Flink 状态与容错机制:从 Checkpoint 到高可用
本文详细介绍了Flink的容错机制,重点解析了Checkpoint、StateBackend和Savepoint三大核心组件。深入剖析了Checkpoint的触发和执行流程,包括Barrier机制、状态快照和故障恢复等关键环节,并对比了Checkpoint与Savepoint的异同。最后总结了Flink通过这套机制确保数据流处理的稳定性和一致性,实现"故障自愈"和"运维灵活"的双重目标。
2026第一天,也是今年第一篇,祝大家新年快乐,心想事成!🧨🧨🧨
Checkpoint 让流动的数据 “有记忆”(故障后快速续跑),
StateBackend 让状态 “有形”(状态数据变成可存储的实体),
Savepoint 让系统 “可复刻”(计划内的灵活迁移与复原)。
一、为什么需要 Checkpoint
在分布式流式计算中,任务的执行是持续的、无终止的,只要系统在运行,数据就会源源不断地流入算子。然而,如果中途 “停电” 呢?——节点宕机、网络波动、磁盘损坏都可能中断计算。
如何在系统恢复后,让整个工厂从中断处继续生产、而不是从头再来?
这就是 Checkpoint 存在的意义。它是 Flink 容错体系的核心机制,通过周期性地保存算子的状态(State)与偏移量(Offset),为系统提供了“时间旅行”的能力——故障后可以回到最近一次一致性快照点重新执行,是实现 Exactly-Once 语义的关键机制。
二、Barrier 与 Checkpoint:一致性的基石
Checkpoint 的核心机制来自 Chandy-Lamport 的分布式快照算法。它解决了:如何在不暂停整个系统的情况下,捕获所有算子的一致状态;Flink 在此基础上实现了可扩展的分布式状态快照体系。
核心组件
| 模块 | 核心类 | 职责 |
|---|---|---|
| 协调器 | CheckpointCoordinator |
统一发起 Checkpoint、分发 Barrier、收集 ACK、管理Checkpoint的生命周期 |
| 任务端 | StreamTask、OperatorChain |
接收 Barrier、执行状态快照 |
| 状态存储 | StateBackend |
保存算子状态 |
| Barrier 处理 | CheckpointBarrierHandler |
对齐输入流、控制 Barrier 传播 |
| 汇报与恢复 | AcknowledgeCheckpoint、TaskStateSnapshot |
上报确认、触发恢复 |
CheckpointCoordinator 是整个流程的“大脑”,而每个 Task 则是它的“神经末梢”。
Barrier:数据流中的“快照标签”
Barrier 是 Flink 的巧妙设计。它是一种插入在数据流中的特殊标识,用于标定一致性边界。
其作用:
- 注入:CheckpointCoordinator 向每个 Source 插入 Barrier;
- 传播:Barrier 随数据流向下游传播;
- 对齐:多输入算子等待所有输入到达相同 ID 的 Barrier,保证状态一致。
Barrier就像每条生产线都贴上“第 N 次巡检标签”,
各车间在当前批次处理完后同步保存现场状态。
流程概述
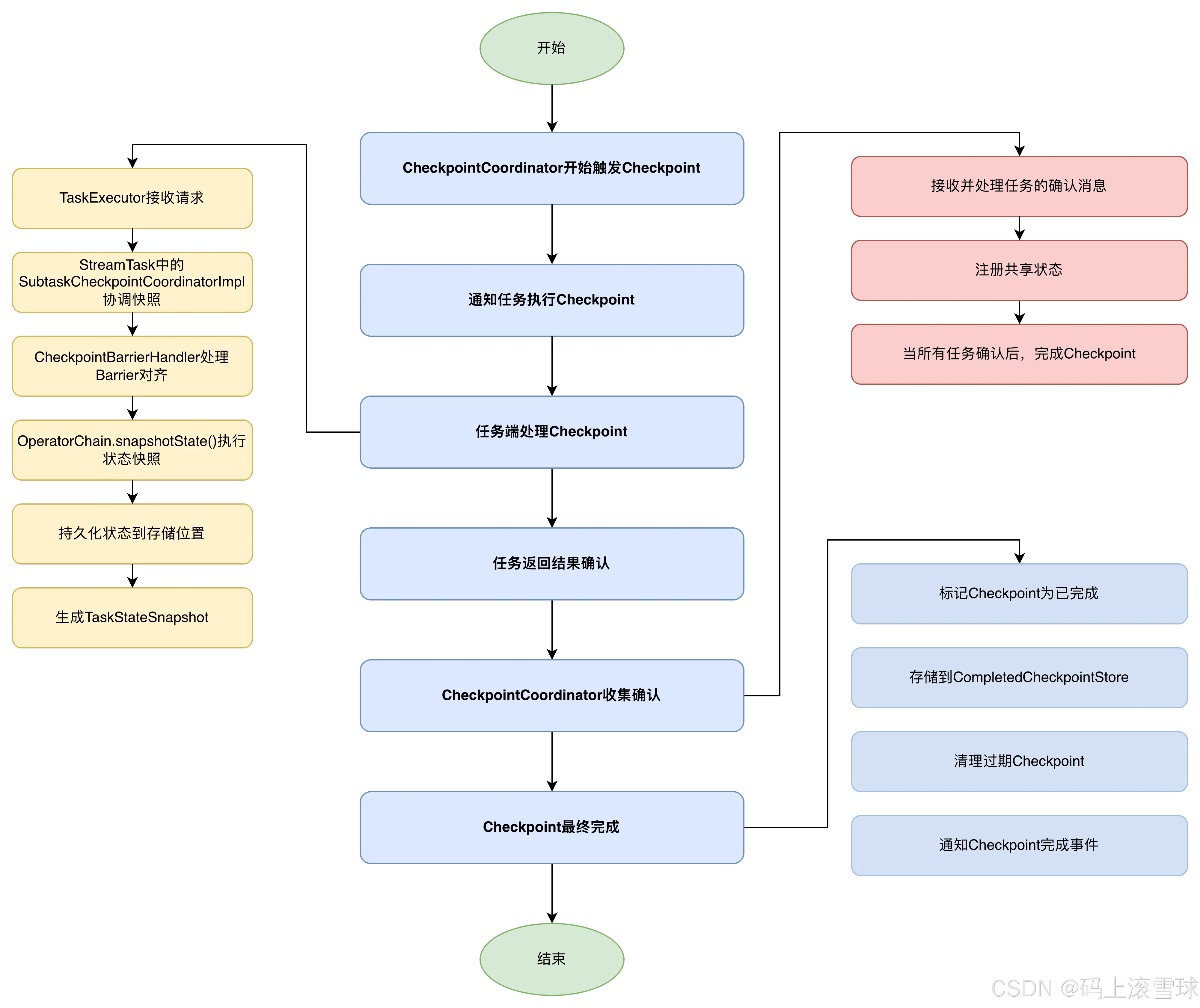
