clickhouse - 入门一篇就够了
介绍
随着数据技术的不断进步,LinkHouse作为新一代的高性能列式数据库,正在凭借其独特的技术优势,逐渐在数据处理和分析领域崭露头角。本文将深入探索LinkHouse的一些最新技术使用场景,并通过实战代码展示其在实际应用中的魅力。
Linkhourse与ES对比:
LinkHouse技术与ES(Elasticsearch)框架相比,具有一些明显的优势。以下是LinkHouse技术相对于ES框架的主要优势:
-
更高的查询性能:LinkHouse技术采用了列式存储和向量化引擎,这使得它在处理大量数据时能够提供更快的查询性能。相比之下,ES框架在处理复杂查询时可能会遇到性能瓶颈,因为它需要扫描和处理更多的数据。
-
更好的数据压缩和存储效率:LinkHouse技术使用高效的列式存储格式,能够更好地压缩数据并减少存储空间的需求。这不仅可以降低存储成本,还可以提高数据访问速度。相比之下,ES框架的存储效率可能较低,因为它使用基于文档的存储方式。
-
更强的数据一致性保证:LinkHouse技术提供了更强的数据一致性保证,确保在分布式环境中数据的准确性和一致性。这对于需要处理大量数据和复杂查询的企业级应用来说非常重要。相比之下,ES框架在处理数据一致性方面可能较为复杂,并且可能需要额外的配置和管理。
-
更灵活的扩展性:LinkHouse技术具有良好的扩展性,可以轻松地增加节点以扩展集群的规模和性能。这使得它能够适应不断变化的数据需求和业务场景。相比之下,ES框架的扩展性可能受到一些限制,例如集群管理和资源分配方面的挑战。
LinkHouse技术概述
LinkHouse,作为一个专为大数据场景设计的数据库管理系统,以其高效的列式存储、快速的查询响应和强大的扩展能力而闻名。它不仅能够处理海量的结构化数据,还提供了丰富的SQL接口,使得开发者能够轻松地进行数据查询、转换和分析。
前沿使用场景
- 实时数据分析与监控
在金融风控、智能运维等领域,对实时数据的分析和监控至关重要。LinkHouse通过其高效的数据处理能力,能够实现对实时数据流的快速处理和分析,帮助企业和开发者及时发现问题并作出响应。
SELECT * FROM transactions WHERE create_time > NOW() - INTERVAL 1 MINUTE;
- 复杂事件处理(CEP)
在物联网(IoT)和边缘计算领域,复杂事件处理(CEP)是一种常见的数据处理模式。LinkHouse通过其强大的SQL接口和流处理能力,能够轻松地实现复杂事件的检测和处理。
SELECT device_id, AVG(temperature) FROM ( SELECT device_id, temperature, ROW_NUMBER() OVER (PARTITION BY device_id ORDER BY create_time) AS rn FROM sensor_data WHERE temperature > 80 ) t WHERE t.rn <= 3 GROUP BY device_id HAVING COUNT(*) = 3;
- 数据湖仓一体化
随着数据湖和数据仓库的融合趋势,LinkHouse也在这方面展现出其技术优势。它不仅能够高效地处理存储在数据湖中的大规模数据,还能够与现有的数据仓库无缝集成,实现数据的一体化管理和分析。
SELECT * FROM lake_data JOIN warehouse_data ON lake_data.id = warehouse_data.id;
LinkHouse技术优势
-
高效的列式存储:LinkHouse采用列式存储结构,使得数据在磁盘上的存储更加紧凑,同时提高了数据扫描和聚合的效率。
-
强大的查询性能:LinkHouse针对大数据场景进行了优化,支持复杂的SQL查询操作,并能够快速地返回查询结果。
-
灵活的扩展性:LinkHouse支持水平扩展,通过增加节点可以轻松地扩展集群的规模和性能,满足不断增长的数据处理需求。
安装
docker安装
创建文件夹,用于存储数据、配置文件及日志文件
mkdir -p /data/clickhouse/data
mkdir -p /data/clickhouse/conf
mkdir -p /data/clickhouse/log
拉取镜像
# 下载最新版本clickhouse
docker pull clickhouse/clickhouse-server
# 下载指定版本clickhouse
docker pull clickhouse/clickhouse-server:22.6.3.35-alpine
此教程采用22.6.3.35版本
创建临时容器,目的是为了获取配置文件,方便今后配置
# 容器关闭后会自动删除掉
docker run -d --rm --name clickhouse-server --ulimit nofile=262144:262144 clickhouse/clickhouse-server:22.6.3.35-alpine
将容器中的配置文件拷贝到本机目录
docker cp clickhouse-server:/etc/clickhouse-server/config.xml /data/clickhouse/conf/config.xml
docker cp clickhouse-server:/etc/clickhouse-server/users.xml /data/clickhouse/conf/users.xml
创建并启动容器
docker run -d --name=clickhouse-server -p 8123:8123 -p 9090:9000 --ulimit nofile=262144:262144 -v /data/clickhouse/data:/var/lib/clickhouse:rw -v /data/clickhouse/conf/config.xml:/etc/clickhouse-server/config.xml -v /data/clickhouse/conf/users.xml:/etc/clickhouse-server/users.xml -v /data/clickhouse/log:/var/log/clickhouse-server:rw clickhouse/clickhouse-server:22.6.3.35-alpine
开启相关端口
firewall-cmd --zone=public --add-port=8123/tcp --permanent
firewall-cmd --zone=public --add-port=9090/tcp --permanent
systemctl restart firewalld.service
进入容器
docker exec -it clickhouse-server bash
通过clickhouse客户端连接上数据库
clickhouse-client
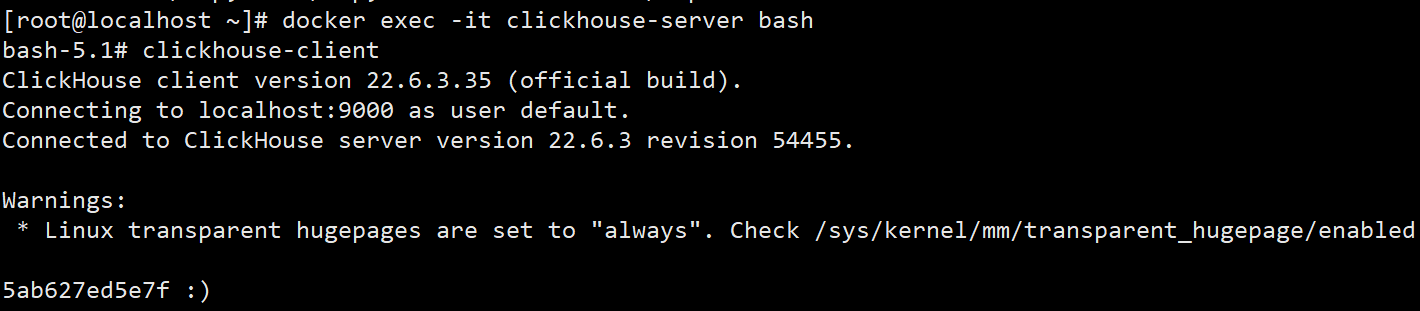
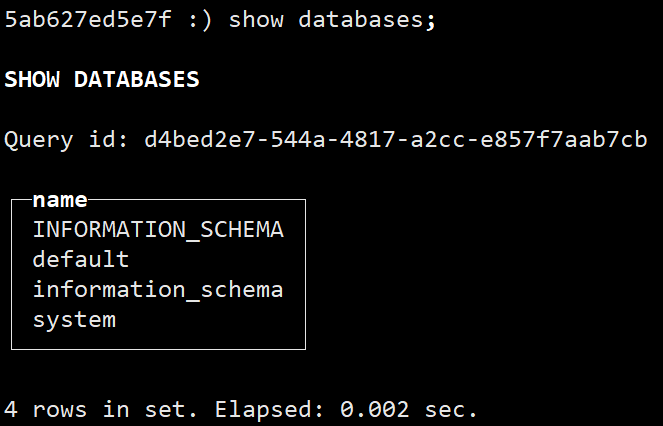
查看数据库
show databases;
数据类型
整型
Int8— [-128 : 127]Int16— [-32768 : 32767]Int32— [-2147483648 : 2147483647]Int64— [-9223372036854775808 : 9223372036854775807]Int128— [-170141183460469231731687303715884105728 : 170141183460469231731687303715884105727]Int256— [-57896044618658097711785492504343953926634992332820282019728792003956564819968 : 57896044618658097711785492504343953926634992332820282019728792003956564819967]
别名:
Int8—TINYINT,BOOL,BOOLEAN,INT1.Int16—SMALLINT,INT2.Int32—INT,INT4,INTEGER.Int64—BIGINT.
无符号整型范围
UInt8— [0 : 255]UInt16— [0 : 65535]UInt32— [0 : 4294967295]UInt64— [0 : 18446744073709551615]UInt128— [0 : 340282366920938463463374607431768211455]UInt256— [0 : 115792089237316195423570985008687907853269984665640564039457584007913129639935]
UUID
通用唯一标识符(UUID)是一个16字节的数字,用于标识记录。
UUID类型值的示例如下:
61f0c404-5cb3-11e7-907b-a6006ad3dba0
如果在插入新记录时未指定UUID列的值,则UUID值将用零填充:
00000000-0000-0000-0000-000000000000
要生成UUID值,ClickHouse提供了 generateuidv4函数。
用法示例
示例1
这个例子演示了创建一个具有UUID类型列的表,并在表中插入一个值。
CREATE TABLE t_uuid (x UUID, y String) ENGINE=TinyLog
INSERT INTO t_uuid SELECT generateUUIDv4(), 'Example 1'
SELECT * FROM t_uuid
┌────────────────────────────────────x─┬─y─────────┐
│ 417ddc5d-e556-4d27-95dd-a34d84e46a50 │ Example 1 │
└──────────────────────────────────────┴───────────┘
示例2
在这个示例中,插入新记录时未指定UUID列的值。
INSERT INTO t_uuid (y) VALUES ('Example 2')
SELECT * FROM t_uuid
┌────────────────────────────────────x─┬─y─────────┐
│ 417ddc5d-e556-4d27-95dd-a34d84e46a50 │ Example 1 │
│ 00000000-0000-0000-0000-000000000000 │ Example 2 │
└──────────────────────────────────────┴───────────┘
注意
UUID数据类型只支持 字符串 数据类型也支持的函数(比如, min, max, 和 count)。
算术运算不支持UUID数据类型(例如, abs)或聚合函数,例如 sum 和 avg.
日期类型
Date
日期类型,用两个字节存储,表示从 1970-01-01 (无符号) 到当前的日期值。允许存储从 Unix 纪元开始到编译阶段定义的上限阈值常量(目前上限是2106年,但最终完全支持的年份为2105)。最小值输出为1970-01-01。
值的范围: [1970-01-01, 2149-06-06]。
日期中没有存储时区信息。
Date32
一个日期。支持与DateTime64相同的日期范围。以本机字节顺序存储为有符号32位整数,其值表示自1970-01-01以来的天数(0表示1970-01-01,负值表示1970年之前的天数)。
示例
创建一个date32类型列的表,并向其中插入数据:
CREATE TABLE dt32
(
`timestamp` Date32,
`event_id` UInt8
)
ENGINE = TinyLog;
插入数据
-- 解析数据
-- - 从字符串解析出日期,
-- - 也可以是一个小数字,表示从1970-01-01经过的天数
-- - 也可以是一个大数字,表示从1970-01-01经过的秒数
INSERT INTO dt32 VALUES ('2100-01-01', 1), (47482, 2), (4102444800, 3);
SELECT * FROM dt32;
查询结果
┌──timestamp─┬─event_id─┐
│ 2100-01-01 │ 1 │
│ 2100-01-01 │ 2 │
└────────────┴──────────┘
DateTime
时间戳类型。用四个字节(无符号的)存储 Unix 时间戳)。允许存储与日期类型相同的范围内的值。最小值为 1970-01-01 00:00:00。时间戳类型值精确到秒(没有闰秒)。
值的范围: [1970-01-01 00:00:00, 2106-02-07 06:28:15]。
时区
使用启动客户端或服务器时的系统时区,时间戳是从文本(分解为组件)转换为二进制并返回。在文本格式中,有关夏令时的信息会丢失。
默认情况下,客户端连接到服务的时候会使用服务端时区。您可以通过启用客户端命令行选项 --use_client_time_zone 来设置使用客户端时间。
因此,在处理文本日期时(例如,在保存文本转储时),请记住在夏令时更改期间可能存在歧义,如果时区发生更改,则可能存在匹配数据的问题。
DateTime64
此类型允许以日期(date)加时间(time)的形式来存储一个时刻的时间值,具有定义的亚秒精度
示例
1. 创建一个具有 DateTime64 类型列的表,并向其中插入数据:
CREATE TABLE dt
(
`timestamp` DateTime64(3, 'Asia/Istanbul'),
`event_id` UInt8
)
ENGINE = TinyLog
INSERT INTO dt Values (1546300800000, 1), ('2019-01-01 00:00:00', 2)
SELECT * FROM dt
┌───────────────timestamp─┬─event_id─┐
│ 2019-01-01 03:00:00.000 │ 1 │
│ 2019-01-01 00:00:00.000 │ 2 │
└─────────────────────────┴──────────┘
- 将日期时间作为integer类型插入时,它会被视为适当缩放的Unix时间戳(UTC)。
1546300800000(精度为3)表示'2019-01-01 00:00:00'UTC. 不过,因为timestamp列指定了Asia/Istanbul(UTC+3)的时区,当作为字符串输出时,它将显示为'2019-01-01 03:00:00' - 当把字符串作为日期时间插入时,它会被赋予时区信息。
'2019-01-01 00:00:00'将被认为处于Asia/Istanbul时区并被存储为1546290000000.
