vllm实践
不过这 128 条 prompt 完全一样,所以 Prefix Cache 会命中,后续请求的 Prefill 几乎是白送的,数据会偏好看。所使用的模型为 Qwen3/qwen-1.7b,与前文离线推理部分保持一致,便于对比两种模式的差异与集成方式。表示“所有主机都不走代理”。(具体行为取决于你系统里 no_proxy 的解析方式,常见意图是尽量不走代理。把这两个环境变量设成空,等价于关闭 HTT
文章目录
一、vLLM离线和在线部署推理、并测试在线服务性能
1.0 环境配置
- vLLM安装
pip install vllm
若发现下载包速度过慢,可将 PyPI 源切换至国内镜像,例如:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
# 也可以直接在安装的时候临时性指定 -i
pip install vllm -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装完成后,执行验证脚本;若终端打印版本号(示例:0.10.1.1),即表明 vLLM 框架已就绪。
import vllm
print(vllm.__version__)
- 参数解释
- 温度(temperature):用于调节模型输出的概率分布多样性。温度越高,输出分布越平缓,随机性越强;温度越低,分布越尖锐,倾向于选择高概率词元。当温度趋近于 0 时,模型输出趋于确定性,几乎总是选择概率最高的词元。
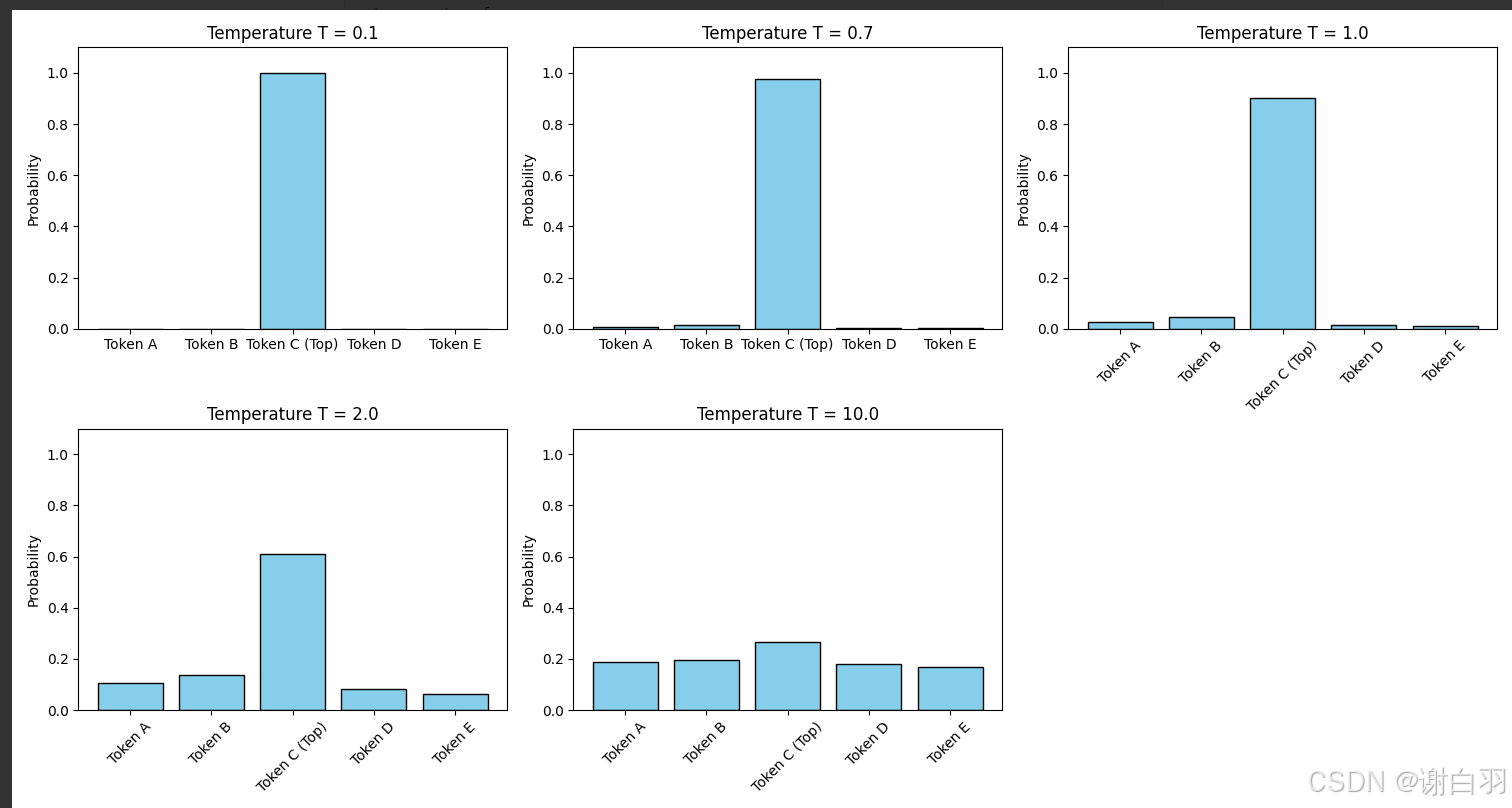
- op-p(nucleus sampling,p=0.95):与温度协同作用,仅保留累计概率达到或超过 p 值的最小词元集合。该策略在维持生成多样性的同时,有效排除低概率、语义不合理词元被选中的可能性,从而避免生成内容偏离逻辑或语义连贯性。
- llm = LLM(model=“Qwen2.5-1.5B-Instruct”) 会自动从 Hugging Face 模型仓库下载对应权重。如果网络问题的话可以考虑代理,或者先下载到某个文件夹再将文件夹的路径传入到model="xxx-dir"中。下载完成后,模型权重将被加载至 GPU 显存中。
模型显存占用约为 3 GB,计算依据为:1.5B 参数 × 2 字节(FP16 精度)。此外,还需额外预留显存空间用于存储 KV Cache(键值缓存),KV Cache的作用在于Transformer 自注意力计算时避免对历史 token 的键值对重复计算,从而提升推理效率。模型显存占用约为 3 GB,计算依据为:1.5B 参数 × 2 字节(FP16 精度)。此外,还需额外预留显存空间用于存储 KV Cache(键值缓存),KV Cache的作用在于Transformer 自注意力计算时避免对历史 token 的键值对重复计算,从而提升推理效率。
- 调试的launch.json配置
python配置填写对应启动文件路径
“python”: “${workspaceFolder}/code/demo.py”,
{
"version": "0.2.0",
"configurations": [
{
"name": "vLLM: API Server Debug",
"type": "debugpy",
"request": "launch",
"module": "vllm.entrypoints.openai.api_server",
"args": [