三、Checkpoint流程源码详细剖析
1. Checkpoint启用阶段
在DefaultExecutionGraph.enableCheckpointing()方法中,Flink完成Checkpoint的初始化配置:
public void enableCheckpointing(CheckpointCoordinatorConfiguration chkConfig,...){
// 创建CheckpointCoordinator实例
checkpointCoordinator=newCheckpointCoordinator(
jobInformation.getJobId(),
chkConfig,
operatorCoordinators,
checkpointIDCounter,
checkpointStore,
checkpointStorage,
ioExecutor,
checkpointsCleaner,
newScheduledExecutorServiceAdapter(checkpointCoordinatorTimer),
failureManager,
createCheckpointPlanCalculator(...),
checkpointStatsTracker);
// 注册作业状态监听器,控制Checkpoint调度器启停
if(checkpointCoordinator.isPeriodicCheckpointingConfigured()){
boolean allTasksOutputNonBlocking=...;
registerJobStatusListener(
checkpointCoordinator.createActivatorDeactivator(allTasksOutputNonBlocking));
}
}
- 创建
CheckpointCoordinator实例,配置Checkpoint的核心组件 - 注册作业状态监听器
CheckpointCoordinatorDeActivator
2. 调度器启动阶段
CheckpointCoordinatorDeActivator监听作业状态变化,控制Checkpoint调度器的启停:
public void jobStatusChanges(JobID jobId,JobStatus newJobStatus,long timestamp){
if(newJobStatus==JobStatus.RUNNING&& allTasksOutputNonBlocking){
// 作业运行且无阻塞输出时启动调度器
coordinator.startCheckpointScheduler();
}else{
// 其他状态停止调度器
coordinator.stopCheckpointScheduler();
}
}
- 当作业进入
RUNNING状态且所有任务输出非阻塞时,启动Checkpoint调度器 - 当作业状态改变或存在阻塞输出时,停止Checkpoint调度器
3. 周期性触发设置
在CheckpointCoordinator.startCheckpointScheduler()方法中,设置周期性Checkpoint的初始触发:
public void startCheckpointScheduler() {
synchronized (lock) {
// ...
