强化学习5:基于策略——策略梯度
摘要:策略梯度是强化学习中直接优化策略的方法,通过神经网络表示策略并使用梯度上升最大化期望回报。核心算法包括蒙特卡洛策略梯度(用完整轨迹回报更新)、Actor-Critic(结合策略和价值网络降低方差)、TRPO(通过KL散度约束保证稳定更新)、PPO(采用裁剪机制限制更新幅度)以及SAC(基于最大熵框架平衡探索与利用)。这些方法通过不同机制解决了策略优化中的方差问题和稳定性挑战,在连续动作空间任
概念
策略梯度是强化学习中一类直接优化策略的方法。
-
传统价值方法 (如 Q-learning):教智能体哪个动作值钱。先学一个价值函数(评估每个“状态-动作”对的好坏),再从价值函数中推导出策略(例如,在每个状态选价值最高的动作)。
-
策略梯度方法:教智能体“直接去做这个动作(学习策略)。直接用一个神经网络来代表策略。输入是状态,输出是动作的概率分布(连续动作则输出分布的参数)。然后,我们直接朝着增加期望回报的方向调整网络的参数。
核心思想
不评估每个动作有多好(价值函数),直接用一个带参数的神经网络(即策略网络
)来表示策略,并通过梯度上升来调整参数,使得能获得更高总回报的动作被选中的概率更大
-
输入:当前状态
。
-
输出:所有动作的概率分布(例如:向左 70%,向右 30%)。
-
目标:调整网络参数
,使得“好动作”的概率变大,“坏动作”的概率变小。
核心公式
1.目标函数
表示策略的期望回报,目标是最大化:
![]()
-
智能体与环境交互产生的轨迹为
-
轨迹的累积奖励为
-
τ∼πθ 表示轨迹的概率分布由策略πθ 决定
2.策略梯度公式
-
:表示参数更新的方向。它告诉你,为了让当前动作
的概率增加,参数
-
:是整条轨迹获得的总回报。如果
很大,我们就往这个方向大幅增加概率
经典算法
1.蒙特卡洛策略梯度
策略梯度:遵循前面提到的策略梯度公式,用整个轨迹的总回报作为每个动作的权重
蒙特卡洛:通过蒙特卡洛采样来获得真实的累积回报 ,并以此作为更新的权重
更新公式:
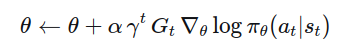
算法流程:
- 随机初始化策略网络
的参数
-
采样轨迹:用当前策略
与环境交互,收集一条完整轨迹
-
计算累积奖励:对每条轨迹计算折扣累积奖励
-
计算梯度:对每个时刻t,计算损失
(负号将梯度上升转为梯度下降优化)
-
更新参数:对所有时刻的损失求和,反向传播更新策略参数
2.演员-评论家算法(Actor-Critic)
Actor-Critic(演员-评论家) 是策略梯度方法中最重要的改进之一。它结合了基于策略(Policy-Based,即Actor)和基于价值(Value-Based,即Critic)两种方法的优点,通过引入一个价值网络来评估当前策略的表现,从而大幅降低REINFORCE算法中过高的方差,实现更稳定、更高效的训练。
演员(Actor):学习策略,负责选择动作
-
输入:当前状态
-
输出:动作的概率分布
-
参数:
-
职责:决定做什么。它根据当前状态选择动作,并不断优化自己的策略,以获取更高的回报
-
更新方式:
评论家(Critic):学习价值函数 或
,评估动作的好坏
-
输入:状态 s(有时也输入动作 a)
-
输出:状态价值
或状态-动作价值
-
参数:
-
职责:评价做得好不好。它观察Actor的动作和环境的奖励,给出一个评分
-
更新方式:
训练流程
-
初始化Actor网络
、Critic 网络
、学习率
、折扣因子
-
在每个时间步 t:
-
观察当前状态
-
采样动作:根据 Actor 的概率分布选择动作
-
执行动作:与环境交互,获得奖励
和下一个状态
-
Critic评价:计算TD误差
-
Critic更新:梯度下降
-
Actor更新:梯度上升
-
-
重复直到收敛
优势
-
大幅降低方差:用优势函数代替总回报 Gt,去除了状态价值基线,只保留动作带来的相对好处。训练曲线更平滑。
-
支持单步更新(online):不需要像REINFORCE那样等到episode结束,可以在每个时间步或每几个时间步后立即更新,适合持续性任务(如机器人控制)。
-
更高效的样本利用:结合了TD学习的快速更新和策略梯度的直接优化。