"--model",
"Qwen/Qwen3-1.7B",
"--dtype",
"float16",
"--max-model-len",
"4096",
"--gpu-memory-utilization",
"0.95",
"--max-num-batched-tokens",
"8192",
"--max-num-seqs",
"256",
"--port",
"13333",
"--tensor-parallel-size",
"2",
"--pipeline-parallel-size",
"1",
"--enforce-eager"
],
"env": {
// 可选:设置 CUDA_VISIBLE_DEVICES 控制 GPU 使用
// "CUDA_VISIBLE_DEVICES": "0,1",
// 开启 vLLM 调试日志
"VLLM_LOGGING_LEVEL": "DEBUG",
"PYTHONPATH": "${workspaceFolder}:${env:PYTHONPATH}"
},
"python": "${workspaceFolder}/code/demo.py",
"console": "integratedTerminal",
"justMyCode": false,
"cwd": "${workspaceFolder}",
"stopOnEntry": false
}
]
}
1.1 vLLM离线部署qwen
-
两个进程分别在做什么
- 进程 0(收发用户输入的LLMEngine进程):用LLMEngine负责接收用户输入的文本提示(prompts),执行分词处理,并用类内变量EngineCoreClient将请求打包后通过 ZeroMQ(ZMQ)套接字通信机制发送至推理进程,在随后还需要接收结果。
- 进程 1(模型推理执行的EngineCore进程):通过 ZMQ 接收来自 LLMEngine 的请求,将其存入 EngineCore 的输入队列;调度器按既定策略取出请求并调度 GPU 执行推理(具体推理计算的过程还会委托给其他组件),计算结果写入 EngineCore 的输出队列,再经 ZMQ 回传至进程 0,最终将请求的推理结果返回给用户。具体如图中所示。
-
下载模型
from modelscope.hub.snapshot_download import snapshot_download
# 下载 Qwen3-1.7B 到指定目录(移除无效参数)
model_dir = snapshot_download(
model_id="qwen/Qwen3-1.7B", # ModelScope 上的模型ID
local_dir="/home/lixiang/models/Qwen3-1.7B" # 本地保存路径
)
print(f"模型已下载到:{model_dir}")
- 离线推理
import os
os.environ["VLLM_USE_V1"] = "1" # 必须在 import vllm 之前!
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from vllm import LLM, SamplingParams
# 核心修复:把主逻辑包裹在 if __name__ == '__main__' 里
if __name__ == '__main__':
prompts = [
"Hello, my name is",
