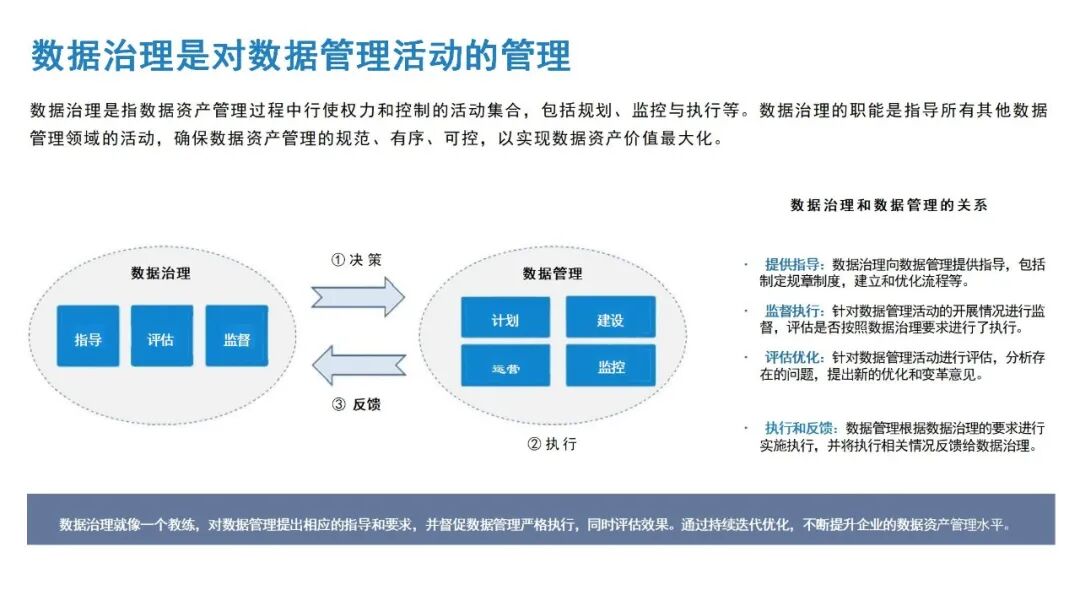
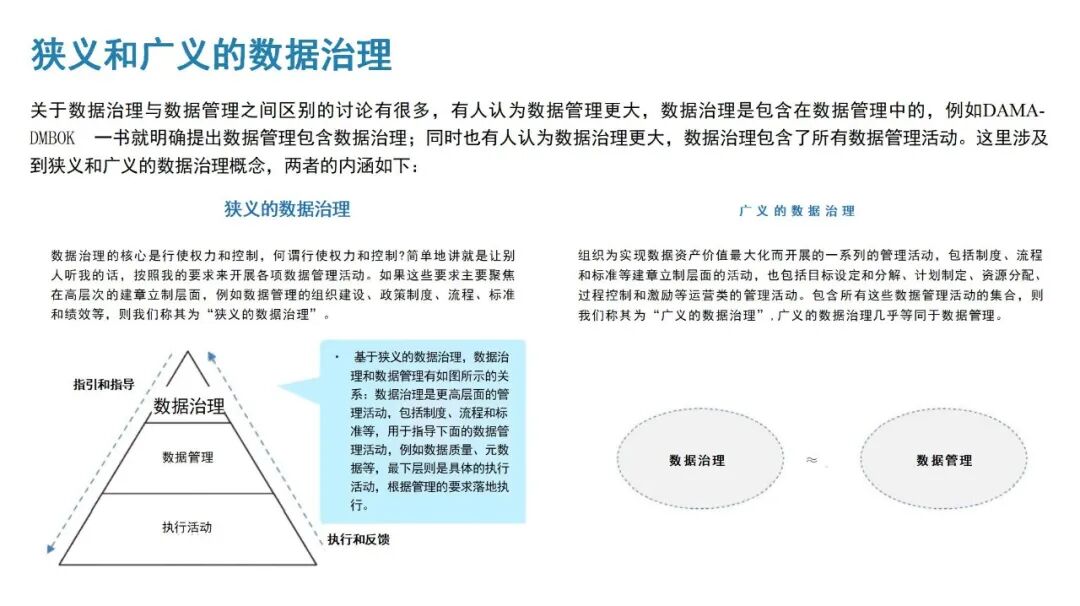
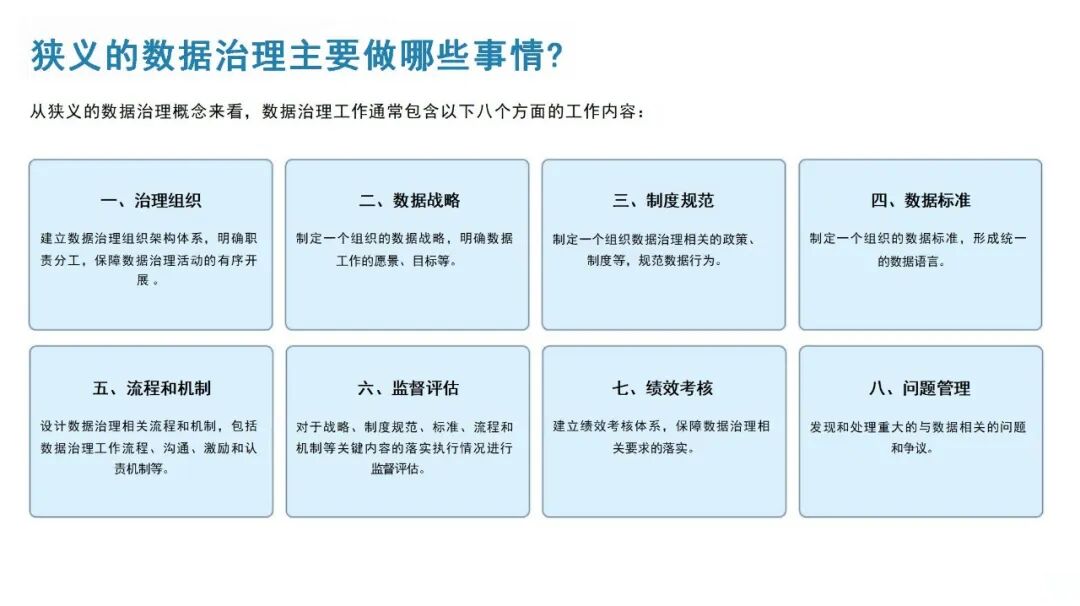
大模型赋能数据治理手册:重构数据价值释放的核心路径(附相关材料下载)
微信公众号:木木自由,更多数据分析,经营分析、财务分析、商业分析、数据治理、数据要素、数据资产干货以及资料分享
木木自由· 数据分析·领地
在数字经济深度发展的今天,数据已成为企业与社会发展的核心战略资产,而数据治理作为规范数据全生命周期、提升数据质量、释放数据价值的关键手段,其重要性日益凸显。传统数据治理模式受限于技术瓶颈,难以应对海量异构数据的处理需求,而生成式大模型的崛起,凭借其强大的语义理解、模式识别与自主学习能力,为数据治理注入了全新活力,推动数据治理从“人工主导”向“智能自主”转型。
在此,【数据分析·领地】整理了《大模型赋能数据治理手册》具体如下:
大模型赋能数据治理手册(56页 PPT).pptx
大模型赋能数据治理(22页 PPT).pptx
【指南】大模型与数据治理指南(32页 PPT).pptx
【报告】Data for AI 实践之路:从数据治理到智能应用.pdf
【报告】生命科学MDM中的自主AI:数据治理新纪元.pdf
【报告】百思数据治理大模型(BS-LM)技术白皮书 AI原生时代的数据治理新范式 百.pdf
【实践】华为数据治理最佳实践手册(269页).pdf
···
文来源:【数据分析·领地星球】查看网络整理以及个人实践总结结正文开始
一、核心概念解析:厘清大模型与数据治理的内在关联
要理解大模型赋能数据治理的价值,首先需明确两个核心概念的内涵,以及二者的双向赋能关系。
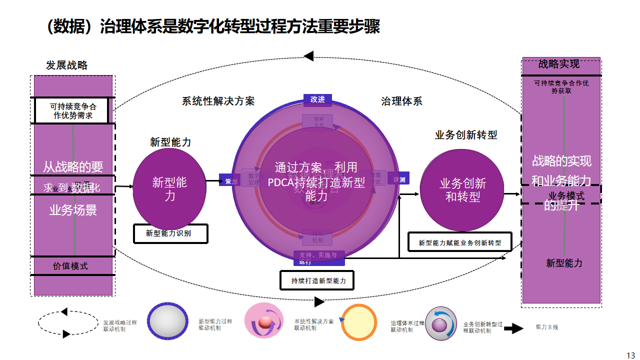
数据治理,本质上是对数据从产生、采集、存储、流转到应用、销毁的全生命周期进行规范化管理的一系列活动,核心目标是解决数据“脏、乱、散、险”的问题,实现数据的准确性、完整性、一致性、及时性与安全性,最终将数据资源转化为可复用、可增值的数据资产。其核心环节包括数据采集、数据清洗、数据脱敏、数据标注、数据标准制定、数据安全管控等,是数字化转型的基础工程。
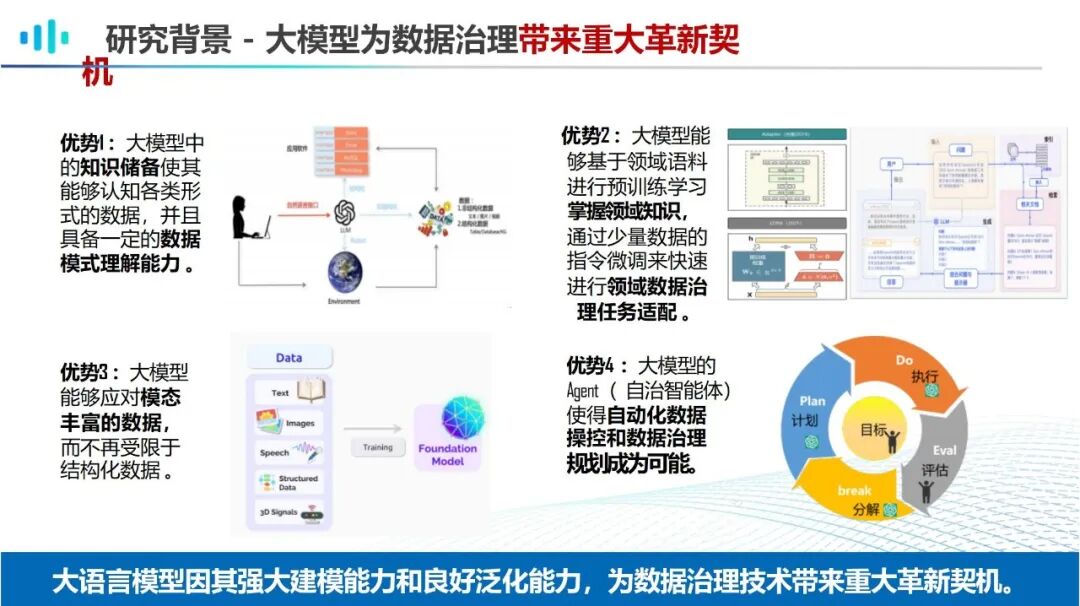
大模型,即大型语言模型(Large Language Model,LLM),是基于海量数据训练而成、具备亿级以上参数的人工智能模型,其核心优势在于能够理解复杂自然语言、识别数据模式、自主生成符合逻辑的内容,并通过持续学习优化自身能力。不同于传统AI模型的“单点任务适配”,大模型具备泛化能力,可跨场景适配数据治理的各类需求,无需针对每个治理环节单独开发模型,大幅降低了技术落地成本。
二者的内在关联呈现“双向赋能”的闭环:数据治理为大模型提供高质量的训练“燃料”,只有经过规范治理的数据,才能避免大模型出现过拟合、偏见或幻觉问题,保障模型输出的准确性;大模型则反哺数据治理,通过智能化技术替代人工完成繁琐、重复的治理工作,突破传统治理模式的效率瓶颈,深化治理深度与广度。
二、为什么需要大模型赋能数据治理?
当前,传统数据治理模式已难以适配数字化转型的需求,诸多痛点制约了数据价值的释放,而大模型的技术特性恰好精准匹配这些痛点,成为数据治理的“破局关键”。
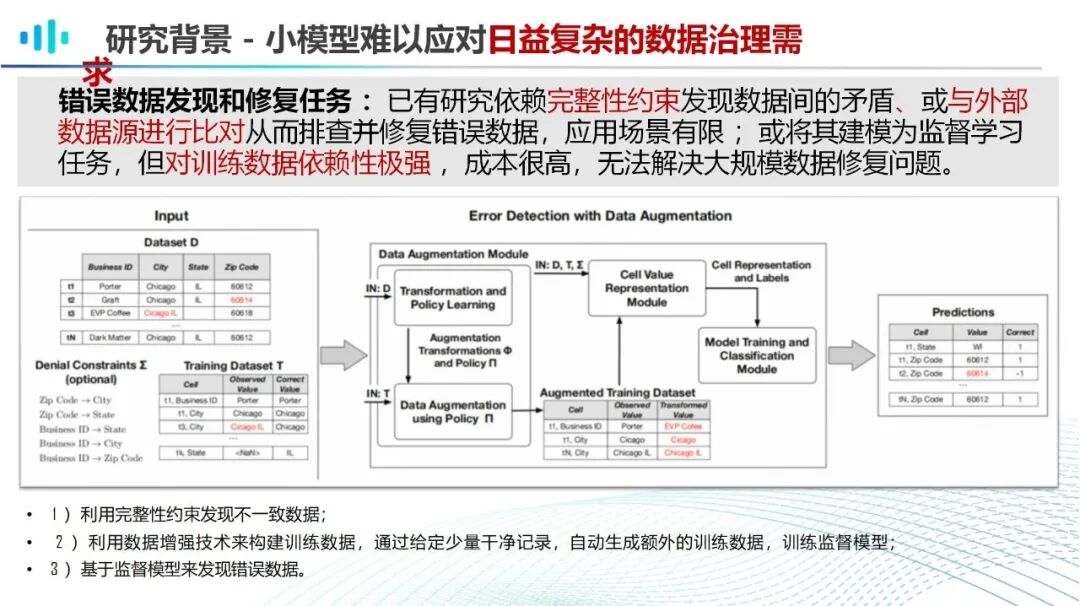
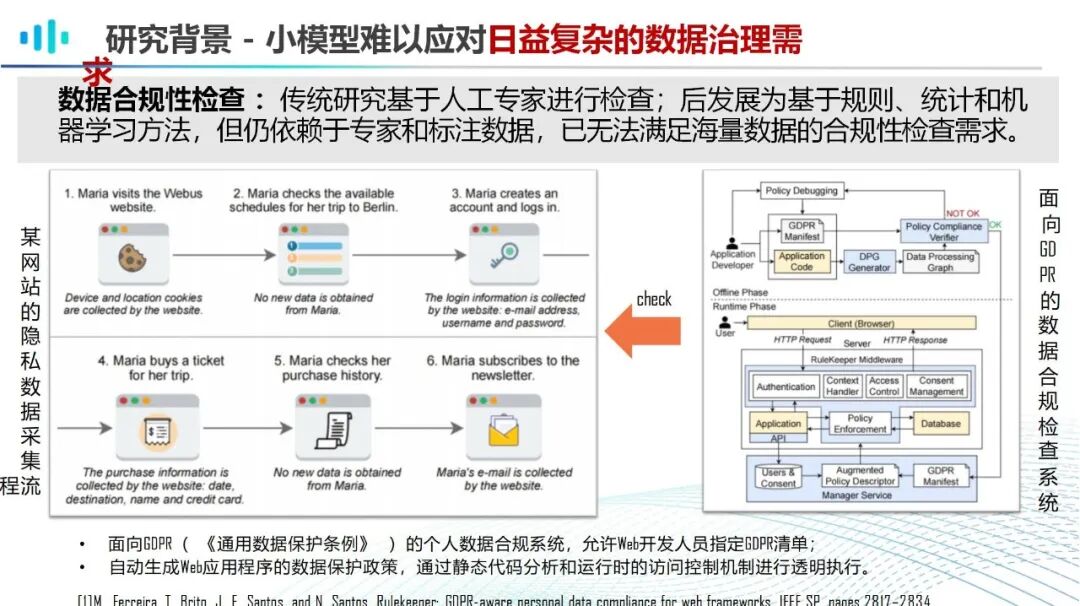
传统数据治理的核心痛点集中在四个方面:一是数据孤岛突出,各业务系统独立搭建,数据格式、统计口径不统一,形成“数据烟囱”,跨部门数据共享与协同治理难度大,例如企业客户数据分散在CRM、电商平台、会员系统中,无法形成完整的客户画像;二是人工成本高企,数据清洗、标注、规则校验等环节高度依赖人工,效率低下且易出错,某零售企业每月处理300万条销售数据需5人团队耗时15天,人工失误还可能导致数据偏差影响决策;三是标准迭代滞后,业务场景快速变化,人工维护的数据标准往往滞后1-2个月,无法及时匹配业务需求,例如电商大促期间新增“预售订单”类型,传统治理模式难以快速适配数据统计需求;四是安全合规承压,海量数据中包含大量敏感信息,传统脱敏、审计方式难以实现全流程管控,易出现隐私泄露风险,同时难以满足《数据安全法》《个人信息保护法》等法规的合规要求。
大模型的出现,为这些痛点提供了针对性的智能化解决方案,其核心价值体现在三个维度:
其一,全流程自动化提升治理效率。借助自然语言理解(NLU)与生成式AI技术,大模型可自动识别数据中的异常值、缺失值,推荐清洗规则,实现数据清洗、标注、校验的自动化,例如金融行业部分银行通过大模型实现“客户风险等级标注”自动化,效率提升90%;某互联网企业采用大模型实现多源数据接入方式自动匹配,集成效率较人工提升80%。
其二,动态适配业务需求,强化治理灵活性。大模型可基于实时业务数据反馈,自主优化治理策略,无需人工干预即可适配业务场景的变化,例如某生鲜电商平台的大模型的可根据季节变化自动调整“库存周转率”计算逻辑,匹配生鲜损耗率的动态波动需求。
其三,沉淀行业知识,突破小样本治理困境。大模型可将垂直领域的治理经验转化为可复用的数字化资产,同时通过生成对抗网络(GAN)等技术扩充小样本数据,解决特殊行业数据样本不足的问题,例如烟草行业通过大模型扩充跨境物流数据样本,将案件类型覆盖率从39.4%提升至63%。
此外,大模型还能推动数据治理从“成本中心”向“价值中心”转型,通过深度挖掘数据关联关系,为企业决策提供更精准的支撑,例如某保险企业通过大模型优化数据治理,将核保数据处理时间从2小时缩短至10分钟,年节约成本超200万元。