2. 过滤 DateTime64 类型的值
SELECT * FROM dt WHERE timestamp = toDateTime64('2019-01-01 00:00:00', 3, 'Asia/Istanbul')
┌───────────────timestamp─┬─event_id─┐
│ 2019-01-01 00:00:00.000 │ 2 │
└─────────────────────────┴──────────┘
与 DateTime 不同, DateTime64 类型的值不会自动从 String 类型的值转换过来
3. 获取 DateTime64 类型值的时区信息:
SELECT toDateTime64(now(), 3, 'Asia/Istanbul') AS column, toTypeName(column) AS x
┌──────────────────column─┬─x──────────────────────────────┐
│ 2019-10-16 04:12:04.000 │ DateTime64(3, 'Asia/Istanbul') │
└─────────────────────────┴────────────────────────────────┘
4. 时区转换
SELECT
toDateTime64(timestamp, 3, 'Europe/London') as lon_time,
toDateTime64(timestamp, 3, 'Asia/Istanbul') as mos_time
FROM dt
┌───────────────lon_time──┬────────────────mos_time─┐
│ 2019-01-01 00:00:00.000 │ 2019-01-01 03:00:00.000 │
│ 2018-12-31 21:00:00.000 │ 2019-01-01 00:00:00.000 │
└─────────────────────────┴─────────────────────────┘
Map
Map(key, value):Map(key, value) 可以存储 key:value 键值对类型的数据。
key— 键值对的key,类型可以是:String, Integer, LowCardinality, 或者 FixedString.value— 键值对的value,类型可以是:String, Integer, Array, LowCardinality, 或者 FixedString.
示例
示例表:
CREATE TABLE table_map (a Map(String, UInt64)) ENGINE=Memory;
INSERT INTO table_map VALUES ({'key1':1, 'key2':10}), ({'key1':2,'key2':20}), ({'key1':3,'key2':30});
查询 key2 的所有值:
SELECT a['key2'] FROM table_map;
查询结果:
┌─arrayElement(a, 'key2')─┐
│ 10 │
│ 20 │
│ 30 │
└─────────────────────────┘
如果在 Map() 类型的列中,查询的 key 值不存在,那么根据 value 的类型,查询结果将会是数字0,空字符串或者空数组。
INSERT INTO table_map VALUES ({'key3':100}), ({});
SELECT a['key3'] FROM table_map;
查询结果:
┌─arrayElement(a, 'key3')─┐
│ 100 │
│ 0 │
└─────────────────────────┘
┌─arrayElement(a, 'key3')─┐
│ 0 │
│ 0 │
│ 0 │
└─────────────────────────┘
Array(T)
由 T 类型元素组成的数组。
T 可以是任意类型,包含数组类型。 但不推荐使用多维数组,ClickHouse 对多维数组的支持有限。例如,不能存储在 MergeTree 表中存储多维数组。
创建数组
您可以使用array函数来创建数组:
array(T)
您也可以使用方括号:
[]
创建数组示例:
SELECT array(1, 2) AS x, toTypeName(x)
┌─x─────┬─toTypeName(array(1, 2))─┐
│ [1,2] │ Array(UInt8) │
└───────┴─────────────────────────┘
SELECT [1, 2] AS x, toTypeName(x)
┌─x─────┬─toTypeName([1, 2])─┐
│ [1,2] │ Array(UInt8) │
└───────┴────────────────────┘
使用数据类型
ClickHouse会自动检测数组元素,并根据元素计算出存储这些元素最小的数据类型。如果在元素中存在 NULL 或存在 可为空 类型元素,那么数组的元素类型将会变成 可为空。
如果 ClickHouse 无法确定数据类型,它将产生异常。当尝试同时创建一个包含字符串和数字的数组时会发生这种情况 (SELECT array(1, 'a'))。
自动数据类型检测示例:
SELECT array(1, 2, NULL) AS x, toTypeName(x)
┌─x──────────┬─toTypeName(array(1, 2, NULL))─┐
│ [1,2,NULL] │ Array(Nullable(UInt8)) │
└────────────┴───────────────────────────────┘
如果您尝试创建不兼容的数据类型数组,ClickHouse 将引发异常:
SELECT array(1, 'a')
Received exception from server (version 1.1.54388):
Code: 386. DB::Exception: Received from localhost:9000, 127.0.0.1. DB::Exception: There is no supertype for types UInt8, String because some of them are String/FixedString and some of them are not.
数组大小
可以使用 size0 子列找到数组的大小,而无需读取整个列。对于多维数组,您可以使用 sizeN-1,其中 N 是所需的维度。
例子
SQL查询:
CREATE TABLE t_arr (`arr` Array(Array(Array(UInt32)))) ENGINE = MergeTree ORDER BY tuple();
INSERT INTO t_arr VALUES ([[[12, 13, 0, 1],[12]]]);
SELECT arr.size0, arr.size1, arr.size2 FROM t_arr;
结果:
┌─arr.size0─┬─arr.size1─┬─arr.size2─┐
│ 1 │ [2] │ [[4,1]] │
└───────────┴───────────┴───────────┘
Bool
从 v19.4.0.49-stable之后,有单独的类型来存储布尔值。
在此之前的版本,没有单独的类型来存储布尔值。可以使用 UInt8 类型,取值限制为 0 或 1。
Decimal
Decimal(P,S),Decimal32(S),Decimal64(S),Decimal128(S)
有符号的定点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会被丢弃(不舍入)。
参数
- P - 精度。有效范围:[1:38],决定可以有多少个十进制数字(包括分数)。
- S - 规模。有效范围:[0:P],决定数字的小数部分中包含的小数位数。
对于不同的 P 参数值 Decimal 表示,以下例子都是同义的: -P从[1:9]-对于Decimal32(S) -P从[10:18]-对于Decimal64(小号) -P从[19:38]-对于Decimal128(S)
十进制值范围
- Decimal32(S) - ( -1 * 10^(9 - S),1*10^(9-S) ) 总共9位小数点后S位
- Decimal64(S) - ( -1 * 10^(18 - S),1*10^(18-S) ) 总共18位小数点后S位
- Decimal128(S) - ( -1 * 10^(38 - S),1*10^(38-S) ) 总共36位小数点后S位
例如,Decimal32(4) 可以表示 -99999.9999 至 99999.9999 的数值,步长为0.0001。
内部表示方式
数据采用与自身位宽相同的有符号整数存储。这个数在内存中实际范围会高于上述范围,从 String 转换到十进制数的时候会做对应的检查。
由于现代CPU不支持128位数字,因此 Decimal128 上的操作由软件模拟。所以 Decimal128 的运算速度明显慢于 Decimal32/Decimal64。
运算和结果类型
对Decimal的二进制运算导致更宽的结果类型(无论参数的顺序如何)。
Decimal64(S1) <op> Decimal32(S2) -> Decimal64(S)Decimal128(S1) <op> Decimal32(S2) -> Decimal128(S)Decimal128(S1) <op> Decimal64(S2) -> Decimal128(S)
精度变化的规则:
- 加法,减法:S = max(S1, S2)。
- 乘法:S = S1 + S2。
- 除法:S = S1。
对于 Decimal 和整数之间的类似操作,结果是与参数大小相同的十进制。
未定义Decimal和Float32/Float64之间的函数。要执行此类操作,您可以使用:toDecimal32、toDecimal64、toDecimal128 或 toFloat32,toFloat64,需要显式地转换其中一个参数。注意,结果将失去精度,类型转换是昂贵的操作。
Decimal上的一些函数返回结果为Float64(例如,var或stddev)。对于其中一些,中间计算发生在Decimal中。对于此类函数,尽管结果类型相同,但Float64和Decimal中相同数据的结果可能不同。
溢出检查
在对 Decimal 类型执行操作时,数值可能会发生溢出。分数中的过多数字被丢弃(不是舍入的)。整数中的过多数字将导致异常。
SELECT toDecimal32(2, 4) AS x, x / 3
┌──────x─┬─divide(toDecimal32(2, 4), 3)─┐
│ 2.0000 │ 0.6666 │
└────────┴──────────────────────────────┘
SELECT toDecimal32(4.2, 8) AS x, x * x
DB::Exception: Scale is out of bounds.
SELECT toDecimal32(4.2, 8) AS x, 6 * x
DB::Exception: Decimal math overflow.
检查溢出会导致计算变慢。如果已知溢出不可能,则可以通过设置decimal_check_overflow来禁用溢出检查,在这种情况下,溢出将导致结果不正确:
SET decimal_check_overflow = 0;
SELECT toDecimal32(4.2, 8) AS x, 6 * x
┌──────────x─┬─multiply(6, toDecimal32(4.2, 8))─┐
│ 4.20000000 │ -17.74967296 │
└────────────┴──────────────────────────────────┘
溢出检查不仅发生在算术运算上,还发生在比较运算上:
SELECT toDecimal32(1, 8) < 100
DB::Exception: Can't compare.
枚举类型
包括 Enum8 和 Enum16 类型。Enum 保存 'string'= integer 的对应关系。在 ClickHouse 中,尽管用户使用的是字符串常量,但所有含有 Enum 数据类型的操作都是按照包含整数的值来执行。这在性能方面比使用 String 数据类型更有效。
Enum8用'String'= Int8对描述。Enum16用'String'= Int16对描述。
用法示例
创建一个带有一个枚举 Enum8('hello' = 1, 'world' = 2) 类型的列:
CREATE TABLE t_enum
(
x Enum8('hello' = 1, 'world' = 2)
)
ENGINE = TinyLog
这个 x 列只能存储类型定义中列出的值:'hello'或'world'。如果您尝试保存任何其他值,ClickHouse 抛出异常。
INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello')
Ok.
3 rows in set. Elapsed: 0.002 sec.
