基于CNN的实时疲劳检测系统
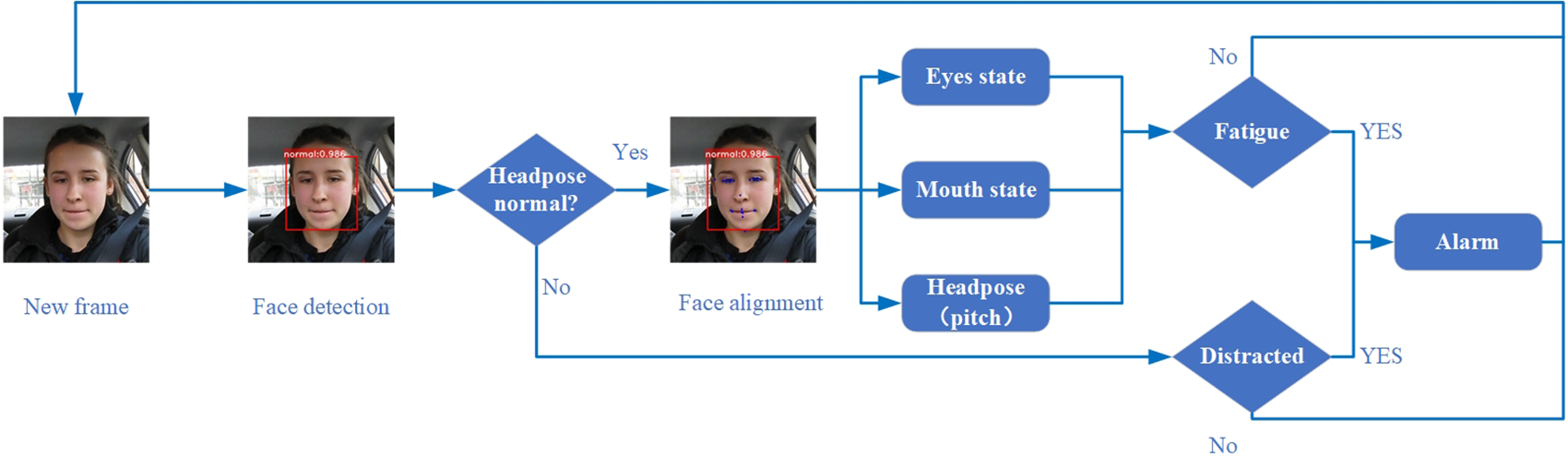
本文提出一种在边缘设备上实时运行的驾驶员疲劳检测系统,结合卷积神经网络与面部对齐技术。通过轻量级人脸检测网络LittleFace实现高精度检测,并优化SDM算法提升对齐速度。系统利用EAR、MAR和头部姿态多特征融合判断疲劳状态,在Jetson Nano上达到58 FPS,平均准确率达89.55%。
基于卷积神经网络和面部对齐的边缘计算设备驾驶员疲劳检测
李晓峰,夏佳豪,曹立波,张冠军和冯谢兴
摘要
大多数基于视觉的疲劳检测方法缺乏高性能且鲁棒的人脸检测器。它们使用单一检测特征来检测驾驶员疲劳,并且无法在边缘计算设备上实现实时效率。针对这些问题,本文提出了一种可在边缘计算设备上实时运行的基于卷积神经网络的驾驶员疲劳检测系统。该系统首先使用所提出的人脸检测网络LittleFace定位人脸,并将人脸分类为两种状态:小偏航角状态“正常”和大偏航角状态“分心”。其次,仅在“正常”状态的人脸区域执行速度优化的SDM算法,以解决大角度侧脸时人脸对齐准确率下降的问题,同时利用“分心”状态检测驾驶员分心。最后,从获得的关键点计算特征参数眼睛闭合率(EAR)、嘴部开合度(MAR)和头部俯仰角,并分别用于检测驾驶员疲劳。进行了综合实验以评估所提出的系统,结果表明其具有实用性与优越性。我们的人脸检测网络LittleFace在边缘计算设备英伟达Jetson Nano上,AFLW测试集上可达到88.53%mAP,帧率为58 FPS。在YawDD、300 W和DriverEyes上的评估结果显示,所提出系统的平均检测准确率可达89.55%。
关键词 卷积神经网络,驾驶员监控,驾驶员疲劳检测,人脸检测,面部对齐,嵌入式系统
引言
在过去十年中,全球范围内因驾驶员疲劳导致了大量的严重交通事故,造成了巨大的人员伤亡和财产损失,已成为一个严重的社会问题。根据国家高速公路安全局的统计数据,美国每年至少有10万起交通事故与驾驶员疲劳有关。在欧洲,统计数据显示约10%–20%的交通事故是由驾驶员警觉性下降引起的。在英国,高达20%的交通事故由驾驶员疲劳或分心造成。在中国,因疲劳驾驶导致的死亡人数占所有高速公路事故死亡人数的14.8%。因此,在驾驶过程中对驾驶员注意力进行监测并实现早期预警,对于道路交通安全具有重要意义。
当前的驾驶员疲劳检测方法可分为三类:(1)基于生理信号的方法。这些方法利用驾驶员的生理信号来检测驾驶员疲劳,例如脑电图(EEG)、眼电图(EOG)和心电图(ECG)。(2)基于车辆的方法。这些方法通过分析车辆的状态来检测驾驶员疲劳,例如方向盘转动、车道偏离、加速度和制动频率。(3)基于视觉的方法。这些方法通过使用图像处理技术提取和分析驾驶员的视觉特征(如眼部状态、嘴部状态和头部姿态)来检测驾驶员疲劳。基于生理信号的方法(尤其是脑电图)比其他方法具有更高的准确率。然而,这些方法通常需要佩戴相关仪器和设备,安装不便且容易使驾驶员感到不适。基于车辆的方法容易受到驾驶习惯、技能、车辆参数、道路条件等因素的影响,检测往往不够及时。基于视觉的疲劳检测方法因其对驾驶员无侵入性且所需设备易于安装,得到了广泛研究和应用。
基于视觉的驾驶员疲劳检测方法需要人脸检测算法。目前基于视觉的驾驶员疲劳检测方法大多采用基于机器学习的算法进行人脸检测。最具代表性的是维奥拉和琼斯提出的级联人脸检测器,他们利用类Haar特征和AdaBoost训练级联分类器,许多研究采用该方法来定位驾驶员人脸。尽管该算法具有良好的性能和实时效率,但研究表明,由于复杂场景和人脸外观变化较大,在实际应用中其准确率可能会显著下降。近年来,深度学习在目标检测等计算机视觉领域取得了显著成果,这促使研究人员将神经网络应用于人脸检测。张等人使用级联CNN以由粗到细的方式同时预测人脸和关键点位置,这将基于深度学习的人脸检测的准确率和运行速度提升到了一个新的水平。然而,对于嵌入式边缘计算设备而言,计算复杂度仍然过大。
