2026巨头疯抢赛道:多任务强化学习Multi-task RL
最近观察了AGI的发展,作为其重要技术路径之一的多任务强化学习MTRL热度暴涨,吸引了很多大佬和机构入场,仅2026年初,就有一批相关论文被顶会接收。细数是数不过来了,就说几个瞩目的:字节跳动的OneReward,一个奖励模型统一多任务图像生成,效果全面超越PS!Meta AI的文章更是首次揭示了多任务RL后训练中一个被忽视的现象:梯度不平衡。可以看出来,MTRL之所以这么火,很大原因在于它能提供
最近观察了AGI的发展,作为其重要技术路径之一的多任务强化学习MTRL热度暴涨,吸引了很多大佬和机构入场,仅2026年初,就有一批相关论文被顶会接收。
细数是数不过来了,就说几个瞩目的:字节跳动的OneReward,一个奖励模型统一多任务图像生成,效果全面超越PS!Meta AI的文章更是首次揭示了多任务RL后训练中一个被忽视的现象:梯度不平衡。
可以看出来,MTRL之所以这么火,很大原因在于它能提供多个层次、多种类型的切入点,满足很多人的需求。无论你是想做理论突破,还是搞应用创新,都有空间。
为了帮助你更清晰地定位,我筛选了14篇MTRL近期发布的顶会&机构文章,都可作为学术范本和前沿风向标,相信你看完就会有收获。
全部论文+开源代码需要的同学看文末
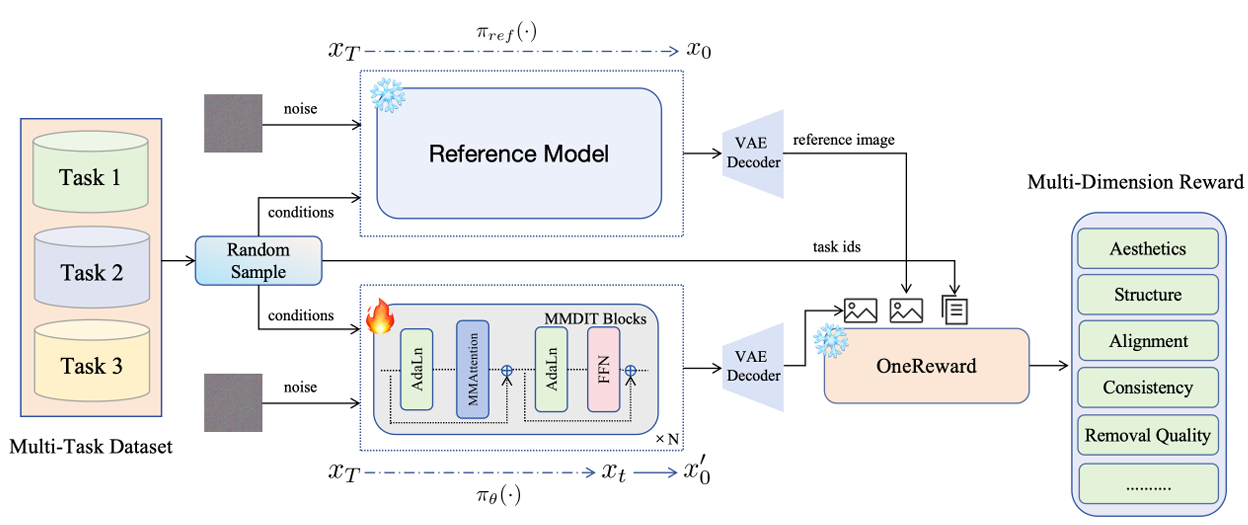
OneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning
研究方法:论文提出OneReward统一强化学习框架,以单个视觉语言模型(VLM)作为奖励模型,通过多任务强化学习直接在预训练基础模型上优化,无需任务特定监督微调(SFT),即可高效完成图像填充、扩展、目标移除和文本渲染等多类掩码引导图像生成任务。
创新点:
-
提出OneReward框架,用单VLM作为奖励模型,适配多任务、多维度的生成结果评估,无需单独训练任务专属奖励模型。
-
基于该框架构建Seedream 3.0 Fill,通过多任务强化学习直优化预训练模型,免任务微调,统一完成多类掩码引导图像编辑且性能领先。
-
设计动态强化学习策略,复用EMA模型为参考模型降低成本,同时开源优化后的FLUX Fill模型,提供新研究基线。
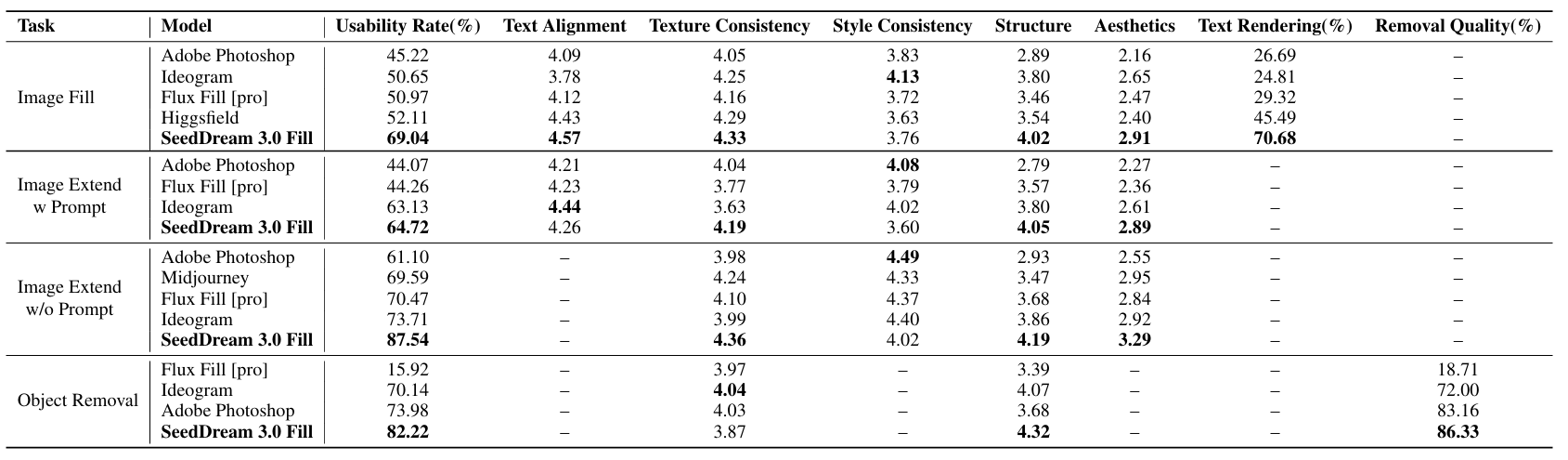
研究价值:研究提出 OneReward 统一强化学习框架,首次将多任务强化学习直接用于掩码引导图像编辑模型优化,打造出性能超越主流竞品的统一编辑模型,还开源优化后的 FLUX Fill 模型,为多任务图像生成的研究和落地提供了新框架、新模型与新基线。
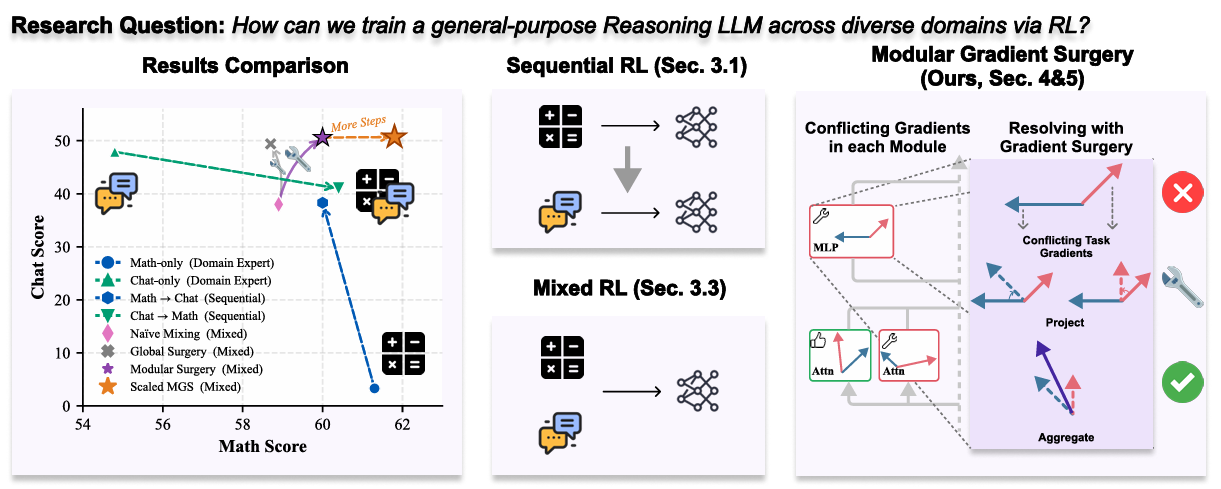
