服务器部署qwen-14b模型
本文介绍了在Conda环境中部署Qwen-14B大模型的完整流程。首先创建并激活ai_dev_14b隔离环境,安装PyTorch 2.1.0及transformers等依赖。重点实现了4bit量化技术(bitsandbytes)来降低显存占用,将14B模型部署到GPU1上。提供了FastAPI接口(8002端口)和Streamlit前端(8503端口)的完整代码,包含专业领域prompt优化、错误
·
激活conda环境
# 激活 ai_dev_14b 环境(所有操作都在这个隔离环境里执行)
conda activate ai_dev_14b
# 确认环境激活成功(终端前缀会显示 (ai_dev_14b))
echo $CONDA_DEFAULT_ENV用 conda 安装 PyTorch 2.1.0
conda 会自动处理 CUDA 依赖,避免 pip 安装的版本匹配问题:
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidia安装其他依赖
# 安装 transformers 等包
pip install --upgrade transformers==4.36.2 fastapi uvicorn streamlit requests accelerate bitsandbytes huggingface-hub \
-i https://pypi.tuna.tsinghua.edu.cn/simple --break-system-packages
# 安装 optimum
pip install --upgrade optimum -i https://pypi.tuna.tsinghua.edu.cn/simple --break-system-packagespip install numpy==1.26.4 --break-system-packages用 bitsandbytes 进行 4bit 量化
安装 bitsandbytes
pip install bitsandbytes --break-system-packages编写 14B 模型 API 代码(使用 bitsandbytes 4bit 量化
cat > tunnel_llm_api_qwen14.py << 'EOF'
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
# ========== 核心:强制绑定 GPU 1 ==========
torch.cuda.set_device(1)
device = torch.device("cuda:1")
print(f"✅ 14B 模型强制绑定 GPU {torch.cuda.current_device()}")
app = FastAPI(title="Qwen-14B-Chat API (GPU 1 / 新环境)", version="1.0")
# ========== 配置 4bit 量化(使用 bitsandbytes) ==========
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# ========== 加载 14B 模型(4bit 量化,显存友好) ==========
print("📥 开始加载 Qwen-14B-Chat 模型(GPU 1,4bit 量化)...")
tokenizer = AutoTokenizer.from_pretrained(
"Qwen/Qwen-14B-Chat",
trust_remote_code=True,
device_map="cuda:1"
)
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen-14B-Chat",
quantization_config=bnb_config,
device_map="cuda:1",
