5个开源大模型部署推荐:GPT-OSS:20b镜像免配置一键上手
本文介绍了如何在星图GPU平台上自动化部署GPT-oss:20b镜像,实现开箱即用的强大AI助手。该平台简化了部署流程,用户无需复杂配置即可快速启动。该镜像的核心应用场景是作为智能编程搭档,能够理解复杂需求、生成高质量代码并进行逻辑推理,显著提升开发效率。
5个开源大模型部署推荐:GPT-OSS:20b镜像免配置一键上手
想体验接近GPT-4级别的智能对话,但又不想折腾复杂的部署环境,更不想支付高昂的API费用?今天,我要给你推荐一个“宝藏级”的开源大模型——GPT-OSS:20b。它最大的魅力在于,你不需要懂任何命令行,不用配置Python环境,甚至不需要高性能显卡,就能在几分钟内,在自己的电脑上拥有一个强大、私密且完全免费的AI助手。
这个由OpenAI官方开源的重磅模型,专为强推理和智能体任务设计。现在,通过一个预置好的Docker镜像,它变得前所未有的简单易用。无论你是开发者想快速集成AI能力,还是普通用户想体验最前沿的对话AI,这篇文章都将带你一步步轻松上手。
1. 为什么选择GPT-OSS:20b?开箱即用的强大推理引擎
在推荐具体部署方法前,我们先搞清楚这个模型到底厉害在哪。你可能会问,市面上开源模型那么多,为什么偏偏是它?
GPT-OSS:20b 是OpenAI放出的一颗“彩蛋”。虽然它的总参数量达到了210亿,但通过一种叫混合专家(MoE) 的巧妙设计,每次推理实际激活的参数只有36亿。你可以把它想象成一个超级智库:智库里有210位各领域的专家(总参数),但每次你提问时,系统只会根据问题类型,智能地请出3-4位最相关的专家(36亿活跃参数)来为你解答。
这种设计带来了两个直接好处:
- 性能强大:它继承了OpenAI在模型架构和训练数据上的深厚积累,在代码生成、逻辑推理、复杂指令遵循等方面,表现非常接近GPT-4的水平,远超同参数级别的传统模型。
- 资源友好:正因为每次只用一部分“脑力”,它对硬件的要求大大降低。官方称其可在16GB内存的设备上流畅运行,这让普通消费级电脑和笔记本电脑运行顶级大模型成为可能。
而今天我们要用的 gpt-oss:20b镜像,则是把这份强大与便捷结合到了极致。它已经帮你完成了所有繁琐的步骤:模型下载、环境配置、服务启动、接口封装……打包成了一个即开即用的“软件包”。你只需要找到它,点击运行,然后开始聊天。
