


首先,安装好pycharm和anaconda(这里使用anaconda2为例)。接着,下载对应版本的hadoop和spark平台并进行配置。
在这里,我们将hadoop解压到:D:\hadoop-2.7.2test
然后将spark解压到:D:\spark-2.0.0-hadoop2.7
1、在win下的配置与linux下不同,主要在于配置cmd脚本。想省心的同学可以直接下载我配置好的版本,链接见文末。
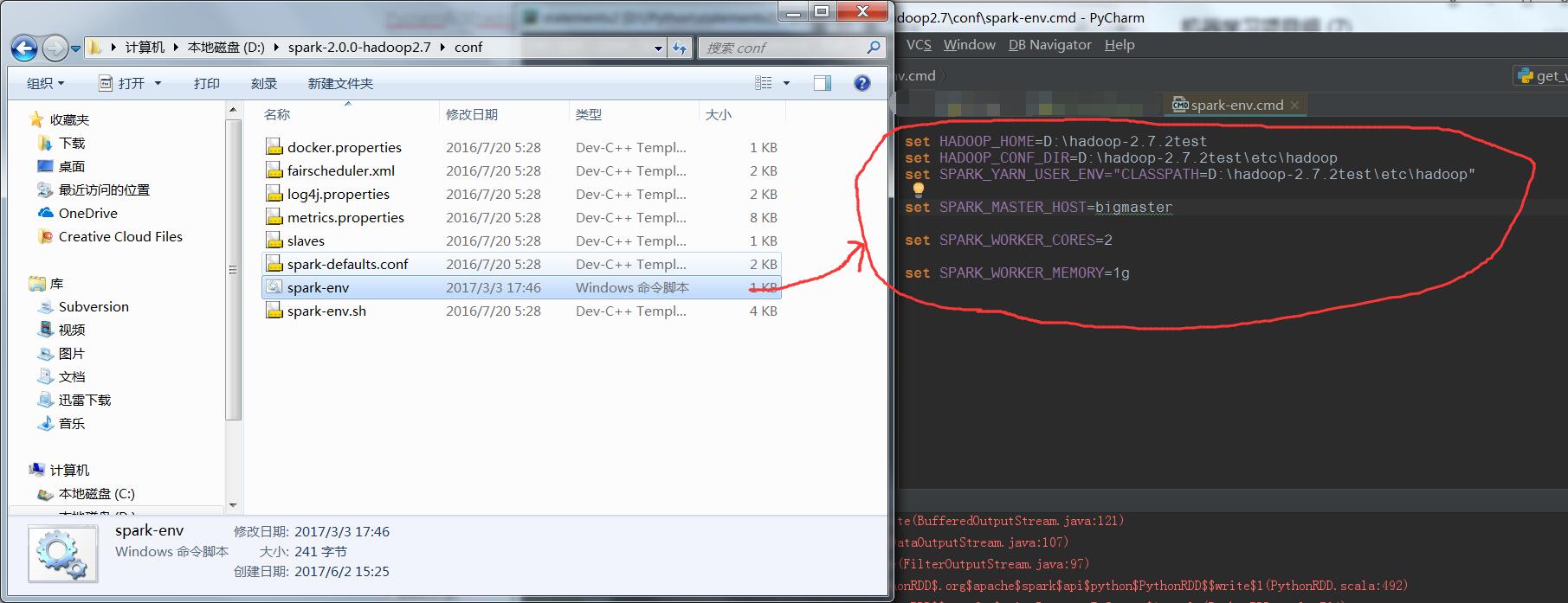
在spark的conf那新增spark-env.cmd文件并编辑如下:
set HADOOP_HOME=D:\hadoop-2.7.2test
set HADOOP_CONF_DIR=D:\hadoop-2.7.2test\etc\hadoop
set SPARK_YARN_USER_ENV="CLASSPATH=D:\hadoop-2.7.2test\etc\hadoop"
set SPARK_MASTER_HOST=bigmaster
set SPARK_WORKER_CORES=2
set SPARK_WORKER_MEMORY=1g
2、打开pycharm,我们配置python运行的环境变量:
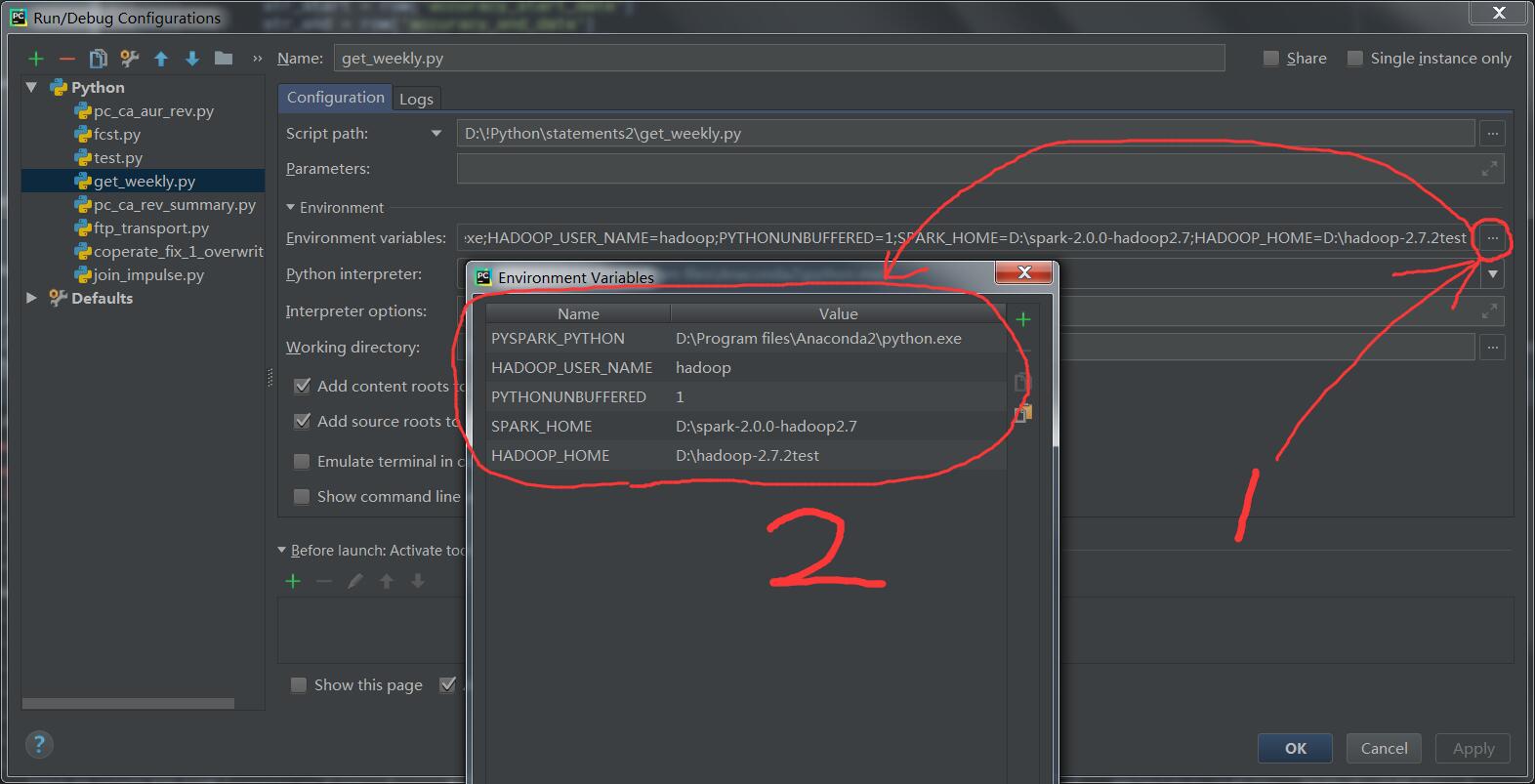
