【2026】TOP15计算机视觉数据集|从基础到前沿,一篇搞懂所有核心数据集
【2026】TOP15计算机视觉数据集|从基础到前沿,一篇搞懂所有核心数据集
《博主简介》
小伙伴们好,我是阿旭。
专注于计算机视觉领域,包括目标检测、图像分类、图像分割和目标跟踪等项目开发,提供模型对比实验、答疑辅导等。
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
引言

本文梳理了2026年最具影响力的计算机视觉数据集,从基础概念到前沿趋势,帮你选对数据、用好数据。
一、先搞懂:计算机视觉数据集到底是什么?
简单来说,视觉数据集是为训练AI模型准备的“带答案的视觉练习题”,核心由两部分构成:
- 原始数据:以JPG/PNG格式的图片、视频为主,是给模型看的“问题”;
- 标注信息:描述原始数据内容的“标准答案”(真值),比如目标的边界框坐标、分割掩码、人体关键点等,是模型学习的依据。
训练模型的过程,就是反复让模型看“练习题(原始数据)+答案(标注)”,直到它能独立给新的视觉数据“答题”。
这里还要分清两个易混淆的概念:
- 数据集:静态的视觉数据+标注集合(比如PASCAL VOC包含数千张标注图片);
- 评测基准(Benchmark):基于数据集制定的性能测试标准/竞赛(比如PASCAL VOC挑战赛,用该数据集评估新模型的优劣)。
二、奠定CV发展的基石:经典基准数据集
这些数据集堪称CV领域的“必修课”,几乎所有从业者都会用到:
1. COCO(Common Objects in Context)

目前最核心、应用最广的目标检测与分割数据集,核心特点是聚焦真实复杂场景(物体嵌入杂乱背景,而非孤立展示)。
- 规模:约33万张图片(超20万张带标注);
- 覆盖类别:80类“可数物体”(人、车、自行车等)+91类“无定形区域”(天空、草地、道路等);
- 标注类型:边界框、实例分割掩码、人体关键点(25万个人体样本);
- 新升级:MJ-COCO-2025版本通过AI自动标注修正了原始版本的标注遗漏、重复、不一致等问题。
2. ImageNet

开启深度学习革命的“里程碑式数据集”,是绝大多数CV模型的预训练首选。
- 规模:超1400万张图片,其中128万张为ILSVRC挑战赛(ImageNet-1K)标注完整;
- 特点:覆盖1000个类别,规模和多样性足以支撑超深神经网络训练;
- 注意:仅用于非商业研究/教育用途,不持有图片版权,仅提供URL列表。
3. Open Images Dataset(OID)

谷歌推出的超大规模、高多样性开源数据集。
- 规模:约900万张图片,含1600万个边界框(600个类别)、280万个实例分割掩码;
- 特色:V7版本新增“点级标注”(5827个类别),适配弱监督学习、零样本分割任务;还包含“本地化叙事标注”——标注者语音描述图片内容的同时,用鼠标追踪对应物体。
4. PASCAL VOC

COCO出现前的核心目标检测基准,虽规模小但影响力深远。
- 规模:VOC2012含约1.15万张图片、2.3万余个标注目标,仅21个物体类别;
- 核心贡献:
- 定义了VOC XML标注格式(支持边界框、分割掩码、多边形等,成为行业通用标准);
- 确立了mAP(平均精度均值)、ROC-AUC等至今仍在用的目标检测评测指标。
三、垂直领域专属:行业定制化数据集生态
通用数据集无法满足工业级场景需求,各领域已形成专属的数据集体系:
1. 自动驾驶与3D感知

核心需求是多传感器融合、3D环境感知,需突破2D边界框的局限:
-
KITTI:早期经典自动驾驶数据集(德国城市道路采集),聚焦激光雷达+双目相机融合,是3D目标检测、立体视觉的核心基准;
-
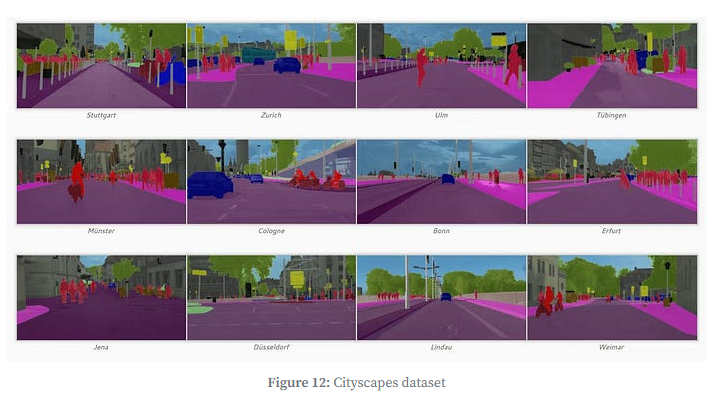
Cityscapes:城市场景语义/实例分割基准,覆盖50个城市、30个类别(道路、人行道、车辆等),是自动驾驶感知层训练的关键;
-
nuScenes:多模态大规模数据集(6摄像头+5雷达+1激光雷达,360°覆盖),包含夜间、雨天数据,适配鲁棒性训练;

