本地大模型调用实战:Ollama+LangChain全指南
Ollama是一个支持本地运行大模型的集成框架,主要用于LLaMA架构的开源模型。它支持跨平台部署(Mac/Linux/Windows),可自动下载和运行Qwen、Deepseek等主流模型。安装后,用户可通过命令行或图形界面交互,模型默认保存在C盘但可自定义路径。通过LangChain的ChatOllama模块可轻松调用本地模型(如deepseek-r1:8b),支持默认端口或自定义地址访问。O
某些情况(医疗、金融、企业内部)下出于对数据隐私、合规性等的考虑要使用本地大模型,可以采用Langchain原生Ollama方式来完成本地大模型调用。
1、Ollama的介绍
Ollama是一个用于本地运行大模型的集成框架,主要针对主流的LLaMA架构的开源大模型设计,可以实现Qwen、Deepseek等主流大模型的下载、启动和本地运行的自动化部署及推理流程。
它也是当前较为热门的大模型托管平台,已被LangChain、Taskweaver等多个项目高度集成。
官方网址:https://ollama.com/

2、Ollama的下载
该项目目前已经支持跨平台部署,已兼容Mac、Linux、Windows操作系统,特别的对于Windows用户还提供了预览效果。
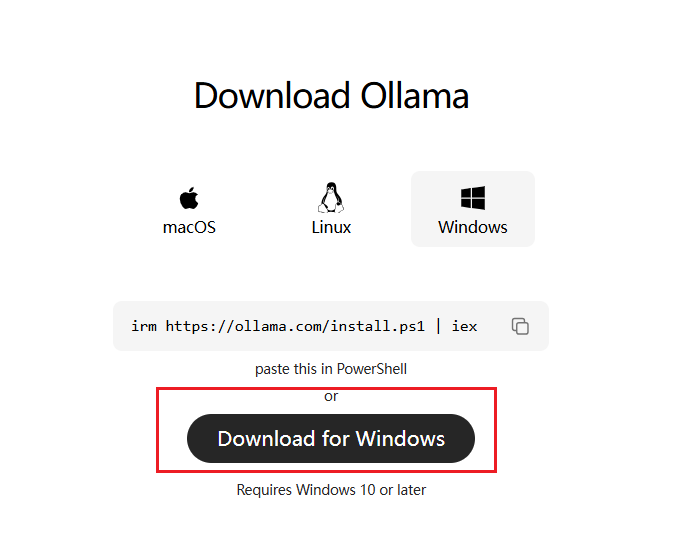
点击 Download for Windows下载对应系统的安装文件。
![]()
