YOLOv8改进 - 注意力机制 | SENetV2: 用于通道和全局表示的聚合稠密层,结合SE模块和密集层来增强特征表示
本文介绍了将SENetV2与YOLOv8结合的方法,以提升图像分类性能。SENetV2是结合Squeeze-and-Excitation(SE)模块和密集层的图像分类模型,引入聚合稠密层用于通道和全局表示。其SE模块重新校准通道特征,密集层优化特征表示,还提出SaE模块增强关键特征捕获。我们将SENetV2的SaELayer集成进YOLOv8,在相关位置嵌入该模块。实验表明,结合SENetV2的Y
前言
本文介绍了将SENetV2与YOLOv8结合的方法,以提升图像分类性能。SENetV2是结合Squeeze-and-Excitation(SE)模块和密集层的图像分类模型,引入聚合稠密层用于通道和全局表示。其SE模块重新校准通道特征,密集层优化特征表示,还提出SaE模块增强关键特征捕获。我们将SENetV2的SaELayer集成进YOLOv8,在相关位置嵌入该模块。实验表明,结合SENetV2的YOLOv8在图像分类准确性上有显著提升。
文章目录: YOLOv8改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv8改进专栏
介绍

摘要
卷积神经网络(CNNs)通过提取空间特征彻底改变了图像分类,并在基于视觉的任务中实现了最先进的准确性。提出的Squeeze-and-Excitation网络模块收集输入的通道表示。多层感知器(MLP)从数据中学习全局表示,并在大多数图像分类模型中用于学习图像的提取特征。本文中,我们引入了一种新型的聚合多层感知器,一个多分支密集层,嵌入到Squeeze-and-Excitation残差模块中,旨在超越现有架构的性能。我们的方法结合了Squeeze-and-Excitation网络模块和密集层。这种融合增强了网络捕捉通道模式和全局知识的能力,从而提高了特征表示。与SENet相比,所提出的模型参数增加可以忽略不计。我们在基准数据集上进行了广泛的实验,以验证模型并与已建立的架构进行比较。实验结果表明,所提出模型在分类准确性上有显著提高。
文章链接
论文地址:论文地址
代码地址:代码地址
参考代码:代码地址
基本原理
SENetV2是一种图像分类模型,其核心特征是引入了聚合稠密层(Aggregated Dense Layer)用于通道和全局表示,是一种结合了Squeeze-and-Excitation(SE)模块和密集层的图像分类模型。该模型旨在通过增强特征表示来提高图像分类性能。SENet V2的核心思想是通过对通道特征和全局特征进行重新校准和激活,从而使网络更加专注于关键特征,提高分类准确性。
SENet V2的关键特点包括:
- Squeeze-and-Excitation(SE)模块:SE模块通过对通道特征进行重新校准,使网络能够更好地捕获关键特征。在SE模块中,通过全局信息来动态调整通道特征的重要性,从而提高网络的表达能力。
- 密集层:SENet V2引入了密集层,用于进一步优化特征表示。密集层有助于增强通道特征的全局表示能力,从而提高网络的分类性能。
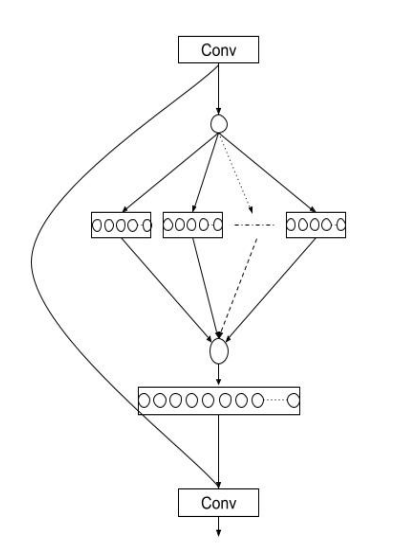
- Squeeze Aggregated Excitation(SaE)模块:SENet V2还提出了SaE模块,将聚合的密集层与SE模块相结合,进一步优化特征表示。SaE模块通过增加层间的基数来优化关键特征的传输,提高网络的性能。
- 实验结果:SENet V2在多个数据集上进行了实验评估,包括CIFAR-10、CIFAR-100和ImageNet。实验结果表明,SENet V2相较于传统架构在图像分类任务中取得了更高的准确性。
SENetV2的结构如下
SaE模块
核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.model_zoo import load_url
# 定义 SE 模块
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
# 全局平均池化层
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 全连接层,包含两层线性变换和激活函数
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size() # 获取输入的维度
y = self.avg_pool(x).view(b, c) # 全局平均池化并改变维度
y = self.fc(y).view(b, c, 1, 1) # 通过全连接层并改变维度
return x * y.expand_as(x) # 按通道加权输入
