深度学习:隐马尔科夫模型
概率图
隐马尔科夫模型属于概率图范畴,简单介绍一下概率图模型,概率图模型(probabilistic graphical model)是一类用图的形式表示随机变量之间条件依赖关系的概率模型,是概率论与图论的结合,图中的节点表示一个或一组随机变量,节点之间的边表示变量间的概率相关关系。根据图中边的有向、无向性,模型可分为两类:有向图、无向图。有向图又称为贝叶斯网,无向图又称为马尔科夫网。
图模型的好处
对于一般的统计计算推断问题,概率模型能够很好的解决,那么引入概率图模型又能带来什么好处呢?
概率图模型吸取了图论和概率二者的长处,利用图表示与模型有关的变量的联合概率分布。具体来说:
- 它使概率模型可视化了,这样就使得一些变量之间的关系能够很容易地从图中观测出来;
- 有一些概率上的复杂的计算可以理解为图上的信息传递,这时我们就无须关注太多的复杂表达式了;
- 图模型能够用来设计新的模型。
总之,图的表达能力非常强,仅仅用点和线就可以表达随机变量之间复杂的关系。如果给关联随机变量的边在加上概率,就可进一步表达随机变量之间关系的强弱和推理逻辑了。
图模型结构
图结构是一种重要的数据结构类型,也是概率图模型的两大支柱之一。概率图模型汇总图的边可能有方向,也可能没有方向。如果一个图包含有向的边,那么这个图模型就是有向概率图模型(或称为贝叶斯网络),否则就是无向概率图模型(又称为马尔可夫网)。
如下图: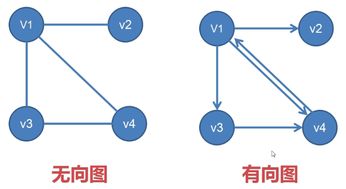
1.有向概率图
有向概率图模型使用带有方向边的图,它们用条件概率分布来表示分解。假设有向概率模型对于分布中的每一个随机变量xi都含有一个影响因子,这个组成xi条件概率的影响因子称为xi的父节点,记为g(xi),则有:
p ( x ) = ∏ p ( x i ∣ g ( x i ) ) p(x) = \prod{p(x_i\lvert{}g(x_i))} p(x)=∏p(xi∣g(xi))
2.无向概率图
无向概率图模型使用带有无向的图,它们不像有向模型那样含有影响因子,对于无向模型来说,由无向边连接的随机变量,它们之间的影响是等价的,不存在一个变量影响或决定另一个变量的概念,它们之间的影响更像一种函数关系。因此,通常将无向概率图模型分解为一组函数,这些函数通常不是任何类型的概率分布。无向模型图中任何满足两两之间有边连接的节点集合称为团,若在一个团中加入任何一个节点都不再形成团,则称该团为极大团(maximal clique)。
无向概率图模型中每个团(或极大团)都伴随着一个因子(或称为势函数)。这些因子仅仅是函数,并不是概率分布。虽然每个因子的输出都必须为非负,但不要求这些因子的和或积分为1。
随机变量的联合概率与所有这些因子的乘积成比例,虽然不能保证乘积为1,但我们可以是其归一化来得到一个概率分布,除以一个常数使其归一化这个常数被定义为ψ函数乘积的所有状态的求和或积分。
隐马尔科夫模型
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。
是在被建模的系统被认为是一个马尔可夫过程与未观测到的(隐藏的)的状态的统计马尔可夫模型。
隐马尔可夫模型三要素
隐马尔可夫模型的三要素,即确定它的三组参数,初始状态项链π状态转移概率矩阵A和观测概率矩阵B。π和A决定状态序列,B决定观测序列。因此A、B和π就是隐马尔可夫模型的三要素,而θ={π, A, B}表示控制隐马尔可夫模型参数的集合。
假设已知隐马尔可夫模型的三要素,即θ={π, A, B},我们该如何得到观测序列{x1, x2, …, xn}呢?一般可以通过以下步骤实现:
- 根据初始状态概率π,获取初始状态z1;
- 根据状态zt和输出观测概率矩阵B选择观测变量取值xt;
- 根据状态zt和状态转移矩阵A,选择确定zt+1;
- 若t<n,令t=t+1,并返回第2步,否则停止。
隐马尔可夫模型三个基本问题
下面用一个简单的例子来阐述:
假设我们手里有三个不同的骰子。第一个骰子是我们平常见到的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。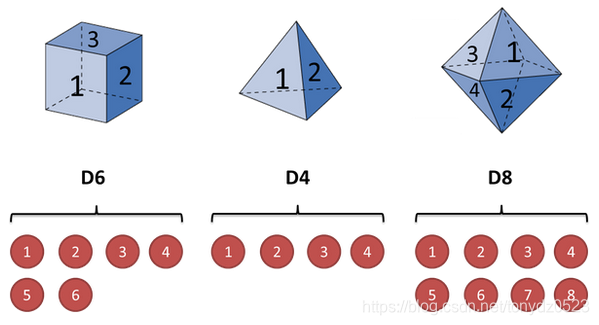
假设我们开始下列步骤:
1)从三个骰子里挑一个(挑到每一个骰子的概率都是1/3);
2)掷骰子,得到一个数字(这个数字为1、2、3、4、5、6、7、8中的一个)。
不停重复上述过程,我们会得到一串数字,每个数字都是1、2、3、4、5、6、7、8中的一个。例如我们可能得到这么一串数字(假设掷骰子10次):1 6 3 5 2 7 3 5 2 4。
这串数字叫作可见状态链或观测序列。但是在隐马尔可夫模型中,我们不仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列。比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率(transition probability)在我们这个例子里,D6的下一个状态是D4、D6、D8的概率都是1/3。D4、D8的下一个状态是D4、D6、D8的转换概率也都是1/3。这样设定是为了便于说明,但是我们其实是可以随意设定转换概率的。比如,我们可以这样定义,D6后面不能接D4, D6后面是D6的概率是0.9,是D8的概率是0.1等。这样就是一个新的HMM。
