<span class=“js_title_inner“>亿级订单系统分库分表技术方案和Flink数据同步方案</span>
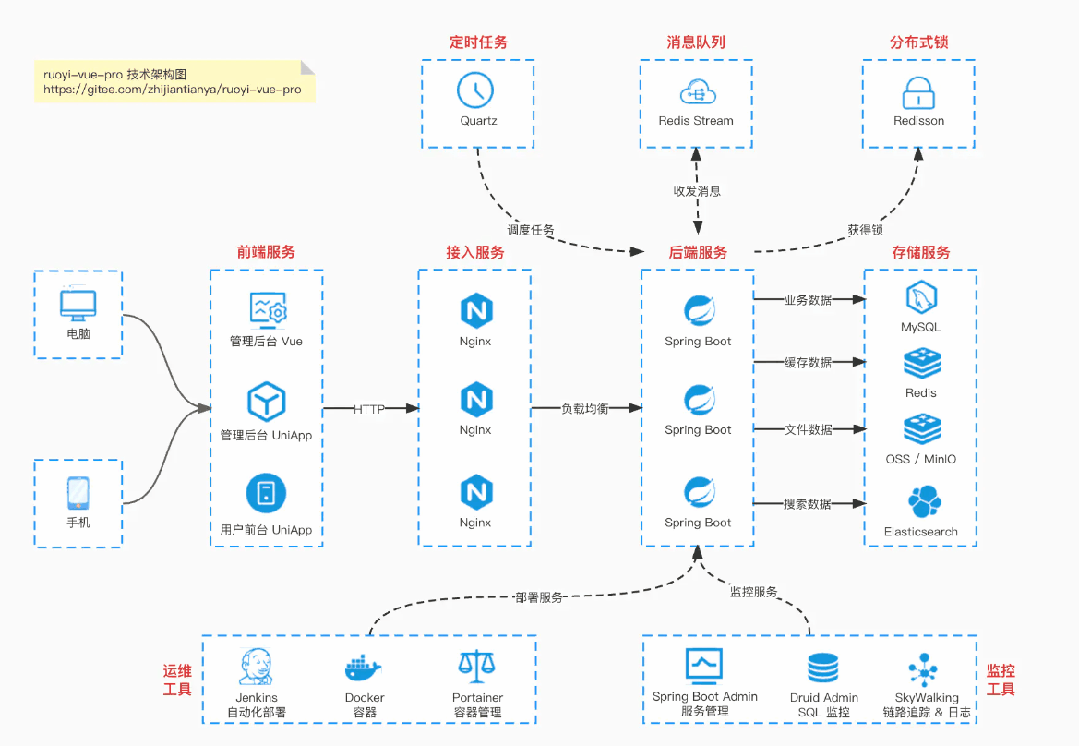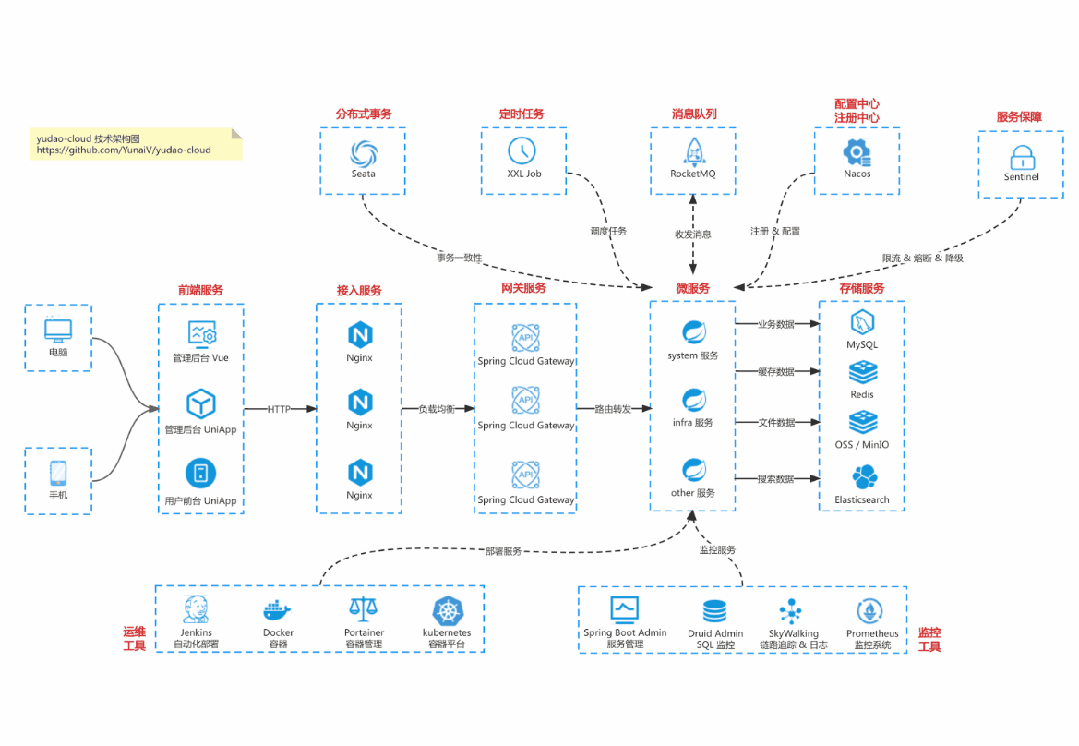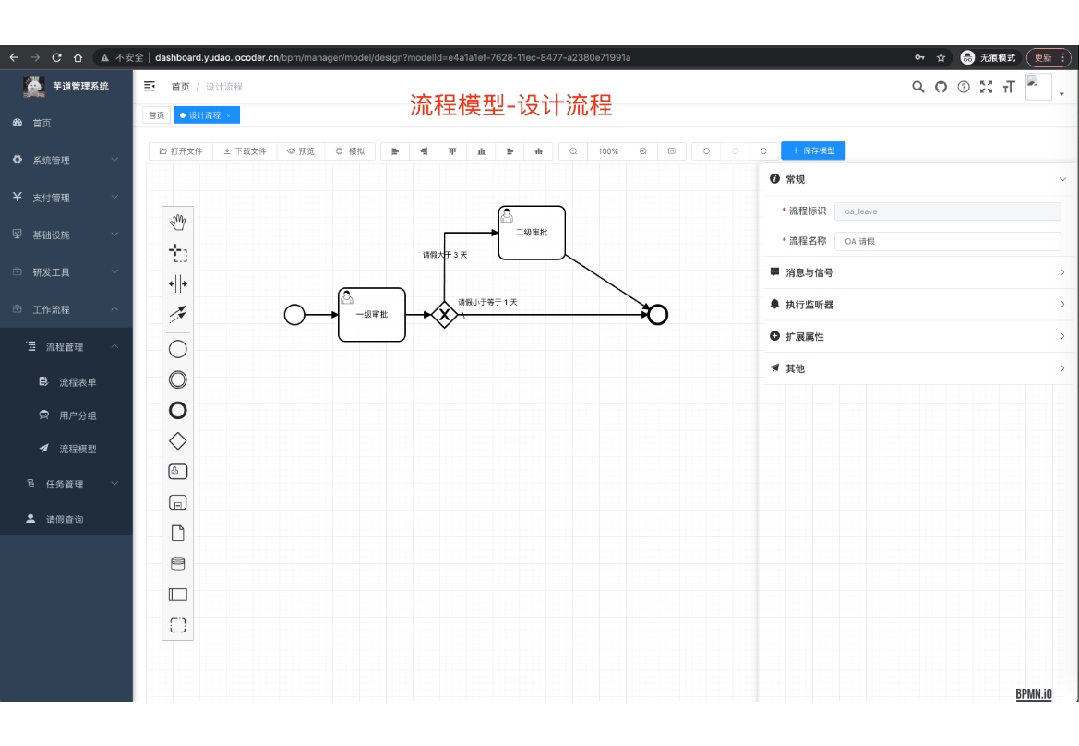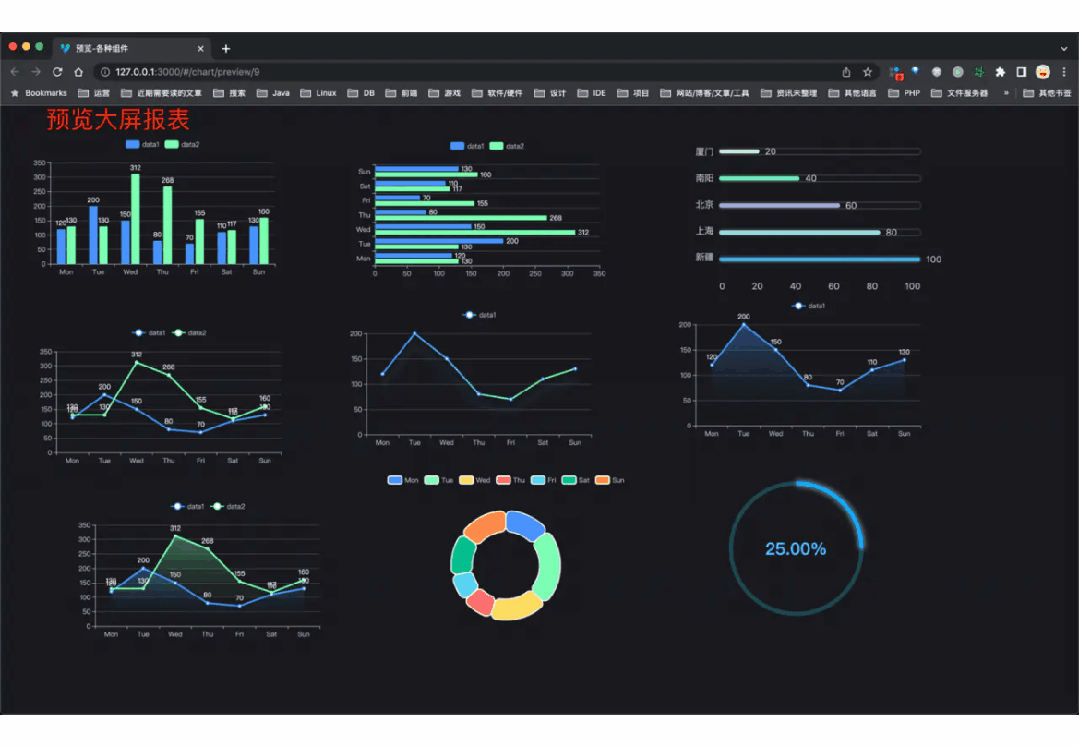
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能。订单表有主键orderId和唯一索引orderNo,orderId依赖数据库自增,orderNo自定义生成并且后4位为类用户id,内部场景用
👉 这是一个或许对你有用的社群
🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料:
《项目实战(视频)》:从书中学,往事上“练”
《互联网高频面试题》:面朝简历学习,春暖花开
《架构 x 系统设计》:摧枯拉朽,掌控面试高频场景题
《精进 Java 学习指南》:系统学习,互联网主流技术栈
《必读 Java 源码专栏》:知其然,知其所以然
👉这是一个或许对你有用的开源项目
国产Star破10w的开源项目,前端包括管理后台、微信小程序,后端支持单体、微服务架构
RBAC权限、数据权限、SaaS多租户、商城、支付、工作流、大屏报表、ERP、CRM、AI大模型、IoT物联网等功能:
多模块:https://gitee.com/zhijiantianya/ruoyi-vue-pro
微服务:https://gitee.com/zhijiantianya/yudao-cloud
视频教程:https://doc.iocoder.cn
【国内首批】支持 JDK17/21+SpringBoot3、JDK8/11+Spring Boot2双版本
来源:juejin.cn/post/7359467967019139108
一、需求背景
随着公司业务的发展,订单系统的数据量和访问量日益增长,单库单表的架构已经无法满足我们的需求。主要面临以下问题:
-
数据量大
:单一数据库存储所有订单数据,导致数据量过大,影响查询效率。
-
并发压力大
:大量用户同时访问系统,产生高并发请求,对数据库造成较大压力。
-
扩展性差