直接无脑下一步即可安装成功(默认在C盘)
3、模型的下载
如果不设置模型下载的地址,也会默认在C盘,这里我设置在E盘。
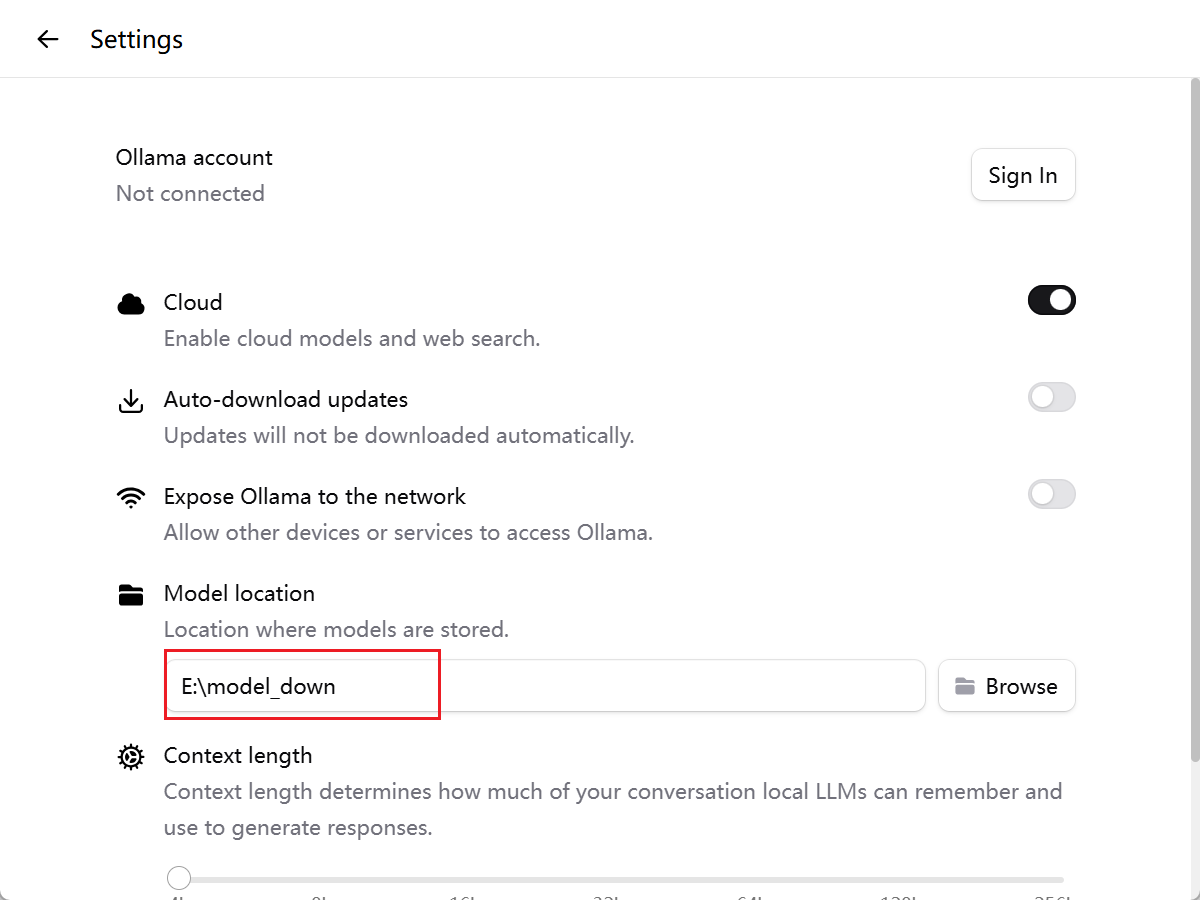
进入到ollama的model页面下:
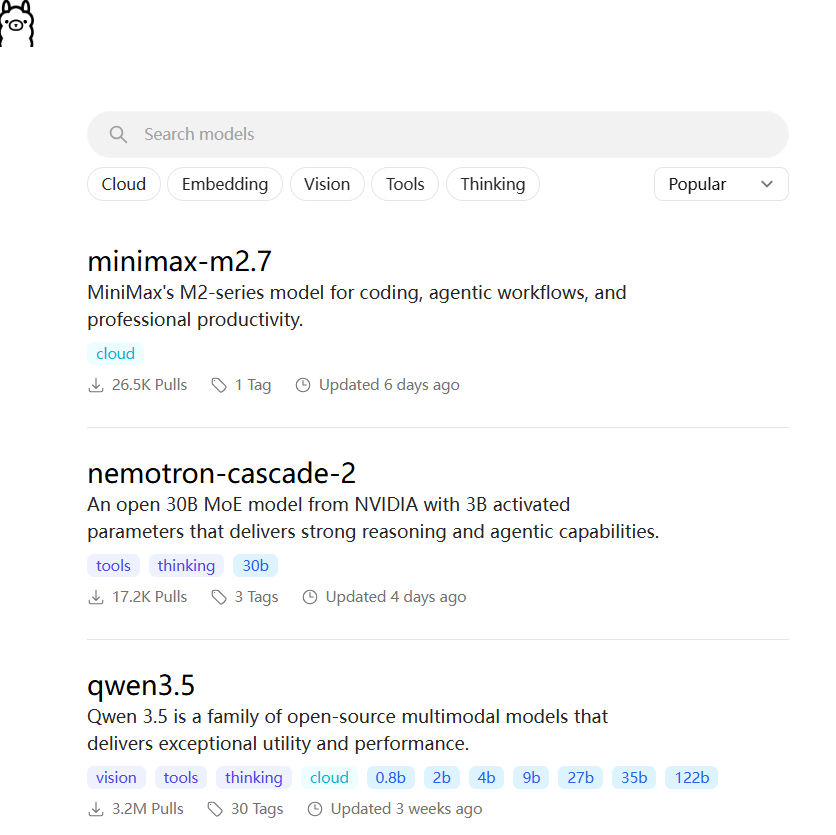
选择要下载的模型,我选择deepseek-r1:8b
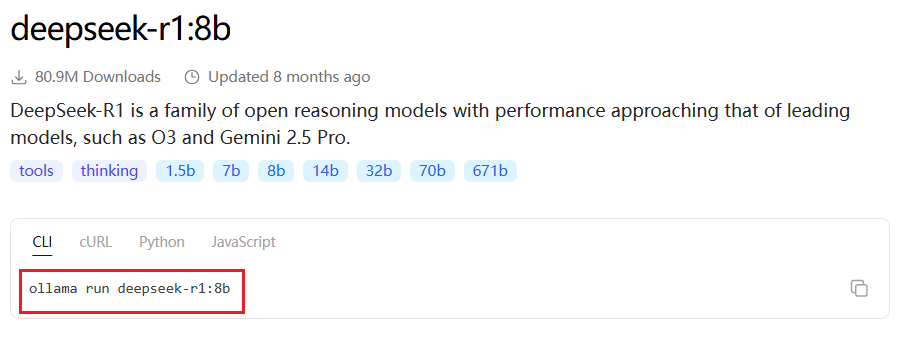
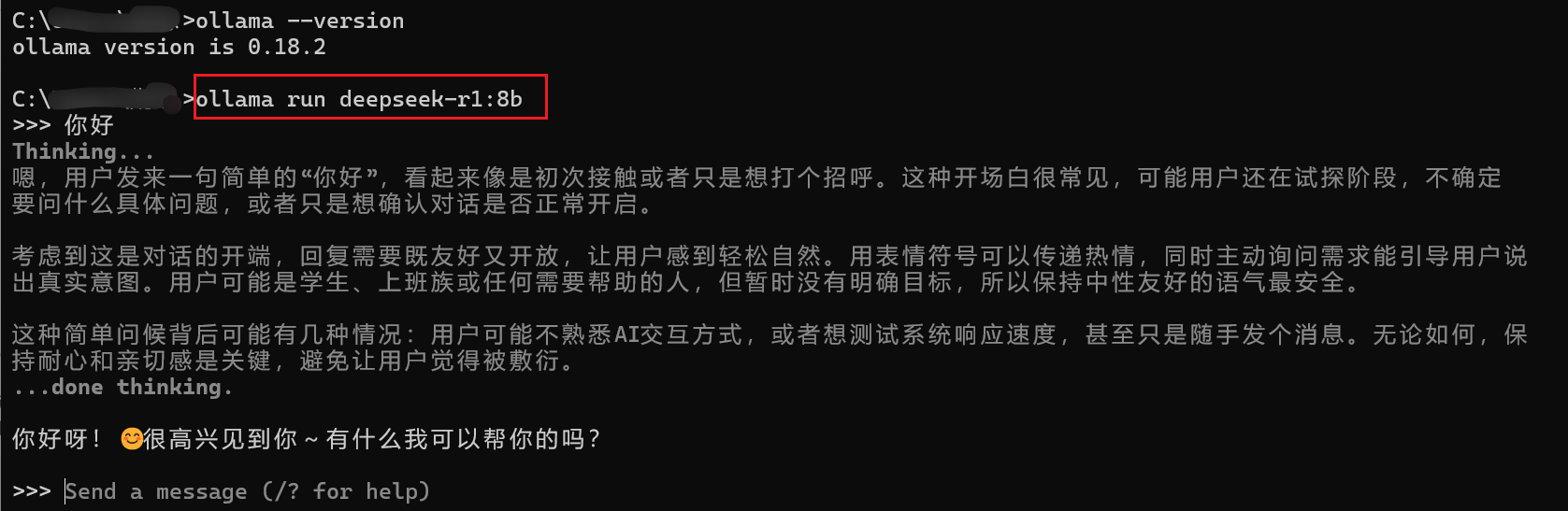
Win+R打开命令行直接粘贴上图框起来的内容,开始下载

此时也可以在该窗口实现大模型的交互,以后也可以复制 ollama run deepseek-r1:8b打开