3.TRPO
传统的策略梯度方法在更新策略时,如果步长(学习率)选择不当,很容易“步子迈得太大”,导致一次性能骤降甚至崩。TRPO的核心就是防止这种情况发生。 它通过引入一个名为“信任区域”的概念来实现。
-
信任区域 (Trust Region):可以理解为新旧策略之间的一个“安全距离”。TRPO会保证每次更新后的新策略,与旧策略的差异都在这个安全区域内
-
衡量工具 (KL散度):为了精确量化新旧策略的差异,TRPO使用了一种叫做 KL散度 的指标
-
约束优化:这样,TRPO的训练目标就变成了一个带约束的数学问题:在保证新旧策略的KL散度小于一个预设阈值的前提下,最大化预期的累积奖励
算法流程
-
收集数据:用当前的旧策略在环境中运行,收集一批状态、动作和奖励数据。
-
计算优势:通过GAE等方法估算出每个“状态-动作”对的优势函数值 A(s,a)。
-
计算策略梯度:计算出标准策略梯度 g。
-
求解约束更新:通过共轭梯度法求解 Hx=g,得到最优的更新方向和步长。
-
回溯线搜索:使用回溯线搜索对步长进行校验,确保最终的更新策略满足KL散度约束。
-
更新策略:使用找到的最佳步长,更新策略网络的参数。
-
迭代:重复以上步骤,直到策略收敛。
4.PPO
PPO在Actor-Critic框架的基础上,对策略更新施加了限制。它引入了裁剪(Clipping) 机制,即在计算策略梯度时,限制新旧策略的更新幅度,防止某一步优化过度导致性能崩塌。
PPO裁剪机制的精髓,在其巧妙的裁剪替代目标函数中。以下是简化的流程:
-
定义概率比率:首先,定义一个概率比率
,它衡量了在相同状态下,新策略相对于旧策略采取某个动作的可能性变化。
-
构建非裁剪项:非裁剪项
是标准的策略梯度目标,其中
是优势函数的估计,用于量化当前动作比平均水平好多少
-
引入裁剪操作:裁剪项
将概率比率
强制限制在
区间内,从源头上限制了策略更新的幅度
-
取最小值,形成最终目标:最终的裁剪替代目标函数
取上述两者的最小值
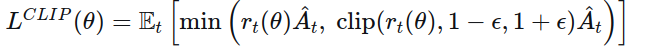
算法流程
-
初始化:Actor 网络
-
收集经验:让当前的 Actor 去跑
个步长,存下所有的
-
计算优势:利用 Critic 算出每个动作的优势函数
-
多次迭代更新:
- 备份当前策略为“旧策略”
- 循环 K 轮:从收集到的经验里随机抽样,计算
,更新 Actor 参数
- 同时更新 Critic 参数
,让
预估得更准
-
重复:用更新后的策略去收集新经验
5.Soft Actor-Critic(SAC)
是一个基于最大熵框架的异策略(Off-Policy)深度强化学习算法,它的核心设计巧妙地平衡了两个关键目标:最大化期望累积奖励,同时最大化策略的熵
-
最大化累积奖励:这是RL的常规目标,驱动智能体学习能获得高分的“最优”策略。
-
最大化熵:熵衡量策略的随机性。熵越高,策略的随机性越大,意味着智能体会更倾向于尝试不同的动作,进行广泛的探索,而不是过早地锁定单一策略
算法流程
-
与环境交互采样:Actor(策略网络)根据当前状态s输出动作的概率分布并采样动作a。在环境中执行a,得到奖励r和下一状态s′,并将转换数据(s,a,r,s′)存入经验回放池。
-
Critic(价值网络)的更新:从经验池中随机采样一个批次的数据进行训练。
-
计算目标Q值:利用目标Q网络估算下一状态的价值,计算TD目标。这里会用到双Q网络的最小值来防止过估计
-
最小化损失函数:通过梯度下降,最小化Critic网络的预测Q值与目标Q值之间的均方误差
-
-
Actor(策略网络)的更新:Actor的目标是生成能获得高Q值且具有高熵的动作:
计算策略损失:Actor的损失函数旨在最大化Critic评估的Q值,并最大化动作的熵
-
自适应温度参数α的更新:如果启用了熵正则化学习,会计算熵损失并通过梯度下降调整温度参数α。这使得探索与利用的平衡能够随着训练动态调整
-
目标网络软更新:采用“软更新”的方式,将当前Q网络的参数按一个小比例τ缓慢地复制给目标Q网络,而非直接替换,从而保证学习过程的稳定性

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)