-
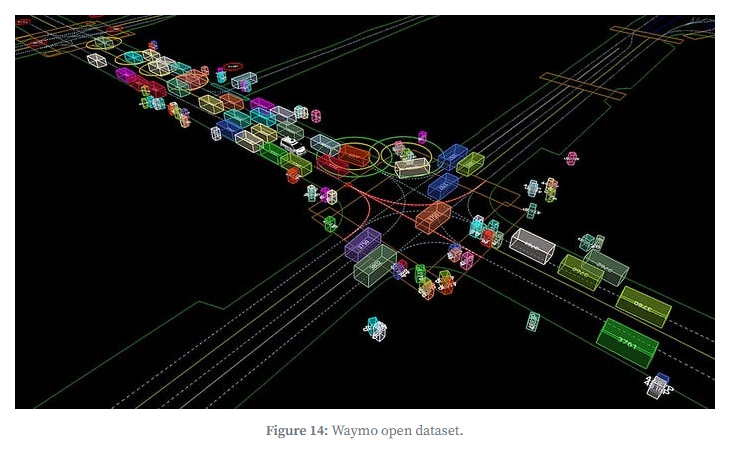
Waymo Open Dataset:以高质量、高密度激光雷达数据著称,覆盖多样驾驶环境,是顶级自动驾驶算法的评测标杆。
2. 零售场景与密集目标检测
解决零售货架“密集堆叠、遮挡严重”导致的检测难题:
-
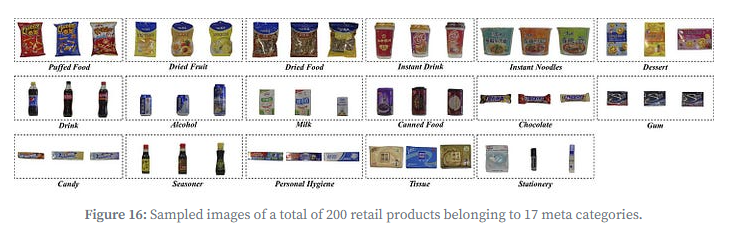
SKU-110K:超市货架密集商品数据集,含11万+SKU类别,主打高遮挡、多尺度物体检测;

-
RPC(Retail Product Checkout):模拟收银台场景,含单商品(训练)、多商品堆叠(测试)数据,适配自动结算系统的物品计数/识别任务。
3. 医疗影像
受HIPAA、GDPR等隐私法规约束,数据集更注重标注的不确定性与3D特征:
-
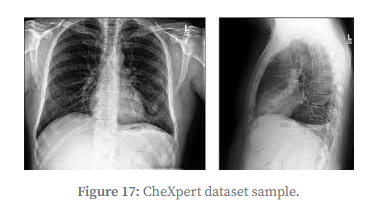
CheXpert:胸部X光片数据集,支持“不确定性标注”(放射科医生无法100%确定病理时的概率化标注);
-
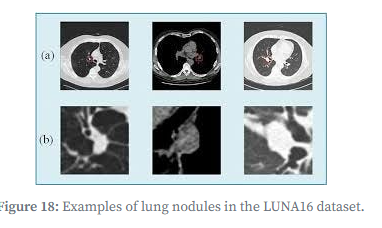
LUNA16:基于LIDC-IDRI数据库的肺结节分析数据集,提供3D CT扫描数据,适配V-Net等3D CNN架构训练。
4. 地理空间与卫星影像
核心挑战是多光谱波段、小目标/旋转目标检测:
-
SpaceNet:商用卫星影像数据集(30-50cm超高分辨率),含6.7万平方公里影像、1100万+建筑轮廓、2万公里道路标注,支持变化检测、城市发展追踪;

-
DOTA-v2.0:大规模航空/卫星影像数据集,含1.1万+图片、170万+标注目标(18类:飞机、船舶、储罐等),采用任意四边形/旋转边界框标注,适配航拍目标的旋转/倾斜特性。

