大模型开发(八):分布式计算框架
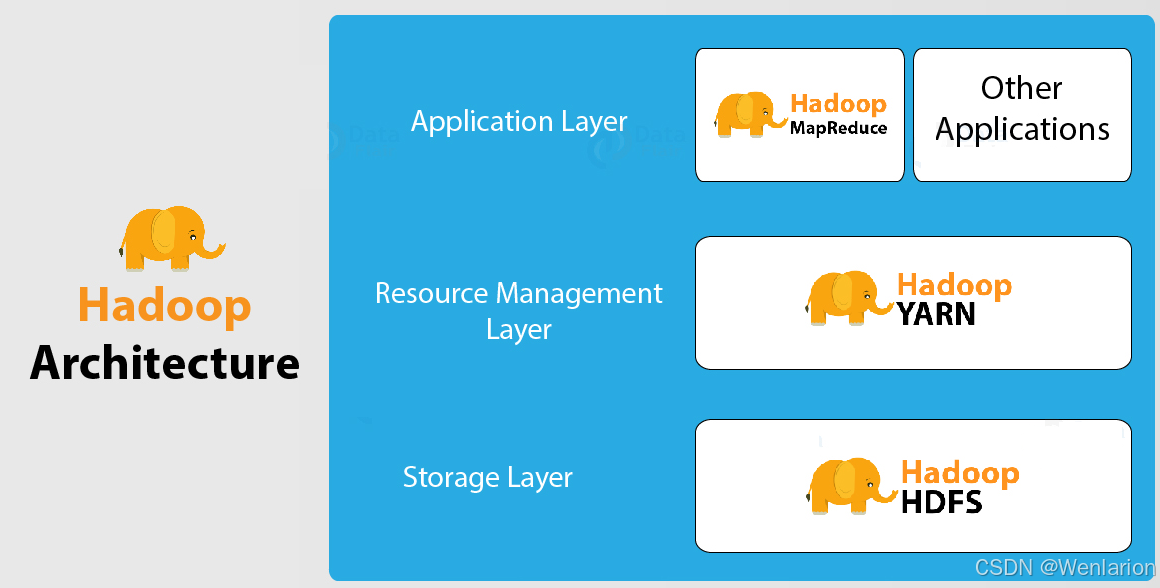
1、Hadoop
1.1 Apache Hadoop
1. Hadoop 介绍
Hadoop 是 Apache 旗下的一个用 Java 语言实现的开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
狭义上说,Hadoop 指 Apache 这款开源框架,它的核心组件有:
- HDFS(分布式文件系统):解决海量数据存储
- YARN(作业调度和集群资源管理的框架):解决资源任务调度
- MAPREDUCE(分布式运算编程框架):解决海量数据计算
广义上来说,Hadoop 通常是指一个更广泛的概念 ——Hadoop 生态圈。当下的 Hadoop 已经成长为一个庞大的体系,随着生态系统的成长,新出现的项目越来越多,其中不乏一些非 Apache 主管的项目,这些项目对 HADOOP 是很好的补充或者更高层的抽象。

2. Hadoop 发展简史
Hadoop 是 Apache Lucene 创始人 Doug Cutting 创建的,最早起源于 Nutch,它是 Lucene 的子项目。Nutch 的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题:如何解决数十亿网页的存储和索引问题。
- 2003 年 Google 发表了一篇论文为该问题提供了可行的解决方案,论文中描述的是谷歌的产品架构,该架构称为:谷歌分布式文件系统(GFS),可以解决他们在网页爬取和索引过程中产生的超大文件的存储需求。
- 2004 年 Google 发表论文向全世界介绍了谷歌版的 MapReduce 系统。
- 同时期,Nutch 的开发人员完成了相应的开源实现 HDFS 和 MAPREDUCE,并从 Nutch 中剥离成为独立项目 HADOOP,到 2008 年 1 月,HADOOP 成为 Apache 顶级项目,迎来了它的快速发展期。
- 2006 年 Google 发表了论文是关于 BigTable 的,这促使了后来的 Hbase 的发展。
因此,Hadoop 及其生态圈的发展离不开 Google 的贡献。
3. Hadoop 特性优点
- 扩容能力(Scalable):Hadoop 是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便地扩展到数以千计的节点中。
- 成本低(Economical):Hadoop 通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
- 高效率(Efficient):通过并发数据,Hadoop 可以在节点之间动态并行地移动数据,使得速度非常快。
- 可靠性(Reliable):能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以 Hadoop 的按位存储和处理数据的能力值得人们信赖。

4. Hadoop 国内外应用
不管是国内还是国外,Hadoop 最受青睐的行业是互联网领域,可以说互联网公司是 hadoop 的主要使用力量。
国外应用
- Yahoo:Hadoop 应用在支持广告系统、用户行为分析、支持 Web 搜索等。
- Facebook:主要使用 Hadoop 存储内部日志与多维数据,并以此作为报告、分析和机器学习的数据源。
- IBM 等公司也大量使用 Hadoop 集群来支撑业务。
国内应用
- 互联网领域:BAT 领头的互联网公司是 Hadoop 的主要使用者和维护者,例如 Ali 云梯(2014 年国内最大 Hadoop 集群)、百度的日志分析平台和推荐引擎系统等。
- 非互联网领域:
- 金融行业:个人征信分析
- 证券行业:投资模型分析
- 交通行业:车辆、路况监控分析
- 电信行业:用户上网行为分析
总之:Hadoop 并不会跟某种具体的行业或者某个具体的业务挂钩,它只是一种用来做海量数据分析处理的工具。
1.2 Hadoop集群搭建
1. 发行版本
Hadoop 发行版本分为开源社区版和商业版:
-
社区版:由 Apache 软件基金会维护的官方版本体系,官网:https://hadoop.apache.org/
-
商业版:由第三方商业公司在社区版基础上修改、整合并做兼容性测试后发行的版本,较著名的有 Cloudera 的 CDH、MapR、HortonWorks 等,Cloudera CDH 相关介绍:https://www.cloudera.com/products/open-source/apache-hadoop/key-cdh-components.html


版本演进
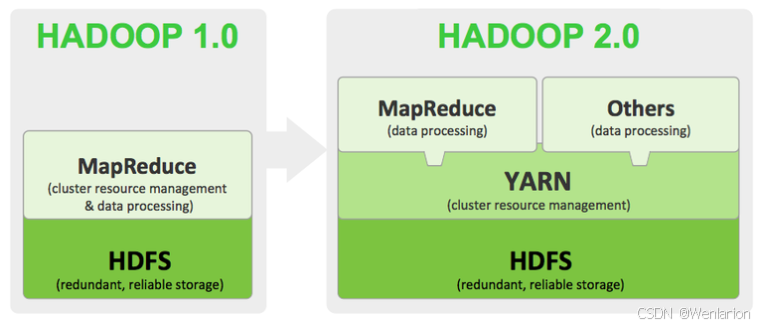
Hadoop 版本由多条分支并行发展,主要分为 3 大系列版本:
-
Hadoop 1.x:由 HDFS(分布式文件系统)+ MapReduce(离线计算框架)组成,架构落后,已淘汰。
-
Hadoop 2.x:由 HDFS + YARN(资源管理系统)+ MapReduce 组成,相比 1.x 功能更强大,扩展性与性能更好,支持多种计算框架。
-
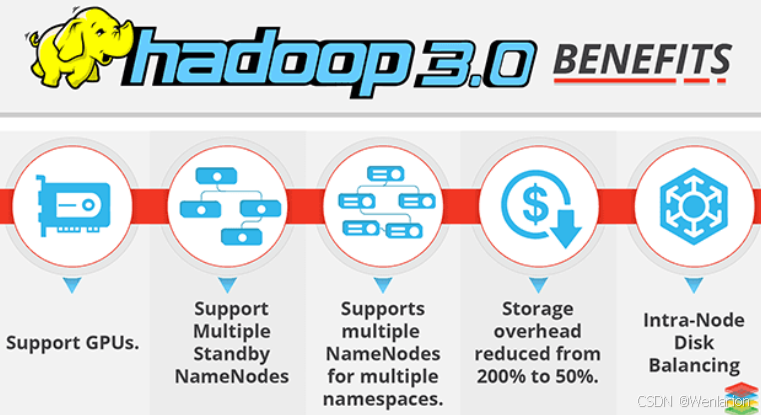
Hadoop 3.x:在 2.x 基础上做了功能增强,目前趋于稳定,核心改进包括:
-
支持 GPU
-
支持多个备用 NameNode
-
支持多 Namespace 下的多个 NameNode
-
存储开销从 200% 降至 50%
-
支持节点内磁盘均衡
-
课程使用版本:Apache Hadoop 3.3.0
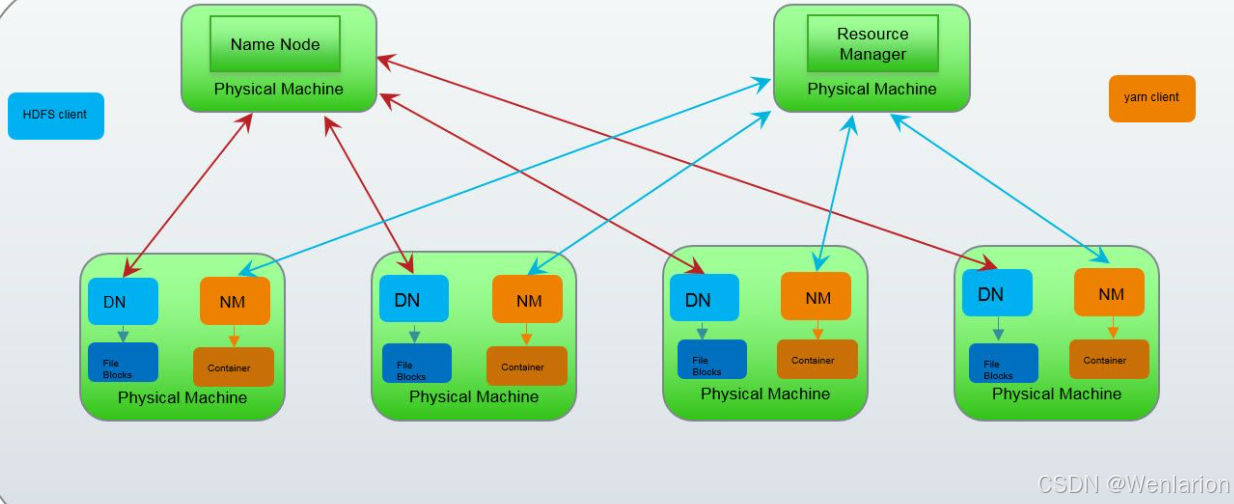
2. 集群简介
Hadoop 集群包含两个逻辑分离但物理常部署在一起的子集群:
-
HDFS 集群:负责海量数据存储,核心角色:
-
NameNode
-
DataNode
-
SecondaryNameNode
-
-
YARN 集群:负责海量数据运算时的资源调度,核心角色:
-
ResourceManager
-
NodeManager
-
MapReduce 说明
MapReduce 是分布式运算编程框架,是应用程序开发包,由用户按规范开发后打包运行在 HDFS 集群上,并受 YARN 集群资源调度管理。
部署模式
Hadoop 支持 3 种部署方式:
-
独立模式(Standalone mode):单机单 Java 进程,仅用于调试。
-
伪分布式模式(Pseudo-Distributed mode):单机多 Java 进程,模拟 HDFS 和 YARN 集群,用于调试。
-
集群模式(Cluster mode):多节点生产环境部署,主节点与从节点分离部署。
3 节点集群角色分配(课程示例)
|
节点 |
NameNode |
DataNode |
ResourceManager |
NodeManager |
SecondaryNameNode |
|---|---|---|---|---|---|
|
node1 |
✅ |
✅ |
✅ |
❌ |
❌ |
|
node2 |
❌ |
✅ |
❌ |
✅ |
✅ |
|
node3 |
❌ |
✅ |
❌ |
✅ |
❌ |








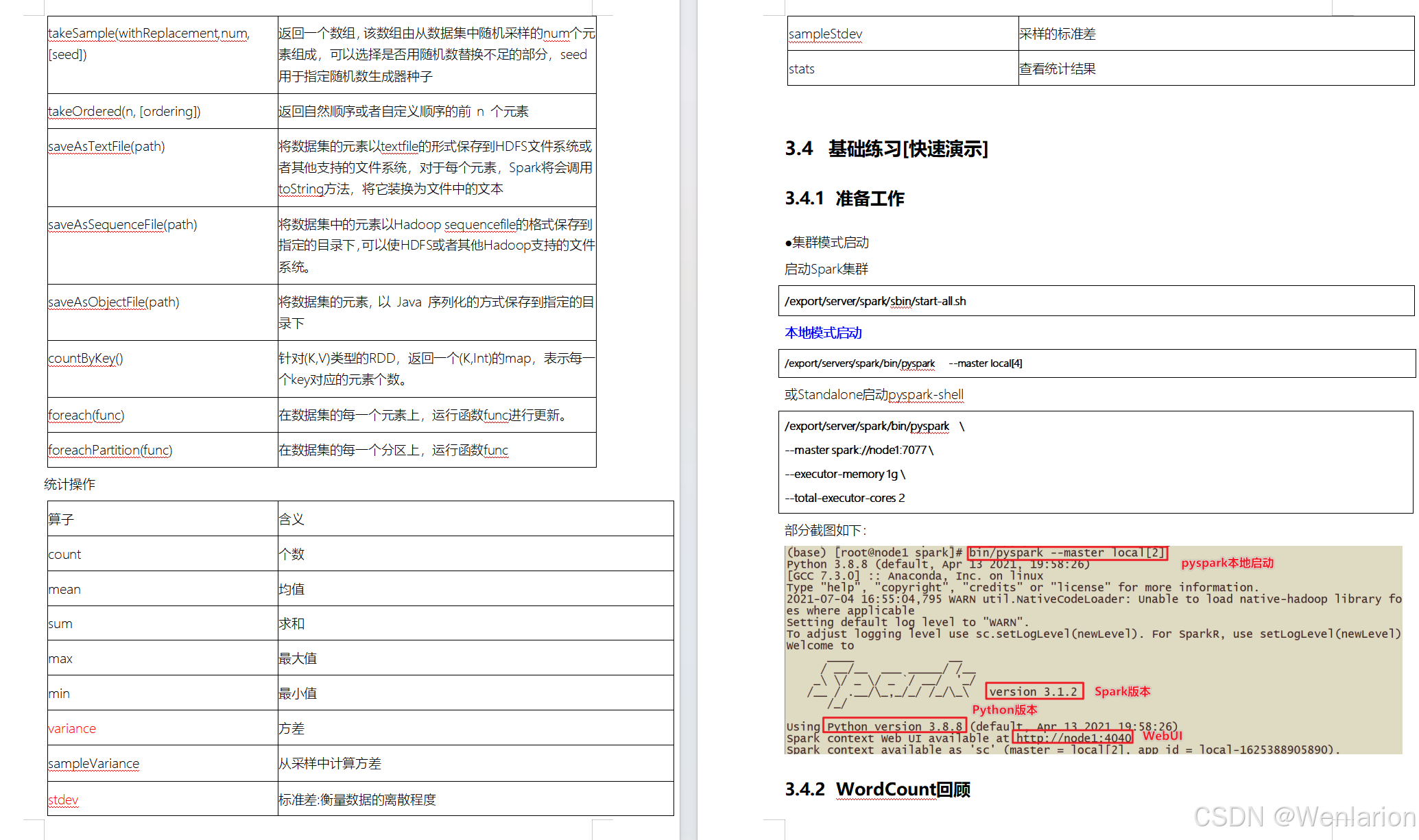
1.3 Hadoop 集群启动、初体验
1. 启动方式
启动 Hadoop 集群需要分别启动 HDFS 集群 和 YARN 集群。
⚠️ 重要注意:首次启动 HDFS 时,必须先对 NameNode 进行格式化操作(本质是清理与准备物理存储):
hadoop namenode -format
1.1 单节点逐个启动
启动 HDFS 服务
- 主节点(node1)启动 NameNode:
$HADOOP_HOME/bin/hdfs --daemon start namenode
- 所有从节点(node2、node3)启动 DataNode:
$HADOOP_HOME/bin/hdfs --daemon start datanode
- node2 启动 SecondaryNameNode:
$HADOOP_HOME/bin/hdfs --daemon start secondarynamenode
启动 YARN 服务
- 主节点(node1)启动 ResourceManager:
$HADOOP_HOME/bin/yarn --daemon start resourcemanager
- 所有从节点(node2、node3)启动 NodeManager:
$HADOOP_HOME/bin/yarn --daemon start nodemanager
✅ 停止服务:将命令中的
start替换为stop即可停止对应角色,例如:
$HADOOP_HOME/bin/hdfs --daemon stop namenode

1.4 MapReduce JobHistory
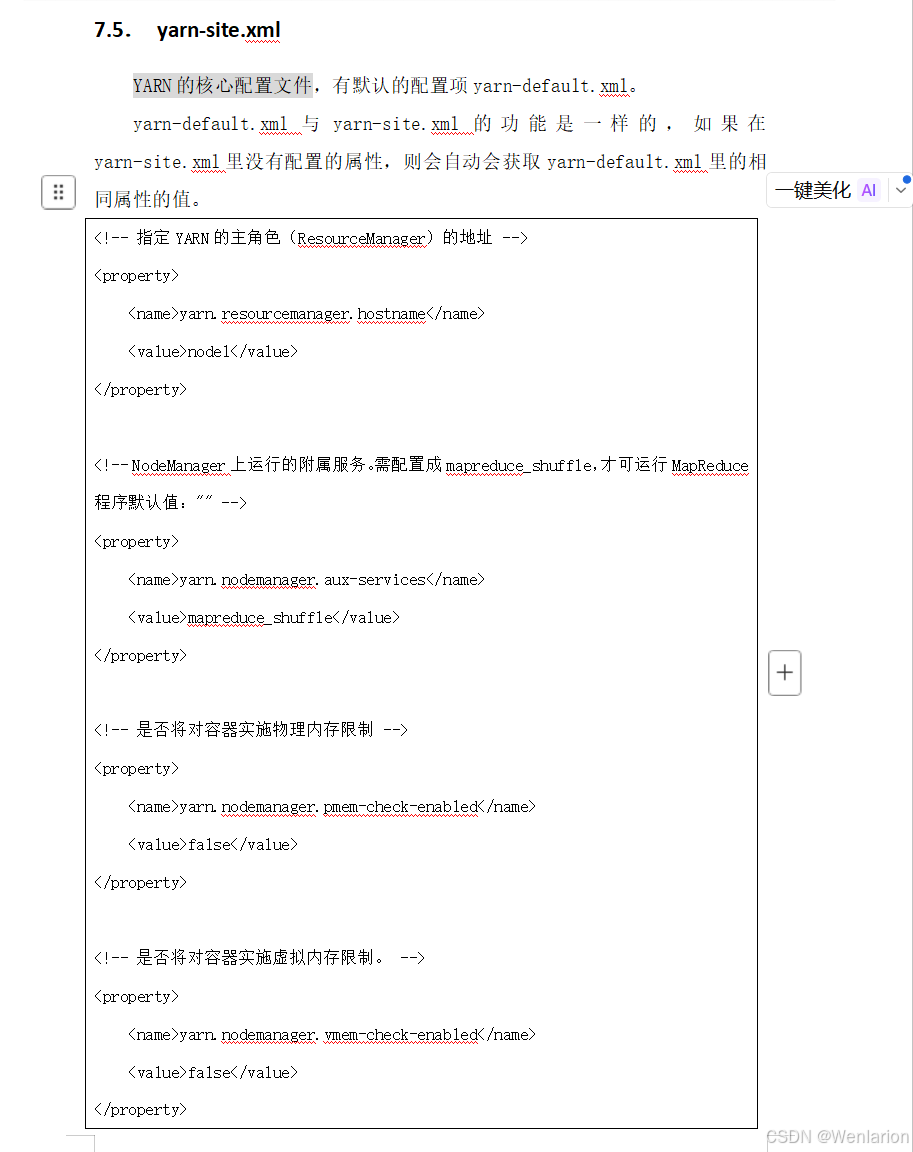
JobHistory 用于记录已完成的 MapReduce 作业运行日志,日志默认存储在 HDFS 中,默认未开启,需要在 mapred-site.xml 中配置并手动启动服务。
1. 修改 mapred-site.xml
进入配置目录并编辑文件
cd /export/servers/hadoop-3.3.0/etc/hadoop
vim mapred-site.xml
添加 JobHistory 相关配置
<!-- MR JobHistory Server 管理的日志存放地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- 查看历史作业记录的 Web UI 地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
补充说明
- 配置完成后,需将修改后的
mapred-site.xml分发到集群所有节点:scp mapred-site.xml node2:$PWD scp mapred-site.xml node3:$PWD - 之后需要手动启动 JobHistory 服务:
$HADOOP_HOME/bin/mapred --daemon start historyserver -
启动后可通过 Web 界面查看历史作业:
http://node1:19888

1.5 HDFS 的垃圾桶机制
1. 垃圾桶机制解析
HDFS 垃圾桶机制用于回收误删除的文件,避免重要数据丢失,被回收的文件可在保留期内恢复。
2. 垃圾桶机制配置
HDFS 默认垃圾桶回收属性为 0,即删除操作不可恢复。需修改 core-site.xml 开启:
<property>
<name>fs.trash.interval</name>
<!-- 回收站保存时间,单位:分钟(1440 = 24h = 1天) -->
<value>1440</value>
</property>
配置完成后,重启 HDFS 集群使配置生效。
3. 垃圾桶机制验证
- 启用后,
dfs命令删除的文件会被移动到用户专属垃圾目录:/user/<username>/.Trash - 保留期内可从垃圾桶恢复文件。
- 若需彻底删除文件(不进入垃圾桶),使用
-skipTrash选项:hdfs dfs -rm -skipTrash /path/to/file
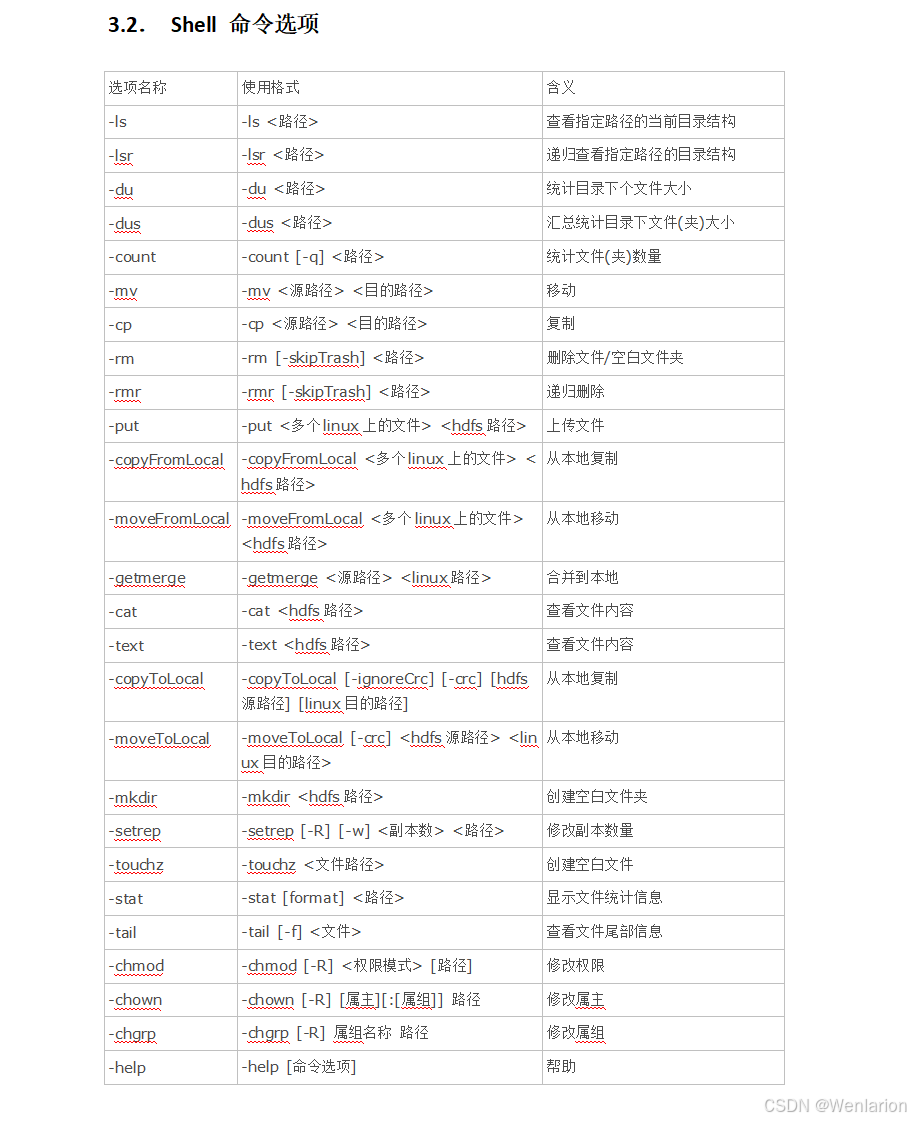
1.6 HDFS 入门
1. HDFS 基本概念
1.1. HDFS 介绍
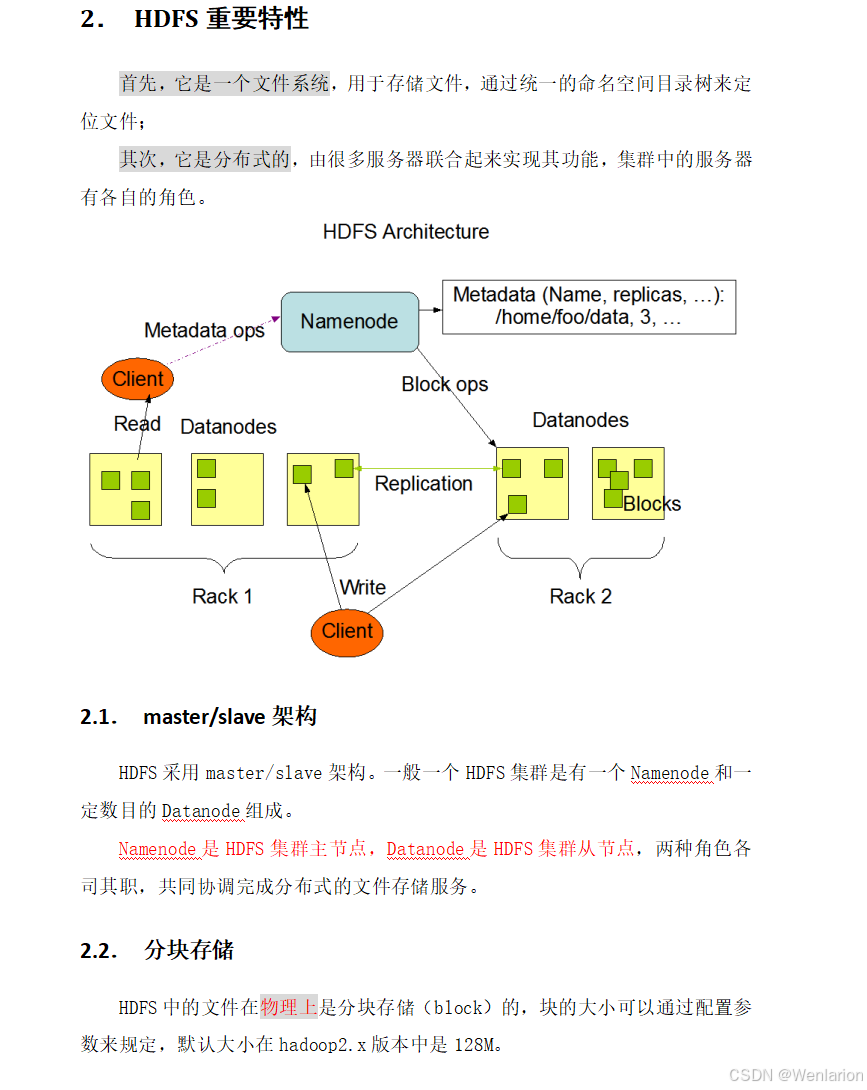
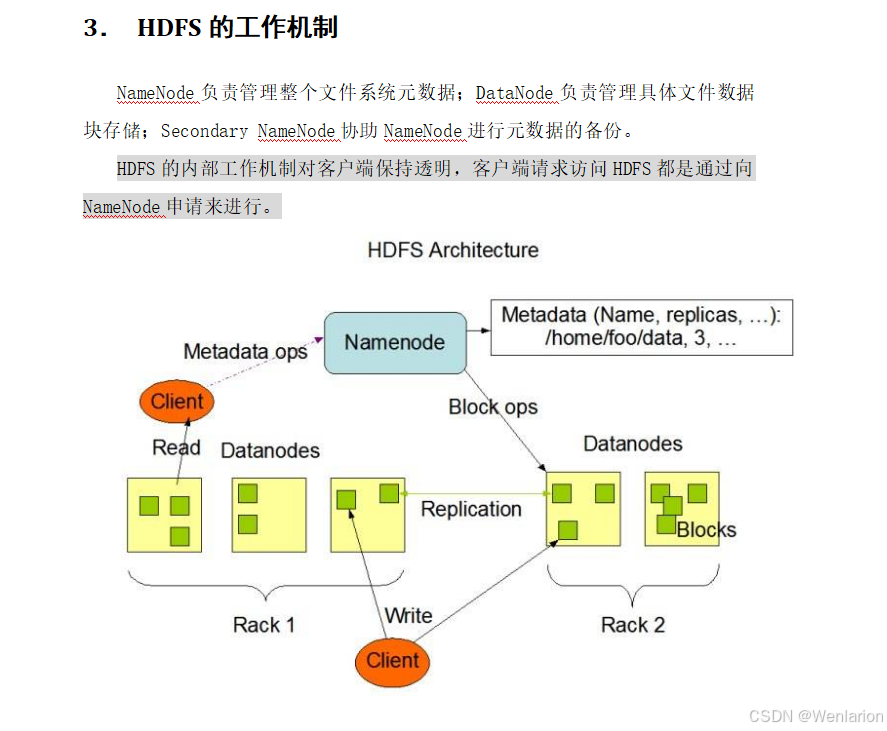
HDFS 是 Hadoop Distributed File System 的简称,意为 Hadoop 分布式文件系统,是 Hadoop 核心组件之一,作为最底层的分布式存储服务而存在。
分布式文件系统解决的核心问题是大数据存储,它是横跨在多台计算机上的存储系统,在大数据时代为存储和处理超大规模数据提供了所需的横向扩展能力。
从 Hadoop 生态架构图中可以清晰看到:
- HDFS 位于最底层的 Storage(存储层),是整个大数据生态的存储基石
- 上层的 YARN、Spark、Hive、HBase 等组件都依赖 HDFS 提供的分布式存储能力








