网络)
- 异步更新全局网络
- Worker 将梯度异步累加到 Global Network
- 保证不同 Worker 的经验独立,提高训练稳定性
- 同步网络参数
- 更新完全局网络后,将最新参数同步回自己的 Actor/Critic
- 准备下一轮交互
2-4 Advantage 的作用
- 在 A3C 中,策略更新不再直接使用 reward,而是使用
Advantage(优势函数)替代了TD Error,更明确地指明“比平均好多少”,降低了策略梯度的方差。 - Advantage 的定义为: A ( s , a ) = Q ( s , a ) − V ( s ) A(s,a)=Q(s,a)−V(s) A(s,a)=Q(s,a)−V(s)
- 其中:
- Q ( s , a ) Q(s,a) Q(s,a):动作价值函数(Action-Value Function)
- 表示:在状态 s s s 下选择动作 a a a,以后能得到的 期望累计回报。
- V ( s ) V(s) V(s):状态价值函数(State-Value Function)
- 表示:在状态 s s s 下,按照当前策略选择动作后,平均能获得的期望累计回报。
- Q ( s , a ) Q(s,a) Q(s,a):动作价值函数(Action-Value Function)
- 它表示:这个动作到底比平均水平好多少。
- 当:
- A ( s , a ) > 0 A(s,a)>0 A(s,a)>0 → 这个动作比平均水平好
- A ( s , a ) < 0 A(s,a) < 0 A(s,a)<0 → 这个动作比平均水平差
2-5 n-step 回报
- n-step 回报 就是: R t ( n ) = r t + γ r t + 1 + γ r t + 2 2 + ⋯ + γ n − 1 r t + n − 1 + γ n V ( s t + n ) R_t^{(n)}=r_t+γr_{t+1}+γ^2_{rt+2}+⋯+γ^{n−1}r_{t+n−1}+γ^nV(s_{t+n}) Rt(n)=rt+γrt+1+γrt+22+⋯+γn−1rt+n−1+γnV(st+n)
- 简单说就是:
- 往前看 n 步,把未来 n 步的奖励都算上,然后再加上第 n 步的价值估计
- n-step 回报 = n 步实际奖励 + 第 n 步状态价值预测
- 说人话,假设你在游戏中:
- 1-step TD:你打了一下怪 → 看怪是否掉血 → 决定下一步策略
- n-step 回报:你连续打了 n 次 → 看总共掉了多少血 → 决定下一步策略
2-6 A3C的如何训练
- A3C 的训练其实就是 Actor-Critic + 多线程并行 + Advantage,流程如下:
- 每个 Worker 独立与环境交互:
- Worker 按当前策略 Actor 选择动作
- 执行动作,环境返回 reward 和 next_state
- 计算 Advantage A ( s , a ) = Q ( s , a ) − V ( s ) A(s,a)=Q(s,a)−V(s) A(s,a)=Q(s,a)−V(s)
- Q(s,a) 用多步回报近似(n-step Return)计算
- V(s) 由
Critic网络估计
- 更新 Critic(价值网络)
- Critic 通过 TD 或 n-step 误差更新价值网络参数 w ← w + β δ ∇ w V w ( s ) w←w+βδ∇_wV_w(s) w←w+βδ∇wVw(s)
- 更新 Actor(策略网络)
- Actor 使用 Advantage 指导策略更新: θ ← θ + α A ( s , a ) ∇ θ l o g π θ ( a ∣ s ) θ←θ+αA(s,a)∇_θlogπ_θ(a∣s) θ←θ+αA(s,a)∇θlogπθ(a∣s)
- A(s,a) > 0 → 增加动作概率
- A(s,a) < 0 → 减少动作概率
- 异步更新全局网络
- 每个 Worker 计算梯度后,异步累加到全局网络
- 然后同步更新自己的网络参数
- 这种异步机制让不同 Worker 的经验互相独立,提高训练稳定性
- 整个流程就是:
Worker 与环境交互
↓
计算 n-step 回报 → 估计 Advantage
↓
Critic 更新价值网络
↓
Actor 更新策略网络
↓
梯度异步更新到全局网络
↓
同步网络参数
2-7 Actor-Critic与A3C对比
Actor-Critic网络:- Actor 网络(策略网络)
- 输入:状态 s s s
- 输出:动作概率分布 π θ ( a ∣ s ) π_θ(a|s) πθ(a∣s)
- Critic 网络(价值网络)
- 输入:状态 s s s
- 输出:状态价值 V ( s ) V(s) V(s) 或动作价值 Q ( s , a ) Q(s,a) Q(s,a)
- Actor 网络(策略网络)
- 而对于
A3C:- 每个 Worker:
- Actor 网络(选择动作)
- Critic 网络(评估动作)
- 可以和 Actor-Critic 一样共享底层特征层
- 全局网络(Global Network):
- 保存全局参数
- 每个 Worker 异步计算梯度后 更新到全局网络
- 然后同步参数回到 Worker
- 每个 Worker:
| 特性 | Actor-Critic(AC) | A3C(Asynchronous Advantage Actor-Critic) |
|---|---|---|
| 核心思想 | Actor + Critic 同步更新策略和价值 | Actor + Critic + 多线程异步 + Advantage |
| 网络数量 | 2 个网络(Actor 网络 + Critic 网络) | 每个 Worker 2 个网络(Actor + Critic),外加全局网络保存参数 |
| 训练方式 | 单线程,按步更新 | 多线程异步,每个 Worker 独立与环境交互,梯度异步累加到全局网络 |
| 回报计算 | TD(1-step)(标准AC是n=1的n-step) | n-step 回报,减少方差并加快训练 |
| 策略更新 | 使用 TD error δ = r + γ V ( s ′ ) − V ( s ) \delta = r + γV(s') - V(s) δ=r+γV(s′)−V(s) | 使用 Advantage A ( s , a ) = R t ( n ) − V ( s ) A(s,a) = R_t^{(n)} - V(s) A(s,a)=Rt(n)−V(s) |
| 优点 | 训练稳定,可处理连续动作 | 并行探索 → 提升训练速度;数据多样性高 → 减少相关性;策略更稳定 |
| 缺点 | 样本利用率低,训练慢 | 线程多 → 需要更多计算资源;调参复杂 |
| 适用场景 | 小规模环境或单 Agent 任务 | 大规模环境、复杂任务、多 Agent 或需要快速训练的场景 |
小结:
- 本期我们介绍了
Actor-Critic与A3C- AC → 改进 Policy Gradient,稳定策略训练
- A3C → 多线程 + Advantage + n-step 回报 → 更快、更稳定训练
- 下一期我们讲
DDPG - 希望文章对你有帮助,如有错误,欢迎指出。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)