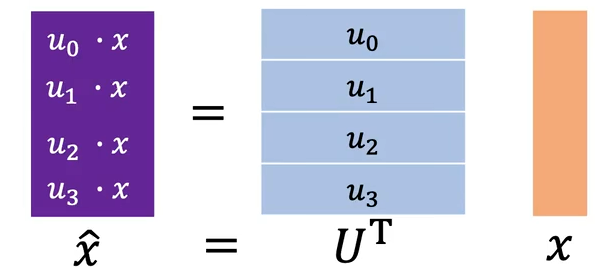
图神经网络(GNN)
GNN 处理的图 (Graph) 是非欧几里得结构化数据,数学表示:
:顶点 / 节点集合,每个节点可自带属性特征
:边集合,代表节点之间的关联、交互、约束关系
- 节点无序、每个节点的邻居数量不固定、拓扑结构不规则(区别于图像 / 文本这种规整数据)。
现实生活中,图的应用广泛:
- 分子化学图:节点 = 原子,边 = 化学键(药物分子筛选、材料性能预测
- 社交网络图:节点 = 用户,边 = 好友 / 互动关系(用户画像、社群分类)
- 交通路网图:节点 = 十字路口,边 = 通行道路、车流关联
- 电商推荐图:节点 = 用户 / 商品,边 = 点击、收藏、购买行为
- 通信网络:节点 = 基站 / 设备,边 = 数据传输链路
GNN的设计用于解决三个主要问题:
- 无法处理图结构数据:CNN只适配图像这种规整网格数据,RNN仅适配一维链式序列,不能建模环形、多分支、复杂网状结构。但是现实世界绝大多数复杂系统不是孤立个体,而是 “实体 + 关系” 构成的图结构,表格 / 向量无法精准表达,所以必须要有一种能处理图的神经网络结构,GNN应运而生。
- 计算量过大:早期图算法(如谱聚类、初代谱域 GCN)依赖全图训练,当图规模达到万级、百万级时,计算量、内存开销会呈指数级增长。以 GraphSAGE、PinSAGE 为代表的采样式 GNN,通过 “邻域采样 + 小批量训练”,无需全图加载,仅采样部分邻居节点完成训练,大幅降低计算成本。
- 标签不足:现实场景中,标注数据的获取成本极高(如药物分子的活性标注、社交用户的兴趣分类、知识图谱的实体标注),绝大多数节点都是无标签的,传统监督学习模型完全无法训练。GNN 天然适配半监督 / 自监督学习,图的拓扑结构让标注节点的信息可以通过连接传播到整个图,仅用少量标注节点就能训练模型,完成对大量无标注节点的预测;同时自监督 GNN(如 GraphMAE、SimGRACE)可以利用图结构本身做预训练,完全无需标注,进一步解决标签稀缺问题。
GNN主要的思路是 “消息传递及邻域聚合” ,即先每个节点生成初始特征向量,然后通过非线性变换聚合相邻节点的特征信息,迭代更新将拓扑结构融入自身特征向量,通过多层神经网络堆叠学习浅层及深层信息。它的设计原则如下:
- 局部相关性:模仿 CNN,每个节点聚合多个邻居的局部信息
- 参数共享:不同子图共用神经网络权重,减少参数量、提升泛化
- 置换不变性:打乱节点排序,模型输出结果不变,适配图的无序特性
- 分层感受野:堆叠网络层数,从局部结构逐步捕捉全局长距离依赖
GNN 四大类核心任务,涵盖了绝大多数图学习场景:
- Supervised classification(监督分类):
- 适用场景:有完整标注的图数据,如分子活性分类、社交网络用户兴趣分类
- 任务类型:节点分类、边分类、全图分类
- Semi-Supervised Learning(半监督学习):
- 适用场景:仅少量节点有标注,绝大多数无标注,是 GNN 最核心的优势场景
- 代表模型:GCN,利用图结构将标注信息传播到全图,仅用少量标注即可完成模型训练
- Representation learning(表征学习):
- 适用场景:无标注数据,学习图 / 节点的低维表征(Embedding),用于下游任务
- 代表方法:Graph InfoMax(图信息最大化),通过最大化局部与全局的互信息,实现无标注图的自监督表征学习
- Generation(图生成):
- 适用场景:生成全新的图结构,如设计新药物分子、生成新社交网络拓扑
- 代表模型:GraphVAE(图变分自编码器)、MolGAN(分子生成 GAN),是生物医药研发、新材料设计的核心技术
CNN是一套通用的局部特征提取范式,它只聚合局部邻域的信息,符合 “空间上相邻的元素相关性更高” 的物理规律,并且同一个卷积核在全图复用,参数量仅由卷积核大小决定。CNN的这些优势符合处理图数据的基本要求,所以现在问题变成了如何把 CNN 的卷积操作从 “规则图像网格”推广到 “不规则图结构”。
对于图像卷积而言它使用固定大小卷积核,邻居位置固定、顺序固定,直接做加权求和即可提取局部特征,但是图结构拓扑完全不规则,每个节点的邻居数量不固定、顺序无意义,没有天然的网格坐标,直接套用图像卷积完全不可行。以下给出两种经典解决方案:
空间域(Spatial-based)卷积
在图的原始拓扑空间上,把 “卷积” 定义为 “节点对邻居的特征聚合操作”。简单来说,对于一个节点,将图上与其具有连接关系的节点加权融合。空间域卷积的核心是 “邻域聚合(Aggregate)” 和 “可选图读出(Readout)”:
- Aggregate(聚合):用邻居节点的特征,更新当前节点下一层的隐藏状态。对应 CNN 的 “卷积核加权求和”
- Readout(读出):把所有节点的特征集合起来,代表整个图的特征。
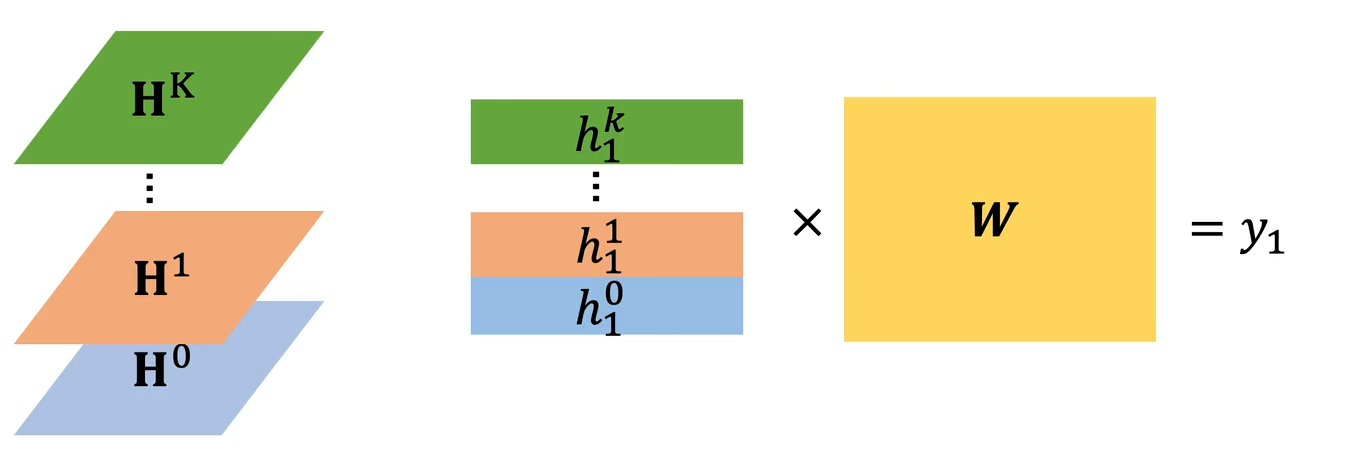
其基本过程如下图所示:
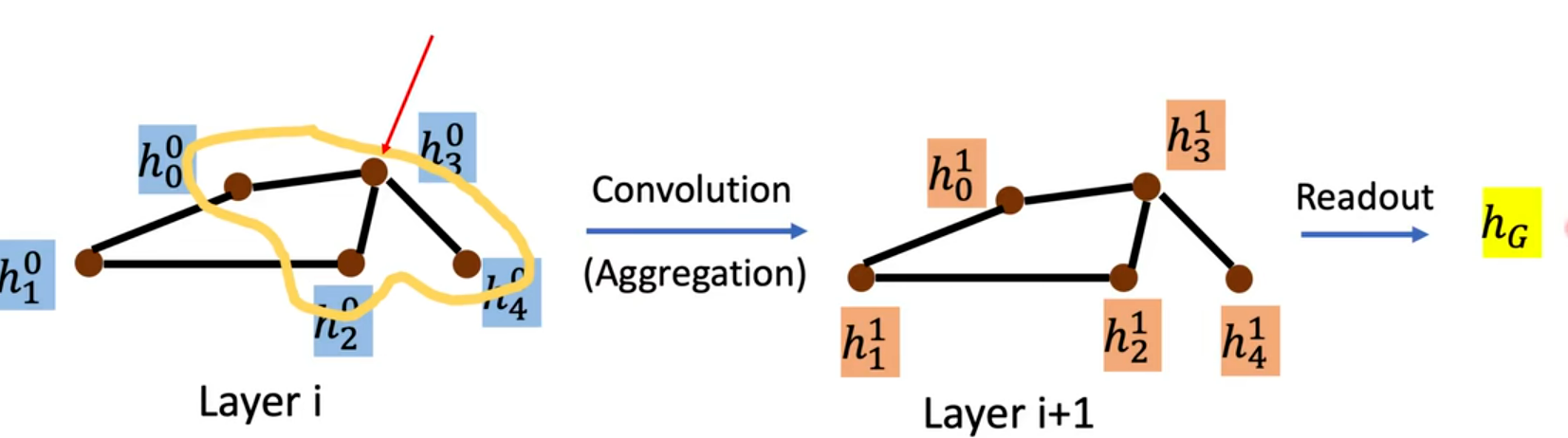
- Layer i(第 i 层,输入 / 上一层特征):棕色圆点代表节点,每个节点对应一个蓝色方块的特征向量(如
,上标0表示第 0 层的特征,下标1,2,3...表示节点编号)。黑色边线表示节点间的拓扑连接关系,定义了每个节点的邻居范围。
- Convolution (Aggregation) 卷积聚合操作:以红色箭头的中心节点 3 为例,取出它的所有邻居(节点 0、2、4)和自身的特征 ,即
。
用聚合函数(比如平均、求和等)把这些特征融合成一个向量
然后乘可训练权重,加上激活函数,得到节点 3 在 Layer i+1 的新特征
