Java AI 之 DJL 实战(第 1 篇):模型训练初体验
初体验
介绍
近年来,机器学习已成为推动科技进步的核心技术之一,广泛应用于图像分类、自然语言处理、推荐系统等领域。虽然Python是目前机器学习的主要语言,但Java依然是许多企业级应用的核心语言,特别是在大规模数据处理、系统集成等场景中。为了弥合Java与机器学习之间的鸿沟,Deep Java Library (DJL) 提供了一套完整的、简化的Java机器学习开发框架,使得开发者可以在Java环境中构建、训练和部署机器学习模型。
Deep Java Library (DJL) 是一个基于Java的深度学习库,是一个由亚马逊AWS开发并贡献给Apache的开源深度学习框架。它封装了多种后端引擎(如TensorFlow、PyTorch、MXNet等),它的核心定位是Java生态与主流AI框架之间的桥梁,让Java开发者能够直接使用Python生态中训练的模型,无需重写或转换。让Java开发者能够轻松利用这些强大的工具构建和应用机器学习模型。
DJL官网:https://djl.ai/
DJL的核心概念与优势
Deep Java Library (DJL) 是一个开源的深度学习框架,旨在简化Java开发者使用深度学习的流程。DJL具有以下核心优势:
- 跨平台后端支持:支持多种主流的深度学习引擎,如TensorFlow、PyTorch、MXNet等,开发者可以选择自己熟悉的引擎。
- 简化的API:提供直观易用的Java API,开发者无需了解底层引擎的细节即可快速构建和训练模型。
- 模型导入与推理:支持直接导入预训练模型,并能快速部署推理服务。
- 广泛的应用场景:适用于图像分类、对象检测、自然语言处理、推荐系统等领域。
为什么DJL独特?
与其他Java深度学习框架不同,DJL采取拥抱而非竞争的策略:
- 不重新实现算法,而是复用PyTorch/TensorFlow的实现
- 不创建新模型格式,直接支持.pt、.pb、.onnx等主流格式
- 不建立封闭生态,而是无缝集成Hugging Face等开放平台
分层架构设计
DJL采用清晰的五层架构:
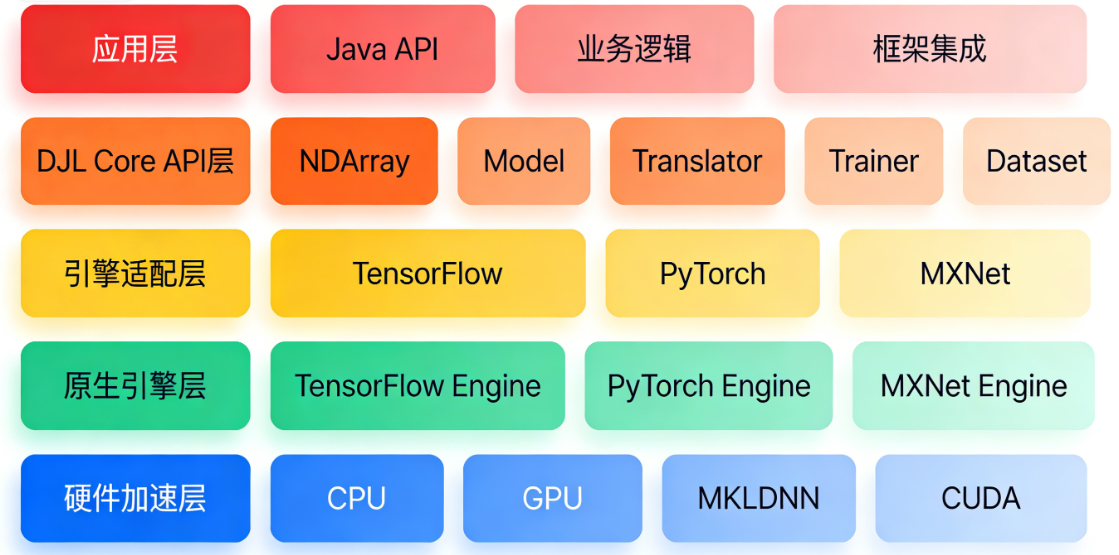
第一层:应用层
- Java应用程序接口
- 业务逻辑和流程控制
- 与其他Java框架(Spring Boot、Spark)集成
第二层:DJL Core API层
提供统一的深度学习抽象:
- NDArray:跨引擎的张量计算
- Model:模型加载和管理的统一接口
- Translator:输入输出转换的标准化
- Trainer:训练过程抽象
- Dataset:数据加载和预处理
第三层:引擎适配层
每个支持的深度学习框架都有对应的适配器:
- PyTorchEngine:对接LibTorch C++库
- TensorFlowEngine:对接TensorFlow C API
- MxNetEngine:对接MXNet C++接口
- OnnxRuntimeEngine(扩展):对接ONNX Runtime
第四层:原生引擎层
- PyTorch的LibTorch
- TensorFlow的C API
- MXNet的C++核心
- 这些是实际的执行引擎
第五层:硬件加速层
- CPU:Intel MKL、OneDNN优化
- GPU:NVIDIA CUDA、cuDNN
- 专用芯片:Apple MPS、Habana Gaudi
使用场景
场景1:传统Java系统AI升级
- 银行风险模型的实时推理
- 电商推荐系统的在线预测
- 制造业质量检测的图像分析
场景2:移动和边缘计算
- Android应用的本地推理
- 物联网设备的实时分析
- 隐私敏感数据的本地处理
场景3:大数据管道集成
- Spark流处理中的实时推理
- Flink事件处理中的AI决策
- 数据湖查询中的智能增强
入门示例 - 猫狗分类
创建基础Maven项目导入依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<djl.version>0.34.0</djl.version>
<logback.version>1.2.13</logback.version>
</properties>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.42</version>
</dependency>
<!-- DJL核心API -->
<dependency>
<groupId>ai.djl</groupId>
<artifactId>api</artifactId>
<version>${djl.version}</version>
</dependency>
<!-- PyTorch引擎 -->
<dependency>
<groupId>ai.djl.pytorch</groupId>
<artifactId>pytorch-engine</artifactId>
<version>${djl.version}</version>
</dependency>
<!-- PyTorch原生库 -->
<dependency>
<groupId>ai.djl.pytorch</groupId>
<artifactId>pytorch-native-cpu</artifactId> <!-- 明确指定CPU版本,避免自动下载GPU版 -->
<version>2.7.1</version>
<classifier>win-x86_64</classifier> <!-- 适配Windows x64系统 -->
<scope>runtime</scope>
</dependency>
<!-- 基础数据集和工具库 -->
<dependency>
<groupId>ai.djl</groupId>
<artifactId>basicdataset</artifactId>