PYSPARK_PYTHON=D:\Program files\Anaconda2\python.exe;
HADOOP_USER_NAME=hadoop;
PYTHONUNBUFFERED=1;
SPARK_HOME=D:\spark-2.0.0-hadoop2.7;
HADOOP_HOME=D:\hadoop-2.7.2test
3、注意hadoop\bin文件夹里面要有winutil.exe。官网下载是不带的,这里文末的链接是我配置好的,已经带winutil.exe。这个exe的作用是模拟一个linux文件系统环境,使得hadoop能够使用linux文件结构思维来操作windows下的目录。
4、在D盘根目录建立一个临时文件夹tmp,用于存放spark和hadoop在运行中产生的缓存文件。
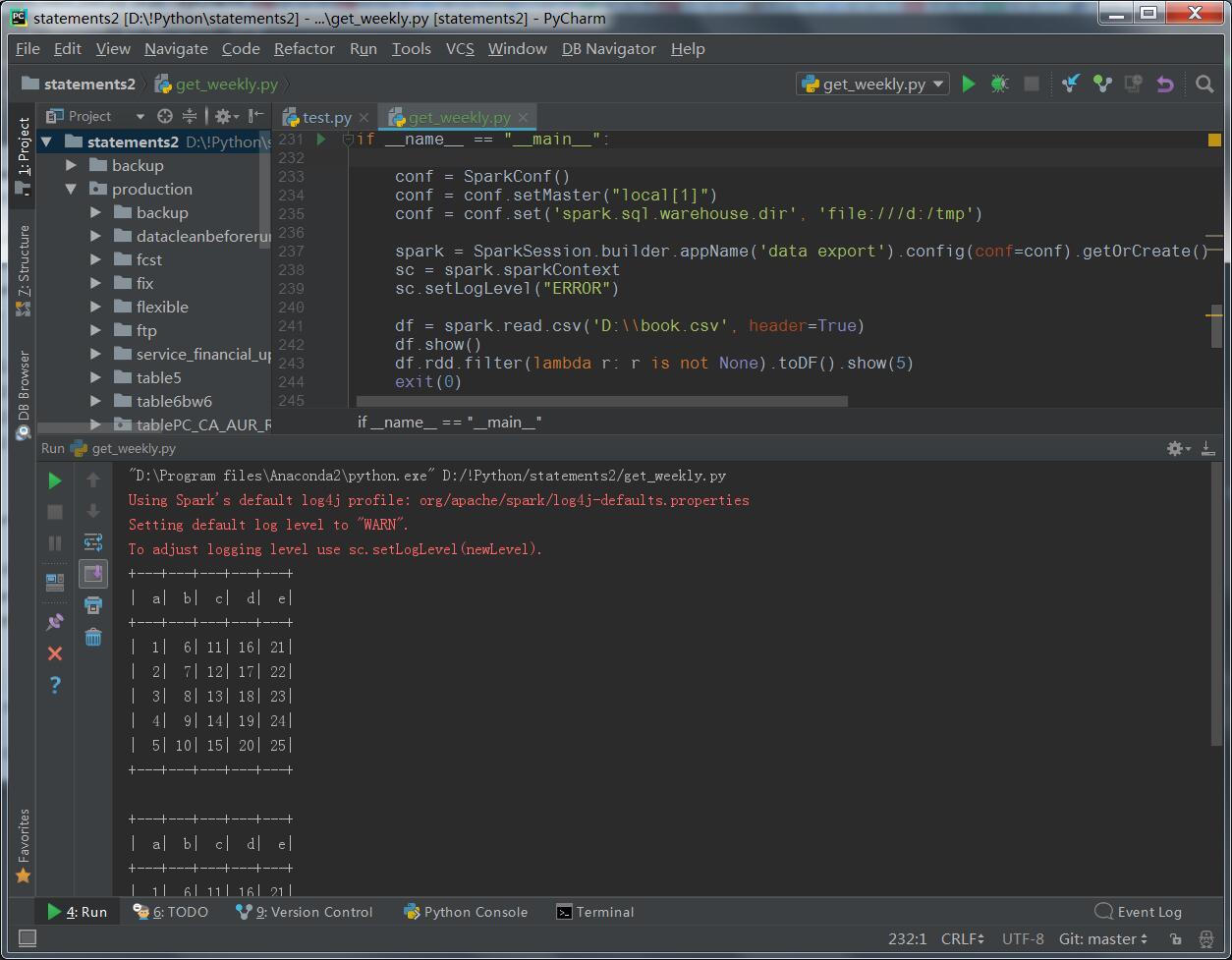
5、实际程序如下,我们可以看到在win下本地运行的时候,需要配置临时文件夹:
if __name__ == "__main__":
conf = SparkConf()
conf = conf.setMaster("local[1]")
conf = conf.set('spark.sql.warehouse.dir', 'file:///d:/tmp')
spark = SparkSession.builder.appName('data export').config(conf=conf).getOrCreate()
sc = spark.sparkContext
sc.setLogLevel("ERROR")
df = spark.read.csv('D:\\book.csv', header=True)
df.show()
df.rdd.filter(lambda r: r is not None).toDF().show(5)
exit(0)示例中读取的book.csv文件内容如下:
a,b,c,d,e
1,6,11,16,21
2,7,12,17,22
3,8,13,18,23
4,9,14,19,24
5,10,15,20,256、最终运行结果
winutil.exe下载
https://pan.baidu.com/s/17GIct-5LAiztjoCo_FvXdA
配置好的hadoop和spark下载(请放在D盘根目录下)
https://pan.baidu.com/s/1Jx3w88DQ0WWPyrZy-7UpvA




 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)