在人脸检测之后,基于视觉的驾驶员疲劳检测方法会提取面部区域中的驾驶员面部特征(如眼部状态、嘴部状态)和头部姿态,以进一步判断驾驶员是否处于疲劳状态。对于通过分析眼部状态来检测疲劳的方法,通常使用PERCLOS(眼睛闭合百分比)来判断驾驶员的警觉程度,该指标已被证明是一种可靠的度量方式。但大多数基于眼部状态分析的检测方法不仅计算量大,而且容易受到光照和太阳镜的影响。Abtahi等人通过打哈欠分析来检测驾驶员疲劳,这类方法的缺点是有时难以将打哈欠与说话或唱歌等场景区分开来。Bergasa等人通过分析点头频率来检测驾驶员疲劳。Batista采用模型方法估计面部朝向,以监控驾驶员注意力方向。然而,传统的基于模型的头部姿态估计方法对光照变化、振动噪声以及大角度非常敏感。这是因为其检测精度依赖于面部特征,而基于深度学习的头部姿态估计方法虽然精度较高,但运行效率较低。Han等人将头部姿态估计视为一个多分类任务,在大头部姿态角度下表现良好,但在头部姿态接近分类阈值时,预测精度会下降。尽管上述提到的特征均能在一定程度上取得较好的效果,但仅使用其中一种特征会导致漏检或误检。
在驾驶员疲劳检测系统中应用面部对齐算法,可以获取人脸各部分的关键点信息,从中可提取用于判断驾驶员疲劳的所有面部特征。程等人使用开源机器学习库Dlib提供的面部对齐算法获取人脸的68个关键点,然后基于眼睛闭合率(EAR)和嘴部开合度(MAR)提取了21个候选特征。尽管Dlib的面部对齐算法具有较高的检测速度,但其检测精度尚不理想,尤其是在头部偏航角较大时。熊和托雷提出了一种级联线性回归方法——监督下降方法(SDM),与Dlib的方法相比,对齐精度显著提高,但在大偏航角情况下仍会下降。此外,该方法无法在边缘计算设备上实时运行。扎德等人使用卷积专家网络(CEN)作为局部检测器来定位关键点,显著提升了对齐性能,特别是针对大角度侧脸。开源人脸分析工具包OpenFace2.0优化了该方法的速度,并添加了跟踪算法以进一步提高检测速度,但其计算复杂度仍然很高,难以应用于实际场景。
本文提出了一种基于卷积神经网络的驾驶员疲劳检测系统,该系统通过面部对齐提取驾驶员疲劳特征,并可在边缘计算设备上实时运行。为了解决基于深度学习的人脸检测器因运行效率低而无法应用于疲劳检测系统的问题,本文提出了一种基于单次多框检测器(SSD)框架的人脸检测网络,该网络可在边缘计算设备上实现高检测精度和实时检测。为了提取驾驶员的疲劳特征,本文优化了SDM在面部对齐中的应用,提高了运行速度,同时确保了所需关键点信息的完整性。针对大头部偏航角下面部对齐与头部姿态估计精度下降的问题,所提出的检测系统利用人脸检测网络根据头部偏航角对面部进行分类。随后仅在小偏航角状态的图像中执行面部对齐与头部姿态估计,而大偏航角状态则用于检测驾驶员分心。系统通过获得的关键点计算眼睛特征参数眼睛纵横比(EAR)、嘴部参数嘴巴纵横比(MAR)以及头部姿态,并据此分别检测驾驶员疲劳状态。
本文的主要贡献总结如下:
- 本文提出了一种基于卷积神经网络和面部对齐的驾驶员疲劳检测系统,可在边缘计算设备上实时运行。我们优化了SSD并将其与我们的多类别非极大值抑制相结合,以同时实现人脸定位和粗略头部姿态估计。优化后的模型在边缘计算设备英伟达Jetson Nano上最高可达58帧每秒的运行速度。
- 该检测系统利用面部对齐获取多个特征参数以检测驾驶员疲劳。通过优化原始SDM并结合人脸分类,显著提高了面部对齐的运行速度,并解决了在大头部偏航角下面部对齐与头部姿态估计准确率下降的问题。
- 由于缺乏关于驾驶员眼部状态变化的公开数据集,我们在实际驾驶场景中收集并标注了视频数据集DriverEyes,该数据集将公开发布于:https://github.com/MrLeexm/DriverEyes
方法 整体框架