INSERT INTO t_enum VALUES('a')
Exception on client:
Code: 49. DB::Exception: Unknown element 'a' for type Enum8('hello' = 1, 'world' = 2)
当您从表中查询数据时,ClickHouse 从 Enum 中输出字符串值。
SELECT * FROM t_enum
┌─x─────┐
│ hello │
│ world │
│ hello │
└───────┘
如果需要看到对应行的数值,则必须将 Enum 值转换为整数类型。
SELECT CAST(x, 'Int8') FROM t_enum
┌─CAST(x, 'Int8')─┐
│ 1 │
│ 2 │
│ 1 │
└─────────────────┘
在查询中创建枚举值,您还需要使用 CAST。
SELECT toTypeName(CAST('a', 'Enum8(\'a\' = 1, \'b\' = 2)'))
┌─toTypeName(CAST('a', 'Enum8(\'a\' = 1, \'b\' = 2)'))─┐
│ Enum8('a' = 1, 'b' = 2) │
└──────────────────────────────────────────────────────┘
规则及用法
Enum8 类型的每个值范围是 -128 ... 127,Enum16 类型的每个值范围是 -32768 ... 32767。所有的字符串或者数字都必须是不一样的。允许存在空字符串。如果某个 Enum 类型被指定了(在表定义的时候),数字可以是任意顺序。然而,顺序并不重要。
Enum 中的字符串和数值都不能是 NULL。
Enum 包含在 可为空 类型中。因此,如果您使用此查询创建一个表
CREATE TABLE t_enum_nullable
(
x Nullable( Enum8('hello' = 1, 'world' = 2) )
)
ENGINE = TinyLog
不仅可以存储 'hello' 和 'world' ,还可以存储 NULL。
INSERT INTO t_enum_nullable Values('hello'),('world'),(NULL)
在内存中,Enum 列的存储方式与相应数值的 Int8 或 Int16 相同。
当以文本方式读取的时候,ClickHouse 将值解析成字符串然后去枚举值的集合中搜索对应字符串。如果没有找到,会抛出异常。当读取文本格式的时候,会根据读取到的字符串去找对应的数值。如果没有找到,会抛出异常。
当以文本形式写入时,ClickHouse 将值解析成字符串写入。如果列数据包含垃圾数据(不是来自有效集合的数字),则抛出异常。Enum 类型以二进制读取和写入的方式与 Int8 和 Int16 类型一样的。
隐式默认值是数值最小的值。
在 ORDER BY,GROUP BY,IN,DISTINCT 等等中,Enum 的行为与相应的数字相同。例如,按数字排序。对于等式运算符和比较运算符,Enum 的工作机制与它们在底层数值上的工作机制相同。
枚举值不能与数字进行比较。枚举可以与常量字符串进行比较。如果与之比较的字符串不是有效Enum值,则将引发异常。可以使用 IN 运算符来判断一个 Enum 是否存在于某个 Enum 集合中,其中集合中的 Enum 需要用字符串表示。
大多数具有数字和字符串的运算并不适用于Enums;例如,Enum 类型不能和一个数值相加。但是,Enum有一个原生的 toString 函数,它返回它的字符串值。
Enum 值使用 toT 函数可以转换成数值类型,其中 T 是一个数值类型。若 T 恰好对应 Enum 的底层数值类型,这个转换是零消耗的。
Enum 类型可以被 ALTER 无成本地修改对应集合的值。可以通过 ALTER 操作来增加或删除 Enum 的成员(只要表没有用到该值,删除都是安全的)。作为安全保障,改变之前使用过的 Enum 成员将抛出异常。
通过 ALTER 操作,可以将 Enum8 转成 Enum16,反之亦然,就像 Int8 转 Int16一样。
字符串
FixedString
固定长度 N 的字符串(N 必须是严格的正自然数)。
您可以使用下面的语法对列声明为FixedString类型:
<column_name> FixedString(N)
其中N表示自然数。
当数据的长度恰好为N个字节时,FixedString类型是高效的。 在其他情况下,这可能会降低效率。
可以有效存储在FixedString类型的列中的值的示例:
- 二进制表示的IP地址(IPv6使用
FixedString(16)) - 语言代码(ru_RU, en_US … )
- 货币代码(USD, RUB … )
- 二进制表示的哈希值(MD5使用
FixedString(16),SHA256使用FixedString(32))
请使用UUID数据类型来存储UUID值,。
当向ClickHouse中插入数据时,
- 如果字符串包含的字节数少于`N’,将对字符串末尾进行空字节填充。
- 如果字符串包含的字节数大于
N,将抛出Too large value for FixedString(N)异常。
当做数据查询时,ClickHouse不会删除字符串末尾的空字节。 如果使用WHERE子句,则须要手动添加空字节以匹配FixedString的值。 以下示例阐明了如何将WHERE子句与FixedString一起使用。
考虑带有FixedString(2)列的表:
┌─name──┐
│ b │
└───────┘
查询语句SELECT * FROM FixedStringTable WHERE a = 'b' 不会返回任何结果。请使用空字节来填充筛选条件。
SELECT * FROM FixedStringTable
WHERE a = 'b\0'
┌─a─┐
│ b │
└───┘
这种方式与MySQL的CHAR类型的方式不同(MySQL中使用空格填充字符串,并在输出时删除空格)。
请注意,FixedString(N)的长度是个常量。仅由空字符组成的字符串,函数length返回值为N,而函数empty的返回值为1。
String
字符串可以任意长度的。它可以包含任意的字节集,包含空字节。因此,字符串类型可以代替其他 DBMSs 中的 VARCHAR、BLOB、CLOB 等类型。
编码
ClickHouse 没有编码的概念。字符串可以是任意的字节集,按它们原本的方式进行存储和输出。 若需存储文本,我们建议使用 UTF-8 编码。至少,如果你的终端使用UTF-8(推荐),这样读写就不需要进行任何的转换了。 同样,对不同的编码文本 ClickHouse 会有不同处理字符串的函数。 比如,length 函数可以计算字符串包含的字节数组的长度,然而 lengthUTF8 函数是假设字符串以 UTF-8 编码,计算的是字符串包含的 Unicode 字符的长度。
浮点型
Float32,Float64
浮点数。
类型与以下 C 语言中类型是相同的:
Float32-floatFloat64-double
我们建议您尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,例如货币数量或页面加载时间用毫秒为单位表示
使用浮点数
- 对浮点数进行计算可能引起四舍五入的误差。
SELECT 1 - 0.9
┌───────minus(1, 0.9)─┐
│ 0.09999999999999998 │
└─────────────────────┘
- 计算的结果取决于计算方法(计算机系统的处理器类型和体系结构)
- 浮点计算结果可能是诸如无穷大(
INF)和«非数字»(NaN)。对浮点数计算的时候应该考虑到这点。 - 当一行行阅读浮点数的时候,浮点数的结果可能不是机器最近显示的数值。
NaN和Inf
与标准SQL相比,ClickHouse 支持以下类别的浮点数:
Inf– 正无穷
SELECT 0.5 / 0
┌─divide(0.5, 0)─┐
│ inf │
└────────────────┘
-Inf– 负无穷
SELECT -0.5 / 0
┌─divide(-0.5, 0)─┐
│ -inf │
└─────────────────┘
NaN– 非数字
SELECT 0 / 0
┌─divide(0, 0)─┐
│ nan │
└──────────────┘
Nullable
可为空(类型名称)
允许用特殊标记 (NULL) 表示«缺失值»,可以与 TypeName 的正常值存放一起。例如,Nullable(Int8) 类型的列可以存储 Int8 类型值,而没有值的行将存储 NULL。
对于 TypeName,不能使用复合数据类型 阵列 和 元组。复合数据类型可以包含 Nullable 类型值,例如Array(Nullable(Int8))。
Nullable 类型字段不能包含在表索引中。
除非在 ClickHouse 服务器配置中另有说明,否则 NULL 是任何 Nullable 类型的默认值。
存储特性
要在表的列中存储 Nullable 类型值,ClickHouse 除了使用带有值的普通文件外,还使用带有 NULL 掩码的单独文件。 掩码文件中的条目允许 ClickHouse 区分每个表行的 NULL 和相应数据类型的默认值。 由于附加了新文件,Nullable 列与类似的普通文件相比消耗额外的存储空间。
!!! 注意点 “注意点” 使用 Nullable 几乎总是对性能产生负面影响,在设计数据库时请记住这一点
掩码文件中的条目允许ClickHouse区分每个表行的对应数据类型的«NULL»和默认值由于有额外的文件,«Nullable»列比普通列消耗更多的存储空间
null子列
通过使用 null 子列可以在列中查找 NULL 值,而无需读取整个列。如果对应的值为 NULL,则返回 1,否则返回 0。
示例
SQL查询:
CREATE TABLE nullable (`n` Nullable(UInt32)) ENGINE = MergeTree ORDER BY tuple();
INSERT INTO nullable VALUES (1) (NULL) (2) (NULL);
SELECT n.null FROM nullable;
结果:
┌─n.null─┐
│ 0 │
│ 1 │
│ 0 │
│ 1 │
└────────┘
用法示例
CREATE TABLE t_null(x Int8, y Nullable(Int8)) ENGINE TinyLog
INSERT INTO t_null VALUES (1, NULL), (2, 3)
SELECT x + y FROM t_null
┌─plus(x, y)─┐
│ ᴺᵁᴸᴸ │
│ 5 │
└────────────┘
操作符
所有的操作符(运算符)都会在查询时依据他们的优先级及其结合顺序在被解析时转换为对应的函数。下面按优先级从高到低列出各组运算符及其对应的函数:
下标运算符
a[N]` – 数组中的第N个元素; 对应函数 `arrayElement(a, N)
a.N` – 元组中第N个元素; 对应函数 `tupleElement(a, N)
负号
-a` – 对应函数 `negate(a)
乘号、除号和取余
a * b` – 对应函数 `multiply(a, b)
a / b` – 对应函数 `divide(a, b)
a % b` – 对应函数 `modulo(a, b)
加号和减号
a + b` – 对应函数 `plus(a, b)
a - b` – 对应函数 `minus(a, b)
关系运算符
a = b` – 对应函数 `equals(a, b)
a == b` – 对应函数 `equals(a, b)
a != b` – 对应函数 `notEquals(a, b)
a <> b` – 对应函数 `notEquals(a, b)
a <= b` – 对应函数 `lessOrEquals(a, b)
a >= b` – 对应函数 `greaterOrEquals(a, b)
a < b` – 对应函数 `less(a, b)
a > b` – 对应函数 `greater(a, b)
a LIKE b` – 对应函数 `like(a, b)
a NOT LIKE b` – 对应函数 `notLike(a, b)
a BETWEEN b AND c` – 等价于 `a >= b AND a <= c
集合关系运算符
详见此节 IN 相关操作符 。
a IN ...` – 对应函数 `in(a, b)
a NOT IN ...` – 对应函数 `notIn(a, b)
a GLOBAL IN ...` – 对应函数 `globalIn(a, b)
a GLOBAL NOT IN ...` – 对应函数 `globalNotIn(a, b)
逻辑非
NOT a` – 对应函数 `not(a)
逻辑与
a AND b` – 对应函数`and(a, b)
逻辑或
a OR b` – 对应函数 `or(a, b)
条件运算符
a ? b : c` – 对应函数 `if(a, b, c)
注意:
条件运算符会先计算表达式b和表达式c的值,再根据表达式a的真假,返回相应的值。如果表达式b和表达式c是 arrayJoin() 函数,则不管表达式a是真是假,每行都会被复制展开。
日期和时间
EXTRACT
EXTRACT(part FROM date);
从给定日期中提取部件。 例如,您可以从给定日期检索一个月,或从时间检索一秒钟。
该 part 参数指定要检索的日期部分。 以下值可用:
DAY— The day of the month. Possible values: 1–31.MONTH— The number of a month. Possible values: 1–12.YEAR— The year.SECOND— The second. Possible values: 0–59.MINUTE— The minute. Possible values: 0–59.HOUR— The hour. Possible values: 0–23.
该 part 参数不区分大小写。
该 date 参数指定要处理的日期或时间。 无论是 日期 或 日期时间 支持类型。
例:
SELECT EXTRACT(DAY FROM toDate('2017-06-15'));
SELECT EXTRACT(MONTH FROM toDate('2017-06-15'));
SELECT EXTRACT(YEAR FROM toDate('2017-06-15'));
在下面的例子中,我们创建一个表,并在其中插入一个值 DateTime 类型。
CREATE TABLE test.Orders
(
OrderId UInt64,
OrderName String,
OrderDate DateTime
)
ENGINE = Log;
INSERT INTO test.Orders VALUES (1, 'Jarlsberg Cheese', toDateTime('2008-10-11 13:23:44'));
SELECT
toYear(OrderDate) AS OrderYear,
toMonth(OrderDate) AS OrderMonth,
toDayOfMonth(OrderDate) AS OrderDay,
toHour(OrderDate) AS OrderHour,
toMinute(OrderDate) AS OrderMinute,
toSecond(OrderDate) AS OrderSecond
FROM test.Orders;
┌─OrderYear─┬─OrderMonth─┬─OrderDay─┬─OrderHour─┬─OrderMinute─┬─OrderSecond─┐
│ 2008 │ 10 │ 11 │ 13 │ 23 │ 44 │
└───────────┴────────────┴──────────┴───────────┴─────────────┴─────────────┘
INTERVAL
创建一个 间隔-应在算术运算中使用的类型值 日期 和 日期时间-类型值。
示例:
SELECT now() AS current_date_time, current_date_time + INTERVAL 4 DAY + INTERVAL 3 HOUR
┌───current_date_time─┬─plus(plus(now(), toIntervalDay(4)), toIntervalHour(3))─┐
│ 2019-10-23 11:16:28 │ 2019-10-27 14:16:28 │
CASE条件表达式
CASE [x]
WHEN a THEN b
[WHEN ... THEN ...]
[ELSE c]
END
如果指定了 x ,该表达式会转换为 transform(x, [a, ...], [b, ...], c) 函数。否则转换为 multiIf(a, b, ..., c)
如果该表达式中没有 ELSE c 子句,则默认值就是 NULL
但 transform 函数不支持 NULL
连接运算符
s1 || s2` – 对应函数 `concat(s1, s2)
创建 Lambda 函数
x -> expr` – 对应函数 `lambda(x, expr)
接下来的这些操作符因为其本身是括号没有优先级:
创建数组
[x1, ...]` – 对应函数 `array(x1, ...)
创建元组
(x1, x2, ...)` – 对应函数 `tuple(x2, x2, ...)
结合方式
所有的同级操作符从左到右结合。例如, 1 + 2 + 3 会转换成 plus(plus(1, 2), 3)。 所以,有时他们会跟我们预期的不太一样。例如, SELECT 4 > 2 > 3 的结果是0。
为了高效, and 和 or 函数支持任意多参数,一连串的 AND 和 OR 运算符会转换成其对应的单个函数。
判断是否为
ClickHouse 支持 IS NULL 和 IS NOT NULL 。
IS NULL
- 对于可为空类型的值,
IS NULL会返回:1值为NULL0否则
- 对于其他类型的值,
IS NULL总会返回0
SELECT x+100 FROM t_null WHERE y IS NULL
┌─plus(x, 100)─┐
│ 101 │
└──────────────┘
IS NOT NULL
- 对于可为空类型的值,
IS NOT NULL会返回:0值为NULL1否则
- 对于其他类型的值,
IS NOT NULL总会返回1
SELECT * FROM t_null WHERE y IS NOT NULL
┌─x─┬─y─┐
│ 2 │ 3 │
└───┴───┘
IN 操作符
该 IN, NOT IN, GLOBAL IN,和 GLOBAL NOT IN 运算符是单独考虑的,因为它们的功能相当丰富。
运算符的左侧是单列或元组。
例:
SELECT UserID IN (123, 456) FROM ...
SELECT (CounterID, UserID) IN ((34, 123), (101500, 456)) FROM ...
如果左侧是索引中的单列,而右侧是一组常量,则系统将使用索引处理查询。
请不要列举太多具体的常量 (比方说 几百万条)。如果数据集非常大,请把它放在一张临时表里(例如,参考章节用于查询处理的外部数据),然后使用子查询。
运算符的右侧可以是一组常量表达式、一组带有常量表达式的元组(如上面的示例所示),或括号中的数据库表或SELECT子查询的名称。
如果运算符的右侧是表的名称(例如, UserID IN users),这相当于子查询 UserID IN (SELECT * FROM users). 使用与查询一起发送的外部数据时,请使用此选项。 例如,查询可以与一组用户Id一起发送到 ‘users’ 应过滤的临时表。
如果运算符的右侧是具有Set引擎的表名(始终位于RAM中的准备好的数据集),则不会为每个查询重新创建数据集。
子查询可以指定多个用于筛选元组的列。 示例:
SELECT (CounterID, UserID) IN (SELECT CounterID, UserID FROM ...) FROM ...
