2026年泰迪杯A题超详细解题思路+附赠数据分析代码+初步代码
若某地形特征在路线沿线的分布与全区分布存在显著差异,则修路者在该特征上存在主动选择,即对应规划原则成立。题目说明NA表示不属于陕甘八县的区域,因此NA分为两类:县域内部的缺失像元(需插值补全)和县域外部的无效像元(保持NA不动)。将秦直道沿线的地形特征分布与陕甘八县全区特征分布进行对比,若两者存在显著差异(p < 0.05),则说明修路者在该特征维度上做出了有意识的选择,即存在对应规划原则。在现代
泰迪杯作为2026年上半年竞赛难度天花板竞赛(由于竞赛时间长、数据量大导致整体难度大)。本文将为大家带来A题的超详细解题思路、具体数据分析、命题分析、模型讲解以及后续解题中可能遇到的难点。预计通过5~10分钟的时间让大家迅速了解A题的相关信息。
针对于数据类型的分析,专门编写了代码去提取不同表格的特征。完整的代码放于文末,提取结果如下所示
|
数据集 |
规模 |
坐标范围(x/m) |
坐标范围(y/m) |
|
DEM高程CSV |
8781行×10396列 |
1,251,834 ~ 1,480,414 |
3,900,485 ~ 4,194,226 |
|
秦直道路线 |
38,923点 |
1,277,950 ~ 1,376,155 |
3,948,071 ~ 4,109,884 |
|
一级分水岭 |
47,248点 |
1,276,339 ~ 1,398,514 |
3,954,477 ~ 4,114,109 |
|
二级分水岭 |
6,341点 |
1,370,865 ~ 1,376,167 |
3,942,933 ~ 3,975,849 |
|
河网 |
24,226点 |
1,264,000 ~ 1,461,954 |
3,907,720 ~ 4,181,709 |
|
遗迹(烽火台/关隘/遗存) |
76点 |
1,283,638 ~ 1,376,136 |
3,938,904 ~ 4,115,186 |
表1 高程CSV数据 数据结构:二维规则栅格(Raster/Grid),维度:8781 × 10396,分辨率 dx = 21.99 m 、dy = 33.46 m
|
变量 |
类型 |
说明 |
|
行索引(y) |
float(连续变量) |
空间坐标(北ing) |
|
列索引(x) |
float(连续变量) |
空间坐标(Easting) |
|
高程值(cell value) |
float(连续变量) |
地形高程(单位:m) |
|
NA值 |
missing |
无数据区域 |
表2 附件2(多图层矢量数据)
「秦直道」表类型:点序列(Line String的离散表达)
|
字段 |
类型 |
|
x坐标/m |
float |
|
y坐标/m |
float |
「一级分水岭」类型:点集→ 线状地形骨架 数据类型:连续变量(float)
「二级分水岭」坐标:连续型 ID:离散型
|
字段 |
类型 |
|
序号 |
int(离散变量) |
|
x坐标/m |
float |
|
y坐标/m |
float |
「河网」结构同上
「烽火台、关隘及遗存」
|
字段 |
类型 |
数据类型 |
|
县名 |
string |
分类变量(categorical) |
|
类型 |
string |
分类变量 |
|
文物名称 |
string |
文本 |
|
朝代 |
string |
分类变量(时间类) |
|
x坐标/m |
float |
连续变量 |
|
y坐标/m |
float |
连续变量 |
表3 县界数据
|
字段 |
类型 |
|
x |
float |
|
y |
float |
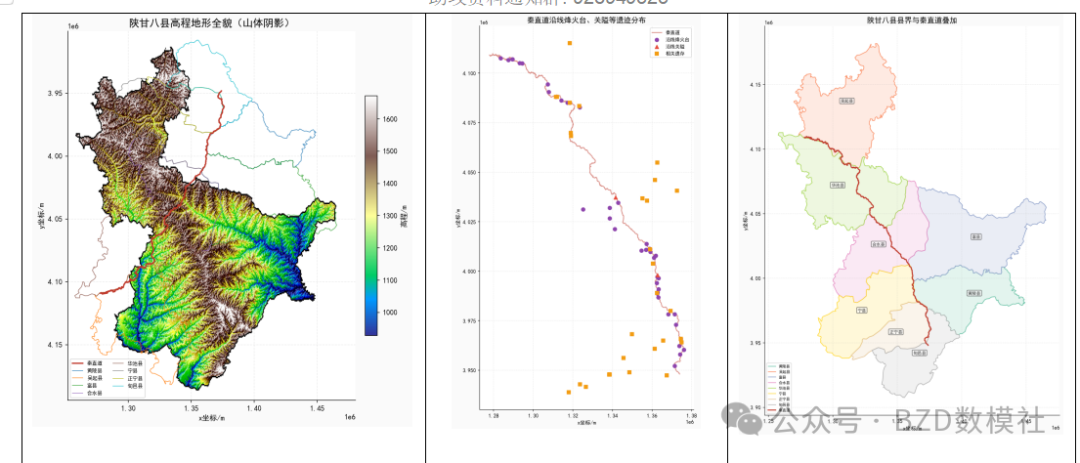
问题一:地形特征分析与量化计算
数据预处理
读取DEM数据后,首先需要处理NA值。题目说明NA表示不属于陕甘八县的区域,因此NA分为两类:县域内部的缺失像元(需插值补全)和县域外部的无效像元(保持NA不动)。
基于插值后的DEM,利用二阶中心差分算子计算全域衍生地形栅格(注意DEM为非正方形像元,,需分别处理):

|
序号 |
特征名称 |
物理含义 |
计算窗口/范围 |
|
1 |
高程/m |
绝对海拔高度 |
点值(双线性采样) |
|
2 |
坡度/° |
地面倾斜角度 |
3×3像元(66m×100m) |
|
3 |
坡向/° |
坡面朝向(0=北,顺时针) |
3×3像元 |
|
4 |
