【浅显易懂理解强化学习】(六):DDPG与TD3集百家之长
·
前言
- 本系列讲究浅显易懂,所以尽量讲的简单并减少数学公式的解释加强实际运用。
- 上一期我们学习了 Actor-Critic 和 A3C,发现它结合了
策略梯度和价值函数的优势,可以在离散动作空间中高效工作。 - 但是,现实中的很多控制任务动作不是离散的,而是连续的,这点和我们在第四期讲过的
Policy Gradients一样,因此,本期我们要介绍的算法,既继承了 Actor-Critic 的稳定训练能力,又像 Policy Gradient 一样可以直接处理连续动作空间。
0 前置知识:软更新(soft update)
- 在强化学习训练过程中,如果 目标网络变化太快,就会导致学习目标不断变化,从而造成训练不稳定。
0-1 硬更新(Hard Update)
- 在早期的 DQN 中,通常使用的是 硬更新(Hard Update): θ ′ ← θ θ^′←θ θ′←θ
- 也就是:
- 每隔 N 步
- 直接把主网络参数完全复制到目标网络
- 代码我们一般直接这样写:
#每 1000 步:
target_network = main_network
- 这种方式虽然简单,但问题是:
- 目标网络会 突然发生巨大变化。
0-2 软更新(Soft Update):
- 于是我们采用另一种更新方式: θ Q ′ ← τ θ Q + ( 1 − τ ) θ Q ′ \theta^{Q'} \leftarrow \tau \theta^Q + (1-\tau) \theta^{Q'} θQ′←τθQ+(1−τ)θQ′ θ μ ′ ← τ θ μ + ( 1 − τ ) θ μ ′ \theta^{\mu'} \leftarrow \tau \theta^\mu + (1-\tau) \theta^{\mu'} θμ′←τθμ+(1−τ)θμ′
- 其中:
- τ \tau τ 是一个 很小的系数(例如 0.001)
- 可以理解为:
- 目标网络 每一步只向主网络靠近一点点。
- 这样更新后:
- 目标网络 变化非常平滑
- 学习目标不会突然改变
- 训练 更加稳定
1 DDPG(Deep Deterministic Policy Gradient )
1-1 介绍
- DDPG 是 Deep Deterministic Policy Gradient 的缩写,直译为“深度确定性策略梯度”。它是一种 强化学习算法,专门用于 连续动作空间 的场景,比如机械臂控制、无人车驾驶等。
- 从命名不难看出
DDPG本质上是 Policy Gradient 的一种变体:(可以说是接百家之长了)- 使用
Actor-Critic架构。- Actor 网络直接输出连续动作(确定性策略)。
- Critic 网络评估 Actor 的动作价值(Q 值)。
- 同时它结合了 Policy Gradient 的策略优化,通过 Critic 提供的梯度直接优化 Actor 的策略网络。
- DQN 的经验回放与目标网络 技术
- 使用
- DDPG 的核心思想:
通过 Critic 给 Actor 提供梯度,让 Actor 学会在连续动作空间里做最优动作。
1-2 DDPG 核心公式
- DDPG 的训练可以从 Actor-Critic + 策略梯度 + 目标网络 + 经验回放 四个方面来理解,这些内容我们在前几期都提到过,这里快速过一遍
1-2-1 Actor-Critic 架构
- Actor 策略网络 μ ( s ∣ θ μ ) \mu(s|\theta^\mu) μ(s∣θμ)
输入状态 s s s,输出连续动作 a = μ ( s ) a = \mu(s) a=μ(s)
- Critic 价值网络 Q ( s , a ∣ θ Q ) Q(s,a|\theta^Q) Q(s,a∣θQ)
输入状态 s s s 和动作 a a a,输出动作的价值 Q Q Q,告诉 Actor 这个动作好不好。
1-2-2 Critic 网络更新