图中所有节点都重复这个过程,最终得到 Layer i+1 的全部橙色特征 - Layer i+1(第 i+1 层,输出 / 下一层特征):节点的连接关系不会因为卷积改变,改变的只有节点的特征。
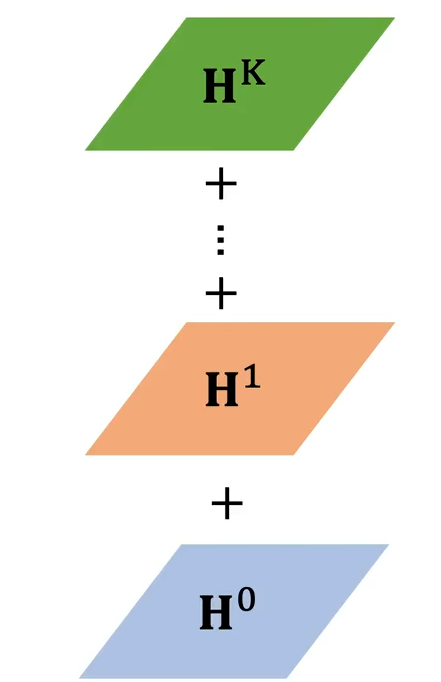
每堆叠一层 GNN,节点的 感受野 就扩大一阶。每一层仅聚合上一层的一阶邻居的特征,通过多层递归自然扩大感受野。例如1层GNN表示节点只能看到 1 阶邻居(直接相连的节点),2层GNN节点能看到2 阶邻居(邻居的邻居),k层 GNN节点能捕捉k跳范围内的局部结构 ,对应 CNN 多层卷积扩大感受野的效果。 - Readout(读出操作,可选):如果是全图任务,比如分子属性预测、图分类、图回归等需要对整个图做预测的场景,则需要将 Layer i+1 的所有节点特征,聚合成一个黄色方块的图级特征
Aggregate(聚合)数学表达如下:
:表示第
层神经网络节点
的特征向量。
:置换不变的聚合函数(如求和、平均、最大池化、注意力加权),保证打乱邻居顺序时结果不变,适配图的无序性。
:节点
:第
:非线性激活函数,引入非线性表达能力
Readout(读出)数学表达式如下:
:GNN 的总层数(最后一层)
:全局聚合函数,常用:求和(Sum)、平均(Mean)、最大池化(Max)、Set2Set、DiffPool 等
这样,GNN就有了动态卷积核,即每个节点的卷积核大小 = 该节点的邻居数,不再是固定的 3×3,完美适配图的不规则性。而且所有节点使用同一套权重,大幅降低参数量,提升泛化能力。
使用空间域卷积的代表模型有NN4G、DCNN、DGC、GraphSAGE、MoNET、GAT、GIN等
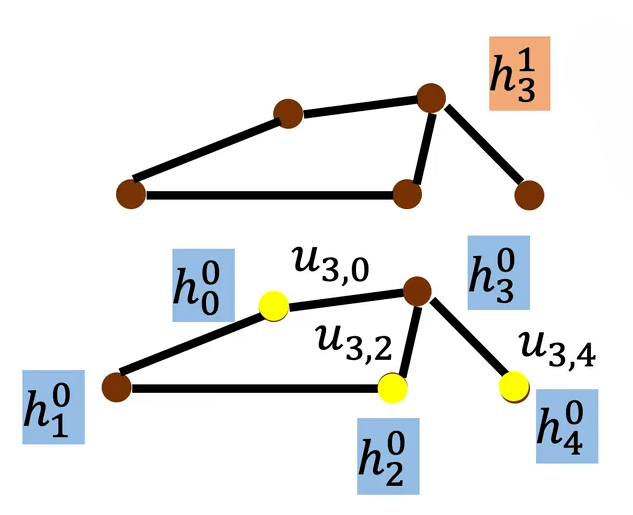
NN4G
NN4G(Neural Networks for Graph)是最早的空间域图神经网络(GNN)原型之一,核心思路非常直观,完全遵循空间域 GNN 的底层逻辑:
每个节点的新特征 = 自身原始属性的特征变换 + 所有邻居节点特征的聚合与变换
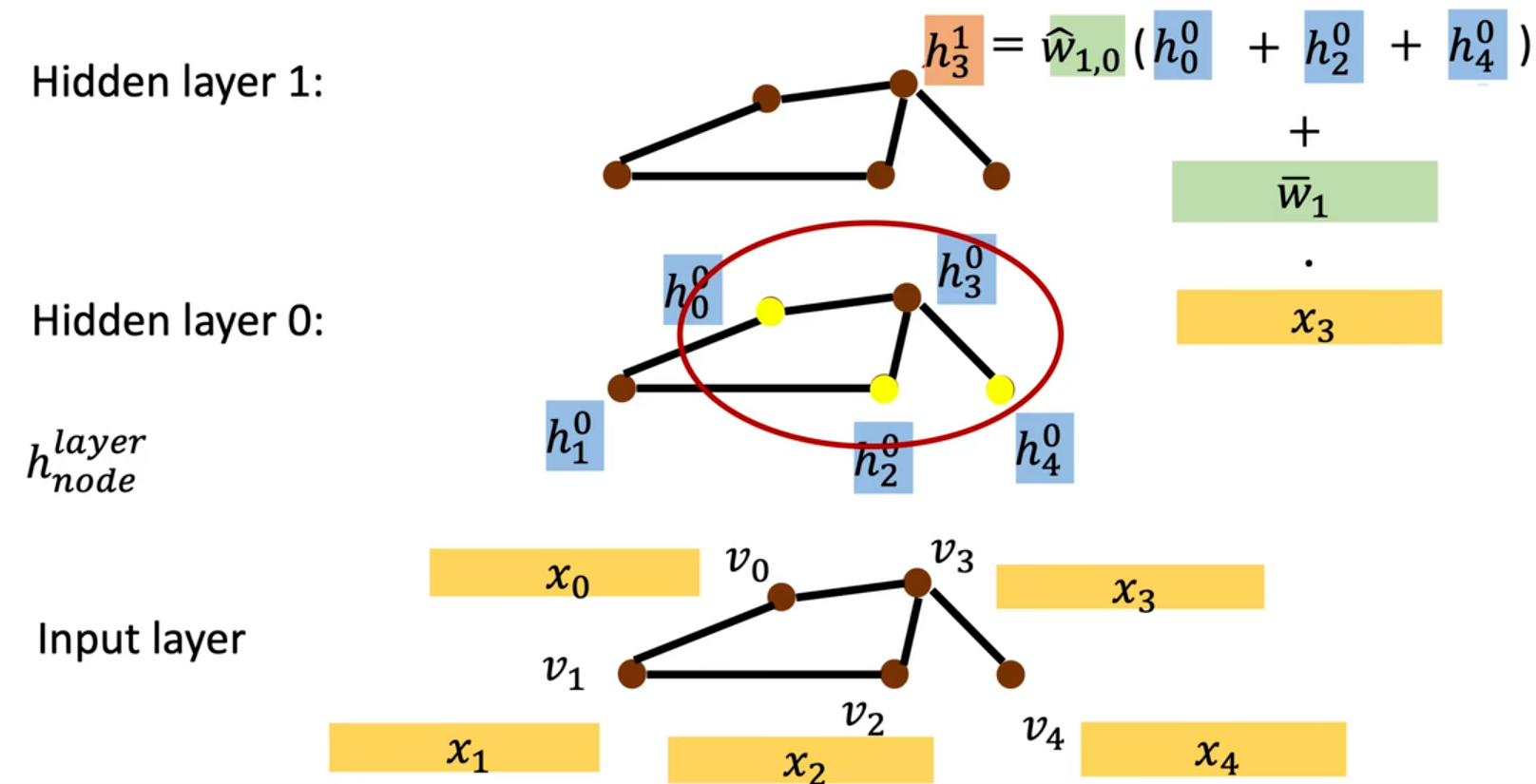
工作过程如下:
- Input Layer(输入层)—— 图的原始输入:
棕色原点为图节点,集合,每个节点
对应的原始输入特征
黑色连线代表图的边集合的邻居是
)
- Hidden Layer 0(第 0 隐藏层):
每个节点,通常
(直接用输入特征作为初始特征,或做简单的初始变换)
红色圆圈圈出了节点特征会被用来更新
- Hidden Layer 1(第 1 隐藏层)—— 特征更新步骤:以节点
邻居特征Aggregate(聚合):(求和聚合操作),
为可训练的共享权重,所有节点的邻居聚合都使用同一套权重
自身特征变换部分:,
是另一组可训练权重,对节点自身的原始属性做线性变换,保留节点的个体属性信息。
特征融合:
这个计算过程是所有节点并行执行的,图中等其他节点,也会用自己的邻居特征 + 自身输入,计算出对应的
,完成一整层的图卷积操作。
- 如果需要更大的感受野(捕捉更远的邻居信息),可以重复上述过程,堆叠更多隐藏层。每一层仅聚合上一层的一阶邻居的特征,通过多层递归自然扩大感受野
下游任务:
- 节点任务(如节点分类、链路预测):直接使用最后一层的节点特征
进行预测。
- 全图任务(如图分类、分子属性预测):通过 Readout 操作(如求和、平均)把所有节点特征聚合为图级特征
,再进行预测。如下图所示
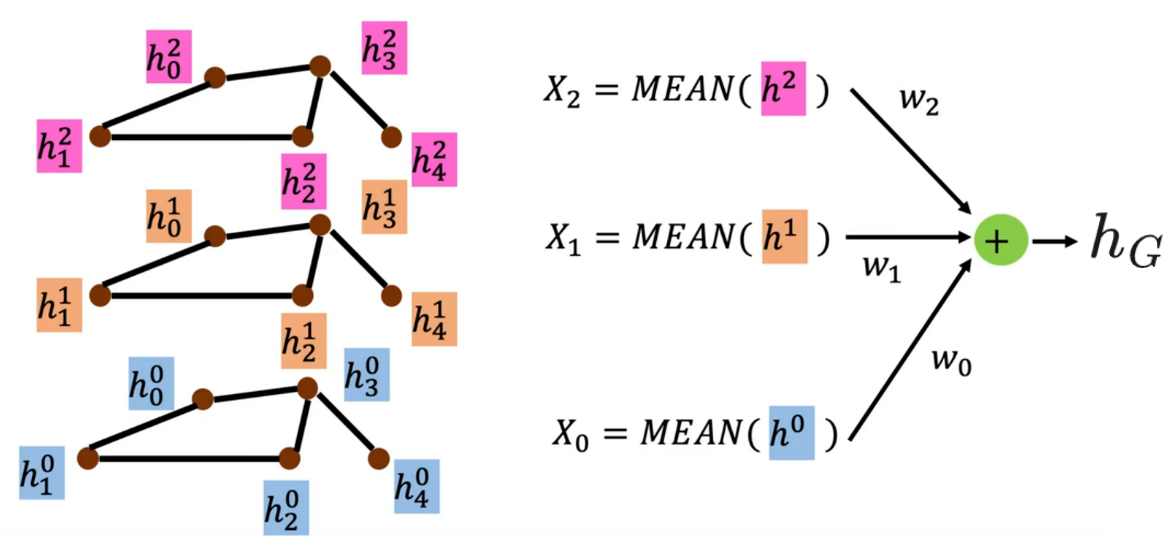
DCNN
DCNN(Diffusion-Convolutional Neural Network,扩散卷积神经网络)的核心思路是将图上的卷积操作,定义为 基于随机游走的多阶扩散过程 (动态卷积核),即让节点特征在图拓扑中做 步随机游走(信息扩散),对
阶可达的所有邻居特征做可学习的加权聚合,从而让节点特征融合多跳范围内的拓扑结构与属性信息。
扩散卷积数学定义
DCNN 的核心是基于随机游走的扩散卷积核,关键步骤:
1.定义随机游走转移矩阵
:
的矩阵
其中
是邻接矩阵,
是度矩阵。
表示从节点
一步随机游走到达节点
的概率
以无向无权图
为例,
邻接矩阵
矩阵,
表示节点
有边相连,否则为 0。
度矩阵
,即节点的度数(邻居数量)。对于上图而言:
随机游走的一步转移矩阵
对A的每一行,除以该行对应节点的度数(
),即
。以
,表示从
。
2.定义
步转移矩阵
:
为单位矩阵,代表 0 步,即节点自身)。
表示从
,表示从
的概率为
,其他节点 2 步无法到达。
3步转移矩阵:,表示从
的概率为
,到达
的概率为
的概率为
,其他节点 3 步无法到达。
3.扩散卷积公式(1 层卷积,k 步扩散):对于节点
层的特征为:
:对第
步扩散,得到节点
:可学习的共享权重,所有节点共用同一套s步权重,控制不同阶邻居的重要性
以节点
- 初始特征矩阵
- 计算各阶扩散特征(
):扩散特征
表示
(0步,自身特征):
,所以
(1步,直接邻居):
(2步,间接邻居):
- 加权求和与激活,生成新特征
是所有节点共享的可学习权重,对各阶扩散特征加权求和:
经过非线性激活函数:
- 全节点并行更新,生成
图中所有节点
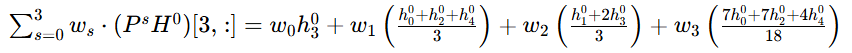
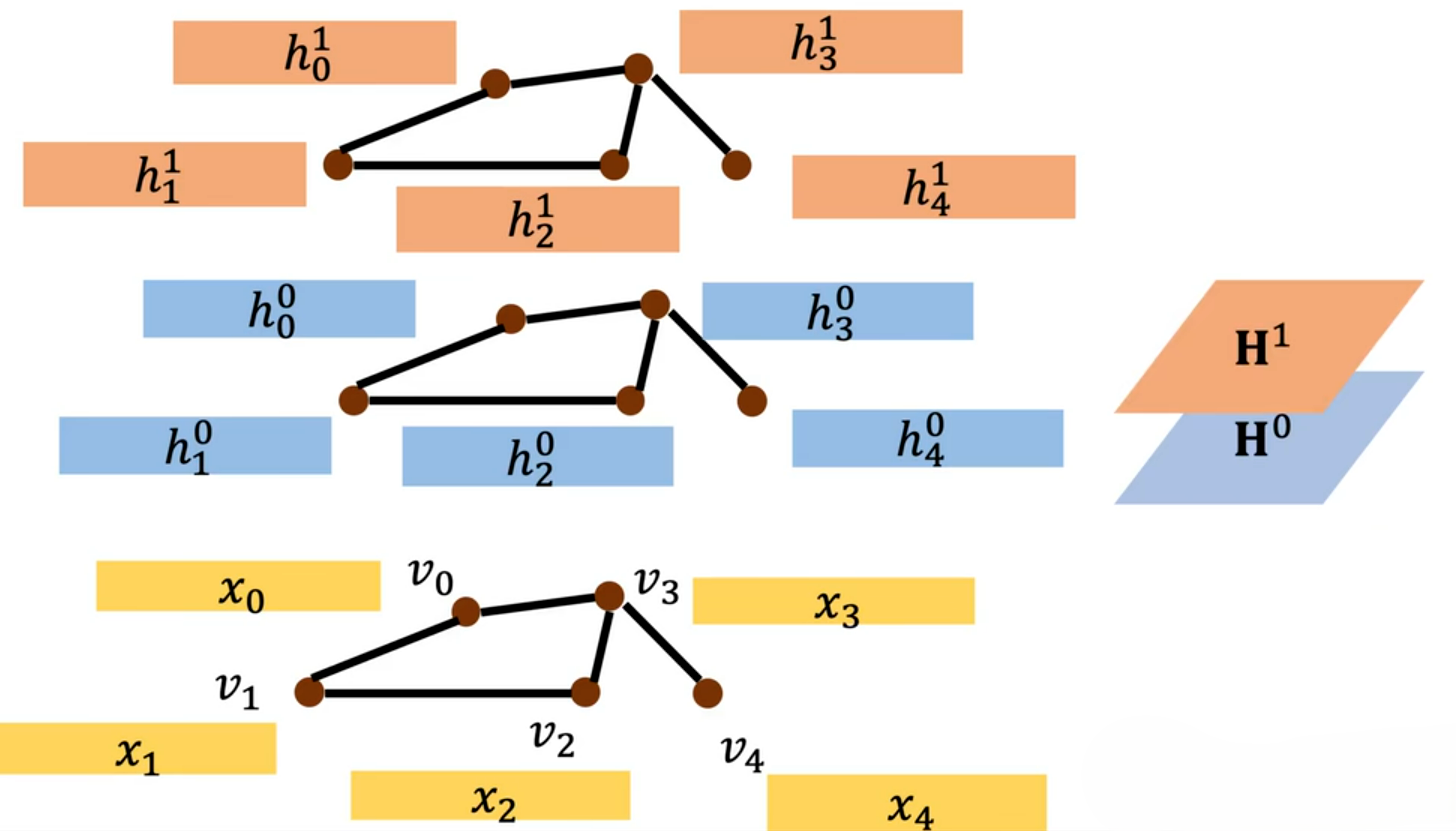
工作过程如下:
- Input Layer(输入层)—— 图的原始输入
- Hidden Layer 0(
,初始特征层):蓝色长条
是节点的第 0 层特征,通常
特征矩阵 - 扩散卷积生成 Hidden Layer 1(