1.7 HDFS 基本原理
1. NameNode 概述
NameNode 是 HDFS 的核心组件,也被称为 Master,其核心特性如下:
-
核心角色:仅存储 HDFS 的元数据(文件系统目录树、文件与块的映射关系),不存储实际数据。
-
数据位置:实际数据存储在 DataNode 中,NameNode 维护文件到块的映射及块所在 DataNode 的信息。
-
位置信息管理:NameNode 不持久化存储块与 DataNode 的位置映射,这些信息在系统启动时由 DataNode 上报重建。
-
单点故障:NameNode 是 Hadoop 集群的单点故障点,一旦关闭,整个 HDFS 集群将无法访问。
-
资源要求:NameNode 所在机器通常配置大量内存(RAM),用于高效维护元数据。
-
元数据存储:
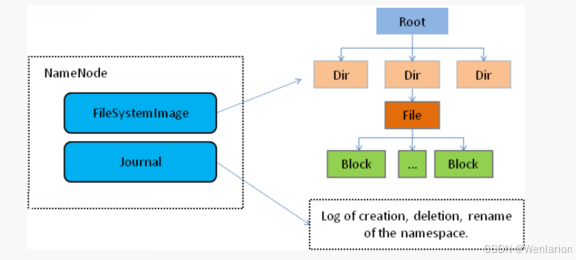
-
FileSystemImage:文件系统目录树的持久化快照 -
Journal(EditLog):命名空间的变更日志(创建、删除、重命名等操作)
-



1.8 HDFS 其他功能
1. 不同集群之间的数据复制
在实际工作中,经常需要在测试集群与生产集群之间进行数据远程拷贝,Hadoop 提供了对应的命令来实现该功能。
1.1 集群内部文件拷贝(scp)
用于在同一集群内的不同节点之间拷贝本地文件:
# 进入目标文件所在目录
cd /export/softwares/
# 递归拷贝文件到 node2 节点的 /export/ 目录下
scp -r jdk-8u141-linux-x64.tar.gz root@node2:/export/
1.2 跨集群之间的数据拷贝(distcp)
用于在不同 HDFS 集群之间高效拷贝数据,底层基于 MapReduce 实现分布式拷贝:
bin/hadoop distcp \
hdfs://node1:8020/jdk-8u141-linux-x64.tar.gz \
hdfs://cluster2:9000/
-
格式:
hadoop distcp <源集群HDFS路径> <目标集群HDFS路径> -
优势:支持分布式并行拷贝,适合大数据量跨集群迁移


2.4 Archive 注意事项
-
Hadoop archives 是特殊档案格式,一个 Hadoop archive 对应一个文件系统目录,扩展名为
.har。 -
创建 archives 本质是运行一个 Map/Reduce 任务,需在 Hadoop 集群上执行。
-
创建 archive 文件会消耗和原文件一样多的硬盘空间。
-
archive 文件不支持压缩,外观类似压缩包但实际无压缩效果。
-
archive 文件一旦创建无法修改,若需变更需重新创建新档案;通常用于定期存档(如每日 / 每周)。
-
创建 archive 时,源文件不会被更改或删除。
1.9 HDFS 元数据管理机制
1. 元数据管理概述
HDFS 元数据按类型分为三类:
-
文件 / 目录属性信息:文件名、目录名、修改时间等。
-
文件存储信息:块信息、分块情况、副本数等。
-
DataNode 信息:用于 DataNode 节点管理。
按形式分为:
-
内存元数据:存储在内存中,提供高效访问。
-
元数据文件:存储在磁盘上,用于持久化,分为两类:
-
fsimage(镜像文件):元数据的持久化检查点,包含所有目录和文件元数据,但不包含文件块位置信息(块位置仅存于内存,由 DataNode 上报后动态维护)。
-
Edits(编辑日志):记录文件系统所有变更操作(创建、删除、修改),客户端操作先写入 Edits 日志。
-
NameNode 启动时,会先加载 fsimage 到内存,再重放 Edits 日志,使内存元数据与磁盘状态一致。





1.10 SecondaryNameNode
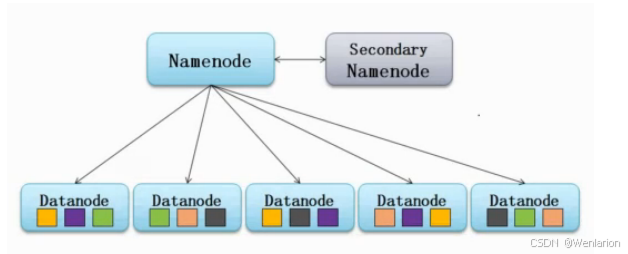
核心角色与背景问题
-
NameNode:管理 HDFS 元数据
-
DataNode:负责实际数据存储
-
SecondaryNameNode:并非 NameNode 的热备,核心职责是合并 NameNode 的 EditLog 到 FsImage,解决以下问题:
-
EditLog 文件会随集群运行不断变大,难以管理
-
NameNode 重启时需合并大量 EditLog 到 FsImage,启动耗时极长
-
NameNode 故障时,旧的 FsImage 会丢失后续变更
-
核心作用
SecondaryNameNode 就像系统的恢复点快照工具,定期将 EditLog 与 FsImage 合并,生成新的 FsImage,从而:
-
减小 EditLog 体积
-
减轻 NameNode 压力
-
加快 NameNode 故障恢复速度
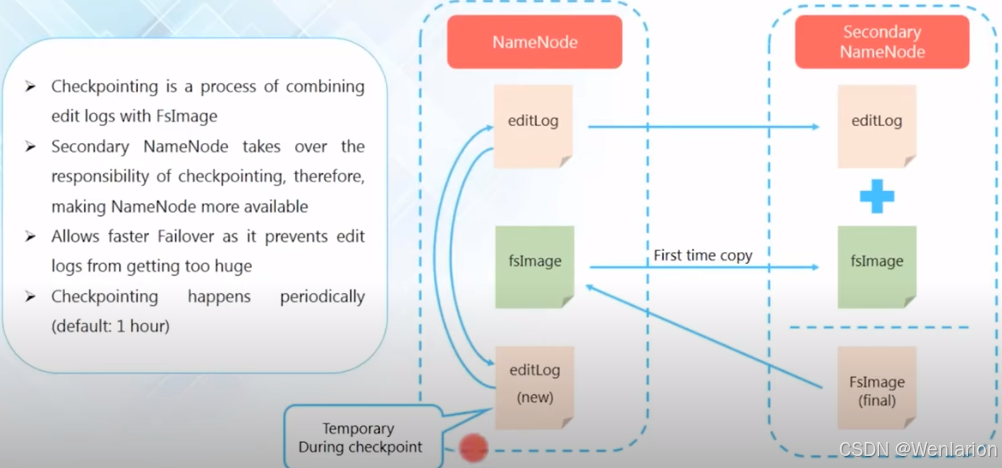
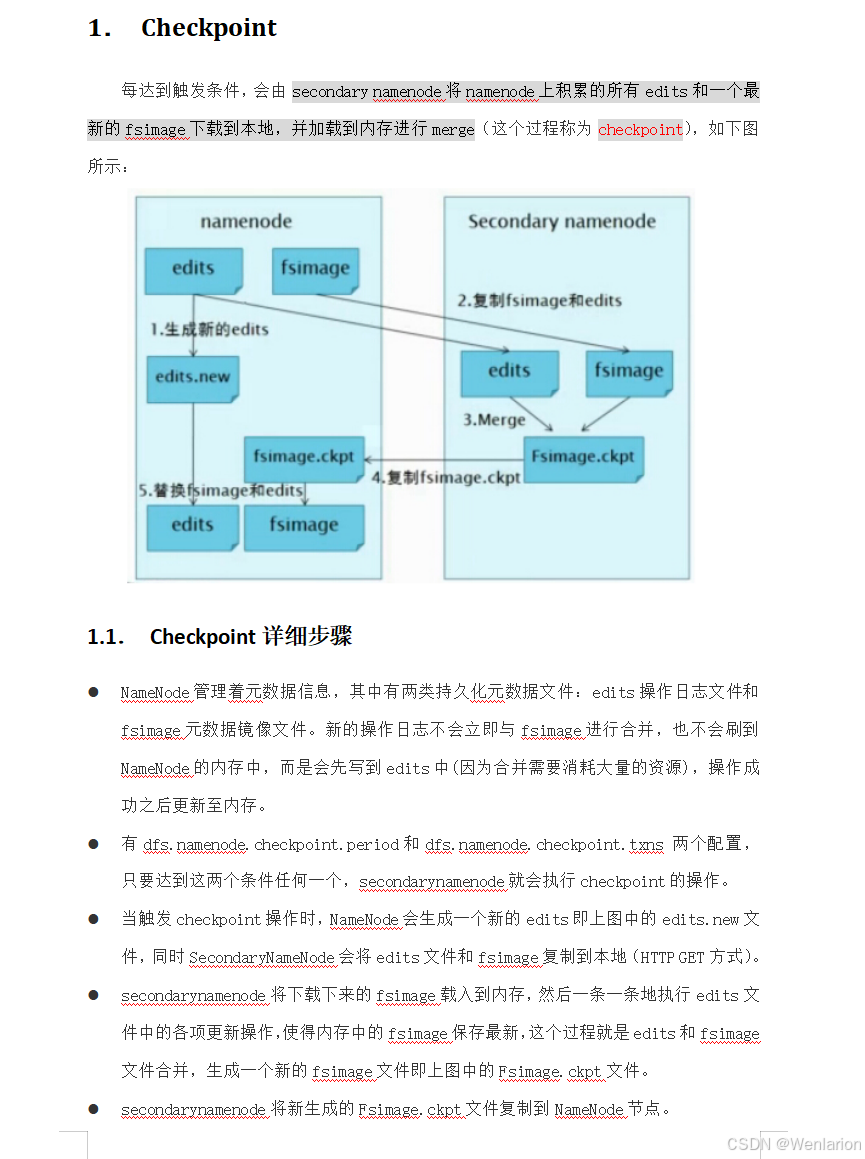
Checkpoint 机制(核心流程)
Checkpoint 是合并 EditLog 与 FsImage 的过程,由 SecondaryNameNode 负责执行:
-
SecondaryNameNode 从 NameNode 拉取当前的 FsImage 和 EditLog
-
在本地内存中合并两者,生成新的 FsImage
-
将新的 FsImage 回传给 NameNode
-
NameNode 用新 FsImage 替换旧文件,并清空旧 EditLog
⏱️ 默认周期:每 1 小时执行一次 Checkpoint,也可通过配置触发。

1.11 HDFS 安全模式
1. 安全模式概述
安全模式是 HDFS 的一种保护状态,在该状态下:
-
✅ 只接受读数据请求
-
❌ 拒绝删除、修改、上传等变更操作
-
作用:保证集群中数据块的安全性
进入与退出机制
-
进入时机:NameNode 主节点启动时,HDFS 自动进入安全模式,开始检查数据块完整性。
-
汇报机制:DataNode 启动后会向 NameNode 汇报可用 block 信息。
-
退出条件:当系统满足最小副本率标准时,自动退出安全模式。
副本率计算与阈值
-
副本数:由参数
dfs.replication设定(例如 5)。 -
副本率:实际可用副本数 / 期望副本数(例如 3/5 = 0.6)。
-
安全阈值:在
hdfs-default.xml中由dfs.namenode.safemode.threshold-pct定义,默认值为 0.999。-
若副本率 < 0.999:系统自动复制副本到其他 DataNode,直到满足阈值。
-
若副本数 > 设定值:系统自动删除多余副本。
-
安全模式下的限制
如果 HDFS 处于安全模式,客户端禁止执行任何修改操作,包括:
-
上传文件
-
删除文件
-
重命名文件
-
创建文件夹
-
修改副本数

1.12 初识 MapReduce
1. MapReduce 计算模型介绍
1.1 理解 MapReduce 思想
MapReduce 的核心思想是 “分而治之”:
-
把一个复杂的问题,按一定规则分解为若干规模较小的子问题
-
逐个解决每个子问题,得到各部分的局部结果
-
最后将各部分结果合并,得到整个问题的最终解
这种思想源于生活与工作经验,在技术领域广泛应用:
-
软件的体系结构设计、模块化开发都是 “分而治之” 的体现
-
Google 分布式计算的实现,本质也是对这一思想的工程化落地



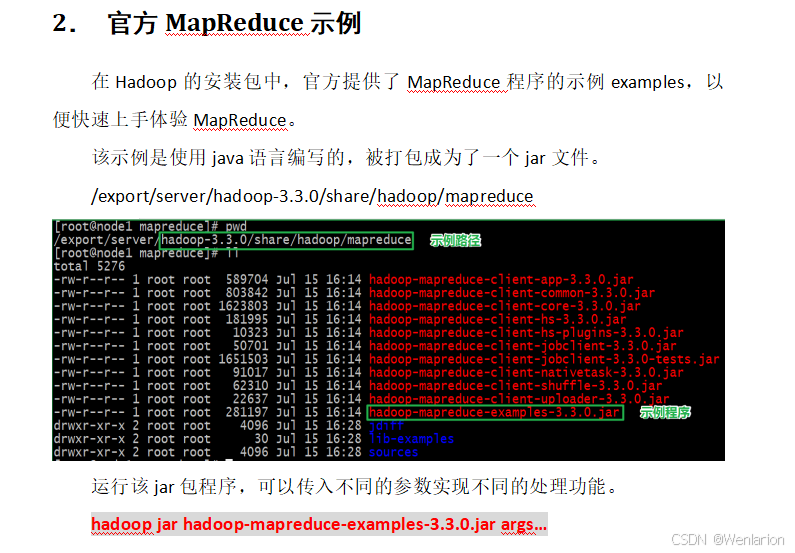

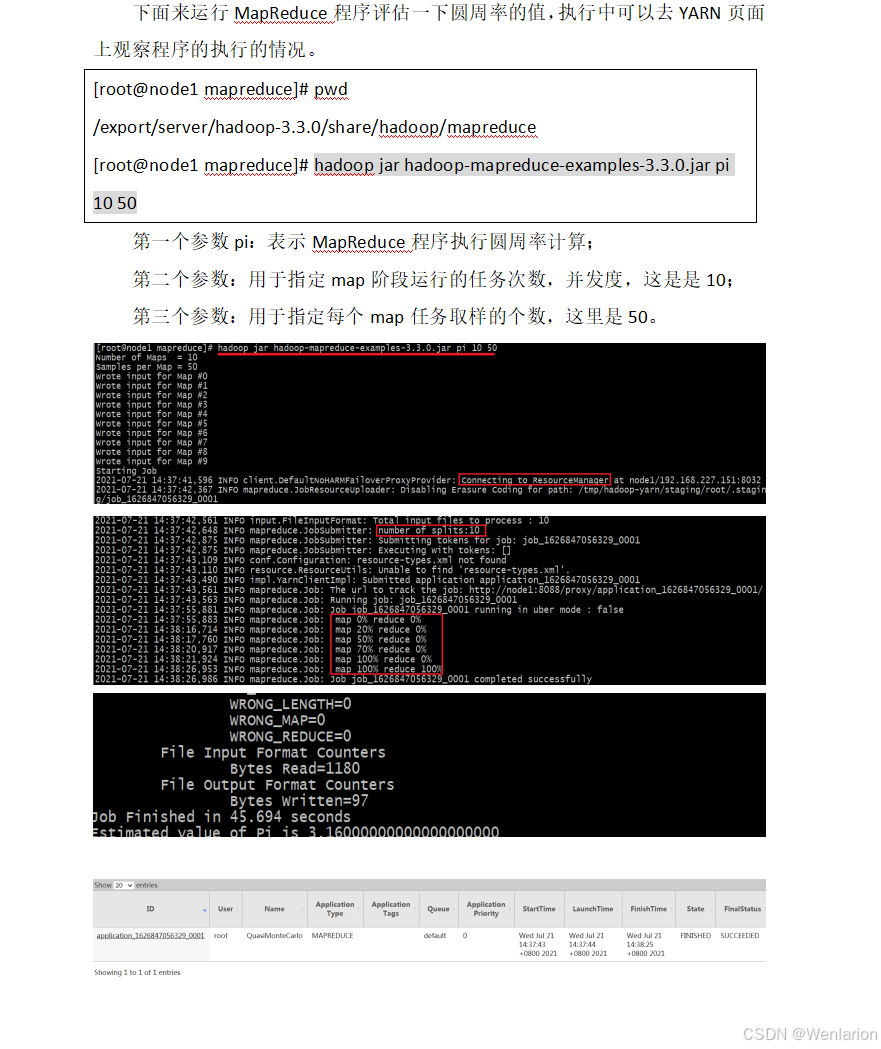




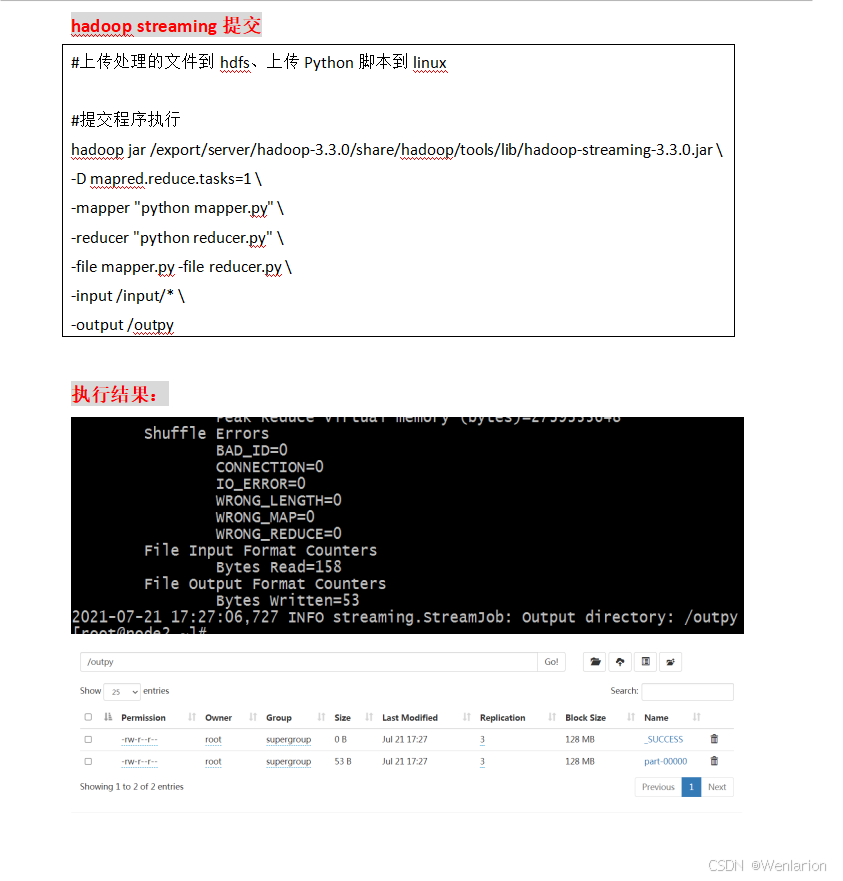
1.13 MapReduce 基本原理
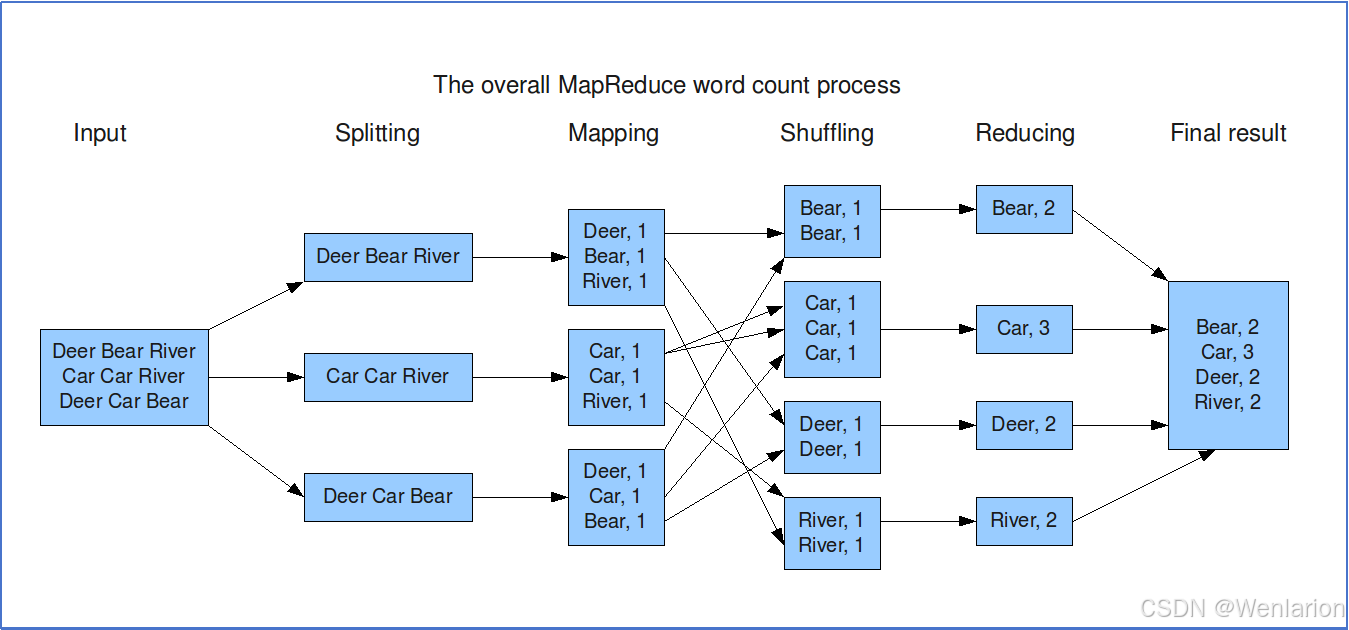
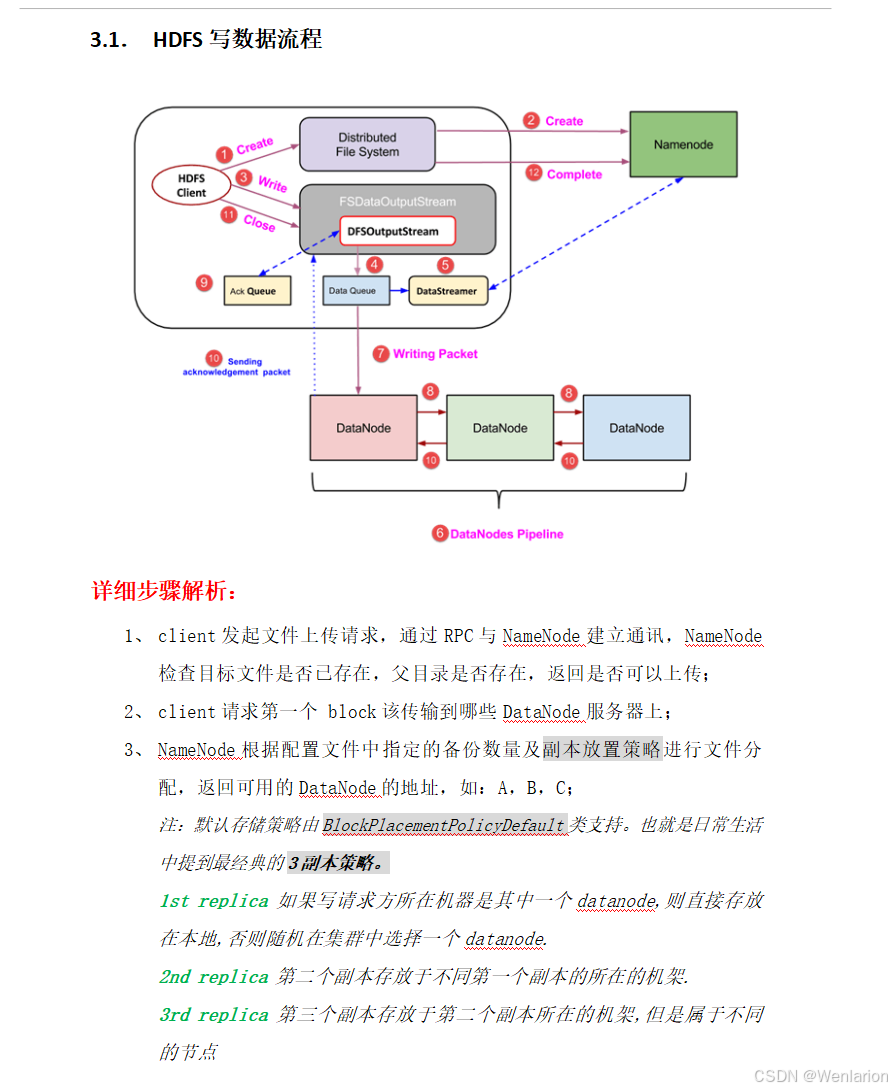
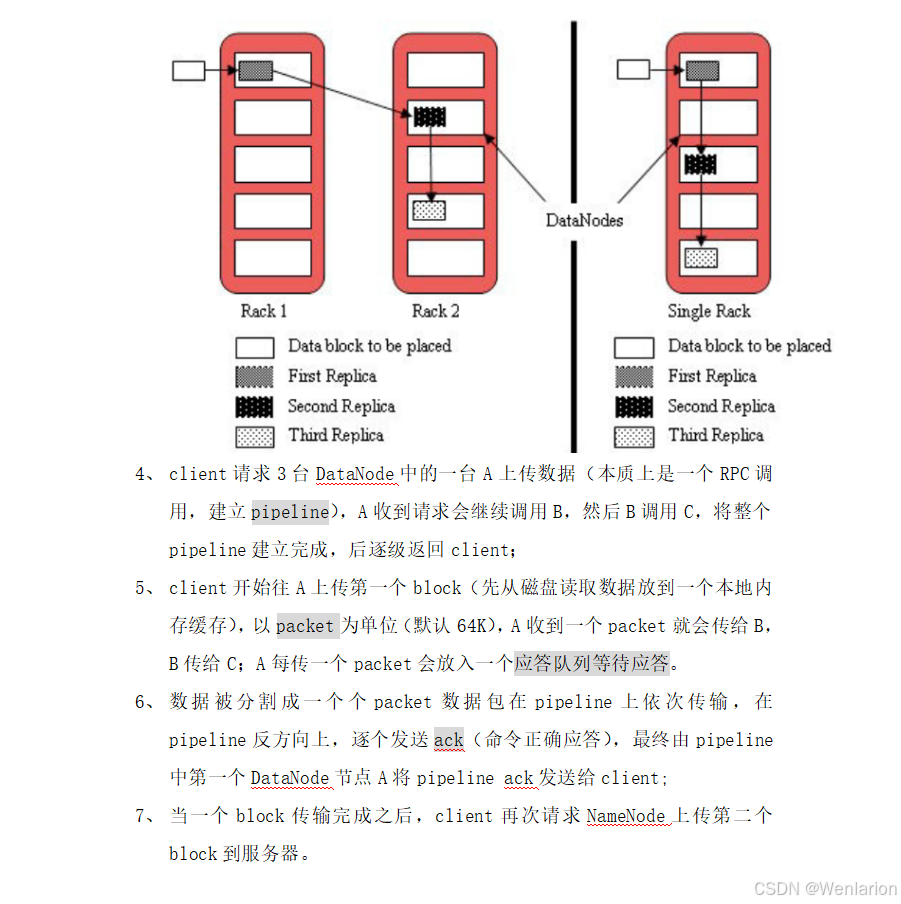
1. 整体执行流程图
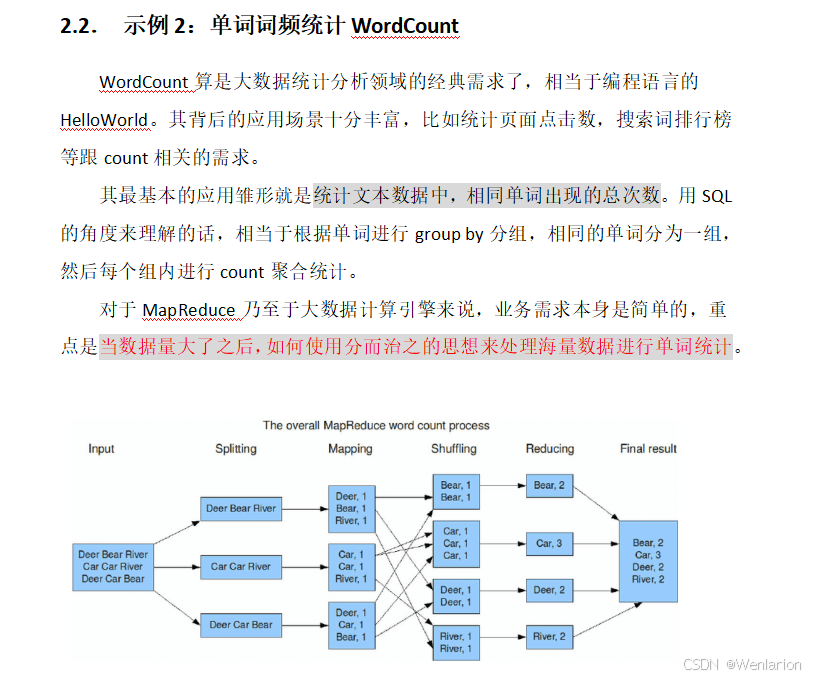
1.1 上层 WordCount 示例流程
以经典的词频统计为例,MapReduce 分为 5 个核心阶段:
-
Input(输入):原始文本数据输入
-
Splitting(分片):将输入数据切分成多个 InputSplit,分发到不同 Map 任务
-
Mapping(映射):每个 Map 任务对分片数据处理,输出
<key, value>键值对(如<Deer,1>) -
Shuffling(混洗):将相同 key 的数据聚合到同一个 Reduce 任务
-
Reducing(归约):Reduce 任务对相同 key 的 value 进行汇总计算,得到最终结果(如
<Bear,2>)
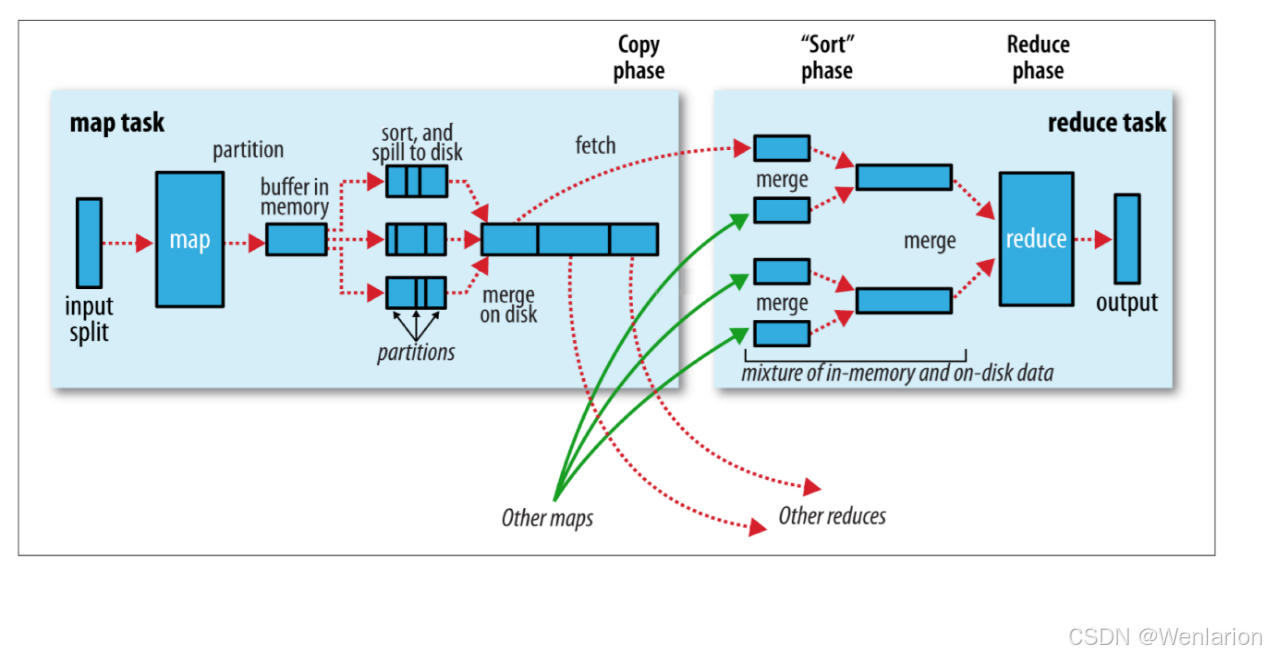
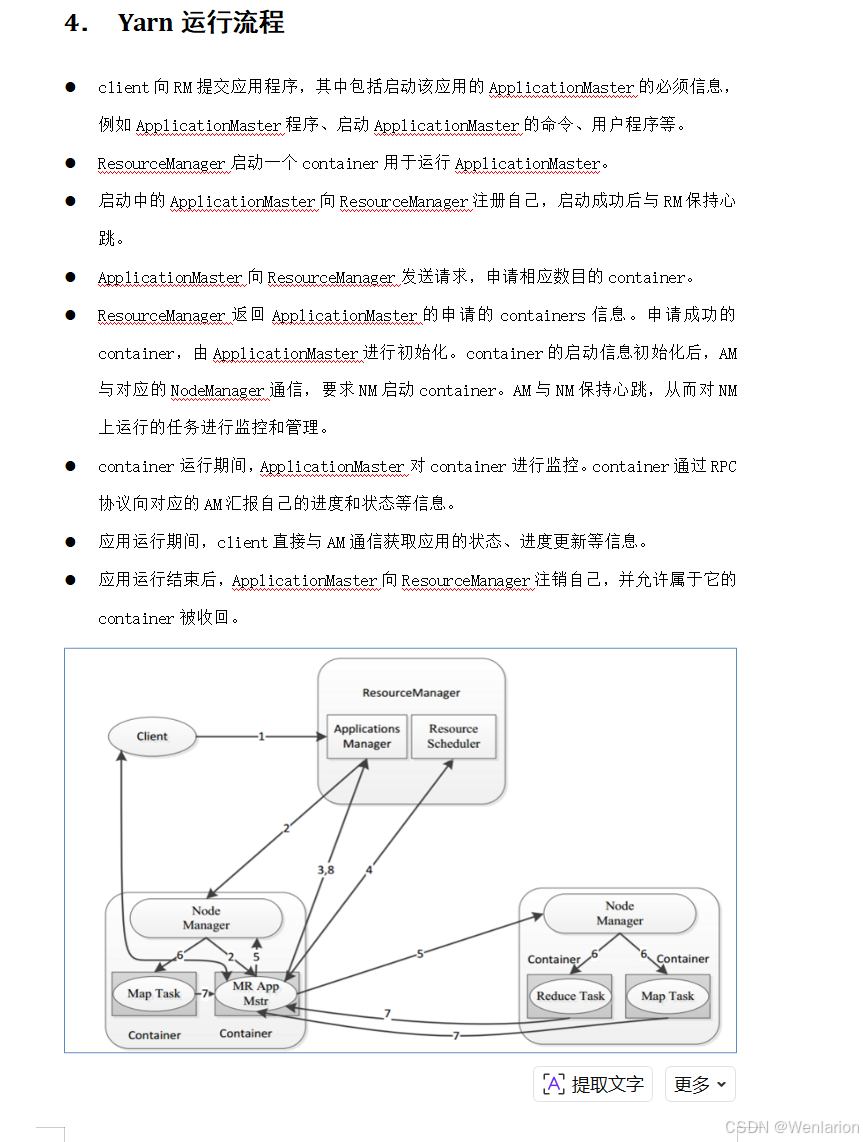
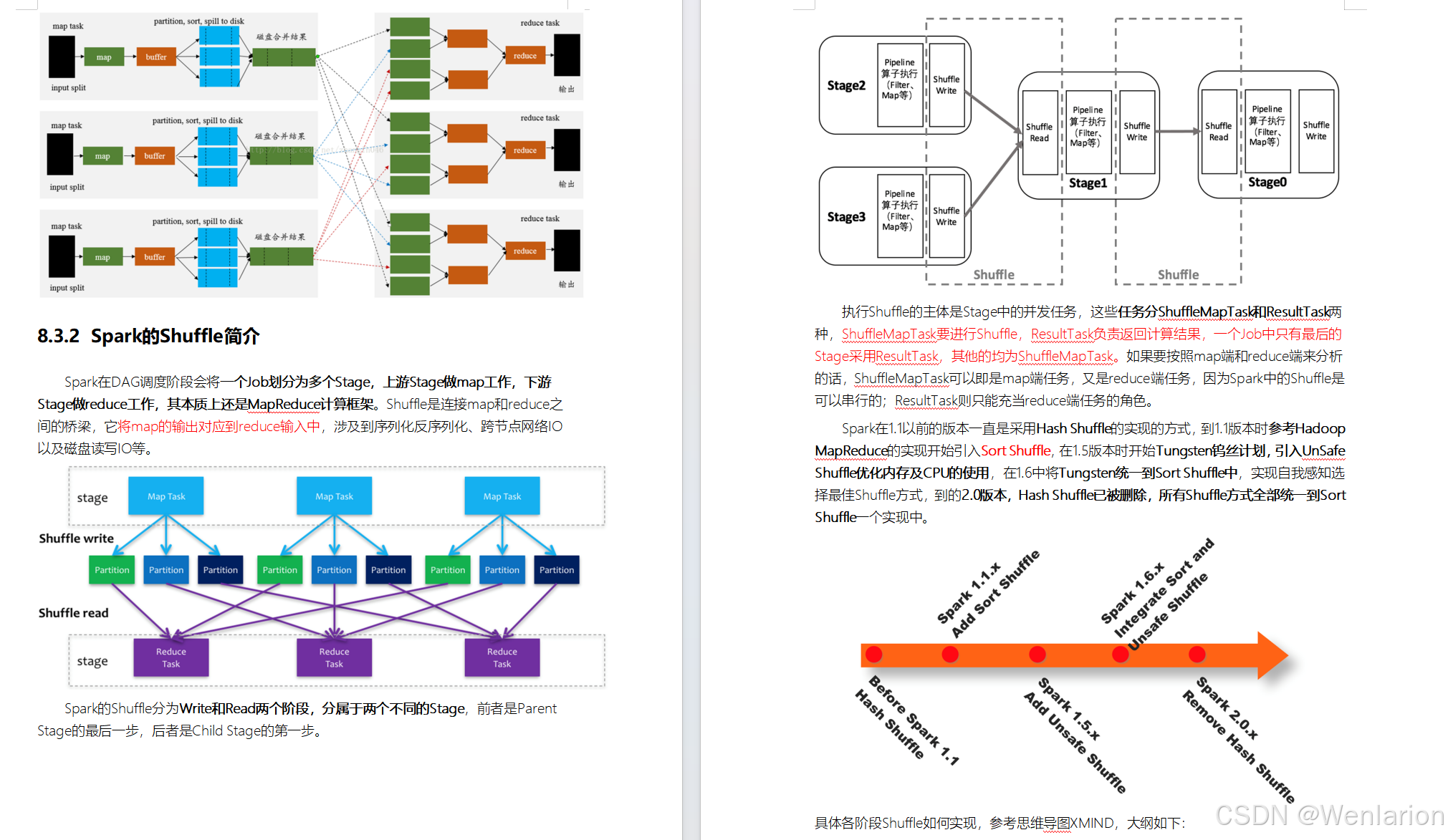
1.2 底层任务执行流程
MapReduce 底层分为 Map Task 和 Reduce Task 两个阶段:
Map Task 阶段
-
Input Split:将输入文件切分为逻辑分片,作为 Map 任务的输入单位
-
Map:执行用户自定义的 Map 逻辑,输出中间键值对
-
Buffer in memory:中间结果先写入内存缓冲区
-
Partition & Sort:缓冲区满时,数据按分区(Partition)排序并溢写到磁盘
-
Merge on disk:多个溢写文件合并为一个有序的分区文件
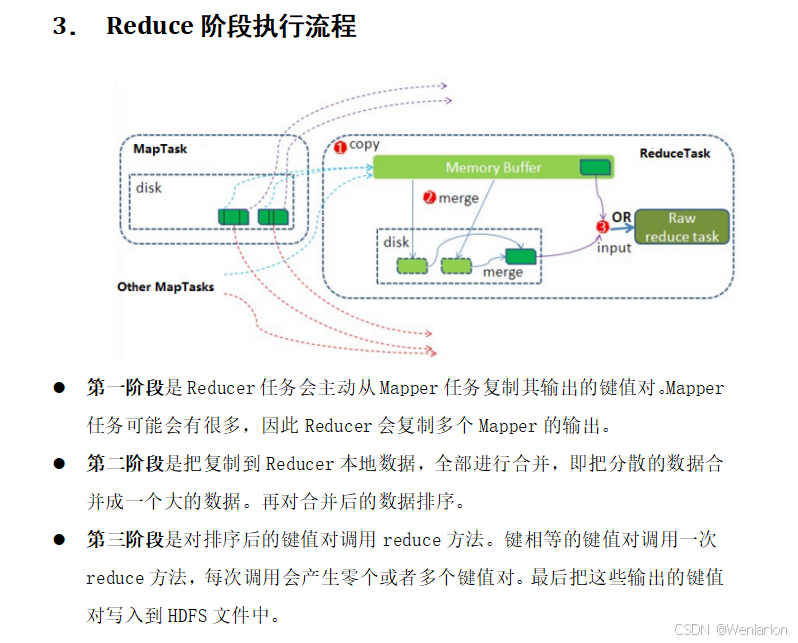
Reduce Task 阶段
-
Copy phase:从各个 Map 节点拉取对应分区的中间数据
-
"Sort" phase:对拉取到的数据进行合并、排序,将相同 key 的 value 聚合在一起
-
Reduce phase:执行用户自定义的 Reduce 逻辑,输出最终结果并写入 HDFS


