图像处理与分类那些事儿:Matlab实践
Matlab代码模板,图像处理,色彩补偿,色彩平衡,显示连通分量数量,自动阈值分割图像,人脸数据集的主成分分析,利用最小距离分类器分类3种植物,
在图像处理的世界里,Matlab是一款强大且好用的工具。今天就来聊聊图像处理过程中常见的几个任务,包括色彩补偿、自动阈值分割,以及基于人脸数据集的主成分分析和植物分类等有趣的操作,还会附上Matlab代码模板。
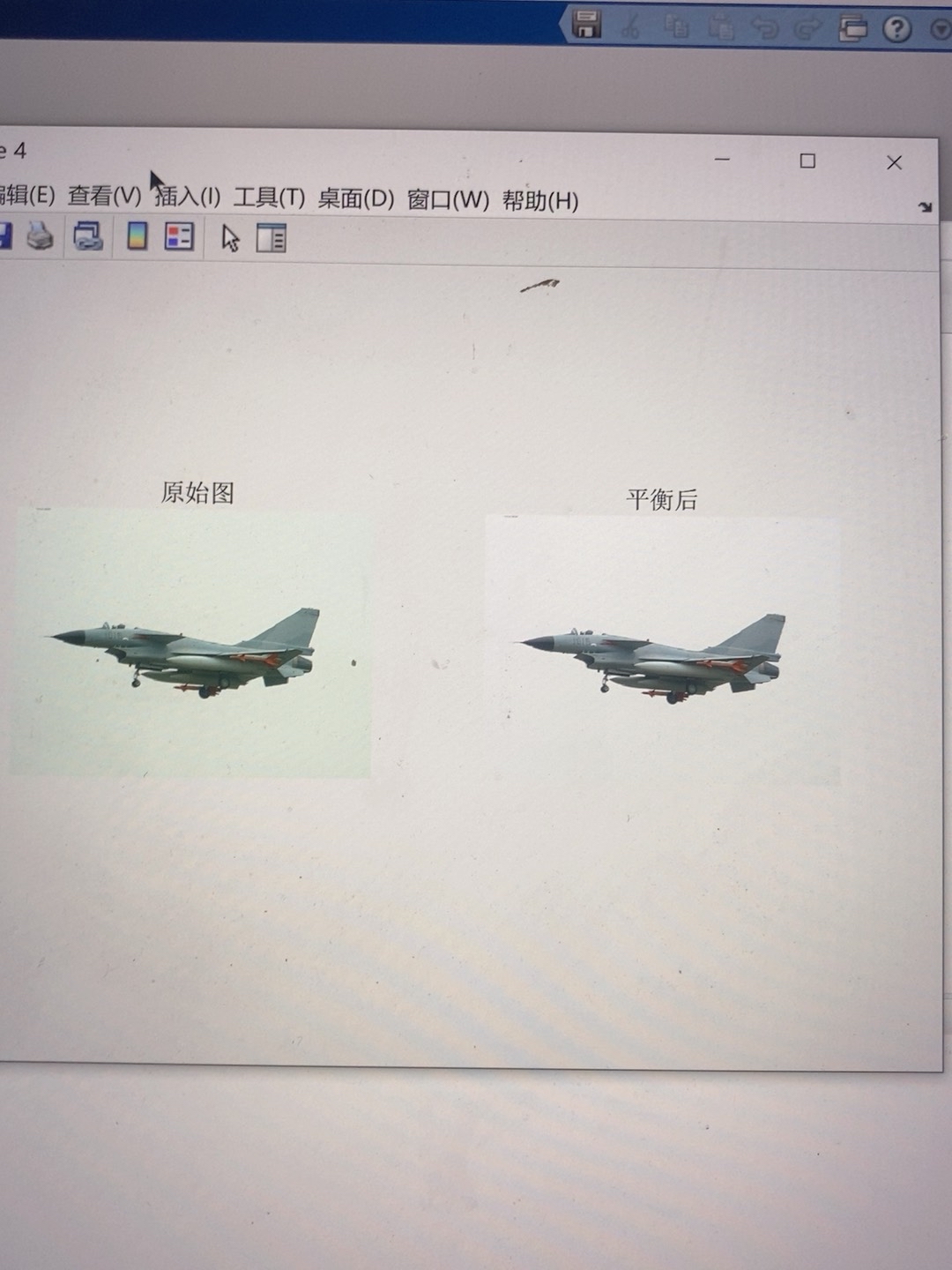
色彩补偿与色彩平衡
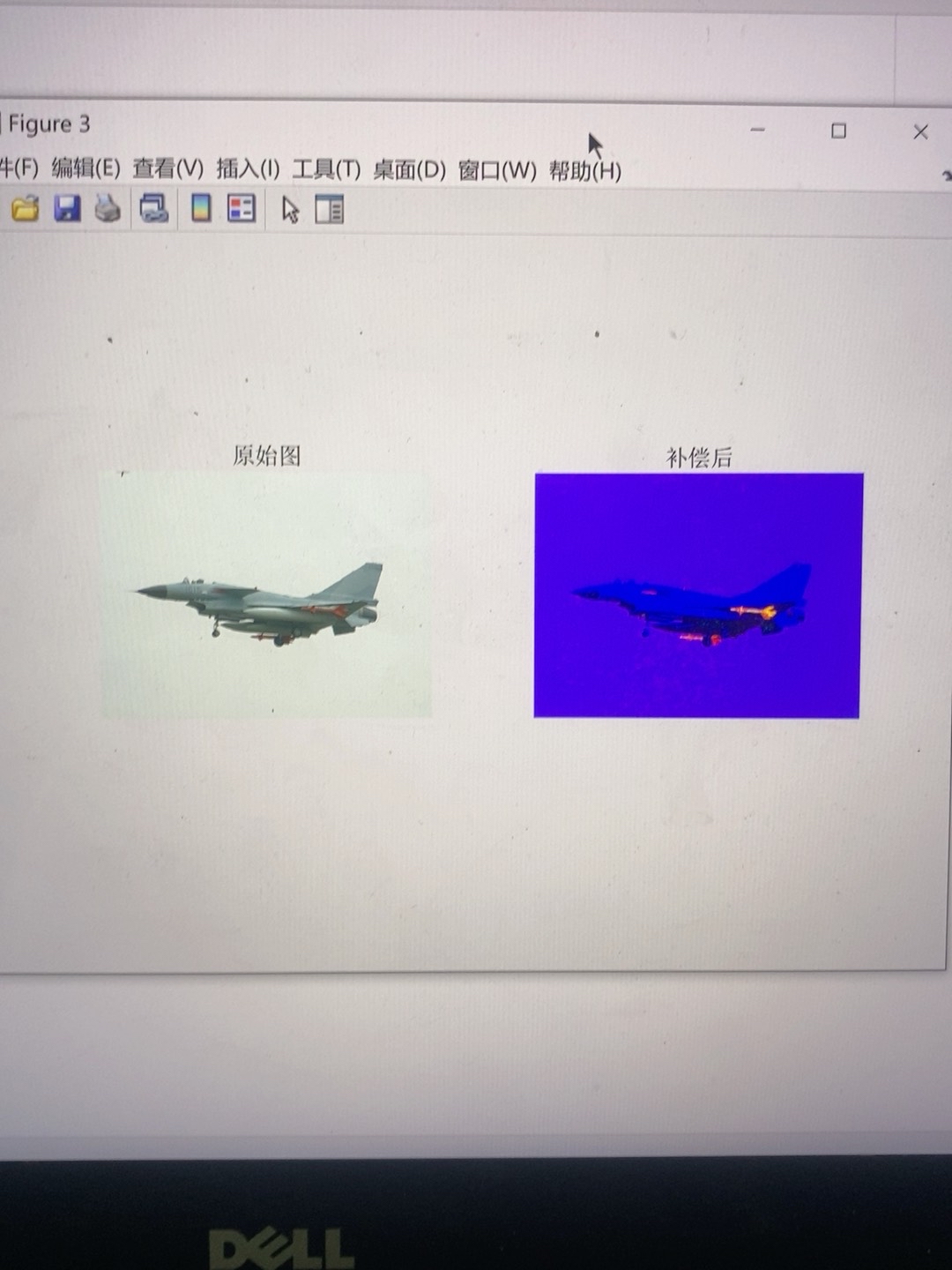
色彩补偿和平衡对于提升图像质量至关重要。比如说,在一些拍摄场景中,由于光线条件不理想,图像可能会偏色。我们可以通过Matlab代码来调整色彩。
% 读取图像
img = imread('your_image.jpg');
% 将图像转换到Lab颜色空间,在这个空间中对亮度和颜色分开处理更方便
lab_img = rgb2lab(img);
L = lab_img(:, :, 1);
a = lab_img(:, :, 2);
b = lab_img(:, :, 3);
% 对a和b通道进行直方图均衡化来调整颜色
a_eq = histeq(a);
b_eq = histeq(b);
% 重构Lab图像