可重复上述扩散卷积过程,堆叠更多隐藏层。每一层都基于上一层的特征做 步扩散,让节点的感受野逐步扩大,捕捉更远的拓扑结构信息(类似 CNN 多层卷积扩大感受野)。最终得到多阶扩散特征
。
对于每个节点单独处理,将其在 步的所有扩散特征
按顺序拼接(Concatenate),形成一个维度为
的长特征向量(
为单步特征维度),将每个节点的拼接长向量乘以大尺寸可训练权重矩阵
,得到节点的最终预测
:
DGC
DGC(Diffusion Graph Convolution,扩散图卷积)是DCNN的升级版,它与 DCNN 一样都是基于随机游走扩散的空间域图卷积模型,核心都是先对初始图特征做 步随机游走扩散,生成多阶扩散特征
。两者的核心差异在于 多阶扩散特征的融合方式:
DGC不再对每个节点做单独处理,而是直接将所有扩散特征矩阵按对应位置逐元素加权相加,得到融合后的全局特征矩阵:
- 图中简化为直接 “+”,实际
是可学习的权重,用于显式控制不同步扩散特征的重要性。
MoNET
MoNET(Mixture Model Networks,混合模型网络)是一种基于 “节点距离度量” 的加权聚合型图神经网络,它解决了传统 GNN(如 NN4G、DCNN)仅用简单求和 / 平均聚合邻居信息的缺陷。
其核心思路可以概括为两点:
- 定义节点 “距离” 度量:
为图中的节点对定义一个特定的距离向量
,该向量包含了基于节点度的归一化信息(
),用于量化两个节点之间的结构相似性。
- 加权求和聚合:
不再对邻居特征进行无差别的简单求和或平均,而是通过一个神经网络学习节点对的距离权重。利用学习到的权重,对邻居特征进行加权线性融合,从而自适应地决定哪些邻居更重要、贡献更大。
早期空间域 GNN(如 NN4G、简单平均聚合)对所有邻居一视同仁,不管邻居是度大的枢纽节点还是度小的普通节点,都用相同的权重求和 / 平均,这会导致度大的节点特征会主导聚合,普通节点的信息被稀释,模型无法区分邻居的重要性。具体体现为高度数节点每一层聚合都会向周围大量节点灌输自己的特征,而低度数节点只有少量邻居,发声权重极低,几层传播后个性特征被彻底同化、抹除,并且度很大的节点,求和聚合时会累加几十上百个邻居特征,特征向量数值增长远快于低度数节点。
MoNET使用节点距离向量衡量不同度节点的贡献:
表示中心节点,也就是我们要更新特征的目标节点,
表示邻居节点与
每一条连接表示节点
表示节点
- 度越大的点,
越小,对聚合的权重贡献降低;度越小的点
以节点 为例说明其工作过程(初始特征
):
- 定义节点距离向量
节点
节点
节点 - 学习权重与加权聚合:
权重生成函数,输出一个标量权重,网络自动学习距离
会输出更大的权重;反之则权重更小。
通过 - 图中的其他节点(
GraphSAGE
GraphSAGE(SAmple and aggreGatE Graph Embedding)是空间域图神经网络的里程碑式模型(2017 年提出),核心目标是解决传统 GNN(如 GCN)的两大问题:
- 依赖全图拓扑,只能处理训练时的固定图,无法泛化到训练后新增的节点 / 新图
- 对于具有百万级节点的大规模图会导致内存爆炸,无法训练
它的核心设计思路是不再依赖全图拓扑,而是对每个节点 “采样固定数量的多阶邻居”,再通过可学习的聚合函数融合邻居特征,生成节点嵌入。
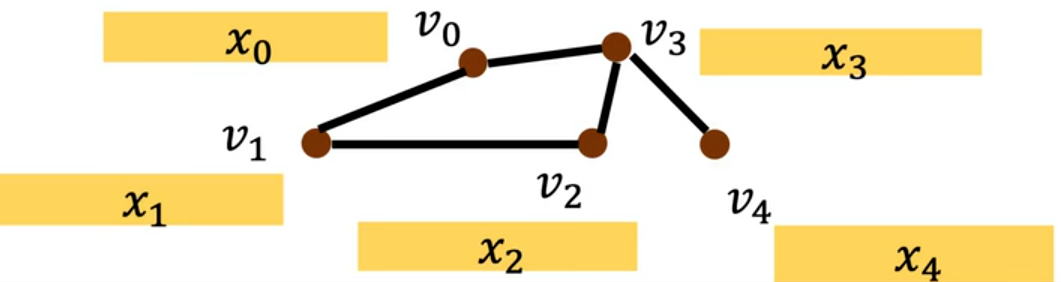
我们用一个5 节点无向图并结合计算公式,手动设置所有参数,一步步计算中心节点 的最终嵌入:
手动初始设置:假设总层数为(捕捉 2 跳邻居信息);每层采样数
(每个节点采样 2 个 1 阶邻居,邻居数不足则取全部),
(2 阶邻居采样数);聚合函数采用平均聚合(Mean Aggregator);初始特征维度
,每层输出维度
;激活函数
(线性激活,简化计算,实际用 ReLU);可训练权重矩阵:
- 初始化:
(用原始特征作为初始特征)
,且
- 第一层迭代(
,捕捉 1 跳邻居信息):对所有节点执行 “采样→聚合→更新→归一化”,重点计算中心节点
- 邻居采样:对每个节点
在此例中,对每个节点采样个 1 阶邻居。
,随机采样 2 个(这里固定为
,实际每次采样随机,相当于数据增强),其他节点邻居数 = 2,直接取全部即可:
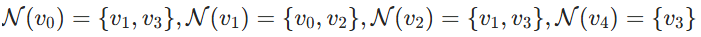
- 邻居聚合:
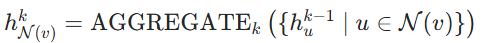
在此例中,
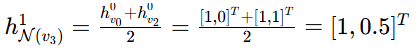
其他节点聚合结果:
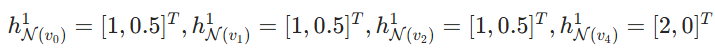
- 特征更新:
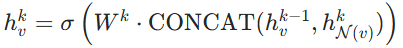
先拼接自身特征和邻居聚合特征,再乘以权重矩阵:
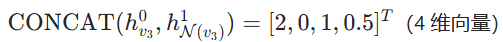
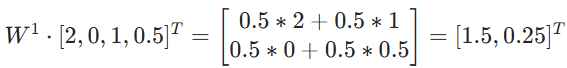
激活函数激活后:

- 特征归一化:
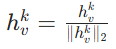
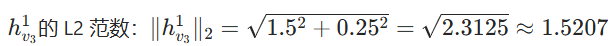
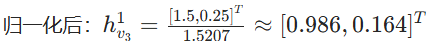
- 第 1 层最终特征(所有节点):
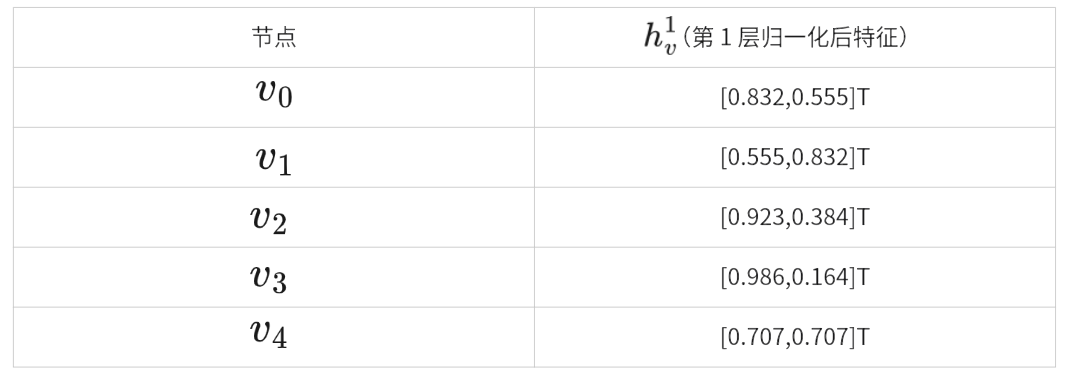
- 邻居采样:对每个节点
- 第 2 层迭代(
,捕捉 2 跳邻居信息):重复上述过程,最终得到:
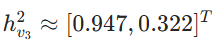
- 生成最终嵌入:
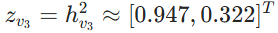