# 定义 SaE 模块
class SaELayer(nn.Module):
def __init__(self, in_channel, reduction=32):
super(SaELayer, self).__init__()
# 检查输入通道数是否满足条件
assert in_channel >= reduction and in_channel % reduction == 0, 'invalid in_channel in SaElayer'
self.reduction = reduction
self.cardinality = 4
# 全局平均池化层
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# cardinality 1
self.fc1 = nn.Sequential(
nn.Linear(in_channel, in_channel // self.reduction, bias=False),
nn.ReLU(inplace=True)
)
# cardinality 2
self.fc2 = nn.Sequential(
nn.Linear(in_channel, in_channel // self.reduction, bias=False),
nn.ReLU(inplace=True)
)
# cardinality 3
self.fc3 = nn.Sequential(
nn.Linear(in_channel, in_channel // self.reduction, bias=False),
nn.ReLU(inplace=True)
)
# cardinality 4
self.fc4 = nn.Sequential(
nn.Linear(in_channel, in_channel // self.reduction, bias=False),
nn.ReLU(inplace=True)
)
# 最终的全连接层
self.fc = nn.Sequential(
nn.Linear(in_channel // self.reduction * self.cardinality, in_channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size() # 获取输入的维度
y = self.avg_pool(x).view(b, c) # 全局平均池化并改变维度
# 分别通过4个全连接层
y1 = self.fc1(y)
y2 = self.fc2(y)
y3 = self.fc3(y)
y4 = self.fc4(y)
# 将4个输出拼接在一起
y_concate = torch.cat([y1, y2, y3, y4], dim=1)
# 最终通过全连接层并改变维度
y_ex_dim = self.fc(y_concate).view(b, c, 1, 1)
return x * y_ex_dim.expand_as(x) # 按通道加权输入
# 示例代码,用于测试 SaELayer 模块
se_v2 = SaELayer(64)
# 示例输入
input = torch.randn(3, 64, 224, 224)
# 前向传播,获取输出
output = se_v2(input)
# 打印输出的形状
print(output.shape) # torch.Size([3, 64, 224, 224])
引入代码
在根目录下的ultralytics/nn/目录,新建一个 attention目录,然后新建一个以 SENetV2为文件名的py文件, 把代码拷贝进去。
import torch
import torch.nn as nn
import torch.nn.functional as F
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid(),
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
class SaELayer(nn.Module):
def __init__(self, in_channel, reduction=32):
super(SaELayer, self).__init__()
assert (
in_channel >= reduction and in_channel % reduction == 0
), "invalid in_channel in SaElayer"
self.reduction = reduction
self.cardinality = 4
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# cardinality 1
