将训练好的BERT分类模型部署到高通跃龙IQ-9075边缘平台(INT8量化+NPU加速)
本文介绍了将PyTorch BERT模型部署到高通IQ-9075边缘计算平台的完整流程。主要内容包括:1)环境准备,配置主机和设备的开发环境;2)将PyTorch模型导出为ONNX格式并进行简化;3)使用校准数据集对模型进行INT8量化;4)通过QNN工具链编译生成NPU可执行文件;5)在设备端进行高效推理。该方案可将模型体积压缩至1/4,推理延迟降至CPU的1/15,同时精度损失控制在1%以内,
💡 前言
在 NLP 领域,BERT(Bidirectional Encoder Representations from Transformers)已成为文本分类、情感分析、意图识别等任务的标配模型。然而,将训练好的 BERT 模型从云端 GPU 服务器迁移到边缘设备上运行,面临着算力受限、内存有限、功耗敏感等一系列工程挑战。将AI模型部署到端侧设备已成为许多项目的最后一公里。
高通跃龙IQ-9075作为一款高性能的边缘计算平台,集成了强大的Hexagon NPU,非常适合运行BERT等NLP模型。
本文将基于我的实际部署经验,手把手示范如何将训练好的PyTorch BERT分类模型,通过ONNX导出、INT8量化和QNN工具链编译,最终在IQ-9075平台设备上利用Hexagon NPU实现高效推理。通过本文的方案,模型体积可压缩至1/4,推理延迟可降至CPU的1/15。
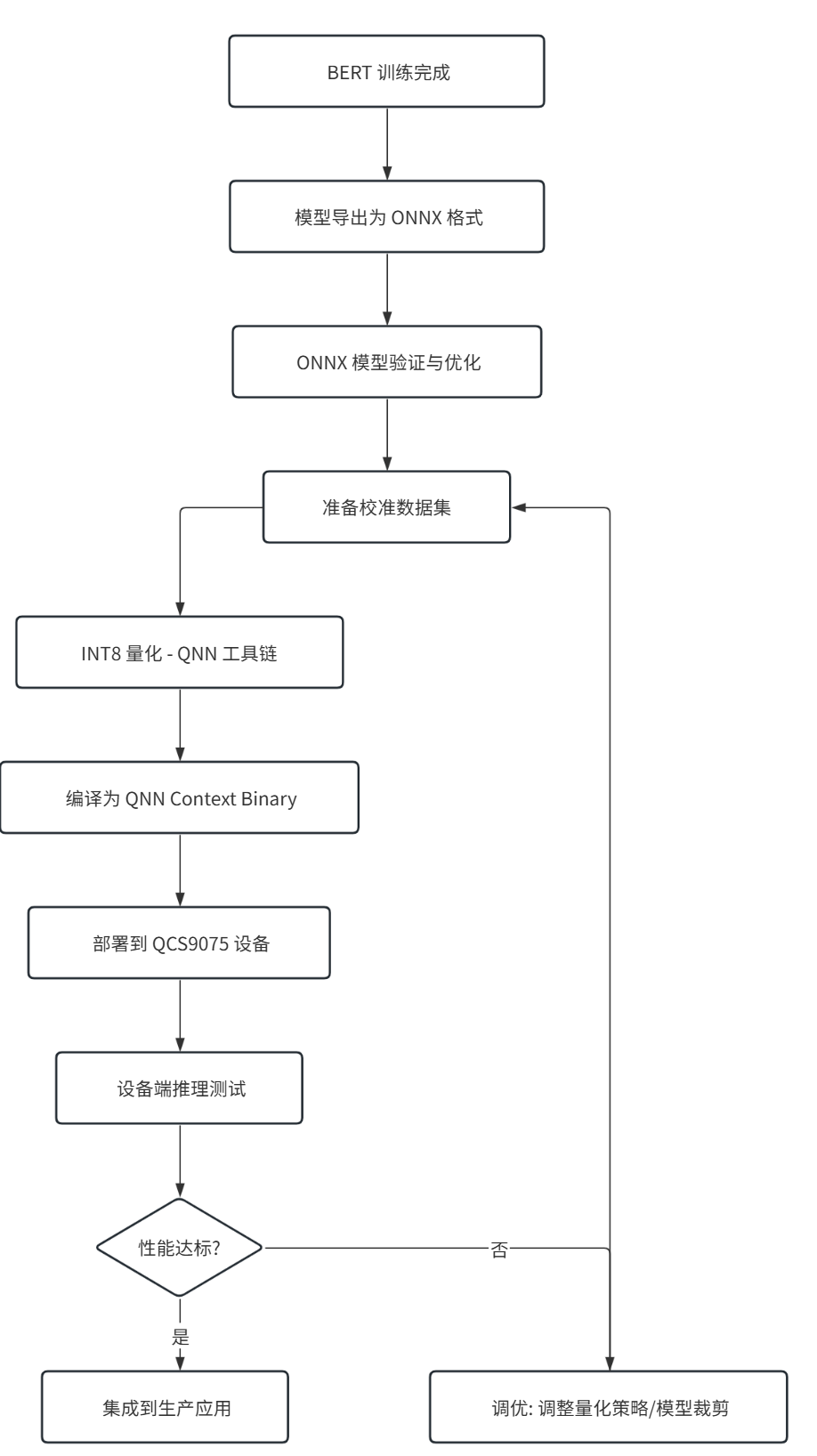
一、整体部署流程概览
从模型训练完成到设备端运行,整个流程主要分为以下五个阶段:
- 环境准备:配置主机开发环境(x86_64)和IQ-9075平台的设备端环境。
- 模型导出:将PyTorch模型导出为ONNX格式,并进行简化。
- 模型量化:使用QNN工具将FP32模型量化为INT8模型。
- 编译部署:将量化后的模型编译为可在NPU上运行的Context Binary,并推送到设备。
- 设备推理:在设备端编写推理脚本,调用QNN Runtime执行模型。
二、环境准备
本阶段需要在主机端(x86_64架构,用于模型转换)和设备端(IQ-9075平台,用于运行推理)分别进行配置。
2.1 主机开发环境 (x86_64)
建议使用Ubuntu系统,并创建独立的Python虚拟环境。
# 1. 创建 Python 虚拟环境
python3 -m venv bert_deploy_env
source bert_deploy_env/bin/activate
# 2. 安装核心依赖
pip install torch torchvision transformers -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install onnx onnxruntime onnxsim -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install numpy pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
2.2 安装 Qualcomm AI Engine Direct SDK (QNN SDK)
从 Qualcomm Developer 官网下载 QNN SDK(建议 v2.22.x 或更高版本)。解压后,配置主机端环境变量:
# 假设QNN SDK解压在/opt/qcom/aistack/qnn/2.22.0
export QNN_SDK_ROOT=/opt/qcom/aistack/qnn/2.22.0
export PATH=$QNN_SDK_ROOT/bin/x86_64-linux-clang:$PATH
export LD_LIBRARY_PATH=$QNN_SDK_ROOT/lib/x86_64-linux-clang:$LD_LIBRARY_PATH
export PYTHONPATH=$QNN_SDK_ROOT/lib/python:$PYTHONPATH
2.3 IQ-9075 设备端环境 (Ubuntu 24.04)
在设备上安装基础环境,并从主机拷贝QNN Runtime库。
# 1. 设备端基础环境
sudo apt update && sudo apt install -y python3 python3-pip libstdc++6
# 2. 在主机端执行,拷贝QNN Runtime库到设备
scp -r $QNN_SDK_ROOT/lib/aarch64-ubuntu-gcc9.4/ user@9075-device:/opt/qnn/lib/
# 3. 在设备端配置环境变量(建议写入 .bashrc)
export LD_LIBRARY_PATH=/opt/qnn/lib/aarch64-ubuntu-gcc9.4:$LD_LIBRARY_PATH