这个嵌入融合了自身的特征以及 1 跳和 2 跳邻居的特征。
看完上述工作过程后,你会发现其实GraphSAGE的创新点并不是很多,它就是在原来“自身 + 邻居特征融合 + 线性矩阵变换”的基础上加上了 “随机采样少量邻居 + L2 归一化”两个操作。但也正是这两个改进让它成为里程碑的原因。
初代的GNN(GCN、NN4G、DCNN、MoNET等)训练时必须载入整张图、全局邻接矩阵,模型参数和整张图强绑定,一旦新增节点、新增子图、换一张图完全无法推理,必须重新全局训练,所以它们只适用于静态固定小图,完全没法工业落地。GraphSAGE不学整张图,它只学 “如何采样局部邻居 → 如何聚合局部特征 → 如何映射向量” 这套规则,如果线上新增用户、新路标、新商品节点,不需要重训模型,直接前向传播生成嵌入即可。
GAT
GAT(Graph Attention Networks)核心思路是将 Transformer 中的自注意力(Self-Attention)机制,适配到图的不规则拓扑结构上,为每个节点的不同邻居,自动学习动态、差异化的注意力权重,再用这些权重对邻居特征做加权聚合,生成节点的新特征。
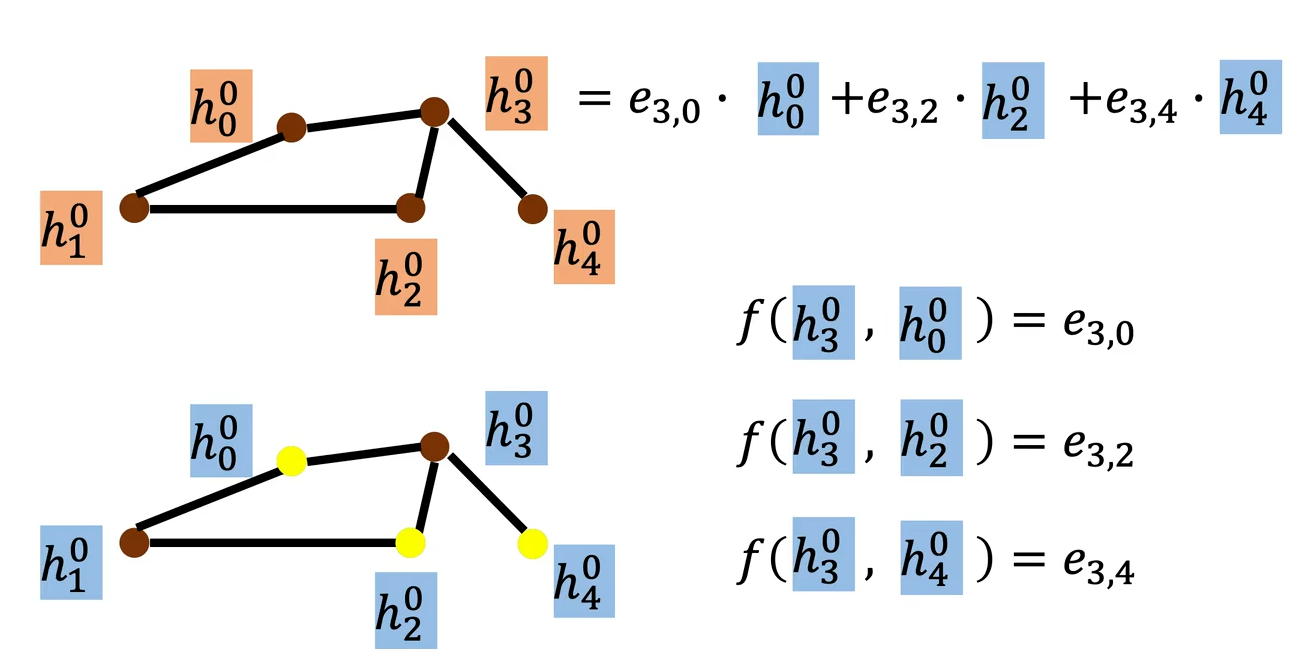
以节点 为例,说明GAT的工作过程:
- 输入:输入为所有节点的初始特征集合:
,其中
表示图中节点总数;
表示单个节点的输入特征维度。
对应图中输入 - 线性变换,提取高维特征:用一个所有节点共享的可训练权重矩阵
,对每个节点的初始特征做线性变换:
作用是将将输入的维特征空间,提取更抽象的语义特征,为后续注意力计算做准备。
- 计算节点对的注意力能量
:对于节点
(如
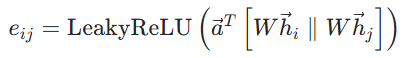
表示将节点
维的向量;
为共享的注意力权重向量,是 GAT 的核心可学习参数,用于将拼接后的特征映射为一个标量;
为非线性激活函数,引入非线性表达能力;
这个公式对应图中函数,即输入两个节点的特征,输出注意力能量
- Softmax 归一化,得到注意力分数
:由于每个节点的邻居数量不同,需要将能量
区间,保证所有邻居的权重和为 1,得到最终的注意力分数
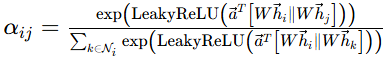
对应可视化中简化的,实际是归一化后的
。
- 加权聚合邻居特征,生成节点新特征:用归一化后的注意力分数
对应图中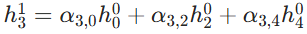
- 多头注意力(Multi-head Attention):单头只能学习一种关系模式,而多头可以学习多种关系模式,提升表达能力。
GAT 引入多头注意力机制(Transformer 核心设计),即并行执行次上述注意力计算,得到
表示第
表示第
表示拼接操作,把
- 多层堆叠:重复上述步骤,堆叠多层 GAT 层,让节点的感受野逐步扩大,捕捉多跳邻居的信息,最终得到节点的嵌入,用于下游任务(节点分类、链路预测、推荐等)。
原始的 GAT 没有采样机制,而是用 “全部邻居” 做注意力,但是GraphSAGE的采样机制是通用工程优化手段,可以使用 “GAT + 邻居采样” 来控制计算量。
GIN
GIN (Graph Isomorphism Network),它的核心目标是解决一个理论问题:
什么样的 GNN 能达到图同构测试的最强表达能力?
Weisfeiler-Lehman (WL) 图同构测试:WL 测试是判断两张图是否同构的经典算法,也是所有 GNN 表达能力的理论上限。(图同构的意思是两张图结构完全一样,只是节点编号 / 位置不同)
WL测试用 迭代给节点 “染色” 的方式,判断两张图是否同构,工作过程如下:
- 初始化:所有节点初始颜色相同(或用节点度 / 特征初始化)
- 迭代更新颜色:对每个节点,收集自身颜色 + 所有邻居颜色的多重集(Multiset)。把这个组合做单射哈希生成新颜色。
- 终止:颜色不再变化时停止
- 判断:两张图最终的颜色分布完全相同 → 判定为同构;否则不同构
GIN 论文证明:任何消息传递 GNN 的表达能力 ≤ WL 测试。只有聚合 + 更新是单射的 GNN,才能达到 WL 上限。
单射性:
在数学中,当且仅当
,即不同输入一定对应不同输出时,函数
GNN把邻居特征的多重集映射为节点表示。单射聚合是指不同的邻居多重集用不同的节点表示(能区分所有结构),非单射聚合是指不同邻居多重集用相同节点表示。
它的工作过程如下:
- 初始化节点特征:第0层特征
,即节点的原始输入特征,是所有计算的起点。
- 邻居特征求和聚合(核心操作):对每个节点
的上一层特征,做求和聚合:
这是 GIN 和 GraphSAGE/GAT 的本质区别:GraphSAGE 用 Mean/Max/LSTM,GAT 用注意力加权,而 GIN 用无差别的求和。求和可以完美保留多集(Multiset)的全部信息,不会丢失邻居的数量、重复度等关键结构信息。 - 融合自身特征与邻居特征:将节点自身的上一层特征,与邻居求和特征做加权融合:
是可学习参数(可设为固定值,也可训练),用于自适应平衡 “自身属性” 和 “邻居结构” 的贡献。当
时,放大自身特征的权重;当
时,弱化自身特征的权重。
- MLP 非线性变换:将融合后的特征输入 MLP,做非线性变换,得到节点
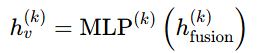
这是 GIN 达到 WL 表达能力的关键保障。MLP 可以近似任意连续函数,保证 “不同的多集输入 → 不同的输出特征” ,即单射性。
MLP(Multilayer Perceptron,多层感知机),是最基础的前馈神经网络,由 “输入层 + 隐藏层(≥1) + 输出层“ 全连接组成,只要隐藏层神经元足够多,MLP 可以以任意精度逼近任何连续函数。MLP 保证了从 “自身 + 邻居求和” 到新特征的映射是单射,这是达到 WL 上限的关键。
