Kafka高可用指南:解决消息丢失、乱序、积压
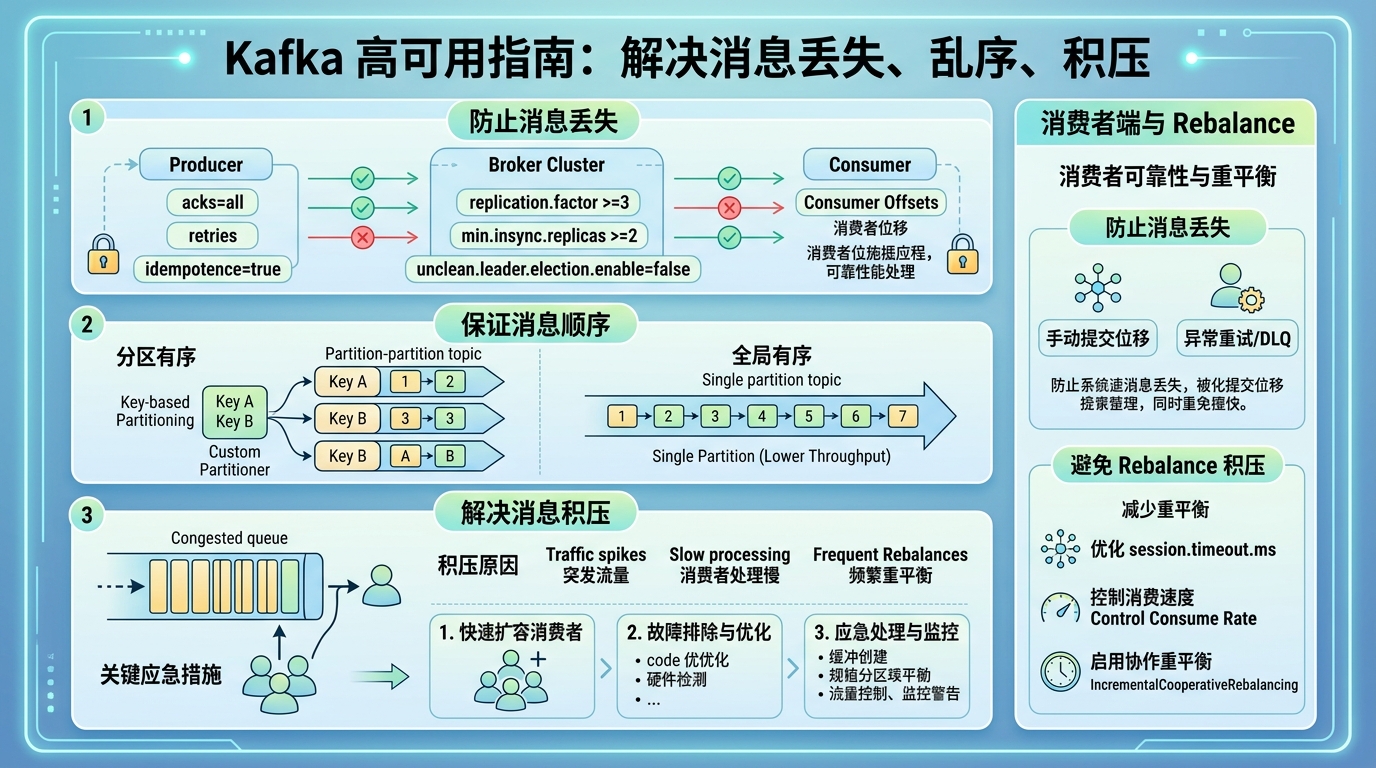
本文深入探讨了Kafka消息系统的三大核心问题及解决方案。针对消息丢失问题,提出生产者端(acks=all+幂等)、Broker端(多副本+最小同步副本)和消费者端(手动提交+幂等)的三道防线。对于消息顺序性,强调利用分区机制和消息键保证局部有序。针对消息积压,给出扩容分区、优化消费逻辑和排查Rebalance的三步应急方案。通过可靠性、顺序性和积压处理的"三驾马车"协同保障,
Kafka高可用指南:解决消息丢失、乱序、积压
引言:从“送快递”到“消息系统”
想象一下,你运营着一家大型快递公司。客户下单后,快递包裹(消息)要经过揽收、分拣、运输、派送等多个环节。如果某个环节出了问题——包裹丢了(消息丢失)、送错了顺序(消息乱序),或者仓库爆仓了(消息积压),整个业务都会乱套。
Apache Kafka 作为业界最流行的消息中间件之一,本质就是一个高性能的“快递系统”。然而,很多开发者在接入 Kafka 后,仍然会遭遇消息丢失、乱序和积压三大难题。本文将深入 Kafka 的底层机制,从可靠性、顺序性、积压处理三个维度,为你梳理一套可落地的保障方案。
一、消息可靠性:三道防线,层层兜底
Kafka 的消息丢失可能发生在生产者(Producer)、Broker 集群、消费者(Consumer) 任一环节。业界公认的解决方案是“三端协同治理”,目标是让消息在被认定为“已提交”后不再丢失,并在异常场景下可重试或回放[reference:0]。
1.1 生产者端:确认机制 + 幂等性 + 重试
acks 参数是生产者端可靠性最核心的配置。它定义了生产者在收到多少个副本的确认后,才认为消息发送成功[reference:1]。
| acks 值 | 行为说明 | 可靠性等级 |
|---|---|---|
| 0 | 生产者不等任何确认,直接发下一条,性能最高 | 至多一次 (At Most Once) |
| 1 | Leader 副本写入即确认,不等待 Follower 同步 | 至少一次 (At Least Once) |
| all / -1 | Leader 等待 ISR 中所有副本写入后才确认 | 高可靠(推荐) |
acks=all 配合 min.insync.replicas ≥ 2,是生产环境防止 Broker 宕机丢消息的标配[reference:2]。
幂等性通过 enable.idempotence=true 开启,确保单分区内消息不重复。其底层基于 PID(Producer ID) + 序列号(Sequence Number) 实现:Broker 会检查序列号,若重复则直接丢弃[reference:3]。
异步回调与重试同样至关重要。必须使用带回调的发送方式,在失败时进行重试或落库补偿,并配置 retries > 0[reference:4]。
1.2 Broker 端:多副本 + 最小同步副本
Broker 端的配置是可靠性的“地基”。核心公式:replication.factor = min.insync.replicas + 1[reference:5]。
同时,必须设置 unclean.leader.election.enable = false,禁止“不同步”的副本成为 Leader,从根本上杜绝数据截断[reference:6]。