:当需要对订单表进行改动时,大量的数据造成表结构修改时间变长。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
二、业务现状
订单系统目前面临以下几个关键问题及相应的解决思路:
| 问题类型 | 当前状况 | 解决方案 |
|---|---|---|
| 主键设计问题 |
订单表有主键orderId和唯一索引orderNo,orderId依赖数据库自增,orderNo自定义生成并且后4位为类用户id,内部场景用orderId进行数据传递,外部场景用orderNo进行数据传递。 |
去除数据库自增,将orderId和orderNo进行合并,将自定义编号作为唯一主键,内外部场景全部采用orderNo进行数据传递。 |
| 索引过多 |
订单表超过10个索引,部分索引用于C端场景,部分索引用于B端场景。 |
将OLTP中的订单数据同步到OLAP数据库中;确保所有C端场景能够命中分库分表的分片键;将B端分析场景进行剥离,例如查询订单列表,在OLAP数据库中进行查询,再根据订单主键CRUD时,再走OLTP数据库。 |
| 历史数据不规范 |
订单表中存在部分老数据,老orderNo没有采用后4位是类用户id,并且老orderNo中可能存在字母。 |
借助Flink将老订单编号数据进行清洗(数据清洗技术方案另行商议),统一采用现有订单编号规则。 |
| 关联表设计不一致 |
订单表存在一些拓展表,比如订单位置、订单申诉记录等,有些采用orderNo进行关联,有些采用orderId进行关联。 |
统一采用主键进行关联,并且需要保证关联字段为分片键。如果有分库,最好将拓展表也进行分库分表,并且需要保证拓展表的分库分表规则和原表一致。 |
| 表结构冗余 |
订单表中字段过多,有计费、开票、退款等非核心数据。 |
考虑纵向拆分,可以从以下几个方面考虑:是否核心、更新是否频繁、字段长度是否过大。 |
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
三、技术选型
1. 分库分表和分布式数据库对比
理解不同类型数据库的特点 :
-
普通数据库
:通常采用传统的垂直架构,由单一的数据库服务器提供数据存储和查询服务。
-
分布式数据库
:采用水平分片的方式,将数据分散到多个数据库服务器上,实现数据的高可用性和可扩展性。
-
云原生数据库
:基于云计算技术构建,具有容器化、微服务等特性,可以快速部署和扩展。
-
云原生分布式数据库