所提出的检测系统的整体流程图如图1所示。为了加快检测速度,摄像头捕获的驾驶员图像被预处理为320×320的灰度图像,然后输入到人脸检测网络中。在定位图像中的人脸的同时,人脸检测网络根据头部偏航角将人脸分类为“正常”或“分心”状态。在完成人脸检测后,系统使用速度优化的SDM进行面部对齐,以进一步提取特征。为了应对大头部偏航角下人脸对齐准确率和头部姿态估计准确率下降的问题,仅在小角度状态“正常”下进行面部对齐,以获得24个关键点的坐标。然后通过这些坐标计算眼部状态参数眼睛闭合率(EAR)、嘴部状态参数嘴部开合度(MAR)以及头部俯仰角。对于眼睛闭合率(EAR)和头部俯仰角,本文根据PERCLOS算法,通过统计一段时间内异常帧的数量是否超过设定阈值来进行疲劳检测。嘴部开合度(MAR)则通过检测打哈欠来判断驾驶员疲劳。这三种疲劳检测方法相互独立,满足其中一种或多种条件即可判定为疲劳。对于大角度状态“分心”,系统会统计在此状态下的帧数,以检测驾驶员分心情况。系统还会统计在一段时间内未检测到驾驶员的帧数,以判断驾驶员是否处于正确的驾驶位置。

人脸检测网络
网络结构
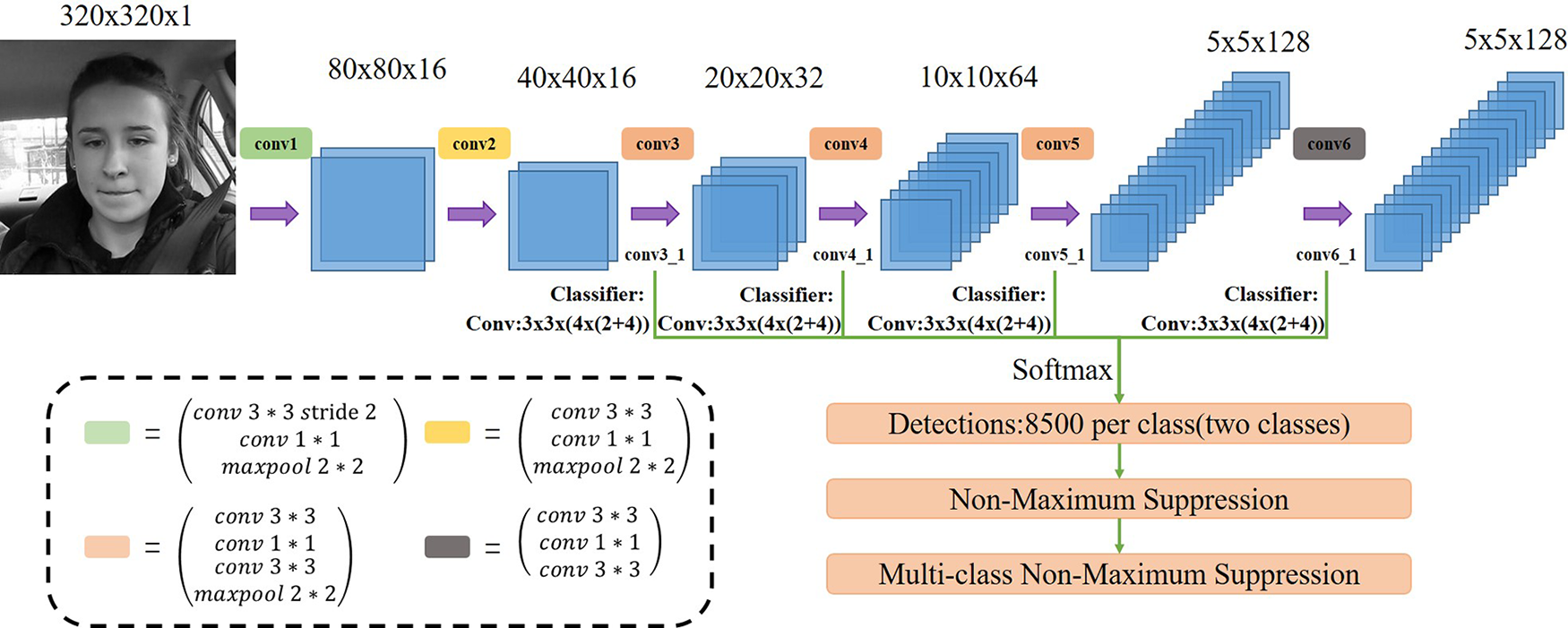
本文提出的人脸检测网络称为LittleFace,其结构如图2所示。参考SSD和libface的网络结构,LittleFace采用一个小型卷积神经网络作为主干特征提取网络,以在边缘计算设备上实现实时检测。与原始的SSD结构相比,LittleFace的层数更少,共使用六组卷积操作,总计16个卷积层和5个最大池化层。每个池化层的区域为2×2,步长为2。LittleFace以灰度图像作为输入,并大量使用1×1卷积滤波器来减少参数数量和计算复杂度。每个卷积层均采用修正线性单元(ReLu)作为激活函数,以增强网络的非线性能力,并在较少的训练步数下达到相同的准确率。ReLu激活函数如下所示:
$$
f(x) = \max(x, 0)
$$
LittleFace对conv3_1、conv4_1、conv5_1和conv6_1四个特征图上的每个默认框集预测各面部状态存在的置信度,并生成对默认框的调整以更精确地拟合人脸。预测结果被合并后通过Softmax激活,在[0,1]中对得分进行归一化,然后首先进行非极大值抑制(NMS)以去除低置信度的重叠预测,再进行所提出的多类别非极大值抑制(Multi-class NMS)以消除人脸的重复预测。
默认框设置
根据SSD的做法,LittleFace在特征图的每个单元格中设置了一系列具有不同尺寸和宽高比的默认框,分别位于卷积层conv3_1、conv4_1、conv5_1和conv6_1。如图2所示,当一个特征单元上有k个默认框时,对每个默认框,我们预测两个面部状态得分,以及相对于原始默认框形状的四个偏移量。这意味着在特征图的每个位置上应用k×(2+4)个滤波器,对于一个m×n的特征图将生成k×(2+4)个输出。用于预测的滤波器均为3×3的滤波器。不同特征图上默认框的尺度按如下方式计算:
$$
s_l = s_{\min} + \frac{s_{\max} - s_{\min}}{n - 1}(l - 1), \quad l \in [1, n]
$$
其中n为4,表示用于预测的特征图数量。$s_{\min}$和$s_{\max}$分别表示最低层特征层和最高层特征层上默认框的尺度。在优化后的模型中,$s_{\min}$为0.2,$s_{\max}$为0.8。对默认框设置不同的宽高比,记为$ar \in {2, 1/2}$。每个默认框的宽度和高度可按如下方式获得:
$$
w_a^l = s_l \sqrt{ar}, \quad h_a^l = s_l / \sqrt{ar}
$$
人脸分类与多类别非极大值抑制
为了解决在大头部偏航角情况下面部对齐与头部姿态估计性能下降的问题,所提出的系统使用人脸检测网络根据头部偏航角的绝对值对人脸进行分类。头部偏航角绝对值小于30°的人脸被划分为“正常”,其余则被划分为“分心”。随后,仅对“正常”状态的人脸执行面部对齐与头部姿态估计,而“分心”状态用于检测驾驶员分心。事实上,我们更倾向于将头部偏航角大于45°的驾驶员视为“分心”,但由于当头部偏航角接近分类阈值时,分类准确率会下降,出于安全考虑,我们使用30°作为分类阈值以提高实际检测准确率。
