YOLOV1、YOLOV2网络架构与代码解析
文章目录
一、YOLOV1 网络架构
YOLOv1是2016年提出的单阶段(One-Stage)端到端目标检测算法,首次将目标检测完全转化为回归问题,实现了实时级的检测速度,是YOLO系列的开山之作。
图 YOLOV1网络架构图
1. 网络架构图
YOLOv1的网络结构基于简化的GoogleNet设计,整体分为特征提取骨干网络、检测头两部分,完整结构对应下图的层级,核心流程如下:
1. 输入层
输入固定为448×448×3的RGB图像,通过固定输入尺寸适配后续的全连接层,保证网络前向传播的维度一致性。
2. 特征提取骨干网络
骨干网络由24个卷积层+4个最大池化层组成,核心用1×1卷积降维+3×3卷积提取特征的组合替代GoogleNet的Inception模块,简化结构的同时保证特征提取能力,核心层级如下:
- 第1组:7×7/64卷积(步长2)+ 2×2最大池化(步长2),输入448×448×3,输出112×112×64
- 第2组:3×3/192卷积 + 2×2最大池化(步长2),输出56×56×192
- 第3组:连续2组
1×1卷积+3×3卷积+ 2×2最大池化(步长2),输出28×28×512 - 第4组:4组重复的
1×1/256卷积+3×3/512卷积,输出28×28×512 - 第5组:
1×1/512卷积+3×3/1024卷积+ 2×2最大池化(步长2),输出14×14×1024 - 第6组:2组重复的
1×1/512卷积+3×3/1024卷积,再经过2个3×3/1024卷积(其中1个步长为2),最终输出7×7×1024的特征图。
3. 检测头(输出层)
检测头由2个全连接层组成,完成从特征到检测结果的映射:
7. 第一个全连接层:将7×7×1024的特征展平,映射为4096维的特征向量
8. 第二个全连接层:将4096维向量映射为最终的7×7×30输出张量,对应检测结果的编码。
- 7×7×1024的特征,展平后维度确实不等于4096:展平操作就是把空间维度(7×7)和通道维度(1024)完全拉直,排成一个一维的长向量,元素总数不变:
7×7×1024 = 50176,最终得到一个长度为50176的一维特征向量。就是通过一个可学习的权重矩阵,实现两个固定维度向量之间的线性变换,输入和输出的维度不需要相等。对应到这个场景,全连接层的配置是:-输入维度:50176(展平后的特征长度- 输出维度:4096(我们想要得到的特征向量长度)
7×7×1024 = 50176,展平只是把三维张量拉成一维向量,元素总数不变,展平后是一个长度为50176的一维向量。 - 从50176维到4096维,不是靠展平实现的,而是靠**全连接层(Linear Layer,也叫线性层/稠密层)**完成的映射,这个过程是带可学习参数的线性变换,不是简单的维度重塑。
4. 输出张量的核心含义
YOLOv1将输入图像划分为7×7的网格,每个网格负责预测中心落在该网格内的目标,7×7×30的输出对应每个网格的预测内容:
- 每个网格预测2个边界框,每个边界框包含5个参数:
x,y(框中心相对于网格的偏移量)、w,h(框宽高相对于整图的比例)、confidence(置信度,= 框包含目标的概率 × 预测框与真实框的IoU) - 每个网格预测20个类别概率(对应PASCAL VOC数据集的20个类别),即目标存在时的类别条件概率
- 最终维度:7×7 × (2×5 + 20) = 7×7×30,与网络输出一致。
2、网络架构的核心特点
- 端到端的单阶段检测,速度极快
摒弃了两阶段算法“候选区域生成+分类回归”的两步流程,一次前向传播即可完成所有目标的位置、类别预测,基础版在GPU上可达45FPS,快速版可达155FPS,首次实现了真正的实时目标检测。 - 全局上下文推理,背景误检率低
训练和推理时均对整幅图像进行处理,能捕捉目标的全局上下文信息,相比仅关注局部区域的两阶段算法,大幅减少了将背景误判为目标的情况。 - 泛化能力强,跨域适配性好
网络学习到的目标特征更通用,在自然图像上完成训练后,迁移到艺术作品、遥感图像等其他域的检测任务时,泛化效果显著优于同期的R-CNN、DPM算法。 - 结构简洁,易实现与部署
骨干网络仅用基础的卷积、池化层,无复杂的模块设计,代码实现和工程部署的门槛极低,为后续YOLO系列的迭代奠定了基础。
3、损失函数:公式与组成解析
YOLOv1的损失函数以和方差 Sum of Squared Error, SSE为基础,将定位损失、置信度损失、分类损失整合为一个统一的损失函数,实现端到端的优化。
1. 损失函数完整公式
L = λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( x i − x ^ i ) 2 + ( y i − y ^ i ) 2 ] + λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( w i − w ^ i ) 2 + ( h i − h ^ i ) 2 ] + ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j ( C i − C ^ i ) 2 + λ n o o b j ∑ i = 0 S 2 ∑ j = 0 B 1 i j n o o b j ( C i − C ^ i ) 2 + ∑ i = 0 S 2 1 i o b j ∑ c ∈ c l a s s e s ( p i ( c ) − p ^ i ( c ) ) 2 \begin{aligned} \mathcal{L} &= \lambda_{coord} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{obj} \left[ (x_i - \hat{x}_i)^2 + (y_i - \hat{y}_i)^2 \right] \\ &+ \lambda_{coord} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{obj} \left[ (\sqrt{w_i} - \sqrt{\hat{w}_i})^2 + (\sqrt{h_i} - \sqrt{\hat{h}_i})^2 \right] \\ &+ \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{obj} \left( C_i - \hat{C}_i \right)^2 \\ &+ \lambda_{noobj} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{noobj} \left( C_i - \hat{C}_i \right)^2 \\ &+ \sum_{i=0}^{S^2} \mathbb{1}_{i}^{obj} \sum_{c \in classes} \left( p_i(c) - \hat{p}_i(c) \right)^2 \end{aligned} L=λcoordi=0∑S2j=0∑B1ijobj[(xi−x^i)2+(yi−y^i)2]+λcoordi=0∑S2j=0∑B1ijobj[(wi−w^i)2+(hi−h^i)2]+i=0∑S2j=0∑B1ijobj(Ci−C^i)2+λnoobji=0∑S2j=0∑B1ijnoobj(Ci−C^i)2+i=0∑S21iobjc∈classes∑(pi(c)−p^i(c))2
2. 核心符号说明
| 符号 | 含义说明 |
|---|---|
| S = 7 S=7 S=7 | 网格的行列数,对应7×7的网格划分 |
| B = 2 B=2 B=2 | 每个网格预测的边界框数量 |
| 1 i o b j \mathbb{1}_{i}^{obj} 1iobj | 指示函数,第 i i i个网格存在目标中心时为1,否则为0 |
| 1 i j o b j \mathbb{1}_{ij}^{obj} 1ijobj | 指示函数,第 i i i个网格的第 j j j个框负责预测目标时为1,否则为0(负责:该框与真实框的IoU为同网格2个框中更大的那个) |
| 1 i j n o o b j \mathbb{1}_{ij}^{noobj} 1ijnoobj | 指示函数,第 i i i个网格的第 j j j个框不负责预测目标时为1,否则为0 |
| λ c o o r d = 5 \lambda_{coord}=5 λcoord=5 | 坐标损失的权重系数,放大定位损失的重要性 |
| λ n o o b j = 0.5 \lambda_{noobj}=0.5 λnoobj=0.5 | 无目标置信度损失的权重系数,降低负样本损失的主导性 |