- Critic 用 Q-learning 思路 训练,核心是最小化 TD误差: y i = r i + γ Q ′ ( s i + 1 , μ ′ ( s i + 1 ∣ θ μ ′ ) ∣ θ Q ′ ) y_i = r_i + \gamma Q'(s_{i+1}, \mu'(s_{i+1}|\theta^{\mu'})|\theta^{Q'}) yi=ri+γQ′(si+1,μ′(si+1∣θμ′)∣θQ′) L = 1 N ∑ i ( Q ( s i , a i ∣ θ Q ) − y i ) 2 L = \frac{1}{N}\sum_i (Q(s_i,a_i|\theta^Q) - y_i)^2 L=N1i∑(Q(si,ai∣θQ)−yi)2
- Q ′ Q' Q′ 和 μ ′ \mu' μ′ 是 目标网络,保证训练稳定。
- Critic 更新就是把当前 Q 值逼近 “下一步奖励 + 下一个状态的估值”。
- 说人话:Critic 的目标是学会预测动作价值:
- 看当前动作值 Q。
- 看下一步可能获得的奖励 + 下一状态的估值。
- 第一期: 【浅显易懂理解强化学习】(一)Q-Learning原来是查表法-CSDN博客
1-2-3 Actor 网络更新(策略梯度)
- Actor 通过 Critic 提供的梯度来优化策略: ∇ θ μ J ≈ 1 N ∑ i ∇ a Q ( s , a ∣ θ Q ) ∣ a = μ ( s i ) ∇ θ μ μ ( s i ∣ θ μ ) \nabla_{\theta^\mu} J \approx \frac{1}{N}\sum_i \nabla_a Q(s,a|\theta^Q)|_{a=\mu(s_i)} \nabla_{\theta^\mu} \mu(s_i|\theta^\mu) ∇θμJ≈N1i∑∇aQ(s,a∣θQ)∣a=μ(si)∇θμμ(si∣θμ)
- 这个公式本质上就是
确定性策略梯度(Deterministic Policy Gradient)定理,是 DDPG 名字中 “Deterministic Policy Gradient” 的来源。
- Actor 不直接看 reward,而是 看 Critic 给的动作价值梯度。
- Actor 学习在每个状态下输出让 Q 值最高的动作。
- 第四期:【浅显易懂理解强化学习】(四):Policy Gradients玩转策略采样-CSDN博客
1-2-4 经验回放(Replay Buffer)
- 把 Agent 与环境交互的 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)存入 回放池。
- 每次训练随机采样一个 batch,打破样本相关性。
- 优势
- 充分利用数据(同一条经验可以训练多次)。
- 减少连续样本相关性导致的训练震荡。
1-2-5 目标网络(Target Network)软更新
- 目标网络 ( μ ′ , Q ′ ) (\mu', Q') (μ′,Q′)与主网络同步,但采用 软更新: θ Q ′ ← τ θ Q + ( 1 − τ ) θ Q ′ \theta^{Q'} \leftarrow \tau \theta^Q + (1-\tau) \theta^{Q'} θQ′←τθQ+(1−τ)θQ′ θ μ ′ ← τ θ μ + ( 1 − τ ) θ μ ′ \theta^{\mu'} \leftarrow \tau \theta^\mu + (1-\tau) \theta^{\mu'} θμ′←τθμ+(1−τ)θμ′
- τ \tau τ很小(如 0.001),保证目标网络变化平滑,提高训练稳定性。
- 软更新使目标网络 每一步只向主网络靠近一点点。(就像前置知识0提到的一样)
1-3 训练流程
- 可以看到
DDPG真就是集百家之长吼吼,把前几期的内容全部串起来了
- 初始化 Actor、Critic 及目标网络,准备回放池
- 与环境交互,存储经验 ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)
- 随机采样 batch 更新:
- Critic:最小化 TD 误差
- Actor:沿 Critic 梯度更新策略
- 软更新目标网络
- 循环训练,直到 Actor 学会连续动作最优策略
1-4 DDPG结构图
state s
│
Actor μ(s)