如图3(a)所示,当图像中头部偏航角的绝对值接近30°时,网络会重复预测人脸,因为此时人脸具有两个类别的特征。为了解决这一问题,我们在进行非极大值抑制(NMS)后对输出结果执行多类别非极大值抑制(Multi-class NMS),在两个类别之间使用Jaccard重叠0.8作为阈值,以去除低置信度的预测。图3(b)展示了对图3(a)应用Multi-NMS后的结果。

训练目标
训练目标包括人脸分类目标和边界框回归目标。损失函数是分类损失和定位损失的加权和:
$$
L(y, c, l, g) = \frac{1}{N} L_{cls}(y, c) + \alpha L_{loc}(y, l, g)
$$
置信度损失$L_{cls}$是Softmax损失,其中$c$为状态置信度。定位损失$L_{loc}$是L2损失,其中$l$和$g$分别为预测框和真实框的参数。N为与真实框匹配的默认框数量。当默认框与真实框匹配时,$y=1$,否则$y=0$。权重参数$\alpha$设为1。
面部对齐
SDM方法
如果检测到“正常”状态,系统将使用SDM进行面部对齐,以定位人脸关键点。SDM是一种级联线性回归方法,可用于最小化非线性最小二乘函数,而面部对齐任务可被视为最小化以下函数的任务:
$$
f(s_0 + \Delta s) = |e(I(s_0 + \Delta s)) - f^ |_2^2
$$
其中$e(\cdot)$为特征提取函数,我们在SDM中使用HOG特征代替SIFT以减少计算量。I是图像中的像素集合,$I(s)$是图像中的关键点集合。$s_0$是从训练数据获得的关键点初始配置。在所提出的检测系统中,我们预测24个关键点而非SDM中的66个关键点,以提高运行速度,这24个关键点足以提取所需的驾驶员疲劳特征。$s^ $是在训练过程中已知的正确关键点。$f^ =e(I(s^ ))$表示正确关键点的HOG特征。
目标是递归地获取更新$\Delta s$,以最小化预测关键点与真实关键点之间的差异。$s$的第一次更新可由以下方程推导得出:
$$
\Delta s_1 = R_0 f_0 + b_0
$$
其中,$R_0$和$b_0$分别为通用的下降方向和偏置项,可在训练过程中学习得到。$f_0$是关键点初始配置的HOG特征。
由于对齐很难通过单步完成,SDM在训练过程中会从以下方程中学习一系列下降方向${R_k}$和偏置项${b_k}$,以递归地更新关键点。
$$
s_k = s_{k-1} + R_{k-1} f_{k-1} + b_{k-1}
$$
$$
\Delta s_k = s^* - s_k
$$
其中$f_{k-1}=e(I(s_{k-1}))$是从先前估计的关键点$s_{k-1}$提取的HOG特征。
在训练过程中,给定一组图像${I_i}$及其对应标注的关键点${s_i^ }$。对于每幅图像,从关键点的初始估计$s_i^0$开始,通过$f_i^0=e(I(s_i^0))$,递归地学习$R_k$和$b_k$,以最小化公式(8),并使用$\Delta s_k^i = s_i^ - s_i^k$更新关键点,从而得到估计结果。关键点$s_i^k$随着迭代次数的增加逐渐收敛到真实关键点$s_i^*$。在我们的应用中,训练过程中进行了五次迭代,表现出良好的收敛效果。
$$
\arg \min_{R_k, b_k} \sum_{I_i} \sum_{s_i^k} |\Delta s_k^i - R_k f_k^i - b_k|^2
$$
对SDM的改进
除了减少预测关键点的数量和替换提取的特征外,我们还对原始SDM算法进行了其他修改。与SDM中从每个关键点周围固定大小的块中提取SIFT特征的操作不同,我们采用了一种由粗到精的特征提取策略。具体而言,随着迭代次数的增加,用于特征提取的关键点数量增加,而围绕关键点进行特征提取的块大小则逐渐缩小。通过应用该策略,计算复杂度降低,运行速度得到提升。在前三个迭代中,我们选择12个关键点来提取HOG特征,其索引编号为{1, 2, 3, 4, 5, 8, 11, 14, 17, 18, 19, 20};在最后两个迭代中,我们选择18个关键点来提取HOG特征,其索引编号为{1, 2, 3, 4, 5, 7, 8, 9, 11, 12, 13, 15, 17, 18, 19, 20, 21, 23}。用于在这些关键点周围提取HOG特征的块是宽度分别为瞳孔间距的1.8、1.4、1、0.6、0.4倍的矩形。图4展示了SDM的一个样本结果,其上标注了关键点的索引编号。
