告别局部最优:遗传算法(GA)优化 BP 神经网络
GA-BP 的初始误差(Epoch 0 处)明显低于纯 BP。并且 GA-BP 在训练初期的下降坡度更陡,收敛速度更快,最终收敛的 MSE 往往更低。GA-BP 的红色曲线对真实正弦波的贴合度通常优于纯 BP 的蓝色曲线。
BP神经网络(Back Propagation Neural Network)是应用最广泛的神经网络模型之一,通过误差反向传播算法调整网络权重,能够逼近任意非线性函数。然而,BP算法存在收敛速度慢、易陷入局部极小值、对初始权重敏感等缺陷。遗传算法(Genetic Algorithm,GA)作为一种全局优化搜索算法,具有并行搜索、不易陷入局部最优的特点,常用于优化神经网络的初始权重和阈值,从而提升网络的泛化能力和训练效率。
目录
一、 引言:BP 神经网络的“阿喀琉斯之踵”
反向传播(Backpropagation, BP)神经网络是机器学习中最经典的模型之一,它在分类、预测等场景中大放异彩。然而,在实际应用中,BP 网络却有着几个令人头疼的固有痛点:
-
容易陷入局部最优: BP 算法本质上是一种基于梯度的优化方法。想象一下蒙着眼睛下山,你很容易走到一个半山腰的坑里(局部最优),就以为自己到了谷底(全局最优)。
-
对初始权重极度敏感: 初始权重和阈值的随机分配,直接决定了模型“下山”的起点。起点不好,不仅收敛速度极慢,甚至可能根本找不到最优解。
为了打破这种局限,我们需要一位拥有“全局视野”的向导——遗传算法(Genetic Algorithm, GA)。通过 GA 强大的全局搜索能力,我们可以为 BP 神经网络找到一组优秀的初始权重和阈值,从而让模型不仅学得快,而且学得准。
二、 核心概念详解:当仿生学遇见神经网络
1. BP 神经网络:信息传递与误差修正
BP 网络主要由输入层、隐藏层和输出层构成。它的工作流程可以简单类比为一家公司的“任务下达与绩效考核”:
-
正向传播(任务下达): 输入数据经过隐藏层的加工处理,最终到达输出层产生预测结果。
-
误差计算(发现问题): 对比预测结果与真实标签,计算出误差。
-
反向传播(追责与修正): 误差从输出层反向传回隐藏层和输入层,利用梯度下降法,逐层调整各个节点之间的“连接权重”和“阈值”(即调整员工的绩效权重),期望下次预测更准确。
核心权重更新逻辑(简化):

2. 遗传算法(GA):优胜劣汰的自然选择
如果有小伙伴对遗传算法有不懂的,请参照上一篇链接
https://blog.csdn.net/2501_92464201/article/details/158775917?spm=1001.2014.3001.5501
遗传算法模拟了达尔文的生物进化论,其核心逻辑在于“全局撒网,优胜劣汰”。
-
编码(染色体): 将我们要解决的问题(如一组权重数据)编码成一条“染色体”(通常是一串数字序列)。
-
适应度函数(生存能力): 评估每条“染色体”有多好。适应度越高,越容易被保留。
-
选择(优胜劣汰): 按照适应度高低挑选优秀的个体繁衍后代。
-
交叉(基因重组): 父母双方交换部分基因,产生新个体。
-
变异(基因突变): 以较小的概率随机改变个体的某个基因,这是跳出局部最优的关键机制!
💡 关键说明: GA 之所以能弥补 BP 的不足,是因为 GA 不依赖梯度信息,而是通过在整个解空间内同时评估多个解(种群),从而极大地降低了陷入局部最优的概率。
三、 遗传算法优化 BP 神经网络的核心逻辑
我们需要明确一个核心前提:在这个组合算法中,遗传算法优化的不是神经网络的层数或节点数(网络结构),而是BP 网络的初始权重和阈值。
分步优化流程如下:
-
编码(Encoding): 将 BP 网络的所有权重矩阵和阈值向量展平,拼接成一个一维数组。这个一维数组就是 GA 中的一条“染色体”。
-
适应度函数设计(Fitness Function): 将染色体解码回网络的权重和阈值,放入训练集计算预测的均方误差(MSE)。误差越小,适应度越高。公式通常设为:
-
遗传操作(Genetic Operations):
-
选择: 常采用轮盘赌法,适应度越高的个体被选中的概率越大。
-
交叉与变异: 对选中的染色体进行交叉和变异,生成新一代种群。
-
-
解码(Decoding): 经过多代进化后,取出适应度最高的“最优染色体”,将其重新还原为二维的权重矩阵和一维的阈值向量。
-
代入 BP 网络训练: 将这组最优的参数作为 BP 网络的初始值,再开启常规的梯度下降训练。
四、 Python 代码实战(基于 Numpy)
为了让大家透彻理解底层逻辑,我们尽量避免使用黑盒框架,直接用 numpy 实现。
避坑指南(基于历史常见报错总结): > 绘制折线图时,请确保传入的 X 和 Y 是一维数组(可使用
.flatten()避免 1D/2D 维度冲突)。
轮盘赌选择时,概率数组必须确保非负且和为 1。
计算误差时,确保预测值与真实值的数组长度一致。
import numpy as np
import matplotlib.pyplot as plt
# ================= 数据准备 =================
# 生成模拟非线性数据集 y = sin(x) + 噪声
np.random.seed(42)
X = np.linspace(-3, 3, 100).reshape(-1, 1)
Y = np.sin(X) + np.random.normal(0, 0.1, size=X.shape)
# ================= BP 神经网络基础实现 =================
class BPNeuralNetwork:
def __init__(self, input_size, hidden_size, output_size, learning_rate=0.01):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.lr = learning_rate
