YOLOV3网络架构与代码解析
一、YOLOV3
1、YOLOv3架构图模块与字母详解
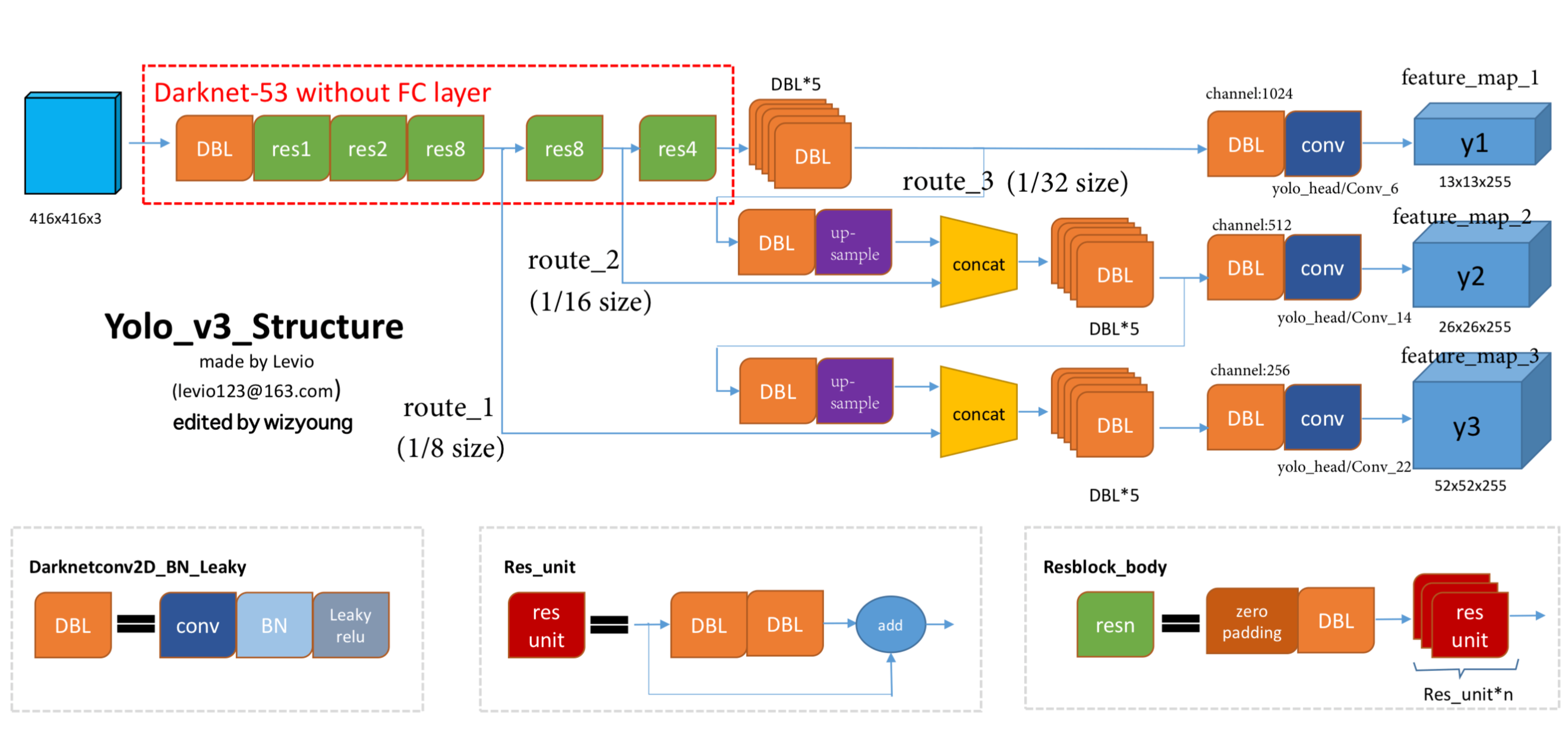
YOLOV3网络架构(引用自CSDN Levio)
提供的架构图,拆解所有模块、字母的含义,从基础单元到完整流程逐一说明:
- DBL:全称
Darknetconv2D_BN_Leaky,是YOLOv3最基础的卷积单元,也是整个网络的最小组成单元。结构为:Conv2d卷积 + BatchNorm批归一化 + LeakyReLU激活函数。该结构延续了YOLOv2的CBL单元设计,替代了YOLOv1的无BN普通卷积;YOLOv3中所有卷积操作均基于DBL实现,无单独的池化层,通过步长为2的DBL实现特征图下采样。YOLOv3的DBL(Darknetconv2D_BN_Leaky),和YOLOv2的CBL结构完全一致,没有任何本质变化,只是因为骨干网络换成了DarkNet-53,所以命名上贴合DarkNet做了调整。 - 唯一的使用差异:YOLOv3完全去掉了单独的MaxPool池化层,所有下采样都通过步长为2的DBL卷积实现,整个网络是纯全卷积结构,没有任何池化层。
- Res_unit:全称
Residual Unit,残差单元,是Darknet-53的核心结构。结构为:2个连续的DBL模块 + 残差Add连接。第一个DBL用1x1卷积降维,第二个DBL用3x3卷积恢复维度,最终将输入与第二个DBL的输出相加,实现残差连接,解决深层网络梯度消失的问题,让网络可以做得更深。 - Resblock_body(resn):残差块体,对应图中的
res1、res2、res8、res4,n代表堆叠的Res_unit数量。结构为:Zero Padding零填充 + 步长2的DBL下采样 + 连续n个Res_unit。作用是完成特征图的下采样,同时通过堆叠残差单元提取深层语义特征,是Darknet-53的核心组成块。
2. 架构中的功能模块
- Darknet-53 without FC layer:YOLOv3的骨干特征提取网络,总共有53个卷积层,无全连接层,是纯全卷积网络。结构为:输入416x416x3图像 → 初始DBL → 依次经过res1、res2、res8、res8、res4共5个Resblock_body,最终输出3个不同下采样倍率的特征图,分别对应1/8、1/16、1/32输入尺寸。
- route:路由层,作用是提取指定网络层的输出特征图,用于后续的多尺度特征融合。图中:
route_1:1/8下采样特征,尺寸52x52,来自第一个res8的输出,是浅层细粒度特征,负责小目标检测;route_2:1/16下采样特征,尺寸26x26,来自第二个res8的输出,是中层特征,负责中目标检测;route_3:1/32下采样特征,尺寸13x13,来自最后res4的输出,是深层语义特征,负责大目标检测。
- up-sample:上采样层,采用最近邻插值算法,将小尺寸的深层特征图放大2倍,让其尺寸与浅层特征图一致,用于后续的通道拼接,实现深层语义特征与浅层细粒度特征的融合。
- concat:通道拼接层,将上采样后的深层特征,与同尺寸的浅层route特征,在通道维度进行拼接。比如将13x13的特征上采样为26x26后,与route_2的26x26特征拼接,融合不同层级的特征信息。
- DBL*5:连续5个DBL模块组成的特征处理单元,位于每个检测分支的concat之后,作用是对拼接后的多尺度特征进行深度融合与提纯,为最终的检测预测做准备。
- yolo_head:检测头,结构为DBL + 1x1 Conv卷积,是最终的预测输出层。1x1卷积将特征通道映射为最终的预测通道数,每个检测头对应一个尺度的输出。
3. 输出部分
- y1、y2、y3:YOLOv3的3个尺度输出特征图,对应不同大小的目标检测:
y1:13x13x255,1/32下采样,感受野最大,负责检测大目标;y2:26x26x255,1/16下采样,感受野中等,负责检测中目标;y3:52x52x255,1/8下采样,感受野最小,负责检测小目标;- 通道数255的来源:COCO数据集80个类别,每个尺度每个网格分配3个锚框,每个锚框预测4个坐标参数+1个置信度+80个类别概率,即
3*(4+1+80)=255。
2、YOLOv3 网络架构
1、YOLOv3 网络架构特点
YOLOv3 以 DarkNet-53 为骨干,基于**特征金字塔(FPN)**实现多尺度检测,在保持实时性的同时大幅提升了检测精度,尤其是小目标检测能力,核心特点如下:
骨干网络:DarkNet-53
- 替代 YOLOv2 的 DarkNet-19,采用53层卷积的全卷积结构,引入残差连接(Res_unit),解决了深层网络梯度消失的问题,让网络可以提取更丰富的深层语义特征。
- 所有卷积层均采用DBL结构(Conv+BN+LeakyReLU),无全连接层,支持任意32倍数的输入尺寸,同时BN层大幅提升了训练收敛速度和稳定性。
- 无单独的最大池化层,通过步长为2的卷积实现下采样,减少了池化带来的特征信息丢失。
多尺度特征金字塔(FPN)结构
从架构图可见,YOLOv3构建了完整的自上而下的特征金字塔,替代了YOLOv2的单尺度Passthrough融合:
- 从DarkNet-53中提取3个不同下采样倍率的特征:1/8(52x52)、1/16(26x26)、1/32(13x13),分别对应浅层、中层、深层特征。
- 深层特征(13x13)经上采样放大2倍后,与中层特征(26x26)concat拼接,再经DBL*5提纯;拼接后的特征再次上采样放大2倍,与浅层特征(52x52)concat拼接,实现了深层语义特征与浅层细粒度特征的深度融合。