<version>${djl.version}</version>
</dependency>
<!-- DJL PyTorch 模型仓库依赖 -->
<dependency>
<groupId>ai.djl.pytorch</groupId>
<artifactId>pytorch-model-zoo</artifactId>
<version>${djl.version}</version>
</dependency>
<!-- 若预训练图像分类模型 -->
<dependency>
<groupId>ai.djl</groupId>
<artifactId>model-zoo</artifactId>
<version>${djl.version}</version>
</dependency>
<!-- SLF4J 接口(若已引入可忽略) -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.36</version>
</dependency>
<!-- Logback 核心实现(关键:补充日志实现类) -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>${logback.version}</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
</dependencies>
代码实现
核心步骤
- 第一步:预处理,调整图片尺寸、将图像转换为张量
- 第二步:创建图像分类翻译器,启用Softmax
- 第三步:创建模型加载条件,定义模型的输入输出类型、来源、预处理规则等
- 第四步:加载模型,从ModelZoo加载模型
- 第五步:创建预测器并进行推理
- 第六步:解析结果
package com.woniuxy;
import ai.djl.Application;
import ai.djl.ModelException;
import ai.djl.engine.Engine;
import ai.djl.inference.Predictor;
import ai.djl.modality.Classifications;
import ai.djl.modality.cv.Image;
import ai.djl.modality.cv.ImageFactory;
import ai.djl.modality.cv.transform.Resize;
import ai.djl.modality.cv.transform.ToTensor;
import ai.djl.modality.cv.translator.ImageClassificationTranslator;
import ai.djl.repository.zoo.Criteria;
import ai.djl.repository.zoo.ModelZoo;
import ai.djl.repository.zoo.ZooModel;
import ai.djl.training.util.ProgressBar;
import ai.djl.translate.Pipeline;
import ai.djl.translate.TranslateException;
import java.io.IOException;
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* 基于DJL+PyTorch的图像分类程序(ResNet预训练模型)
* 功能:加载本地图片,使用ResNet模型完成图像分类,输出前5个最可能的类别及置信度
* 核心依赖:DJL(Deep Java Library),简化Java调用深度学习模型的流程
*/
public class FirstImageClassificationDetail {
public static void main(String[] args) {
// 1. 指定要分类的图像路径(需替换为实际本地图片路径)
String imagePath = "C:\\Users\\Administrator\\Desktop\\animal\\QQ20251223-102831.png";
try {
// 2. 执行图像分类:调用核心分类方法,返回分类结果
Classifications result = classify(imagePath);
// 3. 打印分类结果(判空:避免模型推理失败导致空指针)
if (result != null) {
System.out.println("\n===== 分类结果 =====");
// 获取置信度最高的类别名称(best()返回top1分类结果)
System.out.println("最可能的类别: " + result.best().getClassName());
// 获取最高置信度并格式化(转百分比,保留2位小数)
System.out.println("置信度: " + String.format("%.2f", result.best().getProbability() * 100) + "%");
System.out.println("\n----- 前5个可能类别 -----");
int i = 1;
// topK(5):获取置信度前5的分类结果,遍历打印
for (Classifications.Classification classification : result.topK(5)) {
System.out.printf("%d. %s: %.2f%%\n",
i++, // 排名序号
classification.getClassName(), // 类别名称(如n02124075 Egyptian cat)
classification.getProbability() * 100); // 置信度(转百分比)