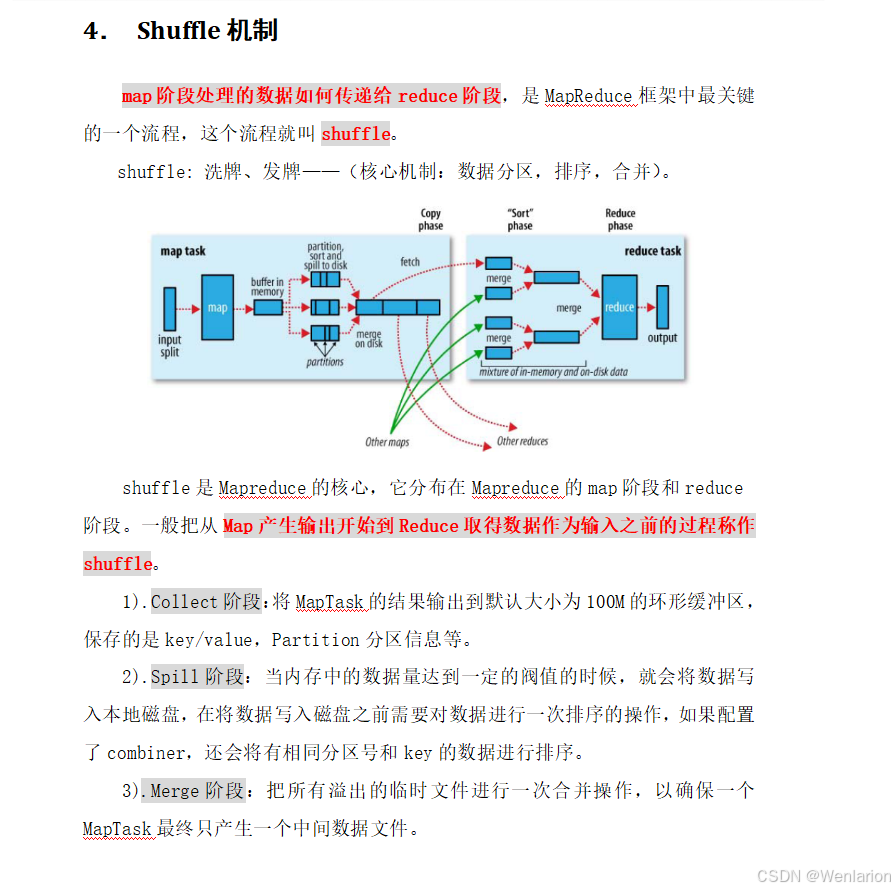

1.14 Apache Hadoop YARN
1. YARN 通俗介绍
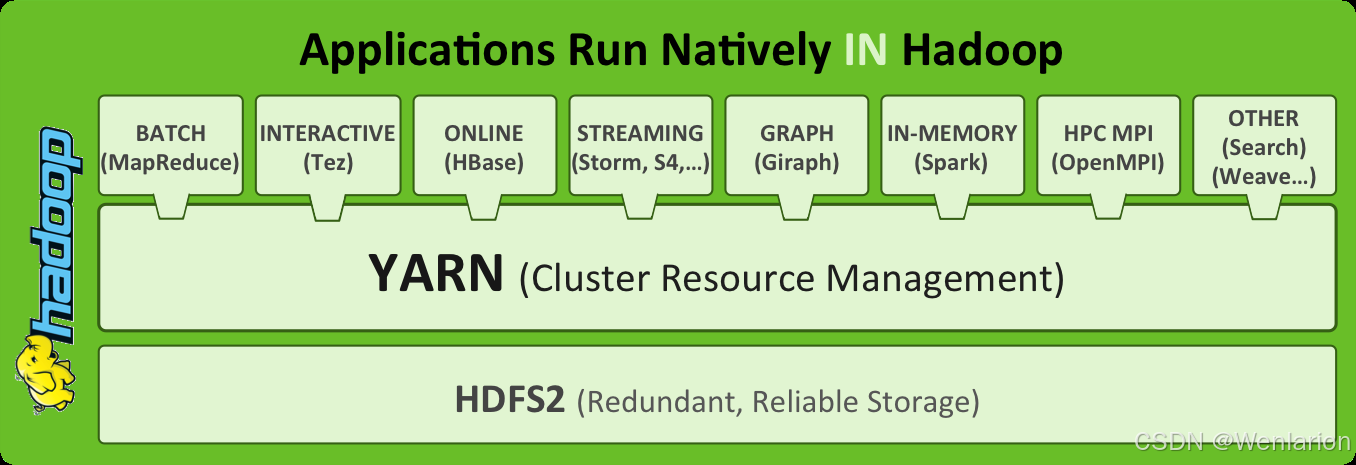
Apache Hadoop YARN(Yet Another Resource Negotiator,另一种资源协调者)是 Hadoop 的通用资源管理与调度平台,为上层计算框架提供统一的资源分配与调度能力。
可以把 YARN 理解为分布式操作系统平台,而 MapReduce、Spark 等计算框架则是运行在其上的 “应用程序”,YARN 负责为这些程序分配 CPU、内存等运算资源。
核心特点
-
资源调度与程序解耦:YARN 不关心用户程序的运行逻辑,只负责资源的申请与分配。
-
多框架兼容:支持 MapReduce、Spark、Storm、Tez 等多种分布式计算框架,只要框架实现了符合 YARN 规范的资源请求机制即可。
-
资源利用率提升:企业可将多个运算集群整合到一个物理集群上,实现资源共享与高效利用。
核心角色
-
ResourceManager(RM):全局资源管理器,负责整个集群的资源调度与分配。
-
NodeManager(NM):单节点资源管理器,负责管理所在节点的资源(CPU、内存等)并执行任务。






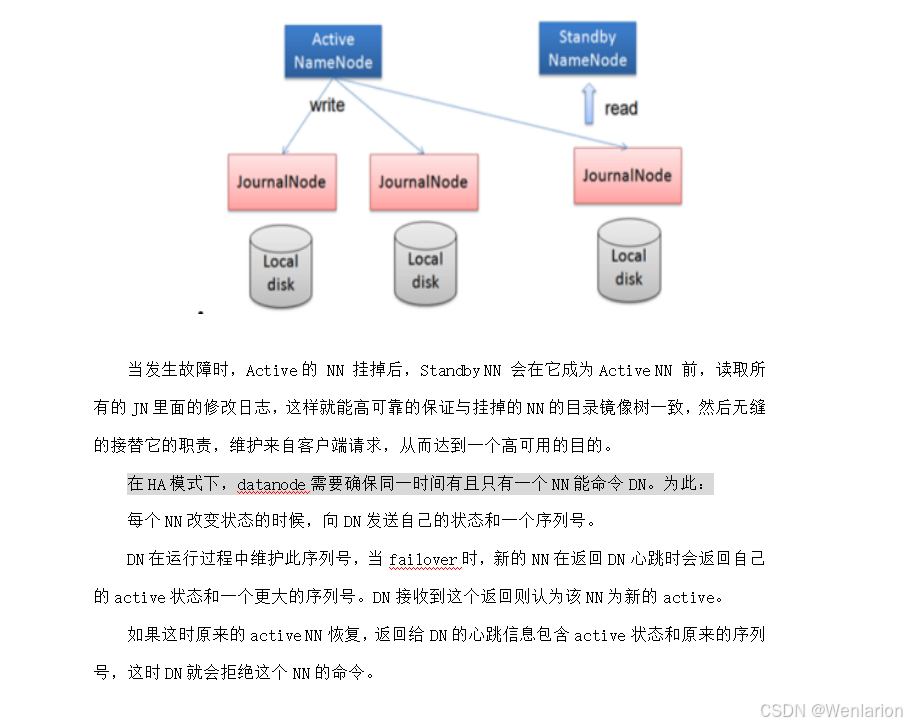
1.15 Hadoop High Availability(高可用)
1. HA 基本概念
HA(High Available,高可用)是保证业务连续性的核心方案,通常包含:
-
活动节点(Active):正在执行业务的主节点
-
备用节点(Standby):作为主节点的备份节点
-
当 Active 节点故障时,Standby 节点会自动检测并接管业务,实现业务不中断或短暂中断
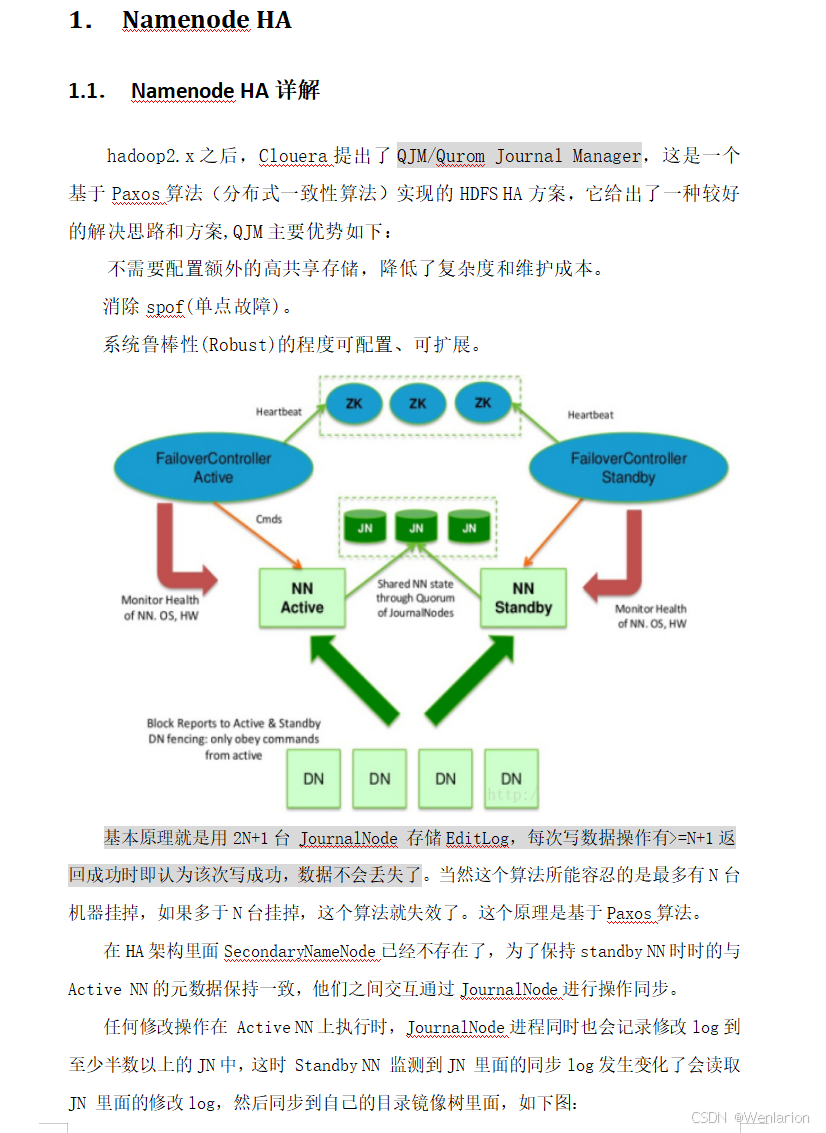
2. HDFS HA 背景
在 Hadoop 1.x 版本中,NameNode(NN)是 HDFS 集群的单点故障点:
-
集群仅存在一个 NameNode
-
若该节点 / 进程不可用,整个 HDFS 集群将无法访问
为解决此问题,诞生了多种 HDFS HA 方案,例如:
-
Linux HA、VMware FT
-
shared NAS+NFS
-
BookKeeper、QJM(Quorum Journal Manager)
-
BackupNode 等
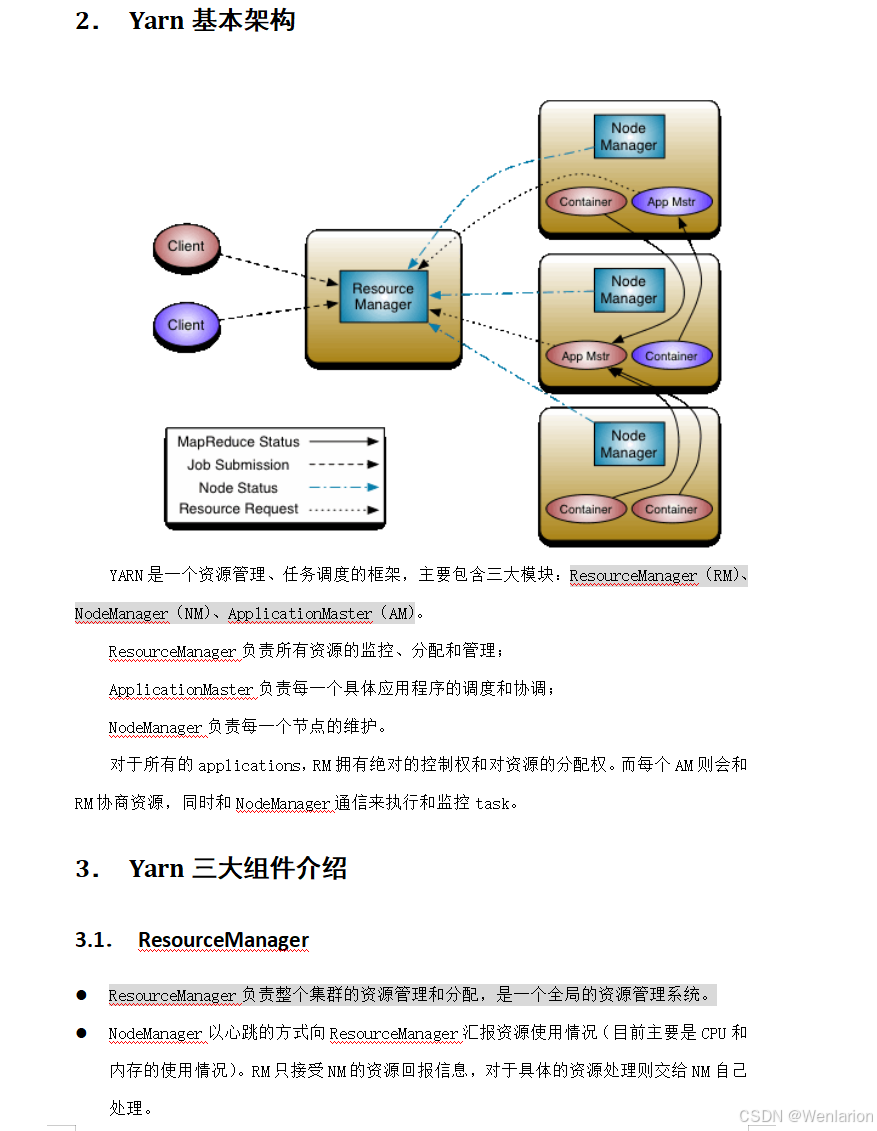
3. HA 核心实现原理
不同 HA 方案的整体流程一致,核心差异在于:如何存储、管理、同步 edits 编辑日志文件。
核心机制:共享日志存储
-
Active NN 和 Standby NN 之间需要一个共享的日志存储位置(如 QJM 的 JournalNode 集群)
-
Active NN 将所有 edits 操作写入共享存储
-
Standby NN 持续读取并执行这些 edits,使内存中的 HDFS 元数据与 Active NN 保持同步
-
一旦发生主从切换,Standby NN 可立即接管 Active NN 的工作
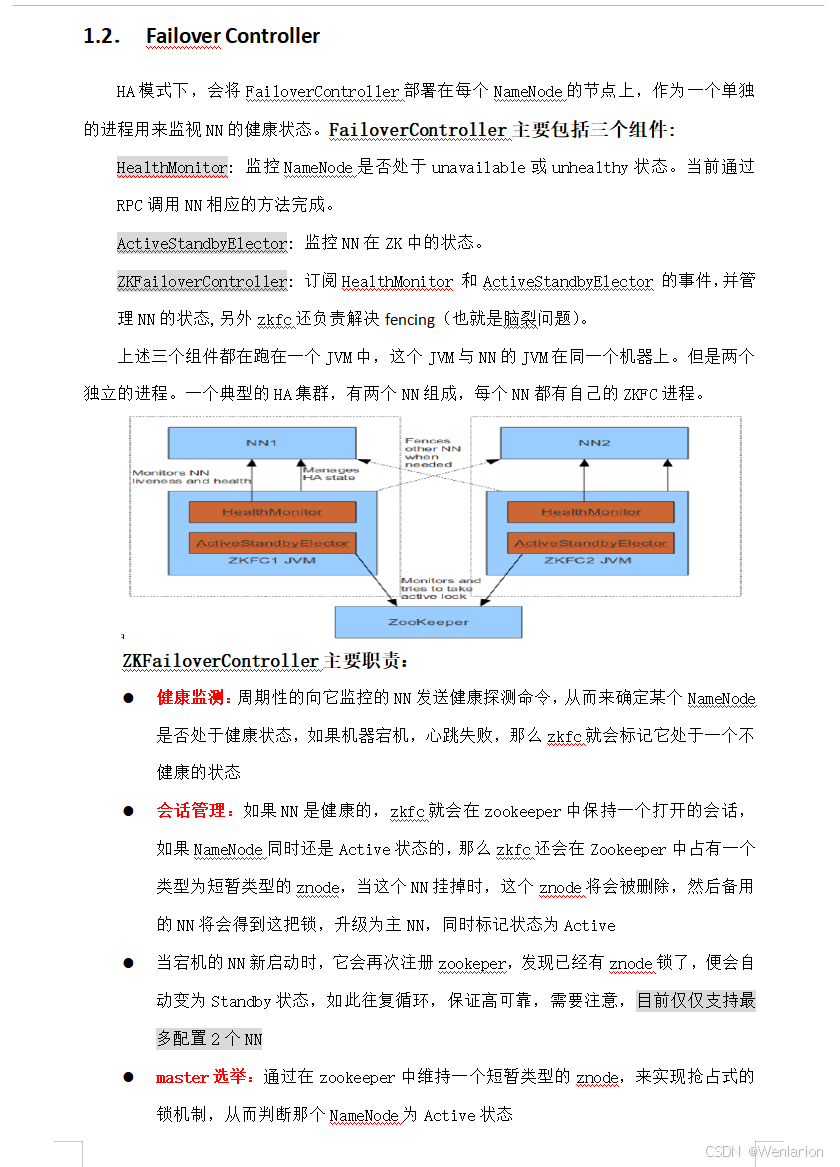