lab_img_eq = cat(3, L, a_eq, b_eq);
% 转换回RGB空间显示
rgb_img_eq = lab2rgb(lab_img_eq);
imshow(rgb_img_eq);代码分析:首先我们读取图像,接着将RGB图像转换到Lab颜色空间。Lab空间将亮度(L)与颜色信息(a和b)分离开。通过对a和b通道进行直方图均衡化,增强了颜色的对比度和均衡性,最后再转换回RGB空间并显示调整后的图像。
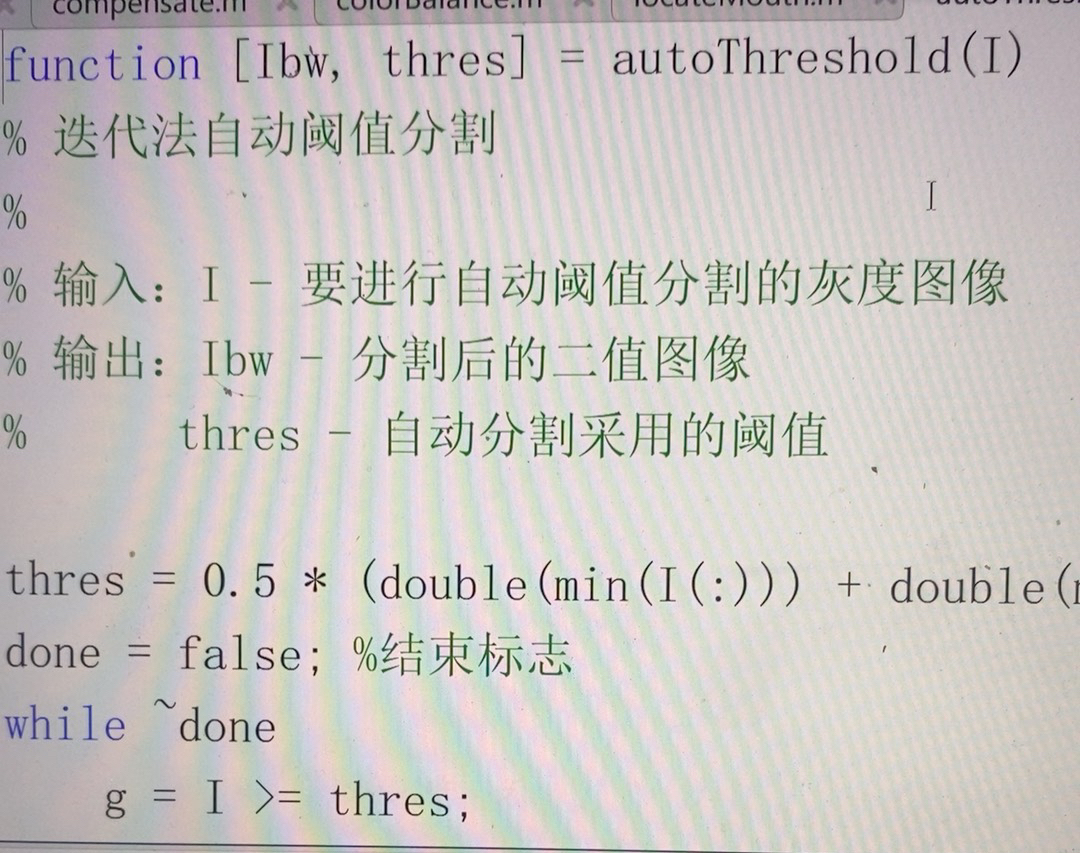
自动阈值分割图像
自动阈值分割可以将图像中的前景和背景分离。Matlab提供了方便的函数来实现这一功能。
% 读取灰度图像
gray_img = imread('gray_image.jpg');
% 使用自动阈值方法(这里用Otsu法)
level = graythresh(gray_img);
bw_img = imbinarize(gray_img, level);
imshow(bw_img);代码分析:我们先读取灰度图像,graythresh函数使用Otsu算法自动计算出一个合适的阈值。imbinarize函数利用这个阈值将灰度图像转换为二值图像,前景和背景就清晰地分开了,便于后续的图像处理操作,比如计算连通分量数量。
显示连通分量数量
在二值图像基础上,我们可以计算并显示连通分量的数量。
