保姆级超详细教程:语音识别模型 Dolphin 本地部署
·
Dolphin介绍
Dolphin —— 由清华大学电子工程系语音与音频技术实验室联合海天瑞声(Dataocean AI)推出的多语言自动语音识别(ASR)模型,专为东方语言与中文方言优化。
一、核心定位与能力
- 核心定位:大规模多语言、多任务 ASR 模型,聚焦东方语言识别。
- 语言覆盖:
- 40 种东方语言(东亚、南亚、东南亚、中东)
- 22 种中文方言(含普通话、粤语、四川话、上海话等)
- 训练数据:21.2 万小时(13.8 万小时专有数据 + 7.4 万小时开源数据)
- 核心功能:语音识别、语音活动检测(VAD)、语音分段、语言识别(LID)
- 不支持:机器翻译任务
二、技术架构
- 基于 Whisper / OWSM 架构改进
- 混合架构:CTC + Attention
- 编码器:E‑Branchformer;解码器:标准 Transformer
- 创新:两级语言标记系统(
<语言><地区>,如<zh><CN>),精准区分方言与地域变体
三、性能优势
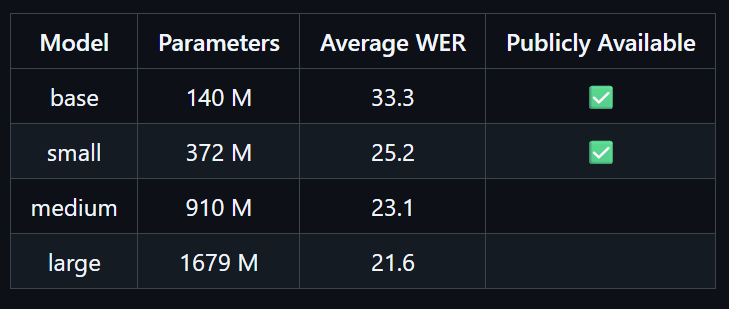
- 词错率(WER)显著低于 Whisper 同等尺寸模型
- Base 版:平均 WER 降低 63.1%
- Small 版:平均 WER 降低 68.2%
- Base 版参数量仅为 Whisper large‑v3 的 1/10,但识别精度更高
四、开源与部署
- 开源地址:github.com/DataoceanAI/Dolphin
- 提供 base / small 两种预训练模型
- 已转换为 ONNX 格式,支持多平台、多语言部署(Python、C++、Java、Go 等)
- 可通过 sherpa‑onnx 快速集成与推理
本地部署
Dolphin 模型参数
Dolphin 环境依赖安装
conda create -n whisper_demo python=3.9
conda activate dolphin
pip install ffmpeg
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 安装torch时注意CUDA版本,此外若安装较慢推荐使用阿里源或者清华源
pip install -U dataoceanai-dolphin
pip install git+https://github.com/SpeechOceanTech/Dolphin.git
# pip库安装与git安装 二选一即可或者使用源码安装
cd dolphin
pip install -r requirements.txt 我在安装的时候出现报错
ERROR: Failed building wheel for ctc-segmentation
问题应该是 ctc-segmentation 需要编译 C++ 扩展,但电脑没有 MSVC 编译环境(Microsoft Visual C++ 14+),所以 wheel 构建失败。
这里我写了一个MSVC编译环境的安装与配置,大家可以参考。
配置好MSVC编译环境重新进行安装便可以正确安装

用例测试
1)最简用法:直接转写一个音频
dolphin audio.wav
2)指定模型与模型目录
dolphin audio.wav --model small --model_dir /data/models/dolphin/
3)指定语言与区域(中文场景建议显式指定)
dolphin audio.wav --model small --model_dir /data/models/dolphin/ --lang_sym "zh" -- region_sym "CN"
参数说明:
--lang_sym "zh":语言代码(示例:中文)
--region_sym "CN":区域代码(示例:中国大陆)
4)将语音 padding 到 30 秒(用于短音频补齐)
dolphin audio.wav --model small --model_dir /data/models/dolphin/ --lang_sym "zh" --region_sym "CN" --padding_speech true
参数说明:
--padding_speech true:对语音进行 padding(通常补齐到 30s)
典型用途:某些模型/推理流程对输入长度敏感,短音频补齐能更稳定
可能副作用:会让推理时长略增加(因为输入变长了)首次运行会下载模型权重
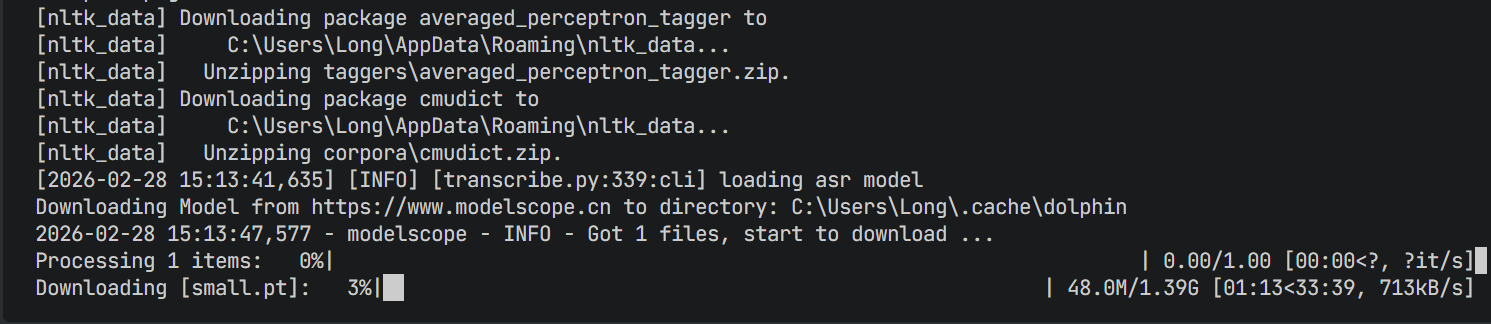
得到音频转写结果


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)