数据仓库与数据挖掘 - 软考备战(三十五)
数据库系统(七)
参考资料:
一文搞懂什么是数据仓库(Data Warehouse)数据仓库与数据库区别有哪些?什么是元数据? - 知乎
5.7 数据仓库与数据挖掘
1. 数据仓库(DW)四大基本特征
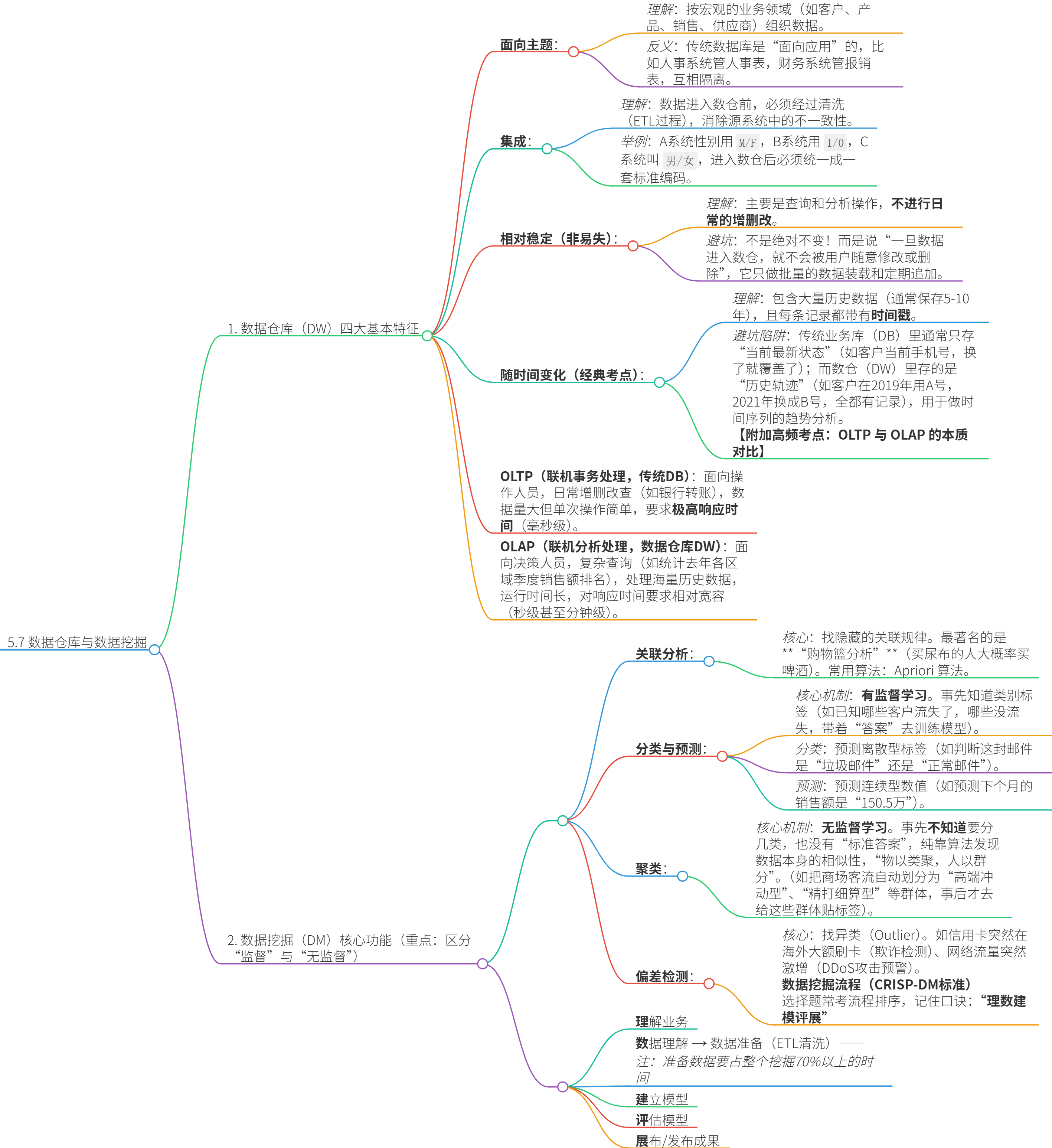
数据仓库不是用来替代业务数据库(OLTP系统)的,而是建在业务库之上,专门用来做分析(OLAP系统)的。
面向主题
按宏观的业务领域(如客户、产品、销售、供应商)组织数据。
传统数据库是“面向应用”的,比如人事系统管人事表,财务系统管报销表,互相隔离。
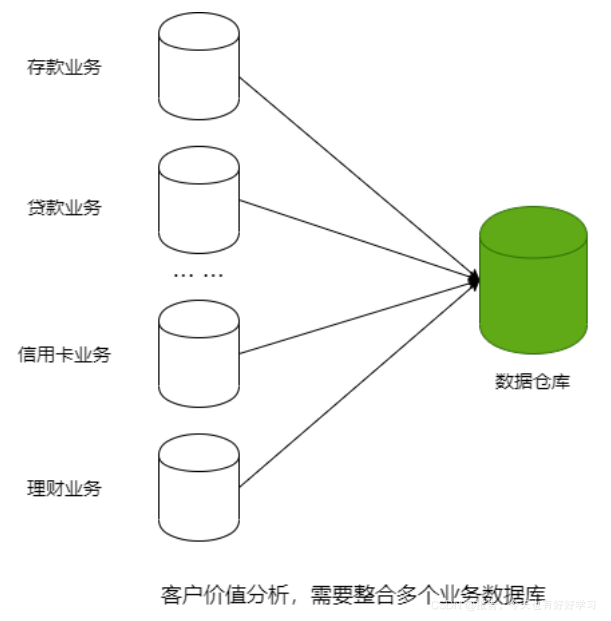
集成
数据进入数仓前,必须经过清洗(ETL过程),消除源系统中的不一致性。
举例:A系统性别用 M/F,B系统用 1/0,C系统叫 男/女,进入数仓后必须统一成一套标准编码。
相对稳定(非易失)
主要是查询和分析操作,不进行日常的增删改。
不是绝对不变!一旦数据进入数仓,就不会被用户随意修改或删除,它只做批量的数据装载和定期追加。
随时间变化
包含大量历史数据(通常保存5-10年),且每条记录都带有时间戳。
传统业务库(DB)里通常只存“当前最新状态”(如客户当前手机号,换了就覆盖了);
而数仓(DW)里存的是“历史轨迹”(如客户在2019年用A号,2021年换成B号,全都有记录),用于做时间序列的趋势分析。
OLTP 与 OLAP 的本质对比
OLTP(联机事务处理,传统DB)
面向操作人员,日常增删改查(如银行转账),数据量大但单次操作简单,要求极高响应时间(毫秒级)。