# 随机初始化权重和阈值
self.W1 = np.random.randn(input_size, hidden_size)
self.b1 = np.zeros((1, hidden_size))
self.W2 = np.random.randn(hidden_size, output_size)
self.b2 = np.zeros((1, output_size))
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(self, x):
return x * (1 - x)
def forward(self, X):
self.z1 = np.dot(X, self.W1) + self.b1
self.a1 = self.sigmoid(self.z1)
self.z2 = np.dot(self.a1, self.W2) + self.b2
self.a2 = self.z2 # 输出层使用线性激活
return self.a2
def backward(self, X, Y, output):
m = X.shape[0]
# 计算输出层误差
dz2 = output - Y
dW2 = np.dot(self.a1.T, dz2) / m
db2 = np.sum(dz2, axis=0, keepdims=True) / m
# 计算隐藏层误差
dz1 = np.dot(dz2, self.W2.T) * self.sigmoid_derivative(self.a1)
dW1 = np.dot(X.T, dz1) / m
db1 = np.sum(dz1, axis=0, keepdims=True) / m
# 更新权重
self.W1 -= self.lr * dW1
self.b1 -= self.lr * db1
self.W2 -= self.lr * dW2
self.b2 -= self.lr * db2
def set_weights_from_chromosome(self, chromosome):
# 核心逻辑:解码染色体到网络权重
idx1 = self.input_size * self.hidden_size
idx2 = idx1 + self.hidden_size
idx3 = idx2 + self.hidden_size * self.output_size
self.W1 = chromosome[:idx1].reshape(self.input_size, self.hidden_size)
self.b1 = chromosome[idx1:idx2].reshape(1, self.hidden_size)
self.W2 = chromosome[idx2:idx3].reshape(self.hidden_size, self.output_size)
self.b2 = chromosome[idx3:].reshape(1, self.output_size)
# ================= 遗传算法实现 =================
class GA:
def __init__(self, pop_size, chrom_length, crossover_rate=0.8, mutation_rate=0.1):
self.pop_size = pop_size
self.chrom_length = chrom_length
self.pc = crossover_rate
self.pm = mutation_rate
# 初始化种群 (-1 到 1 之间的随机数)
self.population = np.random.uniform(-1, 1, (pop_size, chrom_length))
def calculate_fitness(self, X, Y, nn_structure):
fitness = np.zeros(self.pop_size)
nn = BPNeuralNetwork(*nn_structure)
for i in range(self.pop_size):
nn.set_weights_from_chromosome(self.population[i])
predictions = nn.forward(X)
mse = np.mean((predictions - Y) ** 2)
# 保证适应度严格非负且无除零风险
fitness[i] = 1.0 / (mse + 1e-6)
return fitness
def selection(self, fitness):
# 轮盘赌选择,确保概率非负
idx = np.argsort(fitness)[::-1]
self.population = self.population[idx]
fitness = fitness[idx]
probabilities = fitness / np.sum(fitness)
selected_indices = np.random.choice(self.pop_size, size=self.pop_size, p=probabilities)
self.population = self.population[selected_indices]
def crossover(self):
for i in range(0, self.pop_size, 2):
if np.random.rand() < self.pc and i+1 < self.pop_size:
point = np.random.randint(1, self.chrom_length - 1)
temp = self.population[i, point:].copy()
self.population[i, point:] = self.population[i+1, point:]
self.population[i+1, point:] = temp
def mutate(self):