Mean 聚合:丢失邻居数量信息
- 1 个邻居值为 2 → Mean=2;2 个邻居值为 2 → Mean=2 → 无法区分
Max 聚合:丢失邻居数量 + 多样性
- 1 个邻居值为 5 → Max=5;100 个邻居值为 5 → Max=5 → 无法区分
Sum 聚合:完美保留多重集全部信息(数量 + 值)→ 是单射的基础
GAT使用自注意力机制,而注意力权重是可学习的、依赖数据的,不同的邻居多重集,可能学到相同的注意力权重分布,输出相同,也就不满足单射的要求;而GIN通过Sum聚合和MLP实现单射变换,可以完美模拟WL 测试的着色过程。
谱域(Spectral-based)卷积
传统 CNN 仅能处理规则网格数据(如图像、语音),而图(Graph)是非欧几里得结构(顶点连接不规则、无固定顺序),无法直接定义空间域的局部卷积核。谱域图卷积的核心思路是:将图上的顶点特征(空间域信号)通过 “图傅里叶变换” 映射到谱域(频域),在谱域完成卷积操作(利用卷积定理:空间域卷积 = 谱域逐元素乘法),再通过 “逆图傅里叶变换” 将结果映射回空间域,从而实现图结构上的特征提取。
傅里叶变换
傅里叶变换是把一个复杂信号,拆成一堆不同频率的正弦 / 余弦波的叠加。比如一段声音、一张图片,傅里叶变换就是告诉你这个信号里,低频成分(平缓变化的部分)有多少,高频成分(剧烈跳变、细节)有多少。
对于周期函数,可以使用傅里叶级数(Fourier Series)将其拆成某一个基频
的整数倍频率(
)(基频
):
对于任意非周期函数,使用连续傅里叶变换将其拆成所有连续的频率
,这里主要介绍傅里叶变换,具体解释如下:
傅里叶变换的数学公式:
一维连续傅里叶变换:
- 对每一个频率
,算出它在原信号里的权重 / 振幅,结果就是频谱
。
是复正弦函数,根据欧拉公式
得
,用复指数形式,是为了数学计算更简洁
- 根据复数几何意义可知,
就是在复平面上做匀速圆周运动的点,频率
在 频率
- 基函数是指用来 “拼出” 原函数的 “最小基础单元”,就像向量由 x/y/z 轴单位向量组成,基是
。函数也可以由一组基础函数线性叠加组成,这组基础函数就是基函数,基函数必须满足正交性,傅里叶基函数是
,也就是所有频率的复正弦波,用它们可以拼出任意连续信号。
逆变换:
- 此公式含义是对所有可能的频率
一维离散傅里叶变换(DFT):
为原离散信号(空间域/时域),
,将这些采样点放到一起就组成了一个
。DFT的本质就是将这个长度为
用不同频率叠加表示出来。在线性代数中,要线性完整表示一个
比如二维向量,至少要 2 个不共线的基才能表示;三维向量至少要 3 个不共面的基才能表示;如果一个三维向量只用两个基向量表示,由于两个基只能长成一个二维平面,三维空间里绝大多数向量,都不在这个平面上,所以一定无法完整表示一个三维向量,如果一个三维向量用四个基向量表示,这 4 个基在三维空间里必然线性相关(即第 4 个基可以被前 3 个线性表示出来),这第四个基是重复的、冗余的,不会带来新信息。
为了计算上的方便,一般我们选择的
在连续傅里叶变换中,我们选择作为正交基,这是因为对于连续傅里叶变换而言相当于采样了无数个数据组成了连续函数,即它的采样信号组成了一个无限维连续函数空间,所以连续傅里叶变换使用这个连续无穷的正交基向量来表示。
,
,所以
共可以得到
)。也就是说可以用
)来线性组合得到采样的
为离散频谱(频域),表示变换后的频域序列。
- 例如我们构造一个长度
的离散时域信号,采样频率
,信号为
,即
对每个,计算
(直流分量)
说明信号无直流分量。
代入
说明的频率分量振幅为2
同理求出;
时,
。
- 上述得到
求它在 x/y/z 轴上的分量,就是
和对应轴的单位向量做内积(对应元素相乘再求和):
x轴分量:
y轴分量:
x轴分量:傅里叶变换核心本质是原信号
假设原信号为
,我们想提取
对应的振幅
,把
根据正交性,第一项、第三项积分为0,只留下第二项,结果为
普通的信号,如语音/时序结构是一维直线,有固定顺序()和固定距离,基函数是正弦波
(扩展阅读)傅里叶变换在图像上的应用:
参考视频:发现更多精彩视频 - 抖音搜索
一张图像是由很多的像素点组成,每个像素会用具体的数值来表示,这里我们只关注灰度图像。任何图像都可以用正弦波来合成,具体原因如下:
函数
三维曲线如下
我们并不需要关注它的三维形态。将其顶部涂成黑色,底部涂成白色,中间则是连续过渡的黑白色,然后只看它的俯视图:
这样操作我们得到的就是二维余弦曲线,本质上是一幅图像,其Y轴方向颜色恒定不变,X轴方向颜色不断振荡。如果是
的图像,则其X轴方向颜色恒定不变,Y周方向颜色不断振荡:
当提高频率时,颜色振荡频率会更快,即变化的更快,条纹更密集。同理,降低频率则颜色变化更慢。如下图
:
图像如下图所示,颜色会45°倾斜:
也就是说对于函数
(
为常数),我们只需要调整
和
时为倾斜45°)。
如果将
和
两张图像叠加到一起,即
,就可以得到一个稍微复杂的图像:
同理叠加的不同形式函数越多,得到的图像就更复杂、更无规律。事实证明,只要选择的合适的函数(通常需要无限多个)并不断叠加就能合成出任何想要的灰度图像。所以任何图像本质上都可以看作是无数个二维正弦波叠加的结果,每个正弦波都会对应一个系数,这个系数也就是傅里叶变换中的
如果某幅图像中包含
,这样就可以清晰地看到
即表示
在这个坐标系(频域)中缩放某个点(同时缩放
由于图是无数个二维正弦波叠加的结果,所以图像对应的频域也会包含无穷多个点,如下图所示,图中红圈圈出的亮点区域表示大多数正弦波都集中在这里
对于下图的黑白图像,其频域图像如右图所示。
对其应用低通滤波器以及高通滤波器,只保留
将上述滤波后的图像再重新生成会是什么样?