}
}
} catch (IOException e) {
// 捕获图片读取异常(如路径错误、文件不存在、权限不足)
System.err.println("无法读取图像文件: " + e.getMessage());
} catch (ModelException e) {
// 捕获模型相关异常(如模型加载失败、权重损坏)
System.err.println("模型处理错误: " + e.getMessage());
e.printStackTrace();
} catch (TranslateException e) {
// 捕获推理过程异常(如输入格式错误、张量维度不匹配)
System.err.println("推理转换错误: " + e.getMessage());
e.printStackTrace();
}
}
/**
* 核心分类方法:完成模型加载、图片预处理、推理预测
*/
public static Classifications classify(String imagePath)
throws IOException, ModelException, TranslateException {
// 步骤1: 定义图像预处理管道(Pipeline)
// 作用:串联多个图像变换操作,统一输入格式以适配模型要求
Pipeline pipeline = new Pipeline();
// 预处理1:调整图像尺寸为224x224
// 原因:ResNet模型基于ImageNet训练,固定输入尺寸为224x224;尺寸不匹配会导致维度错误或推理结果异常
pipeline.add(new Resize(224, 224))
// 预处理2:将图像转换为张量(ToTensor)
// 原因:深度学习模型仅能处理张量(Tensor)格式;转换后数据范围从[0,255]归一化到[0,1],符合模型训练规范
.add(new ToTensor());
// 步骤2: 创建图像分类翻译器(Translator)
// 作用:桥梁,将Java的Image对象转为模型输入张量,将模型输出张量转为Classifications对象
ImageClassificationTranslator translator =
ImageClassificationTranslator.builder()
// 绑定预处理管道:对输入图片执行Resize+ToTensor
.setPipeline(pipeline)
// 启用Softmax:将模型输出的logits转为概率分布(便于理解置信度)
// 原因:ResNet输出的是原始得分(logits),Softmax后转换为0-1的概率值
.optApplySoftmax(true)
.build();
// 步骤3: 创建模型加载条件(Criteria)
// 作用:定义模型的输入输出类型、来源、预处理规则等,是DJL加载模型的核心配置
Criteria<Image, Classifications> criteria =
Criteria.builder()
// 设置输入类型(Image)和输出类型(Classifications)
// 原因:明确模型的输入输出格式,DJL自动完成类型转换
.setTypes(Image.class, Classifications.class)
// 指定应用场景:计算机视觉-图像分类
// 原因:帮助ModelZoo筛选适配的预训练模型,提升加载效率
.optApplication(Application.CV.IMAGE_CLASSIFICATION)
// 指定模型来源:DJL官方预训练ResNet模型(PyTorch版本)
// 格式说明:djl:// 是DJL的模型仓库协议,ai.djl.pytorch/resnet 指向PyTorch版ResNet
.optModelUrls("djl://ai.djl.pytorch/resnet")
// 绑定翻译器:关联预处理和后处理逻辑
.optTranslator(translator)
// 启用进度条:显示模型下载/加载进度
.optProgress(new ProgressBar())
.build();
// 打印当前使用的深度学习引擎名称(如PyTorch/TensorFlow)
// 原因:验证引擎是否正确加载,便于排查引擎初始化问题
System.out.println("正在使用的引擎: " + Engine.getInstance().getEngineName());
// 步骤4: 加载模型(核心步骤)
System.out.println("正在加载ResNet模型(首次加载需要下载,请耐心等待)...");
try {
// 从ModelZoo加载模型:根据Criteria配置自动下载/加载ResNet预训练模型
// 注意:此处未使用try-with-resources,需手动确保资源释放(优化建议:后续可改为自动释放)
ZooModel<Image, Classifications> model = ModelZoo.loadModel(criteria);
System.out.println("模型加载成功!");
System.out.println("模型名称: " + model.getName()); // 打印模型名称(如resnet18)
// 步骤5: 加载图像
// Paths.get():将字符串路径转为Java NIO的Path对象,兼容不同操作系统
Path path = Paths.get(imagePath);
// ImageFactory.getInstance():获取默认图像工厂(自动适配本地图片格式:PNG/JPG等)
// fromFile():从本地文件加载图片,返回Image对象
Image image = ImageFactory.getInstance().fromFile(path);