2、Spark
2.1 Spark核心原理
课程说明
Spark 源码从 1.x 的 40w 行发展到现在的超过 100w 行,有 1400 多位大牛贡献了代码,整个 Spark 框架源码是一个巨大的工程。
1.Spark 专业术语定义
1.1 Application/App:Spark 应用程序
指用户编写的 Spark 应用程序 / 代码,包含两部分:
-
Driver 功能代码:运行在主节点,负责协调和调度
-
Executor 代码:分布在集群多个节点上,负责实际计算任务
一个 Spark 应用程序由 一个或多个作业(JOB) 组成(代码中可能会调用多次 Action)。
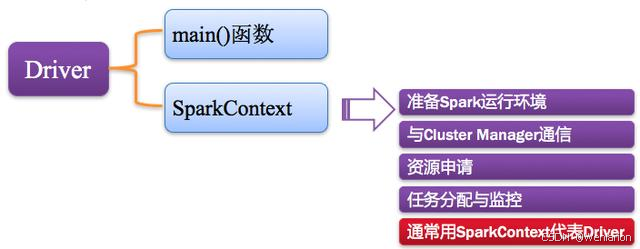
1.2 Driver:驱动程序
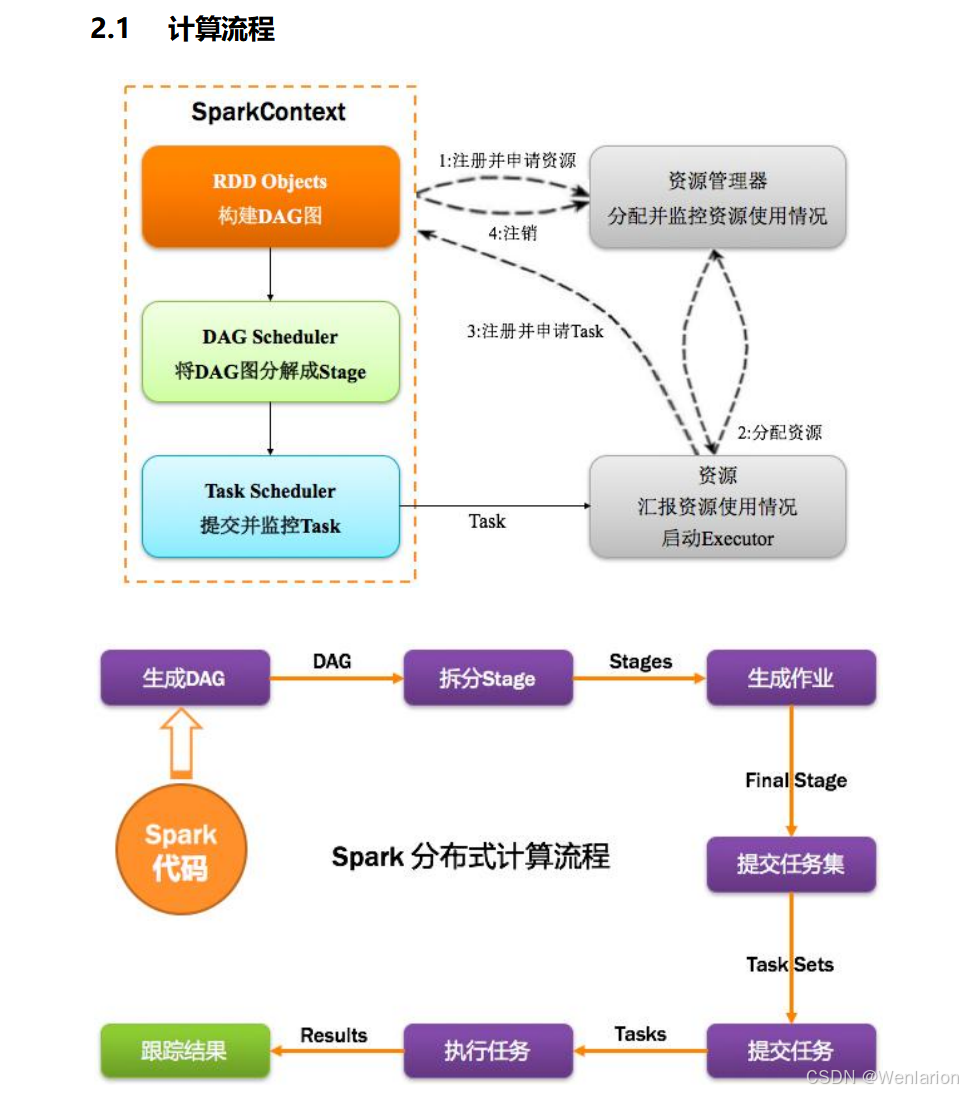
Spark 中的 Driver 即运行 Application 的 main() 函数,并创建 SparkContext,核心职责:
- 创建
SparkContext,准备 Spark 应用程序的运行环境 - 与
ClusterManager通信,进行资源申请、任务分配与监控 - 当 Executor 部分运行完毕后,Driver 负责将
SparkContext关闭
通常
SparkContext就代表 Driver,它是 Driver 的核心入口。