1.3 消费者端:手动提交 + 幂等处理
消费者端的核心原则是:“先处理消息,再提交 Offset”[reference:7]。
- 关闭自动提交 (
enable.auto.commit=false)。 - 手动同步提交 (
commitSync()):确保消息处理成功后才提交偏移量。 - 保证幂等性:业务系统必须保证消费逻辑是幂等的(例如使用数据库主键去重、Redis 记录已处理 ID 等)[reference:8]。
二、消息顺序性:分区内的天然有序
Kafka 保证的是分区(Partition)级别的有序,而非全局有序[reference:9]。
- 全局有序:将 Topic 设置为单分区,牺牲吞吐量换取全局顺序[reference:10]。
- 分区内有序:通过消息键(Key) 将相关消息路由到同一分区(
hash(key) % 分区数),即可保证该键下所有消息的顺序[reference:11]。 - 生产者乱序防范:设置
max.in.flight.requests.per.connection=1,防止重试导致消息顺序错乱[reference:12]。
三、消息积压:快速诊断与应急处理
3.1 根本原因排查
积压的源头无外乎“生产太快”或“消费太慢”。排查路径通常包括:
- 消费者能力瓶颈:消费者实例数是否小于分区数?代码中是否存在慢 SQL 或第三方调用?
- 消费者组重平衡(Rebalance):这是最隐蔽的根源。频繁的 Rebalance 会暂停消费,导致积压[reference:13]。
- 分区数瓶颈:Kafka 的并行度上限由 Topic 的分区数决定。若消费者实例数远超分区数,多余实例将处于空闲状态。
3.2 应急处理“三板斧”
🪓 第一斧:扩容分区与消费者(治标)
若原 Topic 分区数很少(如 3~6 个),需快速提升并发度。具体操作包括创建高分区数的临时 Topic(如将分区数扩大到 12 或 30)、启动轻量级中转程序将消息从原 Topic 快速转发到新 Topic,并部署多倍消费者实例并行消费,从而实现 5~10 倍的消费速度提升[reference:14]。
🪓 第二斧:优化消费逻辑(治本)
排查并优化慢 SQL、下游依赖等瓶颈点,并将“单条处理”改为“批量处理”[reference:15]。
🪓 第三斧:排查与优化 Rebalance
长时间的超时导致消费者“假死”,从而触发 Rebalance[reference:16]。解决方案包括调优 max.poll.interval.ms(建议设大,如 10 分钟),以及关闭自动提交,手动在处理完后提交 Offset[reference:17]。
四、总结:Kafka 消息保障的最佳实践
- 可靠性(不丢):生产者(acks=all + 幂等 + 回调)→ Broker(多副本 + 最小同步副本 + 禁止脏选主)→ 消费者(手动提交 + 幂等)协同保障。
- 顺序性(不乱):利用分区机制,通过消息键(Key)将业务相关数据路由到同一分区,结合生产者的单线程发送保证。
- 积压(不满):排查 Rebalance 和资源瓶颈,利用“分片放大法”紧急扩容,并持续优化消费逻辑。
掌握这套“三驾马车”,你的消息系统就能从“能用”走向“可靠、有序、可控”。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)