| x , y , w , h x,y,w,h x,y,w,h | 真实框的坐标与宽高; x ^ , y ^ , w ^ , h ^ \hat{x},\hat{y},\hat{w},\hat{h} x^,y^,w^,h^ |
| C i C_i Ci | 真实置信度(有目标时为1,无目标时为0); C ^ i \hat{C}_i C^i |
| p i ( c ) p_i(c) pi(c) | 真实类别概率; p ^ i ( c ) \hat{p}_i(c) p^i(c) |
3. 损失函数的5个组成部分
- 边界框中心坐标损失(公式第1行)
仅对负责预测目标的边界框计算坐标的均方误差,通过 λ c o o r d = 5 \lambda_{coord}=5 λcoord=5放大权重,优先保证定位的准确性。 - 边界框宽高损失(公式第2行)
对宽高先开根号再计算均方误差,缓解“相同宽高误差对小目标的影响远大于大目标”的问题,提升小目标的定位精度,同样仅对正样本框计算,乘以 λ c o o r d = 5 \lambda_{coord}=5 λcoord=5。 - 有目标的置信度损失(公式第3行)
对负责预测目标的边界框,计算置信度的均方误差,让网络学习到预测框与真实框的匹配程度。 - 无目标的置信度损失(公式第4行)
对不负责预测目标的边界框计算置信度损失,通过 λ n o o b j = 0.5 \lambda_{noobj}=0.5 λnoobj=0.5降低权重,避免大量无目标的负样本损失主导整个训练过程。 - 分类损失(公式第5行)
对包含目标的网格,计算类别概率的均方误差,每个网格仅预测一组类别概率,与该网格内的预测框数量无关。
4、YOLOv1的核心缺陷
- 密集目标、小目标检测能力弱
每个网格只能预测2个边界框,且只能归属同一个类别。当一个网格内存在多个密集小目标(如密集人群、小尺寸物体)时,网络最多只能检测出1个目标,极易出现漏检;同时7×7的网格划分较为粗糙,对小目标的特征捕捉能力不足。 - 定位精度不足,对特殊长宽比目标适配差
没有两阶段算法的候选框微调过程,直接回归边界框坐标,对长宽比特殊、尺度差异大的目标,定位误差显著高于同期的Faster R-CNN;同时训练时仅让IoU更大的1个框负责预测目标,正样本数量少,定位学习不充分。 - 损失函数的设计存在天然缺陷
均方误差损失对大目标和小目标的误差惩罚不均衡:大目标的微小宽高误差,和小目标的大幅宽高误差,可能产生相近的损失值,即使宽高开根号也无法完全解决该问题;同时定位损失和分类损失的权重平衡仅靠固定系数,无法适配不同训练阶段的需求。 - 多尺度适应能力差,输入要求严格
网络末尾使用全连接层,要求输入图像必须固定为448×448,对不同尺寸的图像只能强制缩放,会导致目标形变,大幅影响检测精度,无法适配多尺度的检测场景。 - 遮挡、重叠目标的检测效果差
当多个目标重叠严重、目标被遮挡,导致多个目标的中心落在同一个网格时,网络无法区分多个目标,极易出现漏检和误检。
5、核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class ConvBlock(nn.Module):
"""
YOLOv1 基础卷积块
结构: Conv2d -> BatchNorm (可选,论文中无) -> LeakyReLU -> MaxPool (可选)
注意: 为了代码简洁,这里严格按照论文,不使用 BatchNorm
"""
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, use_maxpool=False):
super().__init__()
# 定义卷积层
self.conv = nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
bias=False
)
# 论文中使用 LeakyReLU,负轴斜率 alpha=0.1
self.act = nn.LeakyReLU(0.1, inplace=True)
# 是否使用最大池化下采样
self.use_maxpool = use_maxpool
if use_maxpool:
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
def forward(self, x):
"""
参数 x: 输入特征图
返回: 输出特征图
"""
x = self.conv(x)
x = self.act(x)
if self.use_maxpool:
x = self.pool(x)
return x
class YOLOv1(nn.Module):
"""
原始 YOLOv1 模型定义 (You Only Look Once)
论文链接: https://arxiv.org/abs/1506.02640
"""
def __init__(self, num_classes=20, num_bboxes=2, grid_size=7):
"""
初始化参数:
num_classes: 检测类别数量 (默认 PASCAL VOC 20类)
num_bboxes: 每个网格预测的边界框数量 (默认 2)
grid_size: 网格划分大小 S x S (默认 7)
"""
super().__init__()
# 保存超参数
self.S = grid_size # 7
self.B = num_bboxes # 2
self.C = num_classes # 20
# =====================================================================
# 1. 骨干网络 (Backbone)
# =====================================================================
# 作用: 特征提取,将原始像素转化为高级语义特征
# 参考论文 Figure 3: The architecture
self.backbone = nn.Sequential(
# --- Layer 1 ---
# 输入: [Batch, 3, 448, 448]
ConvBlock(3, 64, kernel_size=7, stride=2, padding=3, use_maxpool=True),
# 输出: [Batch, 64, 112, 112] -> 池化后 -> [Batch, 64, 56, 56]
# --- Layer 2 ---
ConvBlock(64, 192, kernel_size=3, padding=1, use_maxpool=True),
# 输出: [Batch, 192, 56, 56] -> 池化后 -> [Batch, 192, 28, 28]
# --- Layer 3 ---
ConvBlock(192, 128, kernel_size=1), # 1x1 降维
ConvBlock(128, 256, kernel_size=3, padding=1), # 3x3 提特征
ConvBlock(256, 256, kernel_size=1), # 1x1
ConvBlock(256, 512, kernel_size=3, padding=1, use_maxpool=True), # 3x3
# 池化后: [Batch, 512, 14, 14]
# --- Layer 4 (重复 4 次 1x1 -> 3x3) ---
ConvBlock(512, 256, kernel_size=1),
ConvBlock(256, 512, kernel_size=3, padding=1),
ConvBlock(512, 256, kernel_size=1),
ConvBlock(256, 512, kernel_size=3, padding=1),
ConvBlock(512, 256, kernel_size=1),
ConvBlock(256, 512, kernel_size=3, padding=1),
ConvBlock(512, 256, kernel_size=1),
ConvBlock(256, 512, kernel_size=3, padding=1),
# --- Layer 5 ---
ConvBlock(512, 512, kernel_size=1),
ConvBlock(512, 1024, kernel_size=3, padding=1, use_maxpool=True),