三、大模型赋能数据治理怎么做?—— 基于实践的实施路径与关键举措
大模型赋能数据治理并非简单的技术叠加,而是需要结合企业实际需求,构建“技术支撑-流程优化-组织保障”的完整体系,遵循“循序渐进、落地见效”的原则,具体可分为三个阶段推进,全程依托行业实践经验,确保可操作性。
第一阶段:前期准备,筑牢基础保障。此阶段的核心是明确治理目标、梳理数据资源、搭建技术底座。一是开展全面的数据资产盘点,明确数据来源、类型、质量现状及治理痛点,优先聚焦核心业务数据(如客户数据、交易数据),避免“全面铺开、重点不清”;二是选型适配的大模型,结合行业特性选择模型类型,通用场景可选用GPT-4、文心一言等通用大模型,垂直行业(金融、烟草、政务)可选用经过行业数据微调的专用大模型,降低适配成本;三是搭建技术支撑体系,整合数据存储工具(如Hadoop、Spark)与大模型平台,实现“数据-模型-应用”的全生命周期管控,同时完善数据安全基础设施,为后续治理工作筑牢安全防线。
第二阶段:分环节落地,实现智能化治理。聚焦数据治理的核心环节,利用大模型实现精准赋能,形成“动态闭环”的治理流程。
在数据采集环节,借助大模型的多源数据识别能力,自动适配MySQL、Oracle数据库与外部API接口、Excel文件等异构数据格式,自动识别数据接入协议,大幅降低多源数据集成成本;跨境电商通过RAG技术构建“商品属性知识库”,接入新平台商品数据时,大模型可一键生成数据校验规则,减少人工核验时间60%。
在数据清洗与标注环节,大模型可自动识别数据中的重复值、异常值(如“客单价10万元”的日用品订单),生成清洗建议并自动执行,同时通过语义理解实现非结构化数据(如文本日志、图片数据)的自动标注,替代人工完成繁琐工作,提升标注精度与效率,例如某金融机构通过大模型自动清洗客户交易数据,数据准确率从88%提升至99.2%。
在数据标准与血缘管理环节,大模型可基于行业规范与企业业务需求,自动生成数据标准(如字段定义、统计口径),同时结合图数据库技术,可视化展示数据全链路流转路径,自动识别冗余环节,助力企业精简数据链路,例如某国有银行通过大模型生成“不良贷款率”“拨备覆盖率”等核心指标的计算标准,确保全行各系统口径一致。
在数据安全与合规环节,大模型可自动识别敏感数据(如身份证号、银行卡号、医疗记录),实现敏感数据的自动脱敏、加密,同时实时监控数据流转过程,识别违规访问与数据泄露风险,生成合规审计报告,帮助企业满足监管要求,某国有银行通过该方式将合规检查时间从“月级”缩短至“小时级”,年减少监管处罚成本超500万元。
第三阶段:优化迭代,构建长效机制。数据治理是持续优化的过程,需建立“模型输出-人工校验-反馈优化”的闭环机制:一是组建人机协同团队,专业人员负责审核大模型的治理结果,尤其在高敏感场景(如金融合同数据、医疗病历治理),确保治理准确性;二是基于用户反馈与业务变化,定期对大模型进行微调,优化治理策略,提升模型适配性;三是建立数据治理效果评估体系,从数据质量、治理效率、成本节约、价值释放等维度进行量化评估,例如通过数据准确率、治理耗时、业务决策效率等指标,持续优化治理流程;同时搭建完善的组织架构,设立“AI数据治理官”角色,统筹业务、IT、算法团队协作,明确权责分工,解决“数据无主”的管理真空问题。
四、未来展望:大模型赋能数据治理的发展趋势与挑战
随着大模型技术的持续迭代与数据要素市场化的深化,大模型赋能数据治理将呈现“智能化、协同化、行业化”的发展趋势,同时也面临一些亟待解决的挑战,未来需在技术创新、合规管控与人才培养方面持续发力。
从发展趋势来看,其一,治理模式将实现“全自动化+自主决策”,大模型将具备更强的自主学习与推理能力,能够自动识别治理痛点、优化治理策略,甚至自主应对复杂的跨领域数据治理场景,实现数据治理的“自动驾驶”,例如园区治理中,大模型可基于时空数据挖掘管理痛点,指导治理重点转向场景化数据服务;其二,跨领域协同治理成为常态,大模型将打破企业内部、行业之间的数据壁垒,实现跨企业、跨行业的数据共享与协同治理,例如政务领域通过大模型整合公安、民政、税务等部门数据,优化“一网通办”服务,提升政务治理效率;其三,行业专用大模型成为主流,通用大模型将结合金融、医疗、政务等行业的业务特性与数据特点,进行针对性微调,形成行业专用治理模型,例如“烟法宝”烟草行业大模型、金融风控治理模型,提升治理的精准度与适配性;其四,数据治理与大模型的双向赋能将更加深化,数据治理的精细化将推动大模型性能持续提升,而大模型的迭代将进一步拓展数据治理的边界,实现“数据-模型-价值”的良性循环。
同时,我们也需清醒认识到面临的挑战:一是模型安全与伦理风险,大模型可能出现数据偏见、幻觉等问题,若治理不当可能导致决策失误,同时模型训练过程中可能涉及数据隐私泄露风险,需建立完善的模型安全管控与伦理规范;二是合规管控难度提升,随着数据治理范围的扩大与技术的复杂化,如何确保数据采集、存储、流转、应用全流程符合法律法规要求,成为企业面临的重要难题;三是复合型人才短缺,数据治理需要既掌握数据治理知识,又熟悉大模型技术的复合型人才,当前这类人才的短缺制约了技术落地速度;四是技术落地成本较高,大模型的部署、微调与维护需要大量的资金与技术投入,中小微企业难以承担,导致技术普及存在差距。
针对这些挑战,未来需从三个方面突破:一是加强技术创新,优化大模型的泛化能力与安全性,降低模型部署与维护成本,推动大模型技术的普惠化;二是完善法律法规与行业规范,明确大模型赋能数据治理的合规边界,建立数据治理与模型安全的监管体系;三是加强人才培养,搭建高校、企业与科研机构的协同培养机制,培养兼具数据治理与大模型技术的复合型人才,为技术落地提供人才支撑。
大模型赋能数据治理手册
★