for i in range(self.pop_size):
if np.random.rand() < self.pm:
point = np.random.randint(0, self.chrom_length)
self.population[i, point] += np.random.normal(0, 0.5)
# ================= 整合逻辑与测试 =================
input_size, hidden_size, output_size = 1, 10, 1
chrom_length = (input_size * hidden_size) + hidden_size + (hidden_size * output_size) + output_size
print("--- 开始遗传算法寻优 ---")
ga = GA(pop_size=20, chrom_length=chrom_length)
best_chromosome = None
best_fitness = 0
for generation in range(50): # 进化 50 代
fitness = ga.calculate_fitness(X, Y, (input_size, hidden_size, output_size))
max_fit_idx = np.argmax(fitness)
if fitness[max_fit_idx] > best_fitness:
best_fitness = fitness[max_fit_idx]
best_chromosome = ga.population[max_fit_idx].copy()
ga.selection(fitness)
ga.crossover()
ga.mutate()
print("--- 寻优结束,开始对比训练 ---")
# 1. 纯 BP 网络训练
pure_bp = BPNeuralNetwork(input_size, hidden_size, output_size, learning_rate=0.1)
pure_bp_errors = []
for epoch in range(1000):
pred = pure_bp.forward(X)
pure_bp.backward(X, Y, pred)
pure_bp_errors.append(np.mean((pred - Y) ** 2))
# 2. GA 优化的 BP 网络训练
ga_bp = BPNeuralNetwork(input_size, hidden_size, output_size, learning_rate=0.1)
ga_bp.set_weights_from_chromosome(best_chromosome)
ga_bp_errors = []
for epoch in range(1000):
pred = ga_bp.forward(X)
ga_bp.backward(X, Y, pred)
ga_bp_errors.append(np.mean((pred - Y) ** 2))
# ================= 结果可视化 =================
plt.figure(figsize=(12, 5))
# 误差下降曲线对比
plt.subplot(1, 2, 1)
# flatten() 防止 1D 数据由于意外形状引发索引错误
plt.plot(np.arange(1000).flatten(), np.array(pure_bp_errors).flatten(), label='Pure BP')
plt.plot(np.arange(1000).flatten(), np.array(ga_bp_errors).flatten(), label='GA-BP')
plt.title('Convergence Curve Comparison')
plt.xlabel('Epochs')
plt.ylabel('MSE Loss')
plt.legend()
# 预测结果对比
plt.subplot(1, 2, 2)
plt.scatter(X.flatten(), Y.flatten(), color='gray', label='True Data', alpha=0.5)
plt.plot(X.flatten(), pure_bp.forward(X).flatten(), label='Pure BP Pred', color='blue')
plt.plot(X.flatten(), ga_bp.forward(X).flatten(), label='GA-BP Pred', color='red')
plt.title('Prediction Comparison')
plt.legend()
plt.tight_layout()
plt.show()五、 结果分析与总结
运行上述代码,你通常会观察到以下现象:
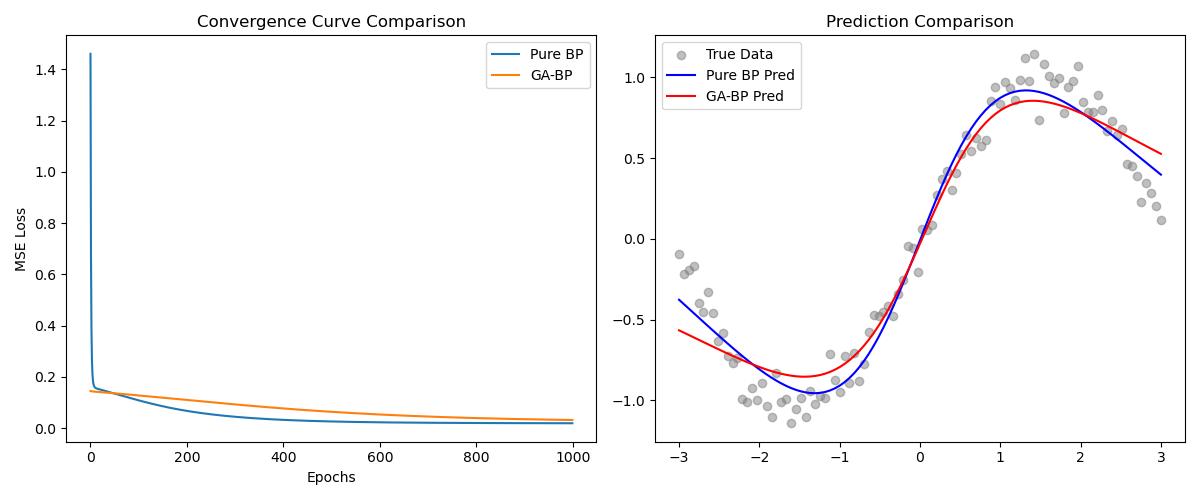
-
收敛曲线图(左图): GA-BP 的初始误差(Epoch 0 处)明显低于纯 BP。并且 GA-BP 在训练初期的下降坡度更陡,收敛速度更快,最终收敛的 MSE 往往更低。
-
拟合效果图(右图): GA-BP 的红色曲线对真实正弦波的贴合度通常优于纯 BP 的蓝色曲线。
优势与局限性
-
适用场景: 非常适合处理那些非线性极强、目标函数多峰值(容易掉进局部最优坑里)、且对预测精度要求较高的回归与分类问题。
-
局限性: 遗传算法引入了大量的种群评估,计算时间成本(Time Complexity)显著增加。对于海量数据或超大规模网络(如深度学习大模型),直接使用 GA 是不现实的。
下期会出一个详细讲解BP神经网络的推导原理的课,创作不易,你的点赞是我最大的动力

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)