:结合了分布式数据库和云原生数据库的特点,实现高性能、高可用、可扩展的数据库服务。
| 产品名称 | PolarDB-分区表 | OceanBase | PolarDB-X | TIDB | 传统分库分表 |
|---|---|---|---|---|---|
| 开发团队 |
阿里-阿里云团队 |
阿里-蚂蚁团队 |
阿里-阿里云团队 |
PingCAP团队 |
根据具体实现和需求可能有多个开发团队参与 |
| 类型 |
云原生数据库 |
分布式数据库 |
云原生分布式数据库 |
分布式数据库 |
传统数据库 |
| 应用场景 |
HTAP(行列混合) |
HTAP(行列混合) |
OLTP(行存索引) |
HTAP(行列混合) |
OLTP(行存) |
| 产品优势 |
一写多读、共享分布式存储、计算与存储分离、自动读写分离、高速链路互联、数据可靠性和强一致性、维护成本很低、支持列存索引 |
可满足金融级容灾标准、水平扩展、支持多租户资源隔离、支持列存索引、支持空间索引 |
支持数据强一致性、支持水平扩展、列存索引(灰度中) |
水平扩展、实时HTAP、行列混合 |
灵活性强、不需要进行数据库迁移 |
| 产品劣势 |
分区算法只能采用单一key、行存节点进行了分区,列存节点也会分区、分区表不支持空间类型 |
成本比PolarDB贵一倍、涉及到数据库迁移 |
成本较高、涉及到数据库迁移、列存索引还在灰度中、OLAP依赖并行计算、目前不支持mysql8.0 |
不属于阿里云体系、运维成本较高、涉及到数据库迁移、不支持空间类型 |
考虑分布式事务兼容性、需要集成中间件 |
| 分片原理 |
推荐使用分区表代替分库分表 |
基于分布式技术的分片、无共享架构实现数据的分散存储和处理。 |
基于MySQL内核的分片、通过特定的存储计算分离架构实现数据的分散存储和处理。 |
基于TiKV内核的分片、通过Raft协议实现数据的一致性复制和分散存储。 |
根据业务需求和自定义的分片规则进行数据分散存储和处理;可以根据具体的实现方式采用不同的分片算法和策略。 |
| 适用场景 |
单一分片键场景、需要HTAP能力、对维护成本敏感 |
金融级应用、多租户场景、需要高可用和强一致性 |
大型OLTP系统、需要水平扩展、对一致性要求高 |
需要HTAP能力、开源社区活跃、需要水平扩展 |
成本敏感、技术栈固定、需要灵活配置 |
| 文档地址 |
PolarDB |
OceanBase |
PolarDB-X |
TIDB |
ShardingSphere |