% 假设已经有二值图像bw_img
[labeled_img, num_components] = bwlabel(bw_img);
disp(['连通分量数量为: ', num2str(num_components)]);
imshow(labeled_img, []);代码分析:bwlabel函数标记二值图像中的连通区域,返回标记后的图像labeledimg以及连通分量的数量numcomponents。我们使用disp函数显示连通分量的数量,同时用imshow展示标记后的图像,不同的连通区域会以不同的颜色显示。
人脸数据集的主成分分析
主成分分析(PCA)是一种常用的数据降维技术,在处理人脸数据集时非常有用。
% 假设已经有人脸图像数据矩阵X,每一行是一张图像的特征向量
% 计算均值脸
mean_face = mean(X);
% 数据中心化
X_centered = bsxfun(@minus, X, mean_face);
% 计算协方差矩阵
covariance_matrix = cov(X_centered);
% 计算特征值和特征向量
[eigenvectors, eigenvalues] = eig(covariance_matrix);
% 对特征值按降序排序
[eigenvalues, sorted_indices] = sort(diag(eigenvalues), 'descend');
eigenvectors = eigenvectors(:, sorted_indices);
% 选择前k个主成分
k = 100;
selected_eigenvectors = eigenvectors(:, 1:k);
% 将原始数据投影到主成分空间
projected_data = X_centered * selected_eigenvectors;代码分析:首先计算均值脸,将数据中心化。然后计算协方差矩阵,通过特征分解得到特征值和特征向量。对特征值排序后,选择前k个特征向量作为主成分。最后将原始数据投影到主成分空间,实现数据降维。
利用最小距离分类器分类3种植物
假设我们有3种植物的特征数据,利用最小距离分类器可以进行分类。
% 假设已经有训练数据train_data,每一行是一个样本,最后一列是类别标签
% 以及测试数据test_data
train_labels = train_data(:, end);
train_features = train_data(:, 1:end - 1);
test_labels = test_data(:, end);
test_features = test_data(:, 1:end - 1);
% 初始化预测标签数组
predicted_labels = zeros(size(test_features, 1), 1);
