BP神经网络:误差反向传播公式的简单推导
最近看了一下BP神经网络(Backpropagation Neural Networks),发现很多资料对于BP神经网络的讲解注重原理,而对于反向传播公式的推导介绍的比较简略,故自己根据《PATTERN RECOGNITION AND MACHINE LEARNING》这本书的思路推导了一下反向传播的过程,记录在这里,以便以后看。
最近看了一下BP神经网络(Backpropagation Neural Networks),发现很多资料对于BP神经网络的讲解注重原理,而对于反向传播公式的推导介绍的比较简略,故自己根据《PATTERN RECOGNITION AND MACHINE LEARNING》这本书的思路推导了一下反向传播的过程,记录在这里,以便以后看。对于BP神经网络的工作原理此处就不再赘述,周志华大牛的《机器学习》中介绍的很详细。
PS: 本人第一次写博客,不足之处还请见谅。
1. BP网络模型及变量说明
1.1 模型简图
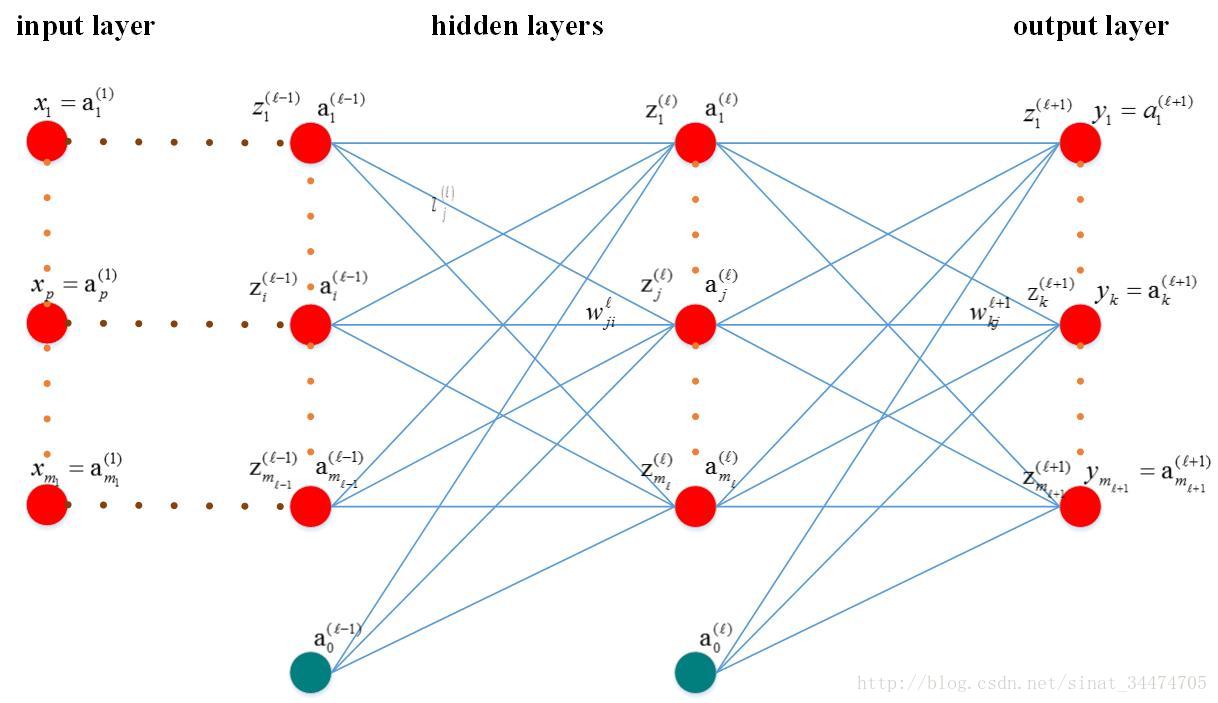
1.2 变量说明:
-
ml<script type="math/tex" id="MathJax-Element-1">m_l</script>:第l<script type="math/tex" id="MathJax-Element-2">l</script>层神经元个数
-
x(1)p <script type="math/tex" id="MathJax-Element-3">x_p^{(1)}</script>: 输入层第p<script type="math/tex" id="MathJax-Element-4">p</script>个神经元,p=1...m1 <script type="math/tex" id="MathJax-Element-5">p=1...m_1</script>; -
yk<script type="math/tex" id="MathJax-Element-6">y_k</script> : 输出层第k<script type="math/tex" id="MathJax-Element-7">k</script>的神经元的输出,
k=1...ml+1 <script type="math/tex" id="MathJax-Element-8">k=1...m_{l+1}</script>; -
tk<script type="math/tex" id="MathJax-Element-9">t_k</script>:输出层第k<script type="math/tex" id="MathJax-Element-10">k</script>的神经元的目标值,
k=1...ml+1 <script type="math/tex" id="MathJax-Element-11">k=1...m_{l+1}</script>; -
z(l)j<script type="math/tex" id="MathJax-Element-12">z_j^{(l)}</script>:第l<script type="math/tex" id="MathJax-Element-13">l</script>层的第
j <script type="math/tex" id="MathJax-Element-14">j</script>的神经元的输入; -
a(l)j<script type="math/tex" id="MathJax-Element-15">a_j^{(l)}</script>:第l<script type="math/tex" id="MathJax-Element-16">l</script>层第
j <script type="math/tex" id="MathJax-Element-17">j</script>个神经元的输出; -
a(l)0<script type="math/tex" id="MathJax-Element-18">a_0^{(l)}</script>:第l<script type="math/tex" id="MathJax-Element-19">l</script>层的偏置项;
-
w(l)ji <script type="math/tex" id="MathJax-Element-20">w_{ji}^{(l)}</script>:第l−1<script type="math/tex" id="MathJax-Element-21">l-1</script>层第i<script type="math/tex" id="MathJax-Element-22">i</script>个神经元与第l <script type="math/tex" id="MathJax-Element-23">l</script>层第j<script type="math/tex" id="MathJax-Element-24">j</script>个神经元的连接权值; -
h(.) <script type="math/tex" id="MathJax-Element-25">h(.)</script>:激活函数,这里假设每一层各个神经元的激励函数相同(实际中可能不同); -