2. 分库分表方案对比
| 中间件名称 | ShardingSphere-JDBC | ShardingSphere-Proxy | Mycat |
|---|---|---|---|
| 类型 |
客户端分表 |
数据库代理 |
数据库代理 |
| 开发团队 |
Apache |
Apache |
Mycat社区 |
| 优势 |
轻量级、易于集成、支持多种数据源、提供分布式事务和读写分离功能 |
功能丰富、支持多种数据源、提供分布式事务、读写分离、分布式主键生成等功能、业务无侵入、支持异构语言 |
开源免费、功能完善、支持多种数据源、提供分布式事务、读写分离、分布式序列等功能、适用于各种项目 |
| 劣势 |
代码改造、集成分布式事务困难、配置较为繁琐 |
性能损耗略高、需要单独部署维护 |
社区支持有限、维护和更新不及时、性能损耗略高、需要单独部署维护 |
| 适用场景 |
对性能要求较高,代码侵入性可接受的OLTP应用 |
支持异构语言,独立于应用程序部署,适用于OLAP应用以及对分片数据库进行管理和运维的场景 |
开源免费,适用于中小规模项目或预算有限的场景 |
| 总结 |
适用于对性能要求较高,代码侵入性可接受的OLTP应用 |
支持异构语言,独立于应用程序部署,适用于OLAP应用以及对分片数据库进行管理和运维的场景 |
开源免费,但社区支持有限、维护和更新不及时。独立于应用程序部署,适用于OLAP应用以及对分片数据库进行管理和运维的场景 |
四、唯一ID方案
在分库分表环境中,设计合适的唯一ID生成方案至关重要。以下是几种常见方案的比较:
1. 数据库自增或Redis自增
-
优点
:实现简单,易于理解
-
缺点
:单点风险、单机性能瓶颈、会暴露业务量
-
适用场景
:小规模系统,数据量不大且增长缓慢的场景
2. Snowflake算法

组成部分 :
-
1位符号位:始终为0
-
41位时间戳:精确到毫秒,可使用69年
-
10位工作机器ID:可支持1024个节点
-
12位序列号:同一毫秒内可生成4096个ID
特点分析 :
-
优点
:高性能高可用、易扩展、ID有序
-
缺点
:需要独立中心节点,时钟回拨可能造成ID重复、没有业务标识
-
适用场景
:高并发分布式系统,每秒生成数万ID的场景
3. UUID/随机算法
-
优点
:简单、无需中心化节点
-
缺点
:生成ID较长,有极小重复几率,不利于索引性能
-
适用场景
:对ID长度不敏感,且对性能要求不高的系统
