【完整源码+数据集+部署教程】台灯材质识别图像分割系统源码&数据集分享 [yolov8-seg-convnextv2&yolov8-seg-EfficientFormerV2等50+全套改进创新点发
背景意义
随着智能家居和物联网技术的迅速发展,家居产品的智能化、个性化需求日益增加。台灯作为家居环境中不可或缺的照明设备,其材质的多样性和设计的独特性使得消费者在选择时面临诸多挑战。传统的台灯材质识别主要依赖人工经验,不仅效率低下,而且容易受到主观因素的影响。因此,开发一种高效、准确的台灯材质识别系统显得尤为重要。
在计算机视觉领域,图像分割技术的进步为物体识别提供了新的思路。YOLO(You Only Look Once)系列模型以其快速的实时检测能力和高准确率,成为目标检测领域的佼佼者。YOLOv8作为该系列的最新版本,结合了深度学习的先进技术,能够在复杂环境中实现高效的图像处理。然而,现有的YOLOv8模型在特定领域的应用上仍存在一定的局限性,尤其是在细粒度的材质识别任务中。因此,基于改进YOLOv8的台灯材质识别图像分割系统的研究具有重要的理论和实际意义。
本研究所使用的数据集包含1300张图像,涵盖17种不同的台灯材质类别,包括陶瓷、织物、玻璃、大理石、金属、塑料和木材等。这些材质的多样性为模型的训练提供了丰富的样本,有助于提高识别的准确性和鲁棒性。通过对这些图像进行实例分割,系统不仅能够识别出台灯的种类,还能准确区分不同材质的细微差别,从而为消费者提供更为精准的产品信息。
在实际应用中,基于改进YOLOv8的台灯材质识别系统能够广泛应用于电商平台、智能家居助手、室内设计软件等领域。通过自动识别和分类台灯材质,系统可以为用户提供个性化的推荐,提升购物体验。此外,该系统还可以帮助商家优化库存管理,减少因材质识别错误而导致的退换货率,从而提高运营效率。
综上所述,基于改进YOLOv8的台灯材质识别图像分割系统的研究,不仅具有重要的学术价值,还具备广泛的应用前景。通过提升台灯材质识别的准确性和效率,能够有效满足市场对智能家居产品的需求,推动家居行业的智能化进程。未来,随着深度学习技术的不断发展,该系统还可以扩展到更多家居产品的材质识别任务,为消费者提供更为全面的服务。
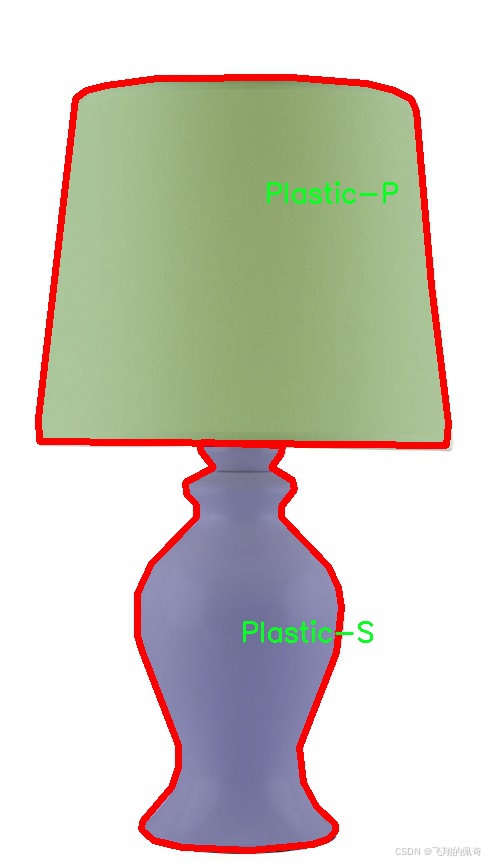
图片效果
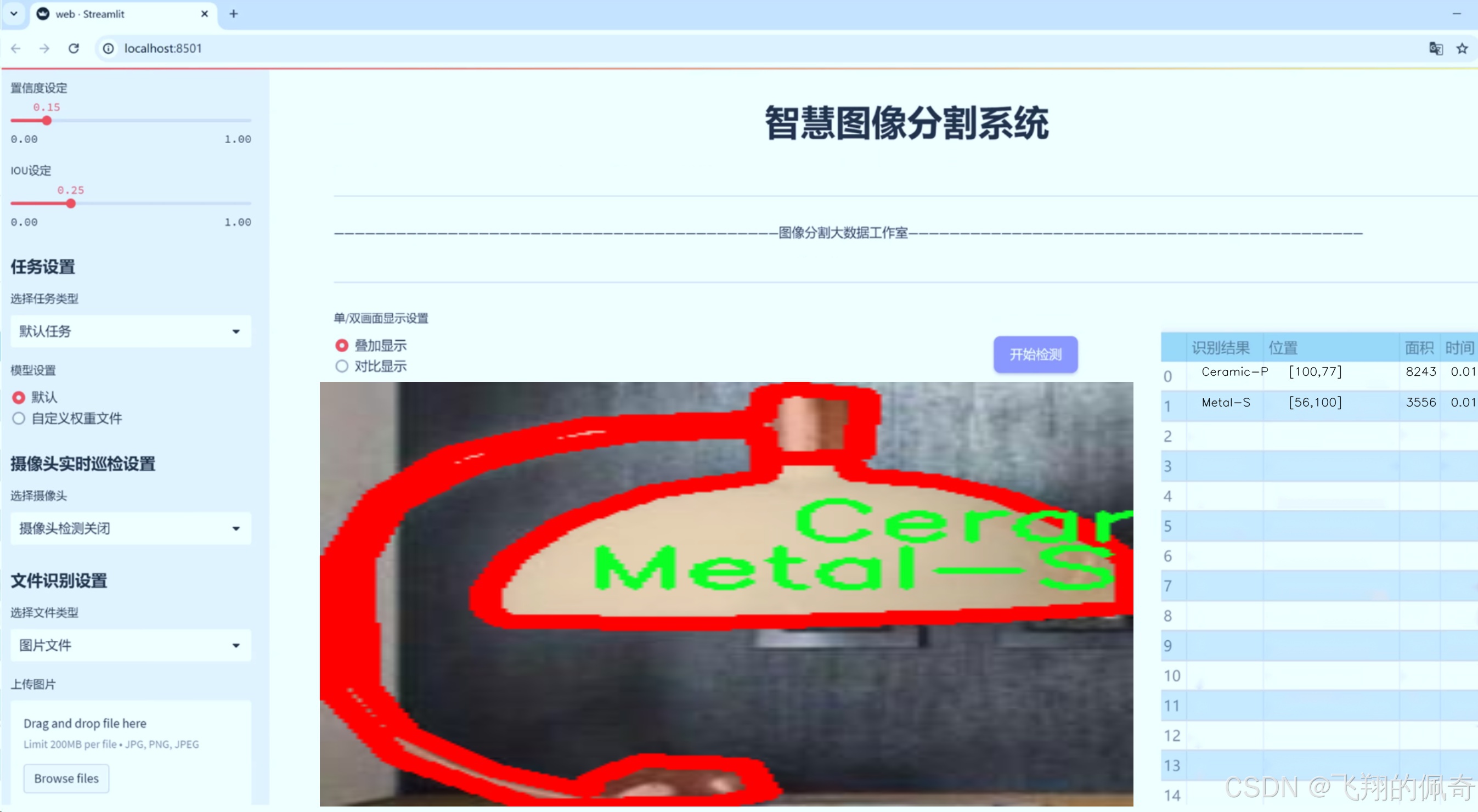
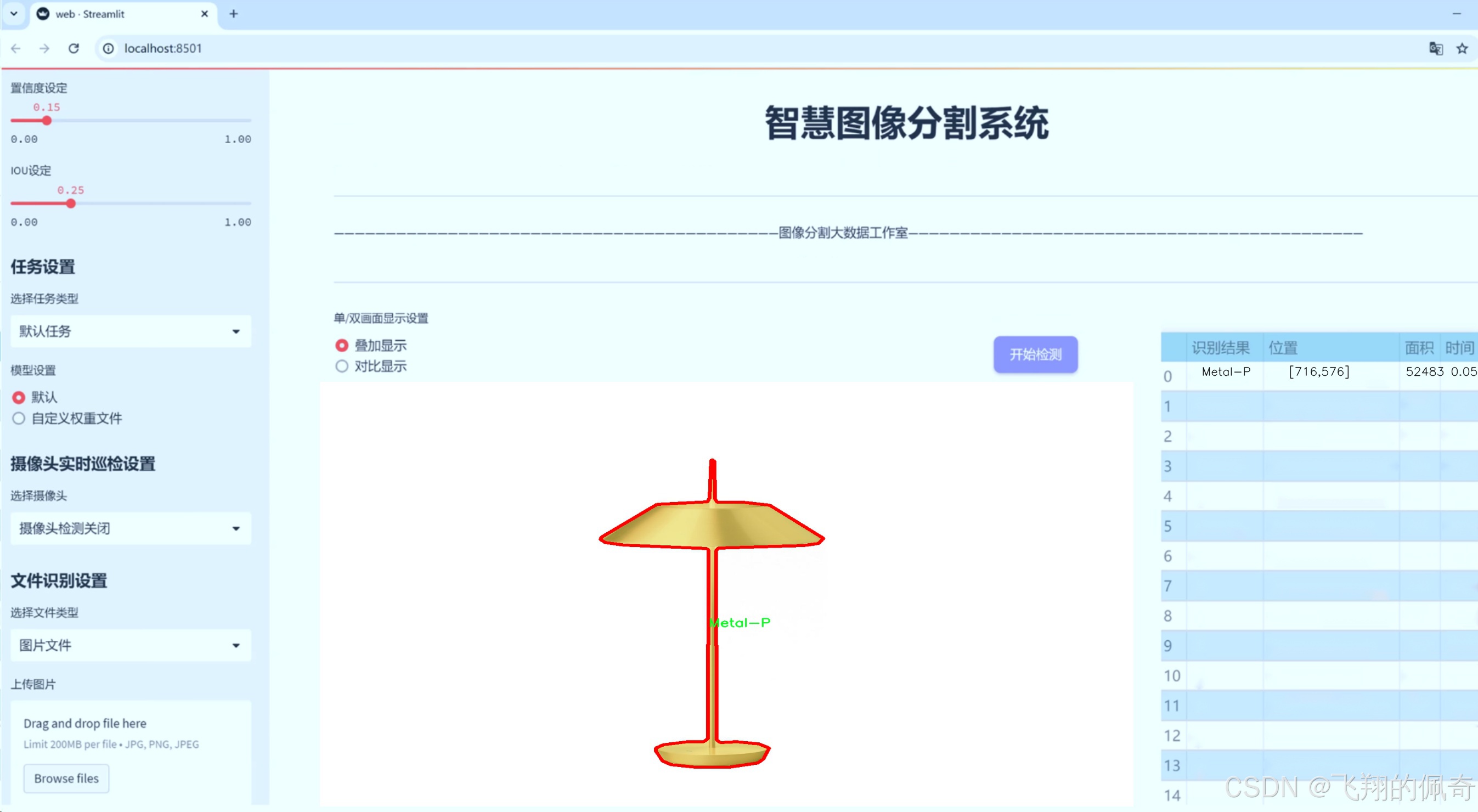
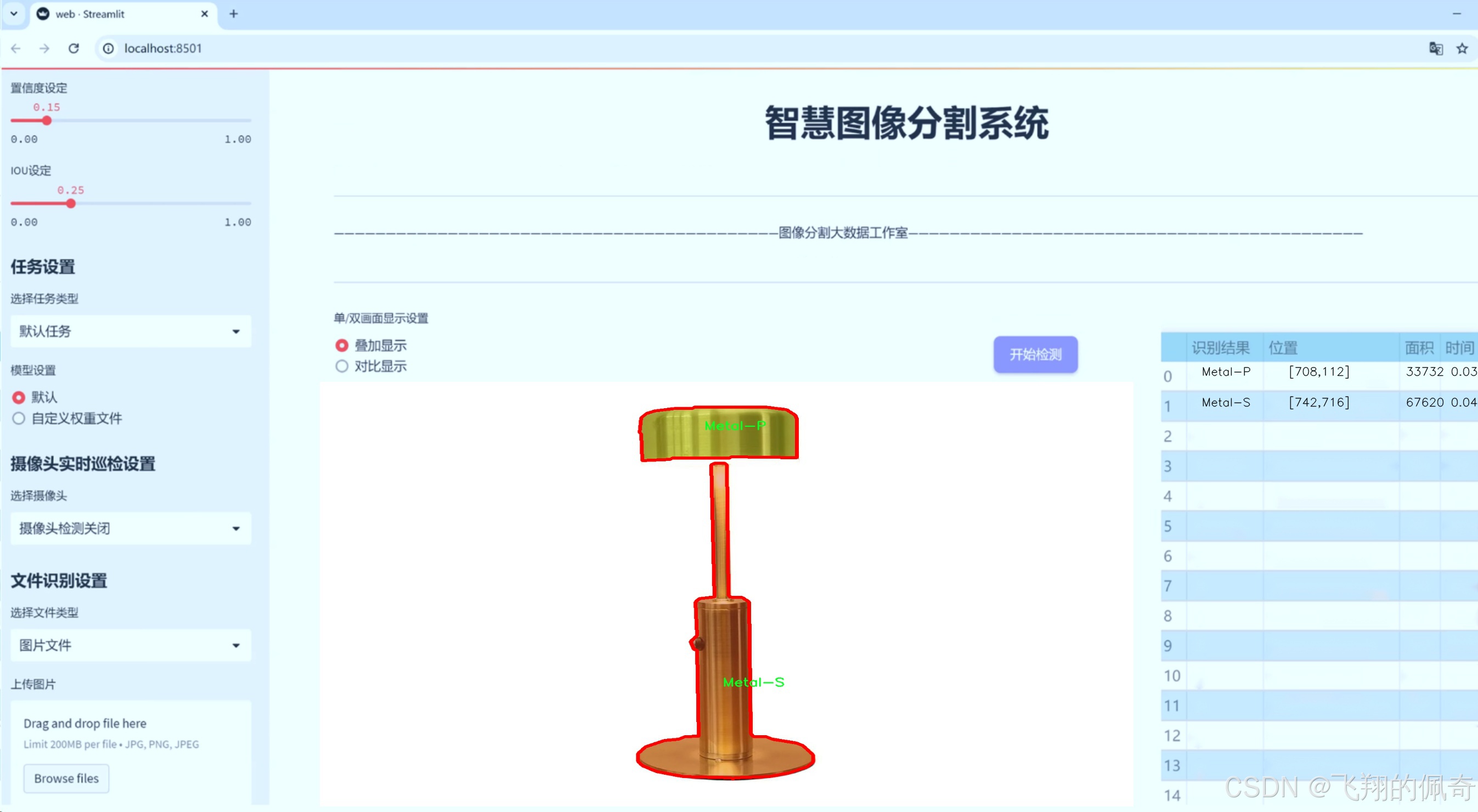
数据集信息
在本研究中,我们使用了名为“DeskTableLamps Material”的数据集,以训练和改进YOLOv8-seg模型,旨在实现高效的台灯材质识别图像分割系统。该数据集专注于多种台灯材质的分类与识别,包含了17个不同的类别,涵盖了从传统材料到现代合成材料的广泛范围。这些类别的多样性不仅为模型提供了丰富的训练样本,也为后续的图像分割任务奠定了坚实的基础。
具体而言,数据集中包含的类别包括:陶瓷(Ceramic-P、Ceramic-S、Ceramic-T)、织物(Fabric-P)、玻璃(Glass-P、Glass-S)、大理石(Marble-S、Marble-T)、金属(Metal-P、Metal-S、Metal-T)、塑料(Plastic-P、Plastic-S、Plastic-T)以及木材(Wood-P、Wood-S、Wood-T)。每一类材料都经过精心挑选,确保其在实际应用中的代表性和多样性。陶瓷类材料的细腻质感、织物类材料的柔和触感、玻璃类材料的透明度、大理石的纹理、金属的光泽、塑料的轻便性以及木材的自然纹理等,都为模型的训练提供了丰富的视觉特征。
在数据集的构建过程中,研究团队不仅注重材料的多样性,还考虑到了不同光照条件、拍摄角度和背景环境对图像分割效果的影响。这一系列的设计使得“DeskTableLamps Material”数据集具备了良好的泛化能力,能够有效应对现实世界中复杂的场景和条件。通过使用这一数据集,YOLOv8-seg模型能够学习到各类材料的独特特征,从而在图像分割任务中实现更高的准确性和鲁棒性。
此外,数据集中的每个类别都附带了详细的标注信息,确保模型在训练过程中能够获得准确的监督信号。这些标注不仅包括材料的类别标签,还涵盖了物体的边界框信息,进一步增强了模型的学习效果。通过对这些信息的充分利用,YOLOv8-seg模型能够在分割任务中精确地识别出不同材质的台灯,并有效区分它们之间的细微差别。
综上所述,“DeskTableLamps Material”数据集为本研究提供了一个全面而丰富的训练基础,使得改进后的YOLOv8-seg模型在台灯材质识别图像分割任务中具备了更强的能力。通过对该数据集的深入分析与应用,我们期望能够推动图像分割技术在家居物品识别领域的进一步发展,为智能家居系统的实现提供更为可靠的技术支持。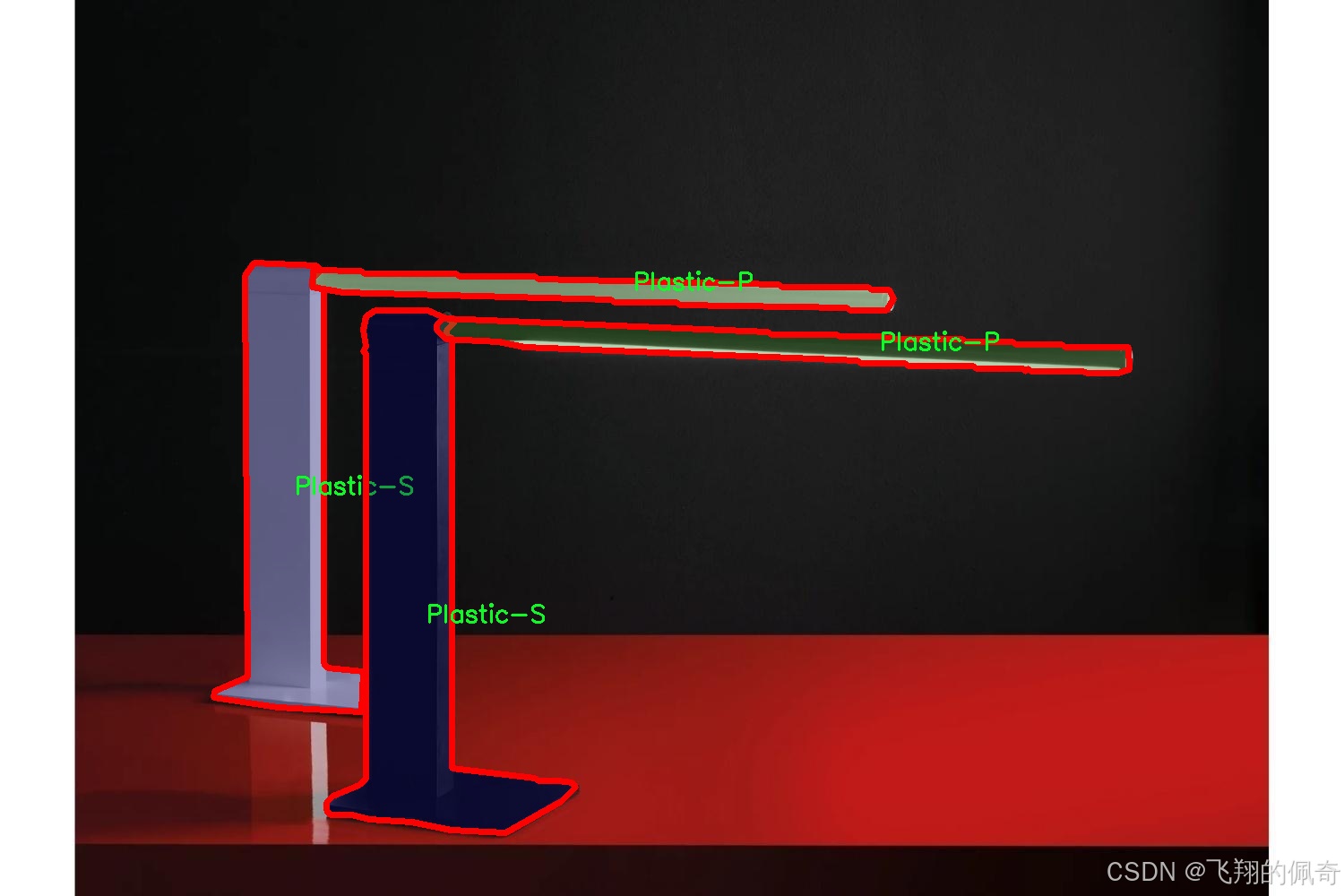



核心代码
```python
import sys # 导入sys模块,用于访问与Python解释器紧密相关的变量和函数
import subprocess # 导入subprocess模块,用于执行外部命令
def run_script(script_path):
"""
使用当前 Python 环境运行指定的脚本。
Args:
script_path (str): 要运行的脚本路径
Returns:
None
"""
# 获取当前 Python 解释器的路径
python_path = sys.executable
# 构建运行命令,使用streamlit模块运行指定的脚本
command = f'"{python_path}" -m streamlit run "{script_path}"'
# 执行命令
result = subprocess.run(command, shell=True) # 使用shell执行命令
if result.returncode != 0: # 检查命令执行是否成功
print("脚本运行出错。") # 如果返回码不为0,表示出错,打印错误信息
# 实例化并运行应用
if __name__ == "__main__":
# 指定要运行的脚本路径
script_path = "web.py" # 这里可以直接指定脚本名,假设在当前目录下
# 运行脚本
run_script(script_path) # 调用run_script函数执行指定的脚本