# 池化后: [Batch, 1024, 7, 7]
# --- Layer 6 ---
ConvBlock(1024, 512, kernel_size=1),
ConvBlock(512, 1024, kernel_size=3, padding=1),
ConvBlock(1024, 512, kernel_size=1),
ConvBlock(512, 1024, kernel_size=3, padding=1),
ConvBlock(1024, 1024, kernel_size=3, padding=1),
ConvBlock(1024, 1024, kernel_size=3, stride=2, padding=1), # 注意:步长为2
# 输出: [Batch, 1024, 7, 7] (这一层虽然stride=2,但由于padding,尺寸保持7x7)
# --- Layer 7 ---
ConvBlock(1024, 1024, kernel_size=3, padding=1),
ConvBlock(1024, 1024, kernel_size=3, padding=1),
# 最终特征图输出: [Batch, 1024, 7, 7]
)
# =====================================================================
# 2. 检测头 (Head / Classifier)
# =====================================================================
# 作用: 将卷积特征映射为最终的检测结果
self.head = nn.Sequential(
# 注意: Flatten 操作在 forward 中显式做,这里只放线性层
# 第1个全连接层: 7*7*1024 -> 4096
nn.Linear(1024 * 7 * 7, 4096),
nn.LeakyReLU(0.1, inplace=True),
nn.Dropout(0.5), # 论文中使用 Dropout 防止过拟合
# 第2个全连接层: 4096 -> S*S*(B*5 + C)
# 计算: 7 * 7 * (2*5 + 20) = 7 * 7 * 30 = 1470
nn.Linear(4096, self.S * self.S * (self.B * 5 + self.C))
)
def forward(self, x):
"""
前向传播逻辑
输入:
x: [BatchSize, 3, 448, 448] - 输入的批量图像
输出:
prediction: [BatchSize, S, S, B*5 + C] - 检测结果
"""
# 1. 通过骨干卷积网络
# 维度变化: [B, 3, 448, 448] -> [B, 1024, 7, 7]
x = self.backbone(x)
# 2. 展平特征图 (Flatten)
# 将 3D 特征图拉成 1D 向量
# 维度变化: [B, 1024, 7, 7] -> [B, 1024*7*7] = [B, 50176]
x = x.flatten(start_dim=1)
# 3. 通过全连接层
# 维度变化: [B, 50176] -> [B, 1470]
x = self.head(x)
# 4. 重塑为最终的检测格式
# 将一维向量重塑为空间网格结构,方便后续计算损失
# 维度变化: [B, 1470] -> [B, 7, 7, 30]
prediction = x.view(-1, self.S, self.S, self.B * 5 + self.C)
return prediction
# ========================================================================== #
# YOLOv1 损失函数 #
# 严格按照论文: https://arxiv.org/abs/1506.02640 公式 3 #
# ========================================================================== #
def compute_iou(boxes1, boxes2):
"""
计算两组边界框的 IoU (Intersection over Union)
注意: 为了数值稳定性,所有计算都在归一化坐标 [0, 1] 下进行
参数:
boxes1: 预测框 [..., 4] -> (x_center, y_center, w, h)
boxes2: 真实框 [..., 4] -> (x_center, y_center, w, h)
返回:
iou: [..., 1]
"""
# 1. 将 (center, w, h) 转换为 (x1, y1, x2, y2) 即左上角和右下角
# 预测框
b1_x1 = boxes1[..., 0:1] - boxes1[..., 2:3] / 2
b1_y1 = boxes1[..., 1:2] - boxes1[..., 3:4] / 2
b1_x2 = boxes1[..., 0:1] + boxes1[..., 2:3] / 2
b1_y2 = boxes1[..., 1:2] + boxes1[..., 3:4] / 2
# 真实框
b2_x1 = boxes2[..., 0:1] - boxes2[..., 2:3] / 2
b2_y1 = boxes2[..., 1:2] - boxes2[..., 3:4] / 2
b2_x2 = boxes2[..., 0:1] + boxes2[..., 2:3] / 2
b2_y2 = boxes2[..., 1:2] + boxes2[..., 3:4] / 2
# 2. 计算交集 (Intersection) 的坐标
inter_x1 = torch.max(b1_x1, b2_x1)
inter_y1 = torch.max(b1_y1, b2_y1)
inter_x2 = torch.min(b1_x2, b2_x2)
inter_y2 = torch.min(b1_y2, b2_y2)
# 3. 计算交集面积 (注意防止宽高为负)
inter_w = torch.clamp(inter_x2 - inter_x1, min=0)
inter_h = torch.clamp(inter_y2 - inter_y1, min=0)
inter_area = inter_w * inter_h
# 4. 计算并集 (Union) 面积
b1_area = (b1_x2 - b1_x1) * (b1_y2 - b1_y1)
b2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1)
union_area = b1_area + b2_area - inter_area + 1e-6 # 加 eps 防止除0
# 5. 计算 IoU
iou = inter_area / union_area
return iou
class YOLOv1Loss(nn.Module):
"""
YOLOv1 损失函数类
"""
def __init__(self, S=7, B=2, C=20, lambda_coord=5, lambda_noobj=0.5):
super().__init__()
self.S = S
self.B = B
self.C = C
self.lambda_coord = lambda_coord # 论文中 lambda_coord = 5
self.lambda_noobj = lambda_noobj # 论文中 lambda_noobj = 0.5
self.mse = nn.MSELoss(reduction='sum') # 均方误差,求和模式
def forward(self, predictions, targets):
"""
计算损失
参数:
predictions: [Batch, S, S, B*5+C] - 网络的原始输出
targets: [Batch, S, S, 5+C] - 真实标签 (注意: target 只有1组框,因为真值只有一个)
最后一维格式: [x, y, w, h, conf, class_one_hot...]
其中 conf=1 表示该网格有目标,0 表示没有
返回:
total_loss: 总损失
"""
# 获取 batch size
BATCH_SIZE = predictions.size(0)