4. 美团分布式ID生成-Leaf
实现方式 :
-
Leaf-snowflake
:通过集群部署,自动剔除时钟回拨的节点,避免ID重复
-
Leaf-segment
:在数据库自增基础上改进,加入批量生成和本地缓存机制
特点分析 :
-
优点
:高可用、解决自增和Snowflake部分缺点
-
缺点
:弱依赖ZooKeeper,需要独立部署Leaf系统
-
适用场景
:大型分布式系统,对ID生成有高可用要求的场景
5. 自定义业务ID
示例格式 :订单类型(1) + 业务类型(1) + 时间戳yyMMddHHmmss(12) + 随机数(4) + 类用户id后4位
特点分析 :
-
优点
:单机生成、含业务属性、含用户标识、有顺序性
-
缺点
:过万QPS情况下容易出现ID冲突
-
适用场景
:中小型系统,对ID可读性有要求的业务
五、分片键和分片策略选择
1. 时间范围(Range)
| 特性 | 说明 |
|---|---|
| 适用场景 |
数据有明显的时间属性,例如日志表、记录表、统计表等 |
| 优点 |
天然分片,好扩展,方便范围查询和排序操作,也可以方便数据归档 |
| 缺点 |
数据可能分布不均匀,易引起单机负载过大的问题 |
2. 租户ID(List)
| 特性 | 说明 |
|---|---|
| 适用场景 |
数据具有明显业务标识,例如Saas系统中的表按照租户ID、订单表按照订单类型、工单表按照工单类型 |
| 优点 |
可以根据具体的属性值进行分片,方便根据属性值进行查询和过滤操作 |
| 缺点 |
分片规则不好维护,可能产生数据倾斜,数据不好扩容 |
3. 自定义业务ID(Hash)
| 特性 | 说明 |
|---|---|
| 适用场景 |
常用于互联网C端场景,例如根据用户ID分片,可以轻松的根据用户ID查找用户所有数据 |
| 优点 |
数据分布均匀,可以实现负载均衡 |
| 缺点 |
数据扩容困难,范围查询效率较低 |
六、最佳实践
结合上述技术选型对比,并从数据迁移成本、可维护性考虑,最终决定采用ShardingSphere-JDBC分库分表方案。
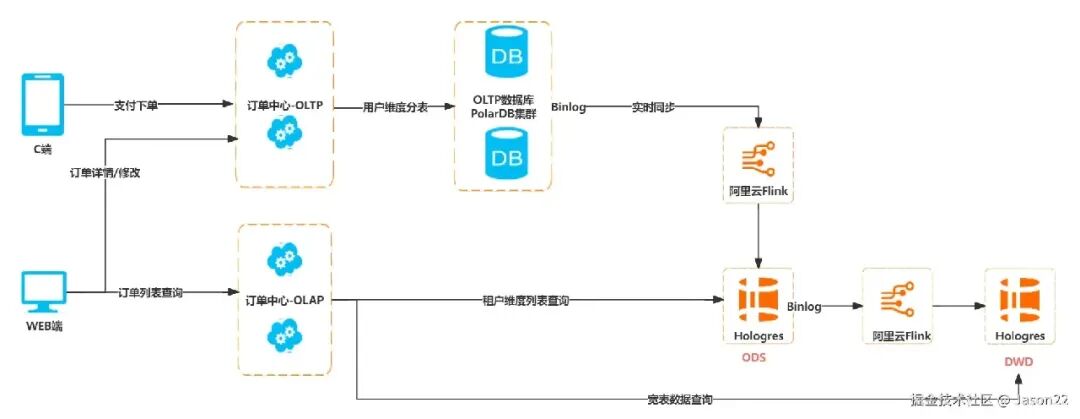
1. 改造点梳理
1.1 数据库结构改造
| 改造项 | 具体内容 |
|---|---|
| 订单表合并字段 |
创建新订单表,将orderNo和orderId进行合并,统一采用自定义编号,自定义编号长度会超过long最大值,需要采用string类型 |