四、2026新趋势:数据集向更高维度进化
CV数据集正从“静态2D图片”向“3D/4D、视频时序、生成式”方向突破:
1. 3D/4D重建
受NeRF、3D高斯溅射技术推动,3D物体数据集成为热点:
-
Objaverse系列:Objaverse 1.0含80万+标注3D物体(是ShapeNet的16倍),XL版本扩展至1000万+,覆盖车辆、建筑、文物等多样类别;

-
OmniObject3D:真实物体高质量扫描数据集,含6000个扫描物体(190个日常类别),提供纹理网格、点云、多视角渲染图、实拍视频等多模态数据。

2. 视频与长时序理解
静态图片分析已趋成熟,“时序理解”成为新前沿:
-
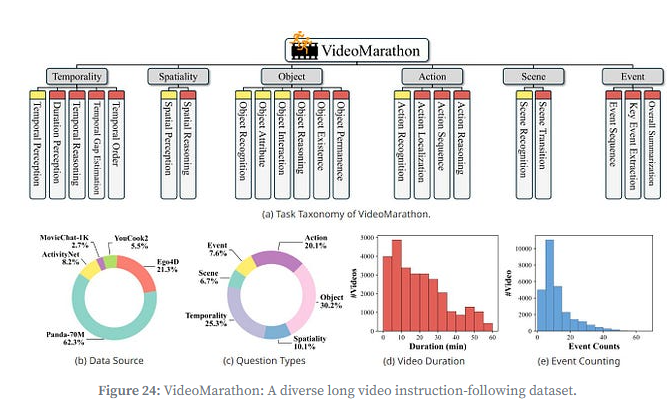
VideoMarathon:长视频指令跟随数据集,含9700小时视频(单片段3-60分钟)、330万+QA标注,覆盖时序、空间、物体、动作等22类任务;
-
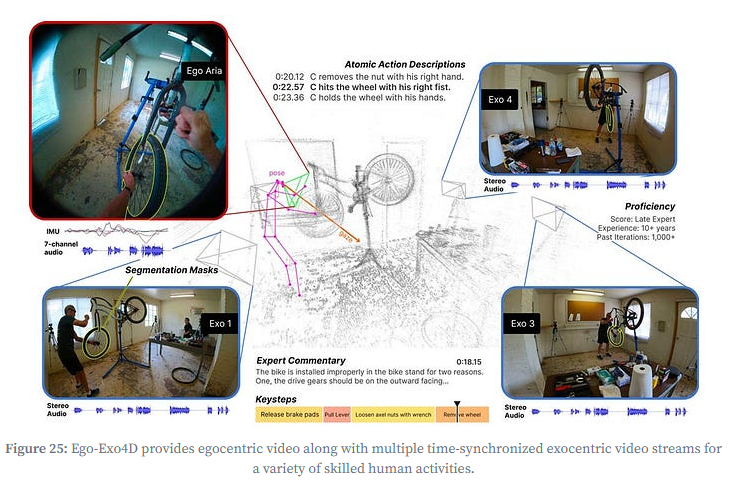
Ego-Exo4D:多视角技能类人体活动数据集,融合第一人称(Ego)+第三人称(Exo)视角,还包含音频、IMU、眼动数据,支持动作拆解、3D人体姿态等任务。
五、实操指南:玩转CV数据集的工具与最佳实践
1. 主流标注格式(模型能“读懂”的标签语言)
| 格式 | 特点 | 适用场景 |
|---|---|---|
| YOLO(TXT) | 坐标归一化[0-1],轻量化 | 实时目标检测(YOLO系列) |
| COCO(JSON) | 支持RLE压缩掩码,适配复杂任务 | 实例分割、姿态估计 |
| Pascal VOC(XML) | 树形结构易读,存储稍冗余 | 通用检测/分割,标注工具 |
2. 数据增强:让模型更鲁棒的关键
实际训练中数据往往不足,通过对图片做随机变换(旋转、亮度调整、裁剪等)生成“新数据”,能避免模型过拟合,提升对新场景的适应能力。
六、总结
从MNIST这类简单学术数据集,到ImageNet、COCO这样推动深度学习革命的大规模数据集,再到2026年聚焦3D、时序、垂直领域的定制化数据,计算机视觉数据集的进化,直接推动了AI模型能力的升级。
如今开发CV模型,选对基准数据集做预训练、针对场景定制专属数据、用好数据增强,已成为核心能力。无论是边缘设备上的实时YOLO模型,还是自动驾驶的3D感知系统,高质量、贴合场景的数据集,永远是模型性能的“底气”。
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献152条内容
已为社区贡献152条内容

所有评论(0)