大模型的本地部署
大模型的本地部署
本地部署工具:
Ollama、Xinference(VLLM、Transformers等多种推理引擎)、VLLM
Xinference 部署
部署的模型:Qwen3-4B-fp8
部署的平台:Autodl租用服务器, GPU(4090D-24G)
配置环境:
cd /root/autodl-tmp
# 创建 Conda 环境,并激活xinference的环境
conda create -n xinference python=3.12 -y
conda activate xinference
pip install "xinference[vllm,transformers]"
配置镜像加速
# 设置模型存储路径到数据盘
export XINFERENCE_HOME=/root/autodl-tmp/xinference
# 设置使用 ModelScope(魔搭)下载模型,速度更快且无需特殊网络
export XINFERENCE_MODEL_SRC=modelscope
# 将这两行加入 ~/.bashrc 永久生效
echo 'export XINFERENCE_HOME=/root/autodl-tmp/xinference' >> ~/.bashrc
echo 'export XINFERENCE_MODEL_SRC=modelscope' >> ~/.bashrc
source ~/.bashrc
启动Xinference:
# 终端运行
xinference-local --host 0.0.0.0 --port 6006
# 后台运行
nohuo xinference-local --host 0.0.0.0 --port 6006 > xinference.log 2>&1 &
访问公网服务,自定义服务地址:
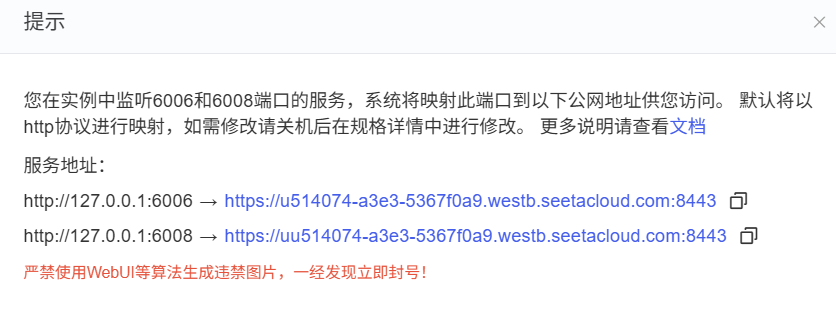
https://u514074-a3e3-5367f0a9.westb.seetacloud.com:8443
选择Xinference部署的模型
配置模型的推理引擎、模型的格式(是否是量化的)、也可以追加VLLM配置信息: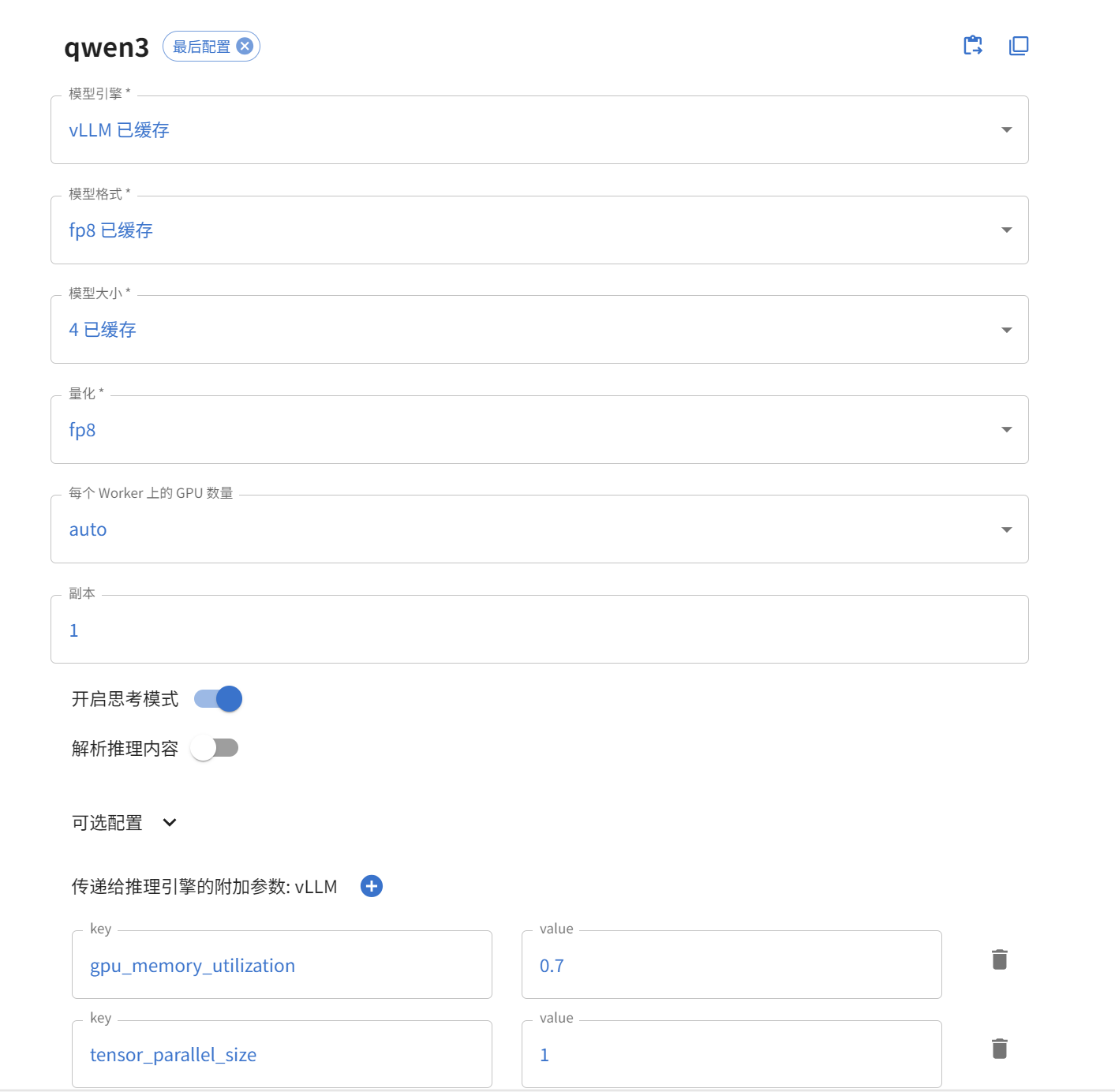
gpu_memory_utilization:0.70, 表示GPU的显存利用率。max_model_len:2048 或 4096,用于限制最大 Token 长度。减小此值可以显著节省 KV Cache 显存,从而允许更高的并发数。
查看Xinference(V2.0+)部署的模型:
xinference list --endpoint http://127.0.0.1:6006
--endpoint http://127.0.0.1:6006:为了能够在公网访问,因为autodl租用的是个docker容器,不是服务器。
压测模型
pip install locust
QPS (Queries Per Second):起源于数据库和搜索引擎领域。它衡量的是系统每秒能够处理的“查询”次数。一个查询通常是原子性的,即“一问一答”且计算开销相对均衡。
req/s (Requests Per Second):更偏向于网络协议层面。它衡量的是服务器每秒接收并处理完成的 HTTP/API 请求数量。在 Locust 等压测工具中,默认使用 req/s 来表示逻辑上的请求完成速率。