剖面曲率 |
沿坡向的曲率(凸凹性) |
3×3像元 |
|
5 |
平面曲率 |
垂直坡向的曲率(汇散性) |
3×3像元 |
|
6 |
地形起伏度/m |
窗口内高程极差 |
11×11像元(242m×368m) |
|
7 |
地表粗糙度 |
实际面积/投影面积 |
3×3像元 |
|
8 |
局部高程百分位/% |
相对局部地势高低 |
51×51像元(1.1km×1.7km) |
|
9 |
地形湿度指数TWI |
汇水与排水倾向 |
流域尺度 |
|
10 |
沿线纵坡/% |
路线坡度(平滑后) |
相邻路线点间 |
|
11 |
路线方向角/° |
行进方向(正北顺时针) |
相邻路线点间 |
|
12 |
沿线累计距离/m |
从路线起点的累计里程 |
沿路线 |
|
13 |
与一级分水岭距离/m |
路线偏离主分水岭程度 |
KD-Tree最近邻 |
|
14 |
与二级分水岭距离/m |
路线偏离次分水岭程度 |
KD-Tree最近邻 |
|
15 |
与河网距离/m |
路线规避水系程度 |
KD-Tree最近邻 |
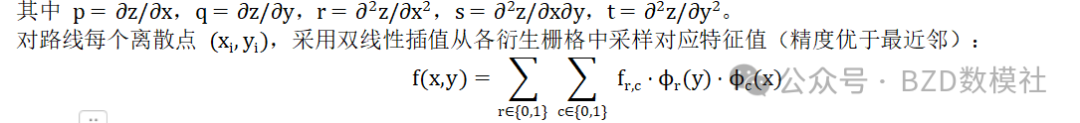
问题二:路线规划原则与设施设置原则挖掘
本问题是在问题1量化结果基础上的模式挖掘。其本质是:通过对比秦直道沿线地形特征分布与陕甘八县全区地形特征分布的差异,统计验证然后归纳出路线规划原则;同时利用42个烽火台和3个关隘遗址的坐标,反推其选址逻辑。
将秦直道沿线的地形特征分布与陕甘八县全区特征分布进行对比,若两者存在显著差异(p < 0.05),则说明修路者在该特征维度上做出了有意识的选择,即存在对应规划原则
若某地形特征在路线沿线的分布与全区分布存在显著差异,则修路者在该特征上存在主动选择,即对应规划原则成立。采用双样本KS检验(Kolmogorov-Smirnov Test):
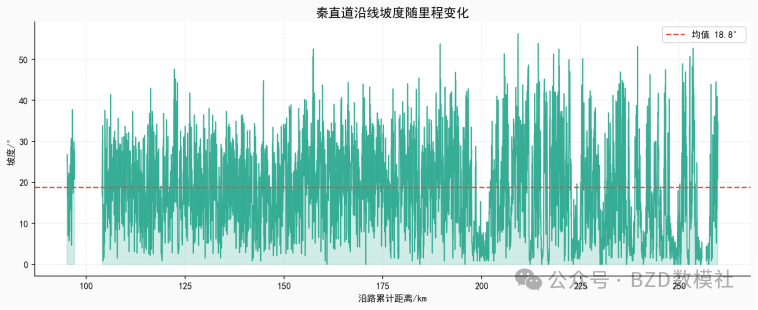
原则一:坡度最小化原则
检验路线沿线坡度均值是否显著低于全区,量化结果:路线坡度均值 vs 全区坡度均值,KS检验
值。
原则二:沿一级分水岭脊线行进原则
路线弯曲系数为1.68,远非直线,说明路线刻意沿地形绕行。计算路线点与一级分水岭的距离分布,验证80%路线点是否在分水岭某距离阈值以内,并与蒙特卡洛随机路线对比:

原则1【坡度最小化】
沿线均值=10.30° 全区均值=12.57°
KS检验: stat=0.1287, p=0.0000e+00 ★显著
原则2【沿分水岭脊线】
与一级分水岭距离: 均值=1.47km 中位数=0.06km 80%点<0.17km
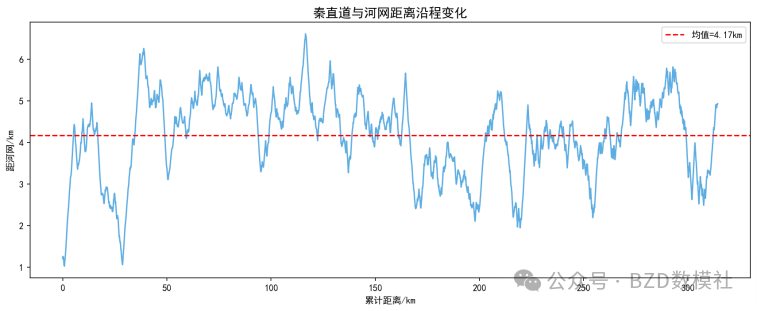
原则3【避开河网低洼】
与河网距离: 均值=4.17km <1km的占比=0.0% <500m占比=0.0%
原则4【高程带偏好】
沿线高程范围=1010~1675m 均值=1395m 标准差=175m
全区标准差=187m → 沿线高程更集中
原则5【线形顺直】
路线总长=314.29km 直线距=187.55km 弯曲系数=1.6758
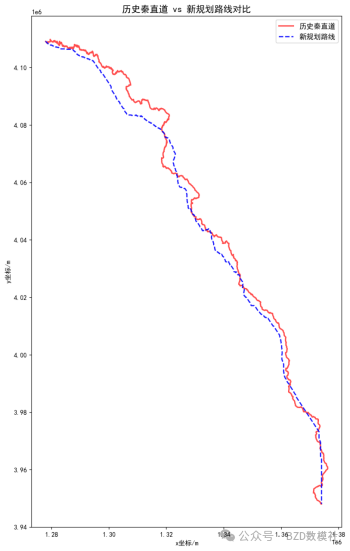
问题三:重新规划秦直道路线
本问题是空间最优路径规划问题。在现代地形数据下,以问题2归纳的规划原则为约束与目标,重新寻找符合古代选线逻辑的最优路线。

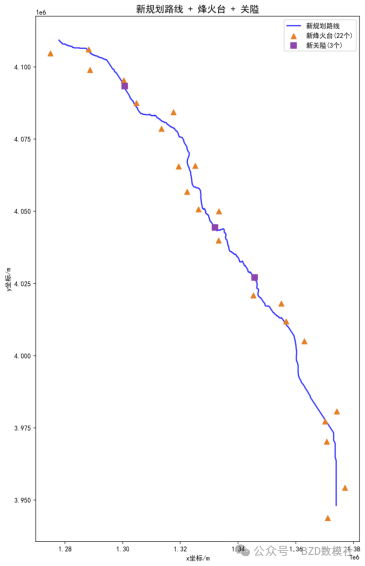
问题四:重新规划烽火台和关隘
本问题是设施选址优化问题,包含两个子任务:烽火台选址(以最少数量实现对全线的连续视觉覆盖)和关隘选址(在地形咽喉处控制交通要道)。
第一步:烽火台候选点筛选
从新路线两侧3km缓冲区内,依据问题2归纳的烽火台选址原则,筛选候选点集合:
条件①:局部高程百分位
(参考历史42个烽火台分布统计)
条件②:坡度 (具备建设条件)
条件③:为半径1km范围内的局部高程极大值点对距离过近(km)的候选点,保留高程更高者去除冗余,得到精简候选集。对每个候选点,以15km为可视半径,结合DEM计算其通视域 (即从 可见的新路线点集合)。

"""
泰迪杯A题:秦直道路线规划 —— 数据读取与探索性分析
运行环境:Python 3.8+
依赖:pip install pandas numpy matplotlib openpyxl rasterio scipy
"""