驾驶员行为分析
该检测系统通过分析“正常”状态图像中的眼部状态、嘴部状态和头部姿态来检测驾驶员疲劳,且这三种检测方法彼此不依赖。该检测系统还使用“分心”状态的图像来检测驾驶员分心,并使用未检测到驾驶员人脸的图像来检测驾驶员不在正确驾驶位置的情况。
眼部状态分析
参考PERCLOS算法,系统通过统计在一段时间内的帧中闭眼帧数是否超过设定阈值来检测驾驶员疲劳。双眼的平均宽高比用于表示驾驶员眼睛的睁开程度。以下公式展示了如何计算左眼的EAR值,右眼同理。
$$
\text{EAR} = \frac{|P_6 - P_{10}| + |P_7 - P_9|}{2 \times |P_5 - P_8|}
$$
其中$P_i$是第$i$个特征点的坐标。在实际应用中,系统会学习并记录驾驶员在正常睁开状态下的眼睛闭合率(EAR),然后乘以0.2倍该EAR值根据PERCLOS算法中的P80标准来判断眼睛是否闭合。研究表明,当驾驶员疲劳时,PERCLOS值通常高于0。因此,系统通过统计在100帧中闭眼帧的数量是否超过60帧来判断驾驶员是否疲劳。
嘴部状态分析
驾驶员疲劳时也会打哈欠,因此系统通过嘴巴纵横比(MAR)来检测打哈欠。当驾驶员打哈欠时,MAR值相较于闭嘴和正常说话状态会显著增加,并且持续较长时间。公式(10)展示了如何计算MAR。通过对YawDD数据集和采集数据的分析,系统判断当MAR超过0.8并持续超过3秒时,驾驶员处于打哈欠状态。
$$
\text{MAR} = \frac{|P_{18} - P_{24}| + |P_{22} - P_{20}|}{|P_{21} - P_{23}| + |P_{17} - P_{19}|}
$$
头部姿态分析
驾驶员在疲劳时可能会频繁点头。检测系统采用基于模型的方法来监测驾驶员的头部俯仰角。与眼部状态分析方法类似,系统通过统计100帧中头部俯仰角异常(绝对值大于30°)的帧数是否超过60帧,来判断驾驶员是否疲劳。如图5所示,我们采用六点基于模型的方法来估计头部姿态,具体方法如下:
如图5右侧所示,建立了6点三维人脸模型,由此可获得这6个点的世界坐标矩阵$(U, V, W)$。对图像中的人脸进行面部对齐后,得到这6个点的图像坐标矩阵$(x, y)$。然后通过应用以下公式,可获得这6个点的相机坐标矩阵$(X, Y, Z)$:
$$
\begin{bmatrix}
x \
y \
1
\end{bmatrix}
=
\begin{bmatrix}
s f_x & 0 & c_x \
0 & f_y & c_y \
0 & 0 & 1
\end{bmatrix}
\begin{bmatrix}
X \
Y \
Z
\end{bmatrix}
$$
其中,$c_x$和$c_y$分别是$x$和$y$方向上的主点偏移量,$f_x$和$f_y$分别是$x$和$y$方向上的焦距,$s$是缩放因子。
利用相机坐标矩阵$(X, Y, Z)$和世界坐标矩阵$(U, V, W)$,可通过应用以下方程获得旋转矩阵$R$和平移矩阵$t$:
$$
s
\begin{bmatrix}
X \
Y \
Z
\end{bmatrix}
=
[R \mid t]
\begin{bmatrix}
U \
V \
W \
1
\end{bmatrix}
$$
得到的旋转矩阵$R$是一个3×3矩阵,最后可根据以下公式获得$\alpha$(俯仰角)、$\beta$(偏航角)和$\gamma$(翻滚角):
$$
\alpha = \tan^{-1}\left(\frac{R_{32}}{R_{33}}\right), \quad
\beta = \tan^{-1}\left(\frac{-R_{31}}{\sqrt{R_{11}^2 + R_{21}^2}}\right), \quad