在输出Token=50的情况下,对该模型进行压测,从50个并发用户到500个并发用户。
| 指标 | 50 并发 | 500高并发 | 变化结论 |
|---|---|---|---|
| 每秒吞吐 (RPS) | 30.71 | 91.77 | 吞吐量大幅增长,利用率更高 |
| 平均响应时间 | 1.18 秒 | 3.21 秒 | 延迟明显增加,开始排队 |
| 最大响应时间 | 1.57 秒 | 4.26 秒 | 极端情况下的等待时间变长 |
| 95% 分位延迟 | 1.20 秒 | 3.70 秒 | 大多数用户的体验下降了 2 秒 |
在输出Token=512的情况下,500个用户的高并发场景下,首Token的响应时间约为15s,排队时间过长,吞吐量大约为14.66 (req/s), 假设每次都生成最大的512个Token, 该配置下最大的Token生成数量是 7500 Token/s。
另外:在并发数为 50 时,平均首字延迟 (TTFT) 已经飙升至 5567ms(约 5.5 秒)。
VLLM部署
部署的模型:Qwen3-4B-Instruct-2507-BF16
部署的平台:Autodl租用服务器, GPU(4090D-24G)
端口映射到公网:
vllm serve /root/autodl-tmp/model/Qwen/Qwen3-4B-Instruct-2507 \
--served-model-name Qwen3-4B \
--max_model_len 1024 \
--reasoning-parser deepseek_r1 \
--host 0.0.0.0 \
--port 6006
--max_model_len 1024: 限制最大长度。这包括了输入的 Prompt 和输出的 Response 总和。--served-model-name Qwen3-4B: API 接口中的“模型 ID”。--reasoning-parser deepseek_r1: 使用 deepseek_r1 作为推理解析器。/root/autodl-tmp/model/Qwen/Qwen3-4B-Instruct-2507: 模型路径,指向本地存储的 Qwen3-4B 模型文件。
本地Python调用
from openai import OpenAI
# 这里的地址换成 AutoDL 提供的公网 URL 和 6006 端口
client = OpenAI(api_key="EMPTY", base_url="https://u514074-be32-f5ef0b3a.westb.seetacloud.com:8443/v1")
response = client.chat.completions.create(
model="Qwen3-4B",
messages=[{"role": "user", "content": "你好,请开始推理"}]
)
print(response)
print(response.choices[0].message.reasoning_content)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)