OLAP(联机分析处理,数据仓库DW)
面向决策人员,复杂查询(如统计去年各区域季度销售额排名),处理海量历史数据,运行时间长,对响应时间要求相对宽容(秒级甚至分钟级)。
2. 数据挖掘(DM)核心功能
数据挖掘是从海量数据中“淘金”的过程。
关联分析
具体内容链接:关联规则概述-CSDN博客
找隐藏的关联规律,“购物篮分析”(买尿布的人大概率买啤酒)。
常用算法:Apriori 算法。
分类与预测
具体内容链接:分类分析概述-CSDN博客
有监督学习。
事先知道类别标签(如已知哪些客户流失了,哪些没流失,带着“答案”去训练模型)。
分类
预测离散型标签(如判断这封邮件是“垃圾邮件”还是“正常邮件”)。
预测
预测连续型数值(如预测下个月的销售额是“150.5万”)。
聚类
具体内容链接:聚类 分析_聚类分析csdn-CSDN博客
无监督学习。
事先不知道要分几类,也没有“标准答案”,纯靠算法发现数据本身的相似性,“物以类聚,人以群分”。
(如把商场客流自动划分为“高端冲动型”、“精打细算型”等群体,事后才去给这些群体贴标签)。
偏差检测
找异类(Outlier)。
如信用卡突然在海外大额刷卡(欺诈检测)、网络流量突然激增(DDoS攻击预警)。
数据挖掘流程(CRISP-DM标准)
“理数建模评展”
理解业务
数据理解——> 数据准备(ETL清洗)
注:准备数据要占整个挖掘70%以上的时间
建立模型
评估模型
展布/发布成果

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)