在信号处理中,假设一个信号曲线由多个余弦波叠加而成,如果去除其高频成分就会丢失图像中的细节(小幅度振荡),但曲线的整体轮廓会保留下来;如果去除低频成分,就会丢失曲线的整体轮廓,只留下细节部分。在图像中也一样,如果只保留低频成分,我们依然可以认出这是什么,但是变得比原图更模糊,即丢失了细节(丢失了图像边缘)。模糊图像的本质就是抚平颜色的快速变化,而边缘正是由这种快速变化构成的,所以说低通滤波器本质上是一种模糊滤波器。
如果移除低频成分,只保留高频成分,那就只留下了图像的细节部分,也就是边缘。所以高通滤波器本质上是一种边缘检测滤波器
正弦波其实并不擅长处理边缘和快速变化,从拐角处出现的多余尖峰就可以认证这一点。
因此,为了处理那些有急剧变化的图像或函数我们需要一种更局部化的波形,它不像正弦波一样无限震荡下去,由此我们引入了“小波“的概念,小波就像是正弦脉冲,他不会无限振荡而是会很快衰减到0。
与正弦波一样,我们可以对小波进行缩放或平移操作:
尽管小波的数学表达式更复杂,但它可以让函数的表示更简洁。用
来表示小波的通用表达式,事实证明只需要通过缩放或平移就可以将若干甚至无穷多个小波叠加起来得到任何函数或者图像。
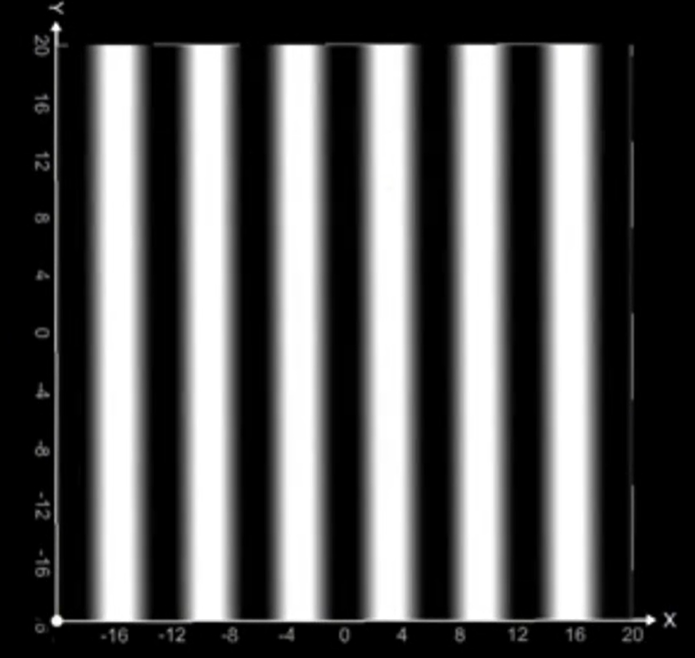
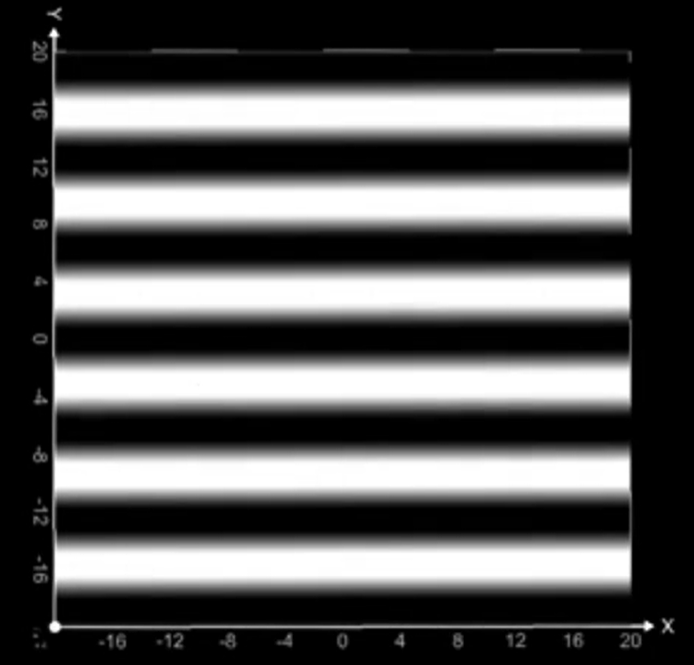

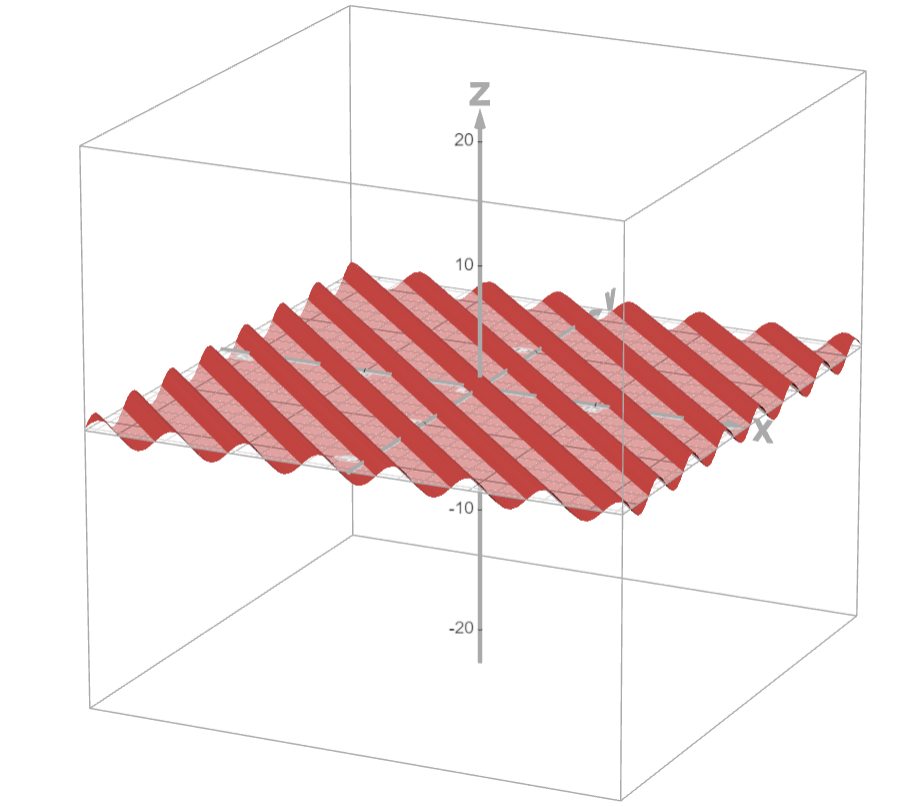







图拉普拉斯矩阵
图拉普拉斯是衡量节点信号和它邻居信号的差异程度,如果一个节点的值和邻居差不多则变化小(平滑,低频),如果一个节点的值和邻居差很多变化大(跳变,高频)。拉普拉斯矩阵,就是把这个 “平滑度” 写成矩阵形式。
我们知道图的邻接矩阵和度矩阵
邻接矩阵
:
度矩阵
(对角矩阵):
图拉普拉斯矩阵的基础定义就是
例如 3 个节点连成一条线(1-2-3),则邻接矩阵和度矩阵为
其图拉普拉斯矩阵为:
- 其对角线为节点的度,非对角线相连的节点为-1,不连为0。
拉普拉斯矩阵
衡量了节点信号和它邻居信号的差异程度。先计算
:
图信号
,每个
是节点
:
其中
只有三种情况,当
时
(节点
且
相连时,
;
。代入得:
也就是
例如,3 个节点连成一条链(1-2-3),图信号
拉普拉斯矩阵:
计算
- 节点1:
表示 “自己 - 邻居”
- 节点2:
表示 “
分别减两个邻居”
- 节点3:
表示 “自己 - 邻居”
对整个图做
分别计算
和
,因为
,所以
为了用
统一表示,将
代入
合并两项,得:
由于无向图的对称性,
,所以
将上述两式相加得
其表示对所有相连的节点对,计算
再求和,结果越大,表示信号跳变越剧烈(高频),反之越小。
拉普拉斯矩阵
1.