代码核心部分分析:
-
导入模块:
sys模块用于获取当前Python解释器的路径。subprocess模块用于执行外部命令。
-
run_script函数:- 接收一个脚本路径作为参数,并构建命令以运行该脚本。
- 使用
subprocess.run方法执行命令,并检查返回码以确定命令是否成功执行。
-
主程序入口:
- 使用
if __name__ == "__main__":确保只有在直接运行该脚本时才会执行后续代码。 - 指定要运行的脚本路径,并调用
run_script函数来执行该脚本。
- 使用
代码的功能:
该代码的主要功能是通过当前Python环境来运行一个指定的Streamlit脚本,并在运行过程中检查是否有错误发生。```
这个程序文件名为 ui.py,它的主要功能是通过当前的 Python 环境来运行一个指定的脚本。程序首先导入了必要的模块,包括 sys、os 和 subprocess,以及一个自定义的路径处理模块 abs_path。
在文件中定义了一个名为 run_script 的函数,该函数接受一个参数 script_path,这个参数是要运行的脚本的路径。函数内部首先获取当前 Python 解释器的路径,使用 sys.executable 来实现。接着,构建一个命令字符串,使用 streamlit 来运行指定的脚本。命令的格式是将 Python 解释器路径和脚本路径组合成一个完整的命令。
随后,使用 subprocess.run 方法来执行这个命令,shell=True 参数表示在 shell 中执行该命令。执行完后,程序会检查返回的状态码,如果返回码不为 0,说明脚本运行过程中出现了错误,此时会打印出“脚本运行出错”的提示信息。
在文件的最后部分,使用 if __name__ == "__main__": 来判断当前模块是否是主程序,如果是,则指定要运行的脚本路径,这里是通过 abs_path 函数获取的 web.py 的绝对路径。最后,调用 run_script 函数来执行这个脚本。
总体来看,这个程序的设计是为了方便用户在当前的 Python 环境中运行一个名为 web.py 的脚本,利用 streamlit 框架来启动一个 Web 应用。
```python
# -*- coding: utf-8 -*-
import cv2 # 导入OpenCV库,用于处理图像和视频
import torch # 导入PyTorch库,用于深度学习模型的操作
from ultralytics import YOLO # 从ultralytics库中导入YOLO类,用于加载YOLO模型
from ultralytics.utils.torch_utils import select_device # 导入选择设备的工具函数
# 根据是否有可用的GPU选择设备
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# 初始化参数字典
ini_params = {
'device': device, # 设备类型,使用选择的设备
'conf': 0.3, # 物体置信度阈值,低于此值的检测结果将被忽略
'iou': 0.05, # 用于非极大值抑制的IOU阈值
'classes': None, # 类别过滤器,None表示不过滤任何类别
'verbose': False # 是否输出详细信息
}
class Web_Detector: # 定义Web_Detector类
def __init__(self, params=None): # 构造函数
self.model = None # 初始化模型为None
self.img = None # 初始化图像为None
self.params = params if params else ini_params # 使用提供的参数或默认参数
def load_model(self, model_path): # 加载模型的方法
self.device = select_device(self.params['device']) # 选择设备
self.model = YOLO(model_path) # 加载YOLO模型
# 预热模型,输入一个零张量以初始化模型
self.model(torch.zeros(1, 3, 640, 640).to(self.device).type_as(next(self.model.model.parameters())))
def preprocess(self, img): # 图像预处理方法
self.img = img # 保存原始图像
return img # 返回处理后的图像
def predict(self, img): # 预测方法
results = self.model(img, **ini_params) # 使用模型进行预测
return results # 返回预测结果
def postprocess(self, pred): # 后处理方法
results = [] # 初始化结果列表
for res in pred[0].boxes: # 遍历预测结果中的每个边界框
class_id = int(res.cls.cpu()) # 获取类别ID
bbox = res.xyxy.cpu().squeeze().tolist() # 获取边界框坐标
bbox = [int(coord) for coord in bbox] # 转换边界框坐标为整数
result = {
"class_name": self.names[class_id], # 类别名称
"bbox": bbox, # 边界框
"score": res.conf.cpu().squeeze().item(), # 置信度
"class_id": class_id # 类别ID
}
results.append(result) # 将结果添加到列表
return results # 返回结果列表
代码核心部分说明:
- 设备选择:根据是否有可用的GPU选择设备,使用
torch.cuda.is_available()判断。 - 参数初始化:设置YOLO模型的参数,包括设备类型、置信度阈值等。
- 模型加载:使用
YOLO类加载模型,并进行预热以初始化模型参数。 - 图像预处理:保存输入图像以便后续使用。
- 预测:调用YOLO模型进行物体检测,返回预测结果。
- 后处理:解析预测结果,提取类别名称、边界框、置信度等信息,并将其整理成字典形式,最终返回结果列表。```