三、模型导出:PyTorch → ONNX
我们将训练好的BERT模型导出为ONNX格式,这是进入高通工具链的第一步。
3.1 加载训练好的 BERT 模型
假设你已经有了一个训练好的基于 bert-base-chinese 的二分类模型。
import torch
from transformers import BertTokenizer, BertForSequenceClassification
model_path = "./bert_classifier_model" # 你的模型路径
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertForSequenceClassification.from_pretrained(model_path, num_labels=2)
model.eval()
3.2 导出 ONNX
导出时需要特别注意,BERT模型的输入包含 input_ids、attention_mask 和 token_type_ids,并且需要设置动态轴以适应不同的batch size。
# 构造 dummy 输入
dummy_input = tokenizer(
"今天心情很好",
return_tensors="pt",
max_length=128,
padding="max_length",
truncation=True
)
torch.onnx.export(
model,
(dummy_input["input_ids"],
dummy_input["attention_mask"],
dummy_input["token_type_ids"]),
"bert_classifier.onnx",
input_names=["input_ids", "attention_mask", "token_type_ids"],
output_names=["logits"],
dynamic_axes={
"input_ids": {0: "batch_size"},
"attention_mask": {0: "batch_size"},
"token_type_ids": {0: "batch_size"},
"logits": {0: "batch_size"}
},
opset_version=17,
do_constant_folding=True
)
print("ONNX 模型导出完成: bert_classifier.onnx")
3.3 验证与简化 ONNX 模型
使用 onnx 和 onnxsim 对模型进行检查和简化,这能减少后续量化编译时的图复杂度。
import onnx
from onnxsim import simplify
onnx_model = onnx.load("bert_classifier.onnx")
onnx.checker.check_model(onnx_model)
# 简化模型
simplified_model, check = simplify(onnx_model)
assert check, "ONNX 简化失败"
onnx.save(simplified_model, "bert_classifier_sim.onnx")
print("ONNX 模型验证通过并已简化")
为什么要简化? onnxsim 会折叠常量、消除冗余算子,减少后续量化和编译时的图复杂度,对部署效率有显著帮助。
四、模型量化:FP32 → INT8
在边缘设备上,FP32的BERT模型体积大、速度慢。通过INT8量化,可以大幅缩小模型体积并利用NPU加速,而精度损失通常可控制在1%以内。
4.1 准备校准数据集
量化需要一组有代表性的校准数据来统计激活值的动态范围。通常准备100~500条样本即可。
import numpy as np
import os
calibration_texts = [
"产品质量非常好,值得购买",
"快递太慢了,包装也破损了",
"性价比很高,推荐给朋友",
"客服态度很差,不会再来了",
# ... 更多代表性样本
]
calib_data_dir = "./calibration_data"
os.makedirs(calib_data_dir, exist_ok=True)
for i, text in enumerate(calibration_texts):
encoded = tokenizer(
text,
max_length=128,
padding="max_length",
truncation=True,
return_tensors="np"
)
np.save(f"{calib_data_dir}/input_ids_{i}.npy", encoded["input_ids"])
