葡萄牙波尔图市出租车分析数据可视化部分
import numpy as npimport osimport xlrdimport datetimeimport matplotlib.pyplot as pltimport pandas as pdplt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签plt.rcParams['axes.unicode_minus']...
·
import numpy as np
import os
import xlrd
import datetime
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
os.chdir(r'E:\葡萄牙波尔图市出租车分析') #设置默认路径
#用pandas直接读取csv文件到df,这里用测试集写代码,最后再用训练集去跑代码
df=pd.read_csv('Porto_taxi_data_test_partial_trajectories.csv')
df.head()

#查看数据基本类型,查看是否有缺失值
df.info()

#查看基本的数据描述
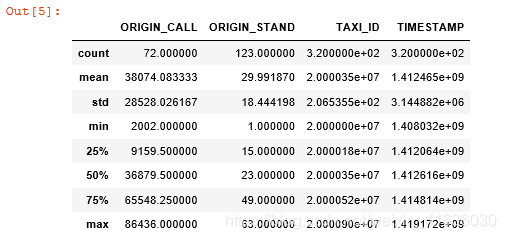
df.describe()
#将bool值转化为0/1
for u in df.columns:
if df[u].dtype==bool:
df[u]=df[u].astype('int') #将true/false转化为0/1
df.head()

df[df.MISSING_DATA==1] #验证数据是否缺失

df.shape
#找到出租车轨迹的起点位置
start_point=[]
for i in df['POLYLINE']:
i=eval(i)
start_point.append(i[0]) #输出起点值
print(start_point)

#输出出租车轨迹的终点位置
dest_point=[]
for i in df['POLYLINE']:
i=eval(i)
dest_point.append(i[-1]) #输出终点值
print(dest_point)

#找到所有轨迹点的经度最大值最小值,纬度最大值最小值
latitude=[]
altitude=[]
for i in df['POLYLINE']:
i=eval(i) #这里需要注意原来提取的i值为字符串,通过eval()可直接将表达式转化为需要的公式
for j in i:
latitude.append(j[0]) #输出经度列表
altitude.append(j[1]) #输出纬度列表
lat_min=min(latitude)
lat_max=max(latitude)
alt_min=min(altitude)
alt_max=max(altitude)
lat_len=len(latitude)
alt_len=len(altitude)
print(lat_min, lat_max, alt_min, alt_max,lat_len,alt_len)
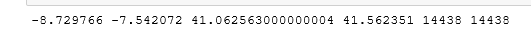
lat_count=0
alt_count=0
for i in latitude:
if i >=-8.71 and i<=-8.51:
lat_count=lat_count+1
for j in altitude:
if j >= 41.04 and j<=41.24:
alt_count=alt_count+1
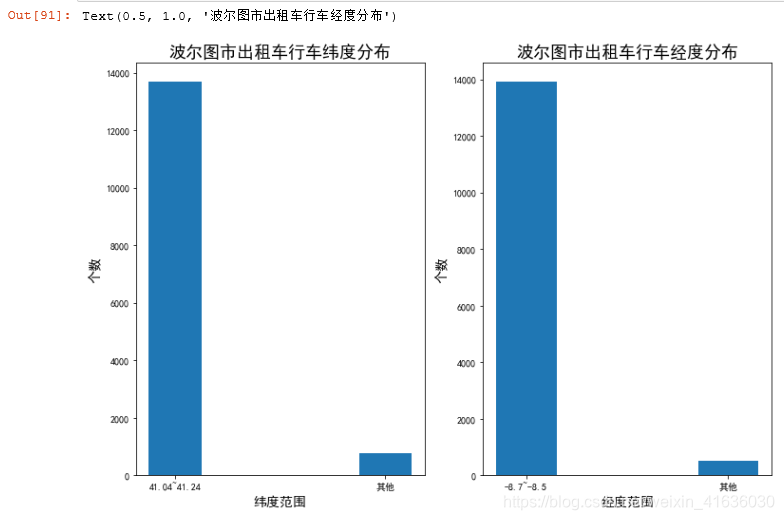
print(lat_count,alt_count)