# =====================================================================
# 第一步: 数据预处理与掩码提取
# =====================================================================
# 1. 提取目标存在掩码 (obj_mask)
# target 的第4个索引 (index 4) 是置信度,1代表该网格有物体中心
# obj_mask shape: [Batch, S, S, 1]
obj_mask = targets[..., 4:5] # 有物体的网格为 True/1
noobj_mask = 1 - obj_mask # 没有物体的网格为 True/1
# =====================================================================
# 第二步: 负责预测框的筛选 (Responsible Predictor)
# 论文逻辑: 每个网格预测 B 个框,选择与 GT 框 IoU 最大的那个框负责预测
# =====================================================================
# 我们需要分别处理 B 个预测框
# 假设 predictions 最后一维排列为: [conf1, x1, y1, w1, h1, conf2, x2, y2, w2, h2, ...classes...]
# 或者是: [x1, y1, w1, h1, conf1, x2, y2, w2, h2, conf2, ...classes...]
# 这里我们采用后者 (与论文代码一致): 坐标在前,置信度在中,类别在后
# 分离预测结果
# 注意:这里我们假设网络输出的 30 维排列如下 (这是标准做法):
# [x, y, w, h, conf, x, y, w, h, conf, class_1, class_2, ..., class_20]
# 取出两个框的坐标预测 (注意: 网络直接预测的是 tx, ty, tw, th)
# 为了计算 IoU,我们需要将其"解码"为相对于整图的归一化坐标
# 但在计算损失时,我们是直接对 tx, ty, tw, th 计算的
# 这里为了简单演示,我们先把预测值拿出来
# 预测框1: [Batch, S, S, 4]
bbox1_pred = predictions[..., 0:4]
conf1_pred = predictions[..., 4:5]
# 预测框2: [Batch, S, S, 4]
bbox2_pred = predictions[..., 5:9]
conf2_pred = predictions[..., 9:10]
# 类别预测: [Batch, S, S, 20]
class_pred = predictions[..., 10:]
# 真实值: [Batch, S, S, 4] (x, y, w, h)
target_bbox = targets[..., 0:4]
target_class = targets[..., 5:]
# 现在,我们需要简单"模拟"一下解码来计算 IoU,以决定哪个框负责
# 注意:在真正的训练中,target_bbox 通常已经是归一化到 [0,1] 且相对于网格的
# 这里为了计算 IoU,我们假设 bbox_pred 和 target_bbox 都在同一空间
# 计算两个预测框分别与 GT 的 IoU
# 注意:这里为了代码简洁,我们直接把坐标当作 (x, y, w, h) 传入 IoU 函数
# 实际上 YOLOv1 的坐标编码有 sigmoid 和 exp 过程,这里仅展示损失函数核心逻辑
iou_b1 = compute_iou(bbox1_pred, target_bbox) # [Batch, S, S, 1]
iou_b2 = compute_iou(bbox2_pred, target_bbox) # [Batch, S, S, 1]
# 拼接 IoU 以便比较
ious = torch.cat([iou_b1.unsqueeze(0), iou_b2.unsqueeze(0)], dim=0) # [2, Batch, S, S, 1]
# 找出 IoU 最大的那个框 (argmax)
# iou_max: [Batch, S, S, 1], best_box: [Batch, S, S, 1] (0 或 1)
iou_max, best_box = torch.max(ious, dim=0)
# best_box 为 0 表示选第1个框,为 1 表示选第2个框
# 我们构造两个掩码
box1_mask = (1 - best_box) * obj_mask # 负责的框是1号且有目标
box2_mask = best_box * obj_mask # 负责的框是2号且有目标
# =====================================================================
# 第三步: 计算各项损失
# =====================================================================
# 1. 坐标损失 (Localization Loss)
# 对应论文公式第1、2行
# 注意: 论文中对 w, h 开了根号 (sqrt),这里为了演示先省略,直接用 MSE
# 收集所有"负责预测"的框的坐标
# 框1的贡献
loc_loss_xy = self.mse(box1_mask * bbox1_pred[..., 0:2], box1_mask * target_bbox[..., 0:2])
loc_loss_wh = self.mse(box1_mask * bbox1_pred[..., 2:4], box1_mask * target_bbox[..., 2:4])
# 框2的贡献
loc_loss_xy += self.mse(box2_mask * bbox2_pred[..., 0:2], box2_mask * target_bbox[..., 0:2])
loc_loss_wh += self.mse(box2_mask * bbox2_pred[..., 2:4], box2_mask * target_bbox[..., 2:4])
# 乘以 lambda_coord
loc_loss = self.lambda_coord * (loc_loss_xy + loc_loss_wh)
# 2. 置信度损失 (Confidence Loss)
# 对应论文公式第3、4行
# --- 有目标的置信度损失 (Obj Loss) ---
# 我们希望负责预测的那个框的置信度逼近它与 GT 的 IoU (或者直接是1)
# 这里简化为逼近 1
obj_loss = self.mse(box1_mask * conf1_pred, box1_mask * iou_max.detach()) # 用 detach 停止梯度
obj_loss += self.mse(box2_mask * conf2_pred, box2_mask * iou_max.detach())
# --- 无目标的置信度损失 (NoObj Loss) ---
# 我们希望不负责的框的置信度逼近 0
noobj_loss = self.mse(noobj_mask * conf1_pred, noobj_mask * torch.zeros_like(conf1_pred))
noobj_loss += self.mse(noobj_mask * conf2_pred, noobj_mask * torch.zeros_like(conf2_pred))
# 乘以权重
conf_loss = obj_loss + self.lambda_noobj * noobj_loss
# 3. 分类损失 (Classification Loss)
# 对应论文公式第5行
# 只要网格中有目标,就计算分类损失
cls_loss = self.mse(obj_mask * class_pred, obj_mask * target_class)
# =====================================================================
# 第四步: 总损失与平均
# =====================================================================
total_loss = loc_loss + conf_loss + cls_loss
# 除以 batch_size 进行平均 (可选,视优化器而定)
return total_loss / BATCH_SIZE
# ------------------------------
# 简单的测试代码
# ------------------------------
if __name__ == "__main__":
# 1. 定义模型
model = YOLOv1(num_classes=20)
print("✅ 模型定义成功")
# 2. 定义损失函数
criterion = YOLOv1Loss()
print("✅ 损失函数定义成功")
# 3. 模拟输入
# 输入图像: Batch=2, 3通道, 448x448
dummy_img = torch.randn(2, 3, 448, 448)
# 模拟标签 (随机生成,仅用于测试维度)
# 标签格式: [Batch, 7, 7, 25] (4坐标 + 1置信 + 20类别)
dummy_target = torch.randn(2, 7, 7, 25)
# 4. 前向传播
predictions = model(dummy_img)
print(f"输入维度: {dummy_img.shape}")
print(f"输出维度: {predictions.shape}")
# 5. 计算损失 (测试)
loss = criterion(predictions, dummy_target)
print(f"测试损失值: {loss.item():.4f}")
print("🎉 全部运行正常!")
