数据分析Python工具Jupter Notebook快速部署
写在前面正在学习数据分析,或者想从事数据分析事业的你,都在用什么Python工具进行算法验证和结果分析的呢?仍旧在使用Python脚本,还是eclipseByPython,还是IDEAbyPython?小编今天与大家分享一个数据分析和Python编写代码的好工具,它就是Jupyter,不论是在学术界还是工业界,Jupyter都已经开始逐步发力,走入主流市场。Jupy
写
在
前
面
正在学习数据分析,或者想从事数据分析事业的你,都在用什么Python工具进行算法验证和结果分析的呢?仍旧在使用Python脚本,还是eclipseByPython,还是IDEAbyPython?
小编今天与大家分享一个数据分析和Python编写代码的好工具,它就是Jupyter,不论是在学术界还是工业界,Jupyter都已经开始逐步发力,走入主流市场。
Jupyter Notebook 顾名思义,它的核心在于展示与快速迭代。其有且不止以下优势:
-
适合数据分析的 处理-计算-分析 的过程,不需要再专门写报告
-
交互式编程, 边看边写
-
一次运行, 多次阅读,保存运行结果
-
Python带来的丰富的第三方包支持,不需要自己再重复造轮子
本文会分享一下如何快速部署自己的Jupyter Notebook,并快速的使用Jupyter上进行科学计算。
Jupyter安装部署
1、下载安装包
https://repo.continuum.io/archive/
2、安装bzip2
yum install bzip2
3、安装
bash Anaconda3-4.2.0-Linux-x86_64.sh -b -p /opt/conda
4、配置环境变量
vim /etc/profileexport PATH=/opt/conda/bin:$PATH
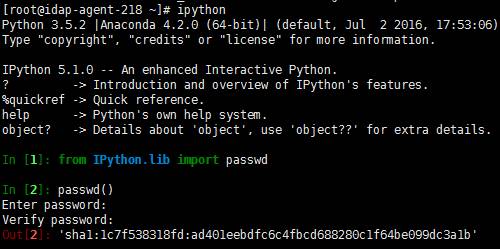
5、配置Security
# 退出command重新登录ipython
from IPython.lib import passwd
passwd()
6、保存SSL证书
!mkdir certificate
cd certificate
!openssl req -x509 -nodes -days 365 -newkey rsa:1024 -keyout mycert.pem -out mycert.pem

7、配置Jupyter notebook
# jupyter notebook --generate-config
# cd ~
# cd .jupyter
# vim jupyter_notebook_config.py
c = get_config()
# Kernel config
c.IPKernelApp.pylab = 'inline' # if you want plotting support always
# Notebook config
c.NotebookApp.certfile = u'/opt/certificate/mycert.pem'
c.NotebookApp.ip = '*'c.NotebookApp.open_browser = False
c.NotebookApp.password = u'sha1:1c7f538318fd:ad401eebdfc6c4fbcd688280c1f64be099dc3a1b'
# It is a good idea to put it on a known, fixed port
c.NotebookApp.port = 8888
c.NOtebookApp.notebook_dir=u"/notebook"
8、运行Jupyter Notebook
jupyter notebook --allow-root
9、集成R Kernel
# 安装R时icu会与anaconda原有的包冲突需要先删除此链接
rm -rf /opt/anaconda3/lib/icu/current
conda install r r-essentials readline
yum install libXdmcp gcc-c++
10、集成pyspark
cd ~
vim .ipython/profile_default/startup/00-first.py
00-first.py内容如下:
import os
import sys
# Configure the environment
if 'SPARK_HOME' not in
os.environ: os.environ['SPARK_HOME'] = '/opt/spark-2.0.2-bin-hadoop2.7'
# Create a variable for our root path
SPARK_HOME = os.environ['SPARK_HOME']
# Add the PySpark/py4j to the Python Path
sys.path.insert(0, os.path.join(SPARK_HOME, "python", "build"))
sys.path.insert(0, os.path.join(SPARK_HOME, "python"))
11、add kernel
conda create -n py35 python=3.5.2 ipykernel
source active py35
ipython kernel install --user
以上是正常的安装过程,安装期间如有问题,请留言。
PS:因排版问题,总结的常见问题就不在本文中体现了。

其实你也可以做的很专业,专业可以让你信心满满。

欢迎转发到朋友圈或分享给好友

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)