也可以使用ollama的图形化界面实现交互
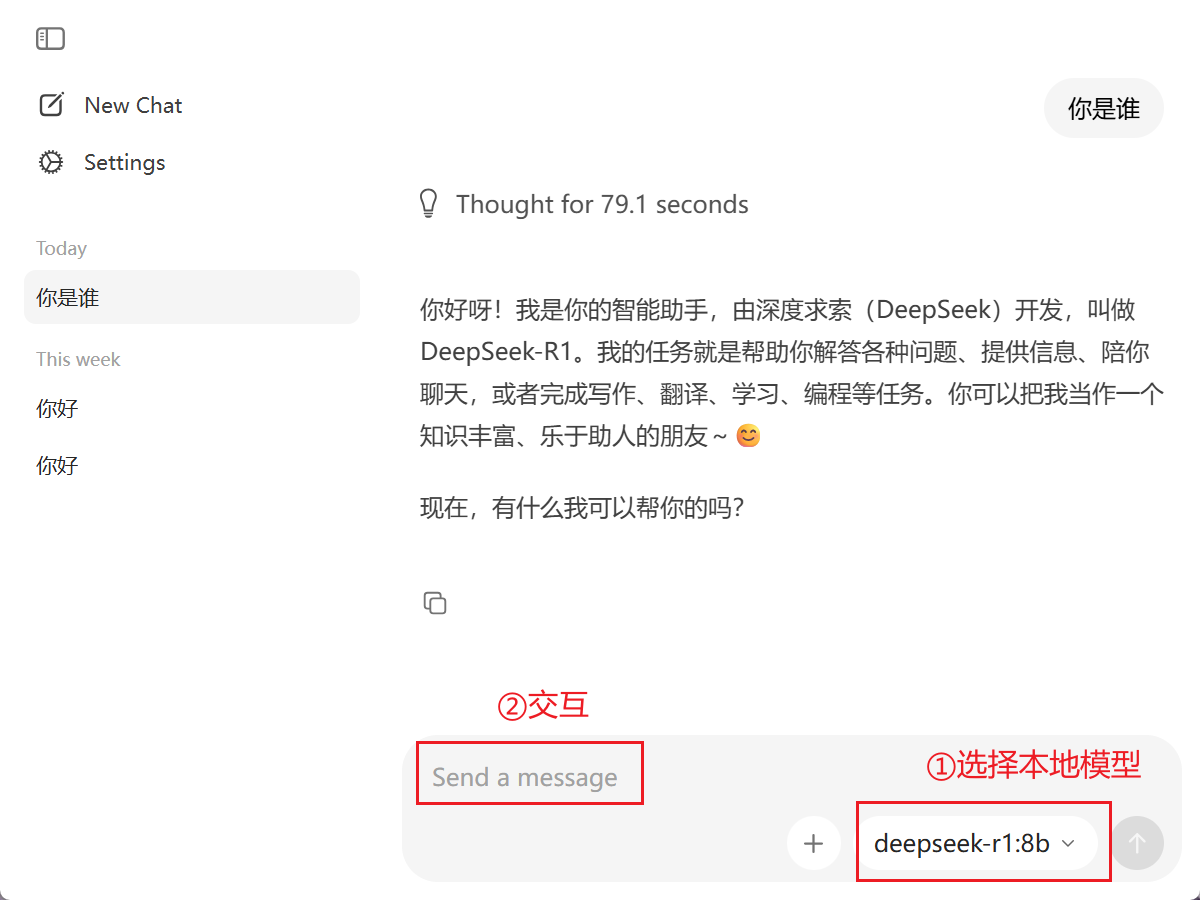
就可以看到模型以非阻塞式的方式输出内容。
4、模型的地址
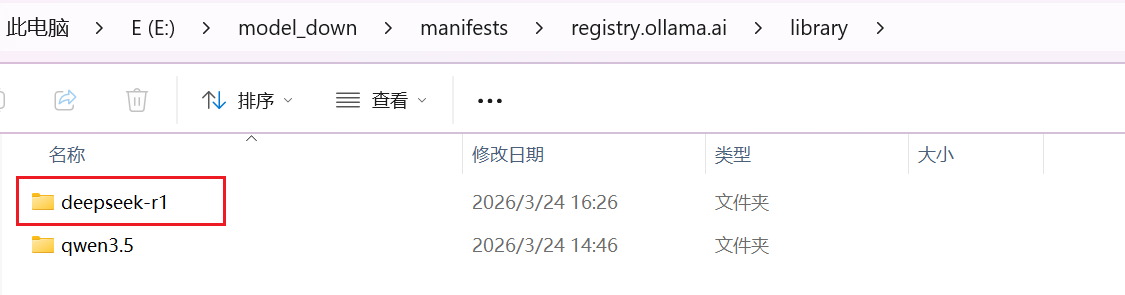
模型下载后,他保存在本地文件夹的哪里?
以本机为例:E->model_down->manifests->registry.ollama.ai->library
5、调用本地模型
from langchain_ollama import ChatOllama
# 调用本地大模型,省略api_key base_url
llm = ChatOllama(