这个程序文件model.py是一个用于图像检测的模块,主要基于YOLO(You Only Look Once)模型实现物体检测。文件中导入了多个库,包括OpenCV用于图像处理,PyTorch用于深度学习,QtFusion中的Detector和HeatmapGenerator类,以及Ultralytics库中的YOLO模型。
首先,程序设置了设备类型,如果系统支持CUDA,则使用GPU(“cuda:0”),否则使用CPU(“cpu”)。接着,定义了一些初始化参数,包括物体置信度阈值、IOU阈值和类别过滤器等。
接下来,定义了一个名为 count_classes 的函数,该函数用于统计检测结果中每个类别的数量。它接收检测信息和类别名称列表作为参数,返回一个包含每个类别计数的列表。
然后,定义了一个名为 Web_Detector 的类,该类继承自 Detector。在构造函数中,初始化了一些属性,包括模型、图像和类别名称。构造函数中还允许用户传入参数,如果没有提供,则使用默认参数。
Web_Detector 类中包含多个方法。load_model 方法用于加载YOLO模型,并根据模型路径判断任务类型(分割或检测)。它还将类别名称转换为中文,并进行模型预热,以确保模型能够正常工作。
preprocess 方法用于图像的预处理,简单地保存原始图像并返回。predict 方法接收处理后的图像并进行预测,返回检测结果。
postprocess 方法对预测结果进行后处理,提取每个检测框的信息,包括类别名称、边界框坐标、置信度和类别ID。结果以字典的形式存储在列表中并返回。
最后,set_param 方法允许更新检测器的参数,以便根据需要调整检测行为。
整体来看,这个程序文件提供了一个结构化的方式来实现基于YOLO的物体检测,支持中文类别名称的转换,并具备灵活的参数设置和结果处理功能。
```以下是经过简化并注释的核心代码部分,主要保留了 Attention 类和 KWConvNd 类的实现。这些类是实现注意力机制和卷积操作的关键部分。
import torch
import torch.nn as nn
import torch.nn.functional as F
class Attention(nn.Module):
def __init__(self, in_planes, reduction, num_static_cell, num_local_mixture, norm_layer=nn.BatchNorm1d,
cell_num_ratio=1.0, nonlocal_basis_ratio=1.0, start_cell_idx=None):
super(Attention, self).__init__()
# 计算隐藏层的通道数
hidden_planes = max(int(in_planes * reduction), 16)
self.kw_planes_per_mixture = num_static_cell + 1 # 每个混合的关键点通道数
self.num_local_mixture = num_local_mixture # 本地混合数
self.kw_planes = self.kw_planes_per_mixture * num_local_mixture # 总的关键点通道数
# 计算本地和非本地单元的数量
self.num_local_cell = int(cell_num_ratio * num_local_mixture)
self.num_nonlocal_cell = num_static_cell - self.num_local_cell
self.start_cell_idx = start_cell_idx
# 定义网络层
self.avgpool = nn.AdaptiveAvgPool1d(1) # 自适应平均池化
self.fc1 = nn.Linear(in_planes, hidden_planes, bias=(norm_layer is not nn.BatchNorm1d)) # 全连接层
self.norm1 = norm_layer(hidden_planes) # 归一化层
self.act1 = nn.ReLU(inplace=True) # 激活函数
# 定义映射到单元的层
if nonlocal_basis_ratio >= 1.0:
self.map_to_cell = nn.Identity() # 直接映射
self.fc2 = nn.Linear(hidden_planes, self.kw_planes, bias=True) # 映射层
else:
self.map_to_cell = self.map_to_cell_basis # 使用基础映射
self.num_basis = max(int(self.num_nonlocal_cell * nonlocal_basis_ratio), 16) # 基础数量
self.fc2 = nn.Linear(hidden_planes, (self.num_local_cell + self.num_basis + 1) * num_local_mixture, bias=False)
self.fc3 = nn.Linear(self.num_basis, self.num_nonlocal_cell, bias=False) # 非本地映射层
self.basis_bias = nn.Parameter(torch.zeros([self.kw_planes], requires_grad=True).float()) # 基础偏置
self.temp_bias = torch.zeros([self.kw_planes], requires_grad=False).float() # 温度偏置
self.temp_value = 0 # 温度值
self._initialize_weights() # 初始化权重
def _initialize_weights(self):
# 权重初始化
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') # Kaiming初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 偏置初始化为0
if isinstance(m, nn.BatchNorm1d):
nn.init.constant_(m.weight, 1) # 归一化权重初始化为1