if (isPeriodicCheckpointingStarted()) {
stopCheckpointScheduler(); // 检查状态,避免重复启动
}
periodicScheduling = true;
scheduleTriggerWithDelay(clock.relativeTimeMillis(), getRandomInitDelay());
}
}
- 检查确保Checkpoint未关闭、已配置周期性Checkpoint、调度器未启动
- 调用
scheduleTriggerWithDelay设置首次Checkpoint触发,添加随机初始延迟
scheduleTriggerWithDelay方法实现:
private void scheduleTriggerWithDelay(long currentRelativeTime, long initDelay) {
nextCheckpointTriggeringRelativeTime = currentRelativeTime + initDelay;
currentPeriodicTrigger = new ScheduledTrigger();
currentPeriodicTriggerFuture =
timer.schedule(currentPeriodicTrigger, initDelay, TimeUnit.MILLISECONDS);
}
4. Checkpoint实际触发入口
ScheduledTrigger类实现Runnable接口,负责实际触发Checkpoint并重新调度下一次触发:
final class ScheduledTrigger implements Runnable {
@Override
public void run() {
synchronized (lock) {
if (currentPeriodicTrigger != this) {
return; // 检查是否是当前调度的触发器
}
// 重新调度下一次Checkpoint
long checkpointInterval = getCurrentCheckpointInterval();
if (checkpointInterval != DISABLED_CHECKPOINT_INTERVAL) {
nextCheckpointTriggeringRelativeTime += checkpointInterval;
currentPeriodicTriggerFuture = timer.schedule(
this,
Math.max(0, nextCheckpointTriggeringRelativeTime - clock.relativeTimeMillis()),
TimeUnit.MILLISECONDS);
}
}
// 触发当前Checkpoint
try {
triggerCheckpoint(checkpointProperties, null, true);
} catch (Exception e) {
LOG.error("Exception while triggering checkpoint for job {}.", job, e);
}
}
}
- 重新调度:计算下一次触发时间,使用定时器调度下一次Checkpoint
- 触发Checkpoint:调用
triggerCheckpoint方法执行实际的Checkpoint操作
5. Checkpoint执行准备
triggerCheckpoint方法执行Checkpoint的实际操作:
CompletableFuture<CompletedCheckpoint> triggerCheckpoint(
CheckpointProperties props,
@Nullable String externalSavepointLocation,
boolean isPeriodic) {
CheckpointTriggerRequest request =
new CheckpointTriggerRequest(props, externalSavepointLocation, isPeriodic);
chooseRequestToExecute(request).ifPresent(this::startTriggeringCheckpoint);
return request.onCompletionPromise;
}
- 创建
CheckpointTriggerRequest对象 - 选择要执行的Checkpoint请求
- 调用
startTriggeringCheckpoint开始实际的Checkpoint触发过程,在CheckpointCoordinator.startTriggeringCheckpoint()方法中,Flink完成Checkpoint执行前的准备工作:
private void startTriggeringCheckpoint(CheckpointTriggerRequest request) {
// ... 前置检查和状态准备 ...
// 计算Checkpoint计划,确定参与的任务
CompletableFuture<CheckpointPlan> checkpointPlanFuture = checkpointPlanCalculator.calculateCheckpointPlan();
// ... 创建PendingCheckpoint对象 ...
// 初始化Checkpoint存储位置
CheckpointStorageLocation checkpointStorageLocation = initializeCheckpointLocation(
pendingCheckpoint.getCheckpointID(),
request.props,
request.externalSavepointLocation,
initializeBaseLocations);
// ... 触发OperatorCoordinator检查点 ...
// ... 触发MasterHook检查点 ...
