机器学习与深度学习系列连载: 第三部分 强化学习(十八) 深度强化学习-模仿学习 Imitation Learning
深度强化学习-模仿学习 Imitation Learning
深度强化学习-模仿学习 Imitation Learning
模仿是人类学习的关键一环,即使没有任何奖励。
强化学习一直围绕着奖励Reward展开,但是存在以下两个问题:
- 在实际生活中Reward总是很稀疏,甚至没有Reward;
- 手工设计的Reward可能会导致无法控制的行为
我们又想到了人类的学习过程,模仿!
儿童是通过模仿学会了全世界最复杂的系统之一:语言。
在强化学习中,模仿学习的核心思想是:
专家指导agent如何解决问题。
总共分类两个方法:
- 行为克隆 Behavior Cloning
- 反向强化学习 Inverse Reinforcement Learning
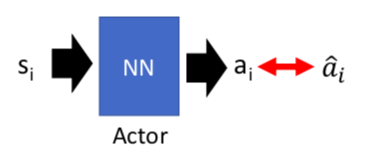
1. 行为克隆 Behavior Cloning
行为克隆顾名思义,就是将专家的行为作为监督学习,智能体agent努力学习,向专家的行为模式接近。
举例:在自动驾驶中,我们从行车记录仪中,提取人类开车行为的数据。
通过机器的行为和人类的行为的比较,机器的目标就是更加接近人类。
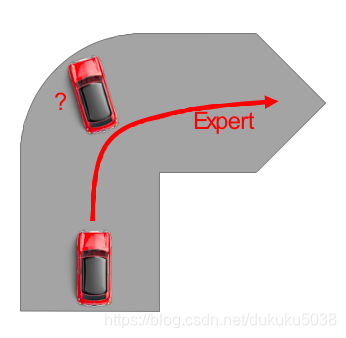
但是纯粹的模仿,会带来以下问题:
- (1) 问题1:Agent可能会遇到人类数据没有遇到的情况,Agent就无法抉择。
很简单,就让专家坐在它旁边。
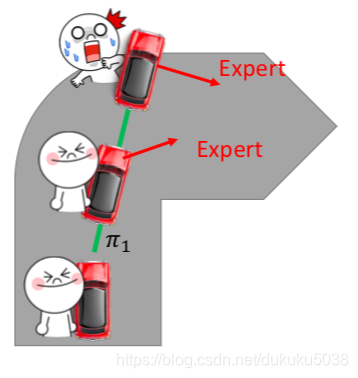
Agent在与环境互动的过程中,专家在它旁边记录数据,这就是Data Aggregation
- Get actor ?1 by behavior cloning
- Using ?1to interact with the environment
- Ask the expert to label the observation ?1 of ?1
- Using new data to train ?2
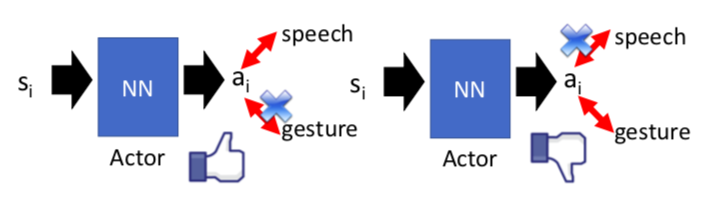
- (2) 问题2:Agent会复制任何人类的行为,即使是不当的行为
举例: 在语言学习的过程中,我们在教agent学说话的过程中,期间可能有我们的手势,但是相对于发音来说,手势不重要。可以被忽略。
- (2) 问题3:Mismatch