plt.figure(figsize=(12,8))
#画出纬度图
plt.subplot(1,2,1)
values=(lat_count, lat_len-lat_count)
index=('41.04~41.24','其他')
plt.bar(index, values,width=0.25)
plt.xlabel('纬度范围',size='14')
plt.ylabel('个数',size='14')
plt.title('波尔图市出租车行车纬度分布',size='18')
#画出经度图
plt.subplot(1,2,2)
values=(alt_count, alt_len-alt_count)
index=('-8.7~-8.5','其他')
plt.bar(index, values,width=0.3)
plt.xlabel('经度范围',size='14')
plt.ylabel('个数',size='14')
plt.title('波尔图市出租车行车经度分布',size='18')
plt.figure(figsize=(6,8))
#画出缺失数图
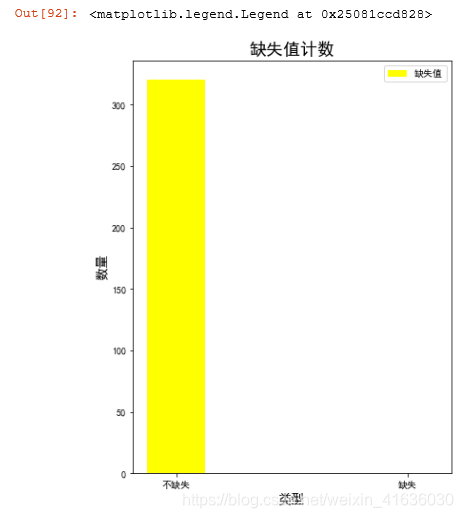
total_data=len(df)
missing_len=len(df[df.MISSING_DATA==0]) #df.MISSING_DATA表示选取MISSING_DATA这一行
index=('不缺失','缺失')
values=(missing_len, total_data-missing_len)
plt.bar(index, values,width=0.25,color='yellow')
plt.xlabel('类型',size='14')
plt.ylabel('数量',size='14')
plt.title('缺失值计数',size='18')
plt.legend(labels=['缺失值'])
set(df['CALL_TYPE']) #set()在这里是去重
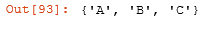
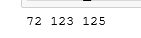
a_count=len(df[df.CALL_TYPE=='A'])
b_count=len(df[df.CALL_TYPE=='B'])
c_count=len(df[df.CALL_TYPE=='C'])
print(a_count,b_count,c_count)
plt.figure(figsize=(6,8))
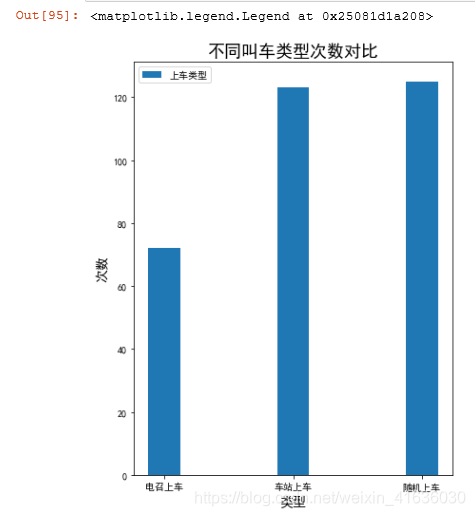
#画出不同类型的图
index=('电召上车','车站上车','随机上车')
values=(a_count, b_count, c_count)
plt.bar(index, values,width=0.25)
plt.xlabel('类型',size='14')
plt.ylabel('次数',size='14')
plt.title('不同叫车类型次数对比',size='18')
plt.legend(labels=['上车类型'])
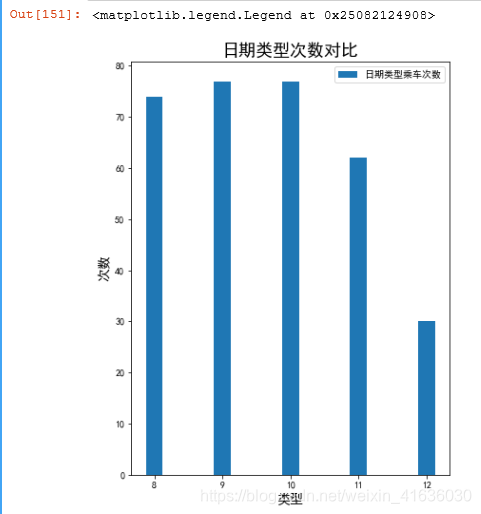
A_count=len(df[df.DAY_TYPE=='A'])
B_count=len(df[df.DAY_TYPE=='B'])
C_count=len(df[df.DAY_TYPE=='C'])