// 打印图像原始尺寸:便于验证图片是否正确加载,以及预处理前的尺寸
System.out.println("图像尺寸: " + image.getWidth() + "x" + image.getHeight());
// 步骤6: 创建预测器并进行推理
// newPredictor():创建模型预测器,每个预测器对应一个推理会话
Predictor<Image, Classifications> predictor = model.newPredictor();
// predict():执行推理,输入Image对象,输出分类结果
return predictor.predict(image);
} catch (Exception e) {
// 捕获模型加载/推理过程中的所有异常,打印日志并返回null
System.err.println("模型处理错误: " + e.getMessage());
e.printStackTrace();
return null;
}
}
}
输出结果
===== 分类结果 =====
最可能的类别: n02124075 Egyptian cat
置信度: 29.48%
----- 前5个可能类别 -----
1. n02124075 Egyptian cat: 29.48%
2. n02123045 tabby, tabby cat: 18.92%
3. n02123159 tiger cat: 14.52%
4. n04589890 window screen: 5.31%
5. n02123394 Persian cat: 2.04%
关键点说明
张量
- 张量是深度学习里的 “多维数据盒子”,能装单个数字、一排数字、表格状数字,甚至像彩色图片那样的多层表格数据;
- 代码里图片会先转成 3 维张量(3 层 224×224),是模型能看懂的唯一数据格式;
- 张量支持 GPU 加速计算,是 ResNet 模型完成图像分类的核心数据载体。
Pipeline
- Pipeline 是 DJL 中管理图像预处理的核心组件,可按顺序串联缩放、转张量、归一化等多个图像变换操作,统一执行预处理逻辑;
- 它能将任意格式 / 尺寸的输入图像转换为模型要求的标准张量格式,适配深度学习模型的输入规格;
- 与 Translator 绑定后可实现预处理自动化,解耦预处理与核心推理逻辑,提升代码复用性和可维护性。
Translator
- Translator 是 DJL 中连接「输入数据」与「模型」、「模型输出」与「业务结果」的核心桥梁组件;
- 它统一处理输入数据的预处理(如绑定 Pipeline)和模型输出的后处理(如格式转换、概率归一化);
- 不同任务有专属实现(如图像分类的 ImageClassificationTranslator),适配各类深度学习任务的输入输出转换需求,让开发者无需关注底层张量变换细节。
ImageClassificationTranslator
- ImageClassificationTranslator 是 DJL 专为图像分类任务设计的翻译器,核心承担「格式转换桥梁」作用;
- 它一端对接 Pipeline 完成输入图像的预处理,另一端将模型输出的原始张量转换为含类别、置信度的 Classifications 对象;
- 支持配置 Softmax 等后处理规则,简化从原始模型输出到可读分类结果的转换,且可灵活适配不同图像分类模型的输入输出要求。
Criteria
- Criteria 是 DJL 中加载预训练模型的核心配置类,用于定义模型加载的全量规则;
- 它指定模型的输入输出类型、应用场景(如图像分类)、模型来源(如官方 ResNet),并绑定 Translator 等关键组件;
- 作为 ModelZoo 加载模型的依据,统一管控模型下载、初始化逻辑,确保加载的模型适配业务的输入输出要求。
ModelZoo
- ModelZoo 是 DJL 的预训练模型仓库,提供官方维护的各类深度学习预训练模型(如 ResNet)的统一加载入口;
- 它依据 Criteria 配置的规则,自动完成模型权重下载、引擎适配、模型初始化等操作;
- 无需手动管理模型文件,简化了从配置到加载可用模型的全流程,降低深度学习模型的使用门槛。
ResNet
- ResNet(残差网络)是 DJL ModelZoo 中内置的经典图像分类预训练模型,基于 ImageNet 数据集训练,适配 1000 类图像分类任务;
- 它要求输入图像为 224×224 尺寸的张量格式,通过残差块结构解决深层网络退化问题,具备较强的特征提取能力;
- 在代码中通过 Criteria 指定模型来源(djl://ai.djl.pytorch/resnet),由 ModelZoo 自动加载,是实现图像分类的核心模型载体。
Predictor
- Predictor 是 DJL 中执行模型推理的核心类,由 ZooModel 创建,专门负责将输入数据送入模型并输出推理结果;
- 它封装了模型推理的底层细节,只需调用 predict () 方法传入预处理后的输入(如图像),即可得到结构化的输出(如 Classifications);
- 每个 Predictor 对应一个独立的推理会话,支持重复调用,是连接加载好的模型与实际推理任务的直接入口。
入门示例 - 目标检测
导入依赖
<!-- 目标检测专用依赖 -->
<dependency>
<groupId>ai.djl</groupId>
<artifactId>model-zoo</artifactId>
<version>${djl.version}</version>
</dependency>
<!-- 图像处理增强 -->
<dependency>
<groupId>ai.djl</groupId>
<artifactId>basicdataset</artifactId>
<version>${djl.version}</version>