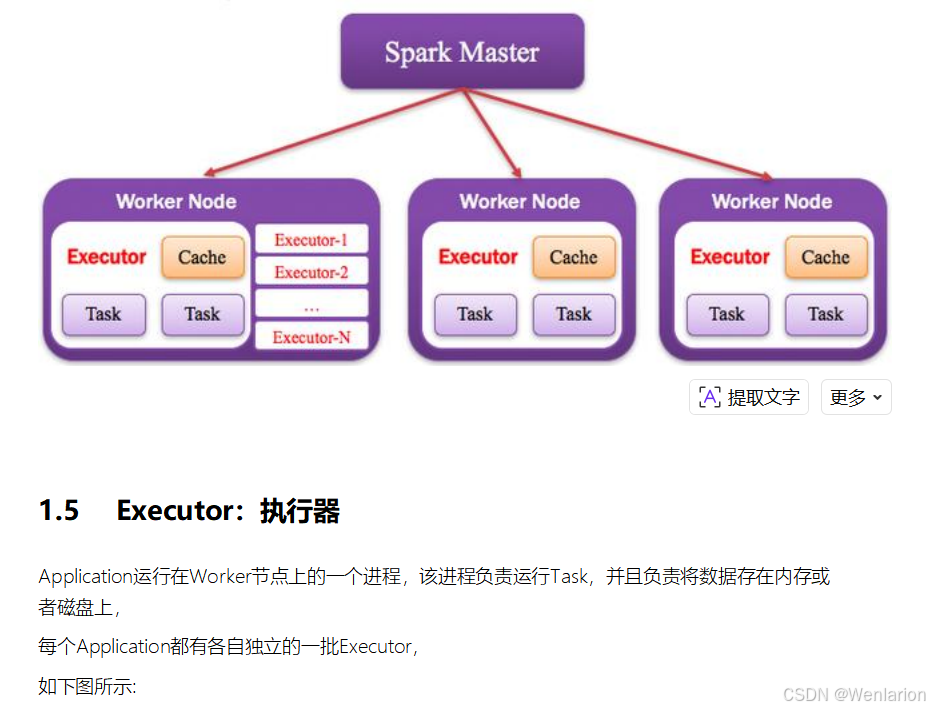
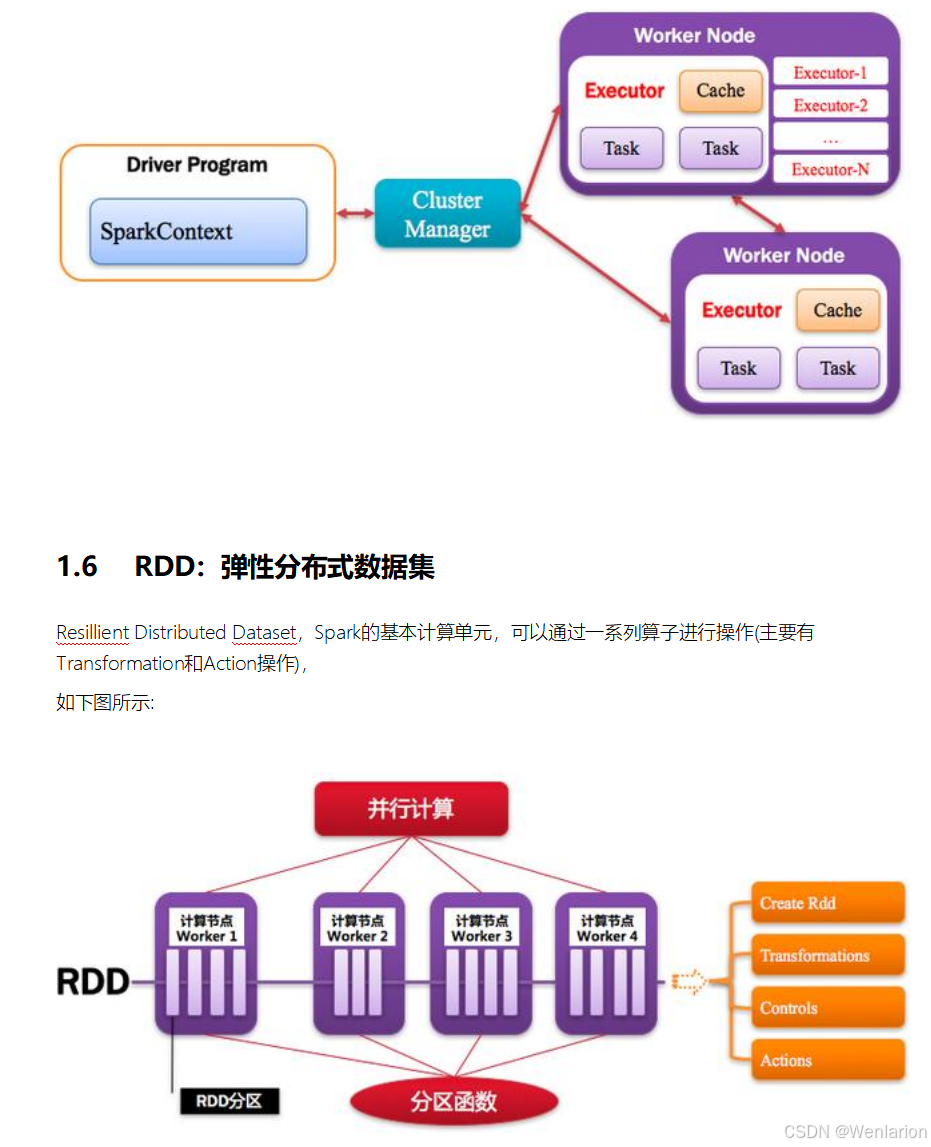
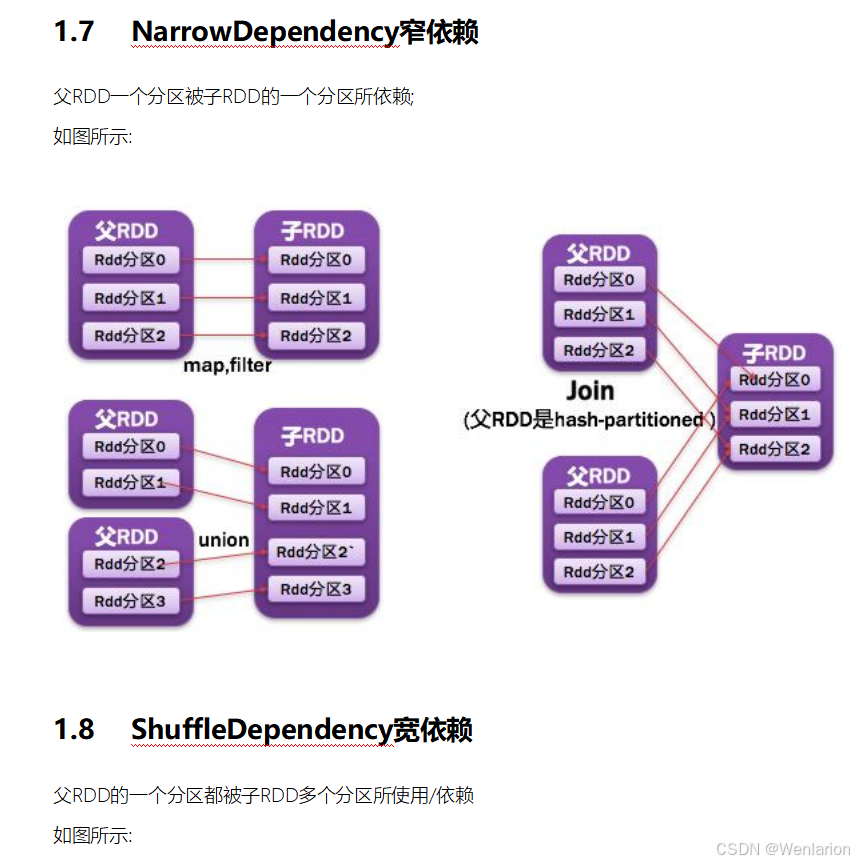
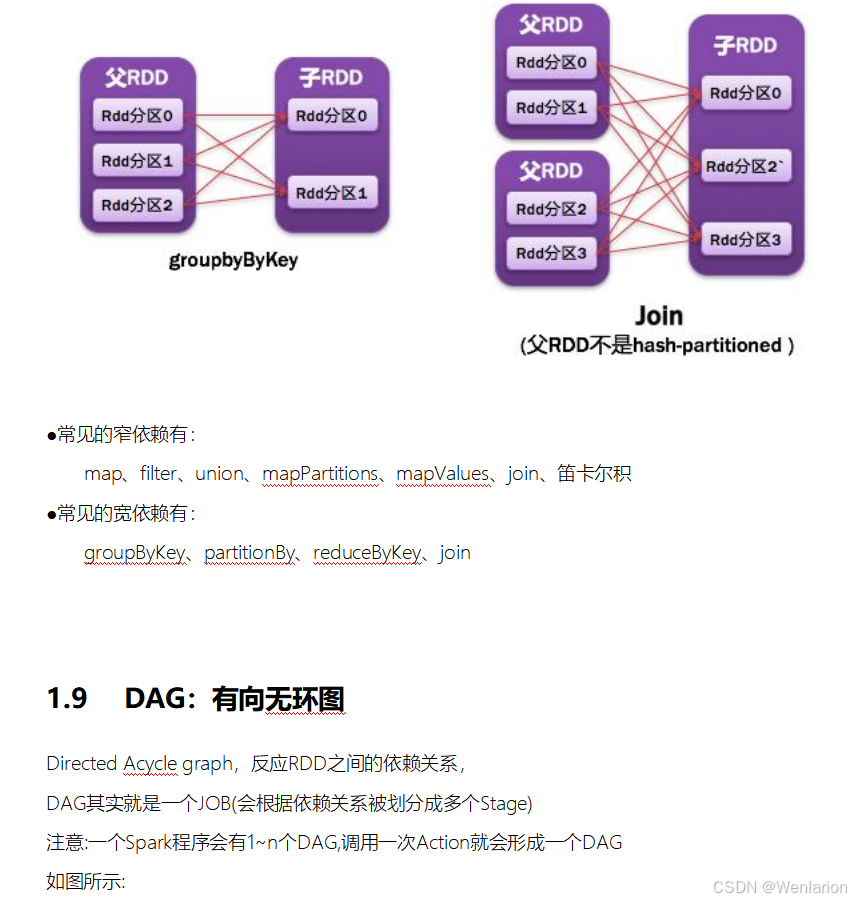
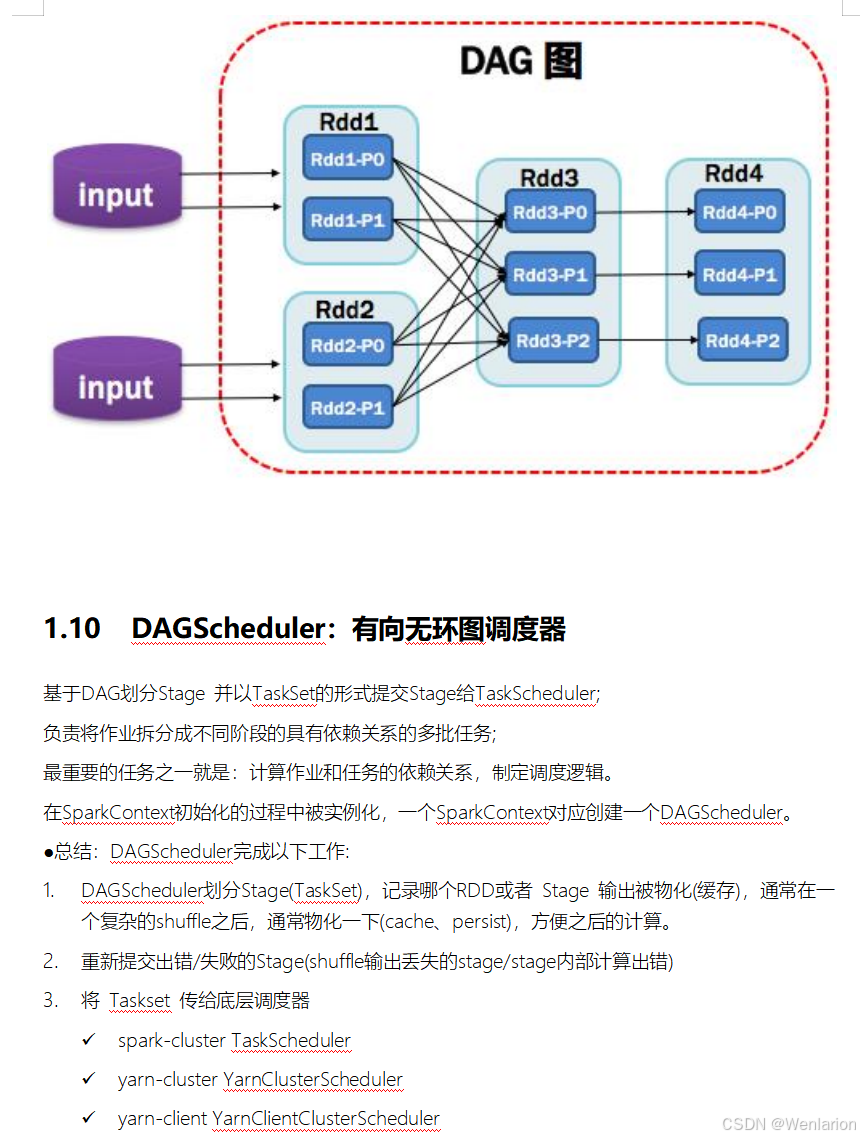
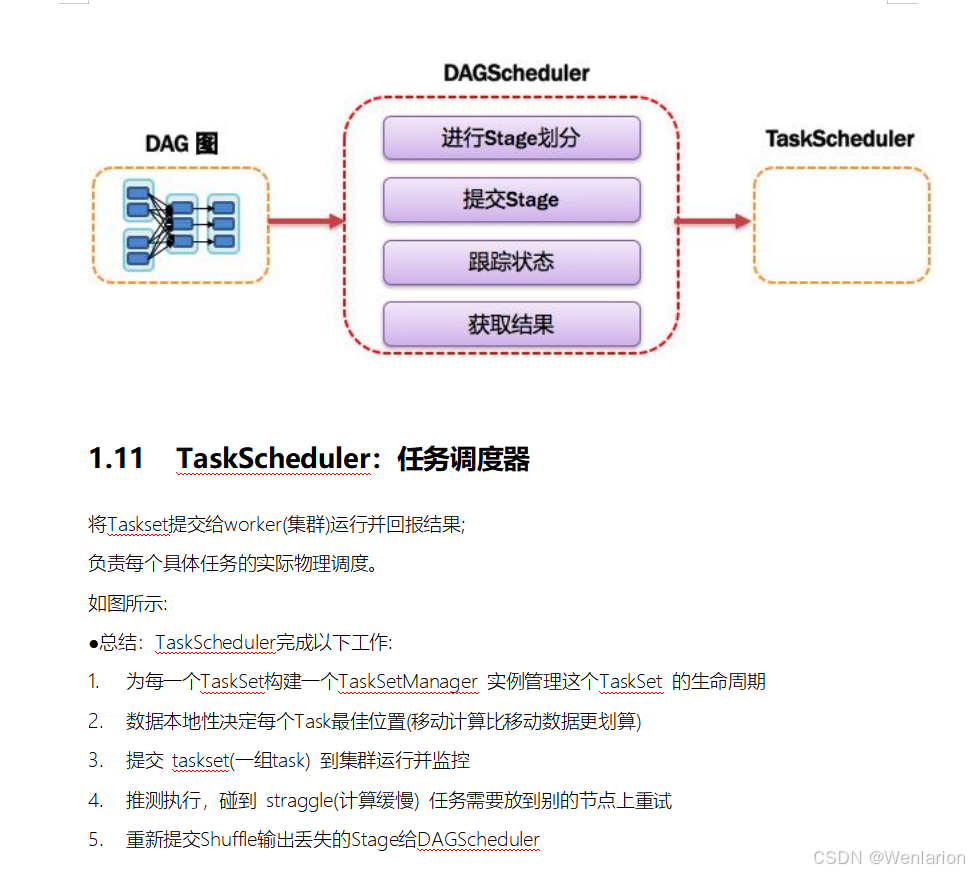
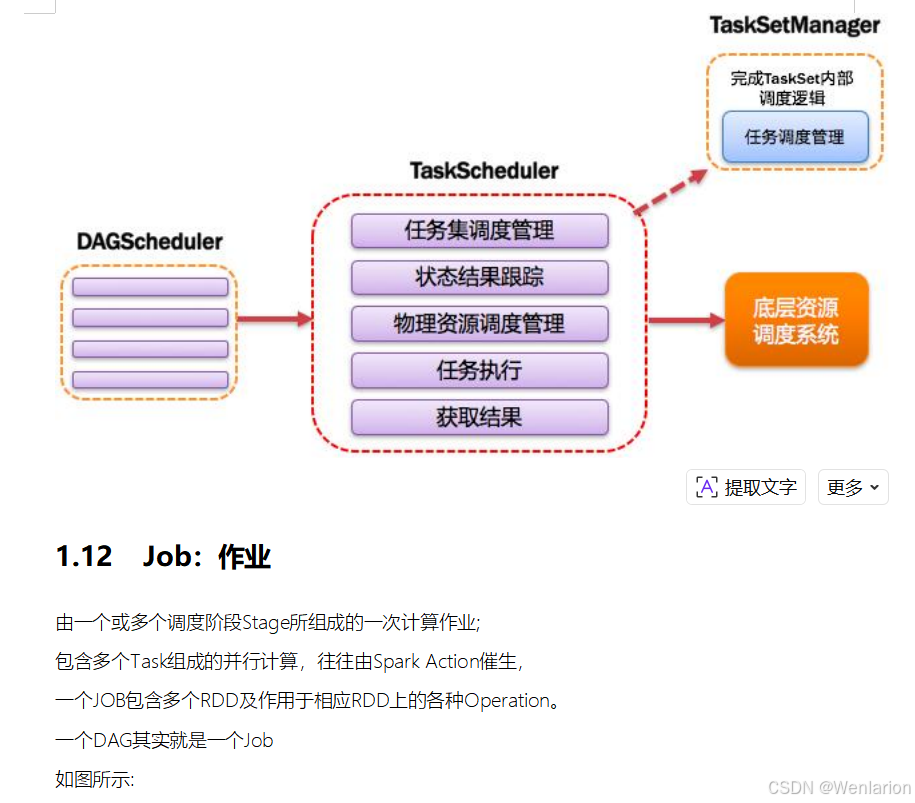
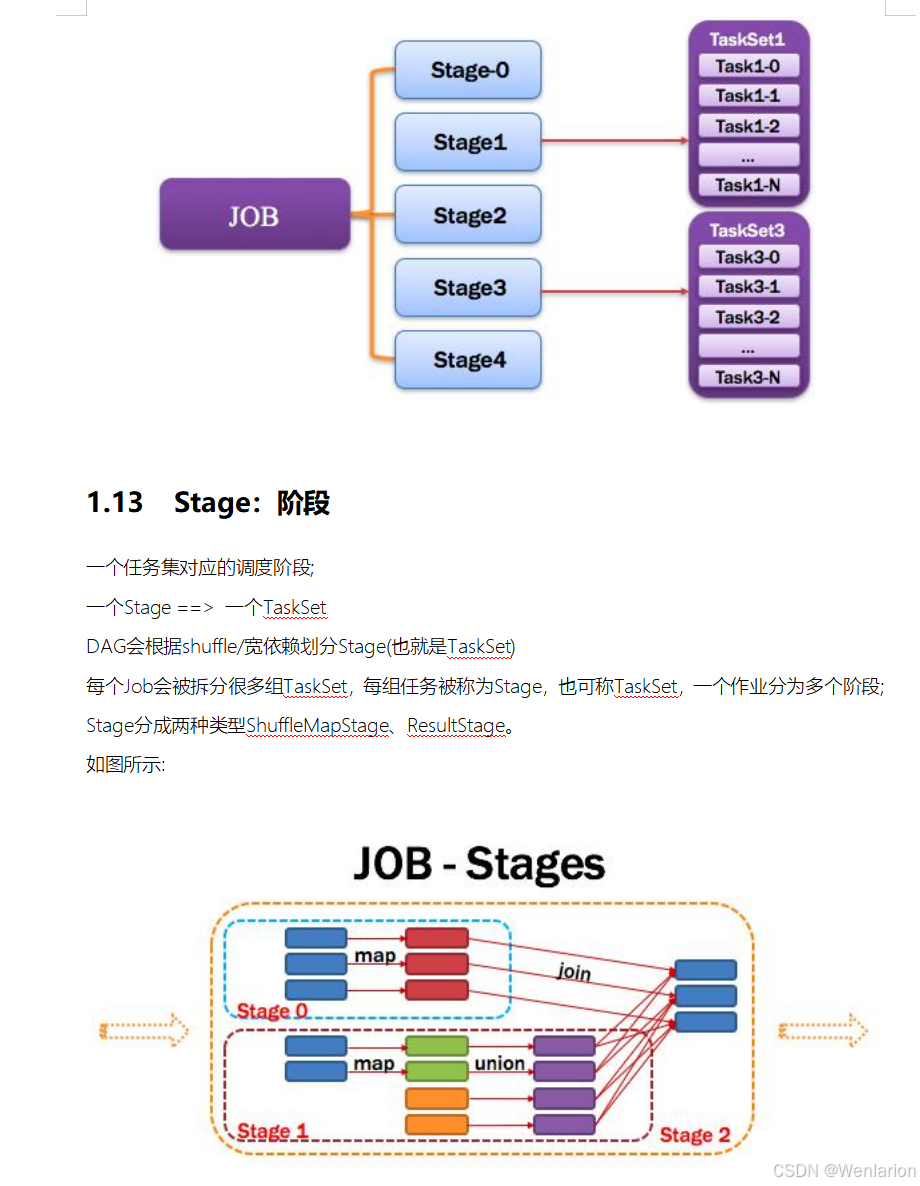
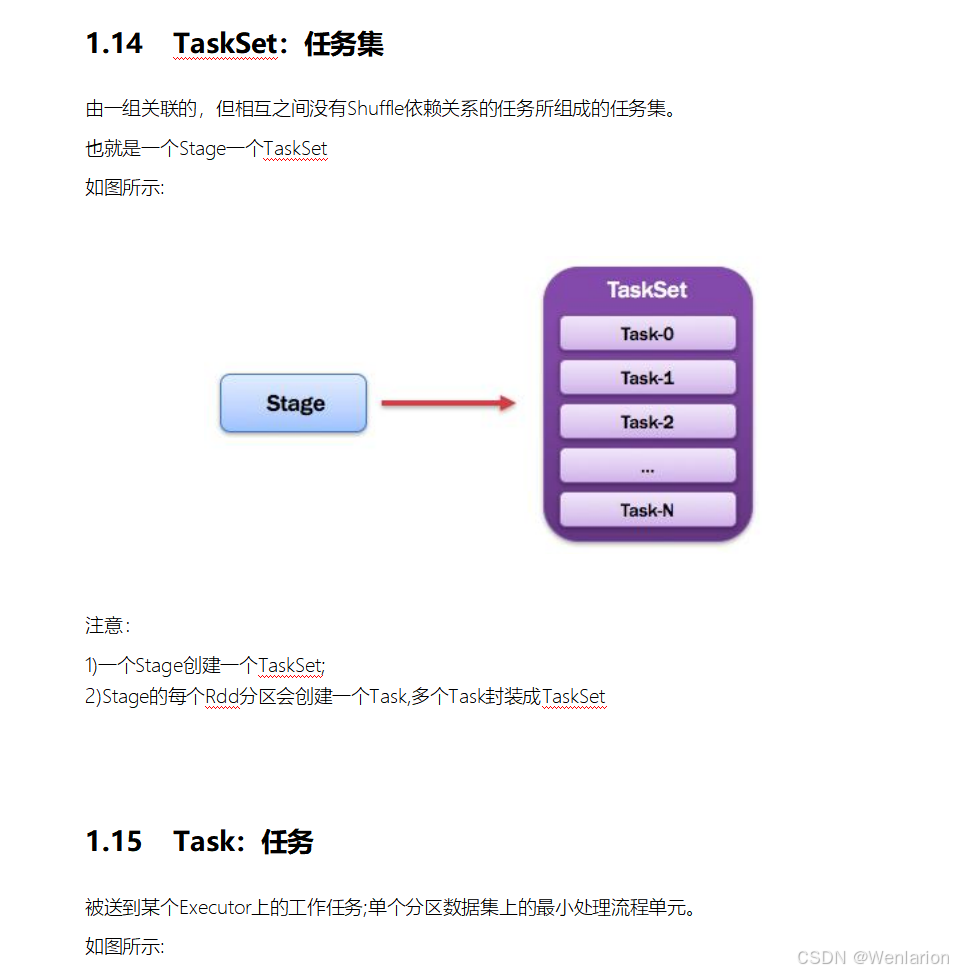
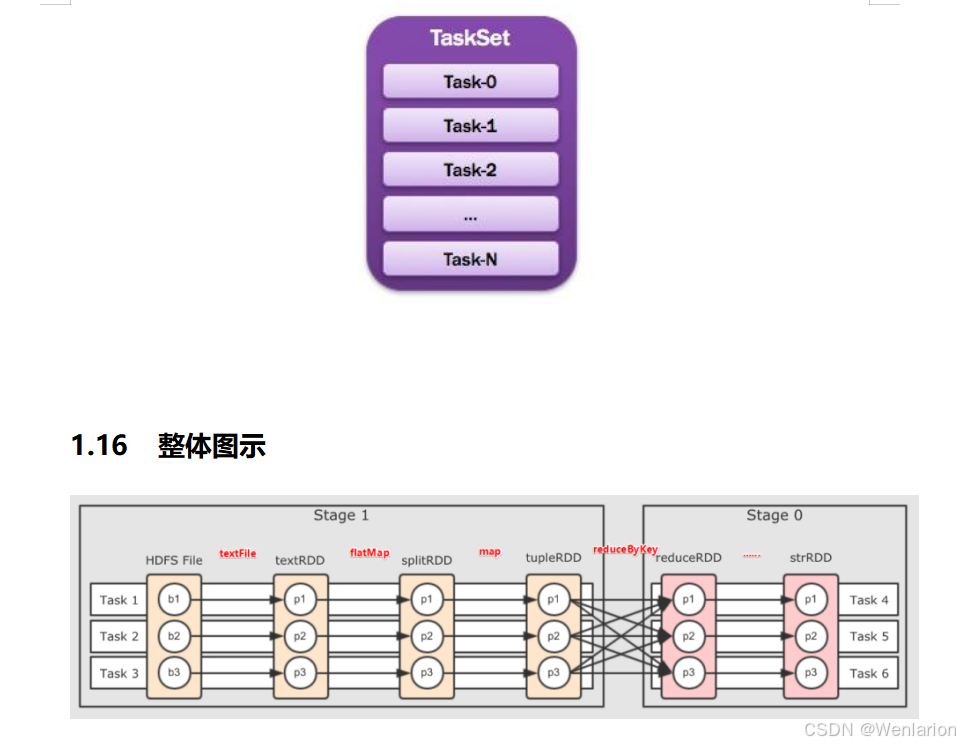
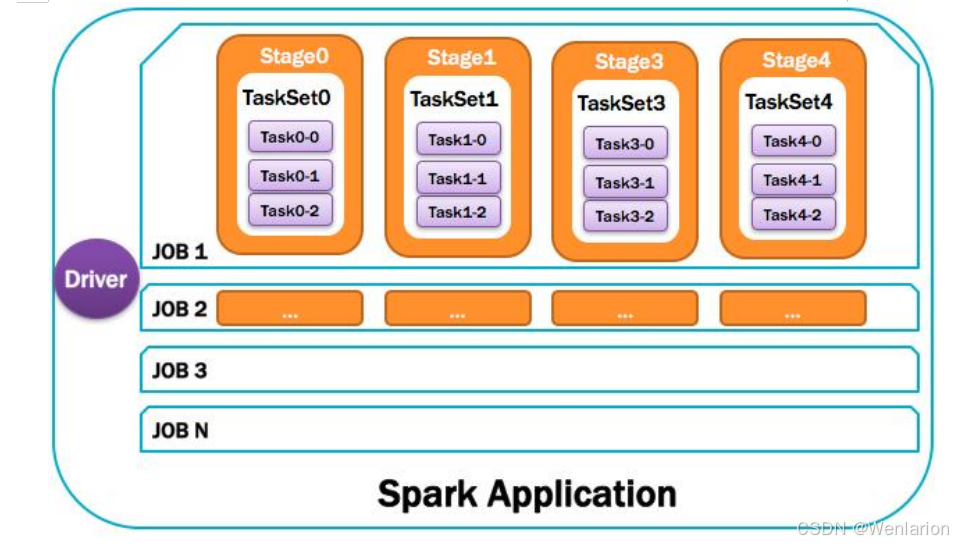
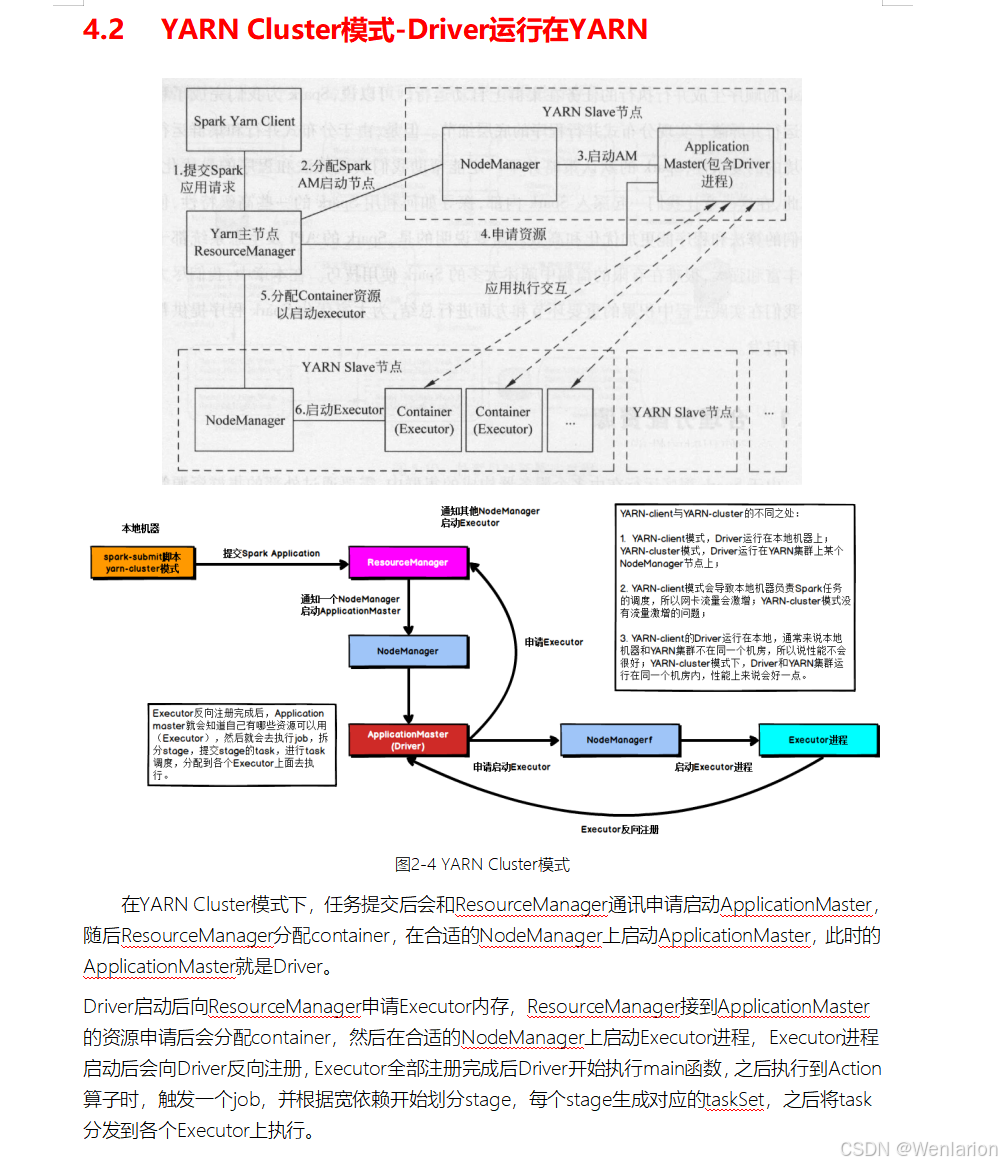
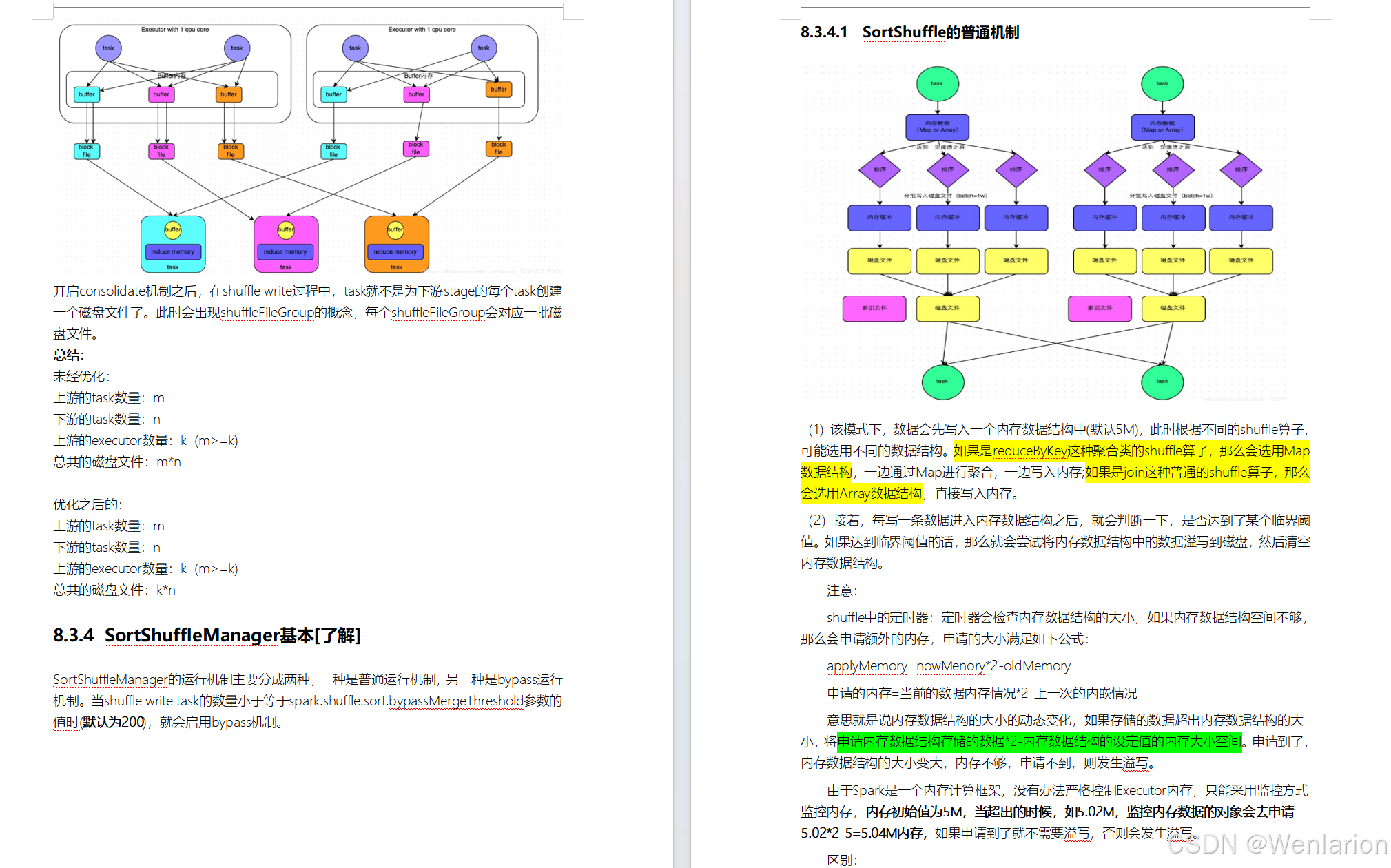
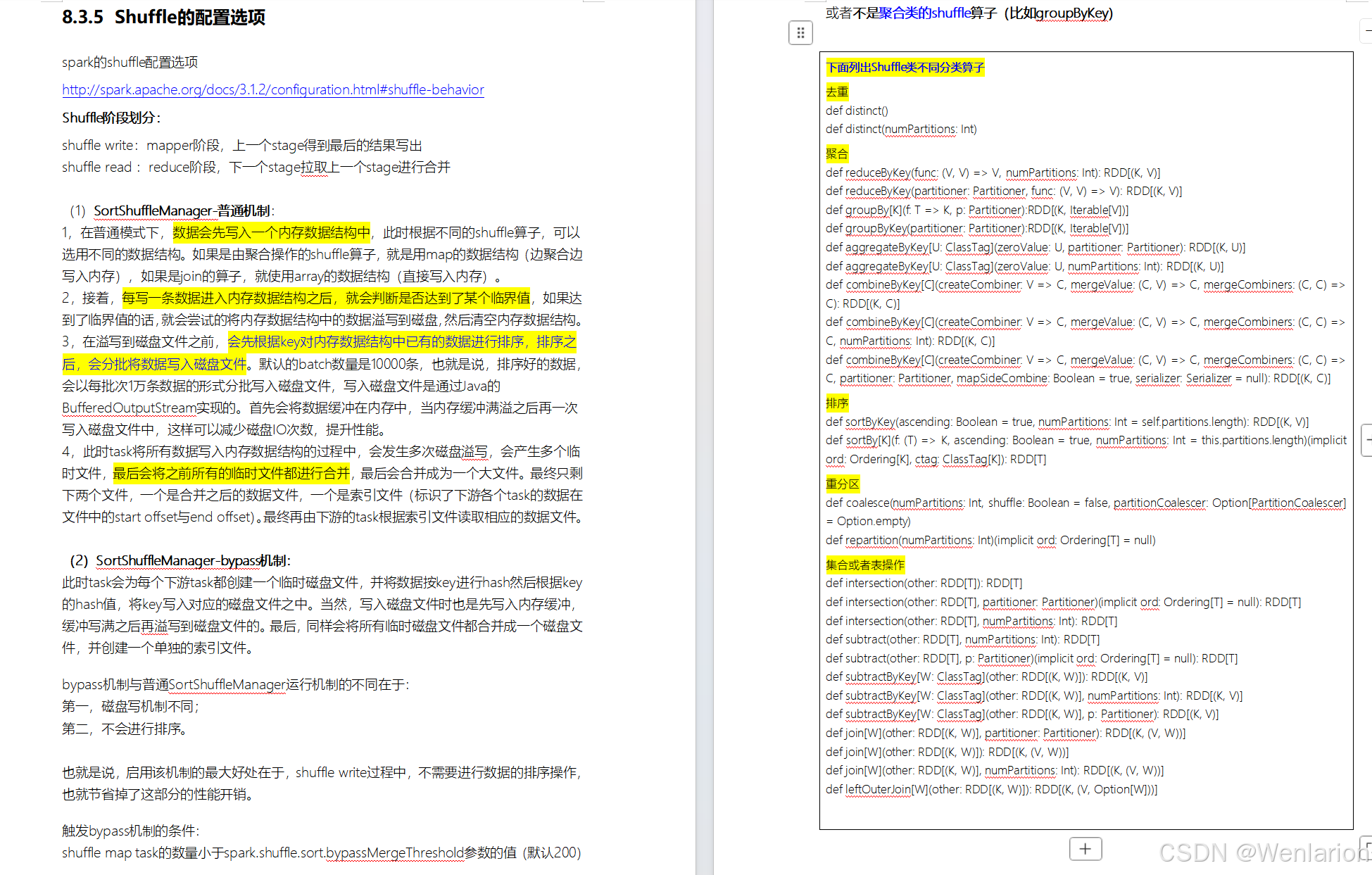
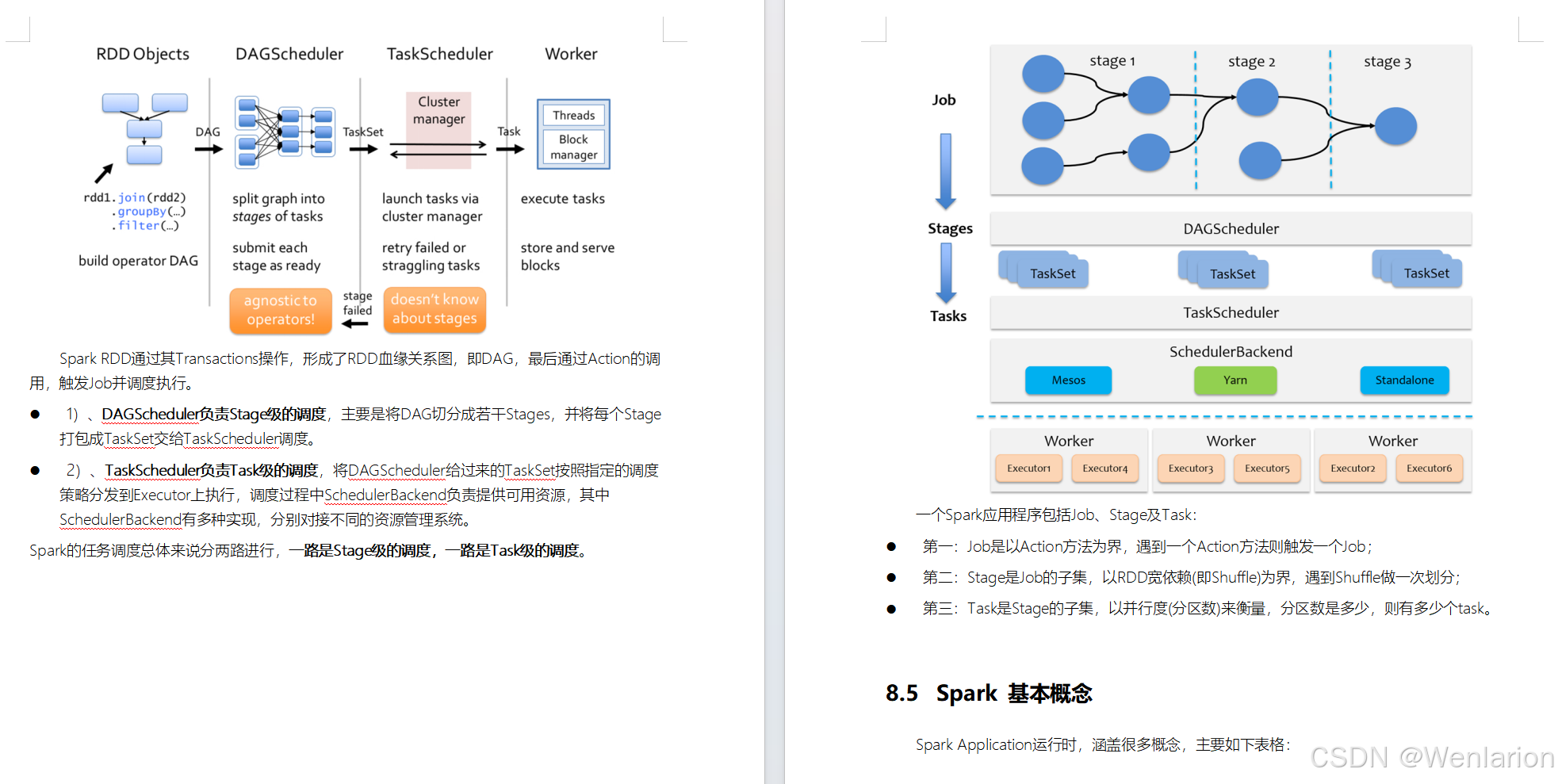
2.Spark运行流程-[掌握]
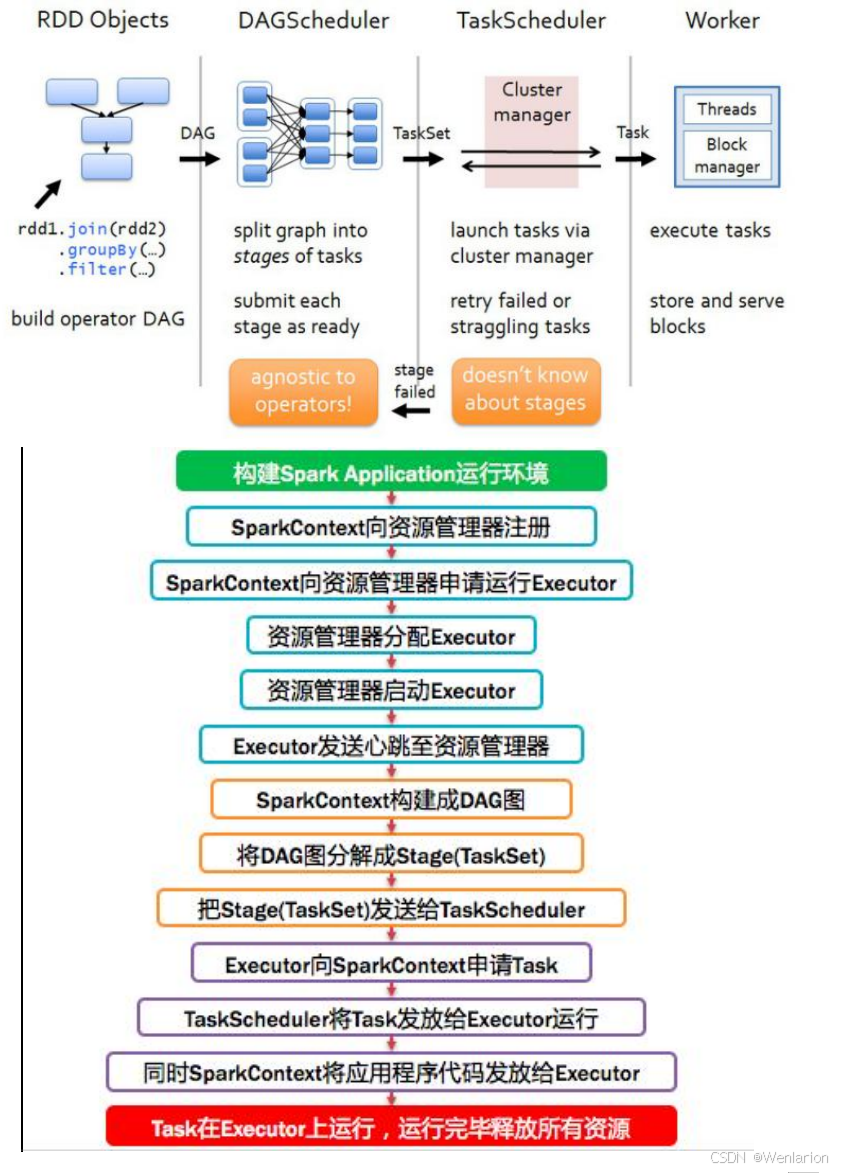
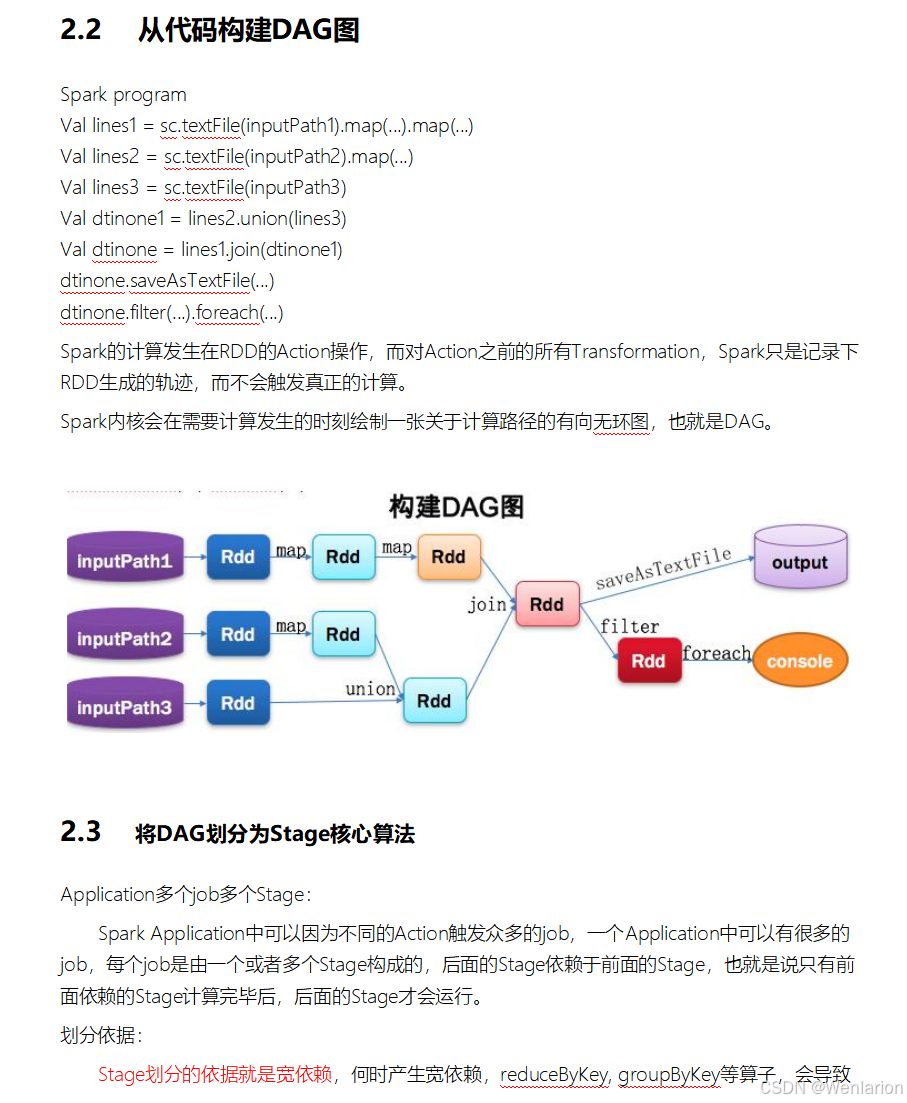
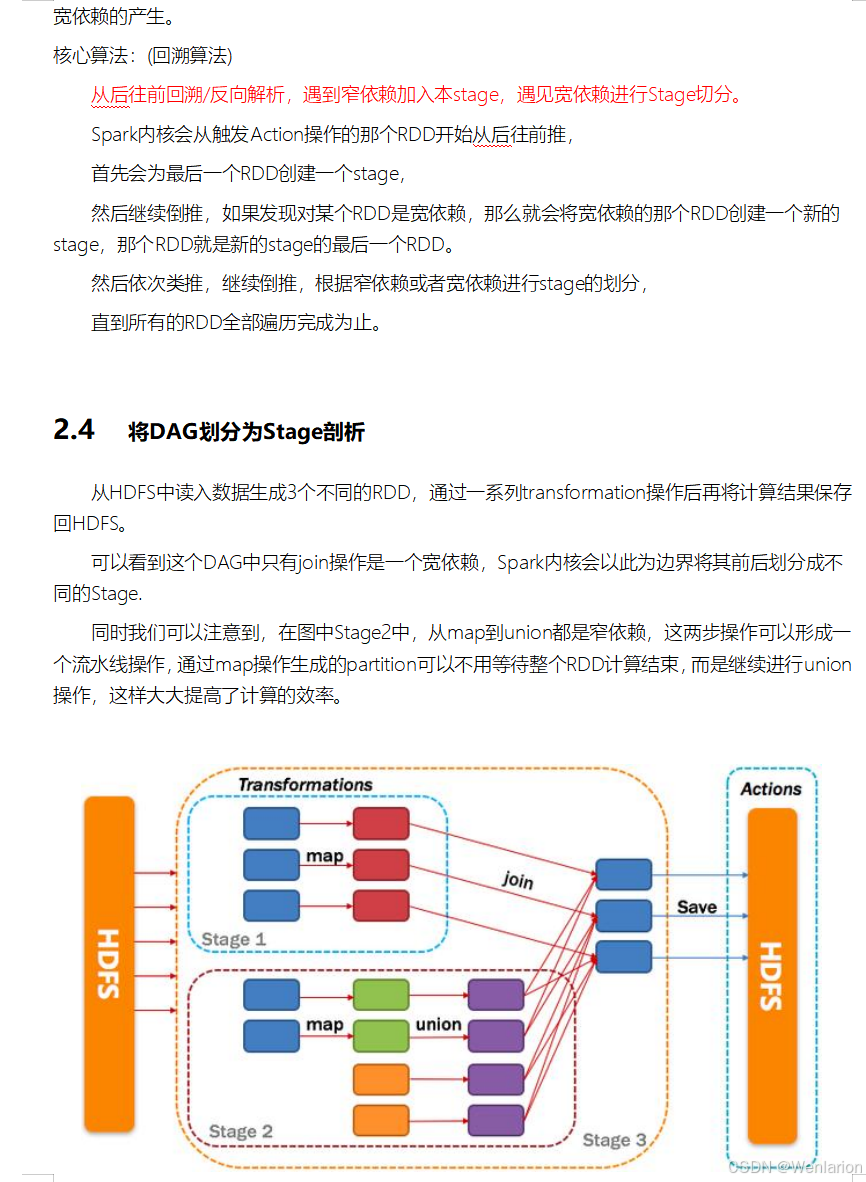
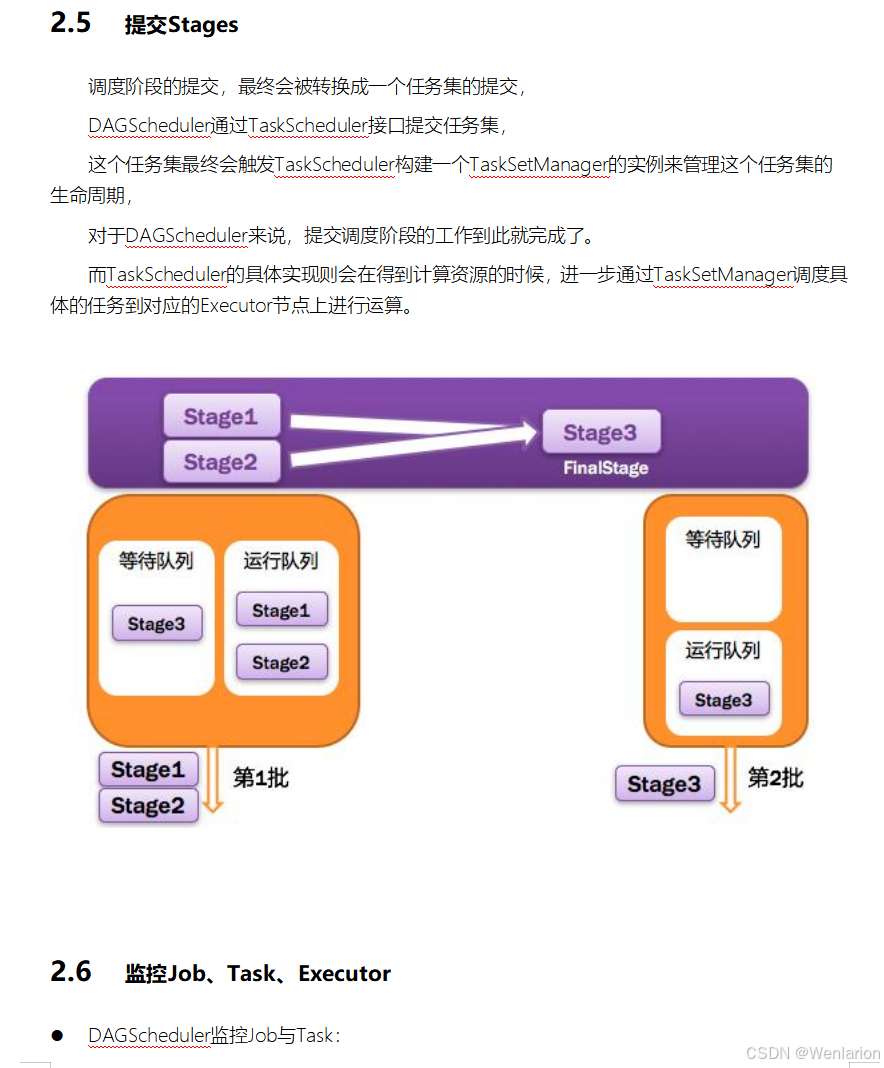