\gamma = \tan^{-1}\left(\frac{R_{21}}{R_{11}}\right)
$$
其他异常驾驶行为检测
系统通过统计在100帧中“分心”帧的数量是否超过60,以及在100帧中未检测到驾驶员的帧数是否超过60,分别判断驾驶员分心和驾驶员不在正确驾驶位置。
实验 数据集和实验设置
数据集
实验中使用的数据集如下:
- AFLW :AFLW标注了真实世界图像,每张图像包含一个或多个人脸。AFLW共标注了2.5万个人脸,每个人脸包含21个关键点以及三个粗略标注的头部姿态角。所提出的人脸检测网络LittleFace在此数据集上进行训练和评估。
- Pointing’04 :Pointing’04由从15人获取的2790张图像组成。每张图像中仅包含一张人脸。Pointing’04根据垂直和水平角度对图像中人物的头部姿态进行标注,将垂直角度划分为${-90, -60, -30, -15, 0, +15, +30, +60, +90}$,将水平角度划分为${-90, -75, -60, -45, -30, -15, 0, +15, +30, +45, +60, +75, +90}$。其性能在该数据集上评估人脸分类任务的表现。
- 300W 和 300W-LP :300W提出了一种半自动标注方法,在统一协议下对某些数据集中的68个关键点进行重新标注,包括AFW(训练337)、HELEN(训练2000+测试330)、IBUG(测试135)、LFPW(训练811+测试224)。300W-LP为300W中的每张图像添加了头部姿态标签,并通过3DDFA对数据进行增强。人脸对齐方法在300W上进行训练和测试,而头部姿态估计方法在300W-LP上进行评估。
- Menpo2D :Menpo2D是一个用于多姿态2D人脸关键点定位与跟踪的基准,包含半正面和侧面姿态的图像。Menpo2D基准为半正面和侧脸设计了不同的可见关键点配置,实现了2D全姿态人脸对齐。该数据集被用于训练和测试人脸对齐方法。
- YawDD :YawDD是一个打哈欠检测数据集,包含男性和女性在驾驶、说话和打哈欠场景中佩戴或不佩戴眼镜/太阳镜的视频。YawDD包含两个子集:Mirror和Dash。Mirror子集包含322段由安装在前挡风玻璃后视镜下方的摄像头采集的视频。Dash子集包含29段由安装在驾驶员仪表盘上的摄像头采集的视频。由于所提出的驾驶员疲劳检测系统安装在驾驶员的仪表盘上,我们使用Dash子集来评估打哈欠检测准确率。
- DriverEyes :DriverEyes是一个由我们通过安装在仪表盘上的摄像头采集的视频数据集,用于评估基于眼状态的疲劳检测方法的准确率。该数据集包含来自20名驾驶员(17名男性和3名女性)的40段视频,涵盖了佩戴和未佩戴眼镜的情况。我们对数据集中由疲劳引起的眼部状态变化进行了全面标注,该数据集后续将发布于:https://github.com/MrLeexm/DriverEyes
实验设置
我们使用英伟达Jetson Nano作为实验平台,这是一种专为嵌入式应用设计的小型计算机,尺寸仅为70×45 mm。硬件配置如下:128核Maxwell GPU、4 GB GPU内存、四核ARM Cortex-A57@1.43 GHz CPU和4 GB内存。我们在Ubuntu 16.04基础上基于C++代码进行实验,实验中的神经网络均基于Caffe框架实现,并通过TensorRT(以fp16模式运行)进行优化,以加速推理过程。
人脸检测
人脸检测评估
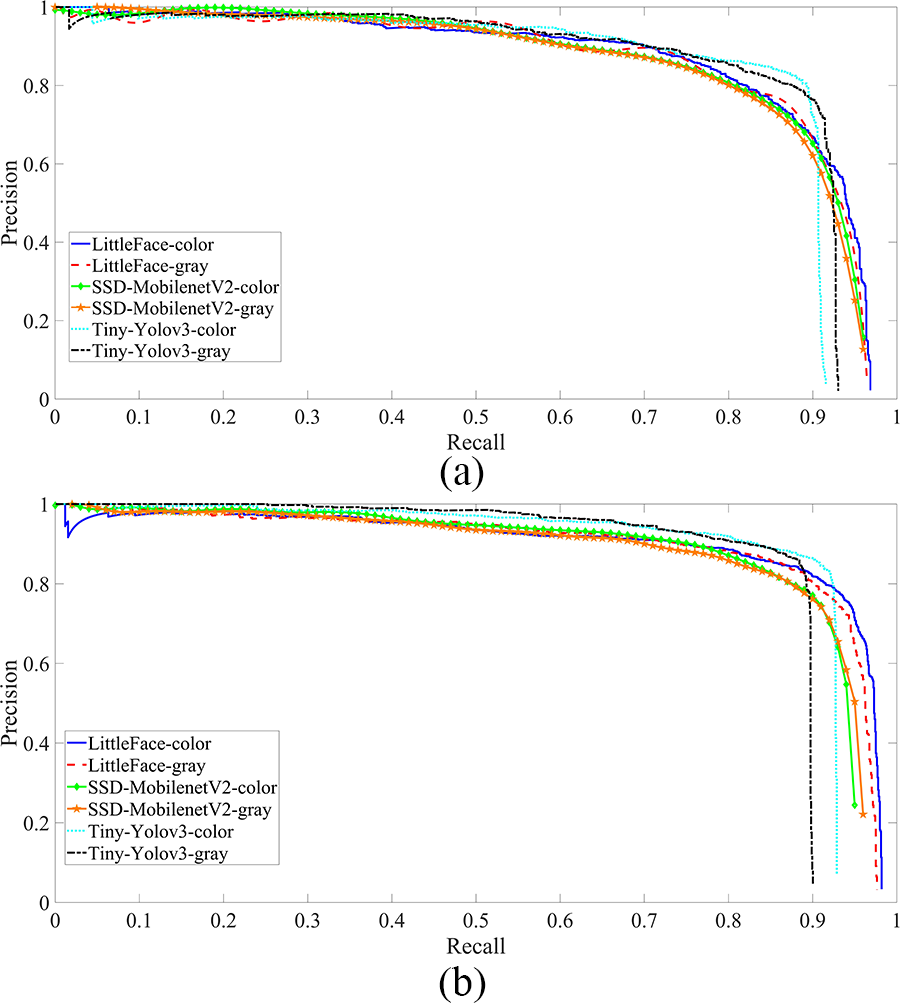
为了评估LittleFace的性能以及使用灰度图像之间的差异,在人脸检测任务中,将灰度图像和彩色图像分别作为输入送入人脸检测网络,比较了LittleFace、SSD-MobilenetV2和Tiny-Yolov3在AFLW上的检测结果。图6显示了各检测方法在AFLW测试集上的P-R曲线,由P-R曲线计算得到的检测结果如表1所示。从表1可以看出:(a)使用相同的检测网络时,以彩色图像作为输入所达到的mAP略高于以灰度图像作为输入的结果;(b)在任意输入情况下,LittleFace的mAP均高于现有的最先进检测方法。