</dependency>
<!-- 绘图工具(用于可视化) -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10.1</version>
</dependency>
代码
package com.woniuxy.image;
import ai.djl.Application;
import ai.djl.ModelException;
import ai.djl.engine.Engine;
import ai.djl.inference.Predictor;
import ai.djl.modality.Classifications;
import ai.djl.modality.cv.Image;
import ai.djl.modality.cv.ImageFactory;
import ai.djl.modality.cv.output.BoundingBox;
import ai.djl.modality.cv.output.DetectedObjects;
import ai.djl.modality.cv.output.Rectangle;
import ai.djl.modality.cv.util.NDImageUtils;
import ai.djl.ndarray.NDArray;
import ai.djl.ndarray.NDManager;
import ai.djl.repository.zoo.Criteria;
import ai.djl.repository.zoo.ModelZoo;
import ai.djl.repository.zoo.ZooModel;
import ai.djl.training.util.ProgressBar;
import ai.djl.translate.TranslateException;
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
/**
* YOLOv5目标检测完整示例
* 功能:
* 1. 检测图片中的多个物体
* 2. 绘制边界框和标签
* 3. 保存可视化结果
* 4. 显示检测统计信息
*/
public class ObjectDetectionDemo {
// 颜色数组,用于不同类别的边界框着色
private static final Color[] COLORS = {
Color.RED, Color.GREEN, Color.BLUE, Color.YELLOW,
Color.CYAN, Color.MAGENTA, Color.ORANGE, Color.PINK
};
public static void main(String[] args) {
// ============= 配置参数 =============
String imagePath = "C:\\Users\\Administrator\\Desktop\\animal\\QQ20251223-151011.png"; // 替换为你的图片路径
String outputPath = "C:\\Users\\Administrator\\Desktop\\animal\\dest.png";
float confidenceThreshold = 0.3f; // 置信度阈值,过滤低置信度检测
System.out.println("启动YOLOv5目标检测...");
System.out.println("输入图片: " + imagePath);
System.out.println("输出图片: " + outputPath);
System.out.println("置信度阈值: " + confidenceThreshold);
try {
// ============= 执行目标检测 =============
DetectedObjects detections = detectObjects(imagePath, confidenceThreshold);
// ============= 可视化结果 =============
System.out.println("\n检测结果统计:");
System.out.println("总检测数: " + detections.getNumberOfObjects());
if (detections.getNumberOfObjects() > 0) {
// 打印检测到的物体信息
System.out.println("\n检测到的物体:");
int index = 1;
for (Classifications.Classification obj : detections.items()) {
DetectedObjects.DetectedObject detectedObject = (DetectedObjects.DetectedObject) obj;
String className = detectedObject.getClassName();
double confidence = detectedObject.getProbability();
BoundingBox box = detectedObject.getBoundingBox();
System.out.printf("%d. %-20s 置信度: %.2f%% 位置: [x=%.0f, y=%.0f, w=%.0f, h=%.0f]\n",
index++,
className,
confidence * 100,
box.getBounds().getX(),
box.getBounds().getY(),
box.getBounds().getWidth(),
box.getBounds().getHeight());
}
// 绘制边界框并保存图片
