流计算概述
流计算
阅读资料:
PyFlink入门实践(一)-All You Need to Know About PyFlink - 知乎
目录
第一部分:“流计算”概念
1. 静态数据 vs 流数据:池塘 vs 河流
静态数据(池塘)
就像一个蓄水池,水已经放进去了,是静止的。不管你什么时候去舀一勺,它就在那,不会变。
流数据(河流)
就像一条奔腾的大河,水(数据)源源不断地流过来,无穷无尽。你没法把河水全装进桶里,只能一边流一边处理。
特征: 又急又多,杂乱无章(下雨天水就浑,来源多),顺序也不一定(上游漂下来的木头可能比下游的石头晚到)。
2. 核心技术:怎么把河水舀起来喝?(窗口与水位线)
因为河水是无限的,我们要算数据,必须把它“切开”。
窗口技术:切西瓜的刀
把无限的数据流切成一段一段有限的“块”,方便计算。
三种切法
|
窗口类型 |
通俗解释 |
适用场景 |
|
滑动窗口 |
就像一块可以前后滑动的“玻璃板”。 |
实时监控:比如监控服务器每秒的 CPU 负载。 |
|
时间盒 |
就像一个个大小固定的“水桶”。 |
定期报告:比如每小时生成一份销售额报表。 |
|
衰减窗口 |
就像一盒“冰激凌”,刚买的时候最好吃(权重高),放久了化掉了(权重低)。 |
推荐系统:给用户推荐商品时,最近浏览的商品权重更高。 |
(1)时间盒(翻页/Hopping)
像翻日历,翻过一页就不回头了。
比如:统计“9:00-9:05”的访问量,到点就关门结算。
(2)滑动窗口
像公交车每隔5分钟发一班,但每班车只管这5分钟内的乘客。
窗口之间有重叠,比如9:00-9:05,然后9:01-9:06。
适合做平滑统计。
(3)衰减窗口
像煮汤,刚放进去的料味道最浓,煮久了(旧数据)味道就淡了,权重降低。
越新的数据越重要。
|
特性 |
滑动窗口 (像滑动的玻璃板) |
时间盒 (像固定的水桶) |
|
更新频率 |
高 (比如每分钟) |
低 (比如每5分钟) |
|
数据重叠 |
有 (窗口之间有数据重复) |
无 (窗口之间互不干扰) |
|
实时性 |
强 (适合实时监控) |
弱 (适合定期报告) |
|
计算复杂度 |
高 |
低 |
水印/水位线:给迟到的乘客留门
网络是有延迟的!
比如9:05分的窗口已经关了,结果9:04分的一条数据因为堵车(网络延迟)9:06才到。算不算?
水印就是“宽容度”。
如果你设置水印是“5秒”,意思就是:“虽然理论上9:05关门,但我会等到9:10才真正锁门,给那些迟到的5秒钟数据留个机会。”