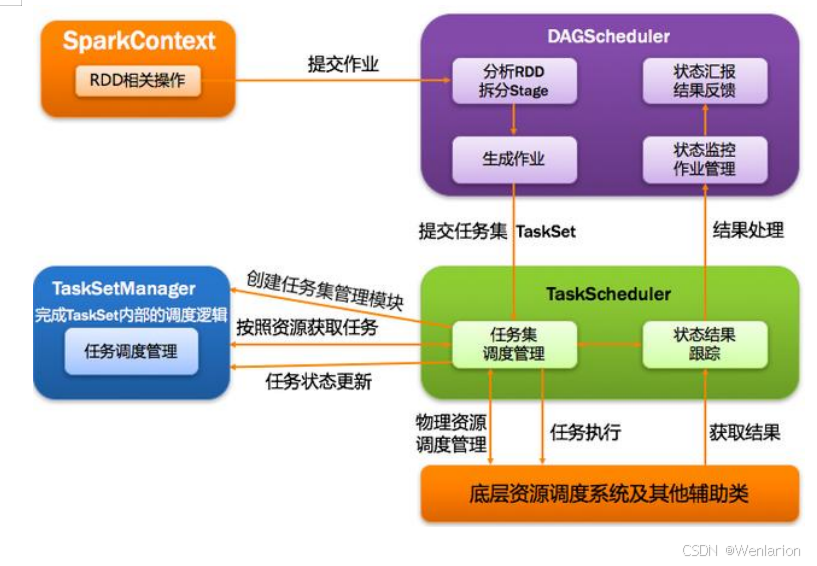
3.Spark运行架构特点-[了解]
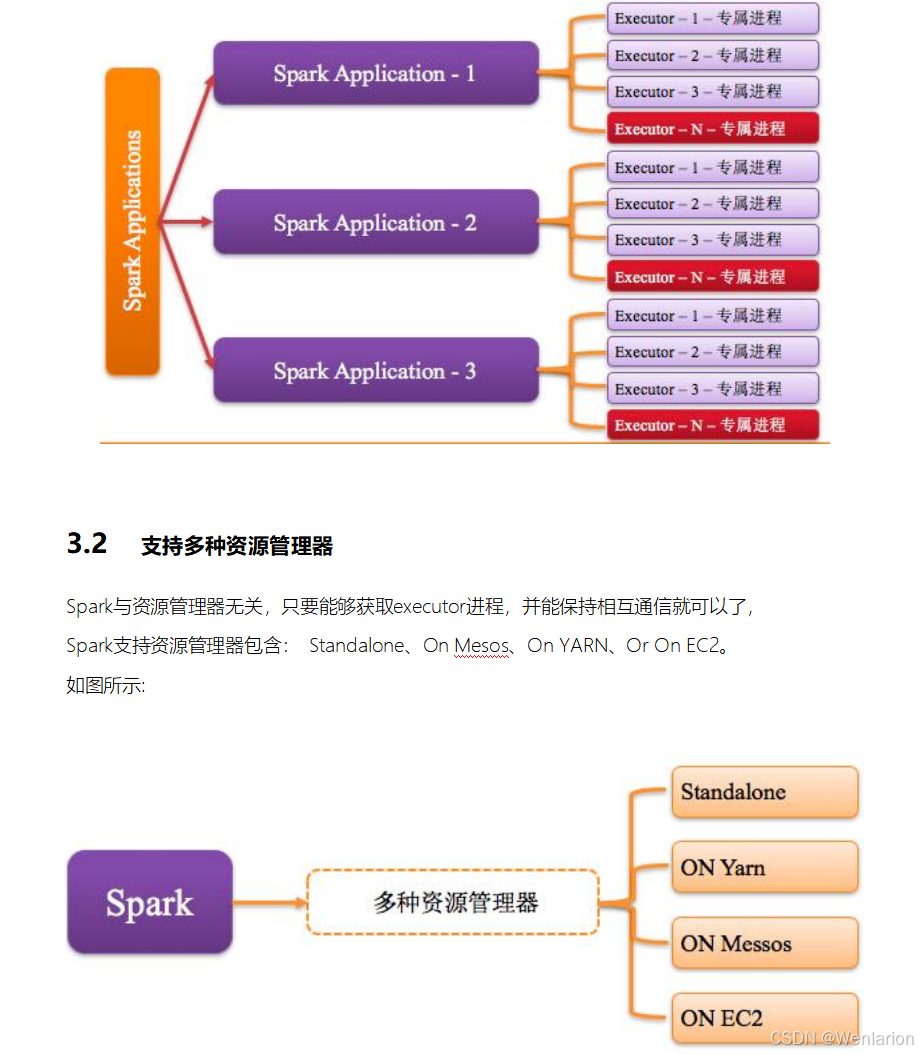
3.1 Executor进程专属
每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行tasks。
Spark Application不能跨应用程序共享数据,除非将数据写入到外部存储系统。如图所示:

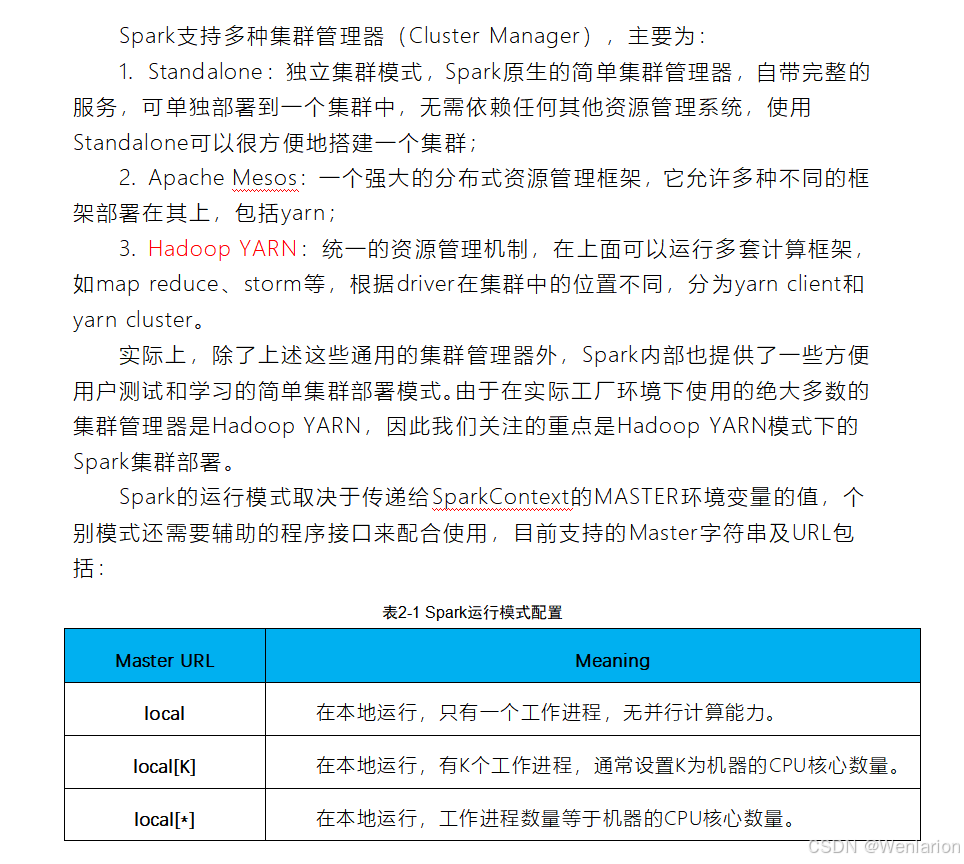
4. Spark部署模式

2.2 PySpark Core

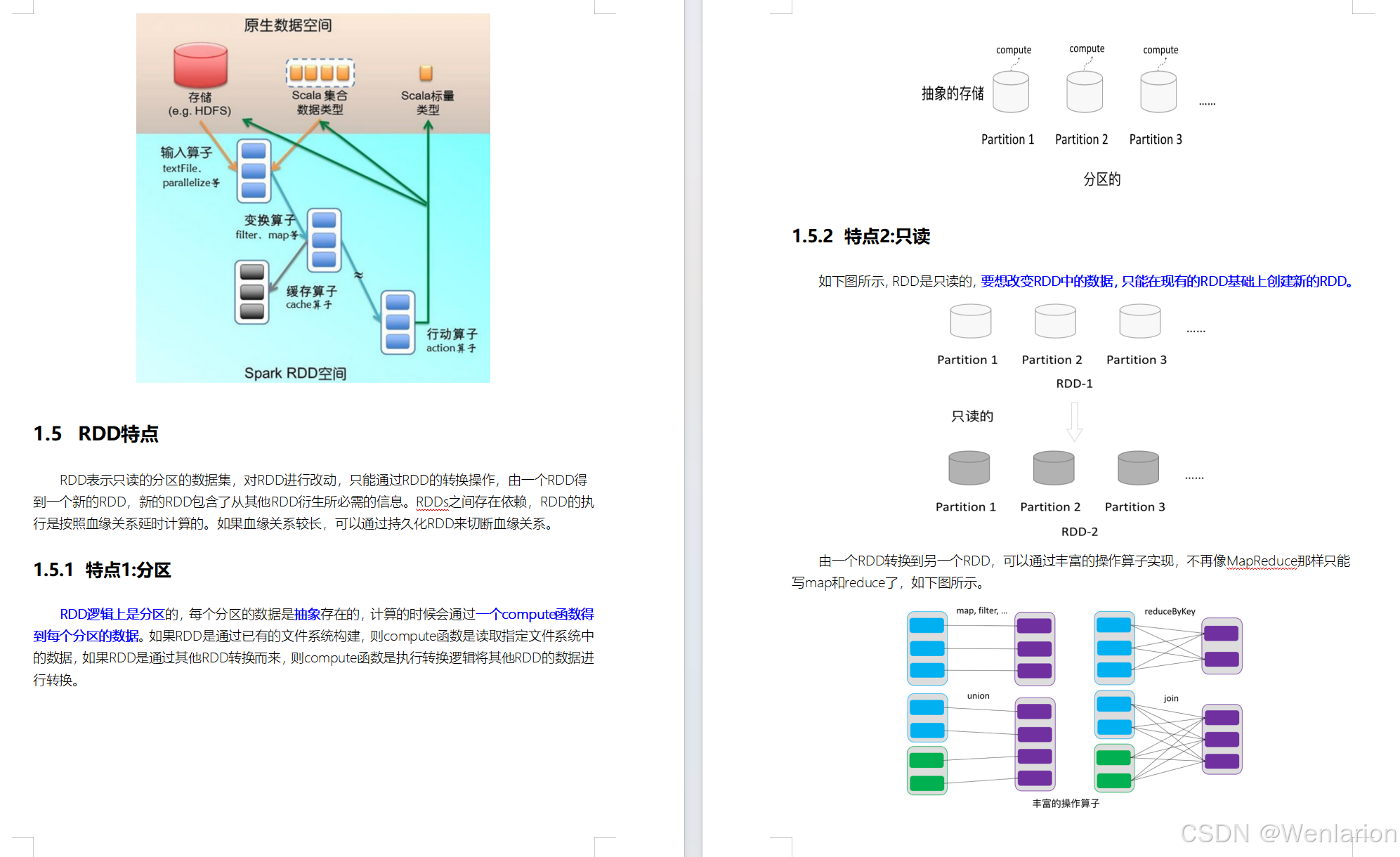
RDD 详解
没有 RDD 之前的痛点
-
MapReduce:仅提供
map/reduceAPI,编码繁琐、运行效率低(多次磁盘 I/O),已逐渐被淘汰。 -
Scala/Java 本地集合:只能处理单机数据,要实现分布式计算非常困难。
-
Hive:用 HQL 简化了 MR 编码,但底层仍依赖 MR,执行速度慢。
-
Spark/Impala:以内存计算为核心,将数据尽量放在内存中,大幅提升迭代和交互式分析效率。
1.1 为什么需要 RDD?
为了解决上述问题,需要一个分布式数据抽象:
-
用这个抽象表示分布式集合,基于它可以方便地完成分布式计算(如 WordCount)。
-
底层细节被封装,对外提供简单易用的 API。
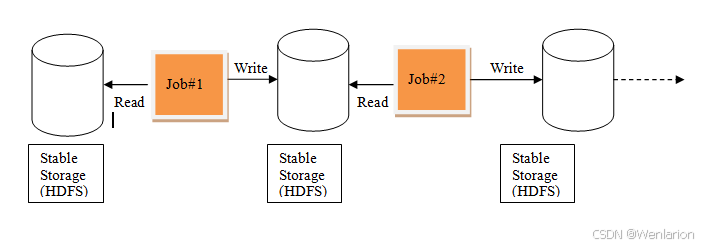
RDD 诞生的背景(对比 MapReduce)
MapReduce 是面向数据集的工作模式:
-
流程:加载数据集 → 操作 → 写入物理存储 → 一次性处理。
-
短板:
-
迭代式算法低效:机器学习(ALS、梯度下降)需要反复查询 / 操作数据集,MR 串行处理耗时久、性能差。
-
数据共享依赖磁盘:迭代时需频繁读写 HDFS,延迟高。
-
交互式数据挖掘不擅长:无法快速响应即席查询。
-
对比 Spark 迭代模式:
-
MR 迭代:
HDFS → Job → HDFS → Job → ...(多次磁盘读写) -
Spark 迭代:数据尽可能放在内存中,
RDD → 计算 → RDD → 计算,避免频繁落盘。






RDD的创建



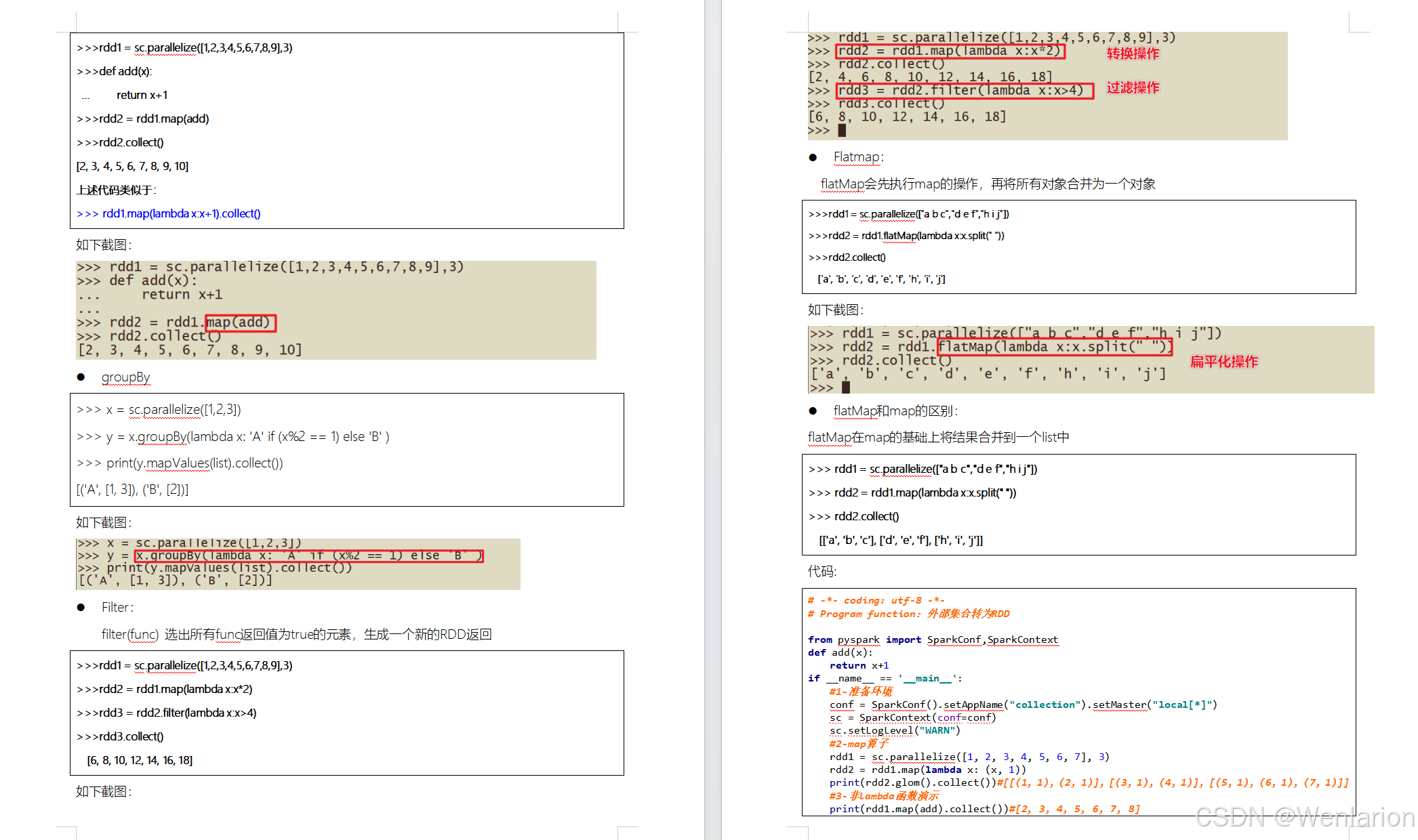
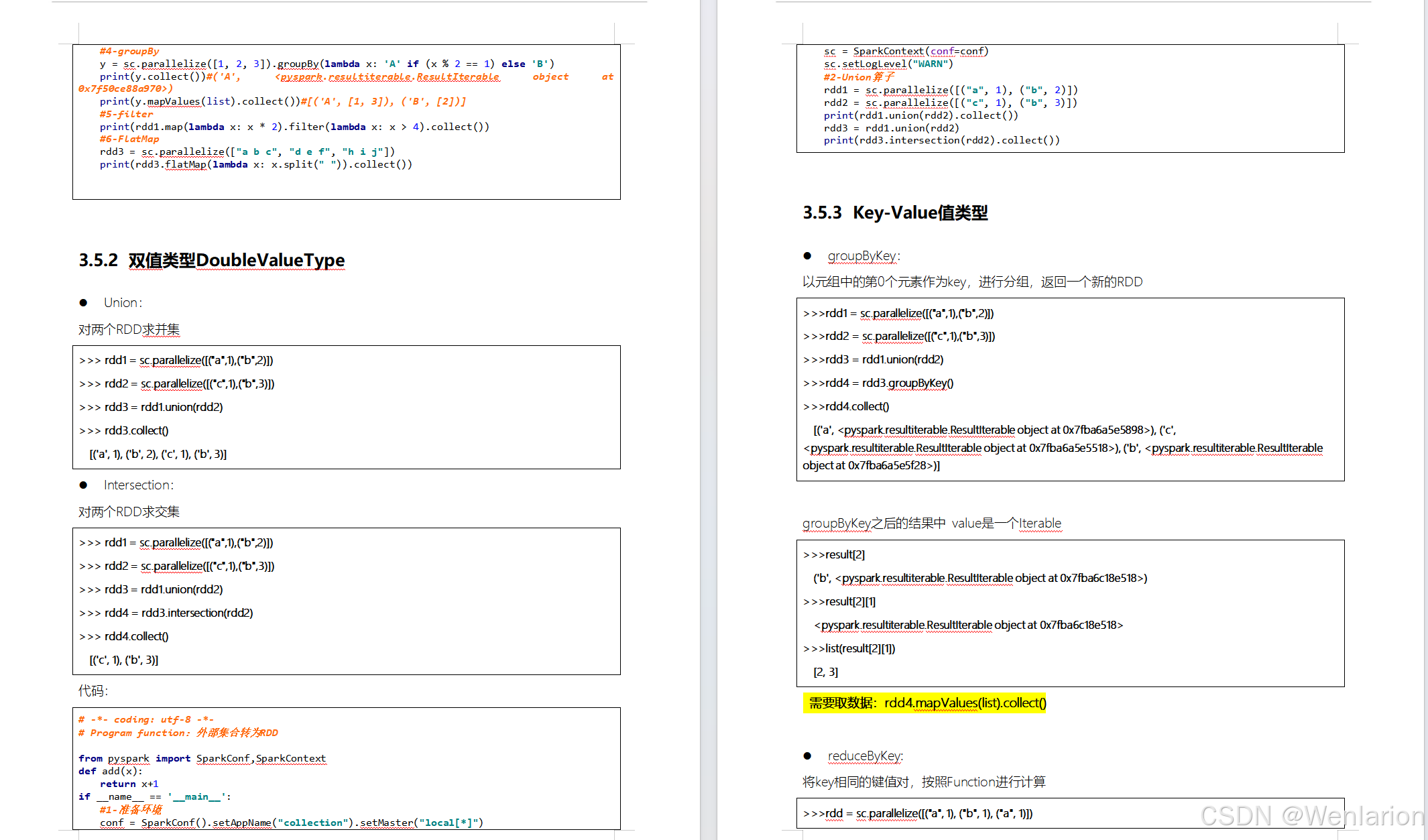
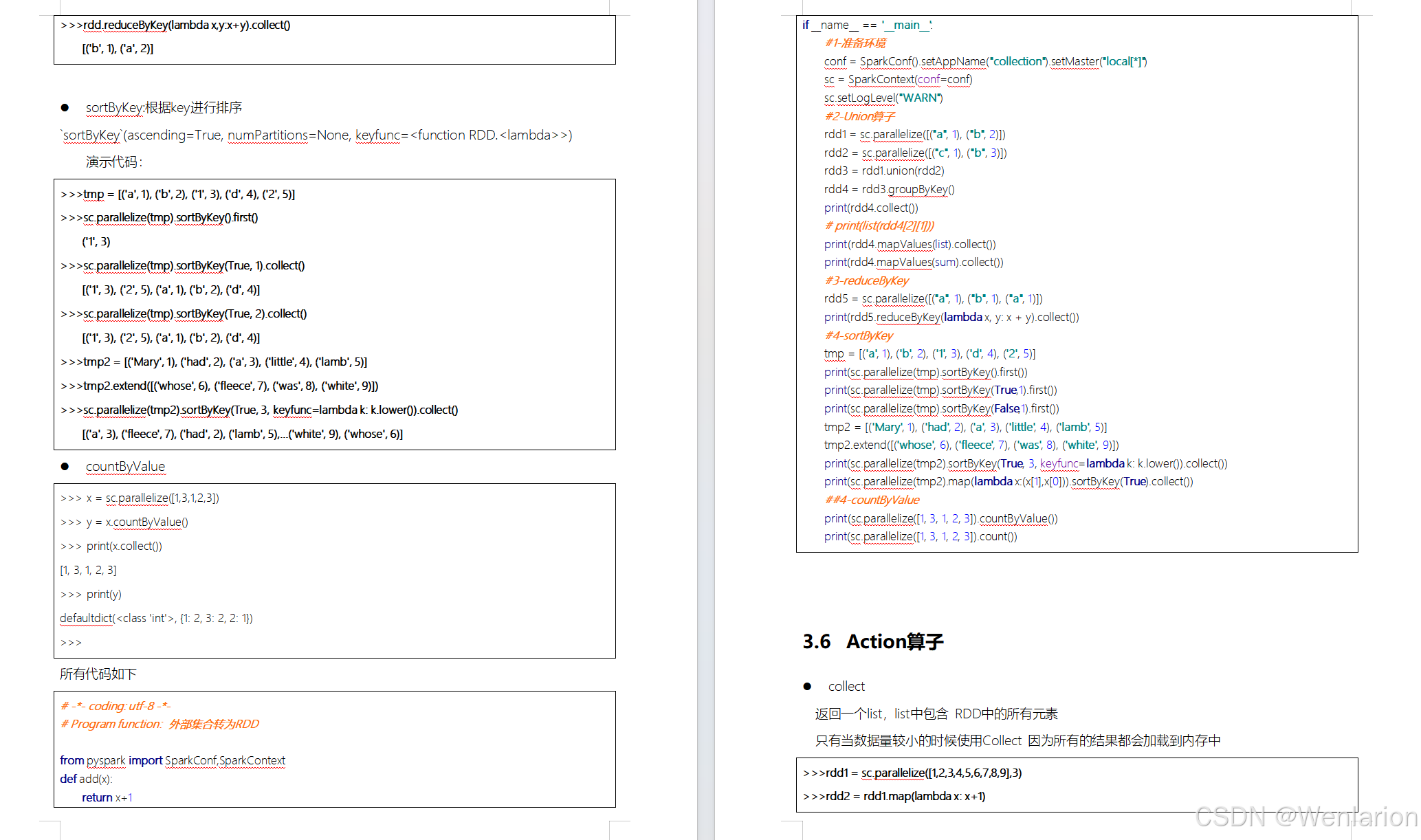
RDD的操作




