A Generalized Algorithm for Multi-Objective Reinforcement Learning and Policy Adaptation复现部分过程记录
论文链接 :https://arxiv.org/pdf/1908.08342
论文代码:https://github.com/RunzheYang/MORL
博客https://blog.csdn.net/weixin_56760882/article/details/145572826以深海宝藏环境(DST 域)举例展示复现结果,本文以FTN 域(水果树导航)为例展示复现过程。
复现过程中,git原论文代码,在笔记本上(RTX 4060)配置环境,并运行。
该项目是通用多目标强化学习算法,核心是envelope MOQ-learning,落地在4 类环境(2 个合成环境 + 2 个真实环境):
两个合成环境:
- Deep Sea Treasure (DST):深海寻宝。
- Fruit Tree Navigation (FTN):果树导航。
两个复杂真实环境:
- Task-Oriented Dialog Policy Learning(Dialog):面向任务的对话策略学习。
- SuperMario Game (SuperMario):超级马里奥游戏。
进入目录synthetic:
|
文件路径 |
核心作用 |
需理解的关键内容 |
|
synthetic/train.py |
合成环境训练入口 |
命令行参数解析(如 指定 FTN 环境、 指定核心算法)、训练循环逻辑 |
|
synthetic/crl/envelope/meta.py |
核心算法实现 |
envelope MOQ-learning 的核心逻辑(多目标奖励加权、策略更新、经验回放) |
|
|
网络结构 |
线性 / 非线性网络配置(适配不同合成环境的状态 / 动作空间) |
|
|
合成环境定义 |
DST/FTN 环境的状态、动作、多目标奖励函数定义(理解环境规则是复现的前提) |
一、环境搭建——基础依赖安装
原代码依赖的 torch 0.4.0(2018 年版本)对 RTX40 系列显卡的 CUDA 架构支持不足(RTX4060 是 Ada Lovelace 架构,sm_89,而 torch 0.4.0 最高仅支持到 sm_75/Turing 架构)。
为适配RTX4060,升级pytorch:
# 1. 创建新环境(指定Python3.6.15)
conda create -n morl-synthetic python=3.6.15 -y
# 2. 激活新环境
conda activate morl-synthetic
# 3. 安装Python3.6兼容的核心依赖(适配RTX4060)
# 先装numpy/scipy(Python3.6最高兼容版)
pip install numpy==1.19.5 scipy==1.5.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 4. 安装torch 1.10.2+cu113(Python3.6唯一支持的高版本,适配RTX4060)
pip install torch==1.10.2+cu113 torchvision==0.11.3+cu113 torchaudio==0.10.2+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html -i https://pypi.tuna.tsinghua.edu.cn/simple验证 PyTorch+CUDA 是否适配 RTX4060:
python -c "import torch;
print('PyTorch版本:', torch.__version__);
print('CUDA版本:', torch.version.cuda);
print('CUDA是否可用:', torch.cuda.is_available());
print('GPU名称:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else '未识别')"安装其他辅助依赖:
# 其他辅助依赖
pip install termcolor==1.1.0 torchfile==0.1.0 Pillow==8.4.0 six==1.16.0 -i https://pypi.tuna.tsinghua.edu.cn/simple安装visdom:
(之所以着重单列出来,是因为visdom 启动时会尝试从外网下载前端静态资源(js/css),但网络总是超时 / 访问失败。最后选择离线下载以及编译)
1.下载 visdom 离线资源包:
cd D:\ProgramData\论文复现\FirRL
# 克隆 visdom 仓库
git clone https://github.com/fossasia/visdom.git【我自己直接下载了zip】
#进入解压的visdom-master目录
cd D:\ProgramData\论文复现\FirRL\visdom-master
# 切换yarn镜像源(解决国内下载依赖慢的问题)
yarn config set registry https://registry.npmmirror.com
# 设置electron镜像源
yarn config set electron_mirror https://npmmirror.com/mirrors/electron/
# 安装Visdom前端编译依赖(耗时3-8分钟,无Error即成功)跳过可选依赖(electron属于可选依赖)
yarn install --ignore-optional
# 编译生成static文件夹(1-2分钟,看到Compiled successfully即成功)
yarn run build
# 查找visdom安装目录(复制输出的路径)
python -c "import visdom; print(visdom.__path__[0])"
输出:D:\Anaconda\envs\morl-synthetic\lib\site-packages\visdom
# 复制编译好的文件夹
xcopy /E /I /Y D:\ProgramData\论文复现\FirRL\visdom-master\py\visdom\static D:\Anaconda\envs\morl-synthetic\lib\site-packages\visdom\static其中:【/E:递归复制所有子目录和文件;】
【/I:如果目标不存在,视为创建目录。】注意地址替换成自己的地址。
该步骤会生成static,原先没有编译前,直接在visdom-master中是没有的。
2.解压 static.zip 到 visdom 安装目录的 static 文件夹:
路径:D:\Anaconda\envs\morl-synthetic\Lib\site-packages\visdom\static
(若没有 static 文件夹,先创建)3.修复 visdom 启动代码的异常处理:
修改D:\Anaconda\envs\morl-synthetic\Lib\site-packages\visdom\server.py第671-673行:
# 原错误代码
# logging.error('Error {} while downloading {}'.format(exc.code, key))
# 替换为
if hasattr(exc, 'code'):
logging.error('Error {} while downloading {}'.format(exc.code, key))
else:
logging.error('Error while downloading {}: {}'.format(key, exc))
解决目录日志问题:
打开 D:\ProgramData\论文复现\FirRL\synthetic\utils\monitor.py,找到init_log函数,添加 1 行创建目录的代码:
def init_log(self, save_path, name):
# 新增这1行(解决FileNotFoundError,不改动论文原逻辑)
import os; os.makedirs(save_path, exist_ok=True)
# 论文原代码保留不动
self.log_file = open("{}{}.log".format(save_path, name), 'w')
4.跳过资源下载启动 visdom:
打开 D:\Anaconda\envs\morl-synthetic\lib\site-packages\visdom\server.py,找到download_scripts()函数,替换整个函数内容:
def download_scripts():
"""
重写函数:跳过所有外网资源下载,直接使用本地static文件夹
"""
import os
# 定义本地static文件夹路径(和你复制的路径一致)
static_dir = os.path.join(os.path.dirname(__file__), 'static')
# 检查本地static文件是否存在(确保你复制的文件有效)
if os.path.exists(os.path.join(static_dir, 'js', 'main.js')):
print("检测到本地static文件夹,跳过外网资源下载!")
return
# 若本地无文件,仅打印提示(不再报错)
print("本地static文件夹缺失,建议检查复制路径!")
return保持morl-synthetic环境激活,启动Visdom(新开一个PowerShell窗口执行)
python -m visdom.server
# 成功启动会看到:It's Alive! 且提示可访问http://localhost:8097
成功后的输出:
Checking for scripts.
It's Alive!
INFO:root:Application Started
You can navigate to http://localhost:8097二、模型训练
FTN 域(水果树导航):