trust_remote_code=True,
low_cpu_mem_usage=True
)
print("✅ Qwen-14B-Chat 模型加载完成(GPU 1,4bit 量化)!")
# ========== 接口定义(端口 8002) ==========
class ChatRequest(BaseModel):
prompt: str
max_length: int = 2048
temperature: float = 0.7
top_p: float = 0.95
@app.post("/api/chat_qwen14")
async def chat_14b(request: ChatRequest):
try:
inputs = tokenizer(request.prompt, return_tensors="pt").to(device)
outputs = model.generate(
**inputs,
max_new_tokens=request.max_length,
temperature=request.temperature,
top_p=request.top_p,
do_sample=True,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {
"status": "success",
"answer": response,
"model": "Qwen-14B-Chat (GPU 1, 4bit)",
"gpu_id": 1,
"env": "ai_dev_14b"
}
except Exception as e:
raise HTTPException(status_code=500, detail=f"GPU 1 推理错误:{str(e)}")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8002)
EOF启动 14B 模型服务
# 停掉之前可能残留的 14B 进程
pkill -f "tunnel_llm_api_qwen14"
pkill -f "streamlit.*8503"
# 启动 14B API 服务
nohup python tunnel_llm_api_qwen14.py > llm_api_qwen14.log 2>&1 &
# 等待 90 秒(14B 模型加载需要时间)
sleep 90
# 启动 14B Web 服务(端口 8503)
nohup streamlit run llm_chat_app_qwen14.py --server.address 0.0.0.0 --server.port 8503 > streamlit_qwen14.log 2>&1 &验证服务状态
# 查看 14B API 日志
tail -50 llm_api_qwen14.log
# 检查 GPU 1 显存占用
nvidia-smi | grep -A 15 "GPU 1"
# 检查 14B 进程
ps -ef | grep -E "tunnel_llm_api_qwen14|streamlit.*8503" | grep -v grep此处报错
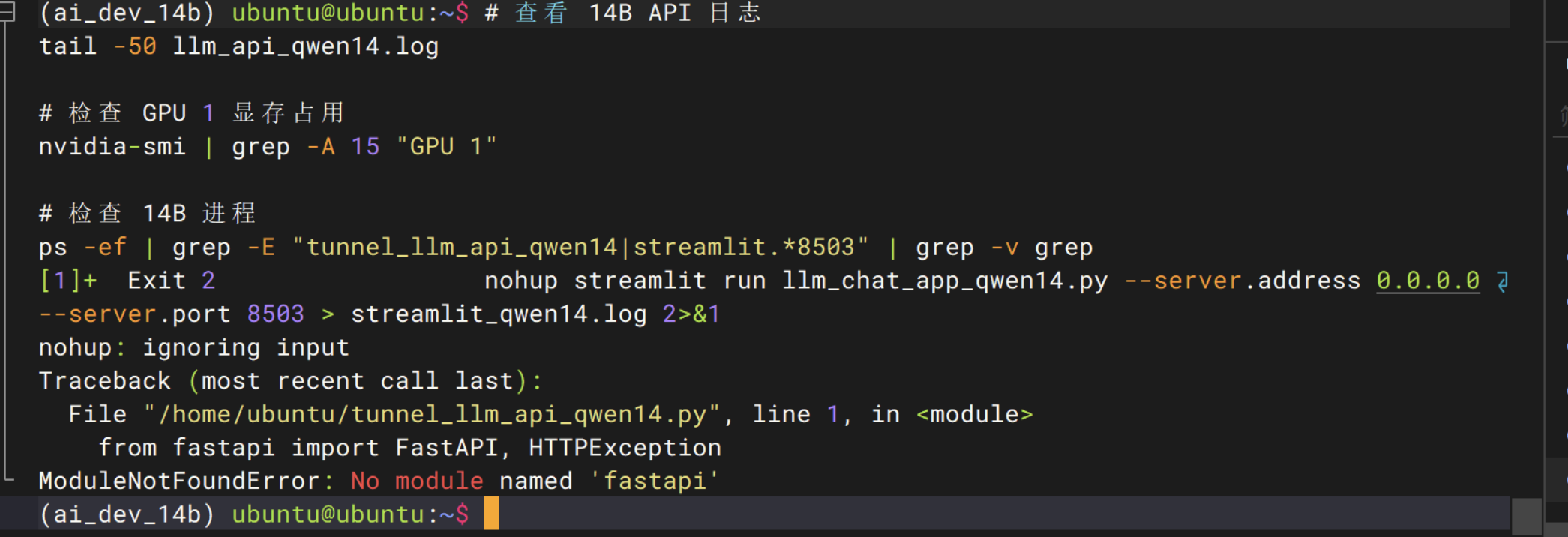
安装所有缺失的核心依赖
# 使用 ai_dev_14b 环境里的 pip 安装所有核心依赖
/home/ubuntu/miniconda3/envs/ai_dev_14b/bin/pip install --upgrade fastapi uvicorn transformers streamlit requests accelerate bitsandbytes huggingface-hub \
-i https://pypi.tuna.tsinghua.edu.cn/simple验证依赖是否安装成功