self.fc1 = nn.Sequential(
nn.Linear(in_channel, in_channel // self.reduction, bias=False),
nn.ReLU(inplace=True),
)
# cardinality 2
self.fc2 = nn.Sequential(
nn.Linear(in_channel, in_channel // self.reduction, bias=False),
nn.ReLU(inplace=True),
)
# cardinality 3
self.fc3 = nn.Sequential(
nn.Linear(in_channel, in_channel // self.reduction, bias=False),
nn.ReLU(inplace=True),
)
# cardinality 4
self.fc4 = nn.Sequential(
nn.Linear(in_channel, in_channel // self.reduction, bias=False),
nn.ReLU(inplace=True),
)
self.fc = nn.Sequential(
nn.Linear(
in_channel // self.reduction * self.cardinality, in_channel, bias=False
),
nn.Sigmoid(),
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y1 = self.fc1(y)
y2 = self.fc2(y)
y3 = self.fc3(y)
y4 = self.fc4(y)
y_concate = torch.cat([y1, y2, y3, y4], dim=1)
y_ex_dim = self.fc(y_concate).view(b, c, 1, 1)
return x * y_ex_dim.expand_as(x)
注册
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.attention.SENetV2 import SaELayer
步骤2
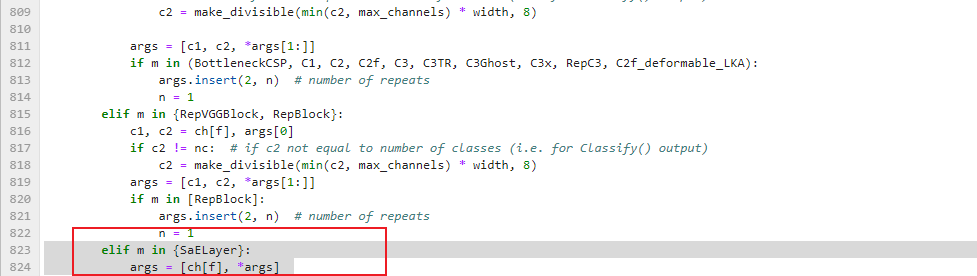
修改def parse_model(d, ch, verbose=True):
elif m in {SaELayer}:
args = [ch[f], *args]
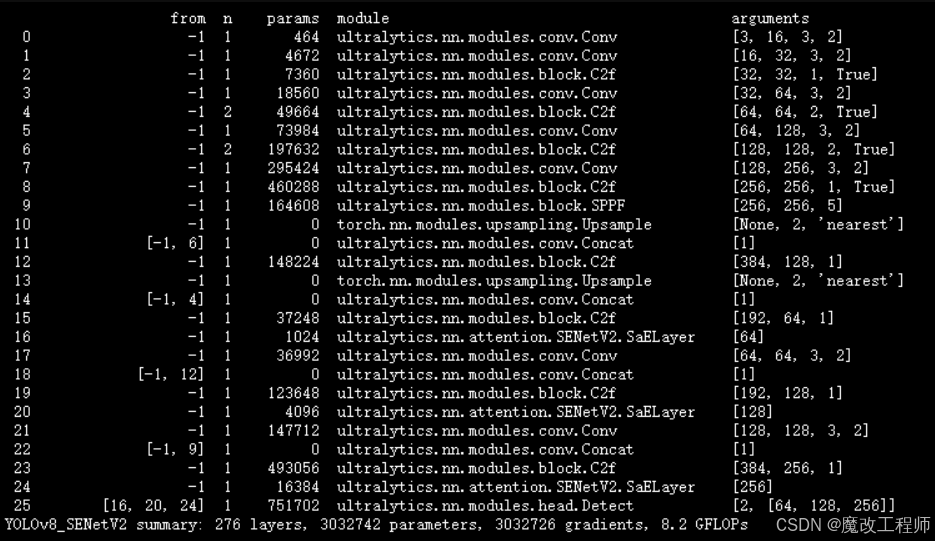
配置yolov8_SENetV2.yaml
ultralytics/ultralytics/cfg/models/v8/yolov8_SENetV2.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, SaELayer, []] # 16
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, SaELayer, []] # 20
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 23 (P5/32-large)
- [-1, 1, SaELayer, []] # 24
- [[16, 20, 24], 1, Detect, [nc]] # Detect(P3, P4, P5)
实验
脚本
import os
from ultralytics import YOLO
# Define the configuration options directly
yaml = 'ultralytics/cfg/models/v8/yolov8_SENetV2.yaml'
# Initialize the YOLO model with the specified YAML file
model = YOLO(yaml)
# Print model information
model.info()
if __name__ == "__main__":
# Train the model with the specified parameters
results = model.train(data='ultralytics/datasets/original-license-plates.yaml',
name='SENetV2',
epochs=10,
workers=8,
batch=1)
结果

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)