- 3个融合后的特征分别送入独立的检测头,实现多尺度检测,彻底解决了YOLOv2单尺度输出对小目标检测能力不足的问题。
多尺度锚框与维度聚类
- 延续YOLOv2的K-means维度聚类锚框设计,但针对3个输出尺度,共聚类得到9个锚框,每个尺度分配3个锚框:大尺度特征(13x13)分配大锚框,中尺度(26x26)分配中锚框,小尺度(52x52)分配小锚框。
- 锚框与特征尺度精准匹配,大幅提升了不同大小目标的边界框召回率,尤其是小目标的召回率。
- 延续直接位置预测逻辑:预测锚框的偏移量 t x , t y t_x,t_y tx,ty经sigmoid激活限制在0~1之间,避免训练初期位置偏移过大,宽高采用对数偏移预测,提升预测稳定性。
独立二元交叉熵分类
- 摒弃了YOLOv2的Softmax多分类方式,改用**每个类别独立的Sigmoid二元交叉熵(BCE)**进行分类预测。
- 解决了Softmax要求类别互斥的问题,支持一个目标同时属于多个类别(如“人”和“女人”),更贴合实际的检测场景,分类灵活性和精度更高。
正负样本匹配优化
- 每个真实目标会匹配所有与真实框IoU最大的锚框作为正样本,同时忽略IoU>0.5但不是最大的锚框,仅对IoU<0.5的锚框计算负样本损失,减少了无效负样本的影响,缓解了类别不平衡问题。
- 每个真实目标可以匹配多个锚框,相比YOLOv2一个目标仅匹配一个锚框,增加了正样本数量,提升了训练效率。
2、YOLOv3 损失函数
YOLOv3的损失函数在YOLOv2的基础上优化,将分类和置信度损失从均方误差(MSE)改为二元交叉熵(BCE),更贴合检测任务的特性,整体分为坐标损失、置信度损失、分类损失三部分,公式如下:
L = λ c o o r d ∑ i = 0 S 2 ∑ j = 0 K 1 i j o b j [ ( t x − t ^ x ) 2 + ( t y − t ^ y ) 2 + ( t w − t ^ w ) 2 + ( t h − t ^ h ) 2 ] − ∑ i = 0 S 2 ∑ j = 0 K 1 i j o b j [ C ^ i log ( C i ) + ( 1 − C ^ i ) log ( 1 − C i ) ] − λ n o o b j ∑ i = 0 S 2 ∑ j = 0 K 1 i j n o o b j [ C ^ i log ( C i ) + ( 1 − C ^ i ) log ( 1 − C i ) ] − ∑ i = 0 S 2 ∑ j = 0 K 1 i j o b j ∑ c ∈ c l a s s e s [ p ^ i ( c ) log ( p i ( c ) ) + ( 1 − p ^ i ( c ) ) log ( 1 − p i ( c ) ) ] \begin{aligned} \mathcal{L} &= \lambda_{coord} \sum_{i=0}^{S^2} \sum_{j=0}^K \mathbb{1}_{ij}^{obj} \left[ (t_x - \hat{t}_x)^2 + (t_y - \hat{t}_y)^2 + (t_w - \hat{t}_w)^2 + (t_h - \hat{t}_h)^2 \right] \\ &- \sum_{i=0}^{S^2} \sum_{j=0}^K \mathbb{1}_{ij}^{obj} \left[ \hat{C}_i \log(C_i) + (1-\hat{C}_i) \log(1-C_i) \right] \\ &- \lambda_{noobj} \sum_{i=0}^{S^2} \sum_{j=0}^K \mathbb{1}_{ij}^{noobj} \left[ \hat{C}_i \log(C_i) + (1-\hat{C}_i) \log(1-C_i) \right] \\ &- \sum_{i=0}^{S^2} \sum_{j=0}^K \mathbb{1}_{ij}^{obj} \sum_{c \in classes} \left[ \hat{p}_i(c) \log(p_i(c)) + (1-\hat{p}_i(c)) \log(1-p_i(c)) \right] \end{aligned} L=λcoordi=0∑S2j=0∑K1ijobj[(tx−t^x)2+(ty−t^y)2+(tw−t^w)2+(th−t^h)2]−i=0∑S2j=0∑K1ijobj[C^ilog(Ci)+(1−C^i)log(1−Ci)]−λnoobji=0∑S2j=0∑K1ijnoobj[C^ilog(Ci)+(1−C^i)log(1−Ci)]−i=0∑S2j=0∑K1ijobjc∈classes∑[p^i(c)log(pi(c))+(1−p^i(c))log(1−pi(c))]
符号与核心解读
| 符号 | 含义 |
|---|---|
| S S S | 每个输出特征图的网格尺寸(3个尺度分别为13、26、52) |
| K K K | 每个网格的锚框数量(每个尺度3个,共9个) |
| 1 i j o b j \mathbb{1}_{ij}^{obj} 1ijobj | 指示函数:第 i i i个网格的第 j j j个锚框负责预测目标时为1(与真实框IoU最大),否则为0 |
| 1 i j n o o b j \mathbb{1}_{ij}^{noobj} 1ijnoobj | 指示函数:第 i i i个网格的第 j j j个锚框不负责目标,且与所有真实框IoU<0.5时为1,否则为0 |
| λ c o o r d = 5 \lambda_{coord}=5 λcoord=5 | 坐标损失权重,放大定位损失的重要性 |