np.save(f"{calib_data_dir}/attention_mask_{i}.npy", encoded["attention_mask"])
np.save(f"{calib_data_dir}/token_type_ids_{i}.npy", encoded["token_type_ids"])
4.2 使用 QNN 工具链进行量化
首先,你需要一个脚本(generate_input_list.py)来生成校准文件的列表,或者手动创建 input_list.txt,内容类似如下:
./calibration_data/input_ids_0.npy
./calibration_data/input_ids_1.npy
...
然后使用 qnn-onnx-converter 工具进行转换和量化。
# 使用 qnn-onnx-converter 转换并量化
qnn-onnx-converter \
--input_network bert_classifier_sim.onnx \
--output_path bert_classifier_quantized.cpp \
--input_list input_list.txt \
--act_bitwidth 8 \
--weight_bitwidth 8 \
--bias_bitwidth 32 \
--use_per_channel_quantization
关键参数说明:
--act_bitwidth 8/--weight_bitwidth 8:激活值和权重量化为INT8。--bias_bitwidth 32:偏置保持INT32以减少累计误差。--use_per_channel_quantization:逐通道量化,对Transformer结构尤为重要。
五、模型编译与部署
5.1 编译为 QNN Context Binary
将量化后的模型编译为可在Hexagon NPU上高效运行的二进制文件。
# 1. 编译模型库
qnn-model-lib-generator \
-c bert_classifier_quantized.cpp \
-b bert_classifier_quantized.bin \
-t aarch64-ubuntu-gcc9.4
# 2. 生成 Context Binary(指定 HTP 后端)
qnn-context-binary-generator \
--model bert_classifier_quantized.so \
--backend $QNN_SDK_ROOT/lib/aarch64-ubuntu-gcc9.4/libQnnHtp.so \
--output_dir ./compiled_model \
--binary_file bert_classifier.serialized.bin
5.2 部署文件到设备
将编译好的模型文件和QNN依赖库传输到IQ-9075设备上。
# 模型文件
scp ./compiled_model/bert_classifier.serialized.bin user@9075-device:/home/user/models/
# QNN Runtime 库(如果之前没传全)
scp $QNN_SDK_ROOT/lib/aarch64-ubuntu-gcc9.4/libQnnHtp.so user@9075-device:/opt/qnn/lib/
scp $QNN_SDK_ROOT/lib/aarch64-ubuntu-gcc9.4/libQnnHtpV75Stub.so user@9075-device:/opt/qnn/lib/
scp $QNN_SDK_ROOT/lib/hexagon-v75/unsigned/libQnnHtpV75Skel.so user@9075-device:/opt/qnn/lib/
六、设备端推理
6.1 使用 Python API 推理
在IQ-9075设备上,我们可以使用ONNX Runtime配合QNN Execution Provider进行推理。
import onnxruntime as ort
import numpy as np
from transformers import BertTokenizer
# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained("./bert_tokenizer")
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
# 创建推理Session,指定QNN Provider
session = ort.InferenceSession(