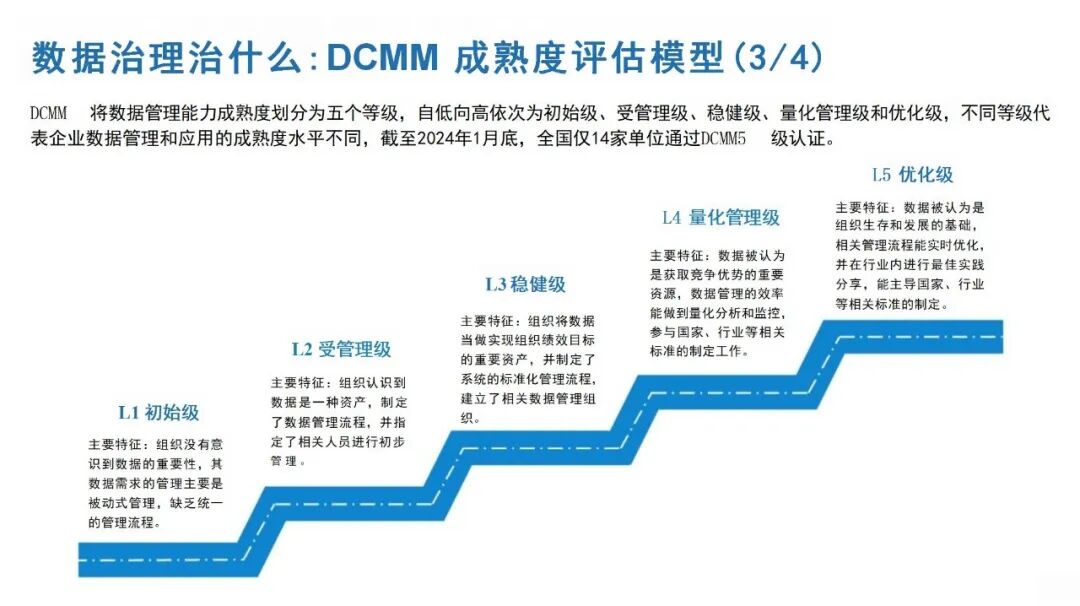


···
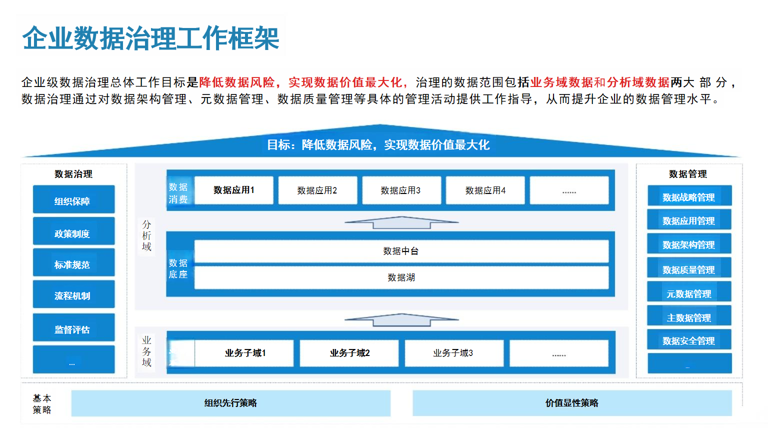
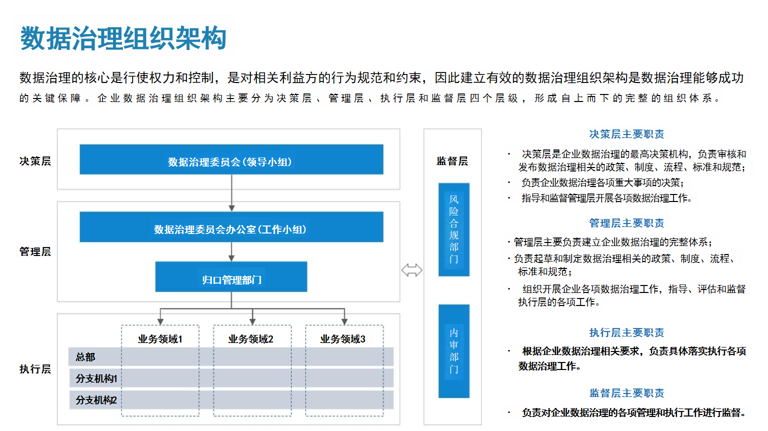

····

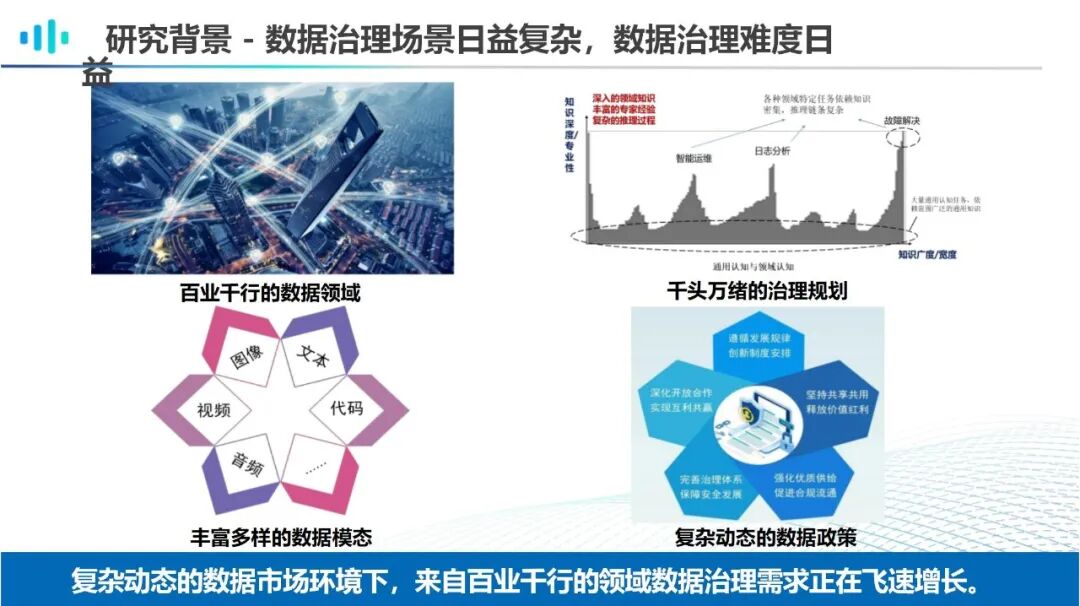




···
篇幅有限只展示部分。(分享PPT在星球“数据治理)
文│来源:整合网络资源和个人实践经验,进【数据分析·领地】星球查看完整版PPT~
- END -
附1:《AI+数据治理指南》
AI 在主数据治理中的应用.pdf
基于DeepSeek的数据治理方案(完整版64页).pdf
基于DeepSeek的数据治理方案(64页 PPT).pptx
大模型赋能数据治理(24页 PPT).pptx
数据流动治理整体解决方案(45页PPT).pptx
AI时代的数据治理(11页 PPT).ppt
AI 在主数据治理中的应用.pptx
数据治理发展情况调研分析 33页.pdf
数据治理全过程域工具包研究(27页).pdf
···


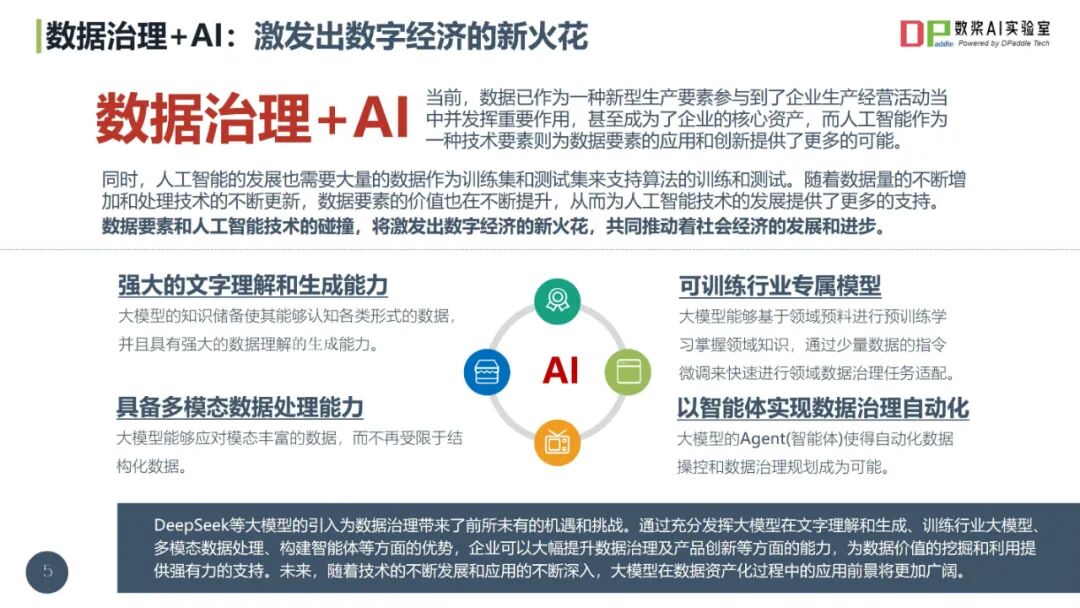
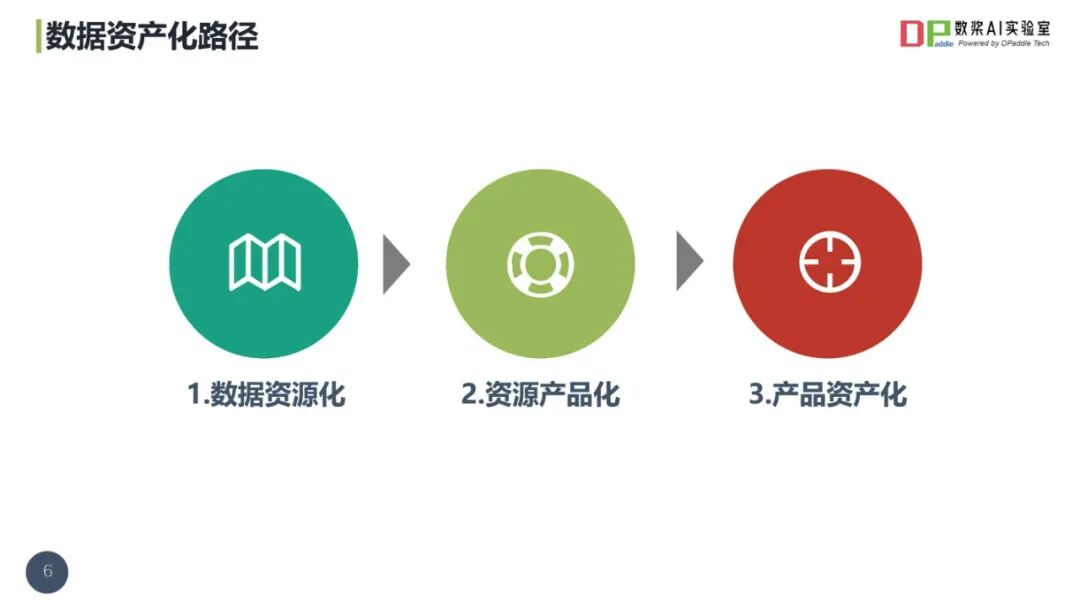