"The president of the United States is",
"Write a poem about China:",
"Who won the world series in 2020?",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=50) # 限制生成长度,减少CPU压力
# 加载本地模型(CPU模式)
llm = LLM(
model="/home/lixiang/models/Qwen3-1.7B",
enforce_eager=True
)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")

离线推理的典型特征:
- 输入 prompt 集合已知、固定,无需动态请求;
- 对单请求延迟不敏感,核心指标为吞吐率(throughput)。
在 GPU 显存允许范围内,推理系统需要最大化批处理规模,填满请求队列直至达到显存或序列长度上限
我们知道大模型推理由 Prefill 和 Decode 两个阶段组成,因此重点关注以下指标:
- TTFT(Time to First Token,首 Token 延迟):
从请求提交到返回第一个输出 token 的端到端延迟。主要由 Prefill 阶段耗时 构成,主要是完整 prompt 的处理时间。 - TPOT(每输出 Token 延迟,不含首 Token)
在 Decode 阶段中,每个后续 token 的平均生成延迟,TPOT反映自回归生成的持续性能,受 KV Cache 访问效率和显存带宽影响显著。 - 吞吐速率(Throughput):单位时间生成的 token 数(tokens/秒)
1.2 vLLM在线部署qwen
- vLLM 展现出显著优势:
- 提供流式输出(streaming)和请求中断/取消(abort/cancel)能力,满足真实用户交互中的灵活性需求;
- 结合 AsyncLLMEngine 与内置的 OpenAI 兼容 API 服务器,可轻松集成至微服务架构,支持优先级调度、超时控制、健康检查等工业级特性;
-
需求
搭建一个与 OpenAI API 接口完全兼容的在线推理服务。所使用的模型为 Qwen3/qwen-1.7b,与前文离线推理部分保持一致,便于对比两种模式的差异与集成方式。 -
服务器
http_proxy= https_proxy= no_proxy=* python3 -m vllm.entrypoints.openai.api_server \
--model "Qwen/Qwen3-1.7B" \
--dtype float16 \
--max-model-len 4096 \
--gpu-memory-utilization 0.95 \
--max-num-batched-tokens 8192 \
--max-num-seqs 256 \
--port "13311" \
环境与启动方式
http_proxy= https_proxy=
把这两个环境变量设成空,等价于关闭 HTTP/HTTPS 代理,避免本机或环境里配置的代理把本地请求(或 Hugging Face 等)导到错误出口。
no_proxy=*
表示“所有主机都不走代理”。通常与上面一起用,确保直连或本地流量不被代理拦截。(具体行为取决于你系统里 no_proxy 的解析方式,常见意图是尽量不走代理。)
python3 -m vllm.entrypoints.openai.api_server