nn.init.constant_(m.bias, 0) # 偏置初始化为0
def forward(self, x):
# 前向传播
x = self.avgpool(x.reshape(*x.shape[:2], -1)).squeeze(dim=-1) # 平均池化
x = self.act1(self.norm1(self.fc1(x))) # 线性变换 -> 归一化 -> 激活
x = self.map_to_cell(self.fc2(x)).reshape(-1, self.kw_planes) # 映射到单元
x = x / (torch.sum(torch.abs(x), dim=1).view(-1, 1) + 1e-3) # 归一化
x = (1.0 - self.temp_value) * x + self.temp_value * self.temp_bias.to(x.device).view(1, -1) # 温度调整
return x.reshape(-1, self.kw_planes_per_mixture)[:, :-1] # 返回结果
class KWconvNd(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1,
bias=False, warehouse_id=None, warehouse_manager=None):
super(KWconvNd, self).__init__()
self.in_planes = in_planes # 输入通道数
self.out_planes = out_planes # 输出通道数
self.kernel_size = kernel_size # 卷积核大小
self.stride = stride # 步幅
self.padding = padding # 填充
self.dilation = dilation # 膨胀
self.groups = groups # 分组卷积
self.bias = nn.Parameter(torch.zeros([self.out_planes]), requires_grad=True).float() if bias else None # 偏置
self.warehouse_id = warehouse_id # 仓库ID
self.warehouse_manager = [warehouse_manager] # 仓库管理器
def forward(self, x):
# 前向传播
# 获取注意力权重
kw_attention = self.attention(x).type(x.dtype)
batch_size = x.shape[0] # 批大小
x = x.reshape(1, -1, *x.shape[2:]) # 重塑输入
weight = self.warehouse_manager[0].take_cell(self.warehouse_id).reshape(self.cell_shape[0], -1).type(x.dtype) # 获取权重
aggregate_weight = torch.mm(kw_attention, weight) # 权重聚合
# 进行卷积操作
output = self.func_conv(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
output = output.view(batch_size, self.out_planes, *output.shape[2:]) # 重塑输出
if self.bias is not None:
output = output + self.bias.reshape(1, -1, *([1]*self.dimension)) # 添加偏置
return output # 返回输出
代码说明:
- Attention 类:实现了一个注意力机制的模块,主要通过全连接层和归一化层来计算输入特征的注意力权重,并根据温度调整这些权重。
- KWconvNd 类:实现了一个通用的卷积层,能够使用注意力机制来动态调整卷积权重,并支持多种卷积参数配置。该类的
forward方法中结合了注意力权重和卷积操作,最终输出卷积结果。
这段代码是深度学习模型中实现注意力机制和卷积操作的核心部分,能够在特征提取中发挥重要作用。```
这个程序文件 kernel_warehouse.py 是一个用于深度学习中卷积操作的模块,主要实现了一个“内核仓库”管理器,允许在不同的卷积层之间共享和重用卷积核,从而减少模型的参数数量和计算复杂度。文件中定义了多个类和函数,以下是对其主要内容的讲解。
首先,文件导入了一些必要的库,包括 PyTorch 的核心模块和一些功能模块。然后定义了一个工具函数 parse,用于处理输入参数,确保它们的格式符合预期。
接下来,定义了 Attention 类,这是一个注意力机制模块。它的构造函数接收多个参数,包括输入通道数、缩减比例、静态单元数量、局部混合数量等。该类通过自适应平均池化、全连接层和归一化层来计算注意力权重,并在前向传播中生成基于输入的权重。这些权重用于动态调整卷积核的使用,从而提高模型的表达能力。
KWconvNd 类是一个通用的卷积层实现,支持不同维度的卷积(1D、2D、3D)。它的构造函数接收卷积的输入输出通道、核大小、步幅、填充等参数,并在前向传播中使用注意力机制生成的权重来执行卷积操作。具体的卷积操作由 func_conv 属性指定,支持不同维度的卷积函数。
KWConv1d、KWConv2d 和 KWConv3d 类分别继承自 KWconvNd,实现了一维、二维和三维卷积的具体细节。它们定义了特定的维度和卷积函数。
KWLinear 类实现了线性层的功能,内部使用了一维卷积来处理输入数据。
Warehouse_Manager 类是内核仓库的管理器,负责管理不同卷积层的卷积核。它的构造函数接收多个参数,包括缩减比例、单元数量比例、共享范围等。该类提供了 reserve 方法,用于创建动态卷积层并记录其信息,store 方法用于存储卷积核,allocate 方法用于分配卷积核给网络中的卷积层。
最后,KWConv 类是一个简单的卷积模块,结合了卷积层、批归一化和激活函数,提供了一个完整的卷积操作接口。
此外,文件还定义了一个 get_temperature 函数,用于计算温度值,这在训练过程中可能用于调节模型的行为。
整体而言,这个文件实现了一个灵活的卷积核管理机制,通过注意力机制和动态卷积核的方式,提升了深度学习模型的效率和性能。