人脸检测的运行效率
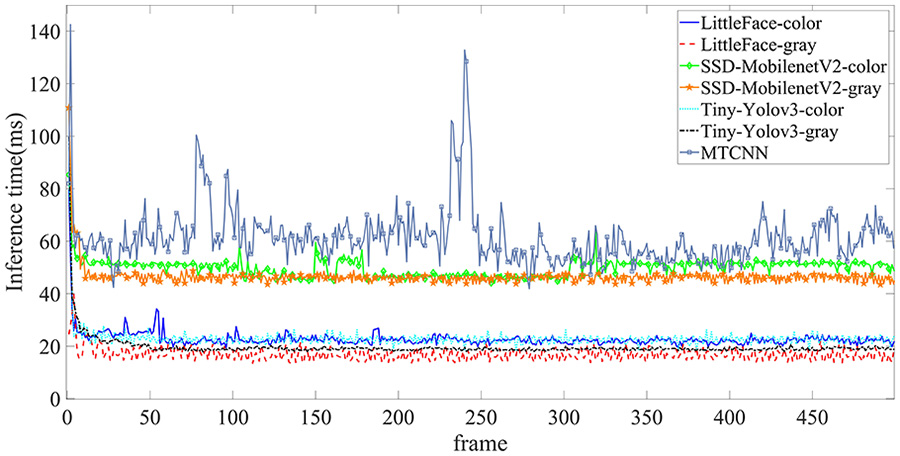
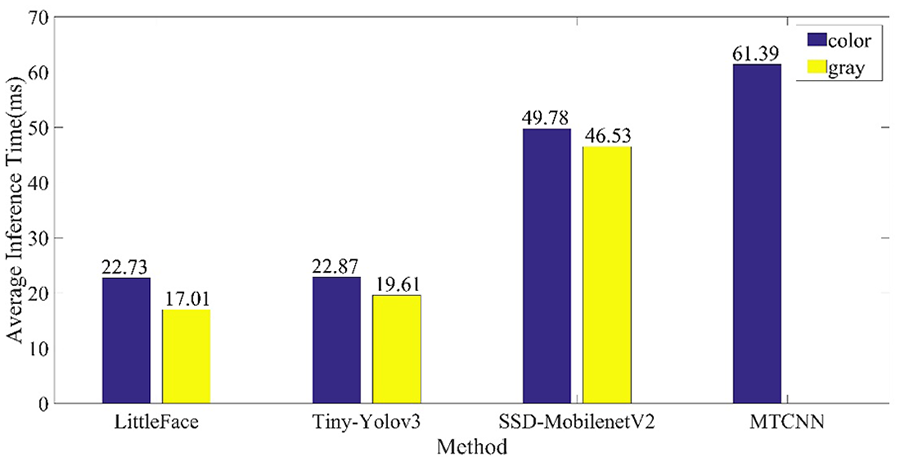
为了评估LittleFace在人脸检测任务中使用灰度图像和彩色图像作为输入时的运行效率及运行速度差异,我们分别将灰度图像和彩色图像作为人脸检测网络的输入,对比LittleFace与上述网络在YawDD数据集的一段视频上的推理时间。同时,我们还与当前最先进的基于彩色图像的人脸检测网络MTCNN进行比较,将图像作为输入。视频中每帧的推理时间如图7所示,平均推理时间如图8所示。从这些图中可以看出:(a)使用相同的检测方法,以灰度图像作为输入的推理时间比以彩色图像作为输入快3–5ms。(b)在任何输入情况下,LittleFace的推理速度都比最先进的检测方法更快,当使用灰度图像作为输入时,平均时间为17.01 ms。(c)从图7可以看出,MTCNN的推理时间波动较大,这是由于其三级级联CNN网络结构所致。
人脸分类评估
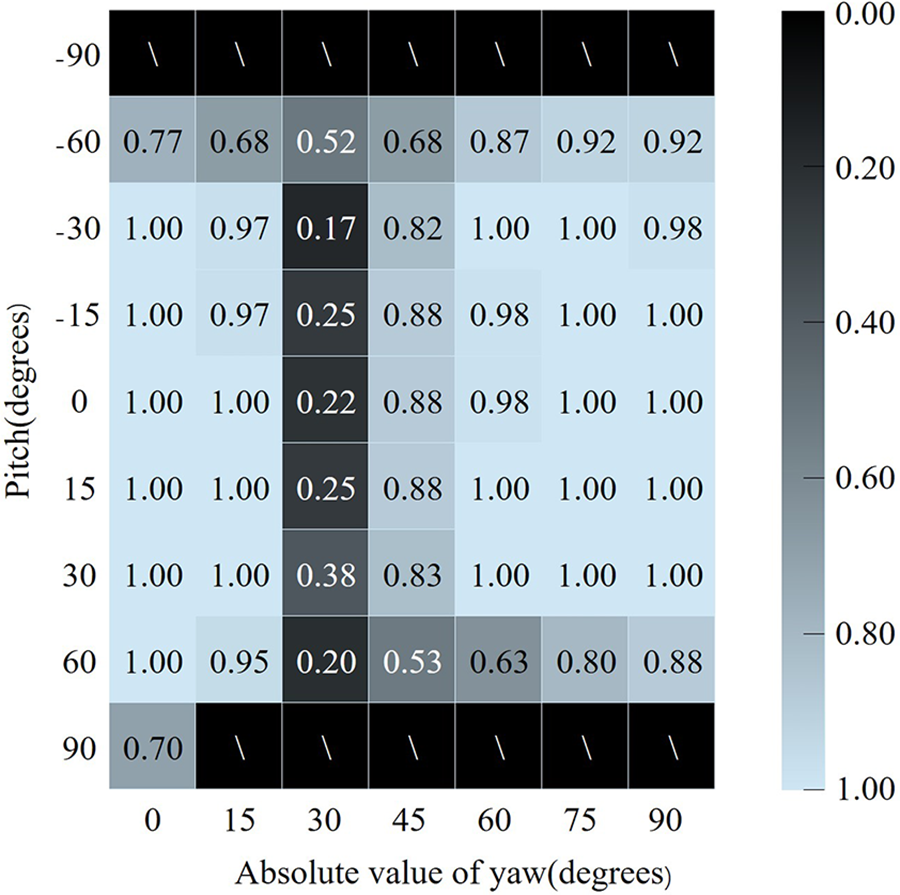
在本部分中,我们在Pointing’04数据集上对不同俯仰角和偏航角下的人脸分类任务性能进行了全面评估,结果如图9所示。在Pointing’04数据集上的人脸检测准确率为97.8%,人脸分类的平均准确率为81.6%。图9显示,当头部偏航角的绝对值接近30°时,准确率较低,但当角度远离30°时,准确率显著提高。
面部对齐
SDM修改的有效性
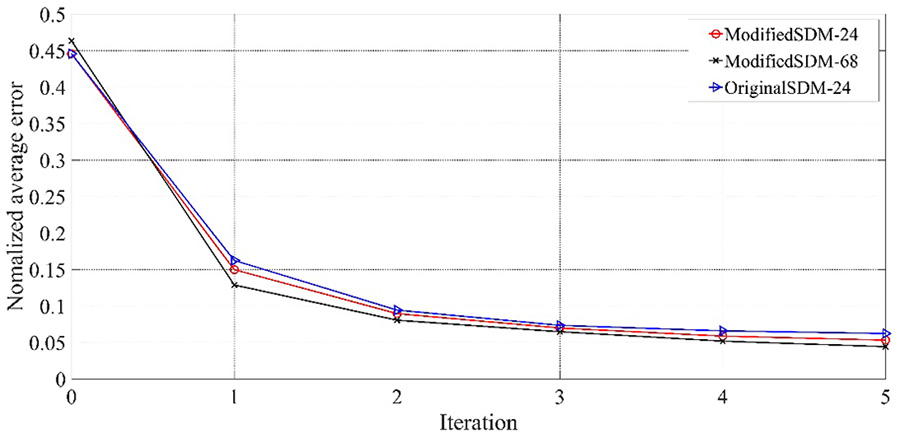
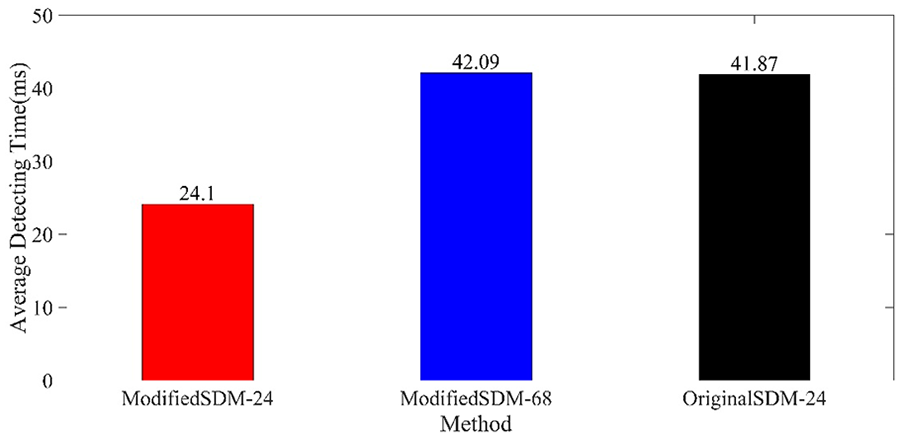
为了评估我们对SDM所做修改的贡献,我们比较了有无所提出修改的SDM的归一化平均误差和运行时间,结果分别如图10和图11所示。未修改的SDM在以每个关键点为中心、宽度为瞳孔间距的矩形区域内提取HOG特征。图10显示:(a)经过五次迭代后,归一化平均误差的差异不明显。(b)修改后的SDM误差略低于未修改的SDM。(c)预测68个关键点的SDM误差略低于预测24个关键点的SDM。图11显示:(a)修改后的SDM运行速度明显快于未修改的SDM。(b)预测24个关键点的SDM运行速度明显快于预测68个关键点的SDM。
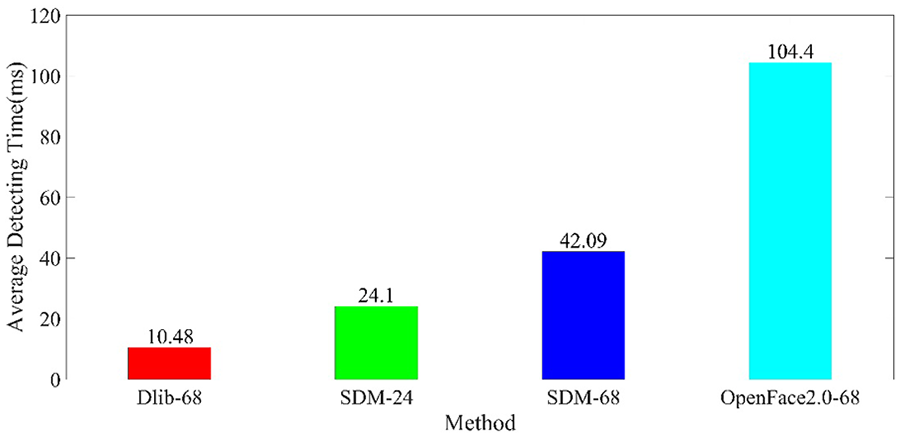
与最先进的方法的速度比较
为了选择一种在边缘计算设备上满足实时运行和高精度要求的人脸对齐方法,我们将改进后的SDM与以下最先进的方法进行运行时间对比:检测68个关键点的Dlib(Dlib-68),以及检测68个关键点的OpenFace2.0(OpenFace2.0-68)。图12显示,只有改进后的SDM-24和Dlib-68能够满足实时运行的要求,因此我们将进一步比较这两种方法的人脸对齐性能。
与Dlib-68的性能比较
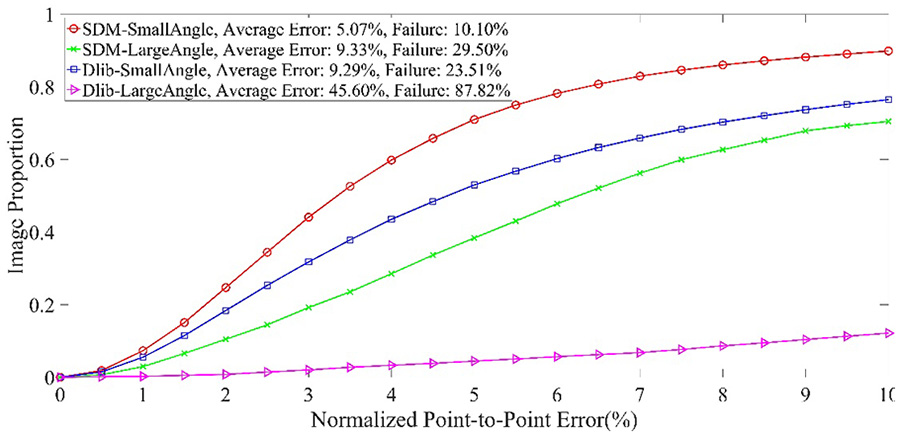
我们按照人脸分类的标准将300W测试集划分为“小角度”集和“大角度”集,以全面评估SDM-24和Dlib-68的人脸对齐性能。图13显示了对齐结果的累积误差分布(CED)曲线,表明在大偏航角下人脸对齐性能下降,且SDM-24优于Dlib-68。我们还在YawDD和DriverEyes上对这两种方法进行了比较,发现在光照条件较差(图14中的第1行和第3行)以及驾驶员戴眼镜闭眼时(图14中的第2行和第4行),Dlib-68的预测关键点会出现较大误差(图14中的第1行和第2行),而SDM-24的结果仍能精确贴合真实人脸形状(图14中的第3行和第4行)。图15显示,不准确的关键点将导致计算出的宽高比无法反映驾驶员的实际状态。
疲劳检测
头部姿态估计