是一个树形导航游戏——agent(智能体)从树根出发,每一步选择分支,目标是收集 6 种水果(多目标),走到树叶(终点)结束一轮;日志里的步数、累计步数、动作、奖励列表就是 agent 在这个树形场景里的行走记录,True表示走到了树叶(本轮结束)。
保持morl-synthetic环境激活
先进入synthetic目录
cd D:\ProgramData\论文复现\FirRL\synthetic运行代码:
python train.py --env-name dst --method crl-envelope --model linear --gamma 0.99 `
>> --mem-size 4000 --batch-size 256 --lr 1e-3 --epsilon 0.5 --epsilon-decay `
>> --weight-num 32 --episode-num 2000 --optimizer Adam --save crl/envelope/saved/ `
>> --log crl/envelope/logs/ --update-freq 100 --beta 0.96 --name s3_r9 `
>> 2>&1 | Tee-Object -FilePath "crl/envelope/logs/training_s3_r9_$timestamp.log"训练过程与结果:

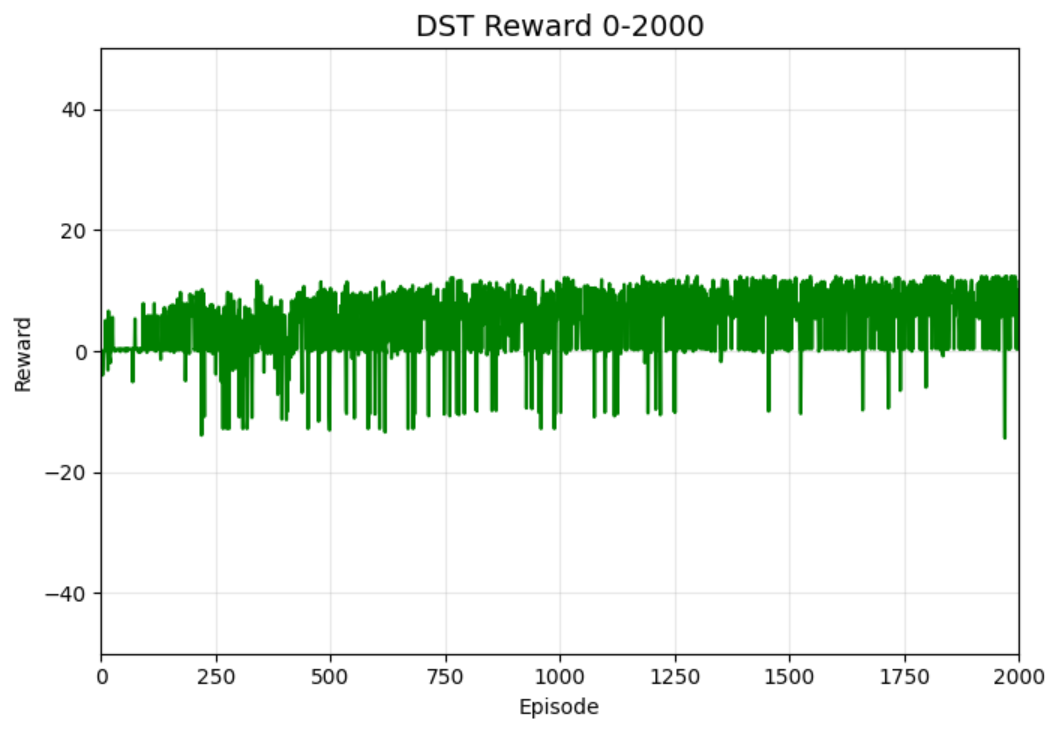
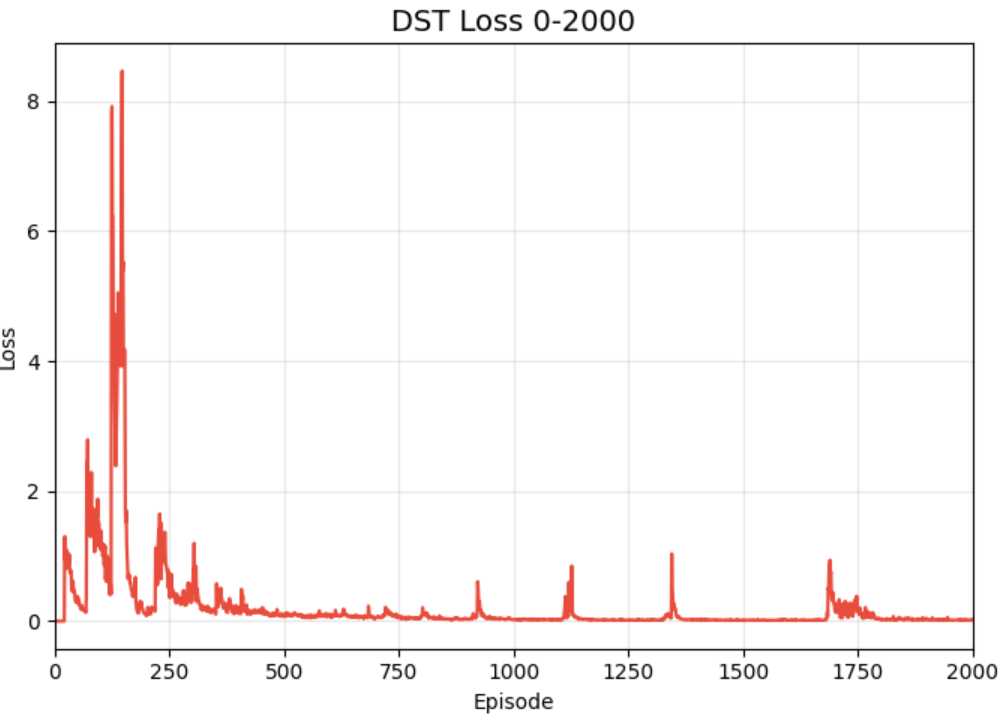
三、评估
评估代码:
$timestamp = Get-Date -Format "yyyyMMdd_HHmmss"; python test/eval_dst.py --env-name dst --method crl-envelope --model linear --gamma 0.99 --save crl/envelope/saved/ --pltpareto --name s3_r9 2>&1 | Tee-Object -FilePath "crl/envelope/logs/eval_s3_r9_$timestamp.log"结果:

policy-0.936:策略 F1 分数(衡量模型生成的策略接近最优解的程度),正常范围 0.85~0.98;prediction-0.945:预测 F1 分数(衡量模型对收益 / 代价的预测准确度);这两个指标远高于阈值(通常 F1>0.85 即达标),说明训练的s3_r9模型在 DST 环境下效果优异。
深海宝藏(DST)环境下多目标强化学习(MORL)的 Pareto 前沿评估图:
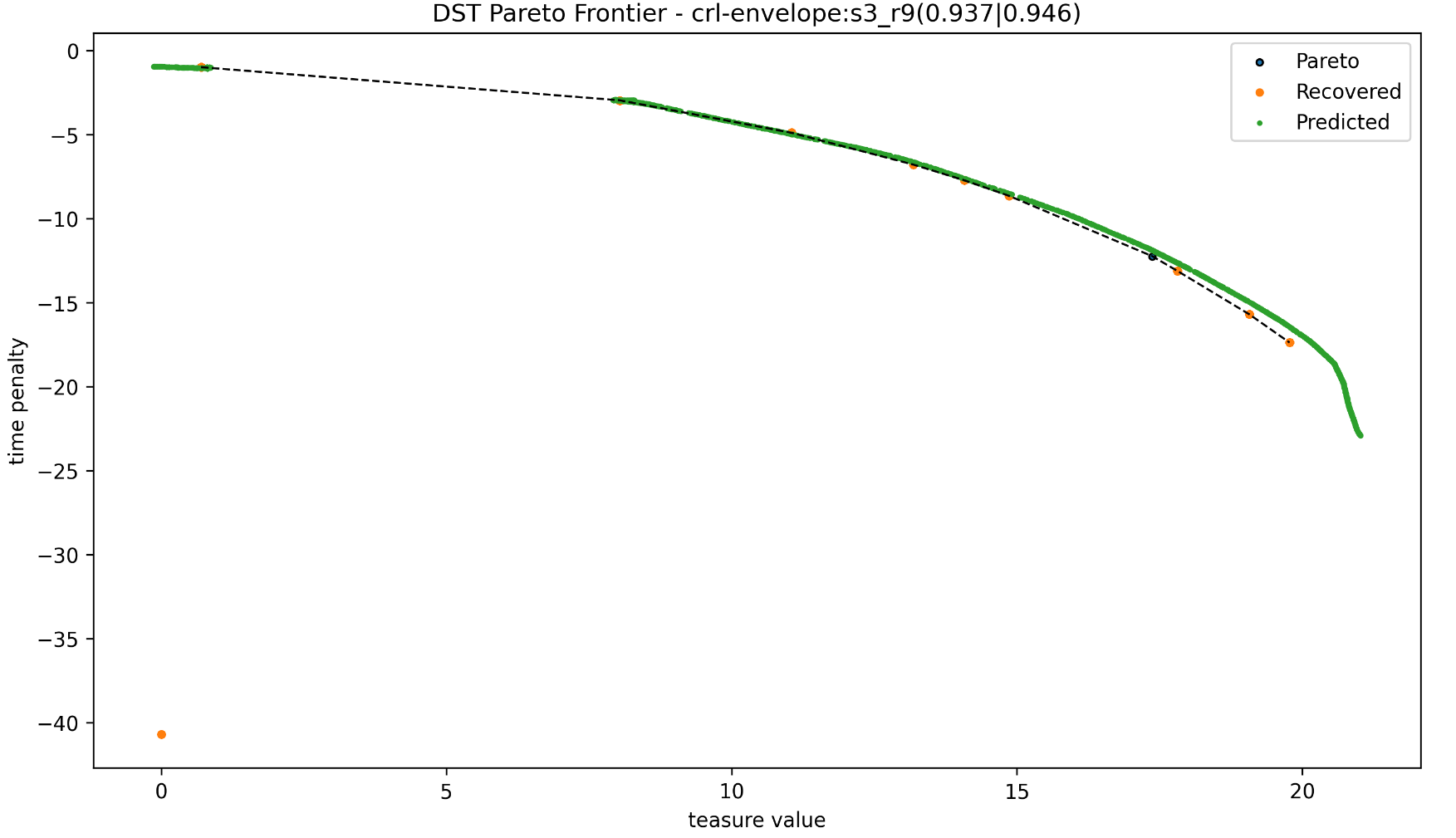
|
元素 |
含义 |
|
X 轴 |
宝藏价值,越大表示获得的宝藏越多(目标 1)。 |
|
Y 轴 |
时间惩罚(负值),越负表示消耗的时间越多 / 惩罚越大(目标 2)。 |
|
黑色虚线 + 黑点 |
理论最优 Pareto 前沿(真实值),是算法需要逼近的目标。 |
|
橙色点 |
策略实际执行得到的解(通过 agent.act 执行策略采样得到)。 |
|
绿色点 / 线 |
模型直接预测的解(通过 agent.predict 输出的 HQ 值)。 |
绿色(Predicted)和橙色(Recovered)点整体紧密贴合黑色虚线(理论 Pareto),说明:
- 模型预测的 Pareto 解(绿色)几乎和理论最优一致;
- 策略实际执行的解(橙色)也高度匹配理论前沿,算法学到的策略能有效复现最优权衡。