IN运算符左侧和右侧的列应具有相同的类型。
IN运算符和子查询可能出现在查询的任何部分,包括聚合函数和lambda函数。 示例:
SELECT
EventDate,
avg(UserID IN
(
SELECT UserID
FROM test.hits
WHERE EventDate = toDate('2014-03-17')
)) AS ratio
FROM test.hits
GROUP BY EventDate
ORDER BY EventDate ASC
┌──EventDate─┬────ratio─┐
│ 2014-03-17 │ 1 │
│ 2014-03-18 │ 0.807696 │
│ 2014-03-19 │ 0.755406 │
│ 2014-03-20 │ 0.723218 │
│ 2014-03-21 │ 0.697021 │
│ 2014-03-22 │ 0.647851 │
│ 2014-03-23 │ 0.648416 │
└────────────┴──────────┘
对于3月17日后的每一天,计算3月17日访问该网站的用户所做的浏览量百分比。 IN子句中的子查询始终只在单个服务器上运行一次。 没有依赖子查询。
空处理
在请求处理过程中, IN 运算符假定运算的结果 NULL 总是等于 0,无论是否 NULL 位于操作员的右侧或左侧。 NULL 值不包含在任何数据集中,彼此不对应,并且在以下情况下无法进行比较 transform_null_in=0.
下面是一个例子 t_null 表:
┌─x─┬────y─┐
│ 1 │ ᴺᵁᴸᴸ │
│ 2 │ 3 │
└───┴──────┘
运行查询 SELECT x FROM t_null WHERE y IN (NULL,3) 为您提供以下结果:
┌─x─┐
│ 2 │
└───┘
你可以看到,在其中的行 y = NULL 被抛出的查询结果。 这是因为ClickHouse无法决定是否 NULL 包含在 (NULL,3) 设置,返回 0 作为操作的结果,和 SELECT 从最终输出中排除此行。
SELECT y IN (NULL, 3)
FROM t_null
┌─in(y, tuple(NULL, 3))─┐
│ 0 │
│ 1 │
└───────────────────────┘
分布式子查询
带子查询的IN-s有两个选项(类似于连接):normal IN / JOIN 和 GLOBAL IN / GLOBAL JOIN. 它们在分布式查询处理的运行方式上有所不同。
注意
请记住,下面描述的算法可能会有不同的工作方式取决于 设置 distributed_product_mode 设置。
当使用常规IN时,查询被发送到远程服务器,并且它们中的每个服务器都在运行子查询 IN 或 JOIN 条款
使用时 GLOBAL IN / GLOBAL JOINs,首先所有的子查询都运行 GLOBAL IN / GLOBAL JOINs,并将结果收集在临时表中。 然后将临时表发送到每个远程服务器,其中使用此临时数据运行查询。
对于非分布式查询,请使用常规 IN / JOIN.
在使用子查询时要小心 IN / JOIN 用于分布式查询处理的子句。
让我们来看看一些例子。 假设集群中的每个服务器都有一个正常的 local_table. 每个服务器还具有 distributed_table 表与 分布 类型,它查看群集中的所有服务器。
对于查询 distributed_table,查询将被发送到所有远程服务器,并使用以下命令在其上运行 local_table.
例如,查询
SELECT uniq(UserID) FROM distributed_table
将被发送到所有远程服务器
SELECT uniq(UserID) FROM local_table
并且并行运行它们中的每一个,直到达到可以结合中间结果的阶段。 然后将中间结果返回给请求者服务器并在其上合并,并将最终结果发送给客户端。
现在让我们检查一个查询IN:
SELECT uniq(UserID) FROM distributed_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM local_table WHERE CounterID = 34)
- 计算两个网站的受众的交集。
此查询将以下列方式发送到所有远程服务器
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM local_table WHERE CounterID = 34)
换句话说,IN子句中的数据集将在每台服务器上独立收集,仅在每台服务器上本地存储的数据中收集。
如果您已经为此情况做好准备,并且已经将数据分散到群集服务器上,以便单个用户Id的数据完全驻留在单个服务器上,则这将正常和最佳地工作。 在这种情况下,所有必要的数据将在每台服务器上本地提供。 否则,结果将是不准确的。 我们将查询的这种变体称为 “local IN”.
若要更正数据在群集服务器上随机传播时查询的工作方式,可以指定 distributed_table 在子查询中。 查询如下所示:
SELECT uniq(UserID) FROM distributed_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM distributed_table WHERE CounterID = 34)
此查询将以下列方式发送到所有远程服务器
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM distributed_table WHERE CounterID = 34)
子查询将开始在每个远程服务器上运行。 由于子查询使用分布式表,因此每个远程服务器上的子查询将重新发送到每个远程服务器
SELECT UserID FROM local_table WHERE CounterID = 34
例如,如果您有100台服务器的集群,则执行整个查询将需要10,000个基本请求,这通常被认为是不可接受的。
在这种情况下,应始终使用GLOBAL IN而不是IN。 让我们来看看它是如何工作的查询
SELECT uniq(UserID) FROM distributed_table WHERE CounterID = 101500 AND UserID GLOBAL IN (SELECT UserID FROM distributed_table WHERE CounterID = 34)
请求者服务器将运行子查询
SELECT UserID FROM distributed_table WHERE CounterID = 34
结果将被放在RAM中的临时表中。 然后请求将被发送到每个远程服务器
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID GLOBAL IN _data1
和临时表 _data1 将通过查询发送到每个远程服务器(临时表的名称是实现定义的)。
这比使用正常IN更优化。 但是,请记住以下几点:
- 创建临时表时,数据不是唯一的。 要减少通过网络传输的数据量,请在子查询中指定DISTINCT。 (你不需要为正常人做这个。)
- 临时表将被发送到所有远程服务器。 传输不考虑网络拓扑。 例如,如果10个远程服务器驻留在与请求者服务器非常远程的数据中心中,则数据将通过通道发送10次到远程数据中心。 使用GLOBAL IN时尽量避免使用大型数据集。
- 将数据传输到远程服务器时,无法配置网络带宽限制。 您可能会使网络过载。
- 尝试跨服务器分发数据,以便您不需要定期使用GLOBAL IN。
- 如果您需要经常使用GLOBAL IN,请规划ClickHouse集群的位置,以便单个副本组驻留在不超过一个数据中心中,并且它们之间具有快速网络,以便可以完全在单个数据中心内处理查询。
这也是有意义的,在指定一个本地表 GLOBAL IN 子句,以防此本地表仅在请求者服务器上可用,并且您希望在远程服务器上使用来自它的数据。
表引擎
表引擎(即表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
引擎类型
MergeTree
适用于高负载任务的最通用和功能最强大的表引擎。这些引擎的共同特点是可以快速插入数据并进行后续的后台数据处理。 MergeTree系列引擎支持数据复制(使用Replicated* 的引擎版本),分区和一些其他引擎不支持的其他功能。
该类型的引擎:
- MergeTree
- ReplacingMergeTree
- SummingMergeTree
- AggregatingMergeTree
- CollapsingMergeTree
- VersionedCollapsingMergeTree
- GraphiteMergeTree
日志
具有最小功能的轻量级引擎。当您需要快速写入许多小表(最多约100万行)并在以后整体读取它们时,该类型的引擎是最有效的。
该类型的引擎:
集成引擎
用于与其他的数据存储与处理系统集成的引擎。 该类型的引擎:
用于其他特定功能的引擎
该类型的引擎:
虚拟列
虚拟列是表引擎组成的一部分,它在对应的表引擎的源代码中定义。
您不能在 CREATE TABLE 中指定虚拟列,并且虚拟列不会包含在 SHOW CREATE TABLE 和 DESCRIBE TABLE 的查询结果中。虚拟列是只读的,所以您不能向虚拟列中写入数据。
如果想要查询虚拟列中的数据,您必须在SELECT查询中包含虚拟列的名字。SELECT * 不会返回虚拟列的内容。
若您创建的表中有一列与虚拟列的名字相同,那么虚拟列将不能再被访问。我们不建议您这样做。为了避免这种列名的冲突,虚拟列的名字一般都以下划线开头。
数据库操作
CREATE DATABASE
该查询用于根据指定名称创建数据库。
CREATE DATABASE [IF NOT EXISTS] db_name
数据库其实只是用于存放表的一个目录。 如果查询中存在IF NOT EXISTS,则当数据库已经存在时,该查询不会返回任何错误。
表操作
CREATE TABLE
对于CREATE TABLE,存在以下几种方式。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = engine
在指定的’db’数据库中创建一个名为’name’的表,如果查询中没有包含’db’,则默认使用当前选择的数据库作为’db’。后面的是包含在括号中的表结构以及表引擎的声明。 其中表结构声明是一个包含一组列描述声明的组合。如果表引擎是支持索引的,那么可以在表引擎的参数中对其进行说明。
在最简单的情况下,列描述是指名称 类型这样的子句。例如: RegionID UInt32。 但是也可以为列另外定义默认值表达式
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS [db2.]name2 [ENGINE = engine]
创建一个与db2.name2具有相同结构的表,同时你可以对其指定不同的表引擎声明。如果没有表引擎声明,则创建的表将与db2.name2使用相同的表引擎。
CREATE TABLE [IF NOT EXISTS] [db.]table_name ENGINE = engine AS SELECT ...
使用指定的引擎创建一个与SELECT子句的结果具有相同结构的表,并使用SELECT子句的结果填充它。
以上所有情况,如果指定了IF NOT EXISTS,那么在该表已经存在的情况下,查询不会返回任何错误。在这种情况下,查询几乎不会做任何事情。
在ENGINE子句后还可能存在一些其他的子句,更详细的信息可以参考 表引擎 中关于建表的描述。
默认值
在列描述中你可以通过以下方式之一为列指定默认表达式:DEFAULT expr,MATERIALIZED expr,ALIAS expr。 示例:URLDomain String DEFAULT domain(URL)。
如果在列描述中未定义任何默认表达式,那么系统将会根据类型设置对应的默认值,如:数值类型为零、字符串类型为空字符串、数组类型为空数组、日期类型为’1970-01-01’以及时间类型为 zero unix timestamp。
如果定义了默认表达式,则可以不定义列的类型。如果没有明确的定义类的类型,则使用默认表达式的类型。例如:EventDate DEFAULT toDate(EventTime) - 最终’EventDate’将使用’Date’作为类型。
如果同时指定了默认表达式与列的类型,则将使用类型转换函数将默认表达式转换为指定的类型。例如:Hits UInt32 DEFAULT 0与Hits UInt32 DEFAULT toUInt32(0)意思相同。
默认表达式可以包含常量或表的任意其他列。当创建或更改表结构时,系统将会运行检查,确保不会包含循环依赖。对于INSERT, 它仅检查表达式是否是可以解析的 - 它们可以从中计算出所有需要的列的默认值。
DEFAULT expr
普通的默认值,如果INSERT中不包含指定的列,那么将通过表达式计算它的默认值并填充它。
MATERIALIZED expr
物化表达式,被该表达式指定的列不能包含在INSERT的列表中,因为它总是被计算出来的。 对于INSERT而言,不需要考虑这些列。 另外,在SELECT查询中如果包含星号,此列不会被用来替换星号,这是因为考虑到数据转储,在使用SELECT *查询出的结果总能够被’INSERT’回表。
ALIAS expr
别名。这样的列不会存储在表中。 它的值不能够通过INSERT写入,同时使用SELECT查询星号时,这些列也不会被用来替换星号。 但是它们可以显示的用于SELECT中,在这种情况下,在查询分析中别名将被替换。
当使用ALTER查询对添加新的列时,不同于为所有旧数据添加这个列,对于需要在旧数据中查询新列,只会在查询时动态计算这个新列的值。但是如果新列的默认表示中依赖其他列的值进行计算,那么同样会加载这些依赖的列的数据。
如果你向表中添加一个新列,并在之后的一段时间后修改它的默认表达式,则旧数据中的值将会被改变。请注意,在运行后台合并时,缺少的列的值将被计算后写入到合并后的数据部分中。
不能够为nested类型的列设置默认值。
案例
CREATE TABLE user (id Int32, name String) ENGINE = MergeTree() ORDER BY id;
插入数据
INSERT INTO user (id, name)VALUES (1, 'John'),(2, 'Jane'),(3, 'Alice');
临时表
ClickHouse支持临时表,其具有以下特征:
- 当回话结束时,临时表将随会话一起消失,这包含链接中断。
- 临时表仅能够使用Memory表引擎。
- 无法为临时表指定数据库。它是在数据库之外创建的。
- 如果临时表与另一个表名称相同,那么当在查询时没有显示的指定db的情况下,将优先使用临时表。
- 对于分布式处理,查询中使用的临时表将被传递到远程服务器。
可以使用下面的语法创建一个临时表:
CREATE TEMPORARY TABLE [IF NOT EXISTS] table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
)
大多数情况下,临时表不是手动创建的,只有在分布式查询处理中使用(GLOBAL) IN时为外部数据创建。
ALTER
大多数 ALTER TABLE 查询修改表设置或数据
大多数
ALTER TABLE查询只支持*MergeTree表,以及Merge和Distributed。
句法:
ALTER [TEMPORARY] TABLE [db].name [ON CLUSTER cluster] ADD|DROP|RENAME|CLEAR|COMMENT|{MODIFY|ALTER}|MATERIALIZE COLUMN ...