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
from matplotlib.patches import Patch
import warnings
warnings.filterwarnings('ignore')
# ============================================================
# 0. 路径配置
# ============================================================
DATA_DIR = r"C:\Users\24404\Desktop\泰迪杯数据"
DEM_CSV = os.path.join(DATA_DIR, "陕甘八县的高程数据.csv")
DEM_TIF = os.path.join(DATA_DIR, "陕甘八县的高程数据.tif")
ANNEX2 = os.path.join(DATA_DIR, "附件2 秦直道及周边地形和相关遗迹的数据.xlsx")
ANNEX3 = os.path.join(DATA_DIR, "附件3 甘陕八县的县界数据.xlsx")
plt.rcParams['font.family'] = 'SimHei' # 中文显示
plt.rcParams['axes.unicode_minus'] = False
# ============================================================
# 1. 读取 DEM CSV
# ============================================================
print("=" * 60)
print("【模块1】读取高程CSV数据")
print("=" * 60)
# 第1行为x坐标(列头),第1列为y坐标(行头)
dem_raw = pd.read_csv(DEM_CSV, header=0, index_col=0, low_memory=False)
print(f"原始形状(行×列): {dem_raw.shape}")
print(f" 行索引(y坐标)范围: {float(dem_raw.index[0]):.2f} ~ {float(dem_raw.index[-1]):.2f} m")
print(f" 列索引(x坐标)范围: {float(dem_raw.columns[0]):.2f} ~ {float(dem_raw.columns[-1]):.2f} m")
# 转为浮点型数组(NA -> np.nan)
dem_raw.replace('NA', np.nan, inplace=True)
dem_raw = dem_raw.astype(float)
y_coords = dem_raw.index.astype(float).values # 纬向坐标数组
x_coords = dem_raw.columns.astype(float).values # 经向坐标数组
dem_array = dem_raw.values # (nrows, ncols) 高程矩阵
# 栅格分辨率
dx = np.mean(np.diff(x_coords))
dy = np.mean(np.abs(np.diff(y_coords)))
print(f" 栅格分辨率: dx={dx:.3f} m, dy={dy:.3f} m")
# 有效像元统计
valid_mask = ~np.isnan(dem_array)
total_cells = dem_array.size
valid_cells = valid_mask.sum()
print(f" 总像元数: {total_cells:,}")
print(f" 有效像元数: {valid_cells:,} ({valid_cells/total_cells*100:.1f}%)")
print(f" NA像元数: {total_cells - valid_cells:,}")
elev_valid = dem_array[valid_mask]
print(f"\n【高程统计(有效像元)】")
print(f" 最小值: {elev_valid.min():.2f} m")
print(f" 最大值: {elev_valid.max():.2f} m")
print(f" 均值: {elev_valid.mean():.2f} m")