因为
均为实对称矩阵,
,所以
2.
对任意向量
半正定矩阵所有特征值满足
。
3.
可以表示图本身固有的基信号变化频率:
通过上述的推导我们知道,对任意图信号
这个和就是所有相邻节点的信号差值平方和,直接衡量信号变化剧烈程度。
对拉普拉斯矩阵
,都满足
同理,如果把特征向量
因为特征向量已经单位化(即
),所以可以得到:
上式表示只计算 “有边相连的邻居节点” 之间的差值平方,再把所有边的结果加总,这表示特征向量
就表示了基信号自己的震荡剧烈程度,对应傅里叶基信号的振动频率

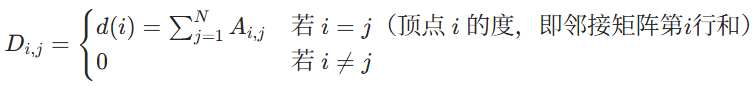

不管是普通信号还是图,频率均表示变化快慢(变化慢则低频,平滑;变化快则高频,跳变),对于普通的傅里叶,它的频率由正弦波的周期决定,基函数是。但是图上没有周期结构,我们需要一组基函数,基函数必须满足:
- 互相正交(方便拆分信号)
- 可以从 “最平滑” 到 “最不平滑” 排列→ 对应低频到高频
由上面的拉普拉斯矩阵的第三条性质 “
的特征值
可以表示图本身固有的基信号变化频率” 可知,
的特征向量
就是图结构自带的频率基信号,并且
作为实对称矩阵其特征向量互相正交。例如一张
的无向图,其拉普拉斯矩阵
的特征向量有10个,即
。这就类似于一维离散傅里叶变换(采样
次)中的
个向量基
,
就是一整套按频率从低到高排序的线性无关正交基,彼此完全独立。
又可以表示基信号的频率,即第
个基变量
的振荡剧烈程度,它对应傅里叶变换中的角频率
(
小,则表示低频、变化慢,即几乎所有相邻节点的
值都差不多;
大,则表示高频、变化块,即几乎所有相邻节点的
值剧烈跳变)。
对应频率
时,最平缓、最低频;
对应频率
,轻微震荡、次低频,依此类推,
对应
时,此时剧烈震荡、最高频。
我们在介绍傅里叶变换时只介绍了一维的情况,而在图中有多个节点,比如的无向图有10个节点,此时维度为10维,所以
中的每个特征向量
又是一个10维向量,即
,每个数值
对应的是第
个节点,它们表示了节点之间的整体特征模式,例如
表示所有节点值完全相同;
表示相邻节点一正一负,交替变化,对应低频
。利用这10个不同频率的
就可以线性组合出图上任何可能的节点信号:
![]()
:输入信号
傅里叶是把一个复杂信号,拆成一堆不同频率的基函数的叠加,同样,图傅里叶就是将任意图信号 ,都可以唯一地写成一堆
相加。
图的谱域卷积是图频域逐元素相乘,路线如下:
图节点信号→图傅里叶变换→频域乘可学习滤波器→逆图傅里叶变换→图卷积结果
对于图,
个节点,图信号(节点特征)
(
为节点的特征维度),图拉普拉斯矩阵
可正交对角化,即
,
是
的特征向量矩阵(图傅里叶基),
是特征值对角阵(图的频率)。
谱域卷积过程如下:
谱域卷积的全流程如下:

假设无向图(,共四个节点)如下图所示,节点的特征值为
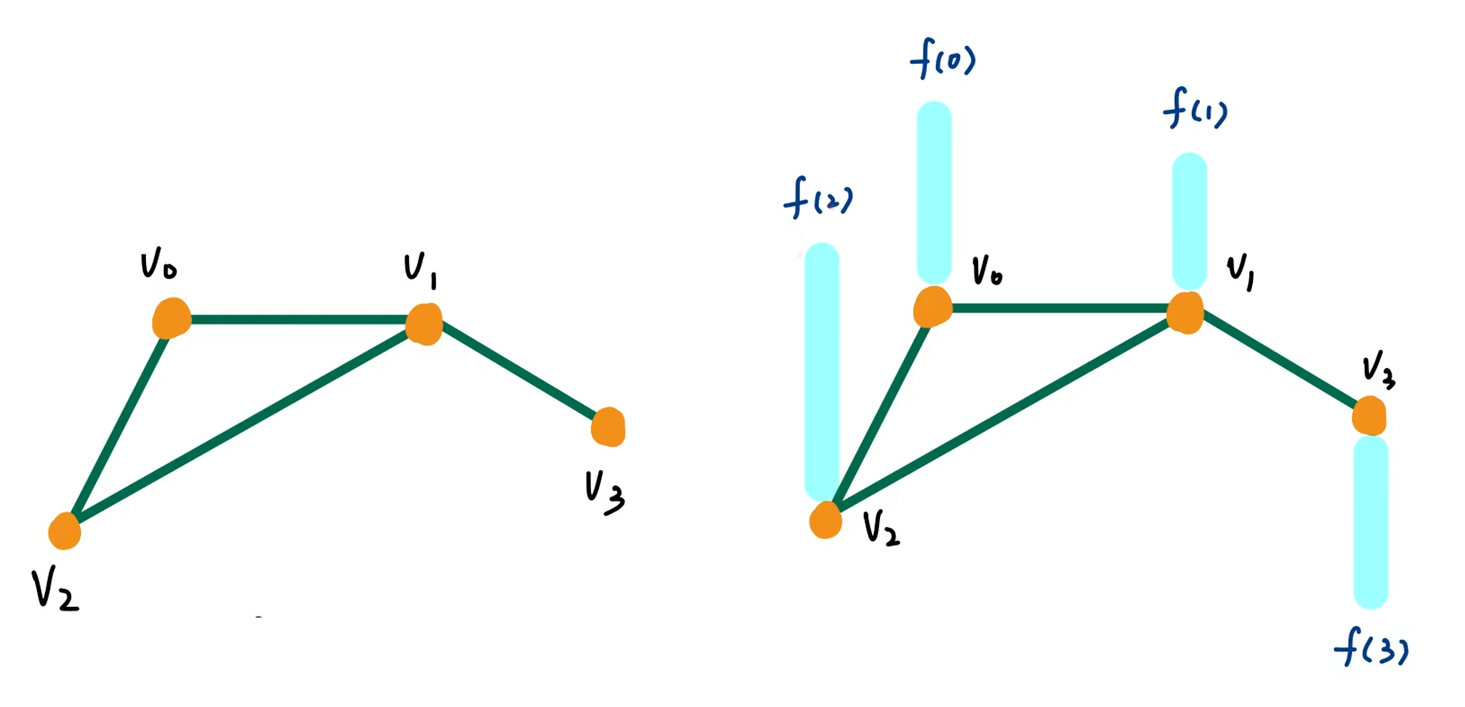
为了方便显示这个计算过程,我们假设每个节点的特征输入只有一个,即此图的输入为
此图的邻接矩阵、度矩阵、拉普拉斯矩阵如下:
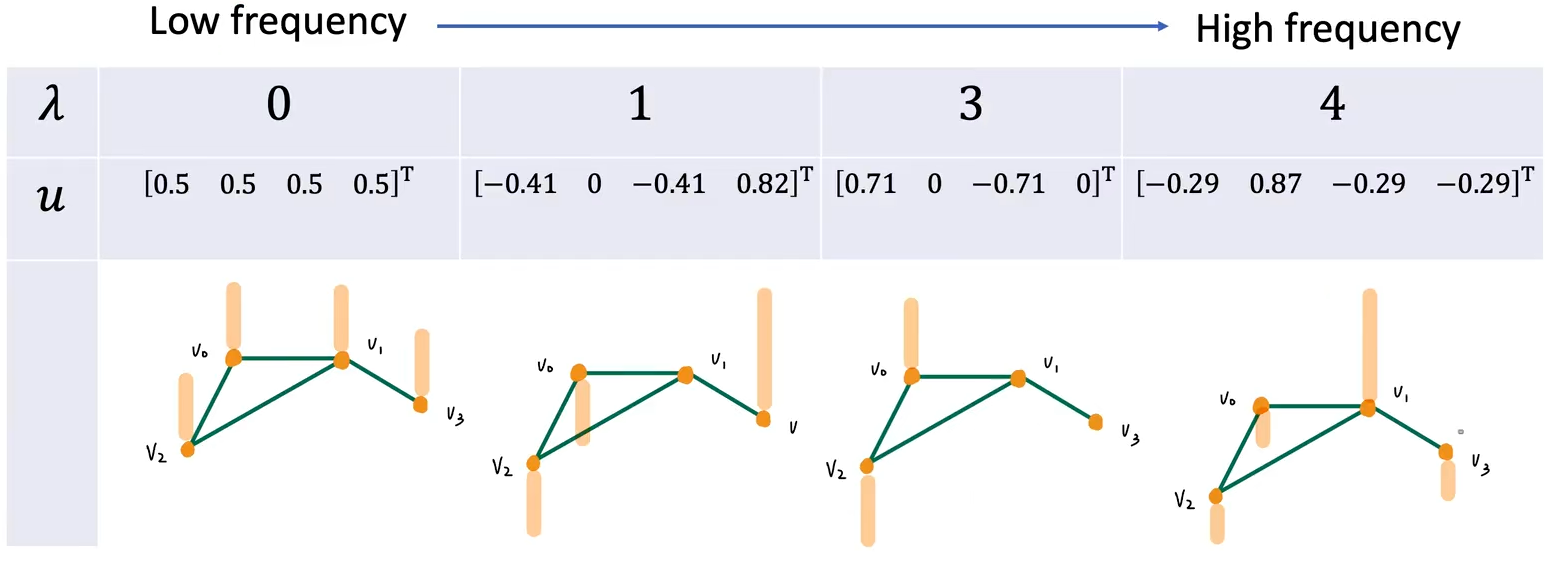
拉普拉斯矩阵正交对角化,得特征值对角矩阵(图频率)与正交矩阵(图傅里叶基):
下图中黄柱表示将 基向量 放在节点图上可以表示的大小。可以直观看出随着频率
的增大,
在各节点之间跳变越剧烈,符合我们之前的分析。
1.图傅里叶变换(空间域→频域):
![]()
这一步是将图的原空间域信号 ,投影到图傅里叶变换的基向量(图拉普拉斯的特征向量
)上,得到频域(谱域)信号
。我们先抛开 “图” 的概念,从最基础的线性代数出发理解这个公式,对于一个
维向量空间
,如果存在一组标准正交基
,满足:
- 正交性:
(基向量之间互相垂直)
- 单位性:
(每个基向量长度为 1)
那么任意一个向量都可以唯一表示为这组基的线性组合,即
,其中系数
就是
在基向量
方向上的投影长度(也是
在
上的权重大小),计算方式是向量内积:
把所有投影系数排成向量 ,把基向量按列组成矩阵
,那么上面的线性组合可以写成矩阵乘法:
因为 是标准正交基构成的矩阵(正交矩阵),满足
(单位矩阵),因此我们对等式两边左乘
,就得到了图中的核心公式:
如下图所示,把右侧 “空间域(顶点域)的图信号”,通过傅里叶变换,投影到左侧 “频域(谱域)的图频率轴” 上。左侧图横轴 表示图频率;纵轴
对应上述公式
,表示原信号
在对应特征向量
上的投影值,也就是频域信号
的分量,代表这个频率分量在原信号中的强度 / 权重
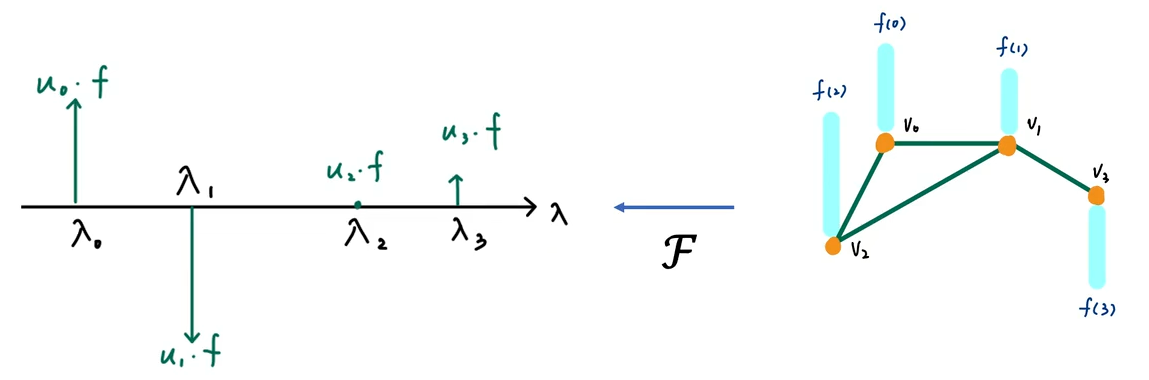