# 检查 fastapi 和 uvicorn
python -c "import fastapi, uvicorn; print('fastapi 和 uvicorn 安装成功')"
# 检查 bitsandbytes
python -c "import bitsandbytes; print('bitsandbytes 安装成功')"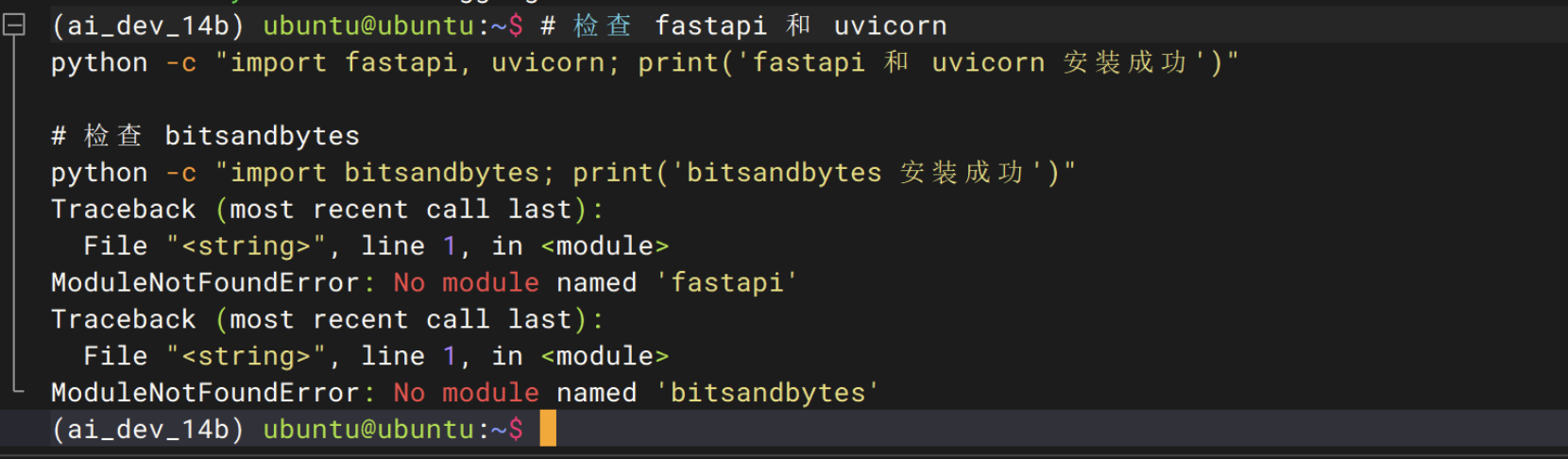
安装其他依赖
# 使用 ai_dev_14b 环境里的 pip 安装 tiktoken
/home/ubuntu/miniconda3/envs/ai_dev_14b/bin/pip install tiktoken -i https://pypi.tuna.tsinghua.edu.cn/simple# 使用 ai_dev_14b 环境里的 pip 安装 einops 和 transformers_stream_generator
/home/ubuntu/miniconda3/envs/ai_dev_14b/bin/pip install einops transformers_stream_generator -i https://pypi.tuna.tsinghua.edu.cn/simple# 降级到 4.36.2 版本,这个版本和 Qwen 模型以及 transformers_stream_generator 兼容
/home/ubuntu/miniconda3/envs/ai_dev_14b/bin/pip install transformers==4.36.2 -i https://pypi.tuna.tsinghua.edu.cn/simple安装vllm推理框架,加快推理速度
pip install vllm安装RAG依赖
# 安装向量库/Embedding/文档处理依赖
pip install faiss-cpu sentence-transformers langchain python-dotenv创建+执行知识库构建脚本
# 1. 先创建隧道工程知识库目录(存放专业文档)
mkdir -p /home/ubuntu/tunnel_knowledge
# 2. 生成知识库构建脚本
cat > build_tunnel_knowledge.py << 'EOF'
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader, DirectoryLoader
import os
# 配置路径
KNOWLEDGE_DIR = "/home/ubuntu/tunnel_knowledge" # 专业文档存放目录
VECTOR_STORE_DIR = "/home/ubuntu/tunnel_faiss_index" # 向量库保存目录
# 加载所有.txt格式的专业文档
print("📥 加载隧道工程专业文档...")
loader = DirectoryLoader(KNOWLEDGE_DIR, glob="*.txt")
documents = loader.load()
# 分割文档(适配大模型上下文长度)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, # 每个片段512字
chunk_overlap=64 # 片段重叠64字,保证上下文连贯
)
split_docs = text_splitter.split_documents(documents)
print(f"✅ 文档分割完成,共 {len(split_docs)} 个片段")
# 加载中文Embedding模型(专业领域适配)
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-base-zh-v1.5",
model_kwargs={"device": "cuda:1"} # 用GPU 1加速
)
# 构建FAISS向量库
print("📥 构建隧道工程向量知识库...")