用 vLLM 自带的 OpenAI 风格 HTTP API 入口(兼容 /v1/chat/completions 等)启动服务。
- vLLM 参数
--model "Qwen/Qwen3-1.7B"
要加载的模型标识(Hugging Face Hub 上的模型名或本地路径)。这里是 Qwen3 1.7B 权重。
--dtype float16
权重与部分计算使用 FP16,在多数 GPU 上比 FP32 省显存、更快;精度略低于 FP32,一般对话场景可接受。
--max-model-len 4096
单条请求上下文的最大长度(含输入 + 已生成 token),上限为 4096。更长会被截断或报错,取决于客户端与 vLLM 行为。
--gpu-memory-utilization 0.95
vLLM 会尝试使用 约 95% 的 GPU 显存 做 KV cache 等,提高并发与吞吐;留 5% 给驱动/碎片等,避免 OOM。机器上若还有别的进程占显存,需要调低。
--max-num-batched-tokens 8192
调度器一步里一批 token 的上限(batch 内 token 总数)。越大吞吐潜力越高,但显存与延迟压力也越大;需与 max-model-len、显存、并发一起权衡。
--max-num-seqs 256
同时处理的序列(请求)数量上限(并发序列数)。越大并发能力越强,同样更吃显存与 KV cache。
--port "13311"
HTTP 服务监听端口,客户端应连 http://<主机>:13311(与 OpenAI 客户端里 base_url 一致)。
小结:脚本在无代理环境下启动 Qwen3-1.7B,用 FP16、最大上下文 4096,并尽量用满 GPU(95%)、限制 batch 8192 token、最多 256 路并发,在 13311 端口提供 OpenAI 兼容 API。若出现 OOM,通常先降 --gpu-memory-utilization、--max-num-seqs 或 --max-num-batched-tokens。
+ 客户端


#!/usr/bin/env bash
# 1. 查看可用模型
curl -s --noproxy '*' http://127.0.0.1:13311/v1/models | jq .
# 2. 走 chat/completions 生成文本
curl -s --noproxy '*' http://127.0.0.1:13311/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-1.7B",
"messages": [{"role": "user", "content": "用20字介绍vLLM"}],
"max_tokens": 30,
"temperature": 0.6
}' | jq -r '.choices[0].message.content'
第 1 段:/v1/models
curl
发 HTTP 请求。
-s(silent)
不显示进度条和错误时的多余信息,只输出响应体,方便管道给 jq。
--noproxy '*'
所有主机都不走代理,避免系统代理把 127.0.0.1 请求拐走。
http://127.0.0.1:13311/v1/models
OpenAI 兼容接口里「列出当前服务提供的模型」;需与 server.sh 里 --port 13311 一致。
| jq .