二、YOLOv2 网络架构
1、YOLOv2 网络架构特点
YOLOv2 以 DarkNet-19 为骨干,通过特征融合、锚框设计和全卷积结构实现了精度与速度的平衡,核心特点如下: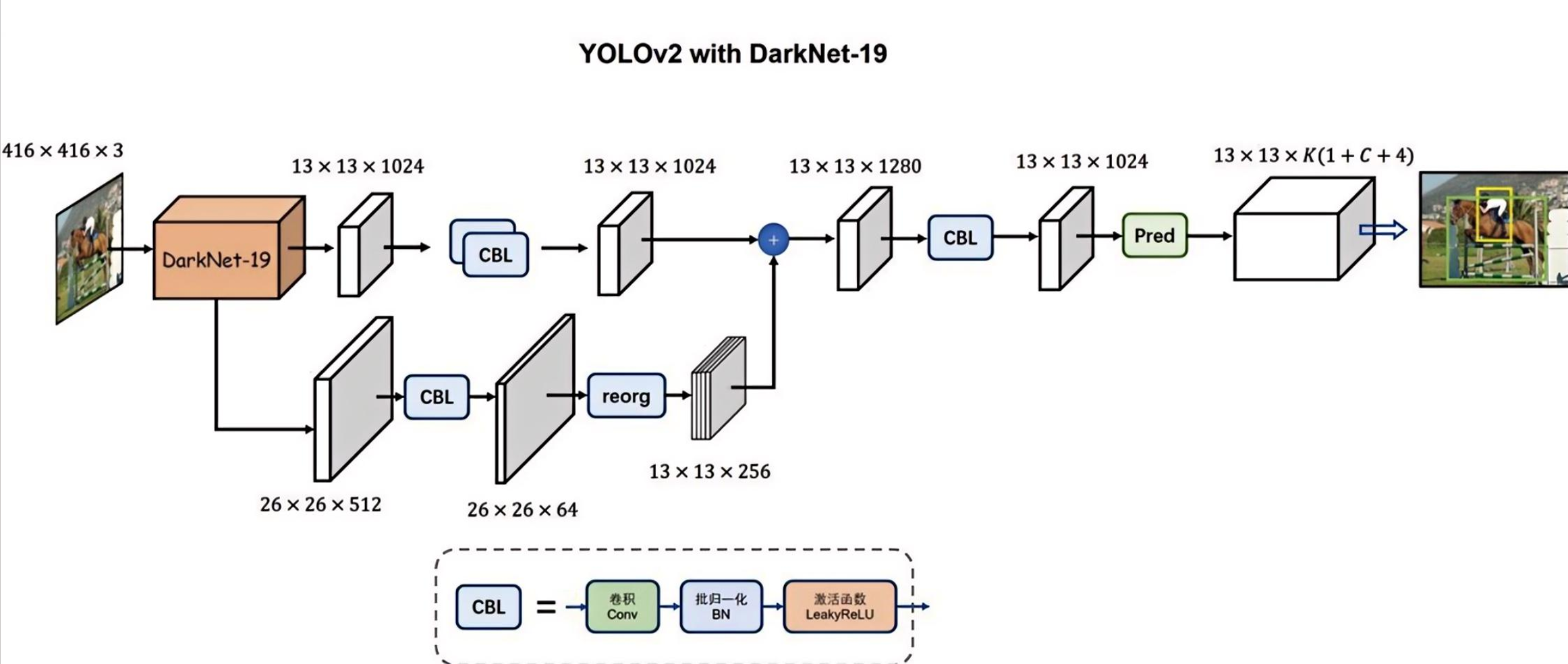
1. 骨干网络:DarkNet-19
- 替代 YOLOv1 的简化 GoogleNet,仅 19 层卷积 + 5 个最大池化层,结构更轻量高效。
- 所有卷积层后加入 批归一化(BN),加速训练收敛、稳定梯度、缓解过拟合。
- 用 全局平均池化 替代全连接层,大幅减少参数数量,避免输入尺寸固定的限制。
2. 特征融合:Passthrough(Reorg)层
从架构图可见:
- DarkNet-19 中间层输出
26×26×512特征,经 CBL(Conv+BN+LeakyReLU)和 Reorg 层,将空间维度压缩、通道维度扩展为13×13×256。 - 与深层特征
13×13×1024通道拼接,得到13×13×1280融合特征,实现**浅层细粒度特征(小目标)+ 深层语义特征(大目标)**的结合,显著提升小目标检测能力。
3. 锚框(Anchor Boxes)与维度聚类
- 引入 Faster R-CNN 的锚框思想,每个网格预设 K 个锚框(默认 5 个),替代 YOLOv1 每个网格 2 个固定框的设计。
- 对训练集真实框做 K-means 维度聚类,自动学习最优锚框宽高(而非手动设计),让锚框更贴合数据集目标分布,提升边界框召回率和定位精度。
4. 全卷积结构与多尺度训练
- 移除 YOLOv1 的全连接层,改用 1×1 卷积 输出最终预测,支持任意 32 倍数的输入尺寸(如 416×416)。
- 训练时随机选择输入尺寸(320×320 ~ 608×608,步长 32),实现 多尺度训练,让模型适应不同尺度目标,提升鲁棒性。
5. 高分辨率分类器微调
- 先在 224×224 图像上预训练分类器,再在 448×448 高分辨率图像上微调,提升模型对高分辨率图像的特征提取能力,进而提升检测精度。
6. 直接位置预测
- 预测锚框的 偏移量( t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th)而非直接框坐标:
- t x , t y t_x, t_y tx,ty 经 sigmoid 激活,限制中心在网格内(0~1),避免训练初期位置偏移过大。
- t w , t h t_w, t_h tw,th 为对数偏移: w = p w e t w w = p_w e^{t_w} w=pwetw, h = p h e t h h = p_h e^{t_h} h=pheth( p w , p h p_w,p_h pw,ph 为聚类锚框宽高),提升宽高预测稳定性。
2、YOLOv2 损失函数
YOLOv2 损失函数在 YOLOv1 基础上优化,针对锚框设计,分为 坐标损失、置信度损失、分类损失 三部分:
L = λ c o o r d ∑ i = 0 S 2 ∑ j = 0 K 1 i j o b j [ ( t x − t ^ x ) 2 + ( t y − t ^ y ) 2 + ( t w − t ^ w ) 2 + ( t h − t ^ h ) 2 ] + ∑ i = 0 S 2 ∑ j = 0 K 1 i j o b j ( t o − t ^ o ) 2 + λ n o o b j ∑ i = 0 S 2 ∑ j = 0 K 1 i j n o o b j ( t o − t ^ o ) 2 + ∑ i = 0 S 2 ∑ j = 0 K 1 i j o b j ∑ c = 1 C ( p c − p ^ c ) 2 \begin{aligned} \mathcal{L} &= \lambda_{coord} \sum_{i=0}^{S^2} \sum_{j=0}^K \mathbb{1}_{ij}^{obj} \left[ (t_x - \hat{t}_x)^2 + (t_y - \hat{t}_y)^2 + (t_w - \hat{t}_w)^2 + (t_h - \hat{t}_h)^2 \right] \\ &+ \sum_{i=0}^{S^2} \sum_{j=0}^K \mathbb{1}_{ij}^{obj} (t_o - \hat{t}_o)^2 + \lambda_{noobj} \sum_{i=0}^{S^2} \sum_{j=0}^K \mathbb{1}_{ij}^{noobj} (t_o - \hat{t}_o)^2 \\ &+ \sum_{i=0}^{S^2} \sum_{j=0}^K \mathbb{1}_{ij}^{obj} \sum_{c=1}^C (p_c - \hat{p}_c)^2 \end{aligned} L=λcoordi=0∑S2j=0∑K1ijobj[(tx−t^x)2+(ty−t^y)2+(tw−t^w)2+(th−t^h)2]+i=0∑S2j=0∑K1ijobj(to−t^o)2+λnoobji=0∑S2j=0∑K1ijnoobj(to−t^o)2+i=0∑S2j=0∑K1ijobjc=1∑C(pc−p^c)2
符号与核心解读
| 符号 | 含义 |
|---|---|
| S S S | 网格尺寸(默认 13×13) |
| K K K | 每个网格的锚框数量(默认 5) |
| 1 i j o b j \mathbb{1}_{ij}^{obj} 1ijobj | 指示函数:第 i i i 个网格的第 j j j 个锚框与真实框 IoU 最大时为 1(负责该目标) |
| 1 i j n o o b j \mathbb{1}_{ij}^{noobj} 1ijnoobj | 指示函数:第 i i i 个网格的第 j j j 个锚框不负责目标时为 1 |
| λ c o o r d = 5 \lambda_{coord}=5 λcoord=5 | 坐标损失权重,放大定位损失的重要性 |
| λ n o o b j = 0.5 \lambda_{noobj}=0.5 λnoobj=0.5 | 无目标置信度损失权重,降低负样本影响 |
| t x , t y t_x, t_y tx,ty | 锚框中心相对于网格的偏移量(sigmoid 激活后 ∈ (0,1)) |
| t w , t h t_w, t_h tw,th | 锚框宽高相对于聚类锚框的对数偏移量 |
| t o t_o to | 置信度:锚框包含目标的概率(有目标时为 1,无目标时为 0) |
| p c p_c pc | 类别概率:目标属于第 c c c 类的概率 |
损失组成解析
-
坐标损失(第 1 行):
- 仅对负责目标的锚框计算,惩罚中心偏移和宽高误差。
- 用对数偏移替代直接预测,提升训练稳定性; λ c o o r d \lambda_{coord} λcoord 放大权重,优先保证定位精度。
-
置信度损失(第 2 行):
- 分为有目标和无目标两部分:
- 有目标时:惩罚锚框置信度与真实 IoU 的误差,让模型学习锚框包含目标的概率。
- 无目标时:用 λ n o o b j \lambda_{noobj} λnoobj 降低权重,避免大量背景锚框的损失主导梯度。
- 分为有目标和无目标两部分:
-
分类损失(第 3 行):
- 仅对负责目标的锚框计算,惩罚类别预测误差,让模型学习目标的类别分布。
3、YOLOv2 的核心缺陷
- 锚框泛化性受限:锚框宽高由训练集 K-means 聚类得到,若测试集目标分布与训练集差异大,检测效果会显著下降。
- 小目标检测仍不足:仅通过 Passthrough 层融合浅层特征,未构建真正的特征金字塔(如 FPN),对极小目标的检测能力弱于两阶段算法。
- 多尺度训练效率低:训练时频繁切换输入尺寸,训练速度较慢,且不同尺度特征的学习不够均衡。
- 类别不平衡问题:无目标锚框数量远多于有目标锚框,虽用 λ n o o b j \lambda_{noobj} λnoobj 缓解,但复杂场景下仍易偏向背景,导致漏检。
- 单尺度输出局限:仅输出 13×13 尺度的特征图,无法像 YOLOv3 那样多尺度输出,对不同尺度目标的适配性仍有提升空间。
- 锚框数量固定:每个网格固定 K 个锚框,若场景中目标数量/尺度变化大,易出现锚框不足或冗余。
4、与 YOLOv1 的对比提升
| 维度 | YOLOv1 | YOLOv2 | 核心提升 |
|---|---|---|---|
| 骨干网络 | 简化 GoogleNet,全连接层输出 | DarkNet-19,全卷积 + BN 层 | 更轻量高效,支持多尺度输入,训练更稳定 |
| 特征融合 | 无,仅用深层特征 | Passthrough 层融合浅层+深层特征 | 显著提升小目标检测能力 |
| 边界框预测 | 每个网格 2 个框,直接预测坐标 | 每个网格 K 个聚类锚框,预测偏移量 | 提升定位精度,适配不同长宽比目标 |