代码:
TUMBLE_START/END:翻页窗口的开始和结束时间。
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND:告诉系统,允许数据晚到5秒。
3. 流计算流程:一个完整的流水线
这就好比你在管理一个工厂的实时监控大屏:
数据实时采集(原料入库)
要快、要稳。
用工具(如 Kafka、Flume)把各地的传感器数据、用户下单行为抓过来。
架构: Agent(搬运工) -> Collector(中转站) -> Store(仓库)。
数据实时计算(加工处理)
这是流水线的核心(比如 Flink)。
原料进来,立马清洗、计算,比如算出“过去1分钟哪款产品最受欢迎”。
实时查询服务(成品出货)
计算好的结果不是这就完了,要直接推送到老板的大屏或者手机上,不需要老板问“现在卖了多少”,系统直接告诉他。
|
特性 |
传统数据处理系统 (离线计算) |
流处理系统 (实时计算) |
|
处理的数据 |
静态数据(存在数据库里的“死”数据) |
流数据(源源不断的“活”数据) |
|
获取的结果 |
过去的结果(昨天、上个月的报表) |
实时结果(此时此刻的状态) |
|
交互方式 |
主动查询(用户发出 SQL 查询) |
主动推送(结果更新后直接推给用户) |
第二部分:对比记忆表
|
维度 |
传统批处理 |
流计算 |
|
数据形象 |
静态池塘(存满再算) |
动态河流(来了就算) |
|
结果时效 |
“马后炮”(过去的结果) |
“此时此刻”(现在的结果) |
|
交互方式 |
人问系统答( Pull) |
算好了主动推给你 |
|
典型应用 |
月度财务报表、年度总结 |
实时股票大盘、双11战报大屏 |
第三部分:工具箱里的神兵利器(Flink 与生态)
Apache Flink:真正的“状态机”
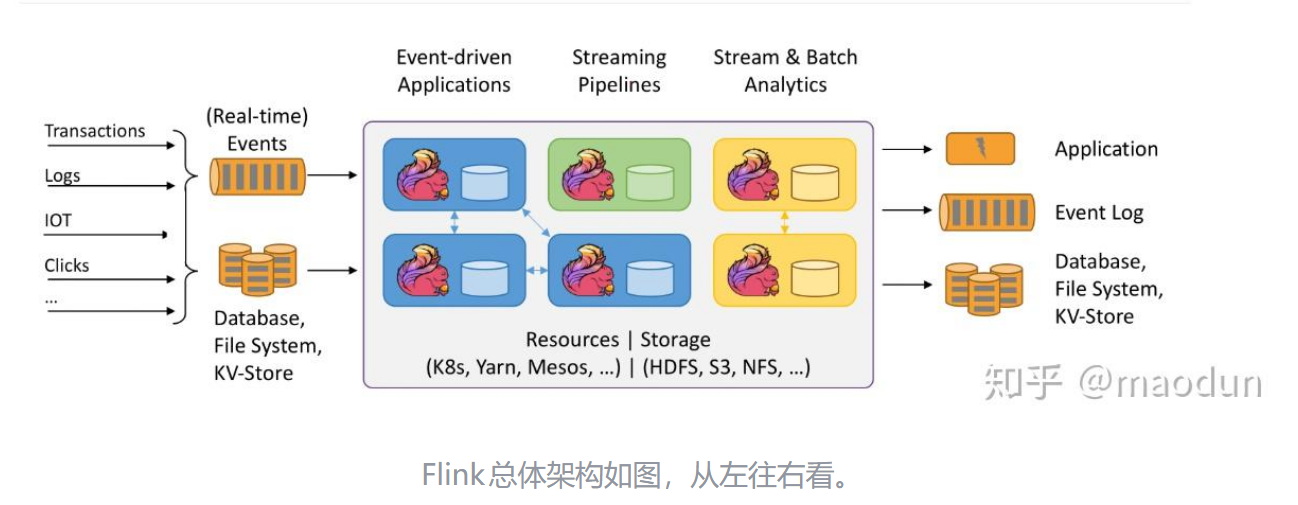
大数据界的“顶流”。
Hadoop 是老大哥(干重活),Spark 是快手(干批处理快),Flink 是专门处理超低延迟流数据的王者。
既能像 Spark 那样处理历史数据,更能毫秒级处理实时数据。
Flink就像一个智能工厂,数据是原料,算子是机器,状态是记性,JobManager是总指挥,TaskManager是工人。这个工厂最大的特点是来一个原料就马上加工,不攒着!