把 JSON 格式化打印,便于阅读。
第 2 段:/v1/chat/completions
-H "Content-Type: application/json"
声明请求体是 JSON,服务端按 JSON 解析。
-d '{ ... }'
POST 的请求体(JSON 字符串)。
请求体字段含义:
字段 含义
model 要用的模型名,须与 vLLM 启动时 --model 及 /v1/models 里一致(这里是 Qwen/Qwen3-1.7B)。
messages 对话历史;数组里每条有 role(如 user)和 content(文本)。这里只有一条用户消息。
max_tokens 本次生成最多再生成多少个 token(不含你输入的 prompt 长度),上限受服务端 max-model-len 等约束。
temperature 采样温度:越高越随机、越有创造性;越低越接近贪心/确定性。0.6 是中等偏稳。
| jq -r '.choices[0].message.content'
从返回 JSON 里取出第一条回复的正文:
-r 表示原始字符串(不转义成带引号的 JSON 字符串),只打印助手回复内容。
1.3 测试在线服务性能
- 测试脚本
#!/usr/bin/env bash
# 临时取消所有代理,运行 benchmark
no_proxy="*" HTTP_PROXY="" HTTPS_PROXY="" http_proxy="" https_proxy="" \
vllm bench serve \
--model Qwen/Qwen3-1.7B \
--host 127.0.0.1 \
--random-input-len 128 \
--port 13312 \
--request-rate 10 \
--num-prompts 100 \
--save-result \
--result-dir ./bench_results \
--label "qwen3-1.7b-test"
环境与命令前缀
no_proxy="*"
所有地址不走代理,避免本机或环境里的代理影响连 127.0.0.1。
HTTP_PROXY="" HTTPS_PROXY="" http_proxy="" https_proxy=""
把常见代理环境变量清空,等价于本次命令不经过 HTTP/HTTPS 代理,和 client.sh 里关代理的目的一致:测本地/直连更稳定、可复现。
vllm bench serve
vLLM 自带的压测子命令:作为客户端向已在运行的 OpenAI 兼容 API 服务发请求并统计吞吐、延迟等(具体行为以你安装的 vLLM 版本 --help 为准)。
vllm bench serve 参数
参数 含义
--model Qwen/Qwen3-1.7B 压测时声明的模型名,需与服务端实际加载的模型一致(请求里会带这个 model)。
--host 127.0.0.1 API 服务所在主机,这里为本机回环。
--port 13312 API 服务的监听端口。压测客户端会连 http://127.0.0.1:13312/...。若你的 server.sh 用的是 13311,需要两边端口一致,否则连错服务。
--random-input-len 128 每条请求的输入长度按随机方式生成,约为 128 个 token(用于模拟不同 prompt 长度;具体随机分布以 vLLM 实现为准)。
--request-rate 10 请求速率,通常为每秒大约 10 个请求(恒定或平均速率,视实现为 Poisson/固定间隔等)。
--num-prompts 100 一共发 100 条 prompt/请求,压测结束后汇总指标。
--save-result 把结果写入文件(与 --result-dir 配合)。
--result-dir ./bench_results 结果保存目录,一般为 ./bench_results。
--label "qwen3-1.7b-test" 给这次跑分一个标签,便于在结果文件或报告里区分不同实验。
小结:脚本在无代理下对 127.0.0.1:13312 上的 vLLM 服务做压测:随机约 128 token 输入、约 10 req/s、共 100 条,并把结果存到 ./bench_results,标签为 qwen3-1.7b-test。使用前请先在同一端口启动与 Qwen/Qwen3-1.7B 一致的 API 服务;若服务只在 13311,把 --port 改成 13311 或改服务端端口即可。
1.4 测试离线服务性能(RTX5060 8G)
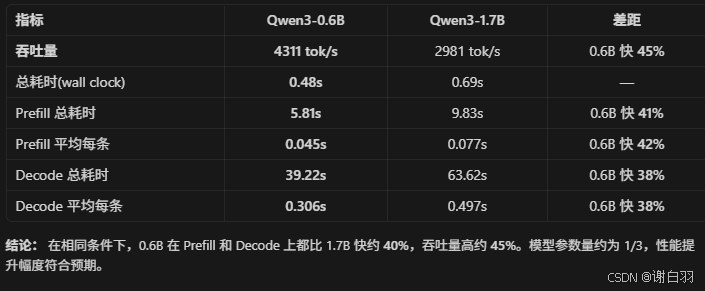
测了128条,每条prompt一样
prompts = ["The future of AI is"] * 128
不过这 128 条 prompt 完全一样,所以 Prefix Cache 会命中,后续请求的 Prefill 几乎是白送的,数据会偏好看。如果想测更真实的场景,应该用不同的 prompt。
- 测试代码
import os
import sys
import time
os.environ["VLLM_USE_V1"] = "1"
os.environ["HF_HUB_OFFLINE"] = "1"
from vllm import LLM, SamplingParams
from vllm.v1.metrics.reader import Counter, Gauge, Histogram
prompts = ["The future of AI is"] * 128
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
CONFIGS = [
{"model": "Qwen/Qwen3-0.6B", "enforce_eager": False},
{"model": "Qwen/Qwen3-1.7B", "enforce_eager": False},