// 调用triggerCheckpointRequest开始实际触发任务检查点
triggerCheckpointRequest(request, timestamp, checkpoint);
}
6. 通知任务执行Checkpoint
在CheckpointCoordinator.triggerCheckpointRequest()方法中,Flink调用triggerTasks方法通知所有参与的任务执行Checkpoint:
private CompletableFuture<Void> triggerTasks(
CheckpointTriggerRequest request, long timestamp, PendingCheckpoint checkpoint) {
// ... 配置CheckpointOptions ...
// 向所有任务发送Checkpoint请求
List<CompletableFuture<Acknowledge>> acks = new ArrayList<>();
for (Execution execution : checkpoint.getCheckpointPlan().getTasksToTrigger()) {
if (request.props.isSynchronous()) {
acks.add(execution.triggerSynchronousSavepoint(checkpointId, timestamp, checkpointOptions));
} else {
acks.add(execution.triggerCheckpoint(checkpointId, timestamp, checkpointOptions));
}
}
return FutureUtils.waitForAll(acks);
}
- 配置
CheckpointOptions(包括Checkpoint类型、存储位置等) - 遍历所有需要触发Checkpoint的任务并向每个任务发送Checkpoint触发请求
7. 任务端接收并处理Checkpoint请求
在Execution.triggerCheckpointHelper()方法中,任务通过TaskManagerGateway向实际运行的任务发送Checkpoint请求:
private CompletableFuture<Acknowledge> triggerCheckpointHelper(
long checkpointId, long timestamp, CheckpointOptions checkpointOptions) {
final LogicalSlot slot = assignedResource;
if (slot != null) {
final TaskManagerGateway taskManagerGateway = slot.getTaskManagerGateway();
return taskManagerGateway.triggerCheckpoint(
attemptId, getVertex().getJobId(), checkpointId, timestamp, checkpointOptions);
}
// ... 任务不再运行的处理 ...
}
任务端实际处理流程:
TaskExecutor接收triggerCheckpoint请求- 根据
ExecutionAttemptID查找对应的Task实例 - 在
Task.triggerCheckpointBarrier()方法中,任务开始处理Checkpoint请求,最终调用CheckpointableTask.triggerCheckpointAsync()方法异步触发Checkpoint - 在
StreamTask.triggerCheckpointAsync()方法中,会执行Checkpoint的核心逻辑, - 调用执行到
SubtaskCheckpointCoordinatorImpl.checkpointState()方法中,官方也在源码中给出来执行Checkpoint的详细步骤:初始化检查、预准备、向下游发送CheckpointBarrier、注册对齐定时器、准备channel状态、执行状态快照。 - 在
SubtaskCheckpointCoordinatorImpl.takeSnapshotSync()方法中,调用operatorChain.snapshotState()方法执行所有算子的状态快照 - 执行本地状态快照(如使用RocksDBStateBackend则执行异步快照)
- 将状态数据持久化到Checkpoint存储位置
- 生成
TaskStateSnapshot并完成上报
8. 任务返回Checkpoint结果确认
任务完成Checkpoint后,通过AcknowledgeCheckpoint消息向CheckpointCoordinator返回结果:
public class AcknowledgeCheckpoint extends AbstractCheckpointMessage {
private final TaskStateSnapshot subtaskState;
private final CheckpointMetrics checkpointMetrics;
// ... 构造函数和getter方法 ...
}
TaskStateSnapshot:包含任务中所有算子的状态快照信息CheckpointMetrics:包含Checkpoint的性能指标(如快照时间、对齐时间等)
9. CheckpointCoordinator收集并完成Checkpoint
在CheckpointCoordinator.receiveAcknowledgeMessage()方法中,Flink接收任务的Checkpoint确认:
public boolean receiveAcknowledgeMessage(AcknowledgeCheckpoint message, String taskManagerLocationInfo) {
// ... 前置检查 ...
synchronized (lock) {
final PendingCheckpoint checkpoint = pendingCheckpoints.get(checkpointId);
// ... 注册共享状态 ...
if (checkpoint != null && !checkpoint.isDisposed()) {
switch (checkpoint.acknowledgeTask(
message.getTaskExecutionId(),
message.getSubtaskState(),
message.getCheckpointMetrics())) {
case SUCCESS:
// ... 日志记录 ...
if (checkpoint.isFullyAcknowledged()) {
completePendingCheckpoint(checkpoint); // 所有任务都已确认,完成Checkpoint
}
break;
// ... 其他情况处理 ...