在监督学习中,我们期望训练数据和测试数据有同样的数据分布
在behavior cloning中, 训练数据来自expert π\piπ,测试数据来自agent 模仿expert,π^\hat{\pi}π^
但是π^\hat{\pi}π^和π\piπ不是100%相同的情况下,在中间的某个行为出现差异,整个结果很有可能就会被影响。 这就是“差之毫厘谬以千里”的道理
2. 反向强化学习 Inverse Reinforcement Learning
在强化学习中,核心的一个环节就是定义奖励Reward,但是定义Reward的过程很难。
反向强化学习就是将定义Reward的过程转换为另一个学习的过程。
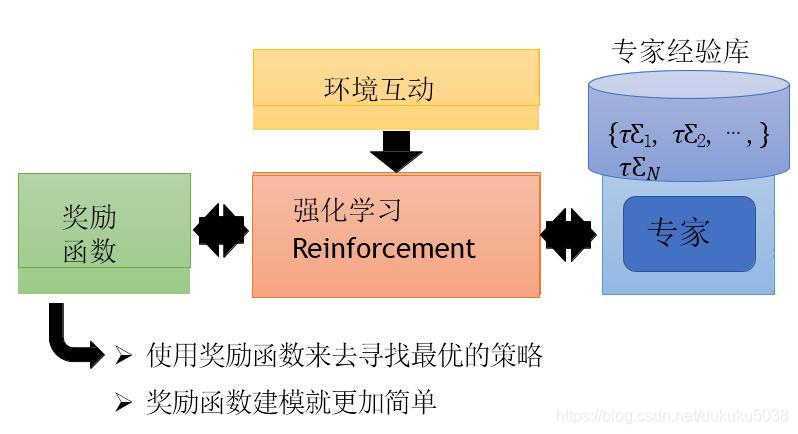
IRL的过程如下;
- 首先用专家的经验与环境互动,学习出Reward函数
- 使用Reward函数训练agent,产生agent的经验
- 然后用更新专家的经验,返回1,更新Reward函数
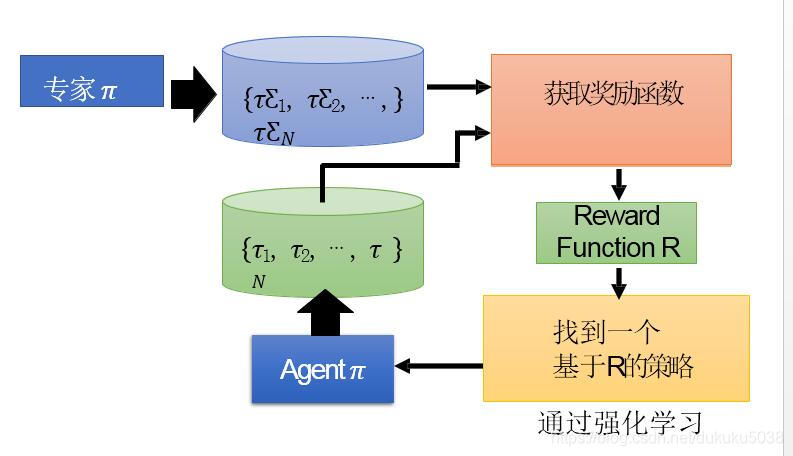
在获取奖励函数的时候,有个大的原则:专家的策略奖励比Agent的策略奖励大。
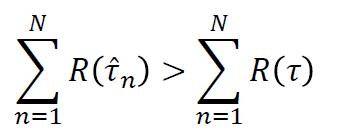
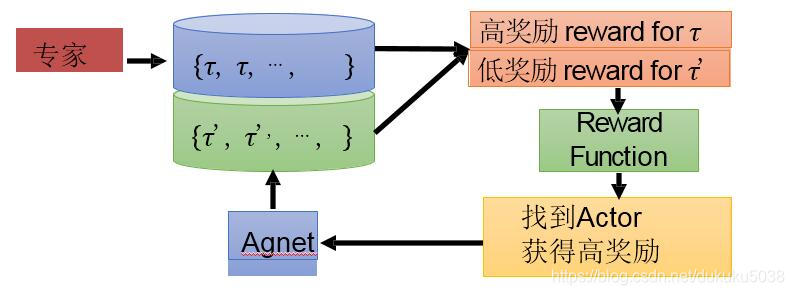
从IRL的算法过程中看,就是一个对抗网络(GAN)
- 找到一个策略 actor 就是 Generator
- 找到一个Reward函数就是Discriminator
大道至简、大道归一
3. 第三人称视角强化学习 Third Person Imitation Learning
我们通过手把手给agent教任务,可以过渡到,我们做,agent 看,类似于给agent上课。

思路参考论文:Ref: Bradly C. Stadie, Pieter Abbeel, Ilya Sutskever, “Third-Person Imitation Learning”, arXiv preprint, 2017
回到我们强化学习的第一篇内容:
Deepmind 大神David Silver讲过一个公式:
人工智能= 强化学习+深度学习

希望和大家一起进步!
本专栏图片、公式很多来自David Silver主讲的UCL-Course强化学习视频公开课和台湾大学李宏毅老师的深度强化学习课程,在这里,感谢这些经典课程,向他们致敬!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)