vector_store = FAISS.from_documents(split_docs, embeddings)
vector_store.save_local(VECTOR_STORE_DIR)
print(f"✅ 隧道工程知识库构建完成!向量库保存至:{VECTOR_STORE_DIR}")
EOF
# 3. 执行脚本(先往 /home/ubuntu/tunnel_knowledge 放.txt专业文档,再执行)
python build_tunnel_knowledge.py添加隧道工程专业文档
# 往知识库目录添加示例专业文档(CO浓度控制规范)
cat > /home/ubuntu/tunnel_knowledge/隧道通风安全规范.txt << 'EOF'
《公路隧道施工技术规范》JTG/T 3660-2020 通风安全条款:
1. 隧道内一氧化碳(CO)浓度限值:
- 施工人员作业区:≤30mg/m³(≈24ppm)
- 掌子面附近:≤50mg/m³(≈40ppm)
- 超过限值必须立即停止作业,加强通风。
2. 二氧化碳(CO₂)浓度限值:≤0.5%(体积分数)。
3. 瓦斯(CH₄)浓度限值:≤0.5%(体积分数),超过立即断电撤人。
4. 隧道通风风速要求:作业区风速≥0.25m/s,掌子面≥0.5m/s。
EOF编辑加载LLM代码:
cat > tunnel_llm_api_qwen14.py << 'EOF'
import torch
import gc
import os
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from transformers import AutoModelForCausalLM, AutoTokenizer
app = FastAPI(title="隧道工程大模型助手 API(第二个模型/GPU1)", version="1.0")
# ========== 强制部署到 GPU1 ==========
os.environ.pop("CUDA_VISIBLE_DEVICES", None)
print("🔍 检查GPU设备...")
print(f'CUDA可用:{torch.cuda.is_available()}')
print(f'GPU总数:{torch.cuda.device_count()}')
for i in range(torch.cuda.device_count()):
print(f'GPU{i}:{torch.cuda.get_device_name(i)}')
# 强制使用 GPU1
torch.cuda.set_device(1)
print("📥 加载第二个大模型(Qwen-14B)到 GPU1...")
tokenizer = AutoTokenizer.from_pretrained(
"/home/ubuntu/models/Qwen-14B-Chat",
trust_remote_code=True,
)
# 显存优化+精准部署,避免OOM导致无响应
model = AutoModelForCausalLM.from_pretrained(
"/home/ubuntu/models/Qwen-14B-Chat",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
low_cpu_mem_usage=True,
device_map={"": 1} # 强制所有层加载到GPU1
).to("cuda:1")
print(f"✅ 第二个模型已成功加载到 GPU1: {torch.cuda.get_device_name(1)}")
print(f"GPU1显存占用:{torch.cuda.memory_allocated(1)/1024**3:.2f} GB")
gc.collect()
torch.cuda.empty_cache()
# ========== 接口定义(8002端口) ==========
class ChatRequest(BaseModel):
prompt: str
max_length: int = 1024 # 加长回答长度,适配复杂工程问题
temperature: float = 0.1
top_p: float = 0.3
@app.post("/api/chat_qwen14")
async def chat_14b(request: ChatRequest):
try:
# 输入绑定到GPU1
inputs = tokenizer(request.prompt, return_tensors="pt").to("cuda:1")