boolean saved = drawBoundingBoxes(imagePath, outputPath, detections);
if (saved) {
System.out.println("\n可视化结果已保存至: " + outputPath);
}
// 按类别统计
System.out.println("\n类别统计:");
detections.items().stream()
.collect(java.util.stream.Collectors.groupingBy(
Classifications.Classification::getClassName,
java.util.stream.Collectors.counting()))
.forEach((className, count) ->
System.out.printf(" %-15s: %d 个\n", className, count));
} else {
System.out.println("未检测到任何物体,请尝试:");
System.out.println(" 1. 降低置信度阈值(当前: " + confidenceThreshold + ")");
System.out.println(" 2. 更换包含明显物体的图片");
System.out.println(" 3. 检查图片质量(避免过于模糊)");
}
} catch (IOException e) {
System.err.println("文件读取错误: " + e.getMessage());
} catch (ModelException | TranslateException e) {
System.err.println("模型处理错误: " + e.getMessage());
e.printStackTrace();
}
}
/**
* 执行目标检测的核心方法
* @param imagePath 图片路径
* @param threshold 置信度阈值
* @return 检测结果
*/
public static DetectedObjects detectObjects(String imagePath, float threshold)
throws IOException, ModelException, TranslateException {
System.out.println("\n初始化检测引擎...");
System.out.println("当前引擎: " + Engine.getInstance().getEngineName());
// ============= 步骤1: 创建检测标准 =============
Criteria<Image, DetectedObjects> criteria = Criteria.builder()
.setTypes(Image.class, DetectedObjects.class)
.optApplication(Application.CV.OBJECT_DETECTION)
.optModelUrls("djl://ai.djl.pytorch/yolov5s") // YOLOv5小版本,速度快
.optEngine("PyTorch")
.optArgument("size", 640) // 输入图片大小
.optArgument("resize", true) // 自动调整大小
.optArgument("threshold", threshold) // 置信度阈值
.optArgument("synsetFileName", "coco.names") // COCO数据集类别名
.optProgress(new ProgressBar()) // 显示进度条
.build();
// ============= 步骤2: 加载模型 =============
System.out.println("📥 加载YOLOv5模型(首次使用需下载,约30MB)...");
try (ZooModel<Image, DetectedObjects> model = ModelZoo.loadModel(criteria)) {
System.out.println("模型加载成功: " + model.getName());
// ============= 步骤3: 加载图片 =============
Path path = Paths.get(imagePath);
if (!Files.exists(path)) {
throw new IOException("图片文件不存在: " + imagePath);
}
Image image = ImageFactory.getInstance().fromFile(path);
System.out.println("图片尺寸: " + image.getWidth() + "x" + image.getHeight());
System.out.println("开始检测物体...");
// ============= 步骤4: 执行检测 =============
long startTime = System.currentTimeMillis();
try (Predictor<Image, DetectedObjects> predictor = model.newPredictor()) {
DetectedObjects detections = predictor.predict(image);
long endTime = System.currentTimeMillis();
System.out.printf("检测耗时: %.2f 秒\n", (endTime - startTime) / 1000.0);
return detections;
}
}
}
/**