| λ n o o b j = 0.5 \lambda_{noobj}=0.5 λnoobj=0.5 | 无目标置信度损失权重,降低负样本损失的主导性 |
| t x , t y t_x, t_y tx,ty | 锚框中心相对于网格的偏移量(sigmoid激活后 ∈ (0,1)) |
| t w , t h t_w, t_h tw,th | 锚框宽高相对于聚类锚框的对数偏移量 |
| C i C_i Ci | 预测置信度(sigmoid激活后),代表锚框包含目标的概率 |
| C ^ i \hat{C}_i C^i | 置信度真实值,有目标时为1,无目标时为0 |
| p i ( c ) p_i(c) pi(c) | 第 c c c个类别的预测概率(sigmoid激活后) |
| p ^ i ( c ) \hat{p}_i(c) p^i(c) | 类别真实值,目标属于第 c c c类时为1,否则为0 |
损失组成解析
-
坐标损失(公式第1行):
- 仅对负责目标的正样本锚框计算,采用均方误差(MSE)惩罚中心偏移和宽高误差。
- 通过 λ c o o r d = 5 \lambda_{coord}=5 λcoord=5放大权重,优先保证定位精度,延续了YOLO系列的设计逻辑。
-
置信度损失(公式第2、3行):
- 采用二元交叉熵BCE计算,替代了YOLOv2的MSE,更适合二分类的置信度预测任务。
- 分为有目标置信度损失和无目标置信度损失:
- 有目标时:惩罚正样本锚框的置信度与1的误差,让模型学习锚框包含目标的概率。
- 无目标时:用 λ n o o b j = 0.5 \lambda_{noobj}=0.5 λnoobj=0.5降低权重,仅对IoU<0.5的负样本锚框计算损失,避免大量背景锚框主导梯度。
-
分类损失(公式第4行):
- 采用**每个类别独立的二元交叉熵(BCE)**计算,替代了YOLOv2的Softmax+MSE。
- 仅对正样本锚框计算,支持多标签分类,解决了Softmax类别互斥的问题,更贴合实际检测场景。
3、YOLOv3 的核心缺陷
- 正负样本匹配策略仍较简单:仅以IoU最大的锚框作为正样本,忽略了其他高IoU的潜在正样本,正样本数量仍有限,复杂场景下易出现类别不平衡,导致小目标漏检。
- 坐标损失设计不足:仍采用MSE计算坐标损失,对不同尺度目标的误差惩罚不均衡,没有考虑预测框与真实框的IoU重叠程度、宽高比等因素,定位精度仍有提升空间。
- 特征融合不够充分:仅采用自上而下的单向FPN结构,没有自下而上的路径增强,浅层特征的语义信息不足,小目标的特征表达能力仍有局限。
- 推理速度有所下降:相比YOLOv2,网络层数更深、检测头更多,推理速度有所降低,在低算力边缘设备上的部署难度更高。
- 锚框泛化性仍受限:锚框宽高仍依赖训练集的K-means聚类结果,跨数据集、跨场景检测时,锚框与目标分布不匹配会导致检测精度大幅下降。
- 无专门的小目标优化机制:虽然多尺度输出提升了小目标检测能力,但小目标特征经过多次下采样后信息丢失仍较严重,没有针对小目标的专门增强机制,极端小目标的检测效果仍不理想。
4、与 YOLOv2 的对比提升
| 维度 | YOLOv2 | YOLOv3 | 核心提升 |
|---|---|---|---|
| 骨干网络 | DarkNet-19(19层卷积,无残差结构) | DarkNet-53(53层卷积,残差连接) | 网络深度大幅提升,特征提取能力更强,解决了深层梯度消失问题,语义特征更丰富 |
| 特征融合 | 单尺度Passthrough层融合,仅2个尺度特征 | 类FPN多尺度特征金字塔,自上而下上采样+多尺度特征拼接 | 3个尺度特征深度融合,兼顾深层语义特征与浅层细粒度特征,特征表达能力大幅提升 |
| 检测输出 | 单尺度输出(13x13),仅能适配有限尺度目标 | 3个尺度输出(13x13、26x26、52x52),分别负责大、中、小目标 | 对不同尺度目标的适配性极强,尤其是小目标检测能力实现质的飞跃 |
| 锚框设计 | 每个网格5个锚框,单尺度统一分配 | 3个尺度各3个锚框,共9个聚类锚框,按尺度匹配目标大小 | 锚框与目标尺度匹配更精准,边界框召回率大幅提升 |
| 分类方式 | Softmax多分类,要求类别互斥,仅支持单标签 | Sigmoid二元交叉熵分类,每个类别独立预测,支持多标签 | 解决了类别互斥的限制,更贴合实际场景,分类灵活性和精度更高 |
| 损失函数 | 均方误差(MSE)计算置信度和分类损失 | 二元交叉熵(BCE)计算置信度和分类损失,坐标损失保留MSE | 损失计算更贴合检测任务的二分类特性,收敛更稳定,精度更高 |
| 正负样本匹配 | 一个目标仅匹配1个IoU最大的锚框,正样本数量少 | 一个目标可匹配多个高IoU锚框,同时忽略IoU>0.5的非负样本 | 正样本数量增加,缓解了类别不平衡问题,训练效率更高 |
| 精度与速度 | COCO mAP@0.5 44.0%,Titan X上67 FPS | COCO mAP@0.5 55.3%,Titan X上30 FPS | 检测精度大幅提升,同时仍保持实时检测能力 |
| 输入适配性 | 支持32倍数的多尺度输入,单尺度输出适配性有限 | 支持32倍数的多尺度输入,多尺度输出适配不同尺寸输入 | 多尺度输入下的检测稳定性更强,不同尺寸输入的精度波动更小 |
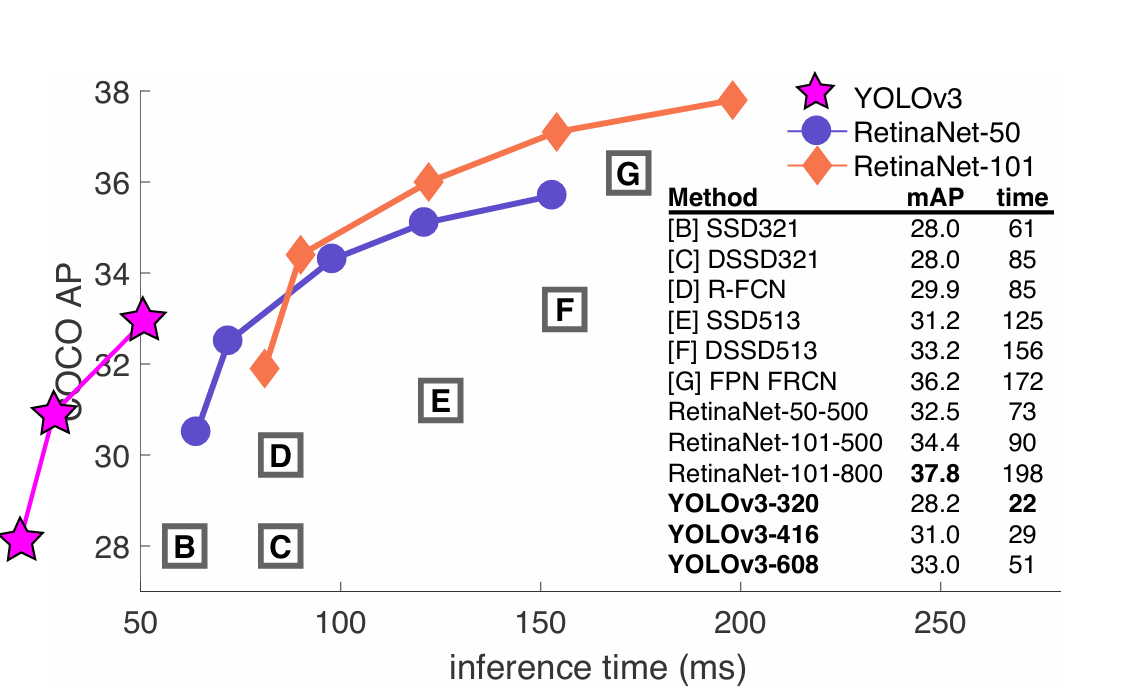
总结
YOLOv3 在 YOLOv2 的基础上,通过深层残差骨干网络、多尺度特征金字塔、多尺度锚框、二元交叉熵分类等核心改进,在保持实时检测能力的同时,大幅提升了检测精度,尤其是小目标检测能力,同时支持多标签分类,更贴合实际工业场景。YOLOv3是YOLO系列最经典的版本之一,奠定了后续YOLOv4、v5、v7等版本的核心架构基础。