│
action a
│
┌───────────┴───────────┐
│ │
环境 env Critic Q(s,a)
│ │
reward r │
│ │
└──── Replay Buffer ────┘
1-5 DDPG 的问题
- 虽然 DDPG 在连续动作空间表现很好,但在实际训练中仍然存在一些比较明显的问题:
-
Q值过估计(Overestimation)
- 由于 Critic 网络在训练时会不断使用自己预测的 Q 值进行更新,这容易导致 Q 值被逐渐高估,从而影响策略学习。(这点和Q-learning的问题类似)
- 说人话就是 Critic 有时候会“过度自信”,觉得某些动作特别好,但其实并没有那么好。
- 这会导致 Actor 学习到 不稳定甚至错误的策略。
-
策略更新过于频繁
- 在 DDPG 中:
- 每次更新 Critic
- 同时更新 Actor
- 这可能导致 Actor 在 Critic 还没学好的时候就跟着更新,从而产生 策略震荡。
- 在 DDPG 中:
-
目标值容易被噪声影响
- 在计算目标 Q 值时: y = r + γ Q ′ ( s ′ , μ ′ ( s ′ ) ) y = r + \gamma Q'(s',\mu'(s')) y=r+γQ′(s′,μ′(s′))
- 如果目标动作带有误差,可能会让 Critic 学到不准确的估值。
- 那么为了解决这些问题,研究者提出了 TD3(Twin Delayed Deep Deterministic Policy Gradient)。
2 TD3(Twin Delayed Deep Deterministic Policy Gradient)
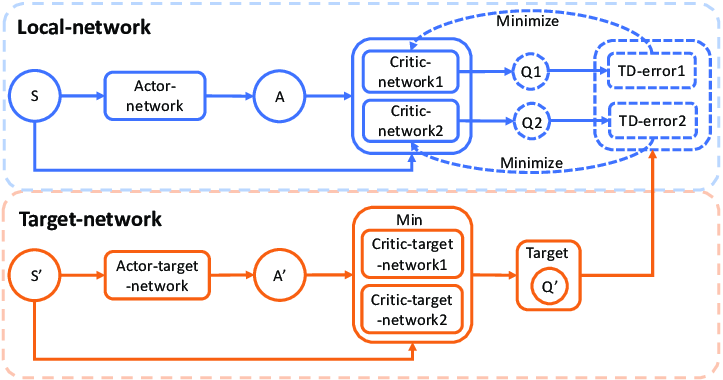
2-1 介绍
- TD3 是 Twin Delayed Deep Deterministic Policy Gradient 的缩写,可以理解为 DDPG 的改进版本。
- 为了解决1-5中提到的
DDPG在实际训练中遇到的三个问题,TD3 提出了三个简单但非常有效的改进,这也是它名字的由来:- Twin Critic(双Q网络) —— 减少 Q 值过估计
- Delayed Policy Update(延迟策略更新) —— 提高训练稳定性
- Target Policy Smoothing(目标策略平滑) —— 减少噪声影响
2-2 三大改进
2-2-1 Twin Critic(双 Q 网络)
- TD3 使用 两个 Critic 网络: Q 1 ( s , a ) , Q 2 ( s , a ) Q_1(s,a), \quad Q_2(s,a) Q1(s,a),Q2(s,a)
- 在计算目标 Q 值时,取 两个 Q 值中较小的那个: y = r + γ min ( Q 1 ′ ( s ′ , a ′ ) , Q 2 ′ ( s ′ , a ′ ) ) y = r + \gamma \min(Q'_1(s',a'),Q'_2(s',a')) y=r+γmin(Q1′(s′,a′),Q2′(s′,a′))
- 这样可以有效减少 Q值过估计问题。
2-2-2 Delayed Policy Update(延迟策略更新)
- 在 DDPG 中:
- 每更新一次 Critic
- Actor 就更新一次
- 但在 TD3 中:
- Critic 更新多次
- Actor 才更新一次
- 这样可以先让 Critic 学得更准确, Actor 再根据更可靠的 Q 值更新策略
2-2-3 Target Policy Smoothing(目标策略平滑)
- 在计算目标动作时,TD3 会加入 小噪声: a ′ = μ ′ ( s ′ ) + ϵ a' = \mu'(s') + \epsilon a′=μ′(s′)+ϵ
- 其中: ϵ ∼ clip ( N ( 0 , σ ) , − c , c ) \epsilon \sim \text{clip}(\mathcal{N}(0,\sigma),-c,c) ϵ∼clip(N(0,σ),−c,c)
- 这个技巧的作用是:
- 防止策略 过度依赖某个精确动作
- 提高策略的 鲁棒性
2-3 训练流程