* 在图片上绘制边界框并保存
* @param inputPath 原始图片路径
* @param outputPath 输出图片路径
* @param detections 检测结果
* @return 是否保存成功
*/
public static boolean drawBoundingBoxes(String inputPath, String outputPath,
DetectedObjects detections) {
try {
// 加载原始图片
BufferedImage originalImage = ImageIO.read(Paths.get(inputPath).toFile());
if (originalImage == null) {
System.err.println("无法读取图片: " + inputPath);
return false;
}
// 创建Graphics2D进行绘制
Graphics2D g = originalImage.createGraphics();
// 设置绘制参数
g.setStroke(new BasicStroke(3)); // 边框粗细
Font font = new Font("Microsoft YaHei", Font.BOLD, 16);
g.setFont(font);
int colorIndex = 0;
// 为每个检测结果绘制边界框
for (Classifications.Classification detection : detections.items()) {
DetectedObjects.DetectedObject detectedObject = (DetectedObjects.DetectedObject) detection;
String className = detectedObject.getClassName();
double confidence = detectedObject.getProbability();
Rectangle rectangle = detectedObject.getBoundingBox().getBounds();
// 计算实际像素坐标
int imageWidth = originalImage.getWidth();
int imageHeight = originalImage.getHeight();
int x = (int) (rectangle.getX() * imageWidth);
int y = (int) (rectangle.getY() * imageHeight);
int width = (int) (rectangle.getWidth() * imageWidth);
int height = (int) (rectangle.getHeight() * imageHeight);
// 选择颜色
Color color = COLORS[colorIndex % COLORS.length];
colorIndex++;
// 绘制边界框
g.setColor(color);
g.drawRect(x, y, width, height);
// 绘制标签背景
String label = String.format("%s (%.1f%%)", className, confidence * 100);
FontMetrics metrics = g.getFontMetrics();
int labelWidth = metrics.stringWidth(label) + 10;
int labelHeight = metrics.getHeight() + 4;
g.setColor(color);
g.fillRect(x, y - labelHeight, labelWidth, labelHeight);
// 绘制标签文字
g.setColor(Color.WHITE);
g.drawString(label, x + 5, y - 5);
// 可选:绘制四个角标
drawCorners(g, x, y, width, height, color);
}
g.dispose(); // 释放图形资源
// 保存图片
String format = outputPath.substring(outputPath.lastIndexOf('.') + 1);
ImageIO.write(originalImage, format, Paths.get(outputPath).toFile());
return true;
} catch (IOException e) {
System.err.println("保存图片失败: " + e.getMessage());
return false;
}
}
/**
* 在边界框四角绘制小三角形(增强视觉效果)
*/
private static void drawCorners(Graphics2D g, int x, int y, int width, int height, Color color) {
int cornerSize = 15; // 角标大小
g.setColor(color);
g.setStroke(new BasicStroke(4));
// 左上角
g.drawLine(x, y, x + cornerSize, y);
g.drawLine(x, y, x, y + cornerSize);
// 右上角
g.drawLine(x + width - cornerSize, y, x + width, y);
g.drawLine(x + width, y, x + width, y + cornerSize);
// 左下角
g.drawLine(x, y + height - cornerSize, x, y + height);