5、核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# ========================================================================== #
# 1. 基础核心模块定义 #
# ========================================================================== #
class DBL(nn.Module):
"""
YOLOv3 基础卷积块: Conv2d + BatchNorm2d + LeakyReLU
对应架构图中的 "DBL"
"""
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super().__init__()
self.conv = nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
bias=False # BN包含偏置,不需要卷积bias
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.LeakyReLU(0.1, inplace=True)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class ResUnit(nn.Module):
"""
残差单元 Res_unit
结构: 1x1 DBL降维 -> 3x3 DBL升维 -> 残差Add连接
"""
def __init__(self, in_channels):
super().__init__()
# 1x1卷积降维,通道数减半
self.dbl1 = DBL(in_channels, in_channels//2, kernel_size=1)
# 3x3卷积恢复通道数
self.dbl2 = DBL(in_channels//2, in_channels, kernel_size=3, padding=1)
def forward(self, x):
residual = x
out = self.dbl1(x)
out = self.dbl2(out)
# 残差连接
out += residual
return out
class ResBlockBody(nn.Module):
"""
残差块体 Resblock_body (resn)
结构: ZeroPadding + 步长2的DBL下采样 -> 堆叠n个ResUnit
"""
def __init__(self, in_channels, out_channels, num_blocks):
super().__init__()
# 零填充 + 步长2的DBL,实现下采样
self.downsample = nn.Sequential(
nn.ZeroPad2d((1, 0, 1, 0)),
DBL(in_channels, out_channels, kernel_size=3, stride=2)
)
# 堆叠n个残差单元
self.res_blocks = nn.Sequential(
*[ResUnit(out_channels) for _ in range(num_blocks)]
)
def forward(self, x):
x = self.downsample(x)
x = self.res_blocks(x)
return x
# ========================================================================== #
# 2. DarkNet-53 骨干网络 #
# ========================================================================== #
class DarkNet53(nn.Module):
"""
YOLOv3 骨干网络 DarkNet-53
输出3个不同尺度的特征图,用于多尺度检测
"""
def __init__(self):
super().__init__()
# 初始卷积层
self.conv1 = DBL(3, 32, kernel_size=3, padding=1)
# 残差块体,对应架构图中的res1、res2、res8、res8、res4
self.resblock1 = ResBlockBody(32, 64, num_blocks=1) # res1
self.resblock2 = ResBlockBody(64, 128, num_blocks=2) # res2
self.resblock3 = ResBlockBody(128, 256, num_blocks=8) # res8 -> route_1 (1/8, 52x52)
self.resblock4 = ResBlockBody(256, 512, num_blocks=8) # res8 -> route_2 (1/16, 26x26)
self.resblock5 = ResBlockBody(512, 1024, num_blocks=4)# res4 -> route_3 (1/32, 13x13)
def forward(self, x):
"""
输入: [Batch, 3, 416, 416]
输出: 3个尺度的特征图
feat1: [B, 256, 52, 52] 1/8下采样