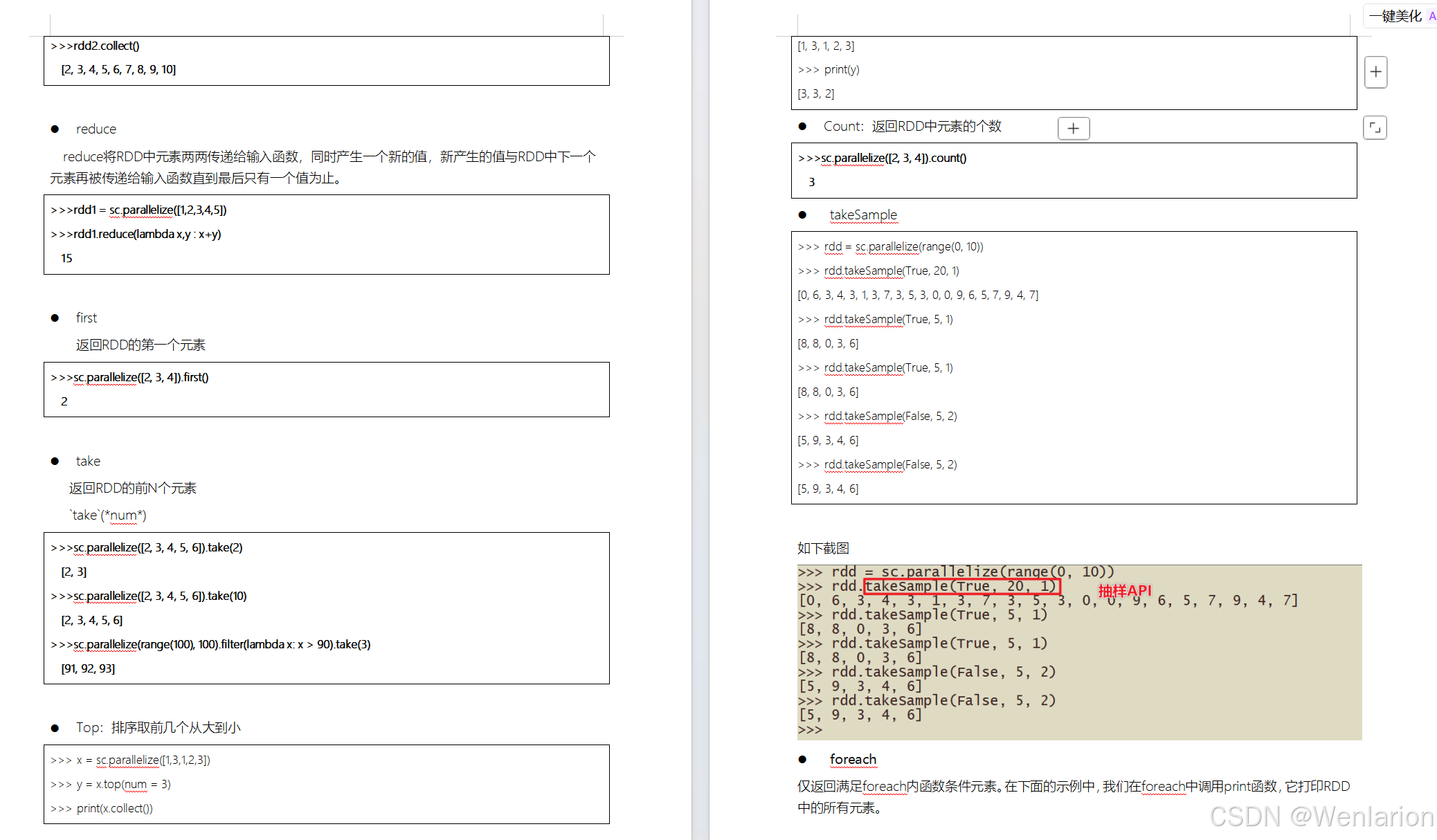


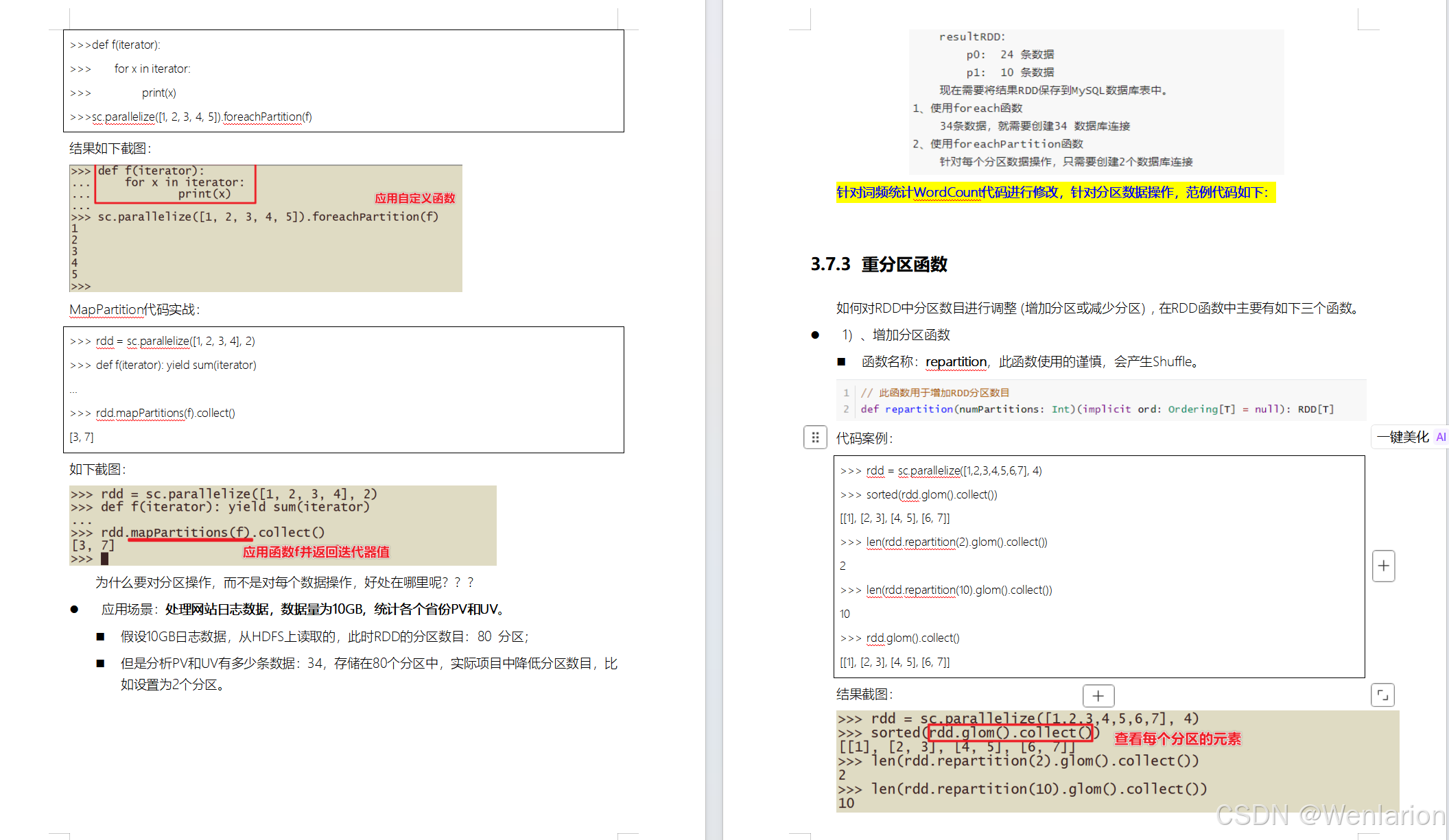
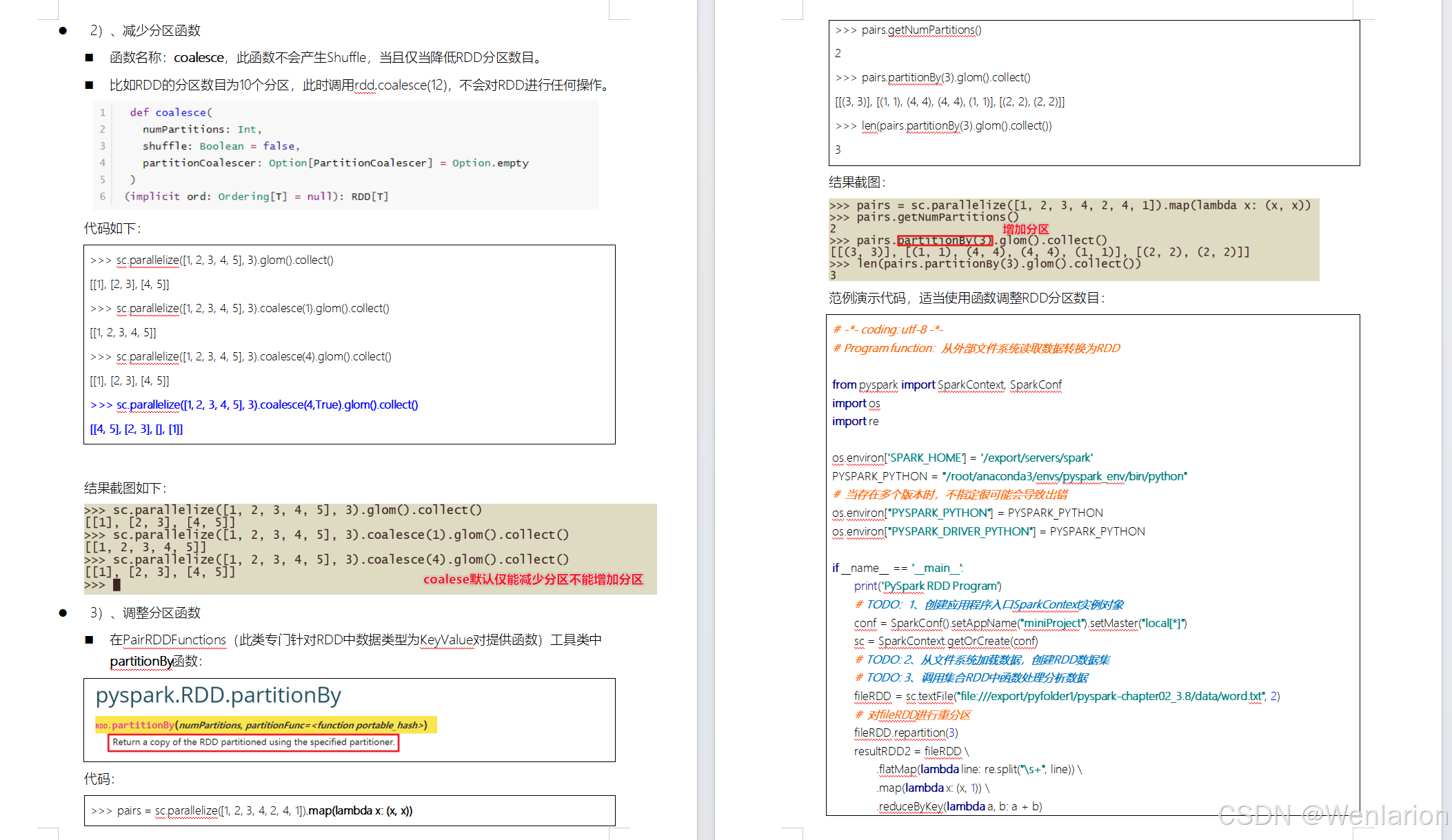
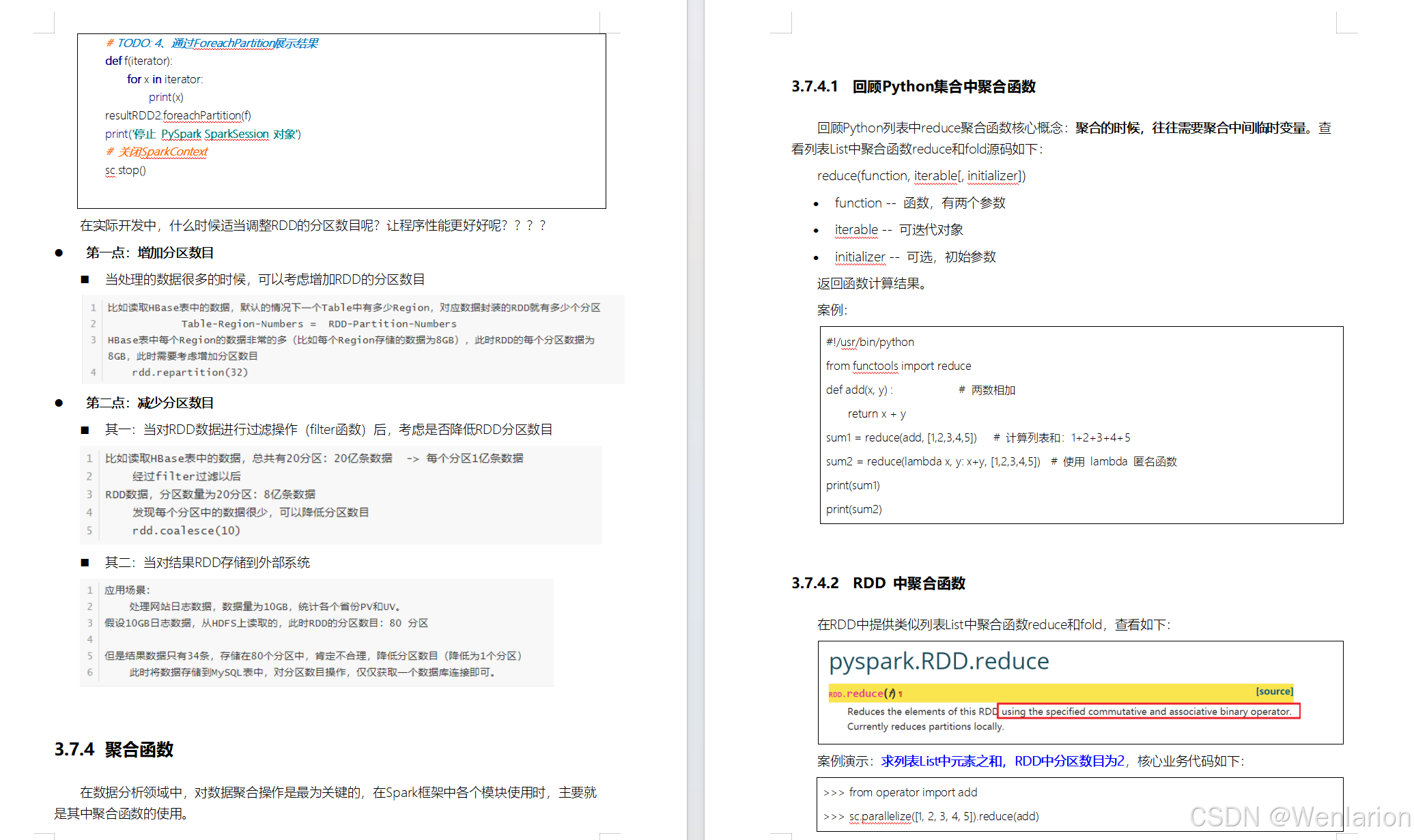
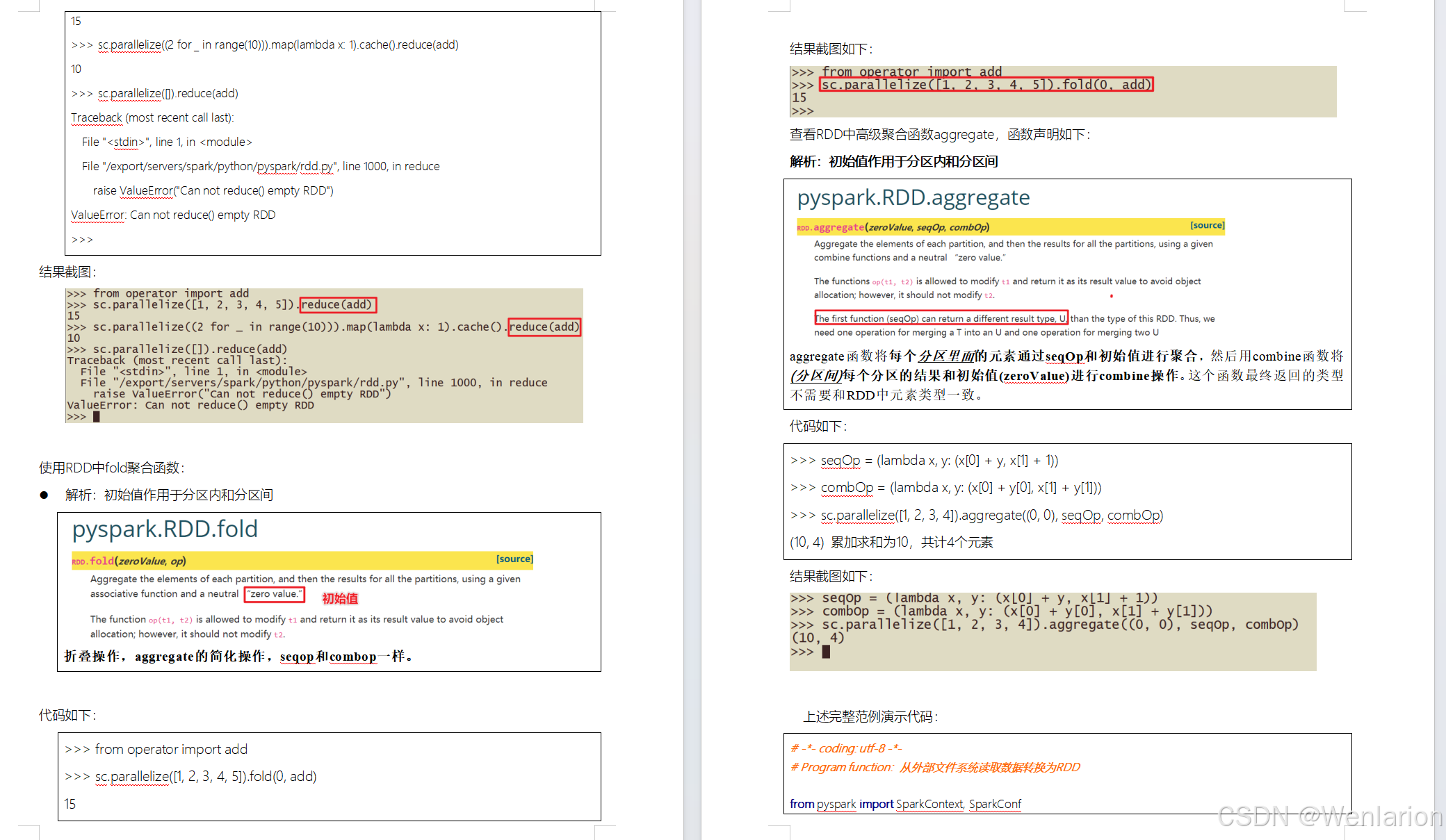



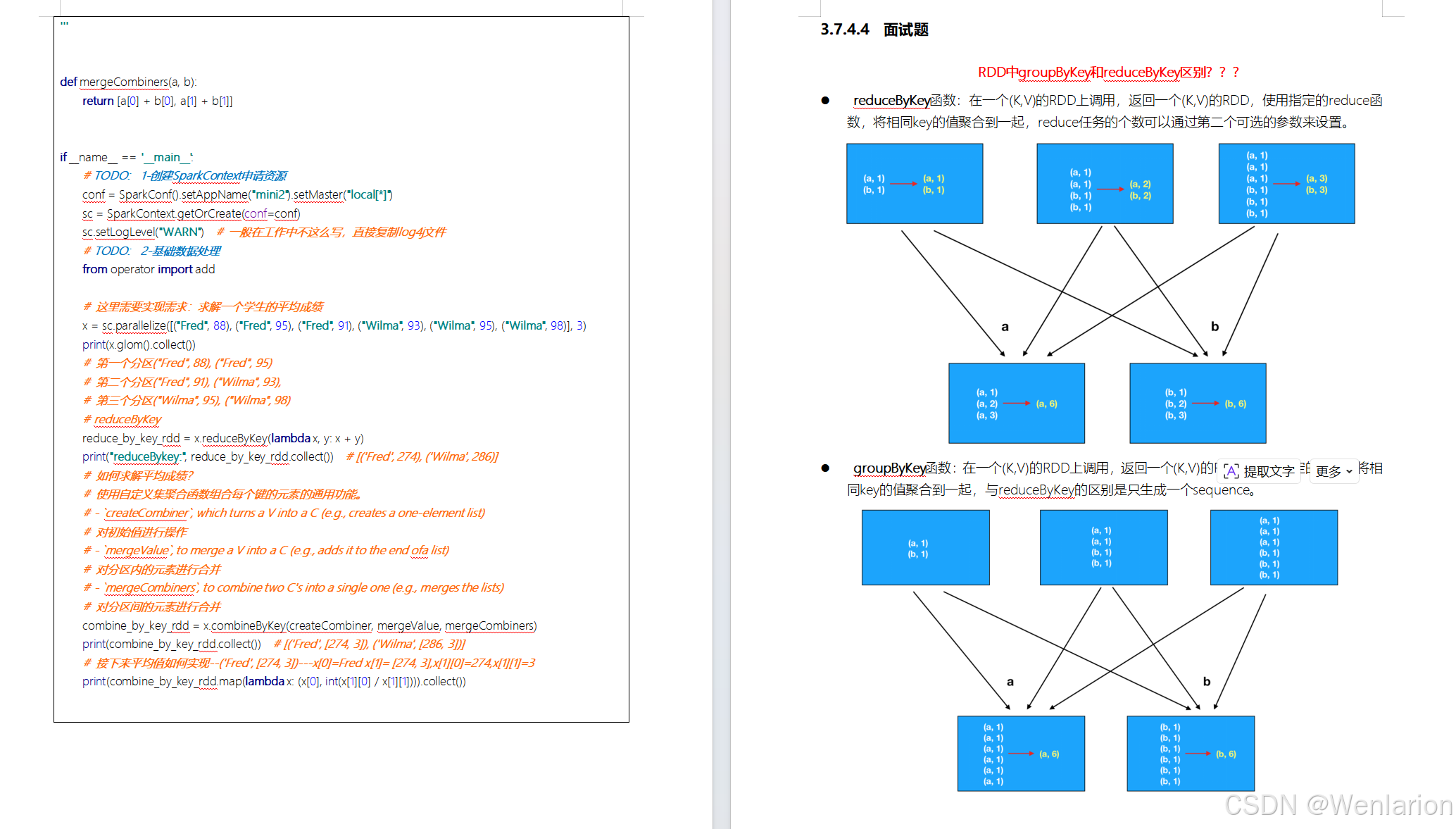
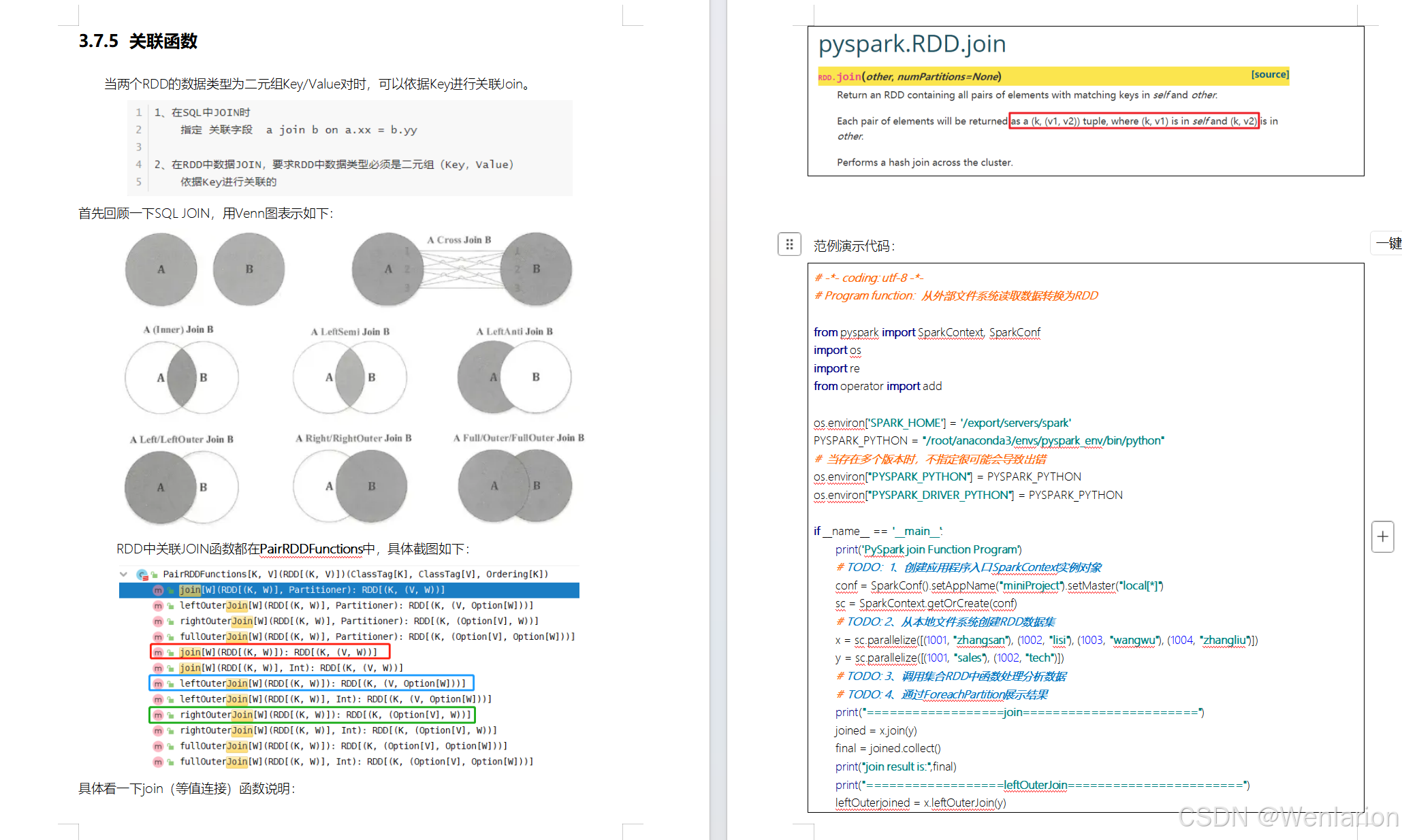
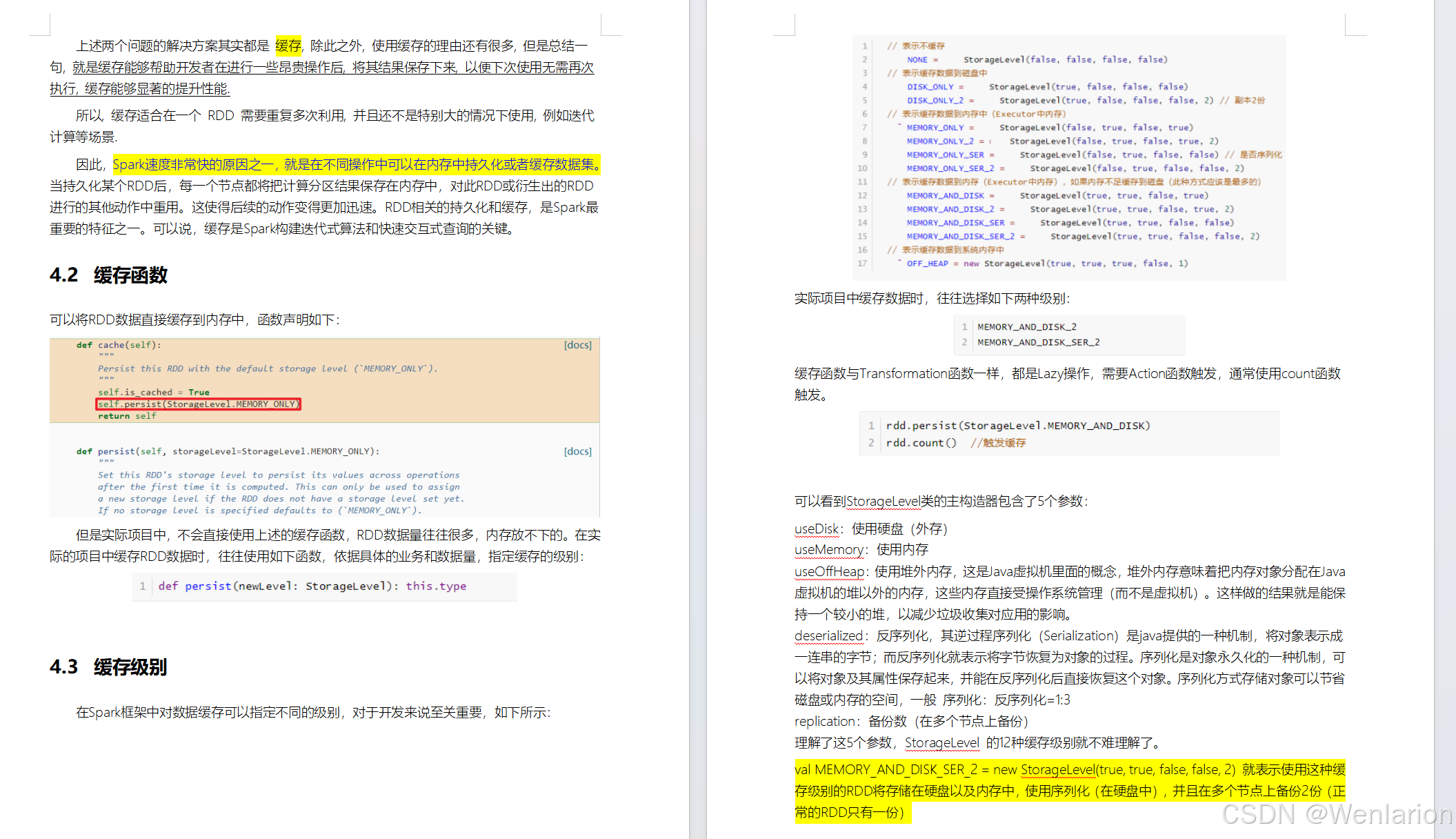
RDD持久化