先搞懂Flink到底是什么
Apache Flink是一个分布式流处理框架,想象一个超级智能的实时数据处理工厂,工厂特点:
- 来一条数据,立马处理一条(来一条处理一条,不是攒一堆再处理)
- 可以搭很多条流水线一起工作(分布式)
- 用普通电脑就能搭建,不需要超级昂贵的服务器
数据流的两种类型
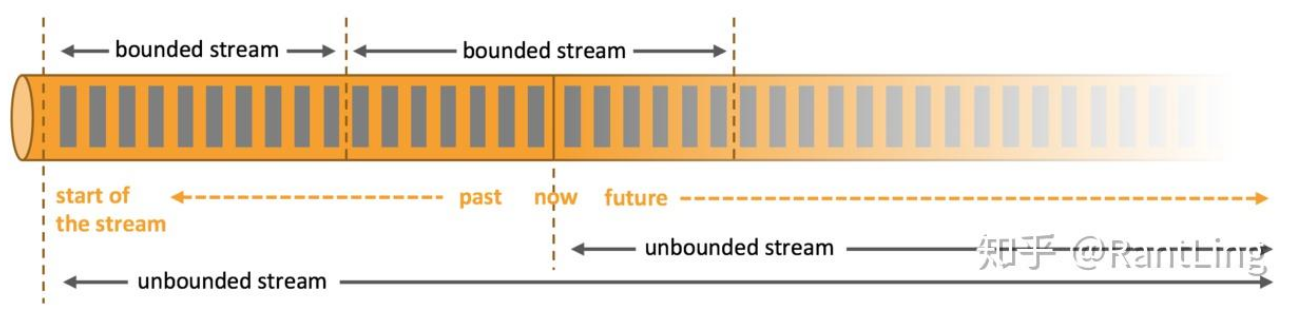
无界流
没有明确开始和结束的数据流,像自来水管的水流,拧开就一直流,不知道什么时候停
- 现实例子:微信消息、用户点击行为、服务器日志
- 处理方式:必须实时处理,来一条处理一条
有界流
有明确开始和结束的数据集,像一桶水,量是固定的
- 现实例子:今天一天的订单数据、一周的访问记录
- 处理方式:可以批量处理,也可以当流处理
Flink核心架构(两个关键角色)
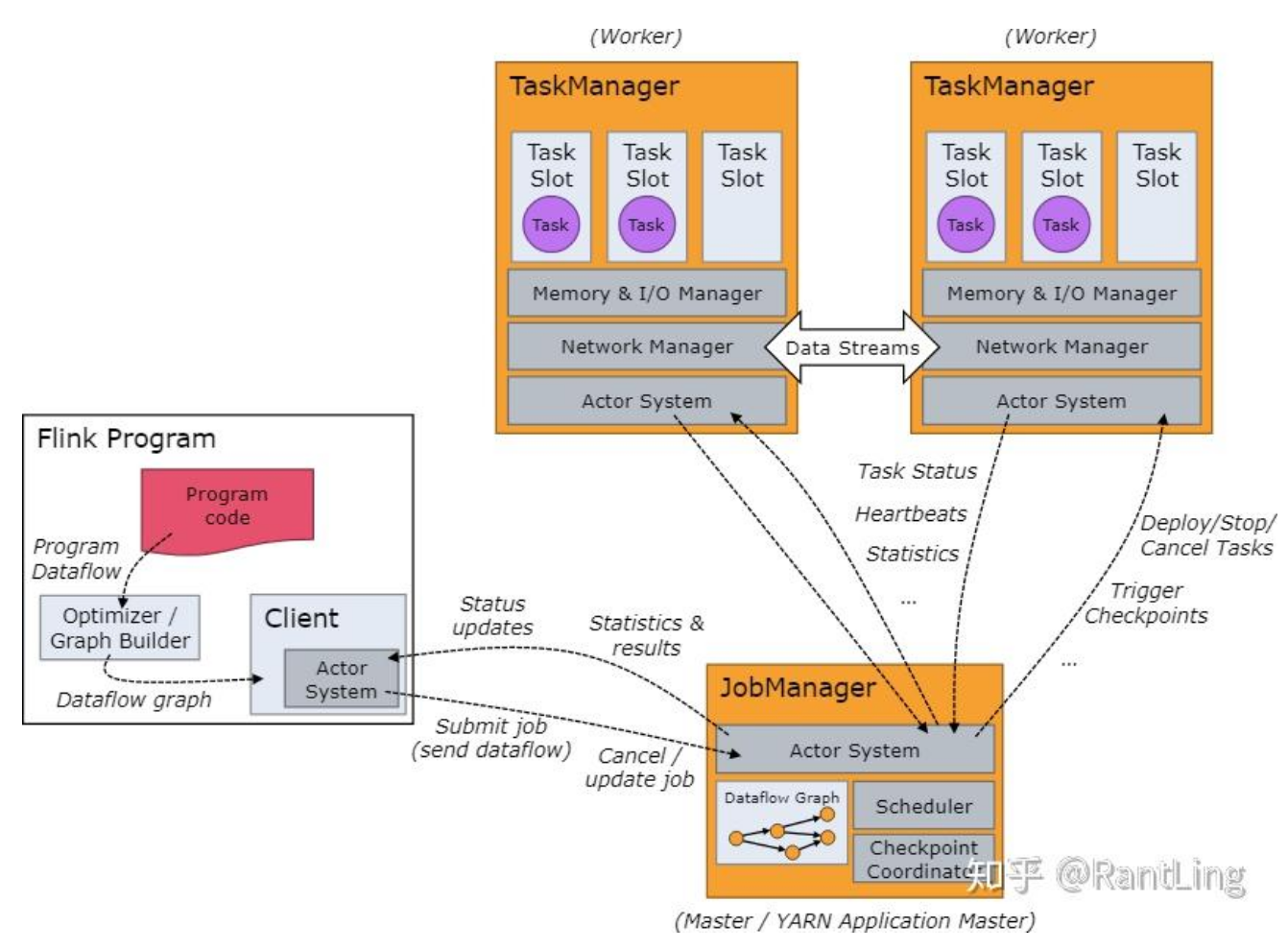
JobManager - 调度总指挥
负责任务调度、协调checkpoint和错误恢复——工厂总指挥
工作内容:
- 收到任务(比如"统计单词频率")
- 看看有哪些工人(TaskManager)空闲
- 分配任务给工人
- 监督工作进度
TaskManager——实际干活的
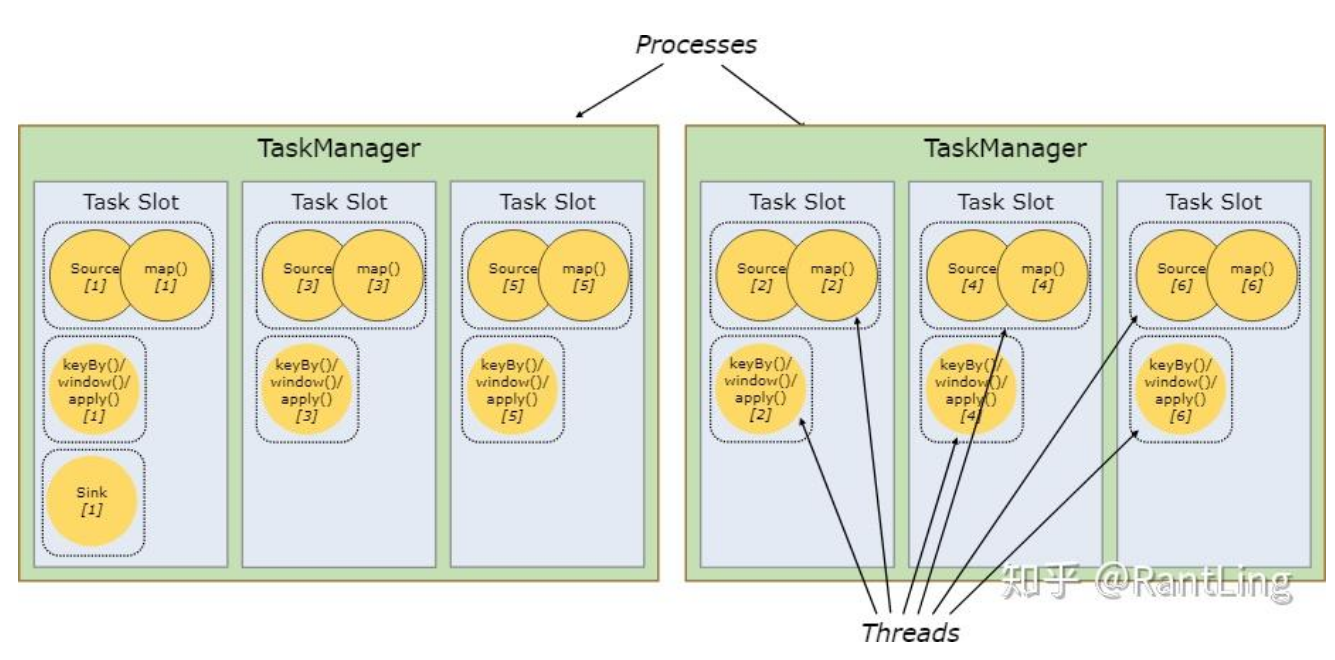
执行数据流task的进程——车间工人
特点:
- 每个工人有多个"工位"(slot)
- 一个slot可以干多种活(资源复用)
- 工人之间不抢资源,分工合作
程序四步走(像做一道菜)
第1步:准备厨房(获取执行环境)
val env = ExecutionEnvironment.getExecutionEnvironment准备厨房,告诉系统"我要开始做饭了"
第2步:买食材(添加数据源)
val text = env.readTextFile("/path/to/file")从超市买菜,也可以从菜园里摘(kafka、数据库等)
第3步:做菜(数据处理)
val counts = text
.flatMap { _.toLowerCase.split("\\W+") } // 洗菜切菜
.map { (_, 1) } // 每个菜装盘子
.groupBy(0) // 按种类分类
.sum(1) // 数一下每类有多少flatMap:把一大块东西切成小块
map:给每块东西贴标签
groupBy:把相同标签的放一起
sum:数数每组有几个
第4步:端上桌(数据输出)
counts.writeAsCsv(outputPath, "\n", " ")把做好的菜端到餐桌(存到文件、数据库、展示给用户)
状态管理(Flink的杀手锏)
- 状态是什么?