feat2: [B, 512, 26, 26] 1/16下采样
feat3: [B, 1024, 13, 13] 1/32下采样
"""
x = self.conv1(x)
x = self.resblock1(x)
x = self.resblock2(x)
feat1 = self.resblock3(x) # route_1
feat2 = self.resblock4(feat1) # route_2
feat3 = self.resblock5(feat2) # route_3
return feat1, feat2, feat3
# ========================================================================== #
# 3. YOLOv3 主模型定义 #
# ========================================================================== #
class YOLOv3(nn.Module):
"""
YOLOv3 完整模型定义,严格对应架构图
"""
def __init__(self, num_classes=80, num_anchors=3):
super().__init__()
self.num_classes = num_classes
self.num_anchors = num_anchors
# 最终输出通道数: 每个锚框*(4坐标 + 1置信度 + num_classes类别)
self.final_channels = num_anchors * (4 + 1 + num_classes)
# 1. 骨干网络 DarkNet-53
self.backbone = DarkNet53()
# ---------------------- 大目标检测分支 (13x13) ----------------------
# DBL*5 特征处理
self.dbl5_1 = nn.Sequential(
DBL(1024, 512, kernel_size=1),
DBL(512, 1024, kernel_size=3, padding=1),
DBL(1024, 512, kernel_size=1),
DBL(512, 1024, kernel_size=3, padding=1),
DBL(1024, 512, kernel_size=1)
)
# 检测头前的DBL
self.head_dbl_1 = DBL(512, 1024, kernel_size=3, padding=1)
# 最终预测卷积
self.pred_1 = nn.Conv2d(1024, self.final_channels, kernel_size=1)
# 上采样分支,用于和26x26特征拼接
self.upsample_conv1 = DBL(512, 256, kernel_size=1)
self.upsample1 = nn.Upsample(scale_factor=2, mode='nearest')
# ---------------------- 中目标检测分支 (26x26) ----------------------
# DBL*5 特征处理 (拼接后通道数 256+512=768)
self.dbl5_2 = nn.Sequential(
DBL(768, 256, kernel_size=1),
DBL(256, 512, kernel_size=3, padding=1),
DBL(512, 256, kernel_size=1),
DBL(256, 512, kernel_size=3, padding=1),
DBL(512, 256, kernel_size=1)
)
# 检测头前的DBL
self.head_dbl_2 = DBL(256, 512, kernel_size=3, padding=1)
# 最终预测卷积
self.pred_2 = nn.Conv2d(512, self.final_channels, kernel_size=1)
# 上采样分支,用于和52x52特征拼接
self.upsample_conv2 = DBL(256, 128, kernel_size=1)
self.upsample2 = nn.Upsample(scale_factor=2, mode='nearest')
# ---------------------- 小目标检测分支 (52x52) ----------------------
# DBL*5 特征处理 (拼接后通道数 128+256=384)
self.dbl5_3 = nn.Sequential(
DBL(384, 128, kernel_size=1),
DBL(128, 256, kernel_size=3, padding=1),
DBL(256, 128, kernel_size=1),
DBL(128, 256, kernel_size=3, padding=1),
DBL(256, 128, kernel_size=1)
)
# 检测头前的DBL
self.head_dbl_3 = DBL(128, 256, kernel_size=3, padding=1)
# 最终预测卷积
self.pred_3 = nn.Conv2d(256, self.final_channels, kernel_size=1)
def forward(self, x):
"""
输入: [Batch, 3, 416, 416]
输出: 3个尺度的预测结果,格式为 [Batch, H, W, num_anchors*(5+num_classes)]