Advancing General-Purpose Reasoning Models with Modular Gradient Surgery
研究方法:论文提出模块化梯度手术(MGS)方法,在多任务强化学习中针对Transformer模型的模块层面解决跨域梯度冲突,有效缓解序列训练的模式干扰与混合训练的梯度冲突问题,实现通用推理大模型在数学、聊天、指令遵循等多领域的稳定高效训练。
创新点:
-
探究多域强化学习两大训练策略,明确序列式存在模式干扰、混合式存在梯度冲突,厘清了跨域干扰的核心成因。
-
提出模块化梯度手术(MGS),在Transformer模块层面消解跨域梯度冲突,避免全局策略的过度保守。
-
首次将梯度操纵用于大模型RL后训练,验证MGS在多任务、长时训练的有效性,提供低开销解决方案。
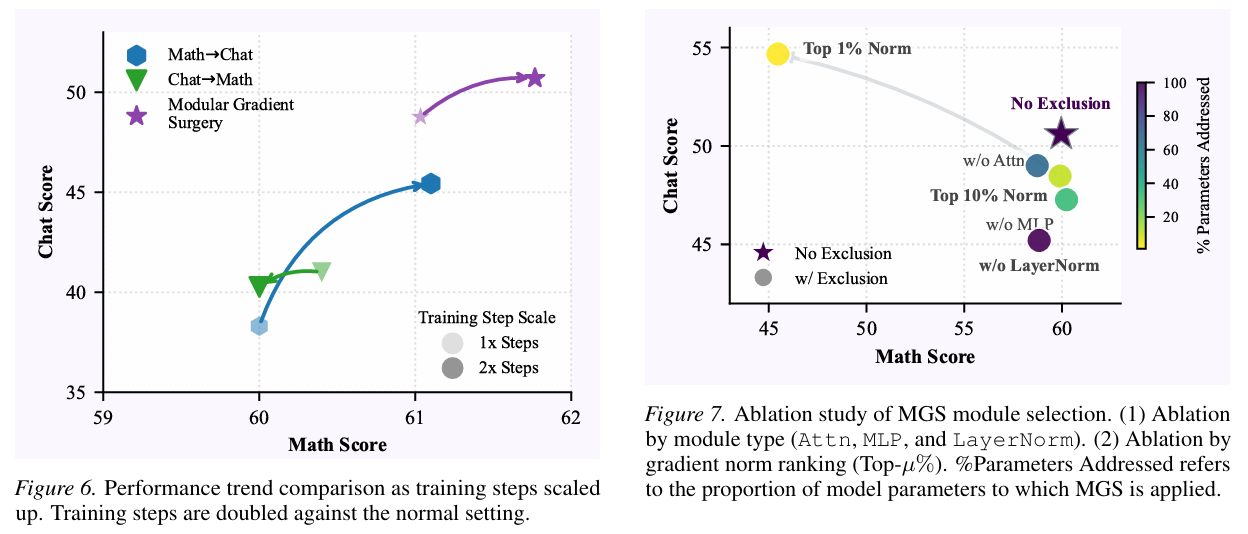
研究价值:研究厘清了多领域强化学习训练通用推理大模型的跨域干扰成因,提出的模块化梯度手术方法有效解决了梯度冲突问题,首次将梯度操纵应用于大模型RL后训练并验证其有效性,为通用推理大模型的多任务强化学习训练提供了高效低耗的新范式与实践参考。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“222”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)