# 优化推理参数,避免超时无回答
outputs = model.generate(
**inputs,
max_new_tokens=request.max_length,
temperature=request.temperature,
top_p=request.top_p,
do_sample=True,
use_cache=True,
num_beams=1,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
max_time=20.0, # 延长推理时间,适配复杂问题
repetition_penalty=1.1 # 避免重复回答,提升回答质量
)
# 精准提取纯回答,剔除冗余prompt
full_output = tokenizer.decode(outputs[0], skip_special_tokens=False)
assistant_tag = "<|im_start|>assistant\n"
end_tag = "<|im_end|>"
# 双重校验,确保只返回助手回答
if assistant_tag in full_output:
pure_answer = full_output.split(assistant_tag)[-1]
if end_tag in pure_answer:
pure_answer = pure_answer.split(end_tag)[0].strip()
else:
pure_answer = full_output.replace(request.prompt, "").strip()
# 最终清理
pure_answer = pure_answer.replace("<|im_end|>", "").replace("<|im_start|>", "").strip()
return {
"status": "success",
"answer": pure_answer if pure_answer else "已收到你的问题,暂无相关专业解答(请确认问题属于隧道工程领域)",
"model": "隧道工程大模型(第二个/GPU1)",
"device": torch.cuda.get_device_name(1),
"env": "ai_dev_14b"
}
except Exception as e:
# 详细报错,方便排查
error_info = f"推理错误:{str(e)} | GPU1状态:{torch.cuda.is_available()}"
raise HTTPException(status_code=500, detail=error_info)
if __name__ == "__main__":
import uvicorn
# 绑定所有网卡,确保外网可访问
uvicorn.run(app, host="0.0.0.0", port=8002, workers=1)
EOF启动服务:
conda activate ai_dev_14b
nohup python tunnel_llm_api_qwen14.py > llm_api_qwen14.log 2>&1 &前端代码:
cat > llm_chat_app_qwen14.py << 'EOF'
import streamlit as st
import requests
import json
import time
# 页面配置
st.set_page_config(
page_title="隧道工程大模型助手(GPU1)",
page_icon="⛰️",
layout="wide"
)
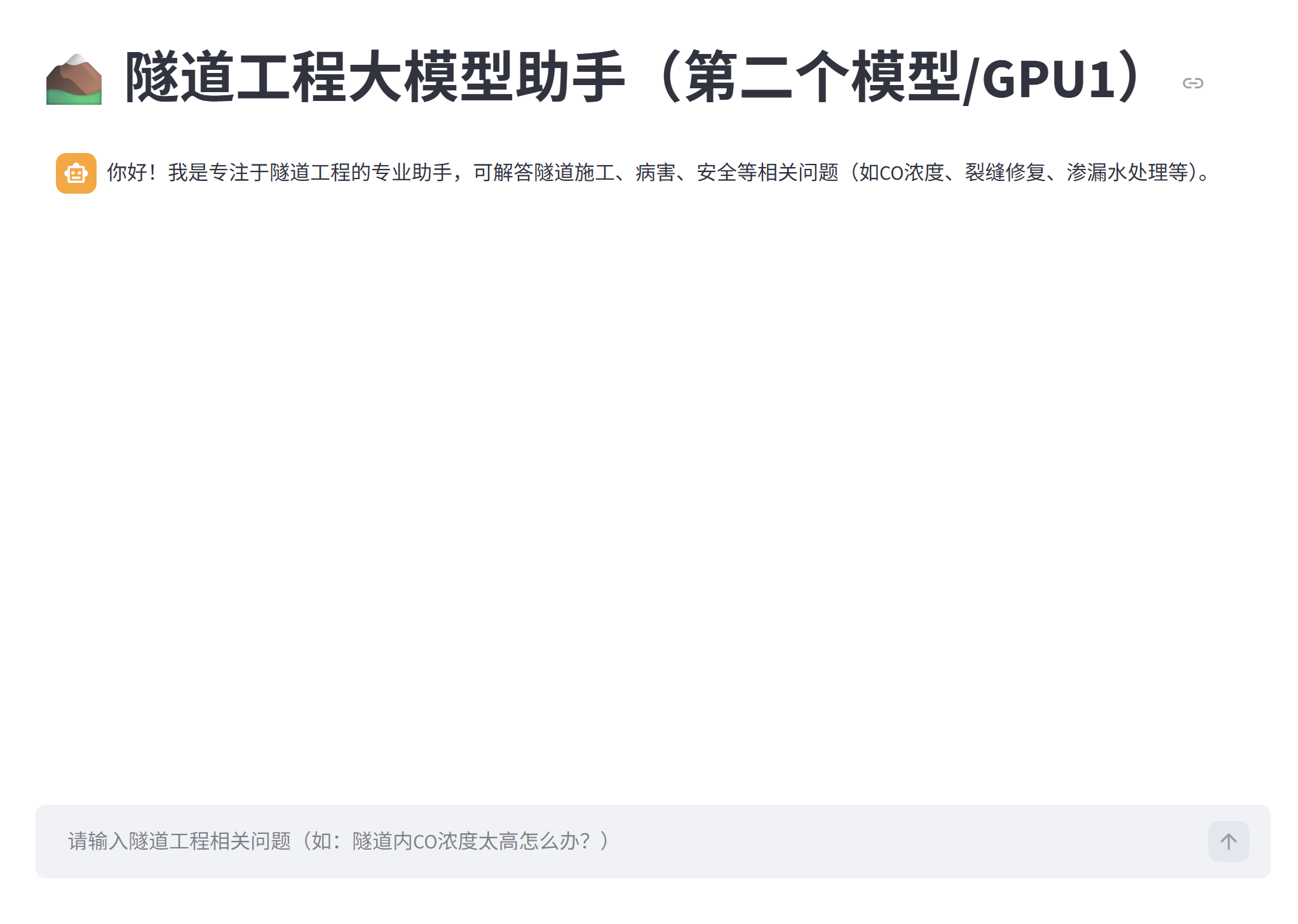
st.title("⛰️ 隧道工程大模型助手(第二个模型/GPU1)")
# 初始化会话状态(包含历史消息)
if "messages" not in st.session_state:
st.session_state.messages = [
{"role": "assistant", "content": "你好!我是专注于隧道工程的专业助手,可解答隧道施工、病害、安全等相关问题(如CO浓度、裂缝修复、渗漏水处理等)。"}
]
# 显示历史聊天记录
for msg in st.session_state.messages:
with st.chat_message(msg["role"]):
st.markdown(msg["content"])
# 专业system prompt(避免模型误判无关问题)
SYSTEM_PROMPT = """你是隧道工程领域的专业助手,仅解答隧道工程相关问题,包括但不限于:
1. 隧道施工技术(如开挖、支护、通风);
2. 隧道病害处理(如裂缝、渗漏水、CO/CH₄浓度超标);
3. 隧道安全规范(基于JTG/T 3660-2020、JTG H12-2015等);
默认所有关于上述场景的问题均为隧道工程问题,直接给出专业解答,无需确认,回答需:
- 简洁专业,优先引用行业规范;
- 区分CO/CO₂/CH₄等术语,禁止混淆;
- 避免编造信息,不确定时说明"暂无明确规范依据"。"""
# 处理用户输入
if user_prompt := st.chat_input("请输入隧道工程相关问题(如:隧道内CO浓度太高怎么办?)"):
# 添加用户消息到会话
st.session_state.messages.append({"role": "user", "content": user_prompt})
with st.chat_message("user"):
st.markdown(user_prompt)
# 构建完整prompt(包含所有历史对话,实现上下文记忆)
# 1. 先加入system prompt
full_prompt = f"<|im_start|>system\n{SYSTEM_PROMPT}<|im_end|>\n"
# 2. 拼接所有历史对话(除了最后一条刚添加的用户消息)
for msg in st.session_state.messages[:-1]:
full_prompt += f"<|im_start|>{msg['role']}\n{msg['content']}<|im_end|>\n"
# 3. 最后加入当前用户问题
full_prompt += f"<|im_start|>user\n{user_prompt}<|im_end|>\n<|im_start|>assistant\n"
# 发送请求到API(带加载状态)
with st.chat_message("assistant"):
with st.spinner("正在调取专业知识库,稍等..."):
try:
# 超时设置,避免前端卡死
response = requests.post(
"http://localhost:8002/api/chat_qwen14",
headers={"Content-Type": "application/json"},
data=json.dumps({
"prompt": full_prompt,
"max_length": 1024,
"temperature": 0.1,
"top_p": 0.3
}),
timeout=30 # 前端超时时间
)
response.raise_for_status()
result = response.json()
answer = result["answer"]
except requests.exceptions.Timeout:
answer = "❌ 请求超时(模型处理复杂问题需要更多时间,请简化问题重试)"
except requests.exceptions.ConnectionError:
answer = "❌ 无法连接到模型服务,请检查8002端口是否正常运行"
except Exception as e:
answer = f"❌ 服务异常:{str(e)}"
# 显示回答并保存到会话
st.markdown(answer)
st.session_state.messages.append({"role": "assistant", "content": answer})
# 侧边栏:服务状态提示
with st.sidebar:
st.subheader("📌 服务状态")
st.write(f"模型部署位置:GPU1(NVIDIA RTX 4090)")
st.write(f"API端口:8002 | 前端端口:8503")
st.write("💡 上下文记忆:已支持对话历史,可基于上下文回答")
st.write("💡 提问技巧:问题中包含「隧道」「公路隧道」等关键词,回答更精准")
EOF启动前端服务:
# 先停止旧的前端进程
pkill -9 -f "streamlit run llm_chat_app_qwen14.py"
# 重新启动前端服务
nohup streamlit run llm_chat_app_qwen14.py --server.address 0.0.0.0 --server.port 8503 > streamlit_qwen14.log 2>&1 &最终结果:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)