| 输入灵活性 | 固定 448×448 | 多尺度输入(320×320~608×608) | 支持多尺度训练,模型鲁棒性更强 |
| 训练稳定性 | 无 BN,易过拟合 | 所有卷积层加 BN | 加速收敛,减少过拟合,提升泛化能力 |
| 检测范围 | 仅检测 VOC 20 类 | YOLO9000 可检测 9000+ 类 | 结合 WordTree,打通检测与分类,扩展类别范围 |
| 精度与速度 | VOC2007 mAP 63.4%,45 FPS | VOC2007 mAP 76.8%,67 FPS;高分辨率下 mAP 78.6% | 精度大幅提升,同时保持实时检测速度 |
| 小目标能力 | 弱(仅用深层特征) | 强(融合浅层细粒度特征) | 小目标检测召回率和精度显著提升 |
总结
YOLOv2 在 YOLOv1 基础上,通过高效骨干网络、特征融合、锚框设计、多尺度训练等技术,在保持实时性的同时,大幅提升了检测精度和小目标能力,还通过 YOLO9000 扩展了检测类别范围,是 YOLO 系列的关键迭代版本,为后续 YOLOv3、v4 等奠定了基础。
5、核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# ========================================================================== #
# 1. 基础组件定义 #
# ========================================================================== #
class ConvBNLeaky(nn.Module):
"""
YOLOv2 基础卷积块: Conv2d + BatchNorm2d + LeakyReLU
对应架构图中的 "CBL"
"""
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super().__init__()
self.conv = nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
bias=False # BN 包含偏置,不需要卷积 bias
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.LeakyReLU(0.1, inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
class ReorgLayer(nn.Module):
"""
重组层 (Reorg / Passthrough Layer)
作用: 将高分辨率特征图 (26x26) 压缩空间维度,扩展通道维度,以便与低分辨率特征融合
逻辑: 将 2x2 的空间块展平为通道
"""
def __init__(self, stride=2):
super().__init__()
self.stride = stride
def forward(self, x):
"""
输入 x: [Batch, C, H, W] (例如 [B, 64, 26, 26])
输出: [Batch, C*s*s, H/s, W/s] (例如 [B, 256, 13, 13])
"""
B, C, H, W = x.size()
s = self.stride
# 1. 调整维度顺序并重塑
# [B, C, H, W] -> [B, C, H/s, s, W/s, s]
x = x.view(B, C, H // s, s, W // s, s)
# 2. 交换维度,将空间块移到通道维度
# -> [B, s, s, C, H/s, W/s]
x = x.permute(0, 3, 5, 1, 2, 4).contiguous()
# 3. 展平通道
# -> [B, C*s*s, H/s, W/s]
x = x.view(B, C * s * s, H // s, W // s)
return x
# ========================================================================== #
# 2. DarkNet-19 骨干网络 #
# ========================================================================== #
class DarkNet19(nn.Module):
"""
YOLOv2 骨干网络: DarkNet-19
用于特征提取,同时返回两个输出:
1. 深层特征 (13x13) 用于语义信息
2. 中层特征 (26x26) 用于细粒度信息 (Passthrough)
"""
def __init__(self):
super().__init__()
# 阶段 1: 输入 416x416 -> 输出 208x208 -> 104x104
self.stage1 = nn.Sequential(
ConvBNLeaky(3, 32, kernel_size=3, padding=1),
nn.MaxPool2d(2, 2)
)
# 阶段 2: 104x104 -> 52x52
self.stage2 = nn.Sequential(
ConvBNLeaky(32, 64, kernel_size=3, padding=1),
nn.MaxPool2d(2, 2)
)
# 阶段 3: 52x52 -> 26x26 (这里输出要保存,用于 Passthrough)
self.stage3 = nn.Sequential(
ConvBNLeaky(64, 128, kernel_size=3, padding=1),
ConvBNLeaky(128, 64, kernel_size=1),
ConvBNLeaky(64, 128, kernel_size=3, padding=1),
nn.MaxPool2d(2, 2)
)
# 阶段 4: 26x26 -> 这里的输出是我们要的中层特征 route1
self.stage4 = nn.Sequential(
ConvBNLeaky(128, 256, kernel_size=3, padding=1),
ConvBNLeaky(256, 128, kernel_size=1),
ConvBNLeaky(128, 256, kernel_size=3, padding=1),
# 注意:MaxPool 放在 stage5 开头,这里先不 pool,保留 26x26
)
# 阶段 5: 26x26 -> 13x13
self.stage5 = nn.Sequential(
nn.MaxPool2d(2, 2),
ConvBNLeaky(256, 512, kernel_size=3, padding=1),
ConvBNLeaky(512, 256, kernel_size=1),
ConvBNLeaky(256, 512, kernel_size=3, padding=1),
ConvBNLeaky(512, 256, kernel_size=1),
ConvBNLeaky(256, 512, kernel_size=3, padding=1),
# 这里输出 route2 (深层特征),但还需要继续卷积
)
# 阶段 6: 继续加深 13x13 特征
self.stage6 = nn.Sequential(
nn.MaxPool2d(2, 2), # 虽然图里没画,但 DarkNet19 这里有 pool,不过我们保持 13x13,stride=1
ConvBNLeaky(512, 1024, kernel_size=3, padding=1),
ConvBNLeaky(1024, 512, kernel_size=1),
ConvBNLeaky(512, 1024, kernel_size=3, padding=1),
ConvBNLeaky(1024, 512, kernel_size=1),
ConvBNLeaky(512, 1024, kernel_size=3, padding=1),
)
def forward(self, x):
"""
输入: [B, 3, 416, 416]
输出:
x1: [B, 256, 26, 26] 中层特征 (用于 Passthrough)
x2: [B, 1024, 13, 13] 深层特征
"""
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
# 保存中层特征 (26x26)
x1 = self.stage4(x)
# 继续下采样提取深层特征 (13x13)
x = self.stage5(x1)
x2 = self.stage6(x)
return x1, x2