2.定义谱域滤波器:
,
是可学习谱域滤波器(对角矩阵,
是对应频率的权重,需训练)。滤波器的本质对不同频率的图信号赋予不同权重,实现频域滤波,由于谱域卷积的 “频域坐标轴” 就是
图的频率),滤波器要对不同频率做加权,权重自然必须是频率 λ 的函数,所以
,即
可以写作
。
本质就是图频域里的加权函数,输入是图频率
,输出是该频率的权重系数,它的函数形式可以自定义设置,初代GNN使用
这种无约束自由函数,此时滤波器
;ChebNet使用
的
阶多项式,即
。
在图像傅里叶频域中,频率轴是,滤波器是
,作用是对不同频率
乘不同系数来起到不同的作用,比如对于低频
使用较大的
则表示保留轮廓,对高频
使用较小的
则表示过滤噪声。在图傅里叶频域中也一样,频率轴是
,滤波器是
,如果对低频
使用较大
则表示保留平滑信号,对高频
使用较小
则表示过滤跳变噪声。
3.逆傅里叶变换(频域→空间域):
![]()
总:谱域卷积总公式如下
因为图拉普拉斯矩阵,矩阵函数定义
,即对
的每个对角元素应用
。根据这个定义上式又可以写成:
即输出信号 = 拉普拉斯矩阵的函数 × 输入信号。
早期谱域图卷积(Spectral-based Convolutional GNN)的两个主要缺点:
- 学习复杂度为
,参数量爆炸且无法泛化:早期谱域图卷积的谱域滤波器
是与图频率一一绑定的对角矩阵,每个图频率
对应一个可学习权重
,而图频率的数量等于节点数
- 不具备局部性(Not localize!!!),全局操作违背卷积核心思想:卷积的核心优势是局部感受野,CNN 中 3×3/5×5 卷积核仅依赖局部邻域的像素,提取局部特征、参数共享、计算高效。而早期谱域图卷积是全局操作,每个节点的输出依赖图中所有节点的输入,完全没有局部性,无法提取局部特征。我们通过一个具体的例子来说明 “全局操作” :
当时,
:
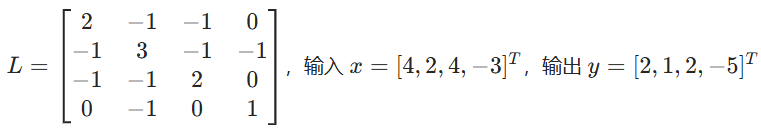
节点0输出,即依赖依赖节点 0、1、2(1 阶邻居)
当时,
:

节点0输出,依赖图中所有 4 个节点(包括节点 3,节点 3 是节点 0 的 2 阶邻居)。
所以谱域卷积的本质是全局频域滤波,每个节点的输出自然依赖全局所有节点的输入,无法限制在局部邻域。
事实上,在图像上也有频域卷积。我们之前说过的CNN操作属于空间域卷积,即卷积核在图像上滑动每到一个位置,覆盖区域像素 × 卷积核对应位置,进行逐元素相乘求和,这是深度学习框架(PyTorch/TensorFlow)实际运行的方式。而频域卷积是将图像进行傅里叶变换后用卷积核在频域内进行逐元素相乘的操作,与图的频域卷积操作一样。
图像空间域卷积优缺点:
图像频域卷积优缺点:
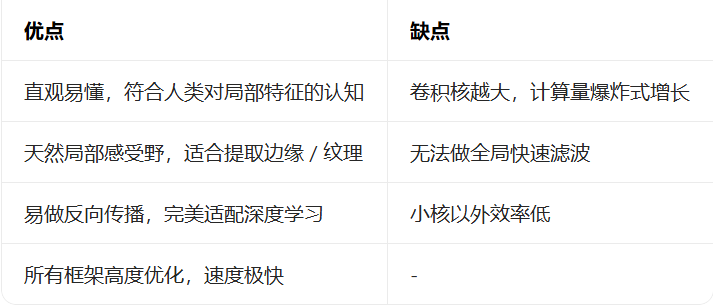
无论是图像频域卷积还是图频域卷积,在实际使用时更常用空间域卷积,频域卷积(傅里叶)只在传统图像处理、超大核滤波偶尔用(比如专业图像模糊、去雾),现代深度学习基本不用。
ChebNet
ChebNet 的核心创新是用切比雪夫多项式(Chebyshev Polynomial)参数化滤波器来解决上述传统谱域卷积遇到的两个问题。
切比雪夫多项式
切比雪夫多项式定义式:
切比雪夫多项式(Chebyshev Polynomials)是俄罗斯数学家帕夫努季・切比雪夫提出的正交多项式族,分为第一类(
)和第二类(
),ChebNet 中使用的是第一类切比雪夫多项式。其显示三角函数定义如下:
:第
阶第一类切比雪夫多项式(
)
,定义域严格限制在
内。
- 三角函数形式揭示其与余弦函数的深层联系
上述切比雪夫定义式实际上就是把
,再算这个角度放大
,根据三角函数公式最后把结果整理成关于
当
时,
当
时,
当
时,
,因为
,将
当
时,
,得:
当
时,
,得:
根据余弦和角公式
,令
,代入得:

移项得:
因为
,所以上式可以写成:
所以切比雪夫多项式就是一个递推公式形式,写成:
之所以可以写成递推形式是因为三角函数里
。
切比雪夫多项式正交性:
第一类切比雪夫多项式的带权正交性定义式:
:第
阶第一类切比雪夫多项式。
:权函数,是切比雪夫多项式正交性的核心要素,决定了内积的度量方式
正交性的本质是不同阶多项式的带权内积为 0,我们可以通过切比雪夫多项式的三角函数定义严格推导:
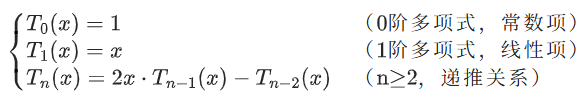
滤波器参数化:
是待学习的参数向量

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)