"bert_classifier_qnn.onnx", # 注意:这里是你的ONNX模型,或者是通过QNN加载的接口,实际QNN推荐直接加载serialized bin
sess_options=sess_options,
providers=["QNNExecutionProvider"],
provider_options=[{
"backend_path": "/opt/qnn/lib/libQnnHtp.so",
"htp_performance_mode": "burst",
"htp_graph_finalization_optimization_mode": "3",
"enable_htp_fp16_precision": "0" # 0 表示使用INT8
}]
)
def predict(text: str) -> dict:
encoded = tokenizer(
text,
max_length=128,
padding="max_length",
truncation=True,
return_tensors="np"
)
outputs = session.run(
["logits"],
{
"input_ids": encoded["input_ids"].astype(np.int64),
"attention_mask": encoded["attention_mask"].astype(np.int64),
"token_type_ids": encoded["token_type_ids"].astype(np.int64)
}
)
logits = outputs[0]
probs = np.exp(logits) / np.sum(np.exp(logits), axis=-1, keepdims=True)
pred_label = np.argmax(probs, axis=-1)[0]
label_map = {0: "负面", 1: "正面"}
return {
"label": label_map[pred_label],
"confidence": float(probs[0][pred_label]),
"probabilities": {label_map[i]: float(probs[0][i]) for i in range(2)}
}
# 测试
result = predict("这款手机拍照效果非常出色,电池续航也很好")
print(f"预测结果: {result['label']}(置信度: {result['confidence']:.4f})")
6.2 使用QNN C++ Runtime API(高性能生产环境)
对于追求极致延迟的场景,推荐使用C++ API直接调用QNN Runtime。核心流程如下:
- 加载后端库(
libQnnHtp.so)。 - 从
serialized.bin创建QNN Context。 - 设置输入Tensor(
input_ids,attention_mask,token_type_ids)。 - 执行图推理。
- 读取输出 Tensor(logits)
- 后处理:softmax → 分类结果
七、性能对比与精度验证
7.1 各推理后端性能对比
以下是在IQ-9075上使用不同后端、不同精度推理BERT-base(序列长度128)的典型性能数据: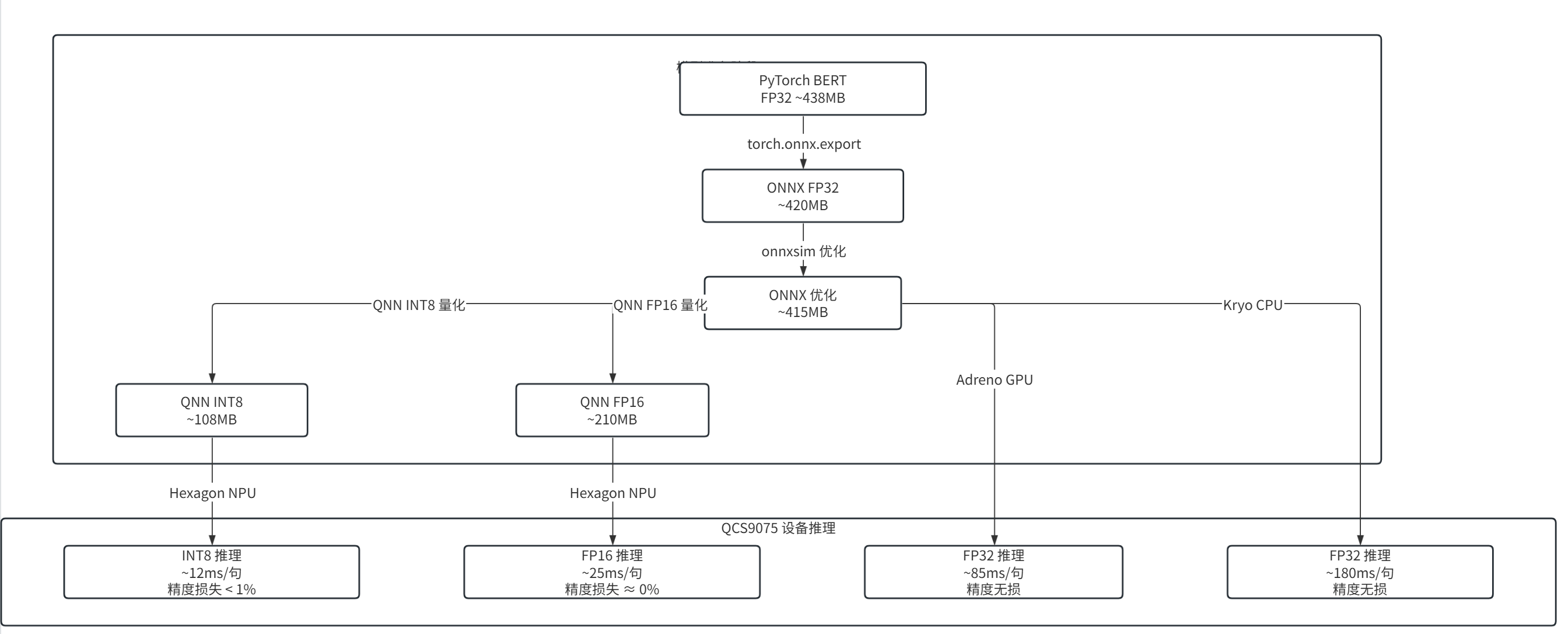
| 推理后端 | 精度 | 模型大小 | 延迟(128 tokens) | 吞吐量 | 功耗 |
|---|---|---|---|---|---|
| Hexagon NPU | INT8 | ~108 MB | ~12 ms | ~83 句/秒 | 低 |
| Hexagon NPU | FP16 | ~210 MB | ~25 ms | ~40 句/秒 | 中 |
| Adreno GPU | FP32 | ~420 MB | ~85 ms | ~12 句/秒 | 中高 |
| Kryo CPU | FP32 | ~420 MB | ~180 ms | ~6 句/秒 | 高 |
结论:INT8量化 + Hexagon NPU 是最佳部署方案,延迟降至CPU的1/15,模型体积压缩至1/4。
7.2 量化前后精度对比
建议编写脚本对比量化前后的模型精度,确保满足业务要求。
from sklearn.metrics import classification_report
def evaluate_model(session, tokenizer, test_data, label_map):
predictions = []
labels = []
for text, label in test_data:
encoded = tokenizer(text, max_length=128, padding="max_length", truncation=True, return_tensors="np")