- TD3 的训练流程与 DDPG 类似,但多了一些改进步骤。
- 初始化 Actor、两个 Critic 以及对应的目标网络
- 与环境交互,获得经验 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1)并存入 Replay Buffer
- 从经验回放池随机采样 batch
- 更新 两个 Critic
- 计算目标值: a ′ = μ ′ ( s ′ ) + ϵ a' = \mu'(s') + \epsilon a′=μ′(s′)+ϵ y = r + γ min ( Q 1 ′ ( s ′ , a ′ ) , Q 2 ′ ( s ′ , a ′ ) ) y = r + \gamma \min(Q'_1(s',a'),Q'_2(s',a')) y=r+γmin(Q1′(s′,a′),Q2′(s′,a′))
- 最小化 TD 误差: L = ( Q i ( s , a ) − y ) 2 L = (Q_i(s,a) - y)^2 L=(Qi(s,a)−y)2
- 延迟更新 Actor
- 每隔 d 步 才更新一次 Actor: ∇ θ μ J \nabla_{\theta^\mu}J ∇θμJ让 Actor 输出 更高 Q 值的动作。
- 软更新目标网络:
θ Q ′ ← τ θ Q + ( 1 − τ ) θ Q ′ \theta^{Q'} \leftarrow \tau \theta^Q + (1-\tau)\theta^{Q'} θQ′←τθQ+(1−τ)θQ′
θ μ ′ ← τ θ μ + ( 1 − τ ) θ μ ′ \theta^{\mu'} \leftarrow \tau \theta^\mu + (1-\tau)\theta^{\mu'} θμ′←τθμ+(1−τ)θμ′
7. 重复以上步骤,直到策略收敛。
2-4 和DDPG对比
| 特性 | DDPG | TD3 |
|---|---|---|
| Critic 数量 | 1 个 | 2 个(Twin Critic) |
| Q值计算 | 单 Q 值 | 取两个 Q 的最小值 |
| Actor 更新 | 每次更新 | 延迟更新 |
| 目标动作 | 直接使用 | 加入平滑噪声 |
| 训练稳定性 | 一般 | 明显更稳定 |
- 总结来说:
- TD3 本质上就是在 DDPG 基础上增加三个改进,使训练更加稳定。
小结:
- 本期我们介绍了用于连续动作空间的强化学习算法 DDPG 与 TD3:
- 其中 DDPG 可以看作 Actor-Critic + Policy Gradient + DQN 技术的结合
- TD3 则通过 Twin Critic、Delayed Policy Update 和 Target Policy Smoothing 三个改进进一步提升训练稳定性。
- 下一期我们讲
PPO - 希望文章对你有帮助,如有错误,欢迎指出。
总结
- 自此,我们的系列以及讲了很多算法了,我们来回顾一下:
Value-basedQ-Learning:- 最经典的强化学习算法,本质是 查表学习每个状态-动作的价值 Q(s,a)。
Sarsa:- 与 Q-Learning 类似,但属于 on-policy 学习,更新时使用 当前策略实际执行的动作
DQN:- 使用 神经网络替代 Q 表,让 Q-Learning 可以处理 高维状态空间(如图像)。
Policy-basedPolicy Gradient:- 直接学习 策略函数 π(a|s),通过梯度优化策略,而不是学习 Q 值。
Actor-Critic:- 结合 Policy Gradient 与 Value Function: Actor 负责决策,Critic 负责评价动作好坏。
A3C:- 通过 多线程并行训练加速 Actor-Critic,提高训练效率和稳定性。
DDPG:- 将 Actor-Critic + DQN 技术结合,用于 连续动作空间控制问题。
TD3:- 在 DDPG 基础上通过 双Q网络、延迟更新、策略平滑提升训练稳定性。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)