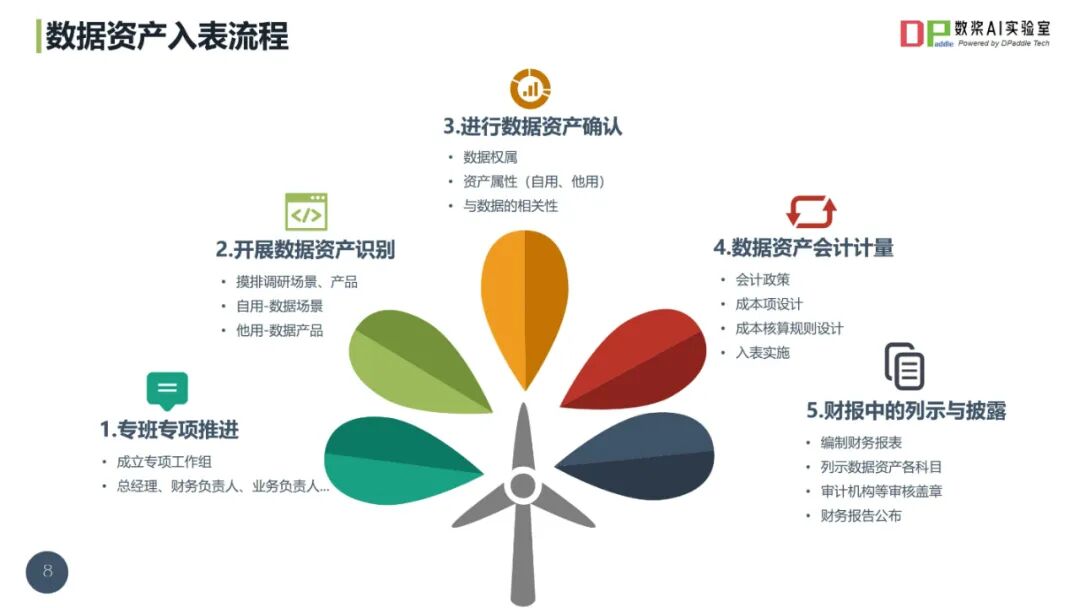




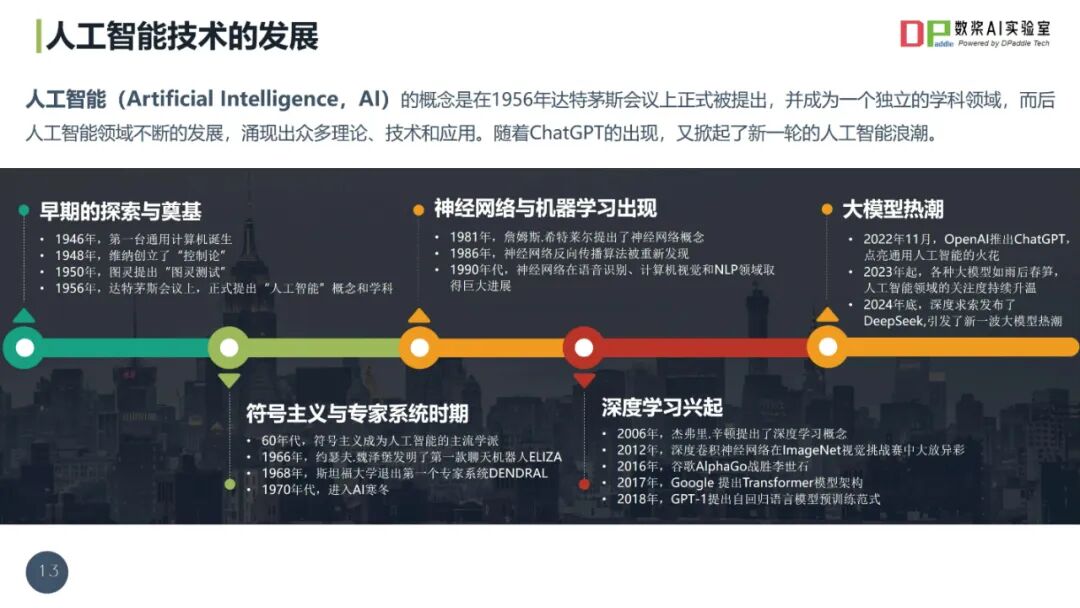
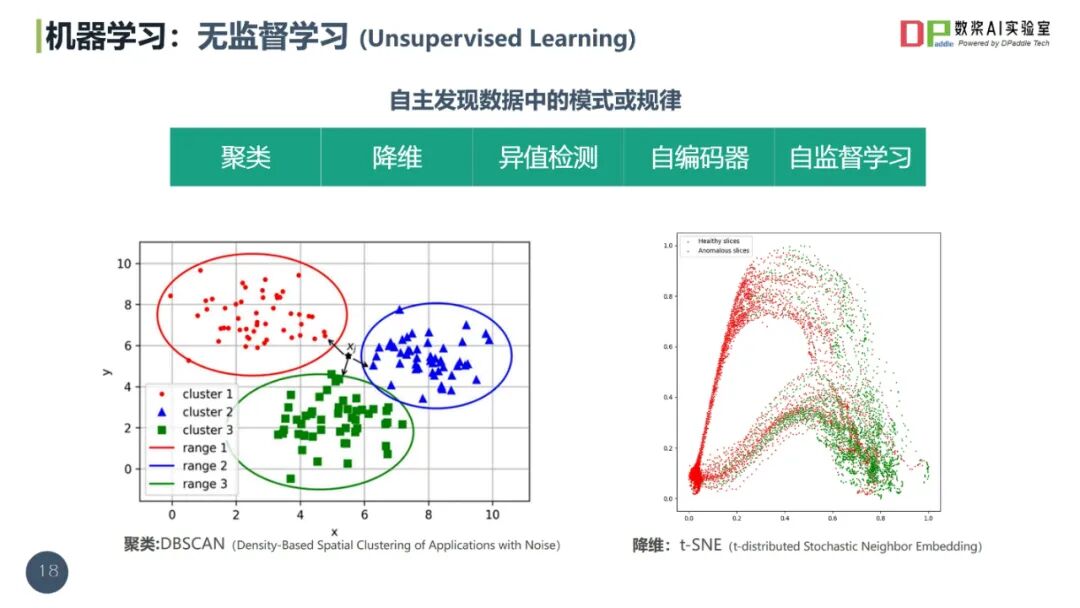
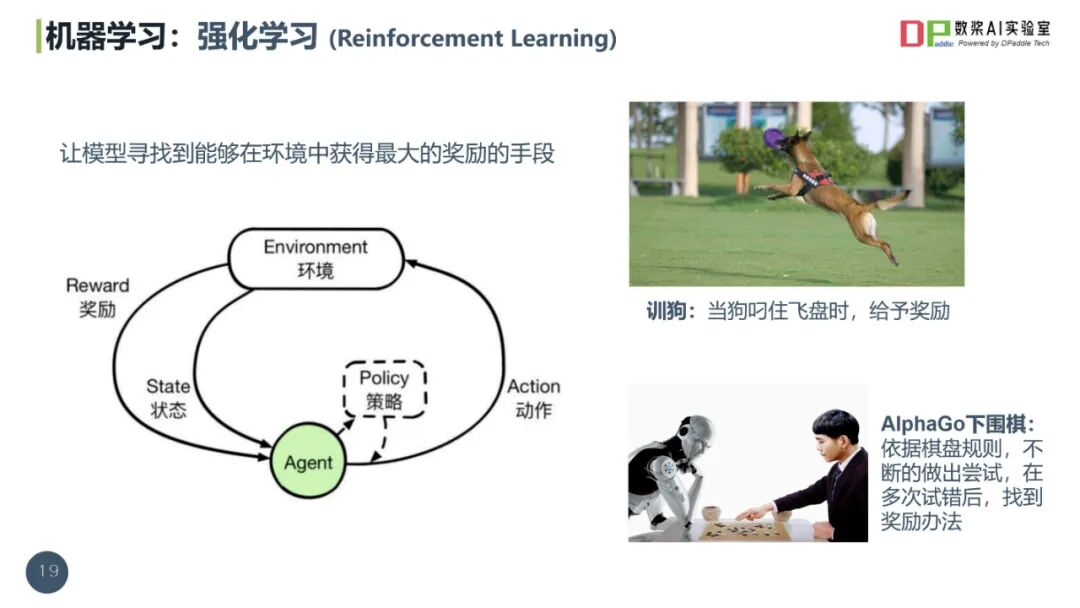
2025数据治理体系构建指南(44页 PPT)





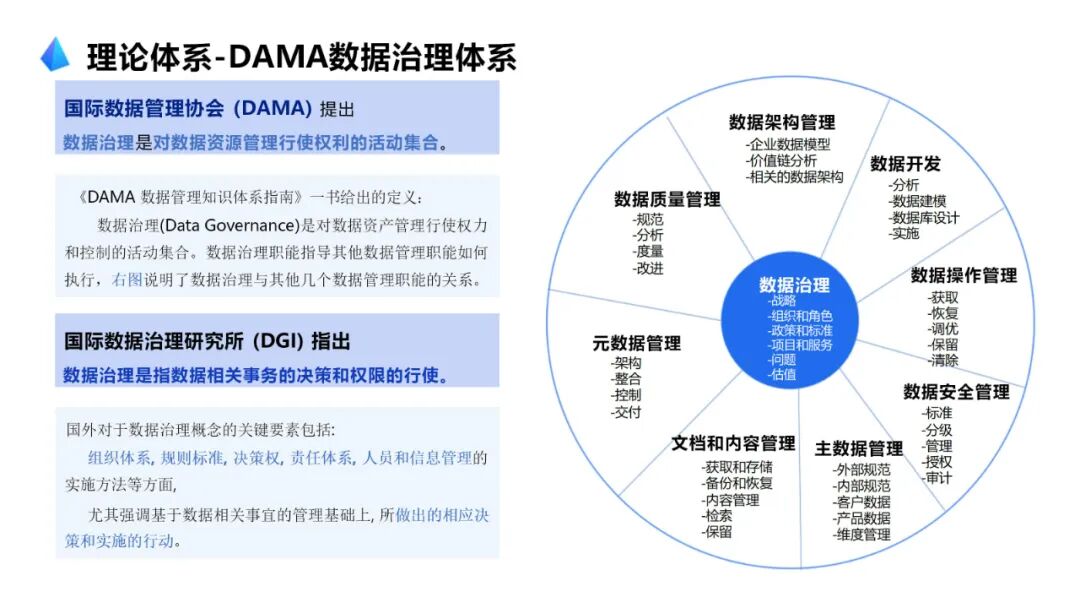
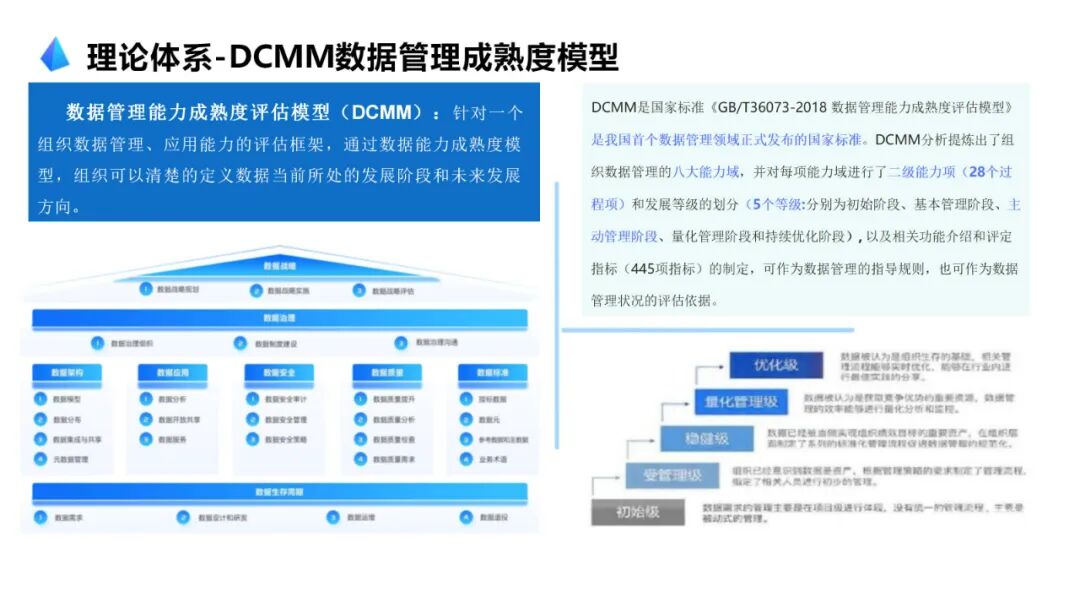


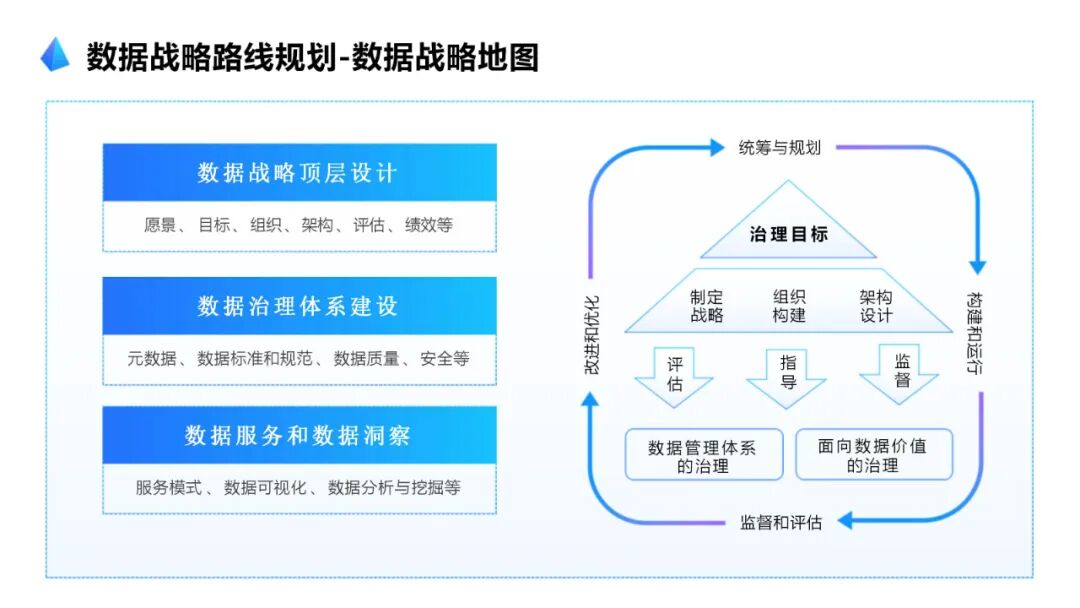
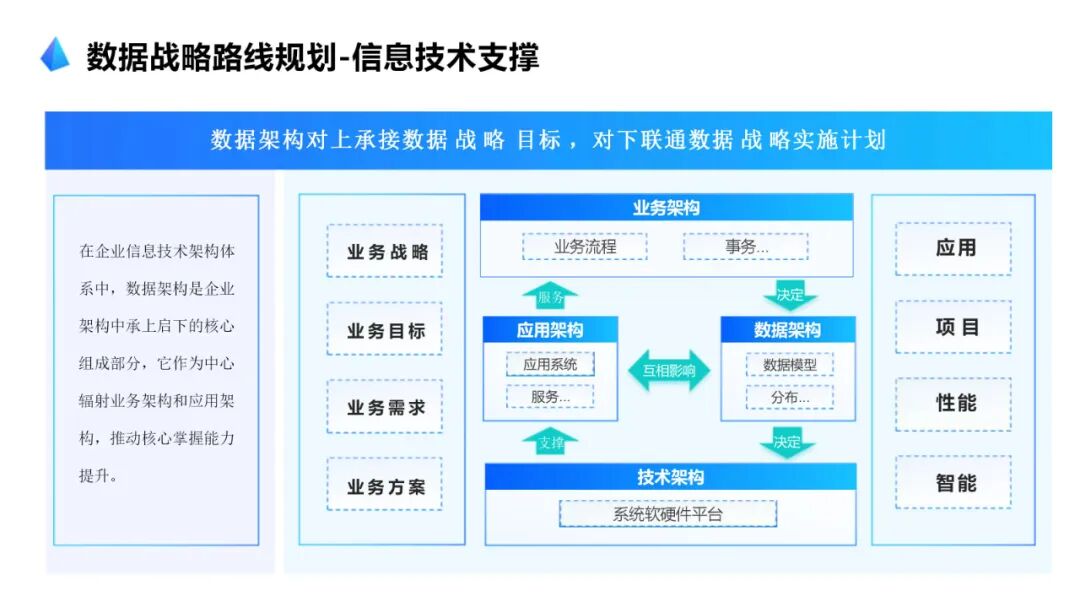
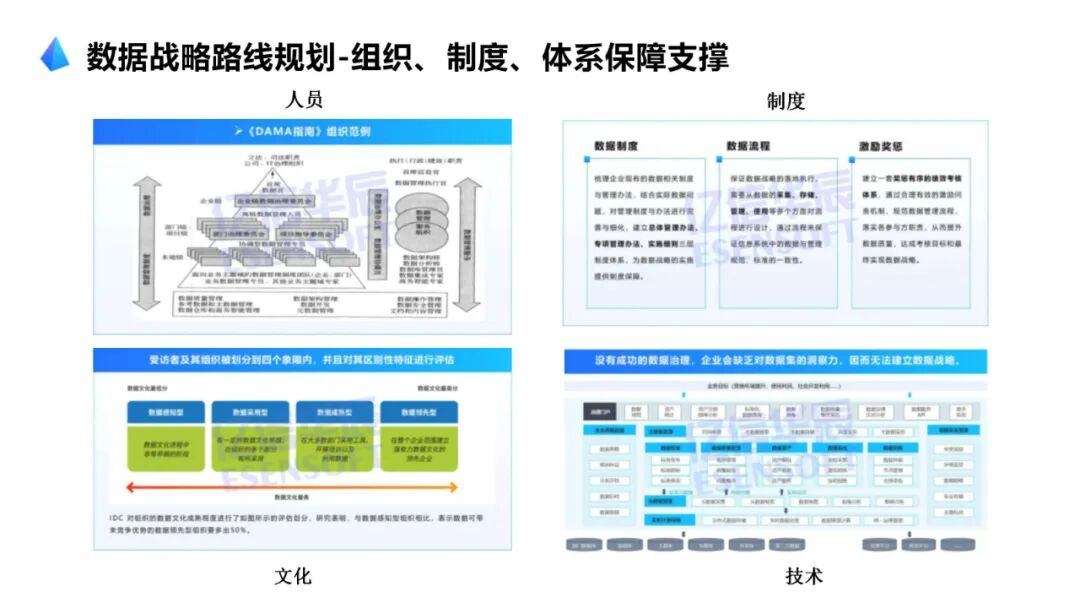
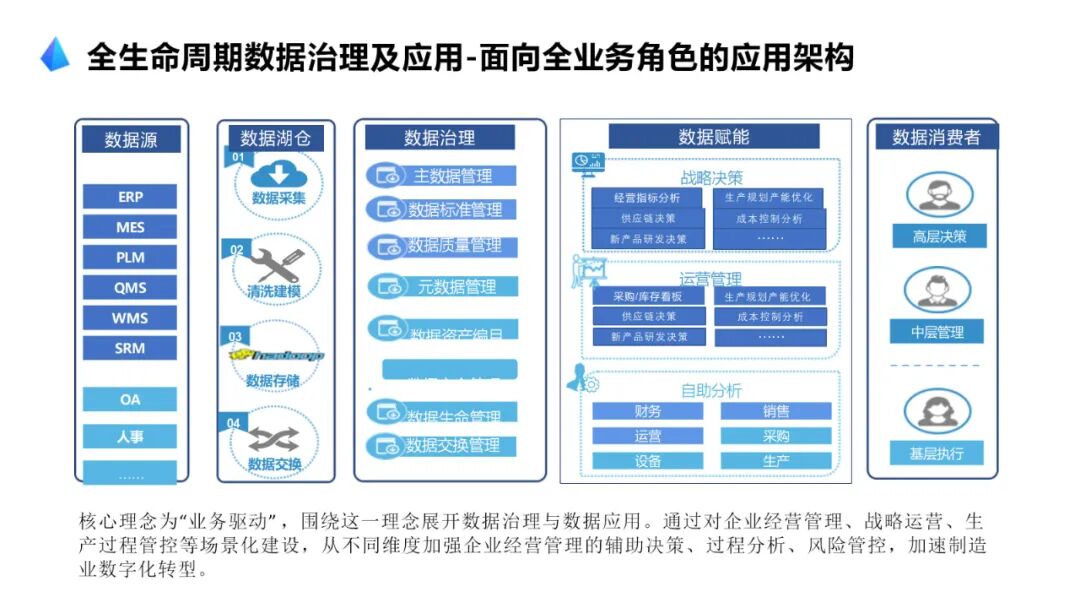
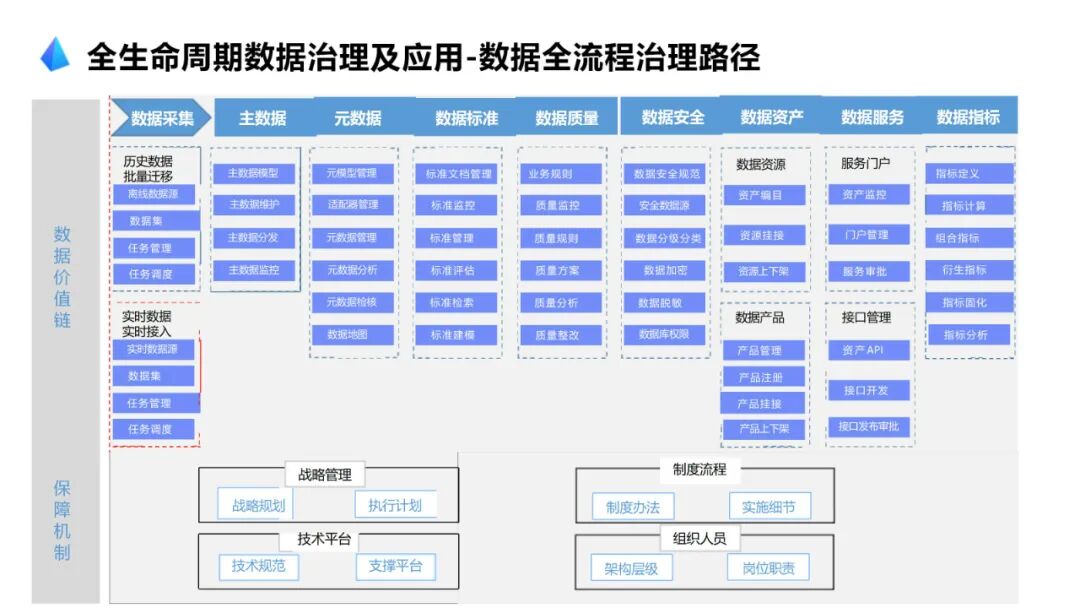
····
附2:数据治理与数据指标库规划指南