]
if __name__ == "__main__":
config_idx = int(sys.argv[1])
cfg = CONFIGS[config_idx]
llm = LLM(
model=cfg["model"],
max_model_len=4096,
max_num_seqs=128,
gpu_memory_utilization=0.8,
disable_log_stats=False,
enforce_eager=cfg["enforce_eager"],
)
t0 = time.perf_counter()
outputs = llm.generate(prompts, sampling_params)
t1 = time.perf_counter()
new_tokens = sum(len(out.outputs[0].token_ids) for out in outputs)
elapsed = t1 - t0
throughput = new_tokens / elapsed
prefill_sum = prefill_count = 0
decode_sum = decode_count = 0
for metric in llm.get_metrics():
if isinstance(metric, Histogram):
if metric.name == "vllm:request_prefill_time_seconds":
prefill_sum = metric.sum
prefill_count = metric.count
elif metric.name == "vllm:request_decode_time_seconds":
decode_sum = metric.sum
decode_count = metric.count
print(f"\n{'='*60}")
print(f"Model: {cfg['model']}")
print(f"enforce_eager: {cfg['enforce_eager']}")
print(f"总耗时(wall clock): {elapsed:.2f}s")
print(f"输出 tokens: {new_tokens}")
print(f"吞吐量: {throughput:.2f} tok/s")
print(f"Prefill 总耗时: {prefill_sum:.2f}s ({prefill_count} 条请求)")
print(f"Prefill 平均每条: {prefill_sum/prefill_count:.3f}s")
print(f"Decode 总耗时: {decode_sum:.2f}s ({decode_count} 条请求)")
print(f"Decode 平均每条: {decode_sum/decode_count:.3f}s")
print(f"{'='*60}\n")
二、让vllm支持一个新的模型
我们的模型是一个示例模型,结构为单层 MLP,所有相关文件位于 code/course6 目录下。简单介绍配置中的关键参数:“architectures” 字段即为上文中三元组的 key,用于唯一标识该模型类型;此外还包含模型所需的其他配置参数,特别是针对 MLP 层的设置。由于该模型仅由一个单一的 MLP 层构成,因此整体结构简单,无需处理多层或复杂模块间的连接逻辑。
1)配置模型配置和模型加载
- 模型配置
{
"architectures": [
"MLPModel"
],
"dtype": "float32",
"hidden_dim": 256,
"input_dim": 128,
"model_type": "llama",
"output_dim": 10,
"pad_token_id": -1,
"transformers_version": "4.56.1",
"vocab_size": 1024
}
我们的模型是一个示例模型,结构为单层 MLP,所有相关文件位于 code/course6 目录下。简单介绍配置中的关键参数:“architectures” 字段即为上文中三元组的 key,用于唯一标识该模型类型;此外还包含模型所需的其他配置参数,特别是针对 MLP 层的设置。由于该模型仅由一个单一的 MLP 层构成,因此整体结构简单,无需处理多层或复杂模块间的连接逻辑。
模型的定义如下, 它由两个Linear层和一个激活算子ReLU组成,分别是self.fc1和self.fc2和self.relu。
- 模型加载
随后需要将模型以 Hugging Face 格式进行导出,原因在于 vLLM 原生支持 Hugging Face 的模型格式,后续我们也会对 vLLM 加载该格式中模型权重的流程进行详细分析。导出代码主要分为三部分:
- 模型配置(config)的实例化,用于定义模型的基本参数和结构信息;
- 模型实例的创建,并调用 save_pretrained 方法将其保存为 Hugging Face 格式;
- 词表文件的导出,尽管在当前示例中我们仅用于演示,并不会实际使用该词表进行分词操作,但仍需一并导出以符合 Hugging Face 模型的标准目录结构。
config = MLPConfig(input_dim=128, hidden_dim=256, output_dim=10)
model = MLPModel(config)
2)模型导出(其实就是导出脚本里面自己写个模型配置和模型类,然后导出safetensors)
- 模型导出
# 保存为 Hugging Face 格式
model.save_pretrained("/home/test_fss/code/vllm_learn/code/course6/mlp_model")
from transformers import AutoTokenizer