}
}
}
return true;
}
- 注册共享状态(用于增量Checkpoint)
- 记录任务的Checkpoint结果
- 当所有任务都已确认Checkpoint完成时,调用
completePendingCheckpoint完成整个Checkpoint
10. Checkpoint完成处理
在completePendingCheckpoint方法中,Flink完成Checkpoint的最后处理:
- 将Checkpoint标记为已完成
- 将Checkpoint信息存储到
CompletedCheckpointStore - 清理过期的Checkpoint
- 通知Checkpoint完成事件
- 更新Checkpoint统计信息
四、状态的载体:StateBackend
1.StateBackend 作用与类型
StateBackend 决定了 Flink 状态内部的存储格式、状态在进行 CheckPoint 时如何持久化以及持久化在哪里,Flink 内置了以下这些开箱即用的 state backends (此前的MemoryStateBackend和FsStateBackend在1.20中已经是弃用状态了)
| 类型 | 特点 | 适用场景 |
|---|---|---|
| HashMapStateBackend | 基于堆内存存储,默认状态后端 | 有较大 state,较长 window 和较大 key/value 状态的 Job;所有的高可用场景。 |
| EmbeddedRocksDBStateBackend | 基于 RocksDB 的本地持久化,支持增量快照 | 状态非常大、窗口非常长、key/value 状态非常大的 Job;所有高可用的场景。 |
2. AsyncSnapshot 异步快照机制
大状态下同步写入会阻塞计算,因此 Flink 引入 AsyncSnapshot。它让状态快照在独立线程异步执行,计算任务可继续运行。
实现原理:
- 两阶段快照:将快照过程分为同步准备和异步执行两个阶段
- 主线程安全:同步阶段仅执行轻量级操作(如创建本地快照),避免阻塞
- 独立执行线程:异步阶段在专门的线程池中执行,不影响计算任务
- 资源隔离:使用
CloseableRegistry管理异步资源,确保资源正确释放
// 同步准备资源
SR snapshotResources = snapshotStrategy.syncPrepareResources(checkpointId);
logCompletedInternal(LOG_SYNC_COMPLETED_TEMPLATE, streamFactory, startTime);
SnapshotStrategy.SnapshotResultSupplier<T> asyncSnapshot =
snapshotStrategy.asyncSnapshot(
snapshotResources,
checkpointId,
timestamp,
streamFactory,
checkpointOptions);
// 异步执行快照操作
FutureTask<SnapshotResult<T>> asyncSnapshotTask =
new AsyncSnapshotCallable<SnapshotResult<T>>() {
@Override
protected SnapshotResult<T> callInternal() throws Exception {
return asyncSnapshot.get(snapshotCloseableRegistry);
}
@Override
protected void cleanupProvidedResources() {
if (snapshotResources != null) {
snapshotResources.release();
}
}
@Override
protected void logAsyncSnapshotComplete(long startTime) {
logCompletedInternal(
LOG_ASYNC_COMPLETED_TEMPLATE, streamFactory, startTime);
}
}.toAsyncSnapshotFutureTask(cancelStreamRegistry);
五、Savepoint:可控的快照与迁移机制
Savepoint 与 Checkpoint 底层机制相同,但设计目标和使用场景完全不同,前者保障系统高可用,后者支撑运维灵活性。以下做一个详细对比:
| 对比维度 | Checkpoint | Savepoint |
|---|---|---|
| 核心定位/目的 | 为意外失败的作业提供快速恢复机制,侧重故障自愈 | 面向计划内的手动运维操作,侧重可移植性与灵活性 |
| 生命周期管理 | 由 Flink 自动创建、管理、删除(可配置保留) | 完全由用户手动创建、拥有、删除,Flink 不干预 |
| 触发方式 | 自动周期性触发(可配置间隔) | 仅支持用户手动触发 |
| 设计目标 | 轻量级创建、极速恢复 | 可移植性、作业变更兼容性(成本相对更高) |