"""
# 1. 骨干网络提取多尺度特征
feat1, feat2, feat3 = self.backbone(x)
# ---------------------- 大目标分支处理 ----------------------
x1 = self.dbl5_1(feat3)
# 大目标检测输出
out1 = self.pred_1(self.head_dbl_1(x1))
# 上采样准备拼接
x1_up = self.upsample1(self.upsample_conv1(x1))
# ---------------------- 中目标分支处理 ----------------------
# 特征拼接: 上采样后的x1_up + feat2
x2 = torch.cat([x1_up, feat2], dim=1)
x2 = self.dbl5_2(x2)
# 中目标检测输出
out2 = self.pred_2(self.head_dbl_2(x2))
# 上采样准备拼接
x2_up = self.upsample2(self.upsample_conv2(x2))
# ---------------------- 小目标分支处理 ----------------------
# 特征拼接: 上采样后的x2_up + feat1
x3 = torch.cat([x2_up, feat1], dim=1)
x3 = self.dbl5_3(x3)
# 小目标检测输出
out3 = self.pred_3(self.head_dbl_3(x3))
# ---------------------- 调整输出格式 ----------------------
# 将 [B, C, H, W] 调整为 [B, H, W, C],方便后续处理
out1 = out1.permute(0, 2, 3, 1).contiguous()
out2 = out2.permute(0, 2, 3, 1).contiguous()
out3 = out3.permute(0, 2, 3, 1).contiguous()
# 返回3个尺度的输出,对应架构图的y1、y2、y3
return out1, out2, out3
# ========================================================================== #
# 4. YOLOv3 损失函数 #
# ========================================================================== #
def compute_iou(boxes1, boxes2):
"""
计算两组框的IoU,框格式为 (x_center, y_center, w, h)
"""
b1_x1 = boxes1[..., 0:1] - boxes1[..., 2:3] / 2
b1_y1 = boxes1[..., 1:2] - boxes1[..., 3:4] / 2
b1_x2 = boxes1[..., 0:1] + boxes1[..., 2:3] / 2
b1_y2 = boxes1[..., 1:2] + boxes1[..., 3:4] / 2
b2_x1 = boxes2[..., 0:1] - boxes2[..., 2:3] / 2
b2_y1 = boxes2[..., 1:2] - boxes2[..., 3:4] / 2
b2_x2 = boxes2[..., 0:1] + boxes2[..., 2:3] / 2
b2_y2 = boxes2[..., 1:2] + boxes2[..., 3:4] / 2
inter_x1 = torch.max(b1_x1, b2_x1)
inter_y1 = torch.max(b1_y1, b2_y1)
inter_x2 = torch.min(b1_x2, b2_x2)
inter_y2 = torch.min(b1_y2, b2_y2)
inter_w = torch.clamp(inter_x2 - inter_x1, min=0)
inter_h = torch.clamp(inter_y2 - inter_y1, min=0)
inter_area = inter_w * inter_h
b1_area = (b1_x2 - b1_x1) * (b1_y2 - b1_y1)
b2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1)
union_area = b1_area + b2_area - inter_area + 1e-6
return inter_area / union_area
class YOLOv3Loss(nn.Module):
"""
YOLOv3 损失函数,严格对应官方实现
"""
def __init__(self, num_classes=80, anchors=None, img_size=416,
lambda_coord=5, lambda_noobj=0.5, ignore_thresh=0.5):
super().__init__()
self.num_classes = num_classes
self.img_size = img_size
self.lambda_coord = lambda_coord
self.lambda_noobj = lambda_noobj
self.ignore_thresh = ignore_thresh # IoU超过该值的锚框忽略损失