在查询中,指定一个或多个以逗号分隔的操作的列表。每个操作都是对列的操作。
支持以下操作:
- ADD COLUMN — 向表中添加新列。
- DROP COLUMN — 删除列。
- RENAME COLUMN — 重命名现有列。
- CLEAR COLUMN — 重置列值。
- 注释列— 向列添加文本注释。
- MODIFY COLUMN — 更改列的类型、默认表达式、TTL 和列设置。
- MODIFY COLUMN REMOVE — 删除列属性之一。
- 修改列 修改设置- 更改列设置。
- 修改列重置设置- 重置列设置。
- MATERIALIZE COLUMN — 在缺少列的部分中具体化列。下面详细描述这些操作。
添加列
ADD COLUMN [IF NOT EXISTS] name [type] [default_expr] [codec] [AFTER name_after | FIRST]
name`使用指定的、`type`和向表中添加新列(请参阅[默认表达式](https://clickhouse.com/docs/en/sql-reference/statements/create/table#create-default-values)部分)[`codec`](https://clickhouse.com/docs/en/sql-reference/statements/create/table#codecs)。`default_expr
如果IF NOT EXISTS包含该子句,并且该列已存在,则查询不会返回错误。如果指定AFTER name_after(另一列的名称),则该列将添加到表列列表中指定列的后面。如果要将列添加到表的开头,请使用该FIRST子句。否则,该列将添加到表的末尾。对于一系列操作,name_after可以是在之前的操作之一中添加的列的名称。
添加列只是更改表结构,而不对数据执行任何操作。之后数据不会出现在磁盘上ALTER。如果从表中读取时缺少某列数据,则会用默认值填充该列(如果有,则执行默认表达式,或者使用零或空字符串)。合并数据部分后,该列将出现在磁盘上(请参阅MergeTree)。
这种方式可以让我们即时完成ALTER查询,而不会增加旧数据量。
例子:
ALTER TABLE alter_test ADD COLUMN Added1 UInt32 FIRST;
ALTER TABLE alter_test ADD COLUMN Added2 UInt32 AFTER NestedColumn;
ALTER TABLE alter_test ADD COLUMN Added3 UInt32 AFTER ToDrop;
DESC alter_test FORMAT TSV;
Added1 UInt32
CounterID UInt32
StartDate Date
UserID UInt32
VisitID UInt32
NestedColumn.A Array(UInt8)
NestedColumn.S Array(String)
Added2 UInt32
ToDrop UInt32
Added3 UInt32
删除列
DROP COLUMN [IF EXISTS] name
删除名称为 的列name。如果IF EXISTS指定了该子句,则即使该列不存在,查询也不会返回错误。
从文件系统中删除数据。由于这会删除整个文件,因此查询几乎立即完成。
提示
如果列被物化视图引用,则无法删除该列。否则,它将返回错误。
例子:
ALTER TABLE visits DROP COLUMN browser
重命名列
RENAME COLUMN [IF EXISTS] name to new_name
将列重命名name为new_name. 如果IF EXISTS指定了该子句,则即使该列不存在,查询也不会返回错误。由于重命名不涉及底层数据,查询几乎瞬间完成。
注意:表的键表达式中指定的列(使用ORDER BY或PRIMARY KEY)无法重命名。尝试更改这些列将产生SQL Error [524].
例子:
ALTER TABLE visits RENAME COLUMN webBrowser TO browser
COMMENT
COMMENT COLUMN [IF EXISTS] name 'Text comment'
给字段添加注释
RENAME
给表重命名
RENAME TABLE 原名 TO 新名
未完…
https://clickhouse.com/docs/zh/sql-reference/statements/alter/column
INSERT
INSERT INTO 语句主要用于向系统中添加数据.
查询的基本格式:
INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
您可以在查询中指定要插入的列的列表,如:[(c1, c2, c3)]。您还可以使用列匹配器的表达式,例如*和/或修饰符,例如 APPLY, EXCEPT, REPLACE。
例如,考虑该表:
SHOW CREATE insert_select_testtable;
CREATE TABLE insert_select_testtable
(
`a` Int8,
`b` String,
`c` Int8
)
ENGINE = MergeTree()
ORDER BY a
INSERT INTO insert_select_testtable (*) VALUES (1, 'a', 1) ;
如果要在除了’b’列以外的所有列中插入数据,您需要传递和括号中选择的列数一样多的值:
INSERT INTO insert_select_testtable (* EXCEPT(b)) Values (2, 2);
SELECT * FROM insert_select_testtable;
┌─a─┬─b─┬─c─┐
│ 2 │ │ 2 │
└───┴───┴───┘
┌─a─┬─b─┬─c─┐
│ 1 │ a │ 1 │
└───┴───┴───┘
在这个示例中,我们看到插入的第二行的a和c列的值由传递的值填充,而b列由默认值填充。
对于存在于表结构中但不存在于插入列表中的列,它们将会按照如下方式填充数据:
- 如果存在
DEFAULT表达式,根据DEFAULT表达式计算被填充的值。 - 如果没有定义
DEFAULT表达式,则填充零或空字符串。
如果 strict_insert_defaults=1,你必须在查询中列出所有没有定义DEFAULT表达式的列。
数据可以以ClickHouse支持的任何 输入输出格式 传递给INSERT。格式的名称必须显示的指定在查询中:
INSERT INTO [db.]table [(c1, c2, c3)] FORMAT format_name data_set
例如,下面的查询所使用的输入格式就与上面INSERT … VALUES的中使用的输入格式相同:
INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] FORMAT Values (v11, v12, v13), (v21, v22, v23), ...
ClickHouse会清除数据前所有的空白字符与一个换行符(如果有换行符的话)。所以在进行查询时,我们建议您将数据放入到输入输出格式名称后的新的一行中去(如果数据是以空白字符开始的,这将非常重要)。
示例:
INSERT INTO t FORMAT TabSeparated
11 Hello, world!
22 Qwerty
在使用命令行客户端或HTTP客户端时,你可以将具体的查询语句与数据分开发送。更多具体信息,请参考«客户端»部分。
限制
如果表中有一些限制,,数据插入时会逐行进行数据校验,如果这里面包含了不符合限制条件的数据,服务将会抛出包含限制信息的异常,这个语句也会被停止执行。
使用SELECT的结果写入
INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] SELECT ...
写入与SELECT的列的对应关系是使用位置来进行对应的,尽管它们在SELECT表达式与INSERT中的名称可能是不同的。如果需要,会对它们执行对应的类型转换。
除了VALUES格式之外,其他格式中的数据都不允许出现诸如now(),1 + 2等表达式。VALUES格式允许您有限度的使用这些表达式,但是不建议您这么做,因为执行这些表达式总是低效的。
系统不支持的其他用于修改数据的查询:UPDATE, DELETE, REPLACE, MERGE, UPSERT, INSERT UPDATE。 但是,您可以使用 ALTER TABLE ... DROP PARTITION查询来删除一些旧的数据。
如果 SELECT 查询中包含了 input() 函数,那么 FORMAT 必须出现在查询语句的最后。
如果某一列限制了值不能是NULL,那么插入NULL的时候就会插入这个列类型的默认数据,可以通过设置 insert_null_as_default 插入NULL。
从文件向表中插入数据
INSERT INTO [db.]table [(c1, c2, c3)] FROM INFILE file_name [COMPRESSION type] FORMAT format_name
使用上面的语句可以从客户端的文件上读取数据并插入表中,file_name 和 type 都是 String 类型,输入文件的格式 一定要在 FORMAT 语句中设置。
支持读取压缩文件。默认会去读文件的拓展名作为文件的压缩方式,或者也可以在 COMPRESSION 语句中指明,支持的文件压缩格式如下:'none', 'gzip', 'deflate', 'br', 'xz', 'zstd', 'lz4', 'bz2'。
这个功能在 command-line client 和 clickhouse-local 是可用的。
样例
echo 1,A > input.csv ; echo 2,B >> input.csv
clickhouse-client --query="CREATE TABLE table_from_file (id UInt32, text String) ENGINE=MergeTree() ORDER BY id;"
clickhouse-client --query="INSERT INTO table_from_file FROM INFILE 'input.csv' FORMAT CSV;"
clickhouse-client --query="SELECT * FROM table_from_file FORMAT PrettyCompact;"
结果:
┌─id─┬─text─┐
│ 1 │ A │
│ 2 │ B │
└────┴──────┘
插入表函数
数据可以通过 table functions 方法插入。
INSERT INTO [TABLE] FUNCTION table_func ...
例如
可以这样使用remote 表函数:
CREATE TABLE simple_table (id UInt32, text String) ENGINE=MergeTree() ORDER BY id;
INSERT INTO TABLE FUNCTION remote('localhost', default.simple_table)
VALUES (100, 'inserted via remote()');
SELECT * FROM simple_table;
结果:
┌──id─┬─text──────────────────┐
│ 100 │ inserted via remote() │
└─────┴───────────────────────┘
性能的注意事项
在进行INSERT时将会对写入的数据进行一些处理,按照主键排序,按照月份对数据进行分区等。所以如果在您的写入数据中包含多个月份的混合数据时,将会显著的降低INSERT的性能。为了避免这种情况:
- 数据总是以尽量大的batch进行写入,如每次写入100,000行。
- 数据在写入ClickHouse前预先的对数据进行分组。
在以下的情况下,性能不会下降:
- 数据总是被实时的写入。
- 写入的数据已经按照时间排序。
也可以异步的、小规模的插入数据,这些数据会被合并成多个批次,然后安全地写入到表中,通过设置async_insert,可以使用异步插入的方式,请注意,异步插入的方式只支持HTTP协议,并且不支持数据去重。
delete
在ClickHouse中,可以使用DELETE语句来删除数据。下面是一些常见的使用方法:
删除整个表中的数据:
DELETE FROM table_name
这将删除表中的所有数据,但保留表结构。
删除满足条件的数据:
DELETE FROM table_name WHERE condition
在WHERE子句中指定条件,删除满足条件的数据。
删除指定范围的数据:
ALTER TABLE table_name DELETE WHERE column BETWEEN min AND max
通过使用ALTER TABLE语句的DELETE子句,可以删除具有指定范围的值的行。要删除的列由WHERE子句中的条件指定。
请注意,ClickHouse的数据删除操作实际上是通过标记行进行逻辑删除,而不是物理删除,这是为了保持高性能。被删除的数据将被标记为已删除,但实际存储在磁盘上,只是在查询时被过滤掉。定期执行OPTIMIZE TABLE操作可以物理删除已标记为删除的数据以释放存储空间。
在执行任何删除操作之前,请始终先备份数据,以防意外删除或需要恢复数据。
select
SELECT 查询执行数据检索。 默认情况下,请求的数据返回给客户端
语法
[WITH expr_list|(subquery)]
SELECT [DISTINCT] expr_list
[FROM [db.]table | (subquery) | table_function] [FINAL]
[SAMPLE sample_coeff]
[ARRAY JOIN ...]
[GLOBAL] [ANY|ALL|ASOF] [INNER|LEFT|RIGHT|FULL|CROSS] [OUTER|SEMI|ANTI] JOIN (subquery)|table (ON <expr_list>)|(USING <column_list>)
[PREWHERE expr]
[WHERE expr]
[GROUP BY expr_list] [WITH TOTALS]
[HAVING expr]
[ORDER BY expr_list] [WITH FILL] [FROM expr] [TO expr] [STEP expr]
[LIMIT [offset_value, ]n BY columns]
[LIMIT [n, ]m] [WITH TIES]
[UNION ALL ...]
[INTO OUTFILE filename]
[FORMAT format]
所有子句都是可选的,但紧接在 SELECT 后面的必需表达式列表除外,更详细的请看 下面.
每个可选子句的具体内容在单独的部分中进行介绍,这些部分按与执行顺序相同的顺序列出:
- WITH 子句
- FROM 子句
- SAMPLE 子句
- JOIN 子句
- PREWHERE 子句
- WHERE 子句
- GROUP BY 子句
- LIMIT BY 子句
- HAVING 子句
- SELECT 子句
- DISTINCT 子句
- LIMIT 子句
- UNION ALL 子句
- INTO OUTFILE 子句
- FORMAT 子句
SELECT 子句
表达式 指定 SELECT 子句是在上述子句中的所有操作完成后计算的。 这些表达式的工作方式就好像它们应用于结果中的单独行一样。 如果表达式 SELECT 子句包含聚合函数,然后ClickHouse将使用 GROUP BY 聚合参数应用在聚合函数和表达式上。
如果在结果中包含所有列,请使用星号 (*)符号。 例如, SELECT * FROM ....
将结果中的某些列与 re2 正则表达式匹配,可以使用 COLUMNS 表达。
COLUMNS('regexp')
例如表:
CREATE TABLE default.col_names (aa Int8, ab Int8, bc Int8) ENGINE = TinyLog
以下查询所有列名包含 a 。
SELECT COLUMNS('a') FROM col_names
┌─aa─┬─ab─┐
│ 1 │ 1 │
└────┴────┘
所选列不按字母顺序返回。
您可以使用多个 COLUMNS 表达式并将函数应用于它们。
例如:
SELECT COLUMNS('a'), COLUMNS('c'), toTypeName(COLUMNS('c')) FROM col_names
┌─aa─┬─ab─┬─bc─┬─toTypeName(bc)─┐
│ 1 │ 1 │ 1 │ Int8 │
└────┴────┴────┴────────────────┘
返回的每一列 COLUMNS 表达式作为单独的参数传递给函数。 如果函数支持其他参数,您也可以将其他参数传递给函数。 使用函数时要小心,如果函数不支持传递给它的参数,ClickHouse将抛出异常。
例如:
SELECT COLUMNS('a') + COLUMNS('c') FROM col_names
Received exception from server (version 19.14.1):
Code: 42. DB::Exception: Received from localhost:9000. DB::Exception: Number of arguments for function plus doesn't match: passed 3, should be 2.