| 关联表改造 |
将有orderId字段的相关表进行改造,统一通过自定义编号进行关联 |
| 字段剥离 |
将订单表中多余字段进行剥离(待定 ) |
1.2 代码改造
| 改造项 | 具体内容 |
|---|---|
| 数据源隔离 |
区分OLTP请求和OLAP请求,并从数据源进行隔离 |
| 引入中间件 |
引入ShardingJDBC,并配置分片键、分库分表数据源、分布式事务代理 |
| 查询优化 |
join查询改造,分表后的关联查询必须带有分片键 |
1.3 数据清洗
| 清洗项 | 具体内容 |
|---|---|
| 订单号清洗 |
对不符合规则的老订单号进行清洗,生成新订单号,并记录新老订单号关系 |
| orderNo关联清洗 |
对有关联orderNo的表进行清洗,将老订单号替换成新订单号 |
| orderId关联清洗 |
对有关联orderId的表进行改造清洗,将orderNo注入到有orderId的关联表中 |
1.4 数据分片
数据规模估算 :
-
现在日订单高峰期20W,按照当前业务5倍进行规划,并预计10年订单量
-
日订单量100W,年订单量3.6亿,10年订单量36亿
-
允许单表最大订单量约5000W,36亿/5000W = 72,为了满足一致性hash原则2^n,取64张表
2. 分布式事务Seata接入
参考SpringCloud多数据源接入Seata和ShardingJDBC最佳实践
3. 实施步骤
| 步骤 | 具体内容 |
|---|---|
| 新建库表 |
在新订单库中,创建订单主表和分表,主要字段包括:订单编号、用户ID、订单状态、金额等信息 |
| 生成新订单号 |
离线生成新订单号并记录新老订单号关系表order_new_relation,保存原订单ID、原订单编号和新订单编号 |
| Flink数据同步 |
通过Flink将老订单数据与关系表进行关联,使用新订单号替换旧数据,按照分片规则将数据同步到对应分表;同时处理订单拓展表的同步 |
七、风险评估与应对措施
| 风险点 | 可能影响 | 应对措施 |
|---|---|---|
|
分片键选择不当 |
查询效率低下,数据分布不均 |
1. 充分分析业务查询模式 2. 选择高频查询字段作为分片键 3. 必要时进行双写或异构索引 |
|
数据迁移风险 |
数据丢失,服务中断 |
1. 制定详细的迁移计划并演练 2. 增量同步 + 全量校验 3. 准备回滚方案 |
|