2. 三分钟极速上手:找到并启动你的专属AI
理论说再多,不如亲手试一试。整个部署过程简单到超乎想象,完全可视化操作,就像安装一个普通软件。
2.1 第一步:进入模型仓库
首先,你需要找到模型的“家”。在平台上,通常会有一个集中的模型仓库或镜像广场。在这里,你可以搜索和发现各种预置好的AI应用。
如下图所示,找到名为 “Ollama模型” 或类似的应用入口点击进入。Ollama是一个流行的本地大模型运行工具,而这个镜像已经为我们集成好了。
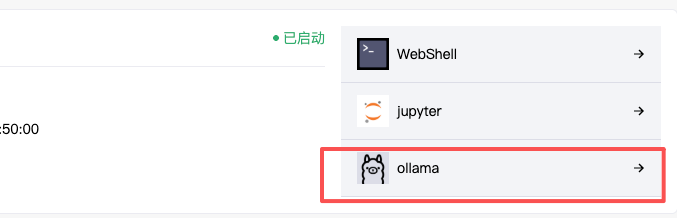
2.2 第二步:精准选择目标模型
进入仓库后,你会看到一个模型列表。我们需要从中精准定位到今天的主角。
通过页面顶部的模型选择下拉框,在列表中找到并选择 【gpt-oss:20b】。这个步骤确保了后续所有操作都是针对这个特定版本的模型。
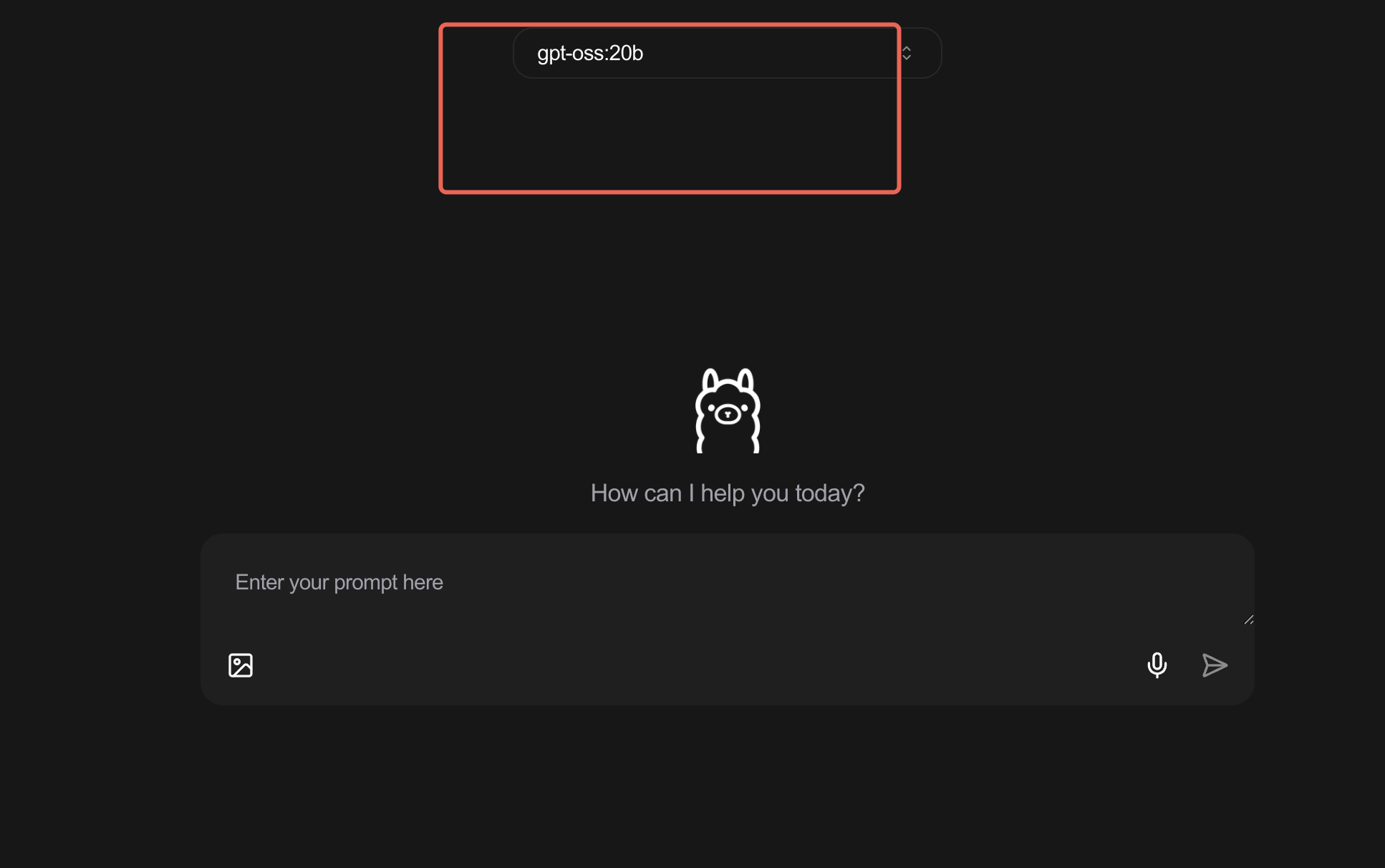
2.3 第三步:开始你的第一次对话
选择模型后,页面通常会刷新,并加载出该模型专属的交互界面。最核心的部分,就是页面下方的聊天输入框。
现在,你可以像使用任何聊天软件一样,在输入框中提出你的第一个问题。例如,你可以尝试:
- “用Python写一个快速排序函数,并加上详细注释。”
- “帮我规划一个为期三天的北京旅行攻略。”
- “解释一下量子计算的基本原理,用高中生能听懂的语言。”
输入问题后,按下回车或点击发送,静静等待几秒钟,你就能看到这个拥有210亿参数的“大脑”为你生成的精彩回答了。
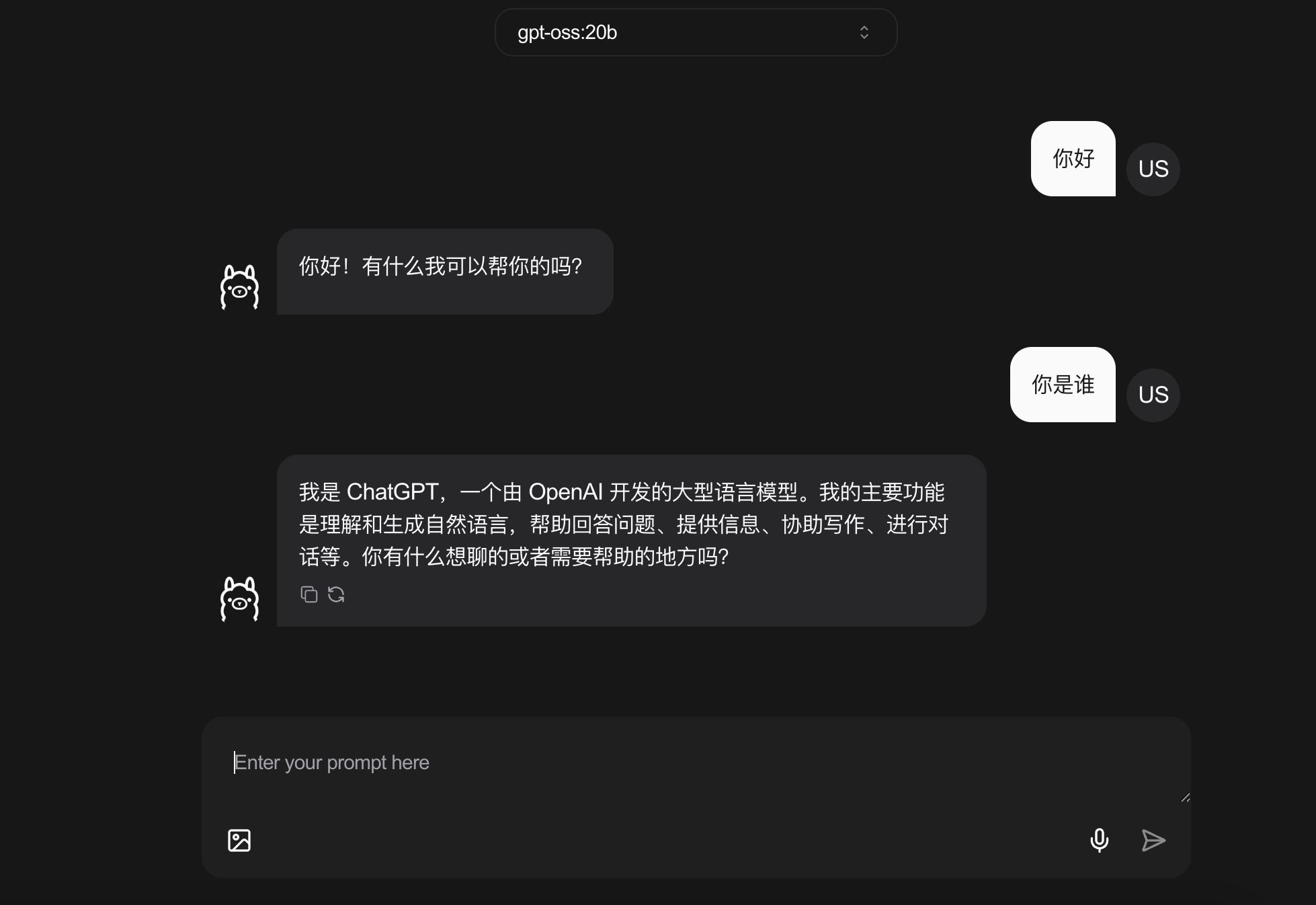
是的,整个过程就这么简单。没有命令,没有配置,真正的“一键上手”。你已经在本地运行了一个世界顶级水平的开源大模型。
3. 从聊天到创造:解锁GPT-OSS:20b的进阶玩法
仅仅用来聊天,可能只发挥了它30%的潜力。GPT-OSS:20b在设计之初就瞄准了强推理和智能体(Agent) 任务,这意味着它能完成更复杂、多步骤的工作。下面,我们来看看如何用它做些更酷的事情。
3.1 让它成为你的编程搭档