print(A_count,B_count,C_count)
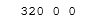
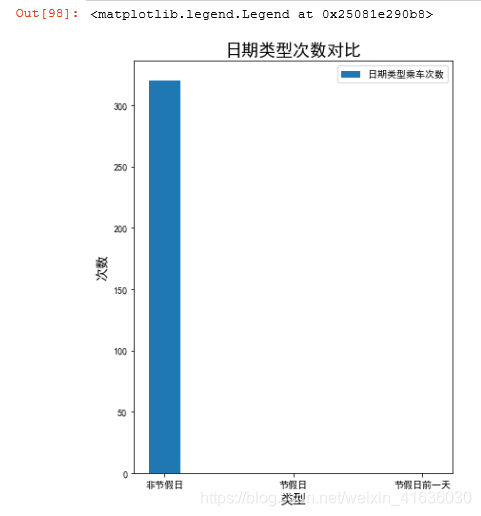
plt.figure(figsize=(6,8))
#画出不同类型的图
index=('非节假日','节假日','节假日前一天')
values=(A_count, B_count, C_count)
plt.bar(index, values,width=0.25)
plt.xlabel('类型',size='14')
plt.ylabel('次数',size='14')
plt.title('日期类型次数对比',size='18')
plt.legend(labels=['日期类型乘车次数'])
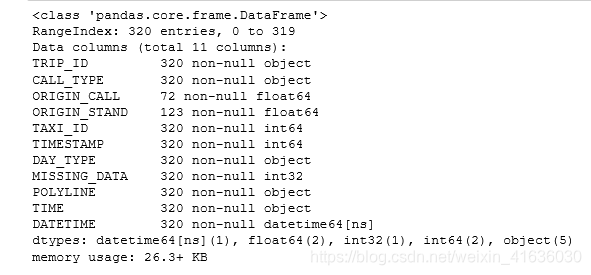
df['TIME']=df['TIMESTAMP'].astype(int).apply(lambda x:pd.datetime.fromtimestamp(x).date())
df.head()
df['DATETIME']=pd.to_datetime(df['TIMESTAMP'],unit='s') #这里是将timestamp转换成以miao
df.head()
df.info()
df['MONTH']=df['TIMESTAMP'].apply(lambda x: pd.datetime.fromtimestamp(x).month)
#df.head()
#df.rename(columns={'TIME':'DATE'},inplace=True)
#df.head()
#df=df.drop('Month',1)
df.head()
month=list(set(df['MONTH']))
def month_count(month):
month_num=[]
for i in month:
month_num.append(len(df[df['MONTH']==i]))
return month_num
month_count(month)
values=(month_count(month))
print(values)
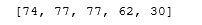
plt.figure(figsize=(6,8))
#画出不同类型的图
index=(month)
values=(month_count(month))
plt.bar(index, values,width=0.25)
plt.xlabel('月份',size='14')
plt.ylabel('次数',size='14')
plt.title('每个月份搭乘次数',size='18')
plt.legend(labels=['月份乘车次数'])
df.head()
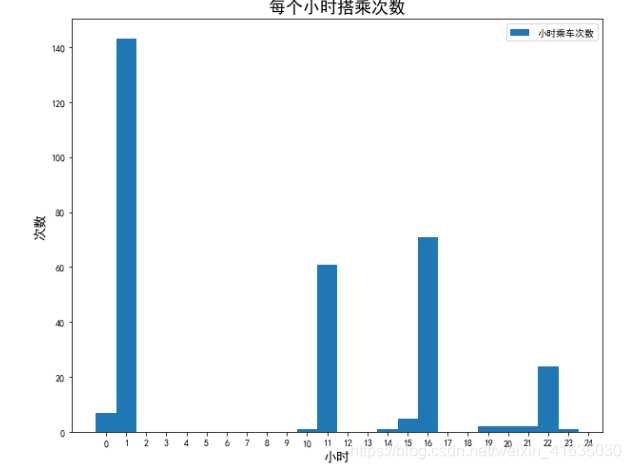
df['HOUR']=df['TIMESTAMP'].apply(lambda x: pd.datetime.fromtimestamp(x).hour)
df.head()
hour=list(set(df['HOUR']))
def hour_count(hour):
hour_num=[]
for i in hour:
hour_num.append(len(df[df['HOUR']==i]))
return hour_num
print(hour_count(hour))