for i = 1:size(test_features, 1)
distances = pdist2(test_features(i, :), train_features, 'euclidean');
[~, nearest_index] = min(distances);
predicted_labels(i) = train_labels(nearest_index);
end
% 计算分类准确率
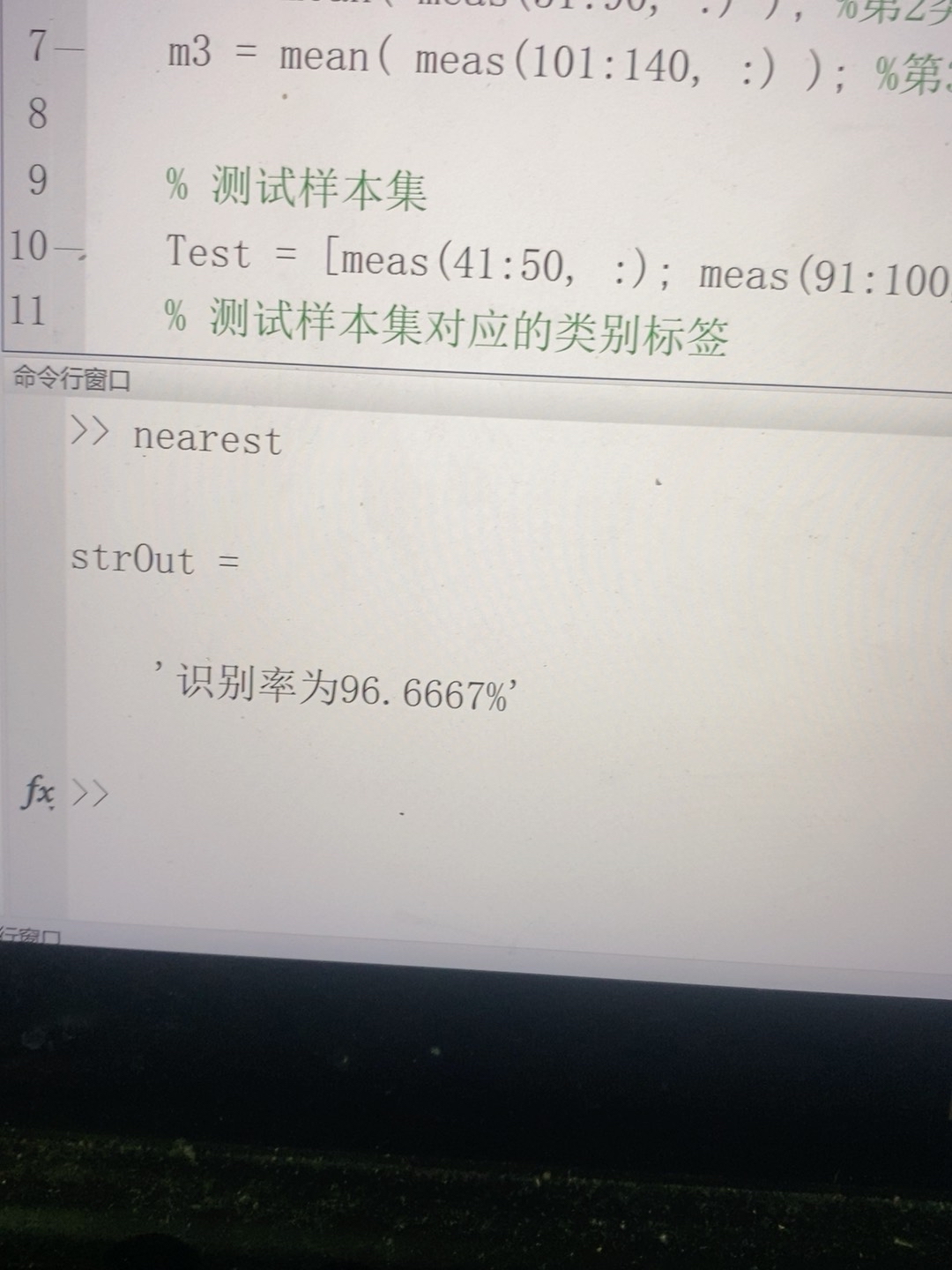
accuracy = sum(predicted_labels == test_labels) / length(test_labels);
disp(['分类准确率为: ', num2str(accuracy * 100), '%']);代码分析:先将训练数据和测试数据分别提取特征和标签。通过循环对每个测试样本计算与所有训练样本的欧氏距离,找到距离最近的训练样本的类别标签作为预测标签。最后计算预测标签与真实标签的匹配比例,得到分类准确率。
以上就是利用Matlab进行图像处理、数据降维和分类的一些常见操作和代码示例啦,希望能给大家带来一些启发,在自己的项目中可以灵活运用这些知识。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)