该例子中, COLUMNS('a') 返回两列: aa 和 ab. COLUMNS('c') 返回 bc 列。 该 + 运算符不能应用于3个参数,因此ClickHouse抛出一个带有相关消息的异常。
匹配的列 COLUMNS 表达式可以具有不同的数据类型。 如果 COLUMNS 不匹配任何列,并且是在 SELECT 唯一的表达式,ClickHouse则抛出异常。
星号
您可以在查询的任何部分使用星号替代表达式。进行查询分析、时,星号将展开为所有表的列(不包括 MATERIALIZED 和 ALIAS 列)。 只有少数情况下使用星号是合理的:
- 创建转储表时。
- 对于只包含几列的表,例如系统表。
- 获取表中列的信息。 在这种情况下,设置
LIMIT 1. 但最好使用DESC TABLE查询。 - 当对少量列使用
PREWHERE进行强过滤时。 - 在子查询中(因为外部查询不需要的列从子查询中排除)。
在所有其他情况下,我们不建议使用星号,因为它只给你一个列DBMS的缺点,而不是优点。 换句话说,不建议使用星号。
极端值
除结果之外,还可以获取结果列的最小值和最大值。 要做到这一点,设置 extremes 设置为1。 最小值和最大值是针对数字类型、日期和带有时间的日期计算的。 对于其他类型列,输出默认值。
分别的额外计算两行 – 最小值和最大值。 这额外的两行采用输出格式为 JSON*, TabSeparated*,和 Pretty* formats,与其他行分开。 它们不以其他格式输出。
为 JSON* 格式时,极端值单独的输出在 ‘extremes’ 字段。 为 TabSeparated* 格式时,此行来的主要结果集后,然后显示 ‘totals’ 字段。 它前面有一个空行(在其他数据之后)。 在 Pretty* 格式时,该行在主结果之后输出为一个单独的表,然后显示 ‘totals’ 字段。
极端值在 LIMIT 之前被计算,但在 LIMIT BY 之后被计算. 然而,使用 LIMIT offset, size, offset 之前的行都包含在 extremes. 在流请求中,结果还可能包括少量通过 LIMIT 过滤的行.
备注
您可以在查询的任何部分使用同义词 (AS 别名)。
GROUP BY 和 ORDER BY 子句不支持位置参数。 这与MySQL相矛盾,但符合标准SQL。 例如, GROUP BY 1, 2 将被理解为根据常量分组 (i.e. aggregation of all rows into one).
实现细节
如果查询省略 DISTINCT, GROUP BY , ORDER BY , IN , JOIN 子查询,查询将被完全流处理,使用O(1)量的RAM。 若未指定适当的限制,则查询可能会消耗大量RAM:
max_memory_usagemax_rows_to_group_bymax_rows_to_sortmax_rows_in_distinctmax_bytes_in_distinctmax_rows_in_setmax_bytes_in_setmax_rows_in_joinmax_bytes_in_joinmax_bytes_before_external_sortmax_bytes_before_external_group_by
有关详细信息,请参阅部分 “Settings”. 可以使用外部排序(将临时表保存到磁盘)和外部聚合。
ClickHouse跳数索引
跳数索引
影响ClickHouse查询性能的因素很多。在大多数场景中,关键因素是ClickHouse在计算查询WHERE子句条件时是否可以使用主键。因此,选择适用于最常见查询模式的主键对于表的设计至关重要。
然而,无论如何仔细地调优主键,不可避免地会出现不能有效使用它的查询用例。用户通常依赖于ClickHouse获得时间序列类型的数据,但他们通常希望根据其他业务维度(如客户id、网站URL或产品编号)分析同一批数据。在这种情况下,查询性能可能会相当差,因为应用WHERE子句条件可能需要对每个列值进行完整扫描。虽然ClickHouse在这些情况下仍然相对较快,但计算数百万或数十亿个单独的值将导致“非索引”查询的执行速度比基于主键的查询慢得多。
在传统的关系数据库中,解决这个问题的一种方法是将一个或多个“二级”索引附加到表上。这是一个b-树结构,允许数据库在O(log(n))时间内找到磁盘上所有匹配的行,而不是O(n)时间(一次表扫描),其中n是行数。但是,这种类型的二级索引不适用于ClickHouse(或其他面向列的数据库),因为磁盘上没有单独的行可以添加到索引中。
相反,ClickHouse提供了一种不同类型的索引,在特定情况下可以显著提高查询速度。这些结构被标记为跳数索引,因为它们使ClickHouse能够跳过保证没有匹配值的数据块。
基本操作
用户只能在MergeTree表引擎上使用数据跳数索引。每个跳数索引都有四个主要参数:
- 索引名称。索引名用于在每个分区中创建索引文件。此外,在删除或具体化索引时需要将其作为参数。
- 索引的表达式。索引表达式用于计算存储在索引中的值集。它可以是列、简单操作符、函数的子集的组合。
- 类型。索引的类型控制计算,该计算决定是否可以跳过读取和计算每个索引块。
- GRANULARITY。每个索引块由颗粒(granule)组成。例如,如果主表索引粒度为8192行,GRANULARITY为4,则每个索引“块”将为32768行。
当用户创建数据跳数索引时,表的每个数据部分目录中将有两个额外的文件。
- skpidx{index_name}.idx:包含排序的表达式值。
- skpidx{index_name}.mrk2:包含关联数据列文件中的相应偏移量。
如果在执行查询并读取相关列文件时,WHERE子句过滤条件的某些部分与跳数索引表达式匹配,ClickHouse将使用索引文件数据来确定每个相关的数据块是必须被处理还是可以被绕过(假设块还没有通过应用主键索引被排除)。这里用一个非常简单的示例:考虑以下加载了可预测数据的表。
CREATE TABLE skip_table
(
my_key UInt64,
my_value UInt64
)
ENGINE MergeTree primary key my_key
SETTINGS index_granularity=8192;
INSERT INTO skip_table SELECT number, intDiv(number,4096) FROM numbers(100000000);
当执行一个不使用主键的简单查询时,将扫描my_value列所有的一亿条记录:
SELECT * FROM skip_table WHERE my_value IN (125, 700)
┌─my_key─┬─my_value─┐
│ 512000 │ 125 │
│ 512001 │ 125 │
│ ... | ... |
└────────┴──────────┘
8192 rows in set. Elapsed: 0.079 sec. Processed 100.00 million rows, 800.10 MB (1.26 billion rows/s., 10.10 GB/s.
增加一个基本的跳数索引:
ALTER TABLE skip_table ADD INDEX vix my_value TYPE set(100) GRANULARITY 2;
通常,跳数索引只应用于新插入的数据,所以仅仅添加索引不会影响上述查询。
要使已经存在的数据生效,那执行:
ALTER TABLE skip_table MATERIALIZE INDEX vix;
重跑SQL:
SELECT * FROM skip_table WHERE my_value IN (125, 700)
┌─my_key─┬─my_value─┐
│ 512000 │ 125 │
│ 512001 │ 125 │
│ ... | ... |
└────────┴──────────┘
8192 rows in set. Elapsed: 0.051 sec. Processed 32.77 thousand rows, 360.45 KB (643.75 thousand rows/s., 7.08 MB/s.)
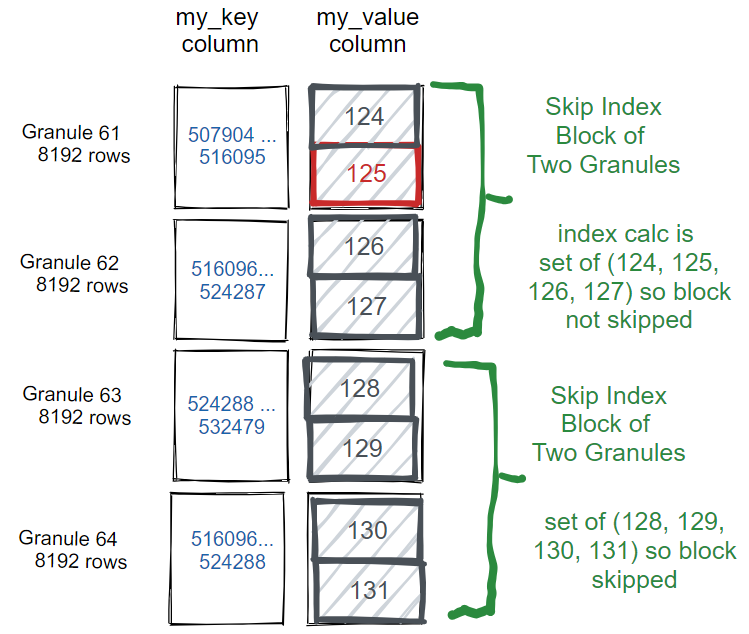
这次没有再去处理1亿行800MB的数据,ClickHouse只读取和分析32768行360KB的数据—4个granule的数据。
下图是更直观的展示,这就是如何读取和选择my_value为125的4096行,以及如何跳过以下行而不从磁盘读取:
通过在执行查询时启用跟踪,用户可以看到关于跳数索引使用情况的详细信息。在clickhouse-client中设置send_logs_level:
SET send_logs_level='trace';
这将在尝试调优查询SQL和表索引时提供有用的调试信息。上面的例子中,调试日志显示跳数索引过滤了大部分granule,只读取了两个:
<Debug> default.skip_table (933d4b2c-8cea-4bf9-8c93-c56e900eefd1) (SelectExecutor): Index `vix` has dropped 6102/6104 granules.
跳数索引类型
minmax
这种轻量级索引类型不需要参数。它存储每个块的索引表达式的最小值和最大值(如果表达式是一个元组,它分别存储元组元素的每个成员的值)。对于倾向于按值松散排序的列,这种类型非常理想。在查询处理期间,这种索引类型的开销通常是最小的。
这种类型的索引只适用于标量或元组表达式——索引永远不适用于返回数组或map数据类型的表达式。
set
这种轻量级索引类型接受单个参数max_size,即每个块的值集(0允许无限数量的离散值)。这个集合包含块中的所有值(如果值的数量超过max_size则为空)。这种索引类型适用于每组颗粒中基数较低(本质上是“聚集在一起”)但总体基数较高的列。
该索引的成本、性能和有效性取决于块中的基数。如果每个块包含大量惟一值,那么针对大型索引集计算查询条件将非常昂贵,或者由于索引超过max_size而为空,因此索引将不应用。
Bloom Filter Types
Bloom filter是一种数据结构,它允许对集合成员进行高效的是否存在测试,但代价是有轻微的误报。在跳数索引的使用场景,假阳性不是一个大问题,因为惟一的问题只是读取一些不必要的块。潜在的假阳性意味着索引表达式应该为真,否则有效的数据可能会被跳过。
