数据挖掘pandas技巧(一):groupby
·
数据挖掘pandas技巧(一):groupby
介绍
python跟其他语言不相同的地方就是有着千千万万个函数,你不可能全部学得完。所以,在日常生活中,要多去学习和回顾一下python中的新函数,新操作,这样不会让你的代码质量停滞不前。本文主要介绍groupby函数的使用。这几个函数作用类似,都是对数据集中的一类属性进行聚合,分组运算操作。
groupby
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'column1':list('abbaa'),
'column2':['yes','no', 'no', 'yes','yes'],
'num1': np.random.randn(5),
'num2': np.random.randn(5)}
)
print(df)
看看我们输出的数据表:
不要问我为什么是四行四列,因为这样看起来比较好看。下面我们来对他进行实际操作。
分组操作
grouped = df['num1'].groupby(df['column1'])
grouped.mean()
这句话的意思就是我们将[‘num1’]这一列的数据依照[‘column1’]列的分类分隔开来。
我们看看结果就知道了: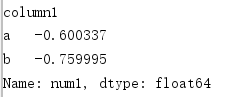
我们发现[‘num1’]里面的数据被分成了a和b两个类别,然后进行了均值计算.
实际上的分组建可以是任意长度的适当数组。
grouped = df['num1'].groupby([df['column1'],df['column2']])
grouped.mean()
我们看看结果:
因为这里的数据集a只有yes,b只有no属性,所以在分组的时候a和b都只占有了一行。
对分组进行迭代
for name, group in df.groupby('column1'):
print(name)
print(group)
输出如下:
这里name就是column1列的名字,group就是要输出的内容。
同样的,两个变量进行分组的时候就是:
for (name1, name2), group in df.groupby(['column1','column2']):
print(name1, name2)
print(group)

nam1,name2是两个列的列名,group仍是输出的内容。
分组生成字典
dict1 = dict(list(df.groupby('column1')))
print(dict1)
输出如下:
如图,它是以字典的形式输出,所以可以对它进行字典操作。
使用axis=1在横轴分块
grouped = df.groupby(df.dtypes, axis = 1)
dict(list(grouped))
输出如图:
进行聚合
df.groupby(['column1','column2'])[['num1']].mean()
如图所示:
通过字典或者series进行分组
people=pd.DataFrame(np.random.randn(5,5),
columns=list('abcde'),
index=['Joe','Steve','Wes','Jim','Travis'])
people.loc[2:3,['b','c']]= np.nan #设置几个nan
输出: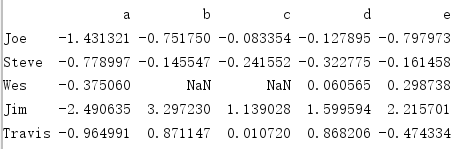
已知列的分组关系:
mapping={'a':'1','b':'2','c':'3','d':'1','e':'2','f':'3'}
by_column=people.groupby(mapping,axis=1)
by_column.sum()
输出如下: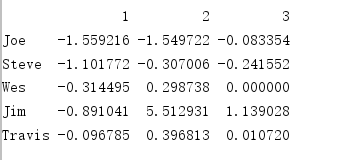
通过函数进行分组
相较于dic或者Series,python函数在定义分组关系映射时更有创意。任何被当做分组键的函数都会在各个索引上被调用一次,其返回值就会被用作分组名称。假设你按长度进行分组,仅仅传入len即可
people.groupby(len).sum()


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)