四、高版本 PyTorch 适配注意事项(避免报错)
原代码基于 PyTorch 0.4.0,高版本需微调:
1. Tensor 数据类型兼容
找到synthetic/train.py/roijers_train.py中类似代码:
# 原代码(0.4.0)
FloatTensor = torch.cuda.FloatTensor if use_cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if use_cuda else torch.LongTensor修改为(适配 1.0+):
# 适配PyTorch 1.10
FloatTensor = torch.cuda.FloatTensor if use_cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if use_cuda else torch.LongTensor
# 新增:修复高版本Tensor赋值警告
torch.set_default_tensor_type(FloatTensor)2. data.cpu()改为cpu().data(部分文件)
act_1 = act_1.data.cpu()可能触发警告
原代码基于 PyTorch 0.4.0,高版本需微调train.py中 Tensor 操作:
操作文件:D:\ProgramData\论文复现\FirRL\synthetic\train.py
找到以下代码:
if args.method == "crl-naive":
act_1 = act_1.data.cpu()
act_2 = act_2.data.cpu()
elif args.method == "crl-envelope":
act_1 = probe.dot(act_1.data)
act_2 = probe.dot(act_2.data)
elif args.method == "crl-energy":
act_1 = probe.dot(act_1.data)
act_2 = probe.dot(act_2.data)修改为(适配 PyTorch 1.0+):
if args.method == "crl-naive":
act_1 = act_1.cpu().data # 调换cpu()和data顺序
act_2 = act_2.cpu().data
elif args.method == "crl-envelope":
act_1 = probe.dot(act_1.cpu().data) # 新增cpu()避免CUDA Tensor报错
act_2 = probe.dot(act_2.cpu().data)
elif args.method == "crl-energy":
act_1 = probe.dot(act_1.cpu().data)
act_2 = probe.dot(act_2.cpu().data)在合成环境中,使用了论文中推荐的参数训练,实现以上可收敛效果。对源代码修改很少,主要还是花费在配置环境上。使用--episode-num 2000 训练时间在3-4小时左右(暂时没有运行5000的)。
另:正常代码输出的log文件并没有保存终端中输出的文件,需要单独存储,然后利用这些数据进行分析和画图,这样较为直观。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)