outputs = session.run(["logits"], {
"input_ids": encoded["input_ids"].astype(np.int64),
"attention_mask": encoded["attention_mask"].astype(np.int64),
"token_type_ids": encoded["token_type_ids"].astype(np.int64)
})
pred = np.argmax(outputs[0], axis=-1)[0]
predictions.append(pred)
labels.append(label)
print(classification_report(labels, predictions, target_names=list(label_map.values())))
return accuracy_score(labels, predictions)
# ... 加载FP32和INT8的session ...
acc_fp32 = evaluate_model(session_fp32, tokenizer, test_data, label_map)
acc_int8 = evaluate_model(session_int8, tokenizer, test_data, label_map)
print(f"FP32精度: {acc_fp32:.4f}, INT8精度: {acc_int8:.4f}, 差异: {abs(acc_fp32 - acc_int8):.4f}")
八、常见调优策略
8.1 量化前后精度对比脚本
import numpy as np
from sklearn.metrics import accuracy_score, f1_score, classification_report
def evaluate_model(session, tokenizer, test_data, label_map):
predictions = []
labels = []
for text, label in test_data:
encoded = tokenizer(
text, max_length=128, padding="max_length",
truncation=True, return_tensors="np"
)
outputs = session.run(["logits"], {
"input_ids": encoded["input_ids"].astype(np.int64),
"attention_mask": encoded["attention_mask"].astype(np.int64),
"token_type_ids": encoded["token_type_ids"].astype(np.int64)
})
pred = np.argmax(outputs[0], axis=-1)[0]
predictions.append(pred)
labels.append(label)
print(classification_report(labels, predictions, target_names=list(label_map.values())))
return accuracy_score(labels, predictions)
分别加载 FP32 和 INT8 模型进行对比
acc_fp32 = evaluate_model(session_fp32, tokenizer, test_data, label_map)
acc_int8 = evaluate_model(session_int8, tokenizer, test_data, label_map)
print(f"FP32 精度: {acc_fp32:.4f}")
print(f"INT8 精度: {acc_int8:.4f}")
print(f"精度差异: {abs(acc_fp32 - acc_int8):.4f}")
8.2 常见调优策略
如果INT8量化后精度下降超过预期,可以尝试以下策略:
- 混合精度量化:对Embedding层和最后的分类头保持FP16,仅对Transformer Encoder层使用INT8。
- 增加校准数据:确保校准数据覆盖了各类别的典型样本,更具代表性。
- 量化感知训练(QAT):在训练阶段模拟量化噪声,让模型提前适应,从源头提升量化后精度。
- 调整量化粒度:从per-tensor量化切换到更精细的per-channel量化。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)