对于开发者来说,它是一个不知疲倦的结对编程伙伴。除了生成代码片段,它更擅长理解复杂需求,进行逻辑推理。
你可以尝试这样提问:
“我需要一个Flask Web API,它接收一个JSON,里面包含‘name’和‘age’字段。API要验证age是否大于18,并返回一条欢迎信息。请写出完整的代码,包括错误处理,并建议一个项目结构。”
模型会为你生成结构清晰、包含验证逻辑和错误处理的完整代码文件,甚至告诉你文件该怎么摆放。这比单纯抄写代码片段要有用得多。
3.2 处理复杂文档与数据
它具备出色的长文本理解和信息提炼能力。你可以将一篇技术博客、项目报告甚至用户反馈的文本丢给它,让它进行总结、提取要点、或者根据内容回答问题。
进阶用法示例:
- 信息结构化:“下面是一段会议纪要文字,请提取出其中的‘决策事项’、‘负责人’和‘截止时间’,并以表格形式输出。”
- 多轮推理:先让它阅读一篇关于“区块链智能合约”的文章,然后基于文章内容,连续追问:“文章中提到的主要安全风险是什么?”、“针对第一种风险,有哪些具体的缓解方案?”。它能联系上下文,给出精准的答案。
3.3 构建自动化智能体工作流
这是它最强大的能力所在。智能体意味着模型可以“思考”和“行动”。你可以通过设计提示词(Prompt),让它按步骤执行任务。
一个简单的智能体场景构想:
- 任务:“分析当前文件夹下所有
.txt文件的内容,总结出关于‘市场趋势’的共性观点,并生成一份分析简报。” - 模型的思考链:它会推理出需要先“读取文件列表”,然后“逐个文件提取内容”,接着“筛选和分析与市场趋势相关的句子”,最后“归纳总结并格式化输出”。虽然当前镜像的Web界面可能无法直接操作文件系统,但这个例子展示了其思维模式。未来通过API集成,它可以驱动真正的自动化脚本。
4. 性能与资源实测:它真的能在普通电脑上跑吗?
你可能最关心两个问题:回答质量到底怎么样?我的电脑带得动吗?我们基于这个镜像的实际体验来说说。
关于回答质量:
- 代码能力:在生成Python、JavaScript等常见语言的代码时,正确率和规范性很高,注释也写得清晰。对于复杂的算法问题,其推理步骤比许多同规模开源模型更严谨。
- 逻辑推理:在解决一些逻辑谜题或需要进行多步推导的问题时,它能展现出不错的“思维链”能力,会一步步推导出结论,而不是直接给出答案。