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
class TransformerEncoderLayer(nn.Module):
"""定义一个Transformer编码器层。"""
def __init__(self, c1, cm=2048, num_heads=8, dropout=0.0, act=nn.GELU(), normalize_before=False):
"""初始化TransformerEncoderLayer,设置参数。
参数:
c1: 输入特征的维度。
cm: 前馈网络中间层的维度。
num_heads: 多头注意力机制中的头数。
dropout: dropout比率。
act: 激活函数,默认为GELU。
normalize_before: 是否在前向传播前进行归一化。
"""
super().__init__()
self.ma = nn.MultiheadAttention(c1, num_heads, dropout=dropout, batch_first=True) # 多头注意力层
self.fc1 = nn.Linear(c1, cm) # 前馈网络的第一层
self.fc2 = nn.Linear(cm, c1) # 前馈网络的第二层
self.norm1 = nn.LayerNorm(c1) # 第一层归一化
self.norm2 = nn.LayerNorm(c1) # 第二层归一化
self.dropout = nn.Dropout(dropout) # dropout层
self.dropout1 = nn.Dropout(dropout) # 第一个dropout层
self.dropout2 = nn.Dropout(dropout) # 第二个dropout层
self.act = act # 激活函数
self.normalize_before = normalize_before # 是否在前向传播前进行归一化
def forward(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""通过编码器模块进行前向传播。
参数:
src: 输入特征。
src_mask: 注意力掩码。
src_key_padding_mask: 键的填充掩码。
pos: 位置编码。
返回:
经过编码器层处理后的特征。
"""
if self.normalize_before:
src2 = self.norm1(src) # 如果需要在前向传播前归一化
q = k = self.with_pos_embed(src2, pos) # 计算查询和键
src2 = self.ma(q, k, value=src2, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2) # 残差连接
src2 = self.norm2(src) # 第二次归一化
src2 = self.fc2(self.dropout(self.act(self.fc1(src2)))) # 前馈网络
return src + self.dropout2(src2) # 返回结果
else:
q = k = self.with_pos_embed(src, pos) # 计算查询和键
src2 = self.ma(q, k, value=src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2) # 残差连接
src = self.norm1(src) # 归一化
src2 = self.fc2(self.dropout(self.act(self.fc1(src)))) # 前馈网络
return self.norm2(src + self.dropout2(src2)) # 返回结果
@staticmethod
def with_pos_embed(tensor, pos=None):
"""如果提供了位置编码,则将其添加到输入张量中。
参数:
tensor: 输入张量。
pos: 位置编码。
返回:
添加了位置编码的张量。
"""
return tensor if pos is None else tensor + pos
class MLPBlock(nn.Module):
"""实现一个多层感知机(MLP)块。"""
def __init__(self, embedding_dim, mlp_dim, act=nn.GELU):
"""初始化MLPBlock,设置嵌入维度、MLP维度和激活函数。
参数:
embedding_dim: 输入嵌入的维度。
mlp_dim: MLP的隐藏层维度。
act: 激活函数,默认为GELU。
"""
super().__init__()
self.lin1 = nn.Linear(embedding_dim, mlp_dim) # 第一层线性变换
self.lin2 = nn.Linear(mlp_dim, embedding_dim) # 第二层线性变换
self.act = act() # 激活函数实例化
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""进行MLP块的前向传播。
参数:
x: 输入张量。
返回:
经过MLP块处理后的张量。
"""
return self.lin2(self.act(self.lin1(x))) # 线性变换 -> 激活 -> 线性变换
class DeformableTransformerDecoderLayer(nn.Module):
"""可变形Transformer解码器层。"""
def __init__(self, d_model=256, n_heads=8, d_ffn=1024, dropout=0., act=nn.ReLU(), n_levels=4, n_points=4):
"""初始化DeformableTransformerDecoderLayer,设置参数。
参数:
d_model: 输入特征的维度。
n_heads: 多头注意力机制中的头数。
d_ffn: 前馈网络的维度。
dropout: dropout比率。
act: 激活函数,默认为ReLU。
n_levels: 特征层的数量。
n_points: 每个层的采样点数量。
"""