plt.figure(figsize=(10,8))
#画出不同类型的图
index=(hour)
values=(hour_count(hour))
plt.bar(index, values,width=1)
plt.xlabel('小时',size='14')
plt.ylabel('次数',size='14')
plt.title('每个小时搭乘次数',size='18')
plt.legend(labels=['小时乘车次数'])
plt.xticks(range(0,25))
df.head()
#df.info()
#统计每行轨迹的数据个数
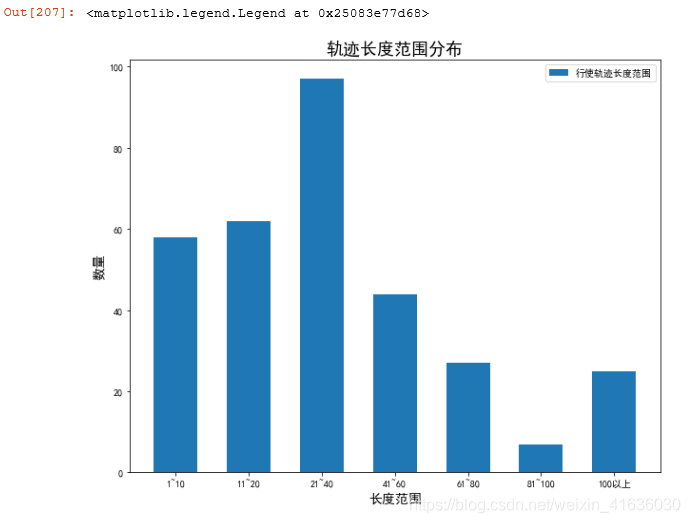
df['POLYLINE_COUNT']=df['POLYLINE'].apply(lambda x: len(eval(x)))
def POLYLINE_COUNT(df):
a,b,c,d,e,f,g=[0,0,0,0,0,0,0]
for i in df['POLYLINE_COUNT']:
if i >=0 and i <= 10: #由于大部分数据行使轨迹都是在0-20之间,所以这里我们单独将0-20拆分两段
a=a+1
elif i>10 and i<=20:
b=b+1
elif i>20 and i<=40:
c=c+1
elif i>40 and i<=60:
d=d+1
elif i>60 and i<=80:
e=e+1
elif i>80 and i<=100:
f=f+1
else:
g=g+1
return (a,b,c,d,e,f,g)
print(POLYLINE_COUNT(df))

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)