计算过程中产生的中间结果——记性
- 例子:
计数器:"我刚才数到100了,来一个新数据就是101"
滑动窗口:"最近5分钟的数据有这些..."
- 为什么状态很重要?
Flink提供了强大的状态管理机制——保证即使电脑突然死机,也不忘之前算的东西
- 技术实现:
定期把记性写到硬盘(checkpoint)
死机重启后,从硬盘读回记性
分层API(不同难度的工具)
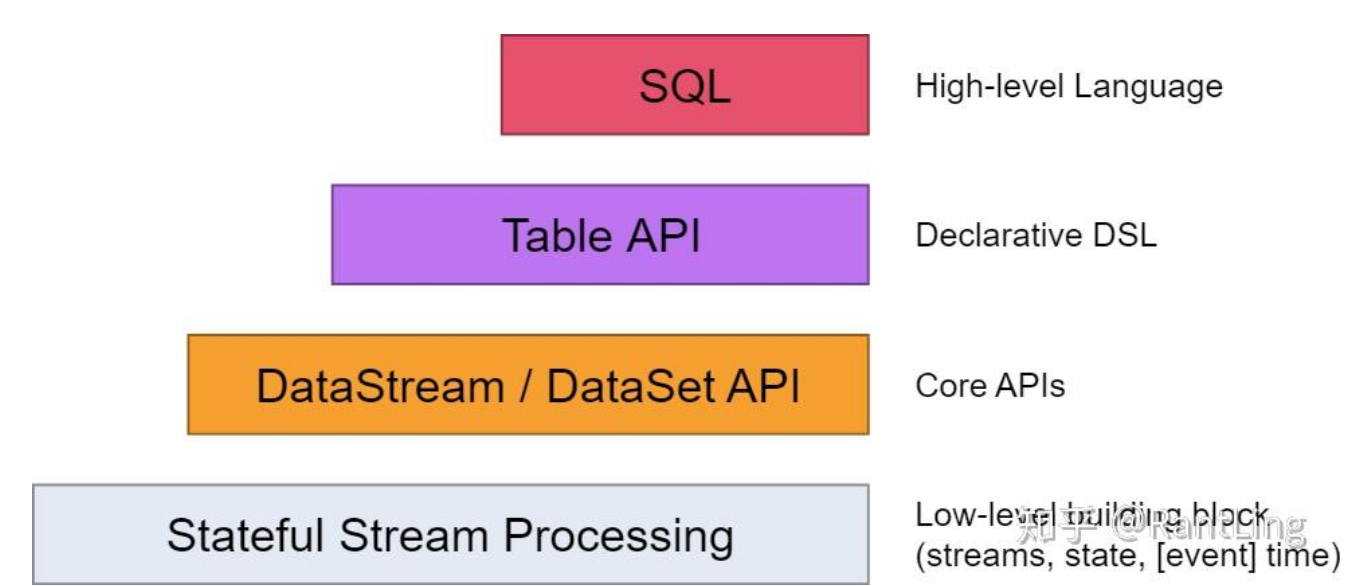
从难到易的4层:
-
ProcessFunction(最灵活,最难用)
就像自己造工具,什么都能做,但很累
-
DataStream/DataSet API(最常用)
像用现成的厨房工具,够用且好使
-
Table API & SQL(最简单)
就像点外卖,说"我要统计单词",不用自己动手
-
Python(对Python友好)
支持Python语言
部署模式(不同规模的工厂)
单机模式
单节点部署——一个人干活的小作坊
适用:学习测试
集群模式
分布式部署——很多工人合作的大工厂
适用:生产环境,处理大数据
Flink vs 其他框架(为什么选Flink)
|
维度 |
Spark Streaming (微批次) |
Flink (流处理) |
核心区别比喻 |
|
处理模式 |
攒一批再处理 |
来一条处理一条 |
🚌 公交车 vs. 🚕 出租车 |
|
核心痛点 |
延迟较高 |
低延迟 |
公交:就算车没坐满,也得等个几分钟才发。 |
|
对比框架 |
Storm |
Flink |
核心区别比喻 |
|
准确性与速度 |
速度快,但难保准确 |
又快又准 |
📦 快递小哥 vs. 📦 精品物流 |
实时统计词频
场景:从socket实时读取单词并统计
// 1. 准备环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 从socket获取数据(像从水龙头接水)
val stream = env.socketTextStream("192.168.1.102", 7777)
// 3. 处理数据
val counts = stream
.flatMap(_.split(" ")) // 切单词
.filter(_.nonEmpty) // 过滤空单词
.map((_, 1)) // (word, 1)
.keyBy(0) // 按单词分组
.sum(1) // 累加计数
// 4. 输出结果
counts.print()
// 5. 开始执行
env.execute()- 像接一根水管到socket
- 水流过来(数据)立刻处理
- 看到单词"hello"就记着:hello+1