分布式事务一致性 |
数据不一致,业务异常 |
1. 使用成熟的分布式事务框架 2. 降低分布式事务粒度 3. 实现补偿机制和监控告警 |
|
查询性能下降 |
用户体验差,系统响应慢 |
1. SQL优化,避免跨分片查询 2. 合理使用缓存 3. 添加读写分离和索引 |
|
应用代码改造工作量大 |
开发周期延长,引入bug |
1. 分阶段实施 2. 完善测试用例 3. 采用灰度发布策略 |
八、常见问题及解决方案
Q1: 如何处理跨分片的分页查询?
解决方案 :
-
使用流式查询避免大offset
-
使用上次查询的最后一条记录ID作为条件
-
对于复杂报表查询,建议使用OLAP数据库
Q2: 分库分表后如何保证唯一性约束?
解决方案 :
-
业务层面进行唯一性校验
-
使用全局唯一ID生成器
-
使用分布式锁进行控制
Q3: 如何进行数据扩容?
解决方案 :
-
对于Hash分片,采用翻倍扩容(如64张表扩展到128张表)
-
使用一致性Hash算法减少数据迁移
-
提前使用FlinkCDC进行数据实时同步
Q4: 分布式事务超时如何处理?
解决方案 :
-
设置合理的超时时间
-
Seata有自动补偿机制
-
高并发场景下,减少分布式事务的使用
-
减少大事务的使用
九、总结
本方案结合一段时间内未来业务规模、运维成本、服务器成本等多种因素进行考虑,并分析了分区表、分布式数据库、分库分表的区别和优劣势。也简单介绍了一下分库分表需要考虑的唯一ID、分片键、分片算法等问题,并结合实际业务简单梳理了一下改造方案。本文采用停机迁移分库分表方案,如果想要不停机迁移,可以参考大众点评分阶段实施。
备注 :如果只分表不分库也能满足需求的话,分区表其实也是一个不错的选择,不用引入其它第三方组件,mysql就原生支持,并且对开发比较友好。但是PolarDB分区表不支持多个分区键用同一个分区规则,并且PolarDB列存数据也会按照行存的进行分区,有一定的性能损耗。
十、参考资料
-
TIDB技术内幕-说存储
-
大众点评订单系统分库分表实践
-
美团-分布式ID生成系统Leaf介绍
-
SpringCloud多数据源接入Seata和ShardingJDBC最佳实践
欢迎加入我的知识星球,全面提升技术能力。
👉 加入方式,“长按”或“扫描”下方二维码噢:

星球的内容包括:项目实战、面试招聘、源码解析、学习路线。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)