# ========================================================================== #
# 3. YOLOv2 主模型定义 #
# ========================================================================== #
class YOLOv2(nn.Module):
"""
YOLOv2 (YOLO9000) 完整模型定义
对应架构图: DarkNet19 -> 特征融合 -> 检测头 -> 输出
"""
def __init__(self, num_classes=20, num_anchors=5):
super().__init__()
self.num_classes = num_classes
self.num_anchors = num_anchors
# 1. 骨干网络
self.backbone = DarkNet19()
# 2. 深层特征处理 (13x13 部分)
self.deep_conv = nn.Sequential(
ConvBNLeaky(1024, 1024, kernel_size=3, padding=1),
ConvBNLeaky(1024, 1024, kernel_size=3, padding=1),
)
# 3. 中层特征处理 (Passthrough 部分)
# 对应架构图: 26x26x512 -> CBL -> 26x26x64
self.passthrough_conv = ConvBNLeaky(256, 64, kernel_size=1)
self.reorg = ReorgLayer(stride=2) # 26x26x64 -> 13x13x256
# 4. 特征融合后的卷积
# 拼接后通道数: 1024 (深层) + 256 (Passthrough) = 1280
self.fusion_conv = nn.Sequential(
ConvBNLeaky(1280, 1024, kernel_size=3, padding=1),
)
# 5. 预测层 (Pred)
# 输出通道数: K * (1 + C + 4)
# 即: 锚框数 * (置信度 + 类别数 + 坐标)
final_channels = num_anchors * (1 + num_classes + 4)
self.pred_conv = nn.Conv2d(1024, final_channels, kernel_size=1)
def forward(self, x):
"""
输入: [Batch, 3, 416, 416]
输出: [Batch, 13, 13, K*(5+C)] 检测结果
"""
# 1. 获取骨干网络特征
# feat_mid: [B, 256, 26, 26]
# feat_deep: [B, 1024, 13, 13]
feat_mid, feat_deep = self.backbone(x)
# 2. 处理深层特征
# [B, 1024, 13, 13] -> [B, 1024, 13, 13]
x_deep = self.deep_conv(feat_deep)
# 3. 处理中层特征 (Passthrough)
# [B, 256, 26, 26] -> [B, 64, 26, 26]
x_pass = self.passthrough_conv(feat_mid)
# [B, 64, 26, 26] -> [B, 256, 13, 13]
x_pass = self.reorg(x_pass)
# 4. 特征融合 (Concat)
# 在通道维度 (dim=1) 拼接
# [B, 1024, 13, 13] + [B, 256, 13, 13] -> [B, 1280, 13, 13]
x_fusion = torch.cat([x_deep, x_pass], dim=1)
# 5. 融合后的卷积
x_fusion = self.fusion_conv(x_fusion)
# 6. 最终预测
# [B, 1280, 13, 13] -> [B, K*(5+C), 13, 13]
pred = self.pred_conv(x_fusion)
# 7. 调整维度顺序,方便后续处理
# [B, C, H, W] -> [B, H, W, C]
# 即: [Batch, 13, 13, K*(5+C)]
pred = pred.permute(0, 2, 3, 1).contiguous()
return pred
# ========================================================================== #
# 4. YOLOv2 损失函数 #
# ========================================================================== #
def compute_iou(boxes1, boxes2):
"""
计算两组框的 IoU
boxes 格式: (x_center, y_center, w, h)
"""
# 转换为 x1, y1, x2, y2
b1_x1 = boxes1[..., 0:1] - boxes1[..., 2:3] / 2
b1_y1 = boxes1[..., 1:2] - boxes1[..., 3:4] / 2
b1_x2 = boxes1[..., 0:1] + boxes1[..., 2:3] / 2
b1_y2 = boxes1[..., 1:2] + boxes1[..., 3:4] / 2
b2_x1 = boxes2[..., 0:1] - boxes2[..., 2:3] / 2
b2_y1 = boxes2[..., 1:2] - boxes2[..., 3:4] / 2
b2_x2 = boxes2[..., 0:1] + boxes2[..., 2:3] / 2
b2_y2 = boxes2[..., 1:2] + boxes2[..., 3:4] / 2
# 交集
inter_x1 = torch.max(b1_x1, b2_x1)
inter_y1 = torch.max(b1_y1, b2_y1)
inter_x2 = torch.min(b1_x2, b2_x2)
inter_y2 = torch.min(b1_y2, b2_y2)
inter_w = torch.clamp(inter_x2 - inter_x1, min=0)
inter_h = torch.clamp(inter_y2 - inter_y1, min=0)
inter_area = inter_w * inter_h
# 并集
b1_area = (b1_x2 - b1_x1) * (b1_y2 - b1_y1)
b2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1)
union_area = b1_area + b2_area - inter_area + 1e-6
return inter_area / union_area
class YOLOv2Loss(nn.Module):
"""
YOLOv2 损失函数
"""
def __init__(self, num_classes=20, num_anchors=5,
anchors=None, # 锚框宽高 (归一化到 0-1 或特征图尺度)
lambda_coord=5, lambda_noobj=0.5,
img_size=416):
super().__init__()
self.num_classes = num_classes
self.num_anchors = num_anchors
self.lambda_coord = lambda_coord
self.lambda_noobj = lambda_noobj
self.img_size = img_size
self.grid_size = img_size // 32 # 13
# 默认锚框 (基于 VOC 数据集聚类的 5 个锚框,单位: 特征图尺度)
# 论文中给出的 (width, height): (1.3221, 1.73145), (3.19275, 4.00944), (5.05587, 8.09892), (9.47112, 4.84053), (11.2364, 10.0071)
if anchors is None:
anchors = torch.tensor([
[1.3221, 1.73145],
[3.19275, 4.00944],
[5.05587, 8.09892],
[9.47112, 4.84053],
[11.2364, 10.0071]
])
self.register_buffer('anchors', anchors) # 注册为 buffer,随模型移动到 device
def forward(self, predictions, targets):
"""