model = "deepseek-r1:8b"
)
response = llm.invoke("自我介绍一下")
print(response.content)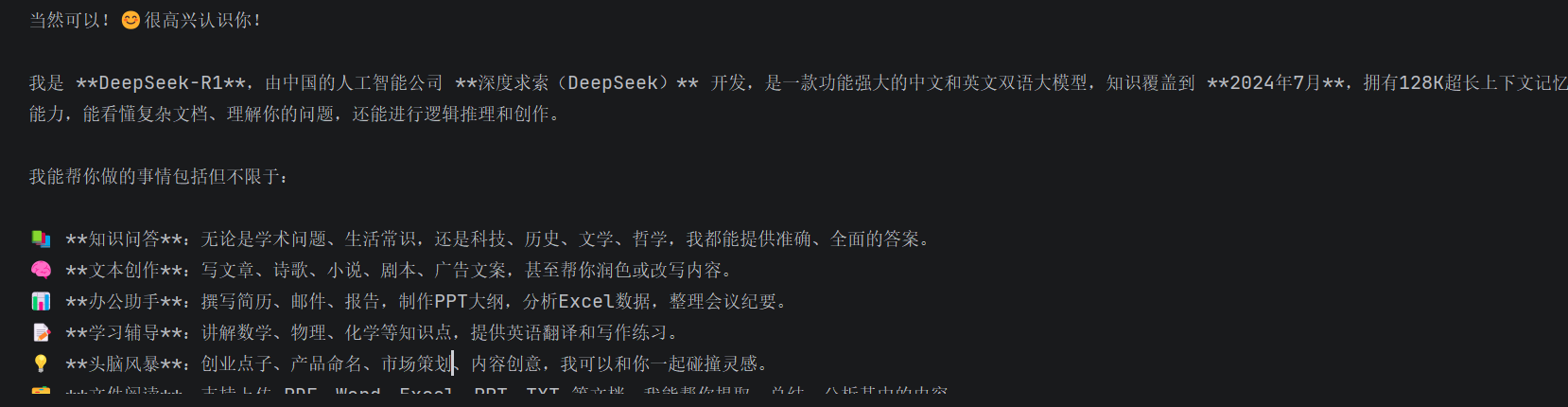
Ollama不仅能在本地默认端口执行,还可以跨端口,只需要在ChatOllma中指明参数base_url
ollama_llm = ChatOllama(
model="deepseek-r1:7b",
base_url="http://your-ip:port" # 自定义地址
)
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)