Ep<script type="math/tex" id="MathJax-Element-26">E_p</script>:网络在第p<script type="math/tex" id="MathJax-Element-27">p</script>个样本输入下的偏差,
n=1...N <script type="math/tex" id="MathJax-Element-28">n=1...N</script>; -
N<script type="math/tex" id="MathJax-Element-29">N</script>:样本总数
2. 误差反向传播相关推导
2.1 正向传播(forward-propagation)
正向传播的思想比较直观,最主要的是对于激活函数的理解。对于网络中第
如果令wj0=1<script type="math/tex" id="MathJax-Element-34">w_{j0}=1</script>,可以将公式简写为:
则经过该神经元后的输出值为:
对于多分类问题,网络输出层第k<script type="math/tex" id="MathJax-Element-37">k</script>个神经元输出可表示为:
这里说明一下,BP神经网络中激活函数通常会取sigmoid<script type="math/tex" id="MathJax-Element-39">sigmoid</script>函数或tanh<script type="math/tex" id="MathJax-Element-40">tanh</script>函数,不清楚的可以百度一下这两个函数,这里不再赘述。
2.2 代价函数(cost function)
由2.1节公式可以得到BP网络在一个样本下的输出值,我们定义平方和误差函数(sum-of-square error function)如下:
所有样本输入下,网络的总误差为:
2.3 反向传播(back-propagation)
这是BP神经网络最核心的部分,误差从输出层逐层反向传播,各层权值通过梯度下降法(gradient descent algorithm)进行更新,即:
上式中,η<script type="math/tex" id="MathJax-Element-82">\eta</script>是每次更新的步长,▽Ep(w)<script type="math/tex" id="MathJax-Element-83">\bigtriangledown{E_p}(w)</script>是第p<script type="math/tex" id="MathJax-Element-84">p</script>个样本输入下的输出偏差对某一层权值的偏导数,表示每输入一个样本更新一次参数。
下面我们以
这里我们定义δ(l)j=∂Ep∂z(l)j<script type="math/tex" id="MathJax-Element-87">\delta_j^{(l)}=\dfrac{\partial E_p}{\partial z_j^{(l)}} </script>,对于输出层,可以得出δ(l+1)k=yk−tk=a(l+1)k−tk<script type="math/tex" id="MathJax-Element-88">\delta_k^{(l+1)}=y_k-t_k=a_k^{(l+1)}-t_k</script>,则上式可表示为:
现在问题转换为求解δ(l+1)k<script type="math/tex" id="MathJax-Element-90">\delta_k^{(l+1)}</script>:
根据δ<script type="math/tex" id="MathJax-Element-92">\delta</script>的定义可知∂Ep∂z(l+1)k=δ(l+1)k<script type="math/tex" id="MathJax-Element-93">\dfrac{\partial E_p}{\partial z_k^{(l+1)}} = \delta_k^{(l+1)}</script>,代入上式,则:
根据z(l+1)k<script type="math/tex" id="MathJax-Element-95">z_k^{(l+1)}</script>和alj<script type="math/tex" id="MathJax-Element-96">a_j^l</script>的定义可知:
代入上式得:
由此我们得到了误差从输出层向低层反向传播的递推公式,进而可以求出误差对于每一层权值的梯度▽Ep(w)<script type="math/tex" id="MathJax-Element-99">\bigtriangledown{E_p}(w)</script>
3. 总结
BP神经网络是应用最多的一种神经网络,其精髓在于误差反向传播。本人在学习这块内容是为了给接下来学习和研究深度学习及caffe做准备,由于个人水平有限,在上述推导中可能存在不合理的地方,还请见谅,同时也欢迎指出内容的不足之处。
4. 参考文献
[1] 周志华,机器学习[M] , 清华大学出版社,2016.
[2] CHRISTOPHER M.BISHOP. PATTERN RECOGNITION AND MACHINE LEARNING [M], 2006.

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)