我们使用300W测试集中标注了偏航角在±30°范围内的样本,来评估头部姿态估计方法。利用SDM-24获得的关键点进行头部姿态估计,结果如表2所示。三个估计角度的平均绝对误差(MAE)为7.19°,平均准确率为92.49%。系统中用于检测驾驶员疲劳的俯仰角的平均估计误差为8.46°,平均准确率为90.23%。
打哈欠检测
我们在YawDD数据集上评估了打哈欠检测算法的性能。检测精度为87.01%,远高于此类检测方法的总体准确率80%。当预测的关键点准确时,该算法可以区分打哈欠、闭嘴、说话和唱歌。
眼睛状态检测
我们在DriverEyes上评估了基于眼睛状态的疲劳检测算法的性能。检测精度为91.42%,远高于此类检测方法的总体准确率80%。该算法能够及时检测到驾驶员因疲劳而频繁闭眼或持续闭眼的场景。
结论
本文提出了一种基于卷积神经网络的驾驶员疲劳检测系统,通过分析提取的面部特征来检测驾驶员疲劳和分心状态,且可在边缘计算设备上实时运行。该系统首先使用本文提出的轻量级人脸检测网络LittleFace定位人脸,并同时将人脸分类为两种状态:小偏航角状态“正常”和大偏航角状态“分心”。其次,仅对“正常”状态的人脸区域执行速度优化的面部对齐算法SDM,以解决大角度侧脸时面部对齐准确率下降的问题,而“分心”状态用于检测驾驶员分心。最后,提取特征参数眼睛闭合率(EAR)、嘴部开合度(MAR)和头部俯仰角通过关键点计算得出,分别用于检测驾驶员疲劳。对于眼睛闭合率(EAR)和头部俯仰角,我们参考PERCLOS算法,通过统计一段时间内异常帧的数量是否超过设定阈值来检测驾驶员疲劳。嘴部开合度(MAR)则通过检测打哈欠来判断驾驶员疲劳。
综合实验用于评估系统的各个部分。在TensorRT的加速下,我们的人脸检测网络LittleFace在边缘计算设备英伟达Jetson Nano上,于AFLW测试集实现了88.53%的mAP和58帧率(FPS),优于最先进的方法。与原始SDM相比,优化后的SDM运行时间减少了一半以上,且准确率几乎相同。在YawDD、300W和DriverEyes上的评估结果表明,所提出的系统的平均检测准确率可达89.55%。
我们在真实驾驶场景中测试了该检测系统。图像由安装在仪表盘上的摄像头获取,边缘计算设备采用英伟达Jetson Nano。该检测系统能够进行实时检测,在大多数条件下具有较高的检测精度,特别是我们的人脸检测网络LittleFace,能够应对光照、姿态和遮挡的大幅变化。然而,在这些极端条件下,当驾驶员佩戴太阳镜时,面部对齐性能可能会下降,从而导致检测精度降低。
随着深度学习算法和计算设备硬件的发展,基于深度学习的面部对齐算法未来可被应用于进一步提高驾驶员疲劳检测系统的鲁棒性和准确性,同时确保实时性能。

 ‘‘分心’’状态和(b) ‘‘正常’’状态。)
‘‘分心’’状态和(b) ‘‘正常’’状态。)

| 表1. AFLW上的检测结果。 | ||||||
|---|---|---|---|---|---|---|
| 方法 | mAP | 分心 | 正常 | 颜色 | 灰度 | 颜色 |
| 灰度 | 颜色 | 灰度 | ||||
| SSD-MobilenetV2 | 87.20 | 86.60 | 86.12 | 85.35 | 88.29 | 87.85 |
| Tiny-Yolov3 | 87.25 | 86.78 | 85.29 | 86.55 | 89.20 | 87.00 |
| LittleFace | 88.53 | 88.05 | 86.84 | 86.31 | 90.22 | 89.78 |
| 表2. 在300W上的平均绝对误差(MAE)(单位:度)和准确率(估计角度在±15°误差范围内的百分比)。MAE按研究中提出的方法计算。 | |||||
|---|---|---|---|---|---|
| 方法 | 滚动角(°) | 俯仰角(°) | 偏航角(°) | 平均绝对误差(°) | 准确率(%) |
| 模型-SDM | 3.09 | 8.46 | 10.02 | 7.19 | 92.49 |

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)