print(f" 中位数: {np.median(elev_valid):.2f} m")
print(f" 标准差: {elev_valid.std():.2f} m")
print(f" 25%分位: {np.percentile(elev_valid,25):.2f} m")
print(f" 75%分位: {np.percentile(elev_valid,75):.2f} m")
# ============================================================
# 2. 读取附件2(多工作表)
# ============================================================
print("\n" + "=" * 60)
print("【模块2】读取附件2:秦直道及周边地形和相关遗迹")
print("=" * 60)
xl2 = pd.ExcelFile(ANNEX2)
print(f"工作表列表: {xl2.sheet_names}")
sheets2 = {}
for name in xl2.sheet_names:
df = xl2.parse(name)
sheets2[name] = df
print(f"\n ── 工作表「{name}」──")
print(f" 形状: {df.shape}(行×列)")
print(f" 列名: {list(df.columns)}")
if 'x坐标/m' in df.columns and 'y坐标/m' in df.columns:
print(f" x范围: {df['x坐标/m'].min():.2f} ~ {df['x坐标/m'].max():.2f} m")
print(f" y范围: {df['y坐标/m'].min():.2f} ~ {df['y坐标/m'].max():.2f} m")
print(df.head(3).to_string(index=False))
# 单独提取常用数据
road = sheets2['秦直道'].copy()
ridge1 = sheets2['一级分水岭'].copy()
ridge2 = sheets2['二级分水岭'].copy()
river = sheets2['河网'].copy()
relics = sheets2['烽火台、关隘及相关遗存'].copy()
print(f"\n【秦直道点数】: {len(road)}")
print(f"【一级分水岭点数】: {len(ridge1)}")
print(f"【二级分水岭点数】: {len(ridge2)}")
print(f"【河网点数】: {len(river)}")
print(f"【遗迹点数】: {len(relics)}")
# 遗迹类型统计
if '类型' in relics.columns:
print(f"\n【遗迹类型分布】:\n{relics['类型'].value_counts().to_string()}")
else:
# 尝试识别列
print(f"遗迹数据列名: {list(relics.columns)}")
print(relics.head(10).to_string())
# ============================================================
# 3. 读取附件3(多工作表)
# ============================================================
print("\n" + "=" * 60)
print("【模块3】读取附件3:陕甘八县县界数据")
print("=" * 60)
xl3 = pd.ExcelFile(ANNEX3)
print(f"工作表列表: {xl3.sheet_names}")
sheets3 = {}
for name in xl3.sheet_names:
df = xl3.parse(name)
sheets3[name] = df
pts = len(df)
print(f" 「{name}」: {pts} 个边界点")
# ============================================================
# 4. 计算秦直道基本几何特征
# ============================================================
print("\n" + "=" * 60)