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, n_heads, dropout=dropout) # 自注意力层
self.cross_attn = MSDeformAttn(d_model, n_levels, n_heads, n_points) # 跨注意力层
self.linear1 = nn.Linear(d_model, d_ffn) # 前馈网络的第一层
self.linear2 = nn.Linear(d_ffn, d_model) # 前馈网络的第二层
self.act = act # 激活函数
self.dropout1 = nn.Dropout(dropout) # dropout层
self.dropout2 = nn.Dropout(dropout) # dropout层
self.norm1 = nn.LayerNorm(d_model) # 归一化层
self.norm2 = nn.LayerNorm(d_model) # 归一化层
self.norm3 = nn.LayerNorm(d_model) # 归一化层
def forward(self, embed, refer_bbox, feats, shapes, padding_mask=None, attn_mask=None, query_pos=None):
"""进行解码器层的前向传播。
参数:
embed: 解码器的嵌入。
refer_bbox: 参考边界框。
feats: 图像特征。
shapes: 特征形状。
padding_mask: 填充掩码。
attn_mask: 注意力掩码。
query_pos: 查询位置编码。
返回:
经过解码器层处理后的特征。
"""
# 自注意力
q = k = self.with_pos_embed(embed, query_pos) # 计算查询和键
tgt = self.self_attn(q.transpose(0, 1), k.transpose(0, 1), embed.transpose(0, 1), attn_mask=attn_mask)[0].transpose(0, 1)
embed = embed + self.dropout1(tgt) # 残差连接
embed = self.norm1(embed) # 归一化
# 跨注意力
tgt = self.cross_attn(self.with_pos_embed(embed, query_pos), refer_bbox.unsqueeze(2), feats, shapes, padding_mask)
embed = embed + self.dropout2(tgt) # 残差连接
embed = self.norm2(embed) # 归一化
# 前馈网络
tgt2 = self.linear2(self.dropout3(self.act(self.linear1(embed)))) # 前馈网络
return self.norm3(embed + tgt2) # 返回结果
@staticmethod
def with_pos_embed(tensor, pos):
"""将位置编码添加到输入张量中(如果提供)。
参数:
tensor: 输入张量。
pos: 位置编码。
返回:
添加了位置编码的张量。
"""
return tensor if pos is None else tensor + pos
代码核心部分说明:
- TransformerEncoderLayer:实现了Transformer编码器的基本结构,包括多头自注意力机制和前馈网络。提供了前向传播的两种方式(前归一化和后归一化)。
- MLPBlock:实现了一个简单的多层感知机(MLP),包含两个线性层和一个激活函数。
- DeformableTransformerDecoderLayer:实现了可变形Transformer解码器层,结合了自注意力和跨注意力机制,并通过前馈网络进行特征转换。
这些模块是构建Transformer模型的基础,广泛应用于计算机视觉和自然语言处理等领域。```
这个程序文件定义了一系列与Transformer相关的模块,主要用于构建和实现Transformer模型,特别是在计算机视觉任务中的应用。文件中包含多个类,每个类都实现了特定的功能。
首先,TransformerEncoderLayer类定义了Transformer编码器的单层结构。它包含多头自注意力机制、前馈神经网络以及层归一化。构造函数中初始化了多头注意力层、前馈网络、归一化层和丢弃层。forward方法根据是否需要预归一化来选择不同的前向传播方式。
接下来,AIFI类是TransformerEncoderLayer的一个扩展,增加了对2D位置嵌入的支持。它的forward方法首先构建2D正弦余弦位置嵌入,然后将输入展平并进行前向传播,最后将输出重新调整为原始形状。
TransformerLayer类实现了一个简单的Transformer层,包含自注意力机制和前馈网络。它的forward方法对输入应用多头注意力和前馈网络,并返回结果。
TransformerBlock类则是一个完整的Transformer模块,包含多个TransformerLayer。它支持输入通道数的变化,并在必要时使用卷积层进行调整。
MLPBlock和MLP类实现了多层感知机(MLP),前者是一个单独的MLP块,后者则是一个完整的MLP网络,支持多层结构。
LayerNorm2d类实现了2D层归一化,适用于图像数据。它通过计算均值和方差来对输入进行归一化,并应用可学习的权重和偏置。
MSDeformAttn类实现了多尺度可变形注意力机制,允许模型在不同尺度上进行注意力计算。它的forward方法处理查询、参考边界框和特征图,计算注意力权重并返回加权的输出。
DeformableTransformerDecoderLayer和DeformableTransformerDecoder类实现了可变形Transformer解码器。解码器层包含自注意力和交叉注意力机制,并通过前馈网络进行处理。解码器则由多个解码器层组成,负责生成最终的输出,包括边界框和分类分数。
整体而言,这个文件实现了一个灵活且强大的Transformer框架,适用于各种视觉任务,尤其是在目标检测和图像处理领域。每个模块都可以独立使用或组合使用,以满足不同的需求。
```python
import base64 # 导入 base64 模块,用于处理 Base64 编码