# 官方COCO数据集预定义的9个锚框,格式为(w, h),对应特征图尺度
if anchors is None:
self.anchors = torch.tensor([
# 大尺度13x13 大锚框
[[116, 90], [156, 198], [373, 326]],
# 中尺度26x26 中锚框
[[30, 61], [62, 45], [59, 119]],
# 小尺度52x52 小锚框
[[10, 13], [16, 30], [33, 23]]
], dtype=torch.float32)
else:
self.anchors = anchors
# 3个输出尺度
self.strides = [32, 16, 8] # 每个尺度的下采样倍率
def forward(self, predictions, targets):
"""
计算总损失
参数:
predictions: 模型输出的3个尺度预测结果,格式为 (out1, out2, out3)
targets: 真实标签,格式为 [Batch, N, 5],每个标签为 (x, y, w, h, class_id),归一化坐标[0,1]
返回:
total_loss: 总损失
"""
device = predictions[0].device
self.anchors = self.anchors.to(device)
BATCH_SIZE = predictions[0].size(0)
# 初始化损失
loss_coord = torch.tensor(0., device=device)
loss_conf_obj = torch.tensor(0., device=device)
loss_conf_noobj = torch.tensor(0., device=device)
loss_cls = torch.tensor(0., device=device)
# 遍历每个尺度的预测结果
for scale_idx, pred in enumerate(predictions):
# 当前尺度的参数
stride = self.strides[scale_idx]
anchors = self.anchors[scale_idx] / stride # 锚框转换为当前特征图尺度
S = pred.size(1) # 特征图尺寸 13/26/52
K = anchors.size(0) # 每个网格3个锚框
# 重塑预测结果 [B, S, S, K*(5+C)] -> [B, S, S, K, 5+C]
pred = pred.view(BATCH_SIZE, S, S, K, 5 + self.num_classes)
# 分离预测内容
pred_xy = torch.sigmoid(pred[..., 0:2]) # 中心偏移 tx, ty
pred_wh = pred[..., 2:4] # 宽高偏移 tw, th
pred_conf = torch.sigmoid(pred[..., 4:5]) # 置信度
pred_cls = torch.sigmoid(pred[..., 5:]) # 类别概率
# 构建网格坐标
grid_y, grid_x = torch.meshgrid([torch.arange(S), torch.arange(S)], indexing='ij')
grid_xy = torch.stack([grid_x, grid_y], dim=-1).float().to(device)
grid_xy = grid_xy.unsqueeze(0).unsqueeze(3) # [1, S, S, 1, 2]
# 解码预测框,用于计算IoU
pred_box_xy = pred_xy + grid_xy
pred_box_wh = torch.exp(pred_wh) * anchors.unsqueeze(0).unsqueeze(0).unsqueeze(0)
pred_boxes = torch.cat([pred_box_xy, pred_box_wh], dim=-1)
# 初始化掩码
obj_mask = torch.zeros_like(pred_conf) # 正样本掩码
noobj_mask = torch.ones_like(pred_conf) # 负样本掩码
txy = torch.zeros_like(pred_xy)
twh = torch.zeros_like(pred_wh)
tconf = torch.zeros_like(pred_conf)
tcls = torch.zeros_like(pred_cls)
# 遍历每个batch的标签
for b in range(BATCH_SIZE):
gt_boxes = targets[b]
# 过滤掉填充的空标签
gt_boxes = gt_boxes[gt_boxes[:, 4] >= 0]
if len(gt_boxes) == 0:
continue
# 转换真实框到当前特征图尺度
gx = gt_boxes[:, 0:1] * S
gy = gt_boxes[:, 1:2] * S
gw = gt_boxes[:, 2:3] * S
gh = gt_boxes[:, 3:4] * S
cls_ids = gt_boxes[:, 4].long()
# 真实框坐标
gt_box_xy = torch.cat([gx, gy], dim=-1)
gt_box_wh = torch.cat([gw, gh], dim=-1)
gt_boxes = torch.cat([gt_box_xy, gt_box_wh], dim=-1)