因为Bloom filter可以更有效地处理大量离散值的测试,所以它们可以适用于大量条件表达式判断的场景。特别的是Bloom filter索引可以应用于数组,数组中的每个值都被测试,也可以应用于map,通过使用mapKeys或mapValues函数将键或值转换为数组。
有三种基于Bloom过滤器的数据跳数索引类型:
- 基本的bloom_filter接受一个可选参数,该参数表示在0到1之间允许的“假阳性”率(如果未指定,则使用.025)。
- 更专业的tokenbf_v1。需要三个参数,用来优化布隆过滤器:(1)过滤器的大小字节(大过滤器有更少的假阳性,有更高的存储成本),(2)哈希函数的个数(更多的散列函数可以减少假阳性)。(3)布隆过滤器哈希函数的种子。有关这些参数如何影响布隆过滤器功能的更多细节,请参阅 这里 。此索引仅适用于String、FixedString和Map类型的数据。输入表达式被分割为由非字母数字字符分隔的字符序列。例如,列值
This is a candidate for a "full text" search将被分割为Thisisacandidateforfulltextsearch。它用于LIKE、EQUALS、in、hasToken()和类似的长字符串中单词和其他值的搜索。例如,一种可能的用途是在非结构的应用程序日志行列中搜索少量的类名或行号。 - 更专业的ngrambf_v1。该索引的功能与tokenbf_v1相同。在Bloom filter设置之前需要一个额外的参数,即要索引的ngram的大小。一个ngram是长度为n的任何字符串,比如如果n是4,
A short string会被分割为A sh`` sho,shor,hort,ort s,or st,r str,stri,trin,ring。这个索引对于文本搜索也很有用,特别是没有单词间断的语言,比如中文。
跳数索引函数
跳数索引核心目的是限制流行查询分析的数据量。鉴于ClickHouse数据的分析特性,这些查询的模式在大多数情况下都包含函数表达式。因此,跳数索引必须与常用函数正确交互才能提高效率。这种情况可能发生在:
- 插入数据并将索引定义为一个函数表达式(表达式的结果存储在索引文件中)或者
- 处理查询,并将表达式应用于存储的索引值,以确定是否排除数据块。
每种类型的跳数索引支持的函数列表可以查看 这里 。通常,集合索引和基于Bloom filter的索引(另一种类型的集合索引)都是无序的,因此不能用于范围。相反,最大最小值索引在范围中工作得特别好,因为确定范围是否相交非常快。部分匹配函数LIKE、startsWith、endsWith和hasToken的有效性取决于使用的索引类型、索引表达式和数据的特定形状。
跳数索引的配置
有两个可用的设置可应用于跳数索引。
- use_skip_indexes (0或1,默认为1)。不是所有查询都可以有效地使用跳过索引。如果一个特定的过滤条件可能包含很多颗粒,那么应用数据跳过索引将导致不必要的、有时甚至是非常大的成本。对于不太可能从任何跳过索引中获益的查询,将该值设置为0。
- force_data_skipping_indexes (以逗号分隔的索引名列表)。此设置可用于防止某些类型的低效查询。在某些情况下,除非使用跳过索引,否则查询表的开销太大,如果将此设置与一个或多个索引名一起使用,则对于任何没有使用所列索引的查询将返回一个异常。这将防止编写糟糕的查询消耗服务器资源。
最佳实践
跳数索引并不直观,特别是对于来自RDMS领域并且习惯二级行索引或来自文档存储的反向索引的用户来说。要获得任何优化,应用ClickHouse数据跳数索引必须避免足够多的颗粒读取,以抵消计算索引的成本。关键是,如果一个值在一个索引块中只出现一次,就意味着整个块必须读入内存并计算,而索引开销是不必要的。
考虑以下数据分布:
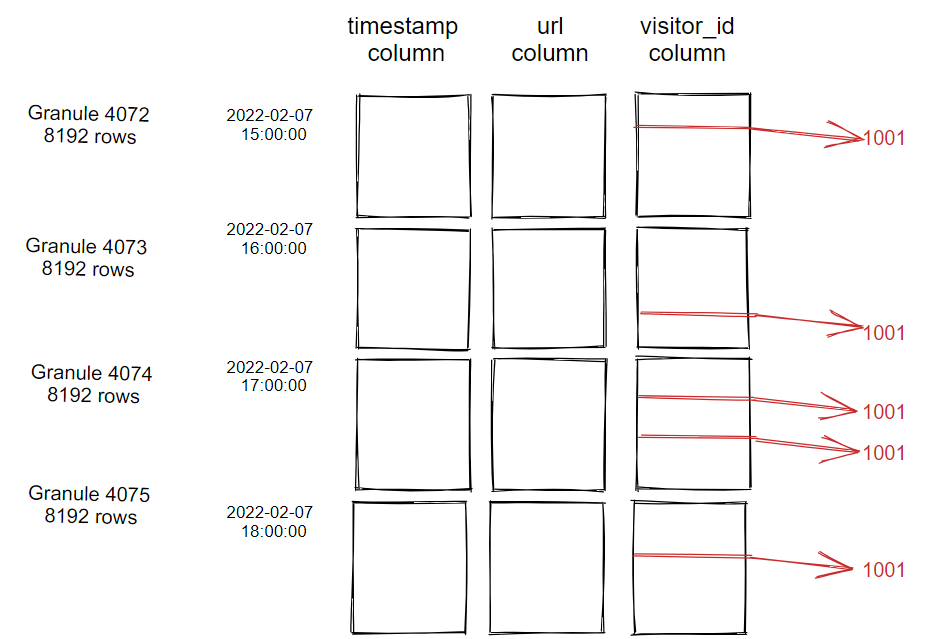
假设主键/顺序是时间戳,并且在visitor_id上有一个索引。考虑下面的查询:
SELECT timestamp, url FROM table WHERE visitor_id = 1001
对于这种数据分布,传统的二级索引非常有利。不是读取所有的32678行来查找具有请求的visitor_id的5行,而是二级索引只包含5行位置,并且只从磁盘读取这5行。ClickHouse数据跳过索引的情况正好相反。无论跳转索引的类型是什么,visitor_id列中的所有32678值都将被测试。
因此,试图通过简单地向键列添加索引来加速ClickHouse查询的冲动通常是不正确的。只有在研究了其他替代方法之后,才应该使用此高级功能,例如修改主键(查看 如何选择主键)、使用投影或使用实体化视图。即使跳数索引是合适的,也经常需要对索引和表进行仔细的调优。
在大多数情况下,一个有用的跳数索引需要主键和目标的非主列/表达式之间具有很强的相关性。如果没有相关性(如上图所示),那么在包含数千个值的块中,至少有一行满足过滤条件的可能性很高,并且只有几个块会被跳过。相反,如果主键的值范围(如一天中的时间)与潜在索引列中的值强相关(如电视观众年龄),则最小值类型的索引可能是有益的。注意,在插入数据时,可以增加这种相关性,方法是在sort /ORDER by键中包含额外的列,或者以在插入时对与主键关联的值进行分组的方式对插入进行批处理。例如,即使主键是一个包含大量站点事件的时间戳,特定site_id的所有事件也都可以被分组并由写入进程插入到一起,这将导致许多只包含少量站点id的颗粒,因此当根据特定的site_id值搜索时,可以跳过许多块。
跳数索引的另一个候选者是高基数表达式,其中任何一个值在数据中都相对稀疏。一个可能的例子是跟踪API请求中的错误代码的可观察性平台。某些错误代码虽然在数据中很少出现,但对搜索来说可能特别重要。error_code列上的set skip索引将允许绕过绝大多数不包含错误的块,从而显著改善针对错误的查询。
最后,关键的最佳实践是测试、测试、再测试。同样,与用于搜索文档的b-树二级索引或倒排索引不同,跳数索引行为是不容易预测的。将它们添加到表中会在数据摄取和查询方面产生很大的成本,这些查询由于各种原因不能从索引中受益。它们应该总是在真实世界的数据类型上进行测试,测试应该包括类型、粒度大小和其他参数的变化。测试通常会暴露仅仅通过思考不能发现的陷阱。
主键稀疏索引
全表扫描
为了了解在没有主键的情况下如何对数据集执行查询,我们通过执行以下SQL DDL语句(使用MergeTree表引擎)创建了一个表:
CREATE TABLE hits_NoPrimaryKey
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY tuple();
接下来,使用以下插入SQL将命中数据集的一个子集插入到表中。这个SQL使用URL表函数和类型推断从clickhouse.com加载一个数据集的一部分数据:
INSERT INTO hits_NoPrimaryKey SELECT
intHash32(c11::UInt64) AS UserID,
c15 AS URL,
c5 AS EventTime
FROM url('https://datasets.clickhouse.com/hits/tsv/hits_v1.tsv.xz')
WHERE URL != '';
结果:
Ok.
0 rows in set. Elapsed: 145.993 sec. Processed 8.87 million rows, 18.40 GB (60.78 thousand rows/s., 126.06 MB/s.)
ClickHouse客户端输出了执行结果,插入了887万行数据。
最后,为了简化本文后面的讨论,并使图表和结果可重现,我们使用FINAL关键字optimize该表:
OPTIMIZE TABLE hits_NoPrimaryKey FINAL;
一般来说,不需要也不建议在加载数据后立即执行optimize。对于这个示例,为什么需要这样做是很明显的。
现在我们执行第一个web分析查询。以下是用户id为749927693的互联网用户点击次数最多的前10个url:
SELECT URL, count(URL) as Count
FROM hits_NoPrimaryKey
WHERE UserID = 749927693
GROUP BY URL
ORDER BY Count DESC
LIMIT 10;
结果:
┌─URL────────────────────────────┬─Count─┐
│ http://auto.ru/chatay-barana.. │ 170 │
│ http://auto.ru/chatay-id=371...│ 52 │
│ http://public_search │ 45 │
│ http://kovrik-medvedevushku-...│ 36 │
│ http://forumal │ 33 │
│ http://korablitz.ru/L_1OFFER...│ 14 │
│ http://auto.ru/chatay-id=371...│ 14 │
│ http://auto.ru/chatay-john-D...│ 13 │
│ http://auto.ru/chatay-john-D...│ 10 │
│ http://wot/html?page/23600_m...│ 9 │
└────────────────────────────────┴───────┘
10 rows in set. Elapsed: 0.022 sec.
Processed 8.87 million rows,
70.45 MB (398.53 million rows/s., 3.17 GB/s.)
ClickHouse客户端输出表明,ClickHouse执行了一个完整的表扫描!我们的表的887万行中的每一行都被加载到ClickHouse中,这不是可扩展的。
为了使这种(方式)更有效和更快,我们需要使用一个具有适当主键的表。这将允许ClickHouse自动(基于主键的列)创建一个稀疏的主索引,然后可以用于显著加快我们示例查询的执行。
包含主键的表
创建一个包含联合主键UserID和URL列的表:
CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;
上面DDL语句中的主键会基于两个指定的键列创建主索引。
插入数据:
INSERT INTO hits_UserID_URL SELECT
intHash32(c11::UInt64) AS UserID,
c15 AS URL,
c5 AS EventTime
FROM url('https://datasets.clickhouse.com/hits/tsv/hits_v1.tsv.xz')