g.drawLine(x, y + height, x + cornerSize, y + height);
// 右下角
g.drawLine(x + width - cornerSize, y + height, x + width, y + height);
g.drawLine(x + width, y + height - cornerSize, x + width, y + height);
}
/**
* 批量处理多张图片
*/
public static void batchDetect(List<String> imagePaths, String outputDir)
throws IOException, ModelException, TranslateException {
System.out.println("开始批量处理 " + imagePaths.size() + " 张图片...");
// 创建输出目录
Files.createDirectories(Paths.get(outputDir));
// 初始化模型(只加载一次,重复使用)
Criteria<Image, DetectedObjects> criteria = Criteria.builder()
.setTypes(Image.class, DetectedObjects.class)
.optApplication(Application.CV.OBJECT_DETECTION)
.optModelUrls("djl://ai.djl.pytorch/yolov5s")
.build();
try (ZooModel<Image, DetectedObjects> model = ModelZoo.loadModel(criteria);
Predictor<Image, DetectedObjects> predictor = model.newPredictor()) {
int processed = 0;
for (String imagePath : imagePaths) {
try {
System.out.printf("\n处理第 %d/%d 张: %s\n",
++processed, imagePaths.size(), imagePath);
// 检测
Image image = ImageFactory.getInstance().fromFile(Paths.get(imagePath));
DetectedObjects detections = predictor.predict(image);
// 生成输出路径
String fileName = Paths.get(imagePath).getFileName().toString();
String outputPath = Paths.get(outputDir,
fileName.replace(".", "_detected.")).toString();
// 绘制并保存
if (drawBoundingBoxes(imagePath, outputPath, detections)) {
System.out.printf(" 检测到 %d 个物体,结果保存至: %s\n",
detections.getNumberOfObjects(), outputPath);
}
} catch (Exception e) {
System.err.println("处理失败: " + imagePath + " - " + e.getMessage());
}
}
System.out.println("\n批量处理完成!");
}
}
}
运行过程中yolov5s可能会下载失败,多运行几次试试,如果不行就手动下载zip然后解压到
C:\Users\当前用户\.djl.ai\cache\repo\model\cv\object_detection\ai\djl\pytorch\yolov5s\0.0.1\yolov5s目录中,并且在该目录中创建coco.names文件,完整文件列表如下所示

coco.names中添加以下内容
person
bicycle
car
motorcycle
airplane
bus
train
truck
boat
traffic light
fire hydrant
stop sign
parking meter
bench
bird
cat
dog
horse
sheep
cow
elephant
bear
zebra
giraffe
backpack
umbrella
handbag
tie
suitcase
frisbee
skis
snowboard
sports ball
kite
baseball bat
baseball glove
skateboard
surfboard
tennis racket
bottle
wine glass
cup
fork
knife
spoon
bowl
banana
apple
sandwich
orange
broccoli
carrot
hot dog
pizza
donut
cake
chair
couch
potted plant
bed
dining table
toilet
tv
laptop
mouse
remote
keyboard
cell phone
microwave
oven
toaster
sink
refrigerator
book
clock
vase
scissors
teddy bear
hair drier
toothbrush
coco.names 是YOLOv5模型的"翻译词典",它把模型识别的80种物体编号(0-79)转换成对应的中文名称,比如把数字"15"翻译成"猫",让计算机的识别结果变成人类能看懂的文字。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)