# 找到目标所在的网格
gi = gx.long().clamp(0, S-1)
gj = gy.long().clamp(0, S-1)
# 计算真实框与所有锚框的IoU
gt_box_anchor = torch.cat([torch.zeros_like(gt_box_wh), gt_box_wh], dim=-1)
anchor_boxes = torch.cat([torch.zeros_like(anchors), anchors], dim=-1)
ious = compute_iou(gt_box_anchor.unsqueeze(1), anchor_boxes.unsqueeze(0)).squeeze(-1)
# 找到每个真实框匹配的最佳锚框
best_ious, best_k = torch.max(ious, dim=-1)
# 标记正样本和忽略样本
for i in range(len(gt_boxes)):
gj_i, gi_i, k_i = gj[i, 0], gi[i, 0], best_k[i]
# 标记正样本
obj_mask[b, gj_i, gi_i, k_i] = 1
noobj_mask[b, gj_i, gi_i, k_i] = 0
# 忽略IoU超过阈值的锚框
noobj_mask[b, gj_i, gi_i, ious[i] > self.ignore_thresh] = 0
# 计算真实偏移量
txy[b, gj_i, gi_i, k_i, 0] = gx[i, 0] - gi_i
txy[b, gj_i, gi_i, k_i, 1] = gy[i, 0] - gj_i
twh[b, gj_i, gi_i, k_i, 0] = torch.log(gw[i, 0] / anchors[k_i, 0] + 1e-6)
twh[b, gj_i, gi_i, k_i, 1] = torch.log(gh[i, 0] / anchors[k_i, 1] + 1e-6)
# 置信度目标
tconf[b, gj_i, gi_i, k_i] = 1
# 类别目标
tcls[b, gj_i, gi_i, k_i, cls_ids[i]] = 1
# 计算当前尺度的损失
# 坐标损失
loss_coord += self.lambda_coord * (
F.mse_loss(obj_mask * pred_xy, obj_mask * txy, reduction='sum') +
F.mse_loss(obj_mask * pred_wh, obj_mask * twh, reduction='sum')
)
# 置信度损失
loss_conf_obj += F.binary_cross_entropy(pred_conf, tconf, weight=obj_mask, reduction='sum')
loss_conf_noobj += self.lambda_noobj * F.binary_cross_entropy(pred_conf, tconf, weight=noobj_mask, reduction='sum')
# 分类损失
loss_cls += F.binary_cross_entropy(pred_cls, tcls, weight=obj_mask, reduction='sum')
# 总损失,除以batch_size平均
total_loss = (loss_coord + loss_conf_obj + loss_conf_noobj + loss_cls) / BATCH_SIZE
return total_loss
# ------------------------------
# 测试代码
# ------------------------------
if __name__ == "__main__":
# 1. 定义模型
model = YOLOv3(num_classes=80)
print("✅ YOLOv3 模型定义成功")
# 2. 定义损失函数
criterion = YOLOv3Loss(num_classes=80)
print("✅ YOLOv3 损失函数定义成功")
# 3. 模拟输入
dummy_img = torch.randn(2, 3, 416, 416) # Batch=2, 3通道, 416x416
dummy_target = torch.zeros(2, 10, 5) # 每个batch最多10个目标
dummy_target[0, 0] = torch.tensor([0.5, 0.5, 0.2, 0.3, 5]) # 示例目标
# 4. 前向传播测试
with torch.no_grad():
out1, out2, out3 = model(dummy_img)
print(f"输入维度: {dummy_img.shape}")
print(f"大目标输出y1维度: {out1.shape}")
print(f"中目标输出y2维度: {out2.shape}")
print(f"小目标输出y3维度: {out3.shape}")
print("🎉 模型前向传播正常!")
# 5. 损失计算测试
predictions = model(dummy_img)
loss = criterion(predictions, dummy_target)
print(f"测试损失值: {loss.item():.4f}")
print("🎉 损失函数计算正常!")

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)