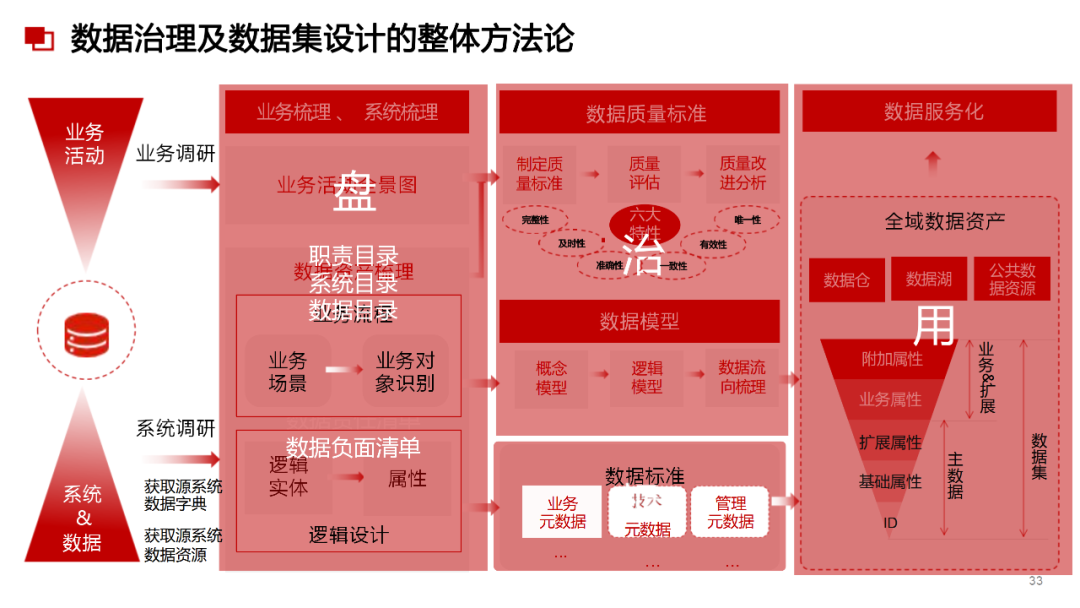
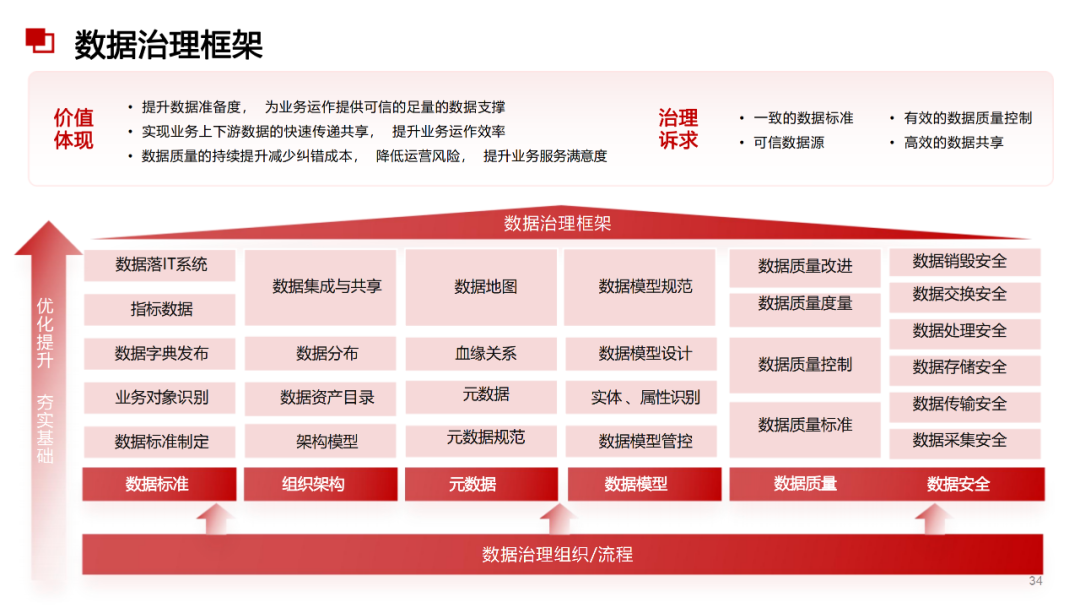
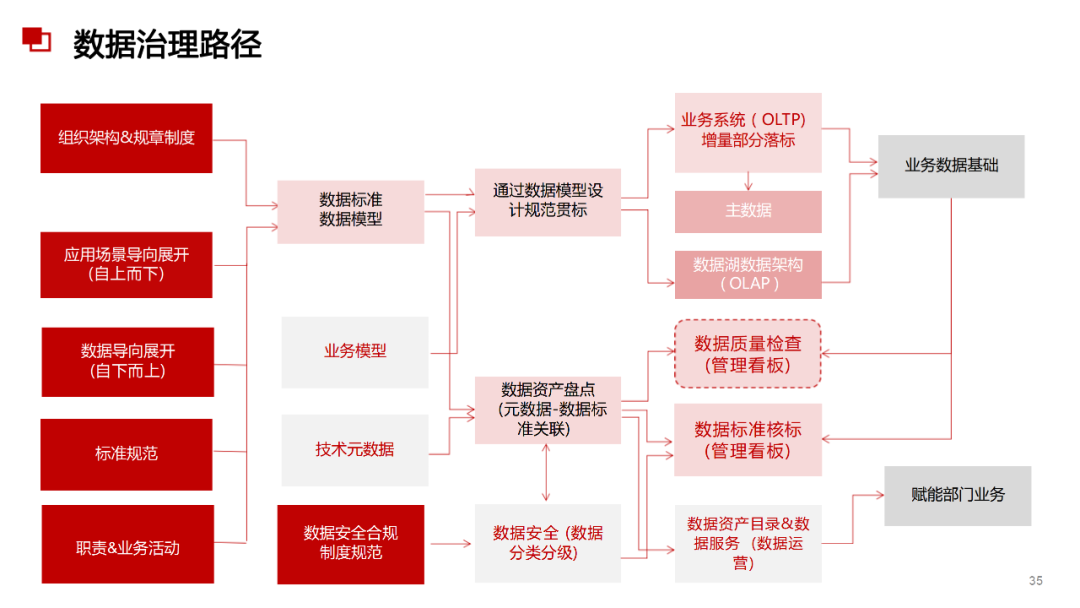
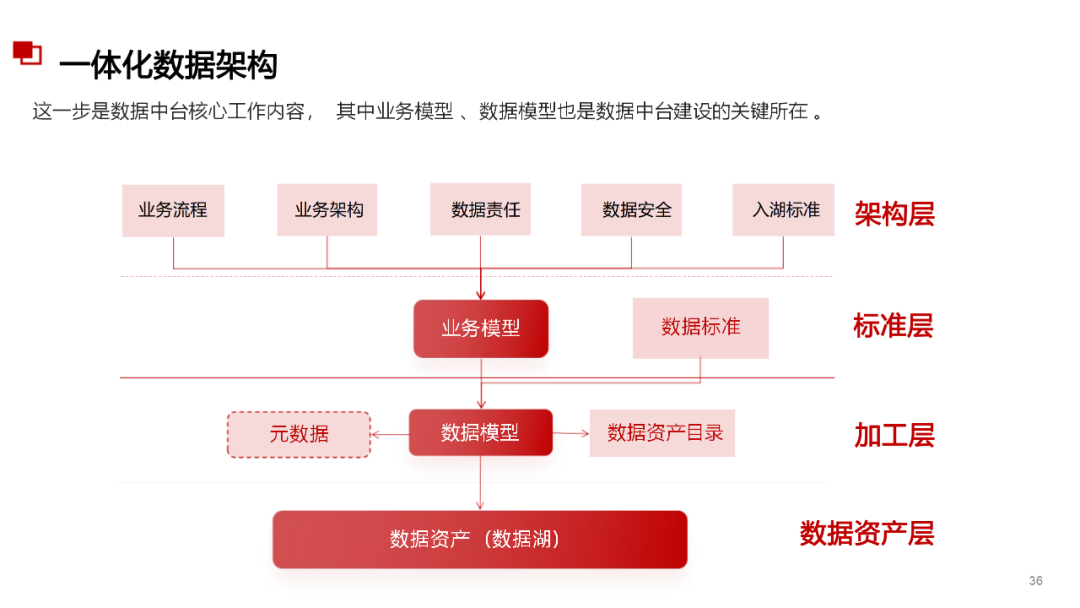
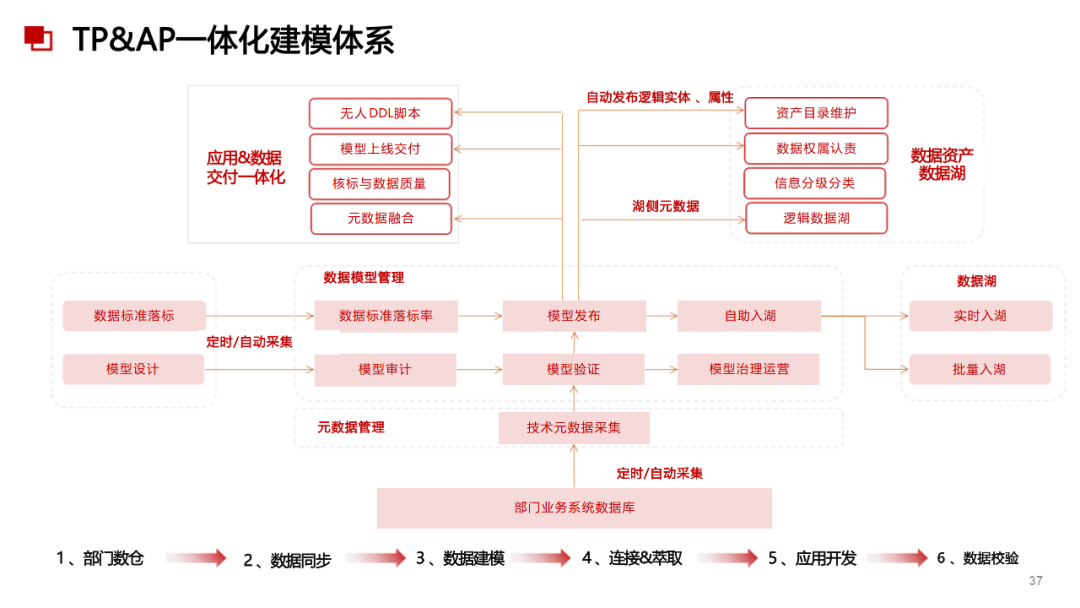
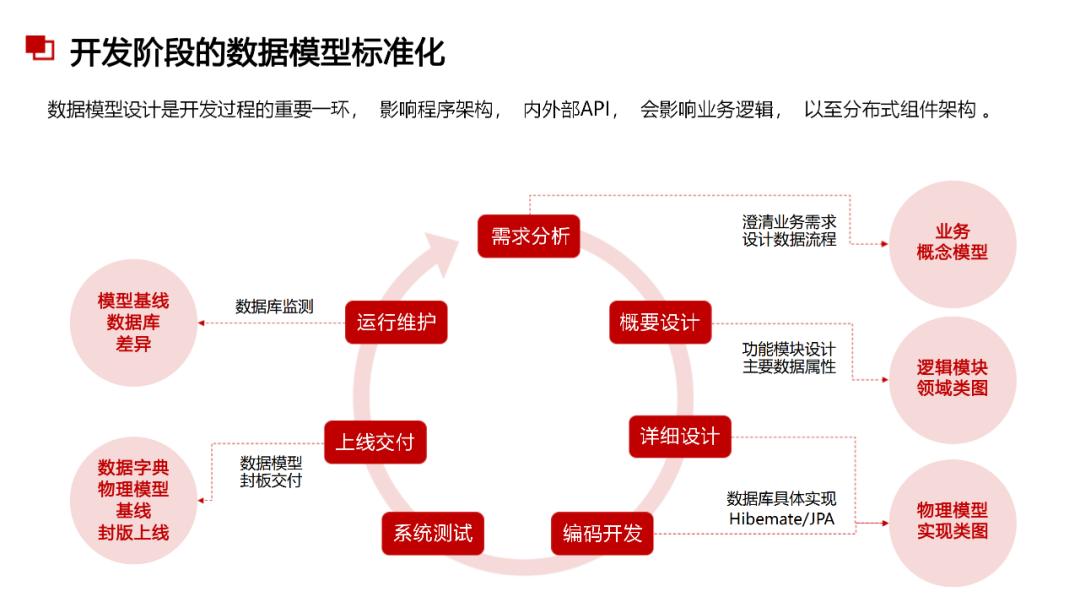
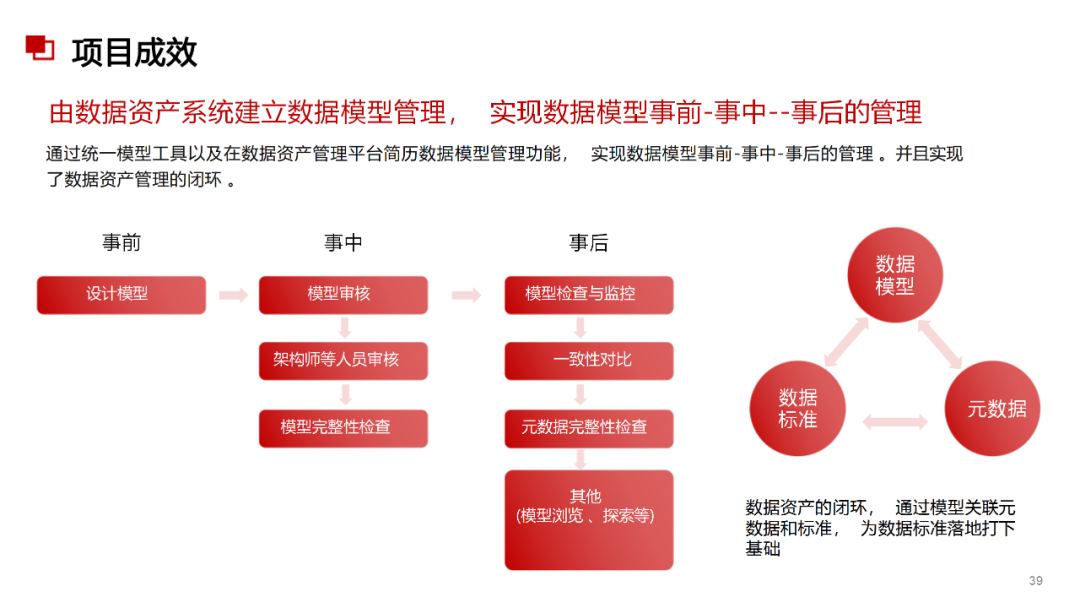