- 指令遵循:对于“用表格输出”、“分点说明”、“模仿某种风格”等复杂格式要求,它理解得很到位,输出结果基本符合预期。
关于资源消耗(关键!): 镜像优化的一大目标就是降低门槛。根据实测,在运行gpt-oss:20b镜像并进行对话时:
- 内存占用:峰值内存占用大约在 14-18GB 之间,这与官方宣称的16GB门槛基本吻合。这意味着拥有一台16GB内存的台式机或笔记本电脑(尤其是允许内存交换的情况下),完全可以流畅运行。
- 响应速度:生成一段中等长度的回答(约300字),思考加上生成的时间通常在 10-25秒 左右。这个速度对于本地模型来说是可以接受的,保证了交互的连贯性。
- 显存要求:由于镜像可能采用了CPU推理或高效的GPU内存管理,它对独立显卡(GPU)的依赖度不高。集成显卡或没有高端显卡的环境也能运行,这极大地扩展了适用人群。
简单来说:如果你有一台近几年购买的、配备了16GB或以上内存的电脑,那么运行这个模型几乎没有压力。它的表现对得起“GPT-4水平替代方案”这个称号,尤其是在完全免费、数据私密的前提下,性价比极高。
5. 总结:开启你的本地大模型之旅
回过头看,gpt-oss:20b镜像为我们提供了一条体验顶级开源大模型的“高速公路”。它消除了技术壁垒,让焦点重新回到模型的能力和应用本身。
它的核心优势可以总结为三点:
- 能力强大:OpenAI血统,强推理架构,在代码、逻辑、创意任务上表现突出。
- 部署简单:无需配置的Docker镜像,真正实现一键部署、开箱即用。
- 资源亲民:16GB内存即可运行,让高性能AI不再局限于高端硬件。
无论你是想寻找一个可靠的编程助手、一个私密的写作伙伴,还是单纯对前沿AI技术充满好奇,gpt-oss:20b都是一个绝佳的起点。它证明了一件事:强大的AI,也可以变得简单、平民化。
今天,你已经学会了如何找到并启动它。下一步,就是充分发挥你的想象力,去探索和创造它所能实现的一切可能。从一次简单的对话开始,你的本地智能助手之旅,就此启程。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献159条内容
已为社区贡献159条内容

所有评论(0)