print("【模块4】秦直道基本几何特征")
print("=" * 60)
rx = road['x坐标/m'].values
ry = road['y坐标/m'].values
# 逐段距离
dx_seg = np.diff(rx)
dy_seg = np.diff(ry)
seg_len = np.sqrt(dx_seg**2 + dy_seg**2)
total_len = seg_len.sum() / 1000 # km
# 直线距离(首尾)
straight = np.sqrt((rx[-1]-rx[0])**2 + (ry[-1]-ry[0])**2) / 1000
# 弯曲系数
sinuosity = total_len / straight
# 方向角(相对正北,顺时针)
bearing = np.degrees(np.arctan2(dx_seg, dy_seg))
print(f" 路线总点数: {len(road)}")
print(f" 路线总长度: {total_len:.2f} km")
print(f" 首尾直线距离: {straight:.2f} km")
print(f" 弯曲系数: {sinuosity:.4f}")
print(f" 平均段长: {seg_len.mean():.2f} m")
print(f" 方向角范围: {bearing.min():.1f}° ~ {bearing.max():.1f}°")
print(f" 主体方向(均值): {bearing.mean():.1f}°")
# ============================================================
# 5. 从DEM采样秦直道沿线高程
# ============================================================
print("\n" + "=" * 60)
print("【模块5】秦直道沿线高程采样")
print("=" * 60)
def sample_dem(x_q, y_q, x_coords, y_coords, dem_array):
"""最近邻采样 DEM"""
col_idx = np.argmin(np.abs(x_coords - x_q))
row_idx = np.argmin(np.abs(y_coords - y_q))
return dem_array[row_idx, col_idx]
road_elev = np.array([
sample_dem(rx[i], ry[i], x_coords, y_coords, dem_array)
for i in range(len(rx))
])
road_elev_valid = road_elev[~np.isnan(road_elev)]
print(f" 采样点总数: {len(road_elev)}")
print(f" 有效采样点: {len(road_elev_valid)}")
print(f" 沿线高程最小: {np.nanmin(road_elev):.2f} m")
print(f" 沿线高程最大: {np.nanmax(road_elev):.2f} m")
print(f" 沿线高程均值: {np.nanmean(road_elev):.2f} m")
print(f" 沿线高程标准差: {np.nanstd(road_elev):.2f} m")
# 全区高程 vs 沿线高程对比
print(f"\n 【对比】全区均值: {elev_valid.mean():.2f} m vs 沿线均值: {np.nanmean(road_elev):.2f} m")
# 沿线累计距离
cum_dist = np.concatenate([[0], np.cumsum(seg_len)]) / 1000 # km
# 沿线纵坡计算
road_grade = np.diff(road_elev) / seg_len * 100 # 百分比坡度
print(f"\n 沿线纵坡(%)统计:")
print(f" 最大上坡: {np.nanmax(road_grade):.2f}%")
print(f" 最大下坡: {np.nanmin(road_grade):.2f}%")