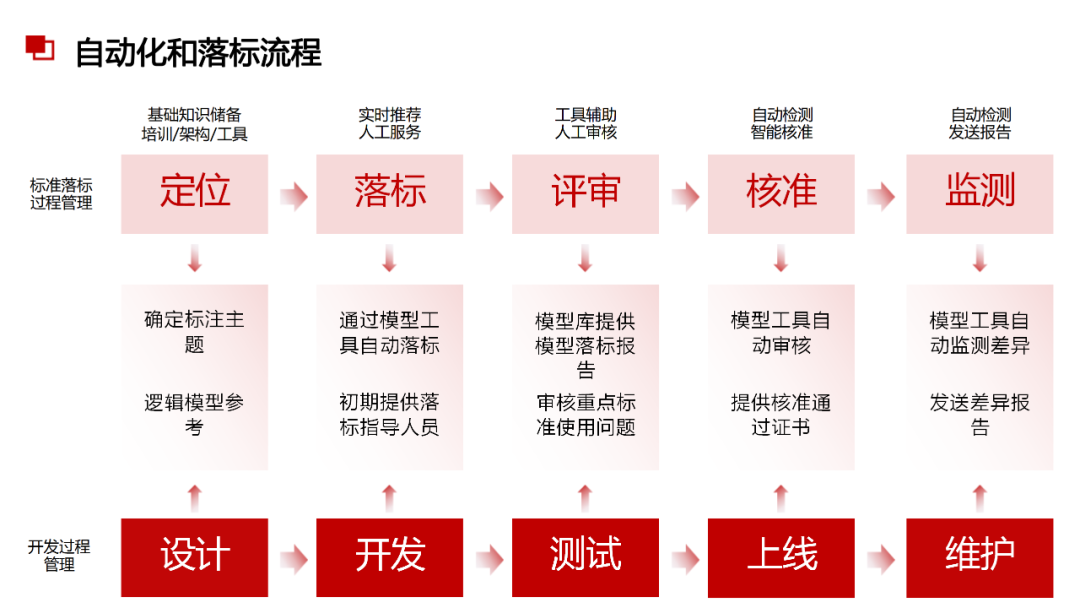
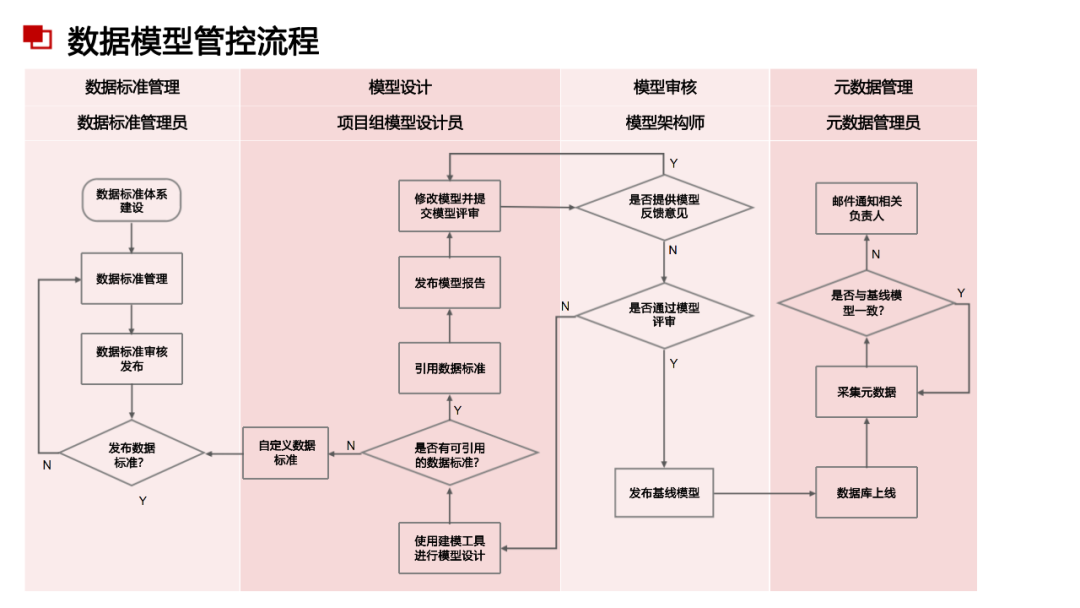
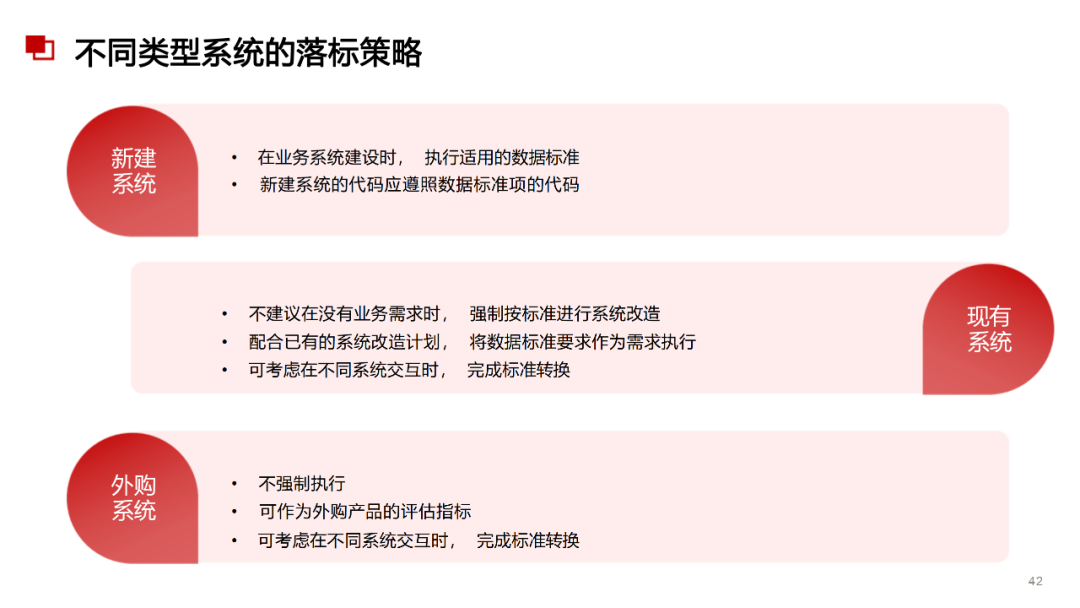
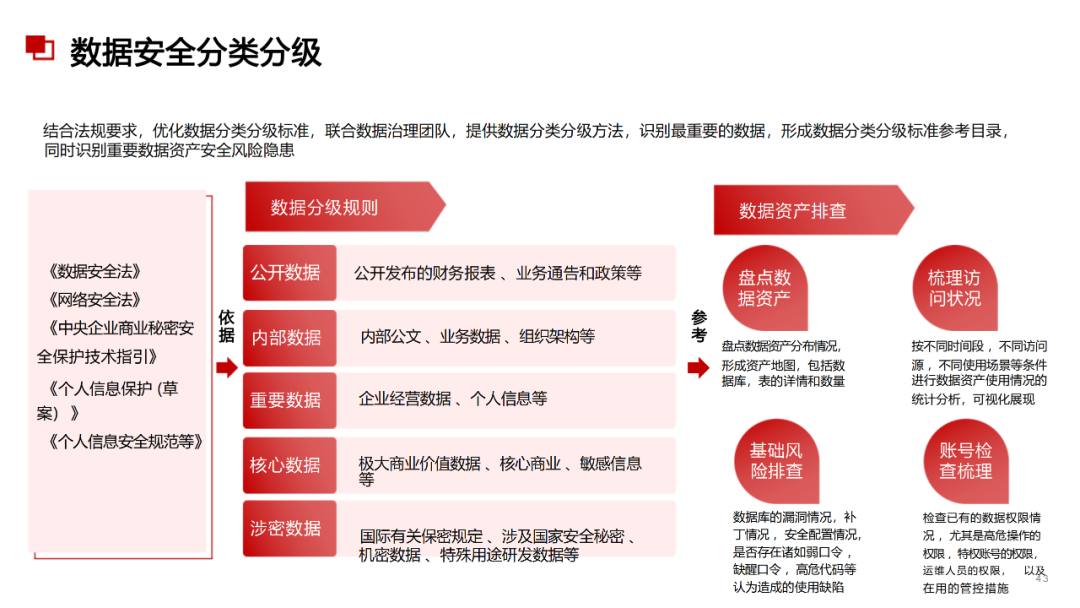
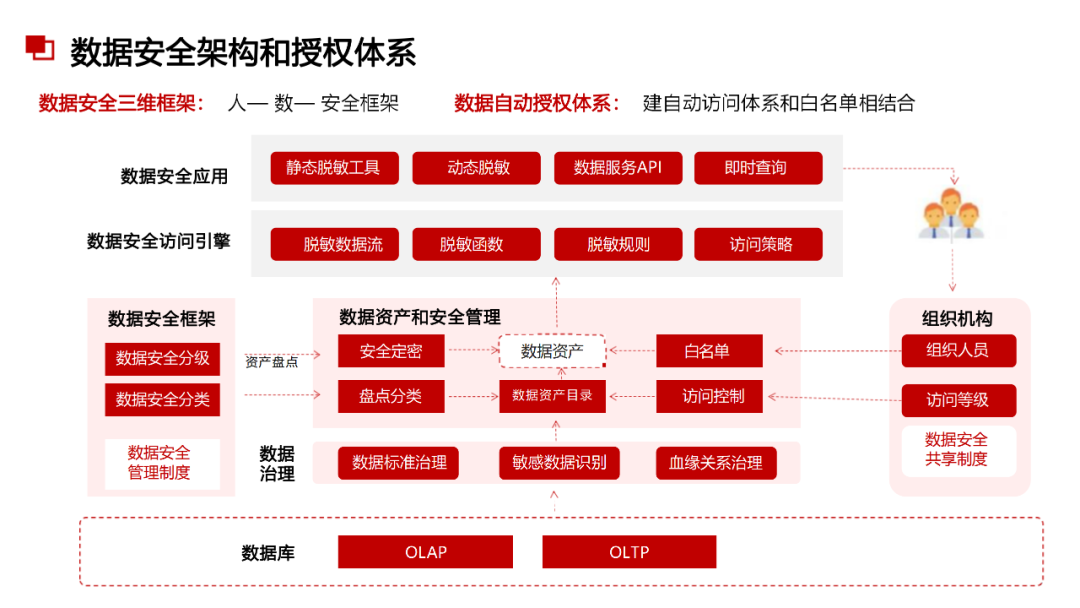
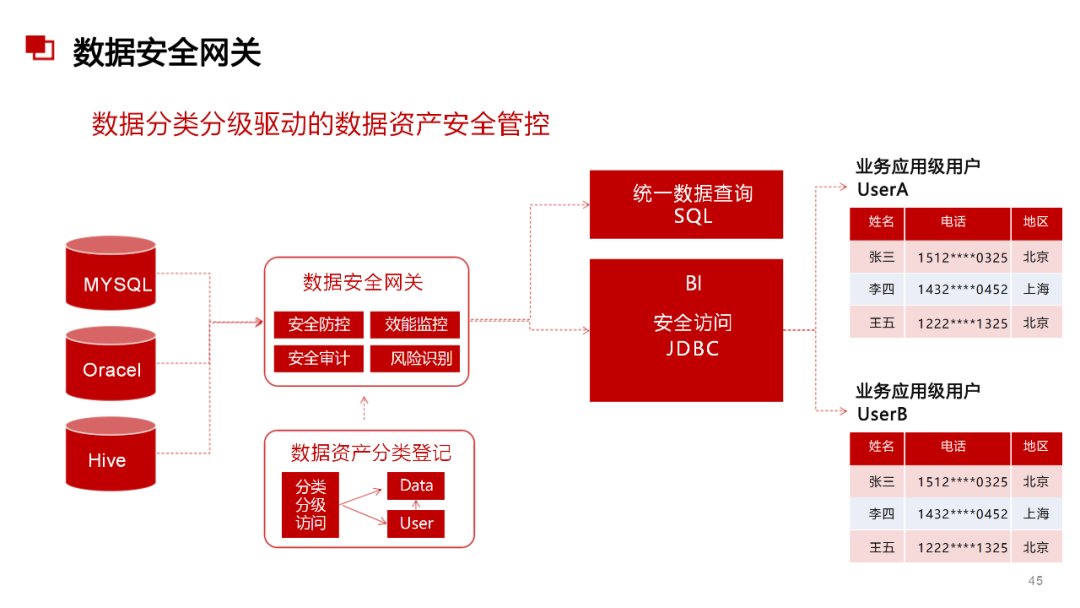