计算损失
参数:
predictions: [Batch, 13, 13, K*(5+C)] - 网络输出
targets: [Batch, N, 5] - 真实标签,格式 (x, y, w, h, class_id),归一化坐标 [0,1]
返回:
total_loss: 总损失
"""
B = predictions.size(0)
S = self.grid_size
K = self.num_anchors
C = self.num_classes
# 1. 重塑预测结果
# [B, 13, 13, K*(5+C)] -> [B, 13, 13, K, 5+C]
pred = predictions.view(B, S, S, K, 5 + C)
# 分离预测的各个部分
pred_xy = torch.sigmoid(pred[..., 0:2]) # [B, 13, 13, K, 2] tx, ty (sigmoid 后在 0-1 之间)
pred_wh = pred[..., 2:4] # [B, 13, 13, K, 2] tw, th
pred_conf = torch.sigmoid(pred[..., 4:5]) # [B, 13, 13, K, 1] 置信度
pred_cls = pred[..., 5:] # [B, 13, 13, K, C] 类别
# 2. 构建网格坐标 (用于解码预测框)
# 创建 13x13 的网格坐标 (cx, cy)
grid_y, grid_x = torch.meshgrid([torch.arange(S), torch.arange(S)], indexing='ij')
grid_xy = torch.stack([grid_x, grid_y], dim=-1).float().to(pred.device) # [13, 13, 2]
grid_xy = grid_xy.unsqueeze(0).unsqueeze(3) # [1, 13, 13, 1, 2]
# 3. 解码预测框 (用于计算 IoU)
# bx = sigmoid(tx) + cx
# by = sigmoid(ty) + cy
# bw = pw * exp(tw)
# bh = ph * exp(th)
anchors = self.anchors.view(1, 1, 1, K, 2) # [1, 1, 1, K, 2]
pred_box_xy = pred_xy + grid_xy
pred_box_wh = torch.exp(pred_wh) * anchors
pred_boxes = torch.cat([pred_box_xy, pred_box_wh], dim=-1) # [B, 13, 13, K, 4] (x,y,w,h) in grid scale
# =====================================================================
# 下面开始构建 Target 掩码和计算损失
# 为了代码简洁,这里展示核心逻辑框架
# 实际训练中需要遍历 targets 分配到对应的网格和锚框
# =====================================================================
# 初始化掩码
obj_mask = torch.zeros_like(pred_conf) # [B, 13, 13, K, 1]
noobj_mask = torch.ones_like(pred_conf) # [B, 13, 13, K, 1]
txy = torch.zeros_like(pred_xy)
twh = torch.zeros_like(pred_wh)
tcls = torch.zeros_like(pred_cls)
tconf = torch.zeros_like(pred_conf)
# 遍历 batch 中的每一张图
for b in range(B):
# 遍历这张图的每一个真实框
for t in range(targets.size(1)):
# 如果标签全为 0 (填充项),跳过
if targets[b, t].sum() == 0:
continue
# 获取真实框坐标 (归一化到 [0,1])
gx_prime, gy_prime, gw_prime, gh_prime, cls_id = targets[b, t]
# 转换到特征图尺度 (13x13)
gx = gx_prime * S
gy = gy_prime * S
gw = gw_prime * S
gh = gh_prime * S
# 找到目标中心落在哪个网格 (i, j)
gi = int(gx)
gj = int(gy)
# 构建真实框 (仅用于计算 IoU,中心点设为 0,因为只比较形状)
gt_box = torch.tensor([[0, 0, gw, gh]]).float().to(pred.device)
# 构建锚框 (同样中心点设为 0)
anchor_shapes = torch.cat([torch.zeros_like(self.anchors), self.anchors], dim=-1)
# 计算每个锚框与真实框的 IoU
ious = compute_iou(anchor_shapes, gt_box).squeeze()
# 找到 IoU 最大的锚框索引
best_k = torch.argmax(ious)
# 标记: 这个网格的这个锚框负责预测目标
obj_mask[b, gj, gi, best_k] = 1
noobj_mask[b, gj, gi, best_k] = 0
# 同时,IoU > 0.5 的锚框也忽略 (不计算 noobj loss)
noobj_mask[b, gj, gi, ious > 0.5] = 0
# 计算目标偏移量 (Ground Truth offsets)
# tx = gx - gi
# ty = gy - gj
txy[b, gj, gi, best_k, 0] = gx - gi
txy[b, gj, gi, best_k, 1] = gy - gj
# tw = log(gw / pw)
# th = log(gh / ph)
twh[b, gj, gi, best_k, 0] = torch.log(gw / self.anchors[best_k, 0] + 1e-6)
twh[b, gj, gi, best_k, 1] = torch.log(gh / self.anchors[best_k, 1] + 1e-6)
# 置信度目标: 1 (或者是 IoU,这里简化为 1)
tconf[b, gj, gi, best_k] = 1 # 实际中可以用 ious[best_k]
# 类别目标: one-hot
tcls[b, gj, gi, best_k, int(cls_id)] = 1
# =====================================================================
# 计算各项损失
# =====================================================================
# 1. 坐标损失 (xy + wh)
loss_xy = F.mse_loss(obj_mask * pred_xy, obj_mask * txy, reduction='sum')
loss_wh = F.mse_loss(obj_mask * pred_wh, obj_mask * twh, reduction='sum')
loss_coord = self.lambda_coord * (loss_xy + loss_wh)
# 2. 置信度损失 (Obj + NoObj)
loss_obj = F.mse_loss(obj_mask * pred_conf, obj_mask * tconf, reduction='sum')
loss_noobj = F.mse_loss(noobj_mask * pred_conf, noobj_mask * torch.zeros_like(pred_conf), reduction='sum')
loss_conf = loss_obj + self.lambda_noobj * loss_noobj
# 3. 分类损失
loss_cls = F.mse_loss(obj_mask * pred_cls, obj_mask * tcls, reduction='sum')
# 总损失
total_loss = (loss_coord + loss_conf + loss_cls) / B
return total_loss

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)