print(f" 平均绝对坡度: {np.nanmean(np.abs(road_grade)):.2f}%")
# ============================================================
# 6. 可视化
# ============================================================
print("\n" + "=" * 60)
print("【模块6】生成可视化图表")
print("=" * 60)
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle("秦直道数据探索性分析", fontsize=16, fontweight='bold')
# (A) DEM缩略图
ax = axes[0, 0]
# 降采样以加快绘图
step = max(1, dem_array.shape[0] // 300)
dem_thumb = dem_array[::step, ::step]
im = ax.imshow(dem_thumb, cmap='terrain', aspect='auto',
vmin=np.nanpercentile(dem_thumb, 2),
vmax=np.nanpercentile(dem_thumb, 98))
ax.set_title("陕甘八县高程分布(缩略)")
ax.set_xlabel("列索引"); ax.set_ylabel("行索引")
plt.colorbar(im, ax=ax, label="高程/m", shrink=0.8)
# (B) 全区高程频率分布
ax = axes[0, 1]
ax.hist(elev_valid, bins=100, color='steelblue', alpha=0.75, density=True)
ax.axvline(np.nanmean(road_elev), color='red', lw=2, label=f'沿线均值 {np.nanmean(road_elev):.0f}m')
ax.axvline(elev_valid.mean(), color='orange', lw=2, linestyle='--', label=f'全区均值 {elev_valid.mean():.0f}m')
ax.set_title("高程频率分布直方图")
ax.set_xlabel("高程/m"); ax.set_ylabel("密度")
ax.legend()
# (C) 秦直道纵断面图
ax = axes[0, 2]
ax.plot(cum_dist, road_elev, color='saddlebrown', lw=1.2)
ax.fill_between(cum_dist, road_elev, np.nanmin(road_elev)-10, alpha=0.2, color='saddlebrown')
ax.set_title("秦直道沿线高程纵断面")
ax.set_xlabel("沿路累计距离/km"); ax.set_ylabel("高程/m")
ax.grid(True, alpha=0.3)
# (D) 平面路线 + 县界 + 遗迹
ax = axes[1, 0]
colors_county = plt.cm.Set3(np.linspace(0, 1, len(sheets3)))
for (cname, cdf), col in zip(sheets3.items(), colors_county):
if 'x坐标/m' in cdf.columns:
ax.plot(cdf['x坐标/m'], cdf['y坐标/m'], lw=0.8, color=col, label=cname)
ax.plot(rx, ry, 'r-', lw=1.5, label='秦直道', zorder=5)
# 遗迹
if 'x坐标/m' in relics.columns:
for _, row in relics.iterrows():
ax.plot(row['x坐标/m'], row['y坐标/m'], 'k^', ms=5, zorder=6)
ax.set_title("秦直道平面路线与县界")
ax.set_xlabel("x坐标/m"); ax.set_ylabel("y坐标/m")