import streamlit as st # 导入 Streamlit 库,用于构建 web 应用
# 读取图片并转换为 Base64
def get_base64_of_bin_file(bin_file):
# 以二进制模式打开文件
with open(bin_file, 'rb') as file:
data = file.read() # 读取文件内容
# 将读取的二进制数据进行 Base64 编码,并返回字符串形式
return base64.b64encode(data).decode()
# 定义 CSS 样式
def def_css_hitml():
# 使用 Streamlit 的 markdown 功能插入自定义 CSS 样式
st.markdown("""
<style>
/* 全局样式 */
.css-2trqyj, .css-1d391kg, .st-bb, .st-at {
font-family: 'Gill Sans', 'Gill Sans MT', Calibri, 'Trebuchet MS', sans-serif; /* 设置字体 */
background-color: #cadefc; /* 设置背景颜色 */
color: #21618C; /* 设置字体颜色 */
}
/* 按钮样式 */
.stButton > button {
border: none; /* 去掉按钮边框 */
color: white; /* 设置按钮文字颜色 */
padding: 10px 20px; /* 设置按钮内边距 */
text-align: center; /* 设置文本居中 */
display: inline-block; /* 使按钮为块级元素 */
font-size: 16px; /* 设置字体大小 */
margin: 2px 1px; /* 设置按钮外边距 */
cursor: pointer; /* 鼠标悬停时显示为手型 */
border-radius: 8px; /* 设置按钮圆角 */
background-color: #9896f1; /* 设置按钮背景颜色 */
box-shadow: 0 2px 4px 0 rgba(0,0,0,0.2); /* 设置按钮阴影效果 */
transition-duration: 0.4s; /* 设置过渡效果时间 */
}
.stButton > button:hover {
background-color: #5499C7; /* 鼠标悬停时改变背景颜色 */
color: white; /* 鼠标悬停时保持文字颜色 */
box-shadow: 0 8px 12px 0 rgba(0,0,0,0.24); /* 鼠标悬停时改变阴影效果 */
}
/* 侧边栏样式 */
.css-1lcbmhc.e1fqkh3o0 {
background-color: #154360; /* 设置侧边栏背景颜色 */
color: #FDFEFE; /* 设置侧边栏文字颜色 */
border-right: 2px solid #DDD; /* 设置右边框 */
}
/* 表格样式 */
table {
border-collapse: collapse; /* 合并边框 */
margin: 25px 0; /* 设置表格外边距 */
font-size: 18px; /* 设置字体大小 */
font-family: sans-serif; /* 设置字体 */
min-width: 400px; /* 设置表格最小宽度 */
box-shadow: 0 5px 15px rgba(0, 0, 0, 0.2); /* 设置表格阴影效果 */
}
thead tr {
background-color: #a8d8ea; /* 设置表头背景颜色 */
color: #ffcef3; /* 设置表头文字颜色 */
text-align: left; /* 设置表头文本左对齐 */
}
th, td {
padding: 15px 18px; /* 设置单元格内边距 */
}
tbody tr {
border-bottom: 2px solid #ddd; /* 设置行底部边框 */
}
tbody tr:nth-of-type(even) {
background-color: #D6EAF8; /* 设置偶数行背景颜色 */
}
tbody tr:last-of-type {
border-bottom: 3px solid #5499C7; /* 设置最后一行底部边框 */
}
tbody tr:hover {
background-color: #AED6F1; /* 鼠标悬停时改变行背景颜色 */
}
</style>
""", unsafe_allow_html=True) # 允许使用 HTML 和 CSS
代码说明:
- 导入模块:导入
base64用于处理文件的 Base64 编码,导入streamlit用于构建 Web 应用。 - get_base64_of_bin_file 函数:该函数接受一个二进制文件路径,读取文件内容并将其转换为 Base64 编码的字符串。
- def_css_hitml 函数:该函数定义了一系列 CSS 样式,用于美化 Streamlit 应用的界面,包括全局样式、按钮样式、侧边栏样式和表格样式。通过
st.markdown方法将 CSS 样式应用到应用中。```
这个程序文件ui_style.py是一个用于 Streamlit 应用的样式定义文件。它主要包含了自定义的 CSS 样式,用于美化应用的界面。以下是对代码的逐行解释。
首先,程序导入了 base64 和 streamlit 库。base64 用于处理二进制数据的编码,而 streamlit 是一个用于构建数据应用的库。
接下来,定义了一个函数 get_base64_of_bin_file(bin_file),该函数接受一个二进制文件的路径作为参数。它打开文件并读取其内容,然后将读取到的二进制数据编码为 Base64 格式,并返回这个编码后的字符串。这在需要将图像或其他二进制文件嵌入到 HTML 中时非常有用。
然后,定义了另一个函数 def_css_hitml(),该函数使用 st.markdown() 方法将一段 CSS 样式嵌入到 Streamlit 应用中。这里的 CSS 样式包括多个部分:
-
全局样式:设置了应用的字体、背景颜色和文字颜色,确保整体视觉风格统一。
-
按钮样式:定义了按钮的外观,包括边框、颜色、内边距、字体大小、边距、圆角、背景色和阴影效果。同时还设置了按钮在鼠标悬停时的样式变化,使其更加吸引用户。
