Java面试被问:%前置模糊查询怎么优化?五种优化方案+选型+真实优化案例分享
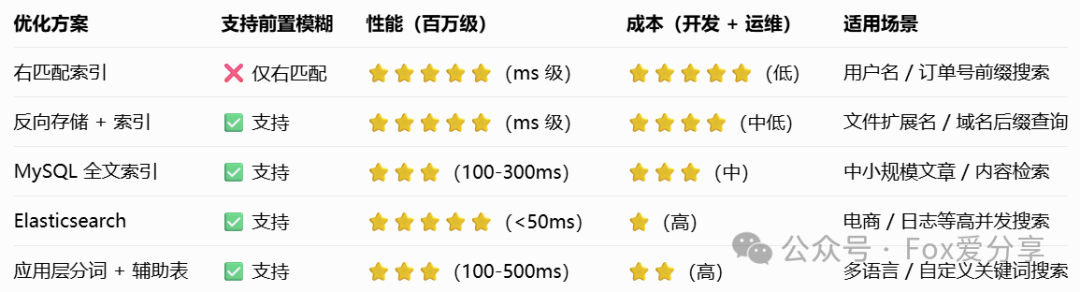
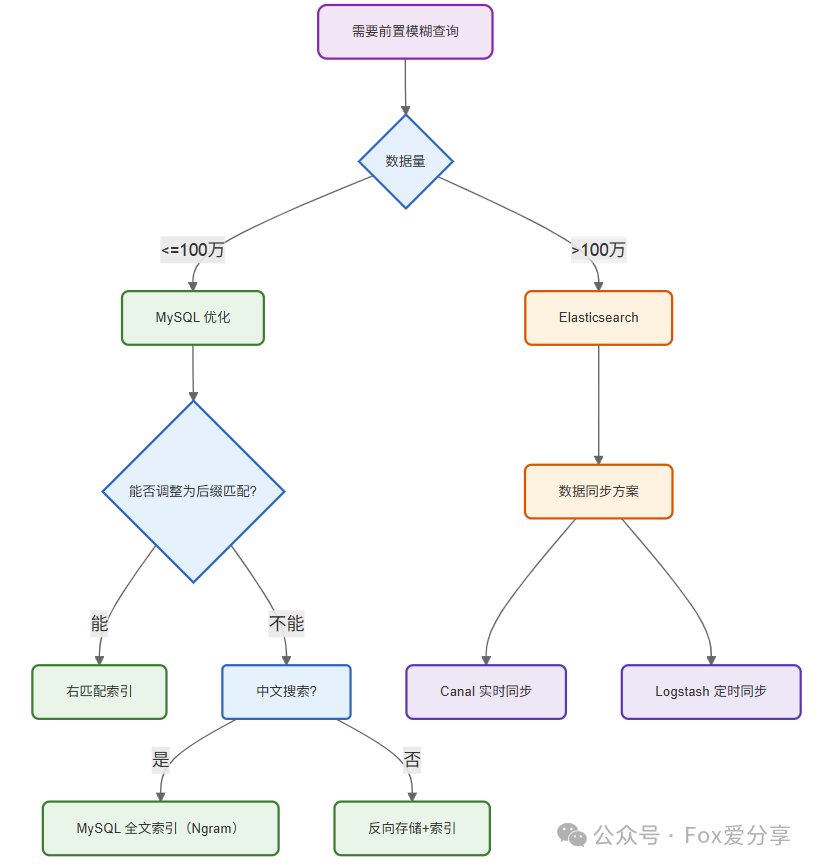
决策流程面试回答建议%前置模糊查询在 MySQL 中无法利用普通 B-Tree 索引,会导致全表扫描。常用优化方法有:如果业务允许,尽量改成右匹配keyword%走索引;对全文检索场景,用 MySQL 全文索引或 Elasticsearch;如果是后缀匹配,可以反向存储字段并建索引;复杂场景建议用搜索引擎。
这个问题在 MySQL 或其他关系型数据库面试中很常见,尤其是在涉及到 LIKE '%keyword' 这种左模糊查询的时候。
1. 问题本质
在 MySQL 中,普通 B-Tree 索引是 前缀匹配 的,也就是说:
LIKE 'keyword%' 可以用到索引(右匹配)LIKE '%keyword'或 LIKE '%keyword%'无法直接用到普通索引(左模糊或全模糊)
原因是 B-Tree 索引的结构是按照字符顺序存储的,只能从左到右比较,无法跳过前面的字符去匹配后面的部分。如果用 %keyword,数据库会进行 全表扫描(Full Table Scan),性能很差。
2. 优化方案
方案 1:右匹配 + 业务调整
-
如果业务允许,尽量把查询改为右匹配:
-- 慢SELECT * FROM user WHERE name LIKE '%abc';-- 快(可走索引)SELECT * FROM user WHERE name LIKE 'abc%';
前提:业务上可以接受只查前缀。
方案 2:使用 全文索引(Full-Text Index)
MySQL 5.6+ InnoDB 支持全文索引,可以用 MATCH() AGAINST() 做全文检索:
ALTER TABLE user ADD FULLTEXT INDEX idx_name(name);SELECT * FROM userWHERE MATCH(name) AGAINST('abc' IN BOOLEAN MODE);
优点:
-
支持任意位置匹配
-
性能远高于
%keyword
缺点:
-
最小匹配长度限制(
ft_min_word_len,默认 4) -
不适合很短的关键词
-
对中文分词支持弱(需要插件如
ngram)
方案 3:反向存储 + 索引
如果业务必须支持 后缀匹配,可以增加一个字段存储反向字符串:
ALTER TABLE user ADD name_reverse VARCHAR(50);-- 更新反向字段UPDATE user SET name_reverse = REVERSE(name);-- 建索引CREATE INDEX idx_name_reverse ON user(name_reverse);-- 查询 name 以 'abc' 结尾SELECT * FROM userWHERE name_reverse LIKE CONCAT(REVERSE('abc'), '%');
这样 LIKE 'xxx%' 就可以走索引了。
方案 4:应用层预处理 + 辅助表
对于长文本(如文章内容),可以在应用层分词后,把关键词存到一个单独的搜索表中,再通过 JOIN 查询匹配结果。
方案 5:使用搜索引擎
如果模糊查询需求复杂(多字段、多语言、高性能),建议引入 Elasticsearch、Solr 等搜索引擎:
-
全文检索
-
分词、同义词、相关性排序
-
分布式支持
3.案例分享
分享几个 真实项目中 %前置模糊查询 优化方案落地的案例,这些都是我在实际工作和面试指导中遇到的场景,方便你理解不同方案的取舍和效果。
案例 1:文件存储系统 —— 后缀匹配优化
背景
-
系统需要根据 文件扩展名 搜索文件,比如
%.jpg、%.pdf。 -
表结构(简化):
files(id, name, size, created_at)-
原 SQL:
SELECT * FROM files WHERE name LIKE '%.jpg';-
问题:全表扫描,百万级数据耗时 3~5 秒。
优化方案
反向存储 + 索引
-
新增字段
name_reverse:
ALTER TABLE files ADD COLUMN name_reverse VARCHAR(255);UPDATE files SET name_reverse = REVERSE(name);
-
建索引:
CREATE INDEX idx_name_reverse ON files(name_reverse);-
查询改写:
SELECT * FROM filesWHERE name_reverse LIKE CONCAT(REVERSE('.jpg'), '%');-- 等价于 name_reverse LIKE 'gpj.%'
-
性能提升:从 3~5 秒 降到 几十毫秒。
经验
-
适合 后缀固定 的场景,比如文件扩展名、域名后缀。
-
写入时需要维护反向列,增加少量存储成本。
案例 2:电商订单号搜索
背景
-
B2B 系统需要支持按订单号 后 4 位 搜索(比如客户只记得末尾)。
-
原 SQL:
SELECT * FROM orders WHERE order_no LIKE '%SN1234';-
问题:全表扫描,千万级订单耗时 8 秒以上。
优化方案
反向存储 + 索引(只存部分后缀)
-
新增
reversed_suffix列,存订单号的后 8 位反向值:
ALTER TABLE orders ADD COLUMN reversed_suffix VARCHAR(8);UPDATE orders SET reversed_suffix = REVERSE(RIGHT(order_no, 8));
-
建索引:
CREATE INDEX idx_reversed_suffix ON orders(reversed_suffix);-
查询:
SELECT * FROM ordersWHERE reversed_suffix LIKE CONCAT(REVERSE('SN1234'), '%');
-
性能提升:从 8 秒 降到 50ms 以内。
经验
-
对于 后缀确定性强 的业务字段,不必反向整列,只反向关键部分即可。
-
节省存储空间,索引更小,查询更快。
案例 3:资讯平台文章搜索
背景
-
用户可以输入任意关键词搜索文章内容,比如 “AI 技术”,文章表里有
title和content字段。 -
原 SQL:
SELECT * FROM articlesWHERE title LIKE '%AI技术%' OR content LIKE '%AI技术%';
-
问题:全表扫描 + 长文本匹配,耗时 2~3 秒,且中文分词差。
优化方案
MySQL 全文索引(ngram 分词)
-
创建全文索引:
ALTER TABLE articles ADD FULLTEXT INDEX idx_article_search(title, content) WITH PARSER ngram;-
查询:
SELECT * FROM articlesWHERE MATCH(title, content) AGAINST('AI技术' IN BOOLEAN MODE);
-
性能提升:从 2~3 秒 降到 100~200ms,且支持中文分词。
经验
-
适合 中小规模数据(百万级以内)的全文搜索需求。
-
对于超短词(<2 个汉字),需要调整
ngram_token_size参数。
案例 4:大型电商商品搜索
背景
-
商品表有 千万级数据,需要支持商品名、品牌、分类、属性等多维度搜索,并且支持任意位置模糊匹配。
-
原 SQL:
SELECT * FROM productsWHERE name LIKE '%手机%' OR brand LIKE '%华为%';
-
问题:全表扫描,耗时 5~10 秒,且无法满足高并发。
优化方案
Elasticsearch 搜索引擎
-
数据同步:MySQL → Canal → Elasticsearch(实时同步)。
-
索引结构:
{"mappings": {"properties": {"name": { "type": "text", "analyzer": "ik_max_word" },"brand": { "type": "keyword" },"category": { "type": "keyword" }}}}
-
查询示例:
GET /products/_search{"query": {"match": { "name": "手机" }}}
-
性能提升:
-
单节点 ES:千万数据响应时间 50ms 左右
-
分布式部署:支持高并发(1000 QPS 以上)
-
支持相关性排序、高亮、拼写纠错等高级功能。
-
经验
-
适合 大数据量、多字段、高并发 的搜索场景。
-
运维成本高,但可扩展性极强。
案例 5:用户昵称全模糊搜索
背景
-
社交产品需要支持用户按昵称任意位置搜索,比如 “小明” 可以匹配 “大明小明”、“小明同学”。
-
原 SQL:
SELECT * FROM users WHERE nickname LIKE '%小明%';-
问题:全表扫描,百万用户耗时 1~2 秒。
优化方案
应用层预处理 + 缓存(Redis)
-
用户注册或修改昵称时,在应用层生成所有可能的 前缀组合,存储到 Redis 有序集合(ZSet)或 ES。
-
例如:昵称 “小明” →
小、小明
-
-
查询时直接从 Redis/ES 中获取匹配的用户 ID 列表,再去 MySQL 查询详细信息。
-
性能:毫秒级响应,支持高 QPS。
经验
-
适合 热数据、高 QPS 的场景。
-
需要权衡存储成本与实时性(昵称修改需同步更新索引)。
4. 总结
方案对比
决策流程
面试回答建议:
“%前置模糊查询 在 MySQL 中无法利用普通 B-Tree 索引,会导致全表扫描。常用优化方法有:
-
如果业务允许,尽量改成右匹配
keyword%走索引; -
对全文检索场景,用 MySQL 全文索引或 Elasticsearch;
-
如果是后缀匹配,可以反向存储字段并建索引;
-
复杂场景建议用搜索引擎。”

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)