# 用个最小的 tokenizer 占位
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.save_pretrained("/home/test_fss/code/vllm_learn/code/course6/mlp_model")
Hugging Face 格式的模型导出后,还需要在 vLLM 端添加对应的模型定义,请见vllm/model_executor/models/mlp.py。
- 在该文件中,需要构建一个 MLP 模型,其内部的算子和计算流程必须与导出时保持一致,即包含两个线性层(Linear)和一个 ReLU 激活函数。
- 值得一提的是,这里的词表实际对应模型中的 self.embed_tokens 模块,其作用是将输入的 token_ids 映射到连续的向量空间,作为模型的输入表示。
- 目前,我们已经定义好了具体的模型模块 models/mlp.py 以及其中的类 MLPModel,接下来需要将其注册到全局的 ModelRegistry 中,以便在模型加载时能够根据架构名称正确查找并实例化该模型。
class MLPConfig(PretrainedConfig):
model_type = "llama" # 自定义类型,vLLM 不支持也无所谓
def __init__(self, input_dim=128, hidden_dim=256, output_dim=10, **kwargs):
super().__init__(**kwargs)
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.output_dim = output_dim
self.vocab_size = 1024
self.pad_token_id = -1
from transformers import PreTrainedModel
import torch.nn as nn
class MLPModel(PreTrainedModel):
config_class = MLPConfig
def __init__(self, config):
super().__init__(config)
self.embed_tokens = nn.Embedding(
config.vocab_size,
config.input_dim,
padding_idx=config.pad_token_id,
)
self.fc1 = nn.Linear(config.input_dim, config.hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(config.hidden_dim, config.output_dim)
def forward(self, x):
x = self.fc1(self.embed_tokens(x))
x = self.relu(x)
return self.fc2(x)
3)vllm注册模型和自定义模型权重加载函数
具体的注册方法如下:
_TEXT_GENERATION_MODELS = {
"MLPForCausalLM": ("mlp", "MLPForCausalLM"),
model_executor/models/mlp.py中应该新添加如下的定义,其中class MLPForCausalLM(nn.Module)是具体是这个类的封装,我们在下文中将配合模型权重的加载去讲解。
class MLPForCausalLM(nn.Module):
pass
class MLPModel(nn.Module):
def __init__(self, *, vllm_config: VllmConfig, prefix: str = ""):
super().__init__()
cfg = vllm_config.model_config.hf_config
quant_config = vllm_config.quant_config
"""
self.fc1 = nn.Linear(config.input_dim, config.hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(config.hidden_dim, config.output_dim)
"""
self.embed_tokens = VocabParallelEmbedding(
cfg.vocab_size,
cfg.input_dim,
quant_config=vllm_config.quant_config,
)
self.fc1 = RowParallelLinear(
cfg.input_dim, cfg.hidden_dim, bias=True, quant_config=quant_config
)
self.act = nn.ReLU()
self.fc2 = RowParallelLinear(
cfg.hidden_dim, cfg.output_dim, bias=True, quant_config=quant_config
)
def forward(
self,
input_ids: torch.Tensor,
positions: torch.Tensor,
intermediate_tensors: Optional[IntermediateTensors] = None,
inputs_embeds: Optional[torch.Tensor] = None,
) -> Union[torch.Tensor, IntermediateTensors]:
x = self.embed_tokens(input_ids)
x, _ = self.fc1(x)
x = self.act(x)
x, _ = self.fc2(x)
return x

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)