-
侧边栏样式:为侧边栏设置了背景色、文字颜色和边框样式,增强了侧边栏的可读性和美观性。
-
Radio 按钮样式:自定义了单选按钮的外观,使其更具交互性和视觉吸引力。
-
滑块样式:为滑块的滑块部分和轨道部分设置了背景颜色,提升了用户体验。
-
表格样式:定义了表格的整体样式,包括边框合并、字体、阴影效果、表头和表格行的背景色等。特别是设置了交替行的背景色和鼠标悬停时的高亮效果,使得表格数据更加易于阅读。
最后,使用 unsafe_allow_html=True 参数,允许在 Streamlit 中渲染 HTML 和 CSS。这使得自定义样式能够正确应用于 Streamlit 应用的界面。
总体而言,这个文件通过自定义 CSS 样式来增强 Streamlit 应用的视觉效果和用户体验,使得应用看起来更加美观和专业。
```python
import os
import torch
import yaml
from ultralytics import YOLO # 导入YOLO模型库
if __name__ == '__main__': # 确保该模块被直接运行时才执行以下代码
# 设置训练参数
workers = 1 # 数据加载的工作进程数
batch = 8 # 每个批次的样本数量
device = "0" if torch.cuda.is_available() else "cpu" # 检查是否有可用的GPU
# 获取数据集配置文件的绝对路径
data_path = abs_path(f'datasets/data/data.yaml', path_type='current')
# 将路径格式转换为Unix风格
unix_style_path = data_path.replace(os.sep, '/')
# 获取数据集目录路径
directory_path = os.path.dirname(unix_style_path)
# 读取YAML配置文件
with open(data_path, 'r') as file:
data = yaml.load(file, Loader=yaml.FullLoader)
# 修改数据集路径
if 'train' in data and 'val' in data and 'test' in data:
data['train'] = directory_path + '/train' # 更新训练集路径
data['val'] = directory_path + '/val' # 更新验证集路径
data['test'] = directory_path + '/test' # 更新测试集路径
# 将修改后的数据写回YAML文件
with open(data_path, 'w') as file:
yaml.safe_dump(data, file, sort_keys=False)
# 加载YOLO模型配置和预训练权重
model = YOLO(r"C:\codeseg\codenew\50+种YOLOv8算法改进源码大全和调试加载训练教程(非必要)\改进YOLOv8模型配置文件\yolov8-seg-C2f-Faster.yaml").load("./weights/yolov8s-seg.pt")
# 开始训练模型
results = model.train(
data=data_path, # 指定训练数据的配置文件路径
device=device, # 指定训练设备
workers=workers, # 数据加载的工作进程数
imgsz=640, # 输入图像的大小
epochs=100, # 训练的轮数
batch=batch, # 每个批次的样本数量
)
代码注释说明:
- 导入库:导入必要的库,包括
os、torch、yaml和YOLO模型库。 - 主程序入口:使用
if __name__ == '__main__':确保代码块仅在直接运行时执行。 - 参数设置:设置数据加载的工作进程数、批次大小和设备(GPU或CPU)。
- 数据集路径:获取数据集配置文件的绝对路径,并转换为Unix风格的路径。
- 读取和修改YAML文件:读取YAML文件,更新训练、验证和测试集的路径,并将修改后的内容写回文件。
- 加载模型:加载YOLO模型的配置文件和预训练权重。
- 训练模型:调用
model.train()方法开始训练,传入数据路径、设备、工作进程数、图像大小、训练轮数和批次大小等参数。```
这个程序文件train.py主要用于训练YOLO(You Only Look Once)模型,具体是YOLOv8版本的模型。程序的主要流程包括设置训练参数、读取数据集配置、修改数据路径、加载模型以及开始训练。
首先,程序导入了必要的库,包括os、torch、yaml、ultralytics中的YOLO模型以及matplotlib。matplotlib的使用设置为’TkAgg’,这可能是为了在训练过程中可视化结果。
在__main__块中,程序首先定义了一些训练参数,如workers(工作进程数)、batch(每个批次的样本数)和device(设备选择,优先使用GPU)。接着,程序通过abs_path函数获取数据集配置文件的绝对路径,该文件是一个YAML格式的文件,包含了训练、验证和测试数据的路径。
程序将获取到的路径转换为Unix风格的路径,并提取出目录路径。然后,它打开YAML文件并读取内容,使用yaml.load函数保持原有顺序。接下来,程序检查YAML文件中是否包含’train’、'val’和’test’的项,如果有,则将这些项的路径修改为相对于当前目录的路径,并将修改后的内容写回到YAML文件中。
在模型加载部分,程序使用YOLO类加载一个特定的模型配置文件(yolov8-seg-C2f-Faster.yaml)和预训练权重(yolov8s-seg.pt)。这一步是为了准备训练所需的模型。
最后,程序调用model.train方法开始训练,传入训练数据的配置文件路径、设备、工作进程数、输入图像大小、训练的epoch数以及批次大小等参数。训练过程中,模型会根据提供的数据进行学习和优化。
总的来说,这个程序文件是一个完整的YOLOv8模型训练脚本,涵盖了从数据准备到模型训练的各个步骤。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 23
23 0
0- 0



 已为社区贡献250条内容
已为社区贡献250条内容

所有评论(0)