- 又来一个"hello":hello现在是2
- 来个新单词"world":world+1
- 一直这样实时统计
核心优势总结
1. 真正的实时
低延迟、高吞吐
来数据马上就处理,不等不靠
2. 精确一次
exactly-once语义
数据不重复、不丢失、只处理一次
3. 状态管理强大
提供checkpoint和savepoint
记性好,死机也不忘之前算的
4. 灵活的API
分层API设计
从简单到复杂,想用哪个用哪个😊
Python + Flink (PyFlink)
- 场景1: 你熟悉 Python,直接用 Python 写数据分析逻辑,Flink 帮你变成分布式任务跑。
- 场景2: 平时玩数据用 Python(探索),正式上线用 Flink(生产),无缝衔接。
补充架构
Lambda 架构: 离线层 + 实时层,两套代码,维护麻烦(为了保准)。
Kappa 架构: 只要一个实时层,万物皆流,维护简单(现在的趋势)。
第四部分:大数据在现实世界里的“七十二变”
|
领域 |
实践应用 (正面影响) |
负面影响与挑战 (需要警惕) |
|
电商 |
个性化推荐:你在淘宝上看了一眼鞋子,下一秒首页就给你推荐了同款。这背后就是流计算在实时分析你的浏览轨迹。 |
算法诱导消费:大数据比你自己更了解你,它会精准地“算计”你,让你不停地买不需要的东西。 |
|
金融 |
贷前风控:你申请贷款时,系统会实时整合你的电商消费、社交行为等 2000+ 个数据点,瞬间给出一个信用分,决定是否放款。 |
过度采集数据:很多 App 会索要与功能无关的权限(比如通讯录、位置),这些数据一旦泄露,后果不堪设想。 |
|
体育 |
VR 训练:运动员戴上 VR 眼镜,置身于真实比赛场景中。系统会实时捕捉他们的动作数据,分析技术动作的优劣,帮助他们改进训练。 |
算法歧视:如果训练数据本身有偏见(比如某些群体的样本少),算法可能会“继承”甚至“放大”这些偏见,导致不公平的结果。 |
过度采集
就像进超市被全身上下扫描,为了卖你瓶牛奶知道了你的身高体重。
风险: 隐私泄露,数据被卖。
算法歧视
AI 是个复读机,它学历史数据。
如果历史招聘数据里男性高管多,它可能就认为“男性更适合当高管”,从而歧视女性求职者。
消费主义陷阱
大数据比你自己还了解你的弱点。
算准了你晚上情绪容易脆弱,专门在那个时候推送“购物车降价”,诱导你冲动消费。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 33
33 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)