| 存储数据格式 | 状态后端特定的原生格式(部分支持增量存储) | 默认状态后端独立的标准格式;Flink 1.15+ 可选择原生格式(更快但有限制) |
| 作业变更兼容性 | 依赖作业代码/拓扑不变,兼容性弱 | 适配作业代码/拓扑变更(如版本升级、算子调整),兼容性强 |
| 自动清理规则 | 作业终止后自动删除(除非配置保留) | 作业终止/恢复后均不会自动删除,需用户手动清理 |
| 典型使用场景 | 系统崩溃、节点宕机后的快速恢复 | 版本升级、作业拓扑调整、集群迁移、计划性停机 |
简单说就是Checkpoint 是 Flink 自动管理的“故障恢复工具”,追求轻量、快速,适配无计划的意外故障;而Savepoint 是用户手动控制的“运维备份工具”,追求兼容、灵活,适配有计划的作业变更/运维操作。Savepoint源码触发入口:0
CheckpointCoordinator.triggerSavepoint(targetDirectory, SavepointFormatType)
Savepoint就像厂长手动下令留档,全厂记录完整状态,用于迁移或检修。
六、故障恢复与高可用机制
1. 故障恢复机制:从失败到重启
当作业发生故障时,Flink 会基于最近一次成功的 Checkpoint 快速恢复,恢复过程由 JobMaster 主导,完整流程如下:
- 失败检测
- 当任务执行失败时,
ExecutionGraph会捕获异常并触发故障处理逻辑; - 系统根据配置的 RestartStrategy(重启策略)决定是否进行恢复。
- 当任务执行失败时,
- 状态转换
- 作业状态从 FAILED 转为 RESTARTING;
- 所有任务的执行状态被重置,为后续重新部署做准备。
- 检查点恢复
JobMaster从CompletedCheckpointStore中加载最近一次成功的 Checkpoint;- 提取其中的 算子状态(Operator State) 与 键控状态(Keyed State) 元信息;
- 将这些状态重新分配给对应的执行顶点(
ExecutionVertex)。
- 重新调度执行
- 调用
scheduleForExecution()重新提交任务; - 各任务从 CREATED → SCHEDULED → DEPLOYING → RUNNING 状态依次过渡;
- 在初始化阶段,任务从
StateBackend中恢复其具体状态,实现“从中断点继续执行”。
- 调用
这就像一条自动化生产线在停机后,工人重新上岗,设备接入电源,系统从上次的“生产进度”继续运行。
2. 高可用机制(HA):让系统不中断
在更高层面,Flink 通过 JobManager 高可用机制(HA),
确保在 JobManager 自身发生故障时,系统仍能自动恢复与接管。
核心能力包括:
-
Leader 选举
由
HighAvailabilityServices(如 ZooKeeper、Kubernetes HA Service)协调,选出新的 JobManager 作为集群领导者。
-
元数据持久化
将 JobGraph、Checkpoint 元信息、执行状态 持久化到共享存储(如 HDFS 或对象存储)。
-
Failover 恢复
当新的 JobManager 当选后,它会从持久化存储中恢复作业与最新的 Checkpoint 元数据,
继续上一次作业的执行。
-
典型配置示例
high-availability:zookeeper high-availability.storageDir:hdfs:///flink/ha/ high-availability.zookeeper.path.root:/flink
可以将它比喻为“厂长轮班制度”:一个厂长倒下,备用厂长立即接任,并从档案室(Checkpoint 存储)中恢复所有生产计划,确保整座数据工厂 不中断生产、不断电运行。
七、总结:一致性是流处理的生命线
我们可以这样理解 Flink 的状态与容错机制:
| 概念 | 比喻 | 核心组件 |
|---|---|---|
| Checkpoint | 自动巡检记录 | CheckpointCoordinator |
| Barrier | 同步标签 | CheckpointBarrierHandler |
| StateBackend | 仓库系统 | HashMapStateBackend |
| Savepoint | 手动留档 | CheckpointCoordinator |
| JobManager HA | 厂长轮班 | HighAvailabilityServices |
| 恢复 | 复工 | JobMaster |
Checkpoint 让流动的数据 “有记忆”(故障后快速续跑),
StateBackend 让状态 “有形”(状态数据变成可存储的实体),
Savepoint 让系统 “可复刻”(计划内的灵活迁移与复原)。
HA 让作业 “不中断” (当JM失效时,自动接管并从快照中恢复全局)
它们共同构成了 Flink 的容错体系:让数据流稳定运行、状态可追溯、数据永不丢失。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)