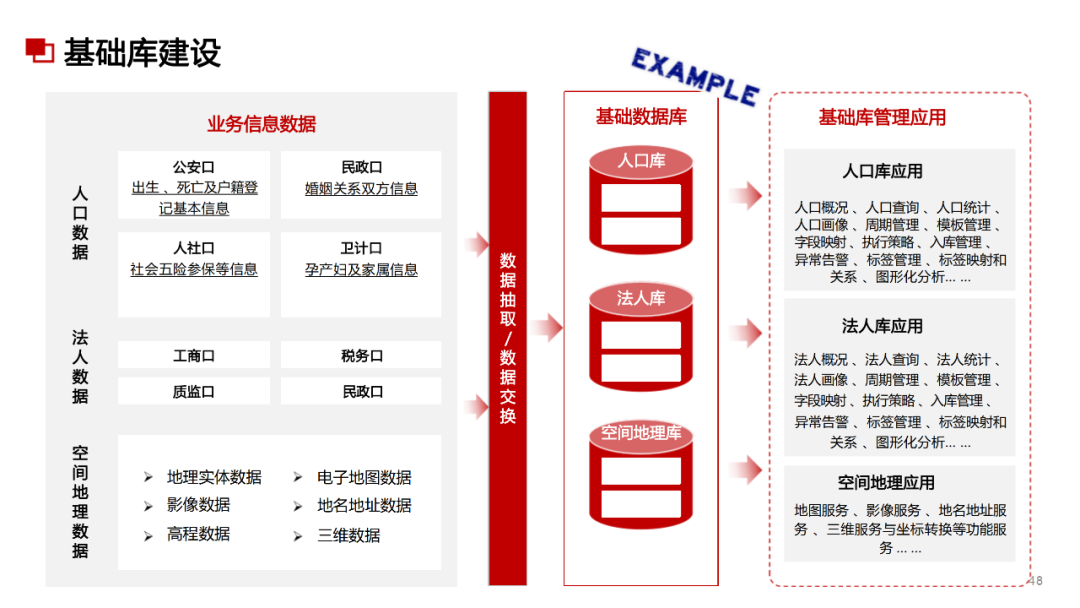

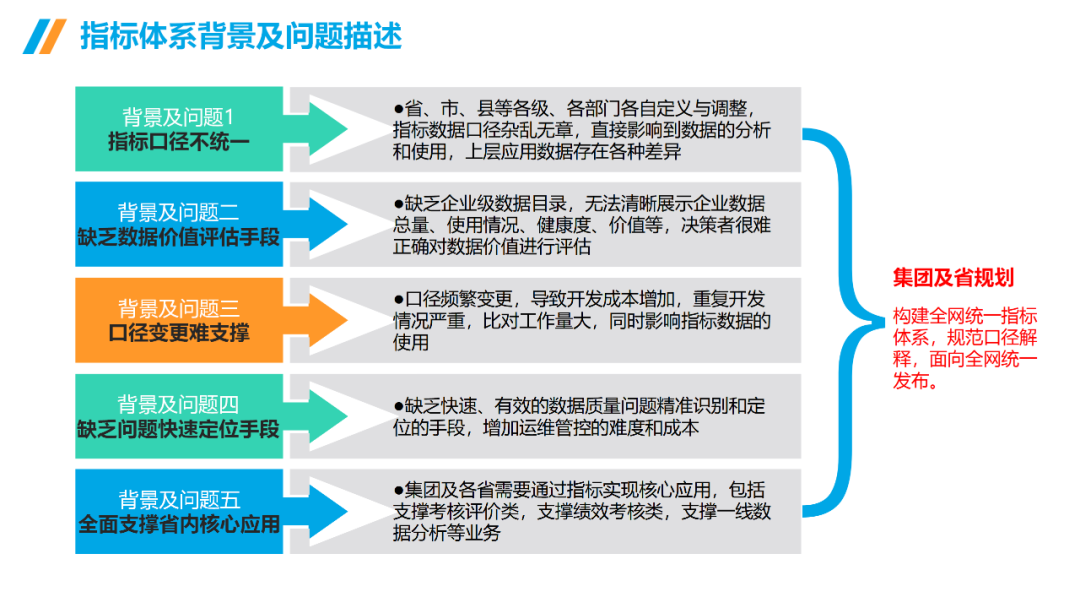
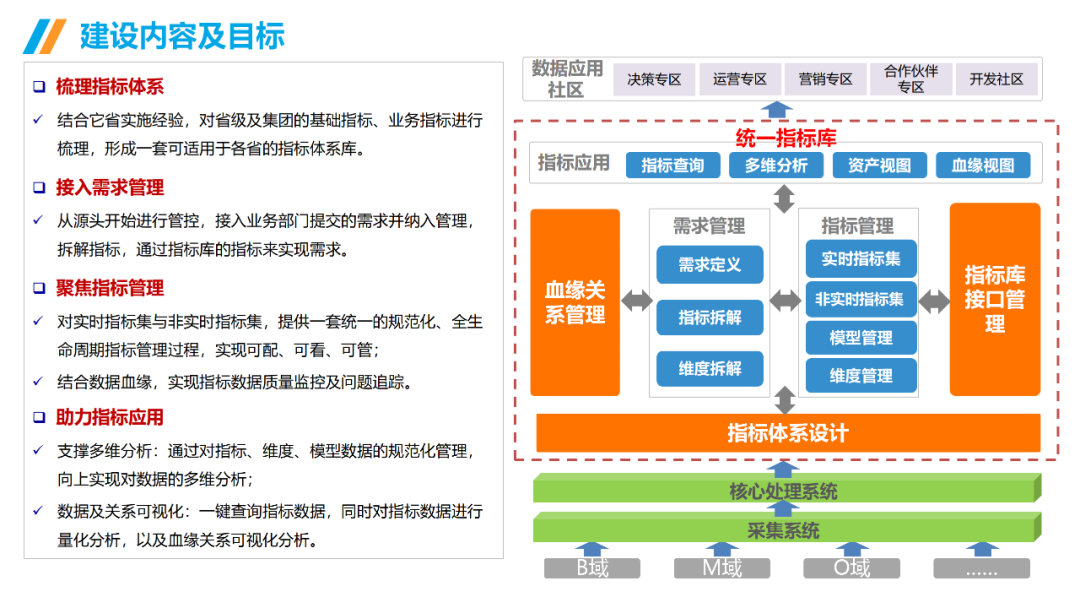