ax.legend(fontsize=6, ncol=2)
ax.set_aspect('equal')
# (E) 沿线纵坡分布
ax = axes[1, 1]
valid_grade = road_grade[~np.isnan(road_grade)]
ax.hist(valid_grade, bins=60, color='darkorange', alpha=0.8)
ax.axvline(0, color='k', lw=1)
ax.set_title("秦直道沿线纵坡分布")
ax.set_xlabel("纵坡/%"); ax.set_ylabel("频数")
ax.grid(True, alpha=0.3)
# (F) 分水岭 + 河网 + 路线叠加
ax = axes[1, 2]
if 'x坐标/m' in ridge1.columns:
ax.plot(ridge1['x坐标/m'], ridge1['y坐标/m'], 'b-', lw=1, label='一级分水岭', alpha=0.8)
if 'x坐标/m' in ridge2.columns:
ax.plot(ridge2['x坐标/m'], ridge2['y坐标/m'], 'c-', lw=0.7, label='二级分水岭', alpha=0.6)
if 'x坐标/m' in river.columns:
ax.plot(river['x坐标/m'], river['y坐标/m'], 'steelblue', lw=0.4, alpha=0.4, label='河网')
ax.plot(rx, ry, 'r-', lw=1.5, label='秦直道', zorder=5)
ax.set_title("路线与分水岭、河网叠加")
ax.set_xlabel("x坐标/m"); ax.set_ylabel("y坐标/m")
ax.legend(fontsize=7)
ax.set_aspect('equal')
plt.tight_layout()
out_fig = os.path.join(DATA_DIR, "data_exploration.png")
plt.savefig(out_fig, dpi=150, bbox_inches='tight')
print(f" 图表已保存: {out_fig}")
plt.show()
# ============================================================
# 7. 输出数据概要报告
# ============================================================
print("\n" + "=" * 60)
print("【模块7】数据概要汇总")
print("=" * 60)
summary = {
"DEM栅格大小(行×列)": f"{dem_array.shape[0]} × {dem_array.shape[1]}",
"栅格分辨率(m)": f"{dx:.2f} × {dy:.2f}",
"全区高程范围(m)": f"{elev_valid.min():.1f} ~ {elev_valid.max():.1f}",
"全区高程均值(m)": f"{elev_valid.mean():.2f}",
"全区高程标准差(m)": f"{elev_valid.std():.2f}",
"秦直道路线总长(km)": f"{total_len:.2f}",
"弯曲系数": f"{sinuosity:.4f}",
"沿线高程范围(m)": f"{np.nanmin(road_elev):.1f} ~ {np.nanmax(road_elev):.1f}",
"沿线高程均值(m)": f"{np.nanmean(road_elev):.2f}",
"沿线平均绝对纵坡(%)": f"{np.nanmean(np.abs(road_grade)):.2f}",
"遗迹总数": len(relics),
"县界数量": len(sheets3),
}
for k, v in summary.items():
print(f" {k:30s}: {v}")
print("\n✅ 数据读取与探索性分析完成!")
print(" 下一步:运行地形特征计算脚本(问题1)")

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)