WHERE URL != '';
结果:
0 rows in set. Elapsed: 149.432 sec. Processed 8.87 million rows, 18.40 GB (59.38 thousand rows/s., 123.16 MB/s.)
optimize表:
OPTIMIZE TABLE hits_UserID_URL FINAL;
我们可以使用下面的查询来获取关于表的元数据:
SELECT
part_type,
path,
formatReadableQuantity(rows) AS rows,
formatReadableSize(data_uncompressed_bytes) AS data_uncompressed_bytes,
formatReadableSize(data_compressed_bytes) AS data_compressed_bytes,
formatReadableSize(primary_key_bytes_in_memory) AS primary_key_bytes_in_memory,
marks,
formatReadableSize(bytes_on_disk) AS bytes_on_disk
FROM system.parts
WHERE (table = 'hits_UserID_URL') AND (active = 1)
FORMAT Vertical;
结果:
part_type: Wide
path: ./store/d9f/d9f36a1a-d2e6-46d4-8fb5-ffe9ad0d5aed/all_1_9_2/
rows: 8.87 million
data_uncompressed_bytes: 733.28 MiB
data_compressed_bytes: 206.94 MiB
primary_key_bytes_in_memory: 96.93 KiB
marks: 1083
bytes_on_disk: 207.07 MiB
1 rows in set. Elapsed: 0.003 sec.
客户端输出表明:
- 表数据以wide format存储在一个特定目录,每个列有一个数据文件和mark文件。
- 表有887万行数据。
- 未压缩的数据有733.28 MB。
- 压缩之后的数据有206.94 MB。
- 有1083个主键索引条目,大小是96.93 KB。
- 在磁盘上,表的数据、标记文件和主索引文件总共占用207.07 MB。
针对海量数据规模的索引设计
在传统的关系数据库管理系统中,每个表行包含一个主索引。对于我们的数据集,这将导致主索引——通常是一个B(+)-Tree的数据结构——包含887万个条目。
这样的索引允许快速定位特定的行,从而提高查找点查和更新的效率。在B(+)-Tree数据结构中搜索一个条目的平均时间复杂度为O(log2n)。对于一个有887万行的表,这意味着需要23步来定位任何索引条目。
这种能力是有代价的:额外的磁盘和内存开销,以及向表中添加新行和向索引中添加条目时更高的插入成本(有时还需要重新平衡B-Tree)。
考虑到与B-Tee索引相关的挑战,ClickHouse中的表引擎使用了一种不同的方法。ClickHouseMergeTree Engine引擎系列被设计和优化用来处理大量数据。
这些表被设计为每秒接收数百万行插入,并存储非常大(100 pb)的数据量。
数据被一批一批的快速写入表中,并在后台应用合并规则。
在ClickHouse中,每个数据部分(data part)都有自己的主索引。当他们被合并时,合并部分的主索引也被合并。
在大规模中情况下,磁盘和内存的效率是非常重要的。因此,不是为每一行创建索引,而是为一组数据行(称为颗粒(granule))构建一个索引条目。
之所以可以使用这种稀疏索引,是因为ClickHouse会按照主键列的顺序将一组行存储在磁盘上。
与直接定位单个行(如基于B-Tree的索引)不同,稀疏主索引允许它快速(通过对索引项进行二分查找)识别可能匹配查询的行组。
然后潜在的匹配行组(颗粒)以并行的方式被加载到ClickHouse引擎中,以便找到匹配的行。
这种索引设计允许主索引很小(它可以而且必须完全适合主内存),同时仍然显著加快查询执行时间:特别是对于数据分析用例中常见的范围查询。
下面详细说明了ClickHouse是如何构建和使用其稀疏主索引的。在本文后面,我们将讨论如何选择、移除和排序用于构建索引的表列(主键列)的一些最佳实践。
数据按照主键排序存储在磁盘上
上面创建的表有:
- 如果我们只指定了排序键,那么主键将隐式定义为排序键。
- 为了提高内存效率,我们显式地指定了一个主键,只包含查询过滤的列。基于主键的主索引被完全加载到主内存中。
- 为了上下文的一致性和最大的压缩比例,我们单独定义了排序键,排序键包含当前表所有的列(和压缩算法有关,一般排序之后又更好的压缩率)。
- 如果同时指定了主键和排序键,则主键必须是排序键的前缀。
插入的行按照主键列(以及排序键的附加EventTime列)的字典序(从小到大)存储在磁盘上。
ClickHouse允许插入具有相同主键列的多行数据。在这种情况下(参见下图中的第1行和第2行),最终的顺序是由指定的排序键决定的,这里是EventTime列的值。
如下图所示:ClickHouse是列存数据库。
- 在磁盘上,每个表都有一个数据文件(*.bin),该列的所有值都以压缩格式存储,并且
- 在这个例子中,这887万行按主键列(以及附加的排序键列)的字典升序存储在磁盘上
- UserID第一位,
- 然后是URL,
- 最后是EventTime:
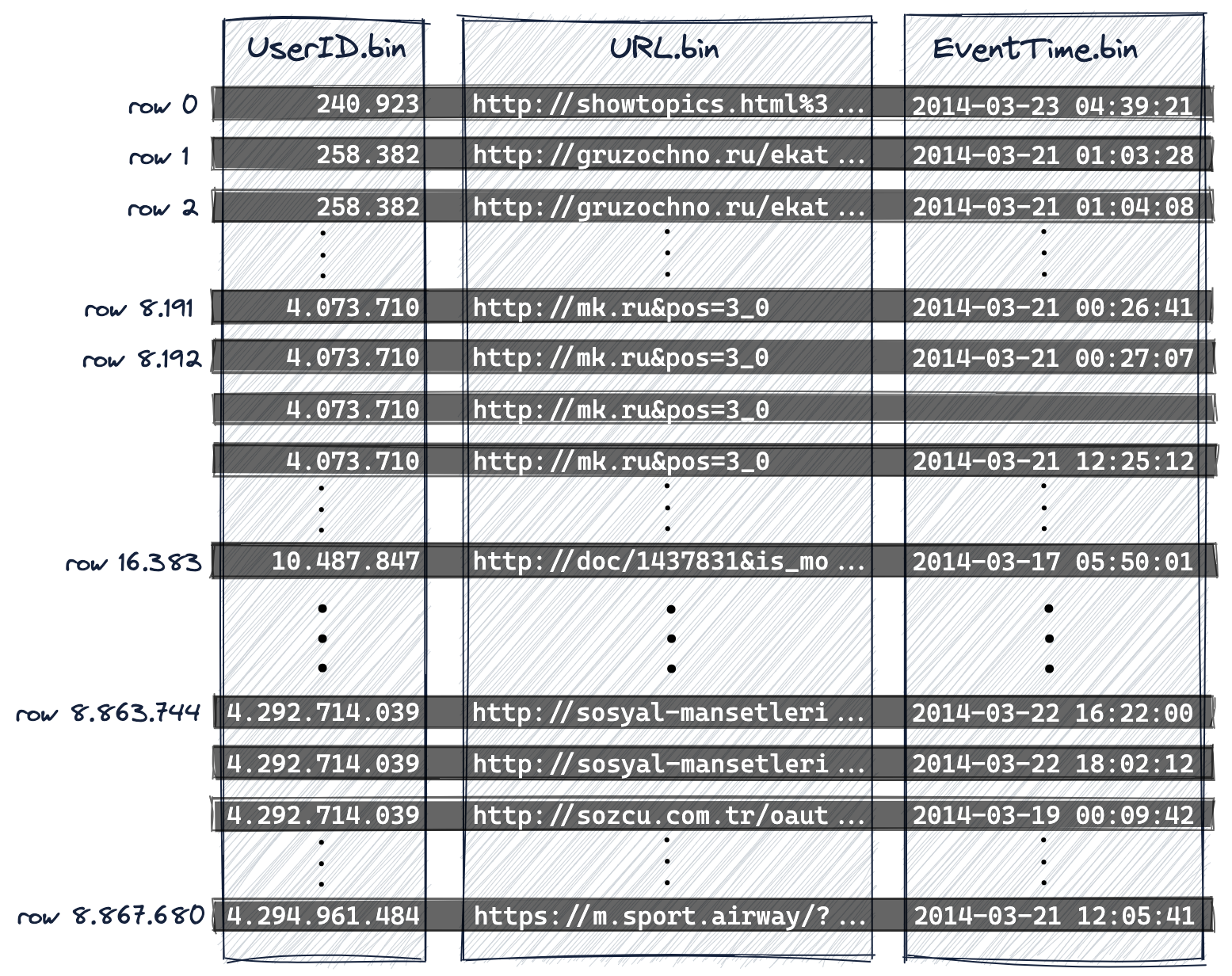
UserID.bin,URL.bin,和EventTime.bin是UserID,URL,和EventTime列的数据文件。
- 因为主键定义了磁盘上行的字典顺序,所以一个表只能有一个主键。
- 我们从0开始对行进行编号,以便与ClickHouse内部行编号方案对齐,该方案也用于记录消息。
数据被组织成颗粒以进行并行数据处理
出于数据处理的目的,表的列值在逻辑上被划分为多个颗粒。颗粒是流进ClickHouse进行数据处理的最小的不可分割数据集。这意味着,ClickHouse不是读取单独的行,而是始终读取(以流方式并并行地)整个行组(颗粒)。
列值并不物理地存储在颗粒中,颗粒只是用于查询处理的列值的逻辑组织方式。
下图显示了如何将表中的887万行(列值)组织成1083个颗粒,这是表的DDL语句包含设置index_granularity(设置为默认值8192)的结果。
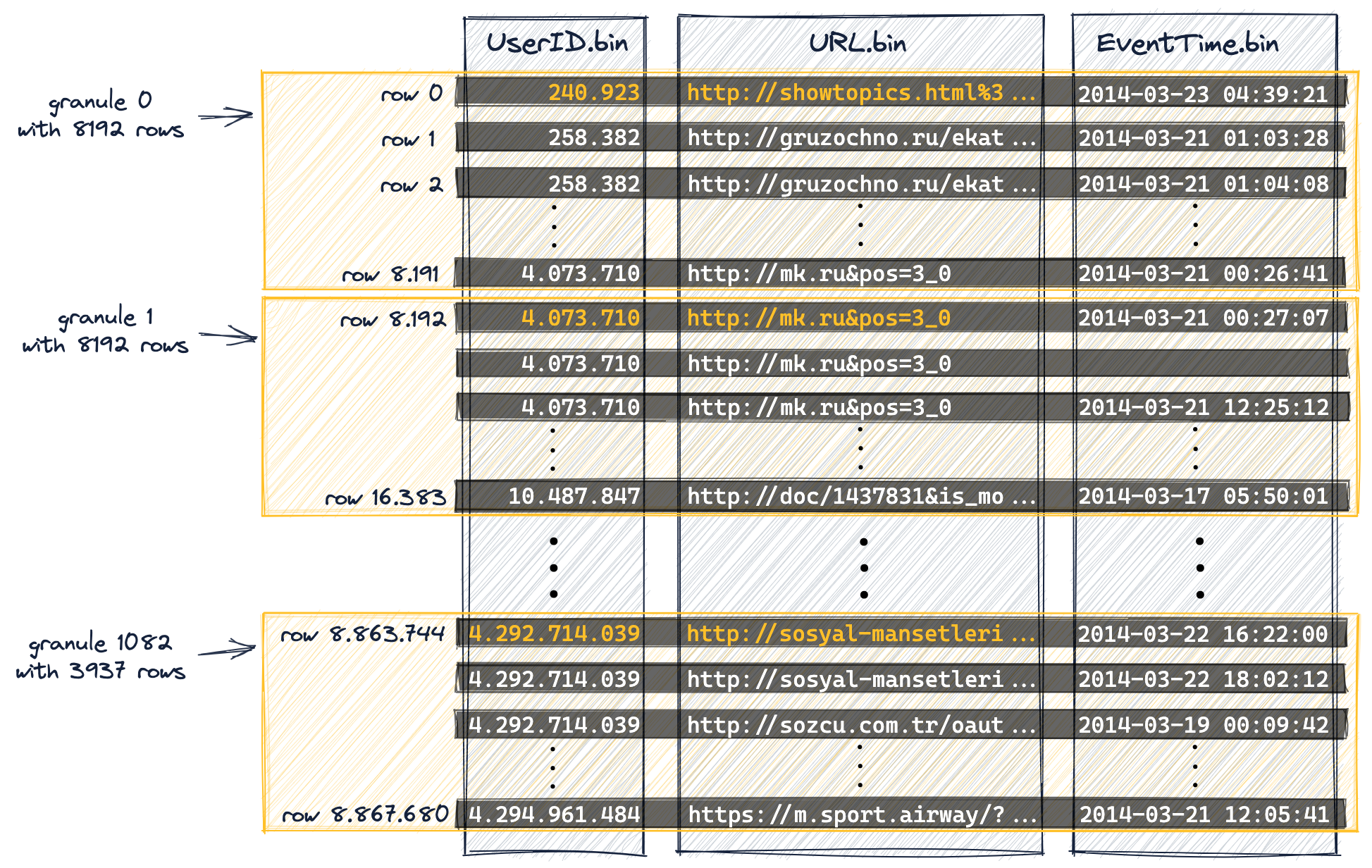
第一个(根据磁盘上的物理顺序)8192行(它们的列值)在逻辑上属于颗粒0,然后下一个8192行(它们的列值)属于颗粒1,以此类推。
最后一个颗粒(1082颗粒)是少于8192行的。
我们在本指南开头的“DDL 语句详细信息”中提到,我们禁用了自适应索引粒度(为了简化本指南中的讨论,并使图表和结果可重现)。
因此,示例表中所有颗粒(除了最后一个)都具有相同大小。
对于具有自适应索引粒度的表(默认情况下索引粒度是自适应的),某些粒度的大小可以小于 8192 行,具体取决于行数据大小。
我们将主键列(UserID, URL)中的一些列值标记为橙色。
这些橙色标记的列值是每个颗粒中第一行的主键列值。正如我们将在下面看到的,这些橙色标记的列值将是表主索引中的条目。
我们从0开始对行进行编号,以便与ClickHouse内部行编号方案对齐,该方案也用于记录消息。
每个颗粒对应主索引的一个条目
主索引是基于上图中显示的颗粒创建的。这个索引是一个未压缩的扁平数组文件(primary.idx),包含从0开始的所谓的数字索引标记。
下面的图显示了索引存储了每个颗粒的最小主键列值(在上面的图中用橙色标记的值)。 例如:
- 第一个索引条目(下图中的“mark 0”)存储上图中颗粒0的主键列的最小值,
- 第二个索引条目(下图中的“mark 1”)存储上图中颗粒1的主键列的最小值,以此类推。
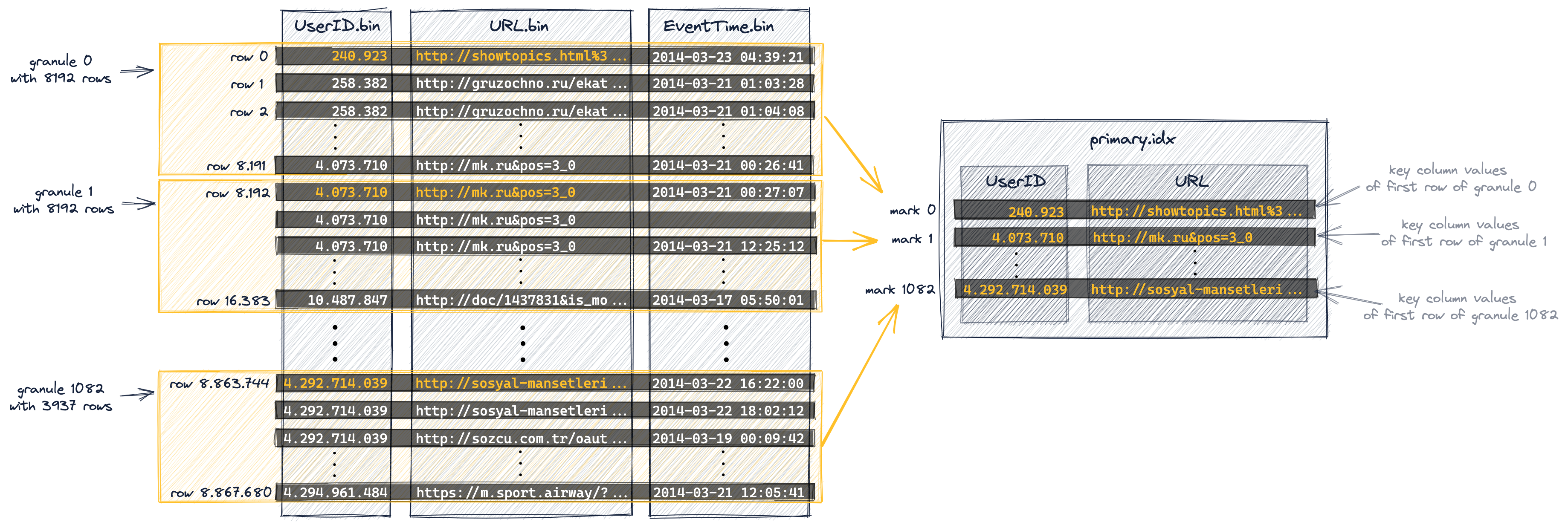
在我们的表中,索引总共有1083个条目,887万行数据和1083个颗粒:

- 最后一个索引条目(上图中的“mark 1082”)存储了上图中颗粒1082的主键列的最大值。
- 索引条目(索引标记)不是基于表中的特定行,而是基于颗粒。例如,对于上图中的索引条目‘mark 0’,在我们的表中没有UserID为240.923且URL为“goal://metry=10000467796a411…”的行,相反,对于该表,有一个颗粒0,在该颗粒中,最小UserID值是240.923,最小URL值是“goal://metry=10000467796a411…”,这两个值来自不同的行。
- 主索引文件完全加载到主内存中。如果文件大于可用的空闲内存空间,则ClickHouse将发生错误。
主键条目称为索引标记,因为每个索引条目都标志着特定数据范围的开始。对于示例表:
-
UserID index marks:
主索引中存储的UserID值按升序排序。
上图中的‘mark 1’指示颗粒1中所有表行的UserID值,以及随后所有颗粒中的UserID值,都保证大于或等于4.073.710。正如我们稍后将看到的, 当查询对主键的第一列进行过滤时,此全局有序使ClickHouse能够对第一个键列的索引标记使用二分查找算法。
-
URL index marks:
主键列UserID和URL有相同的基数,这意味着第一列之后的所有主键列的索引标记通常只表示每个颗粒的数据范围。
例如,‘mark 0’中的URL列所有的值都大于等于goal://metry=10000467796a411…, 然后颗粒1中的URL并不是如此,这是因为‘mark 1‘与‘mark 0‘具有不同的UserID列值。稍后我们将更详细地讨论这对查询执行性能的影响。
未完…
https://clickhouse.com/docs/zh/guides/best-practices
API
生成UUID
generateUUIDv4()
小数转Decimal
toDecimal64(数据, 小数点后精度)
提取数组元素
arrayElement(数组, 元素下标) as 取个字段名
注意:下标从1开始
将数组转换成逗号隔开的字符串
arrayStringConcat(数组, ',') 别名

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)