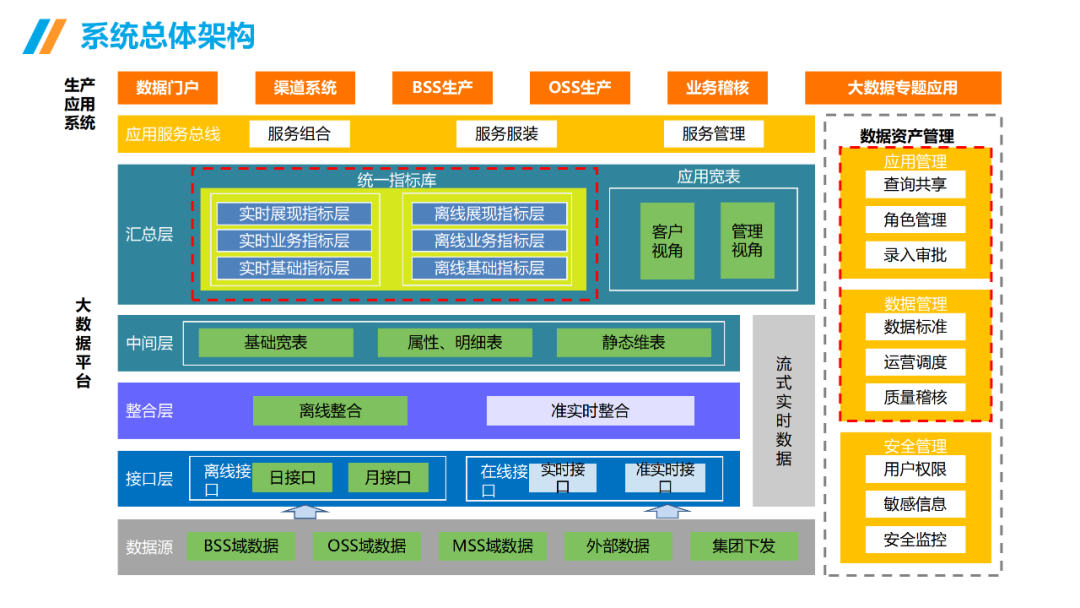
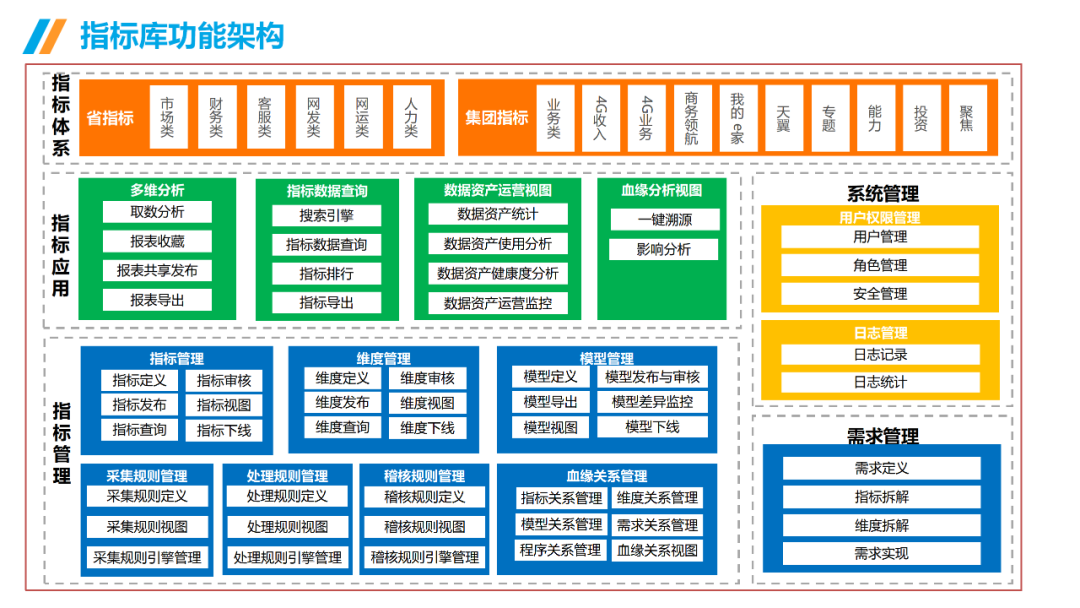
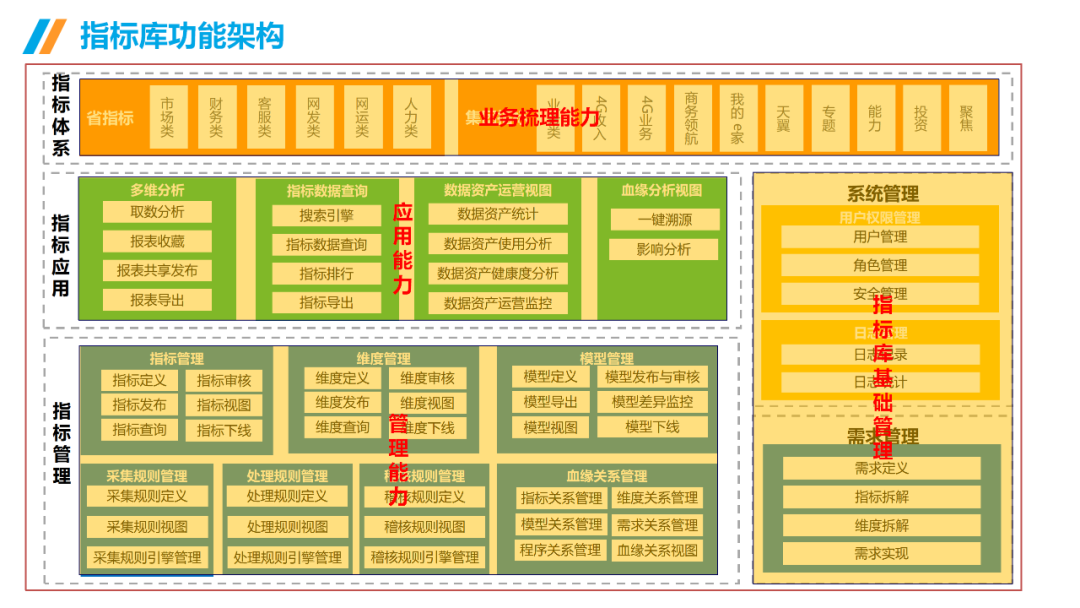

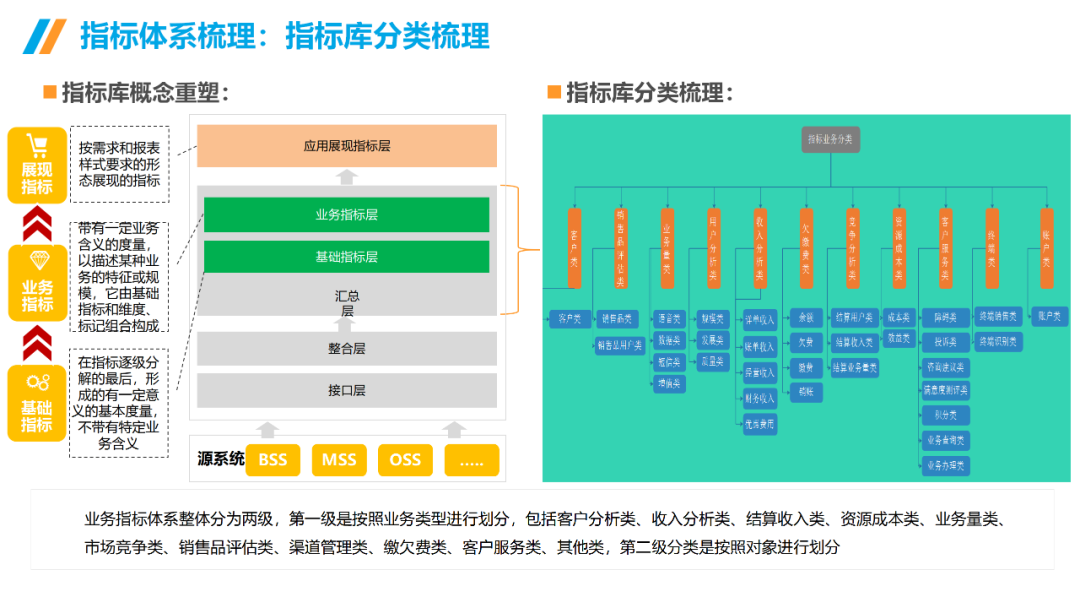

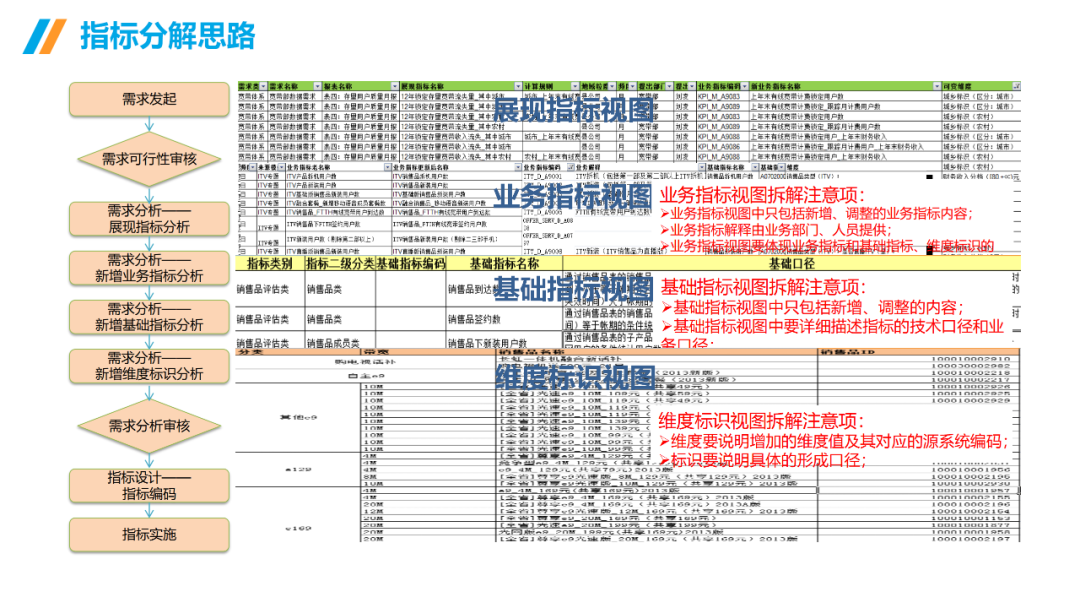
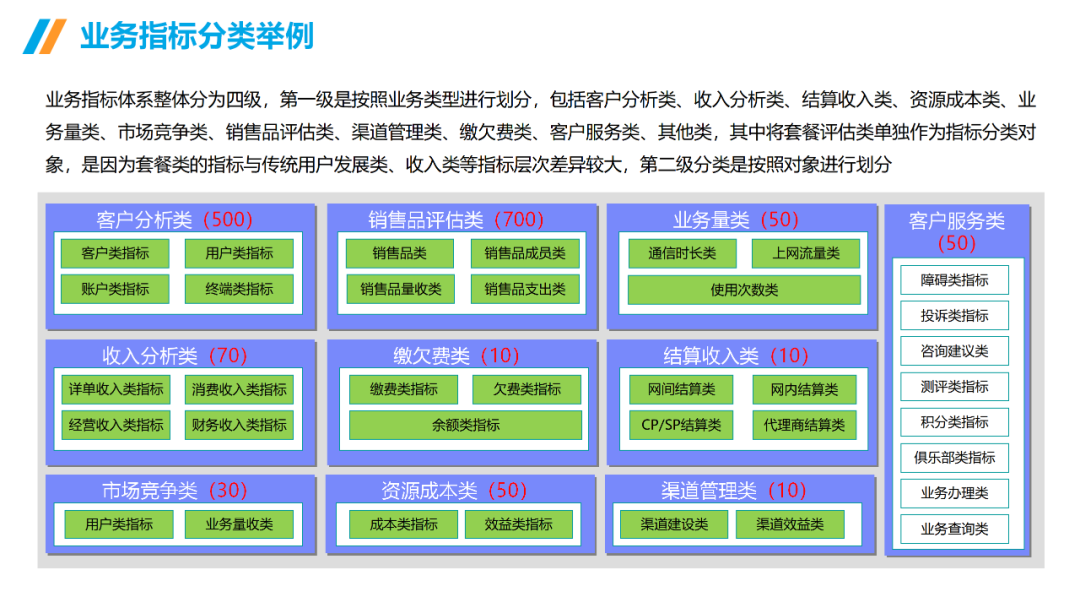

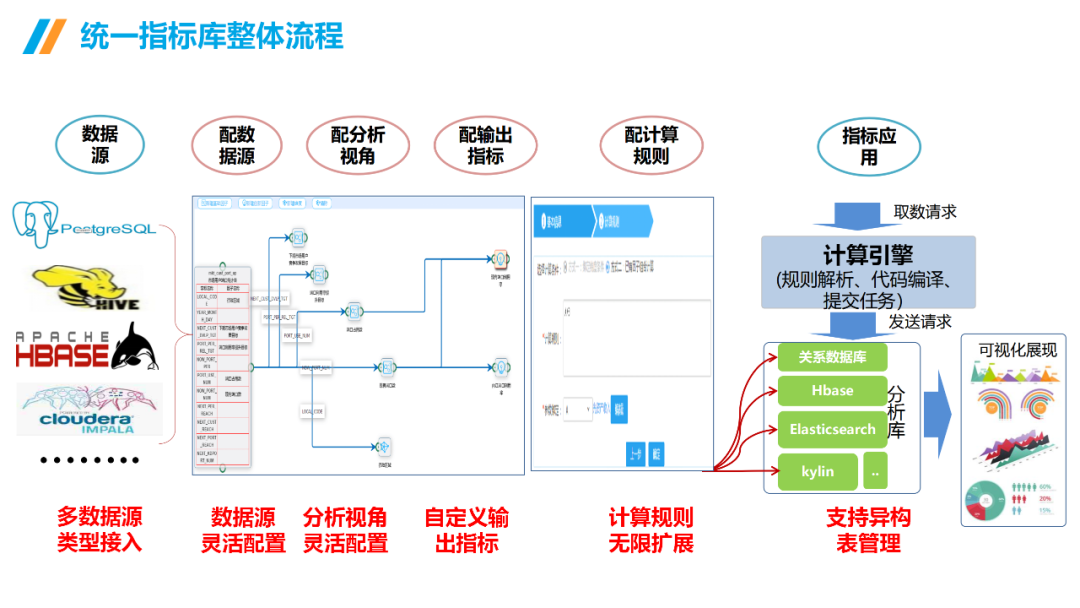
......(由于篇幅有限)
附3:《数据治理全攻略指南》
数据治理全攻略(119页 PPT).pptx
企业数据治理体系知识(26页 PPT).pptx
数据治理-组织架构(51页 PPT).pptx
数据治理知识培训(53页 PPT).pptx
数据治理(质量治理、安全治理、全生命周期治理、治理考核)33页.pptx
华为面向业务价值的数据治理实践(58页).pdf
数据治理解决方案与行业案例.pdf
【数据治理】企业数据治理价值解读白皮书.pdf
····







···
附4:数据资产入表知识地图

···
(进星球看高清版)
「完」
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
进星球获取更多~搜素关键词“数据资产”完整资料~
完
热文先推荐↓:
···
即可各种数据分析思维、工具、课程、书籍、项目、运营、产品相关结构化体系资料~
内容持续更新,期待你来


免责声明:本号所载内容为原创或整理于互联网公开资料,版权归原作者所有。文章仅供读者学习交流,不作任何商业用途。因部分内容无法确认真正来源,如有标错来源或涉及作品版权问题烦请告知,将及时处理,谢谢!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)