同样的,尽管可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率(emission probability)。就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。产生2,3,4,5,6的概率也都是1/6。我们同样可以对输出概率进行其他定义。比如,我有一个被赌场动过手脚的六面骰子,掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。
其实对于HMM来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。但是应用HMM模型的时候,往往是缺失了一部分信息的,有时候你知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;有时候你只是看到了很多次掷骰子的结果,剩下的什么都不知道。如果应用算法去估计这些缺失的信息,就成了一个很重要的问题,这些问题可以归纳这三个基本问题:
1.评估问题
知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道掷出这个结果的概率。看似这个问题意义不大,因为你掷出来的结果很多时候都对应了一个比较大的概率。问这个问题的目的呢,其实是检测观察到的结果和已知的模型是否吻合。如果很多次结果都对应了比较小的概率,那么就说明我们已知的模型很有可能是错的,有人偷偷把我们的骰子换掉了。
2.解码问题
知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道每次掷出来的都是哪种骰子(隐含状态链)。
这个问题其实有两种解法,会给出两个不同的答案。每个答案都对,只不过这些答案的意义不一样。第一种解法求最大似然状态路径,说通俗点呢,就是我求一串骰子序列,这串骰子序列产生观测结果的概率最大。第二种解法呢,就不是求一组骰子序列了,而是求每次掷出的骰子分别是某种骰子的概率。
举例来说,我知道我有三个骰子,六面骰,四面骰,八面骰。我也知道我掷了十次的结果(1 6 3 5 2 7 3 5 2 4),我不知道每次用了那种骰子,我想知道最有可能的骰子序列。
其实最简单而暴力的方法就是穷举所有可能的骰子序列,然后依照第零个问题的解法把每个序列对应的概率算出来。然后我们从里面把对应最大概率的序列挑出来就行了。如果马尔可夫链不长,当然可行。如果长的话,穷举的数量太大,就很难完成了。 另外一种很有名的算法叫做Viterbi algorithm. 要理解这个算法,我们先看几个简单的列子。
首先,如果我们只掷一次骰子:
看到结果为1.对应的最大概率骰子序列就是D4,因为D4产生1的概率是1/4,高于1/6和1/8.
把这个情况拓展,我们掷两次骰子:
结果为1,6.这时问题变得复杂起来,我们要计算三个值,分别是第二个骰子是D6,D4,D8的最大概率。显然,要取到最大概率,第一个骰子必须为D4。这时,第二个骰子取到D6的最大概率是 :
P 2 ( D 6 ) = P ( D 4 ) ∗ P ( D 4 → 1 ) ∗ P ( D 4 → D 6 ) ∗ P ( D 6 → 6 ) = 1 3 ∗ 1 4 ∗ 1 3 ∗ 1 6 P2(D6)=P(D4)*P(D4\to1)*P(D4\to{}D6)*P(D6\to6)=\frac1 3*\frac1 4*\frac1 3*\frac1 6 P2(D6)=P(D4)∗P(D4→1)∗P(D4→D6)∗P(D6→6)=31∗41∗31∗61
同样的,我们可以计算第二个骰子是D4或D8时的最大概率。我们发现,第二个骰子取到D6的概率最大。而使这个概率最大时,第一个骰子为D4。所以最大概率骰子序列就是D4 D6。
继续拓展,我们掷三次骰子:
结果为1,6,3。
我们计算第三个骰子分别是D6,D4,D8的最大概率。我们再次发现,要取到最大概率,第二个骰子必须为D6。这时,第三个骰子取到D4的最大概率是:
P 3 ( D 4 ) = P 2 ( D 6 ) ∗ P ( D 6 → D 4 ) ∗ P ( D 4 → 3 ) = 1 216 ∗ 1 3 ∗ 1 4 P3(D4)=P2(D6)*P(D6\to D4)*P(D4\to 3)=\frac1 {216}*\frac1 3*\frac1 4 P3(D4)=P2(D6)∗P(D6→D4)∗P(D4→3)=2161∗31∗41
同上,我们可以计算第三个骰子是D6或D8时的最大概率。我们发现,第三个骰子取到D4的概率最大。而使这个概率最大时,第二个骰子为D6,第一个骰子为D4。所以最大概率骰子序列就是D4 D6 D4。
写到这里,大家应该看出点规律了。既然掷骰子一二三次可以算,掷多少次都可以以此类推。我们发现,我们要求最大概率骰子序列时要做这么几件事情。首先,不管序列多长,要从序列长度为1算起,算序列长度为1时取到每个骰子的最大概率。然后,逐渐增加长度,每增加一次长度,重新算一遍在这个长度下最后一个位置取到每个骰子的最大概率。因为上一个长度下的取到每个骰子的最大概率都算过了,重新计算的话其实不难。当我们算到最后一位时,就知道最后一位是哪个骰子的概率最大了。然后,我们要把对应这个最大概率的序列从后往前推出来。
3.学习问题
知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),我想反推出每种骰子是什么(转换概率)。这个问题很重要,因为这是最常见的情况。很多时候我们只有可见结果,不知道HMM模型里的参数,所以需要从可见结果估计出这些参数,这是建模的一个必要步骤。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)