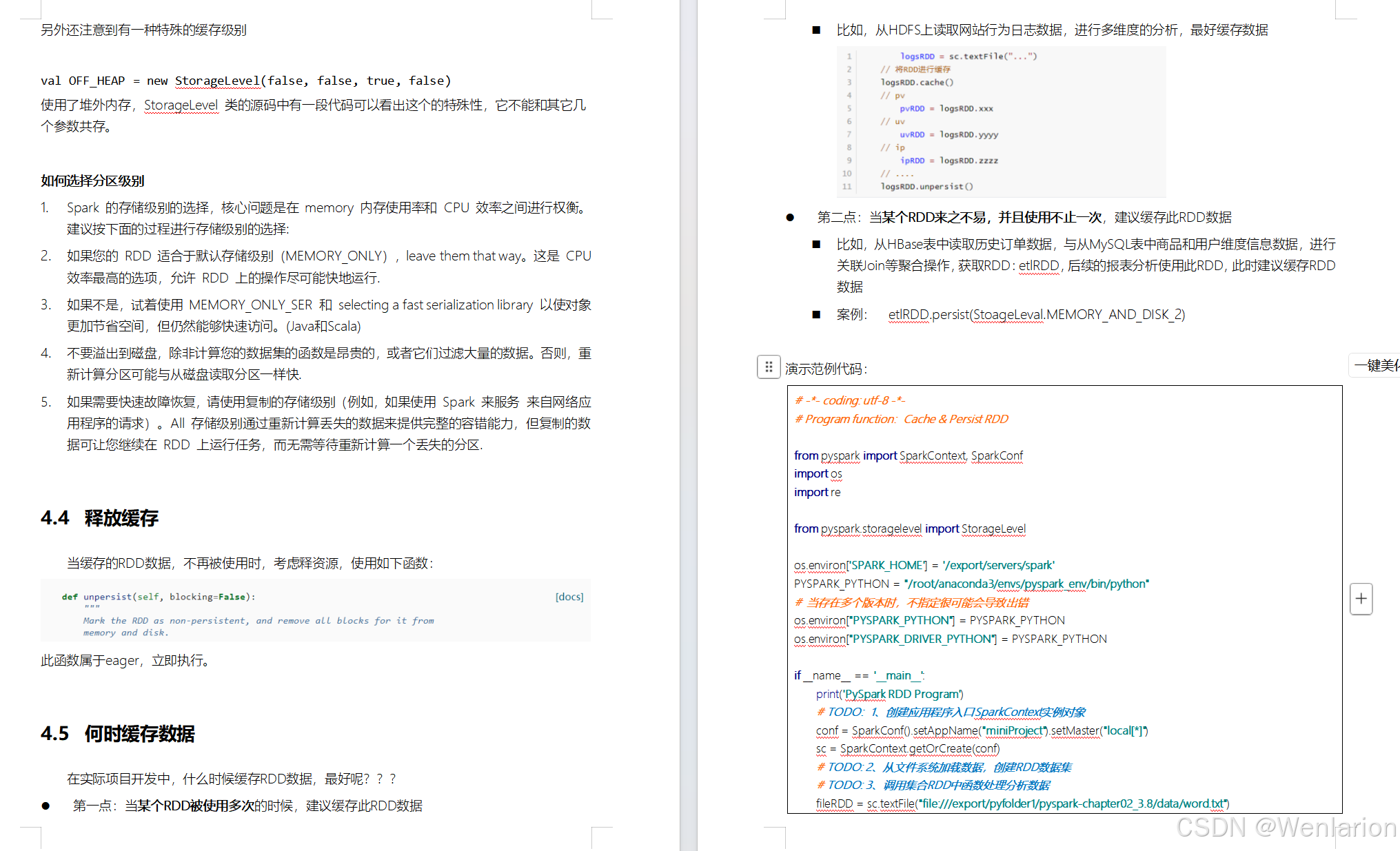
RDD Checkpoint

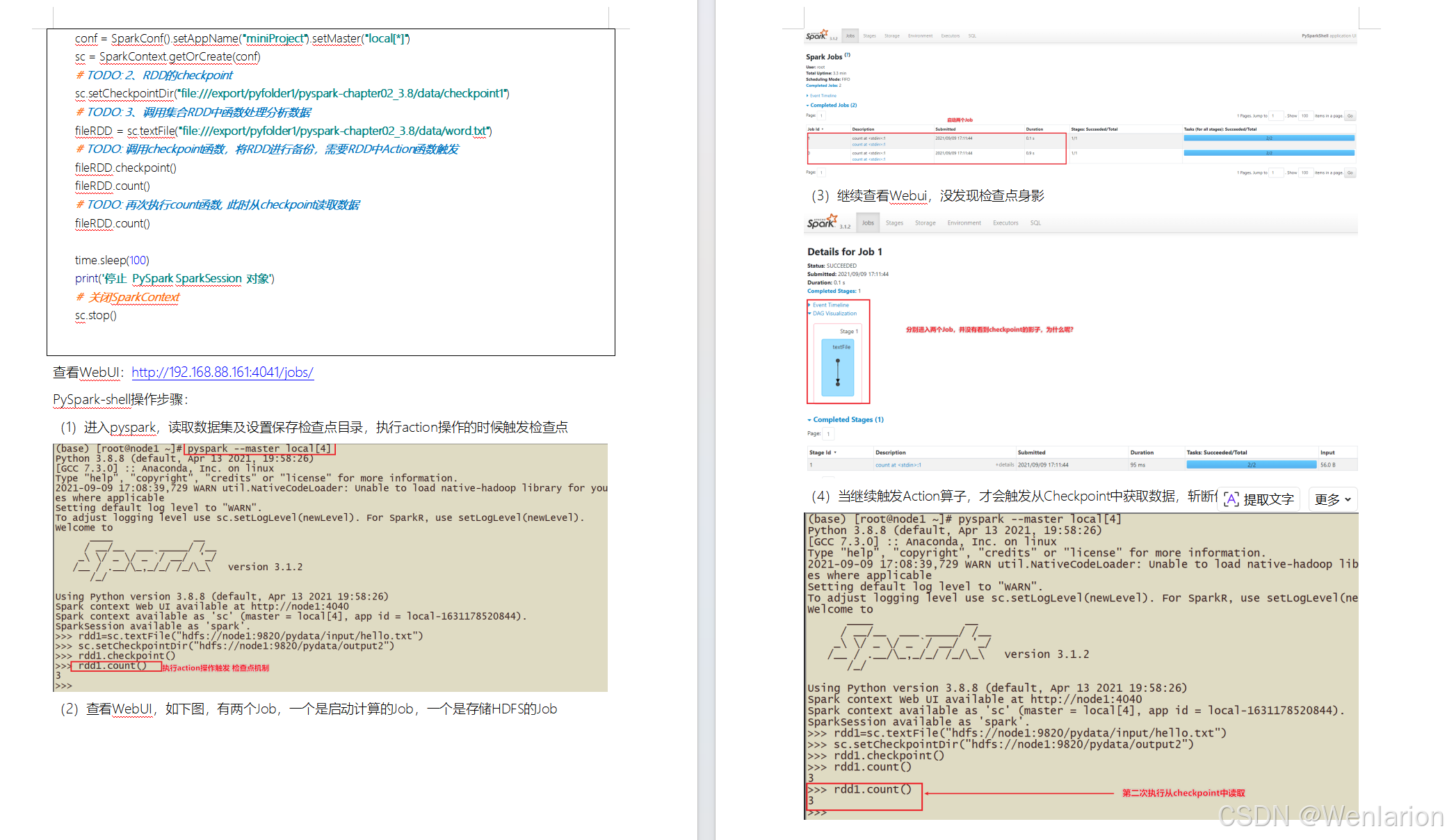
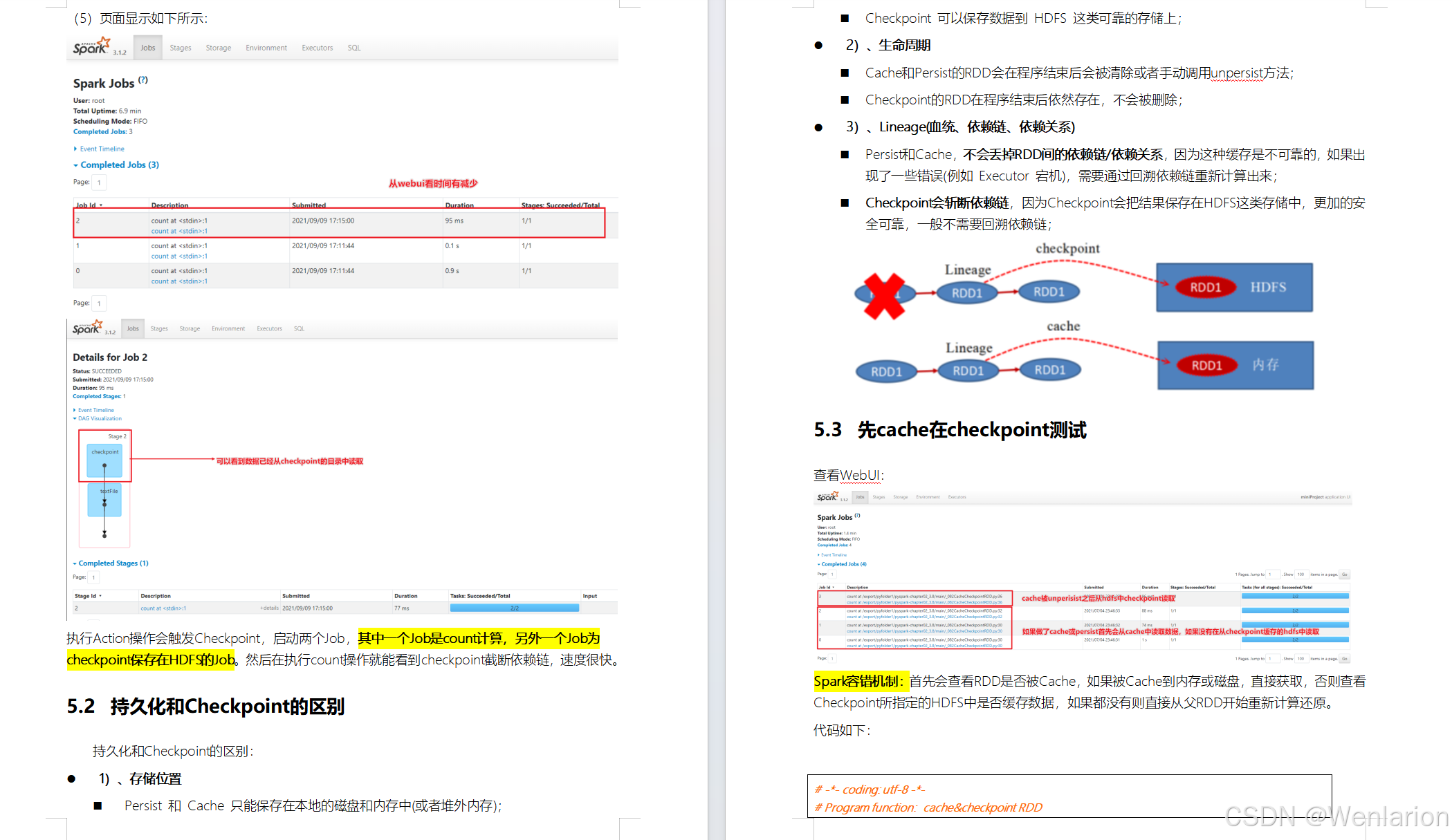
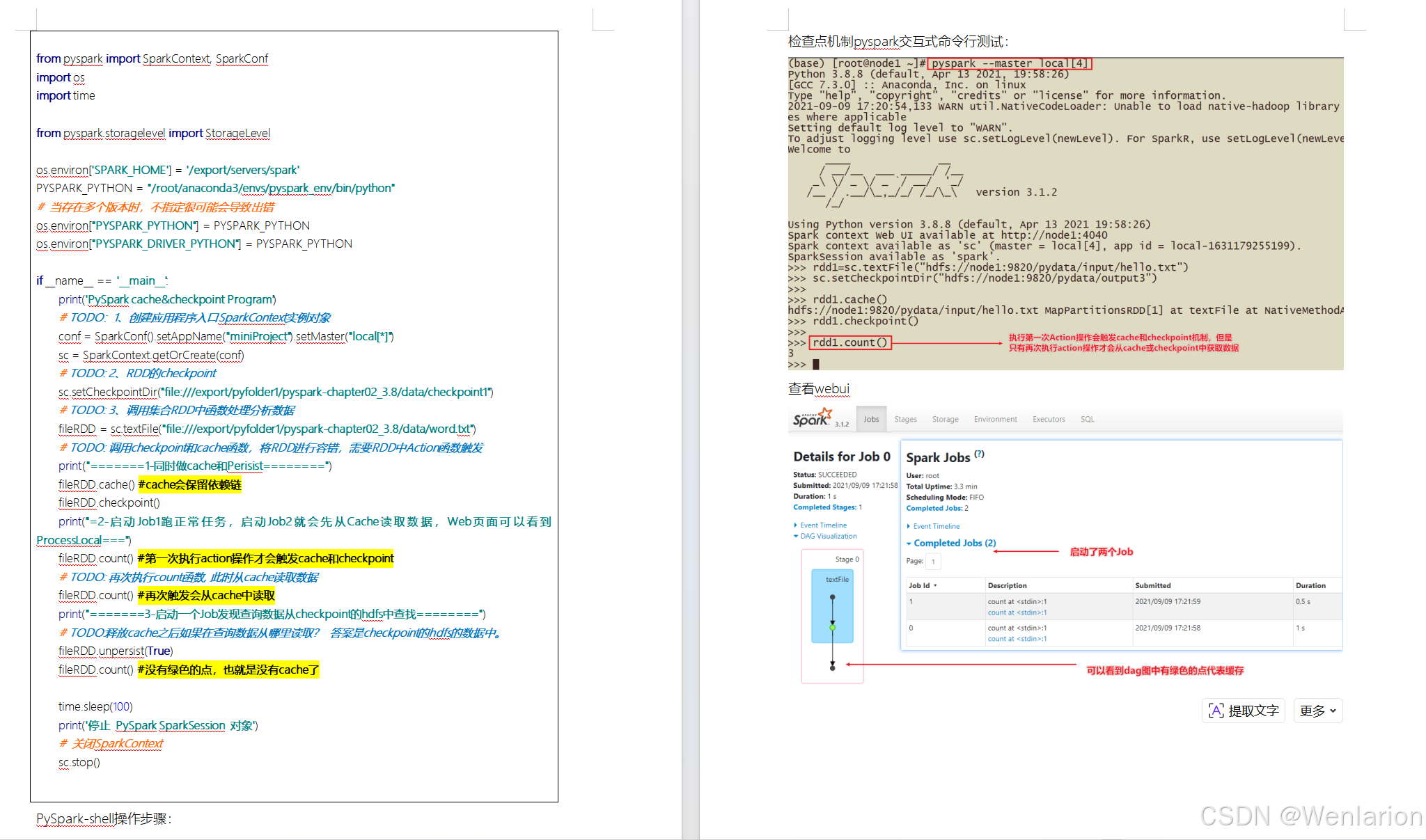
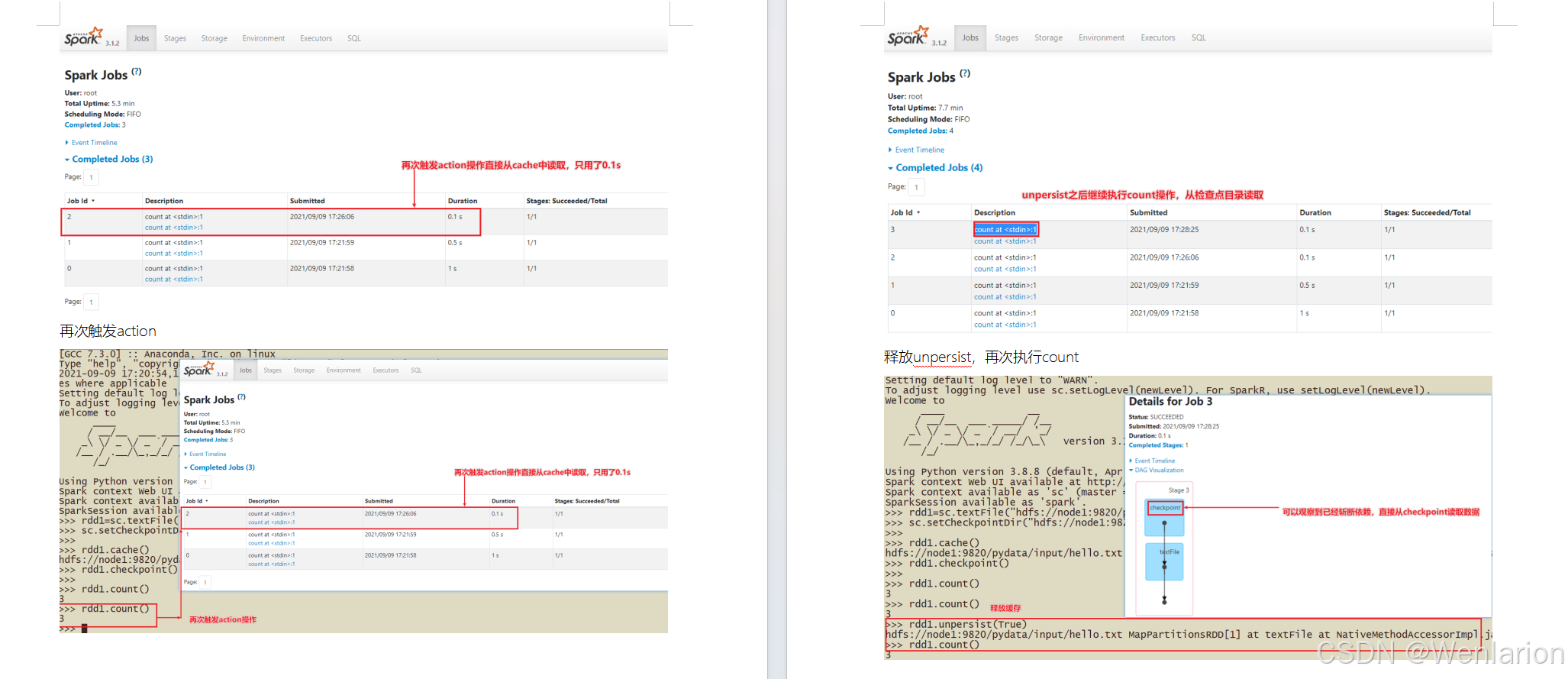
Spark案例练习








共享变量



Spark内核调度











3、Flink
3.1 Flink 批流一体API开发
3.1.1流处理相关概念
流处理的基本概念
一般来说,由于需要支持无限数据集的处理,流处理系统一般采用一种数据驱动的处理方式。它会提前设置一些算子,然后等到数据到达后对数据进行处理。
为了表达复杂的计算逻辑,包括 Flink 在内的分布式流处理引擎一般采用 DAG 图来表示整个计算逻辑,其中 DAG 图中的每一个点就代表一个基本的逻辑单元,也就是算子。由于计算逻辑被组织成有向图,数据会按照边的方向,从一些特殊的 Source 节点流入系统,然后通过网络传输、本地传输等不同的数据传输方式在算子之间进行发送和处理,最后会通过 Sink 节点将计算结果发送到某个外部系统或数据库中。
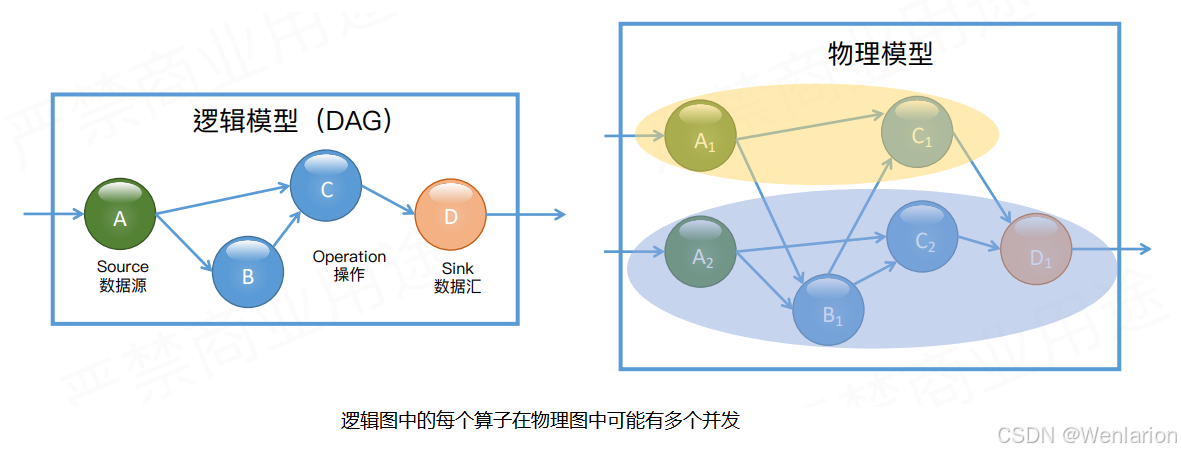
对于分布式流处理引擎,实际运行时物理模型可能比较复杂,由于每个算子都可能有多个实例。如图所示,作为 Source 的 A 算子有两个实例,中间算子 C 也有两个实例。在逻辑模型中,A 和 B 是 C 的上游节点,而在对应的物理逻辑中,C 的所有实例和 A、B 的所有实例之间可能都存在数据交换。在物理模型中,会根据计算逻辑,采用系统自动优化或人为指定的方式将计算工作分布到不同的实例中。只有当算子实例分布到不同进程上时,才需要通过网络进行数据传输,而同一进程中的多个实例之间的数据传输通常是不需要通过网络的。

由于流处理的计算逻辑是通过 DAG 图来表示的,因此它们的大部分 API 都是围绕构建这种计算逻辑图来设计的。例如,对于几年前非常流行的 Apache Storm,它的 Word Count 的示例如表 1 所示。基于 Apache Storm 用户需要在图中添加 Spout 或 Bolt 这种算子,并指定算子之前的连接方式。这样,在完成整个图的构建之后,就可以将图提交到远程或本地集群运行。
与之对比,Apache Flink 的接口虽然也是在构建计算逻辑图,但是 Flink 的 API 定义更加面向数据本身的处理逻辑,它把数据流抽象成为一个无限集,然后定义了一组集合上的操作,然后在底层自动构建相应的 DAG 图。可以看出,Flink 的 API 要更“上层”一些。
流处理和批处理

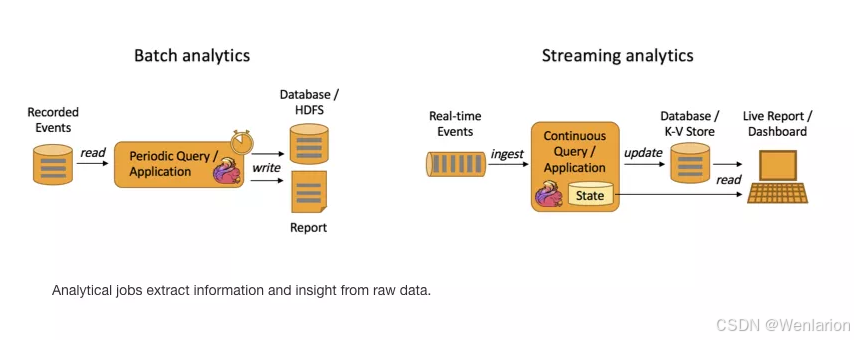
- Batch Analytics,右边是 Streaming Analytics。批量计算: 统一收集数据->存储到DB->对数据进行批量处理,就是传统意义上使用类似于 Map Reduce、Hive、Spark Batch 等,对作业进行分析、处理、生成离线报表
- Streaming Analytics 流式计算,顾名思义,就是对数据流进行处理,如使用流式分析引擎如 Storm,Flink 实时处理分析数据,应用较多的场景如实时大屏、实时报表。

流批一体API
DataStream API 支持批执行模式
Flink 的核心 API 最初是针对特定的场景设计的,尽管 Table API / SQL 针对流处理和批处理已经实现了统一的 API,但当用户使用较底层的 API 时,仍然需要在批处理(DataSet API)和流处理(DataStream API)这两种不同的 API 之间进行选择。鉴于批处理是流处理的一种特例,将这两种 API 合并成统一的 API,有一些非常明显的好处,比如:
可复用性:作业可以在流和批这两种执行模式之间自由地切换,而无需重写任何代码。因此,用户可以复用同一个作业,来处理实时数据和历史数据。
维护简单:统一的 API 意味着流和批可以共用同一组 connector,维护同一套代码,并能够轻松地实现流批混合执行,例如 backfilling 之类的场景。
考虑到这些优点,社区已朝着流批统一的 DataStream API 迈出了第一步:支持高效的批处理(FLIP-134)。从长远来看,这意味着 DataSet API 将被弃用(FLIP-131),其功能将被包含在 DataStream API 和 Table API / SQL 中。
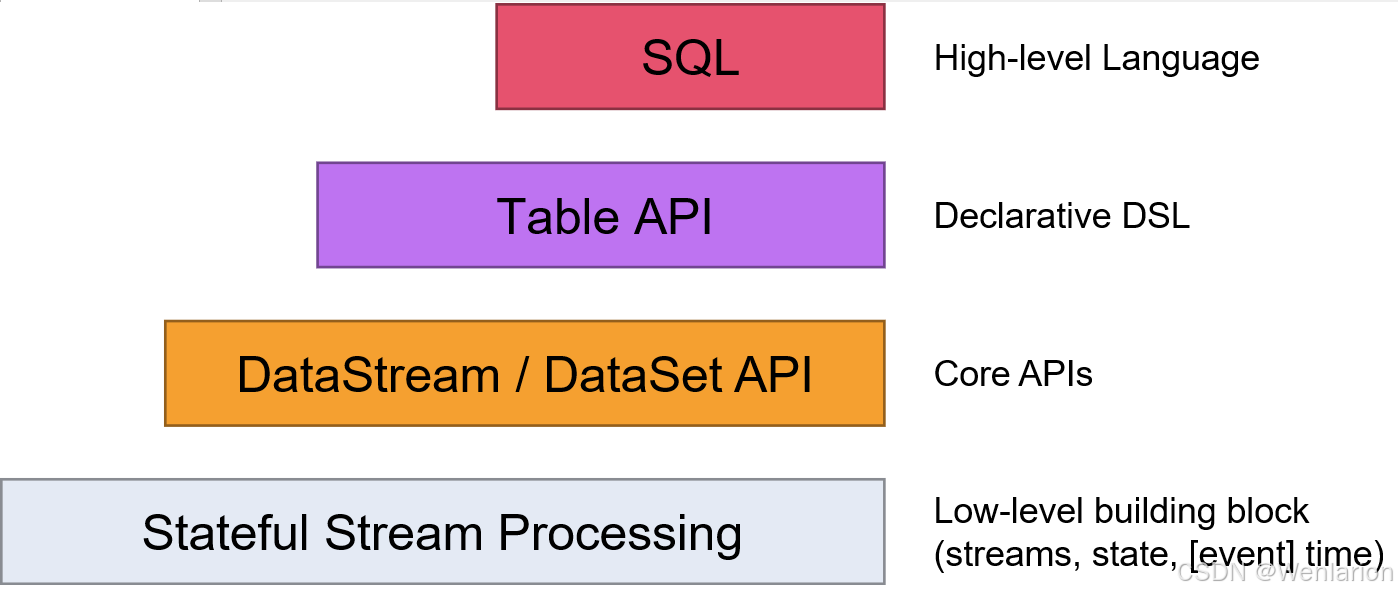
API
Flink提供了多个层次的API供开发者使用,越往上抽象程度越高,使用起来越方便;越往下越底层,使用起来难度越大
注意:在Flink1.12时支持流批一体,DataSetAPI已经不推荐使用了,所以课程中除了个别案例使用DataSet外,后续其他案例都会优先使用DataStream流式API,既支持无界数据处理/流处理,也支持有界数据处理/批处理!当然Table&SQL-API会单独学习


Flink DataStream API编程模型
Flink DataStream API 概览
通过之前的入门案例可以发现:
//1、设置运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2、配置数据源读取数据
DataStream<String> text = env.readTextFile ("input");
//3、进行一系列转换
DataStream<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).keyBy(0).sum(1);
//4、配置数据汇写出数据
counts.writeAsText("output");
//5、提交执行
env.execute("Streaming WordCount");为了实现流式 Word Count:
- 要先获得一个 StreamExecutionEnvironment 对象。它是我们构建图过程中的上下文对象。
- 基于这个对象,我们可以添加一些算子
- 对于流处理程序,我们一般需要首先创建一个数据源去接入数据。在这个例子中,我们使用了 Environment 对象中内置的读取文件的数据源
- 上一步之后,我们拿到的是一个 DataStream 对象,它可以看作一个无限的数据集,可以在该集合上进行序列的操作
- 例如,在 Word Count 例子中,我们首先将每一条记录(即文件中的一行)分隔为单词,这是通过 FlatMap 操作来实现的。调用 FlatMap 将会在底层的 DAG 图中添加一个 FlatMap 算子。然后,我们得到了一个记录是单词的流
- 我们将流中的单词进行分组(keyBy),然后累积计算每一个单词的数据(sum(1))
- 计算出的单词的数据组成了一个新的流,我们将它写入到输出文件中
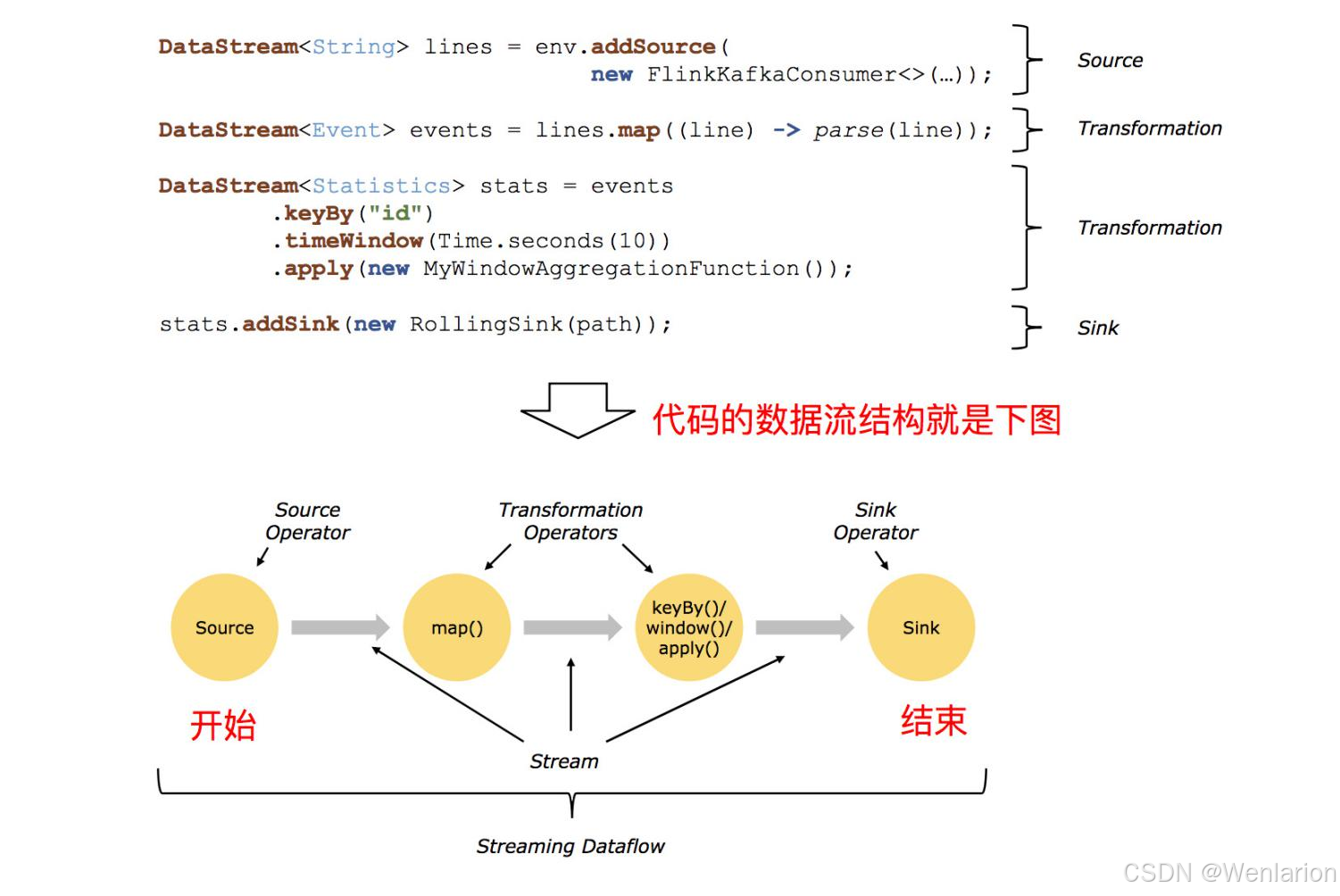
最后,调用 env.execute 方法来开始程序的执行。需要强调的是,前面我们调用的所有方法,都不是在实际处理数据,而是在构通表达计算逻辑的 DAG 图。只有当我们将整个图构建完成并显式的调用 Execute 方法后,框架才会把计算图提供到集群中,接入数据并执行实际的逻辑。
基于 Flink 的 DataStream API 来编写流处理程序一般需要三步:
- 通过 Source 接入数据
- 进行一系统列的处理以及将数据写出
- 不要忘记显式调用 Execute 方式,否则前面编写的逻辑并不会真正执行。
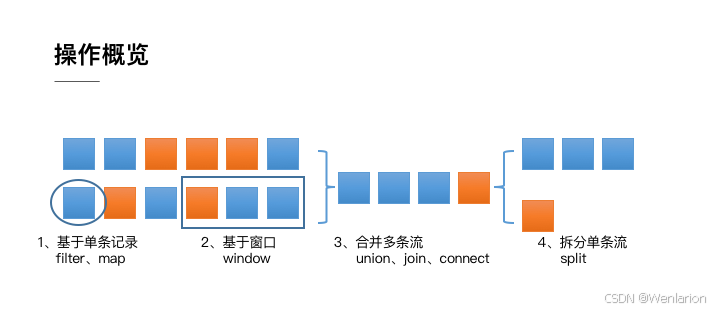
从上面的例子中还可以看出,Flink DataStream API 的核心,就是代表流数据的 DataStream 对象。整个计算逻辑图的构建就是围绕调用 DataStream 对象上的不同操作产生新的 DataStream 对象展开的。整体来说,DataStream 上的操作可以分为四类。
- 第一类是对于单条记录的操作,比如筛除掉不符合要求的记录(Filter 操作),或者将每条记录都做一个转换(Map 操作)
- 第二类是对多条记录的操作。比如说统计一个小时内的订单总成交量,就需要将一个小时内的所有订单记录的成交量加到一起。为了支持这种类型的操作,就得通过 Window 将需要的记录关联到一起进行处理
- 第三类是对多个流进行操作并转换为单个流。例如,多个流可以通过 Union、Join 或 Connect 等操作合到一起。这些操作合并的逻辑不同,但是它们最终都会产生了一个新的统一的流,从而可以进行一些跨流的操作。
- 最后, DataStream 还支持与合并对称的操作,即把一个流按一定规则拆分为多个流(Split 操作),每个流是之前流的一个子集,这样我们就可以对不同的流作不同的处理。
Flink DataStream API编程基本步骤
- 获取执行环境(StreamExecutionEnvironment)
- 加载/创建初始数据集
- 对数据集进行各种转换操作(生成新的DataStream)
- 指定将计算的结果存储到哪个位置
- 触发APP执行(execute)
3.1.2 输入数据源
Data Sources 是什么呢?就字面意思其实就可以知道:数据来源。
Flink 做为一款流式计算框架,它可用来做批处理,也可以用来做流处理,这个 Data Sources 就是数据的来源地。
flink在批/流处理中常见的source主要有两大类。
- 预定义Source
- 基于本地集合的source(Collection-based-source)
- 基于文件的source(File-based-source)
- 基于网络套接字(socketTextStream)
- 自定义Source

预定义Source
基于本地集合的source(Collection-based-source)
在flink最常见的创建DataStream方式有四种:
- 使用env.fromElements(),这种方式也支持Tuple,自定义对象等复合形式。
注意:类型要一致,不一致可以用Object接收,但是使用会报错,比如:env.fromElements("haha", 1);
源码注释中有写:
- 使用env.fromCollection(),这种方式支持多种Collection的具体类型,如List,Set,Queue
- 使用env.generateSequence()方法创建基于Sequence的DataStream
- 使用env.fromSequence()方法创建基于开始和结束的DataStream
补充-在代码中指定并行度
- 指定全局并行度:env.setParallelism(12);
- 获得全局并行度:env.getParallelism();
指定算子设置并行度
获得指定算子的并行度:
eventSource.getParallelism();
基于文件的source(File-based-source)

Flink支持直接从外部文件存储系统中读取文件的方式来创建Source数据源,Flink支持的方式有以下几种:
- readTextFile(path)-TextInputFormat逐行读取文本文件,即遵守规范的文件,并将它们作为字符串返回。
- readFile(fileInputFormat, path) - 按照指定的文件输入格式读取(一次)文件。
- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo)- 这是前两个内部调用的方法。它path根据给定的fileInputFormat. 根据提供的watchType,此源可能会定期(每interval毫秒)监视新数据的路径 ( FileProcessingMode.PROCESS_CONTINUOUSLY),或处理当前路径中的数据并退出 ( FileProcessingMode.PROCESS_ONCE)。使用pathFilter,用户可以进一步排除正在处理的文件。
执行:
Flink 将文件读取过程拆分为两个子任务,即目录监控和数据读取。这些子任务中的每一个都由单独的实体实现。监控由单个非并行(并行性 = 1)任务实现,而读取由多个并行运行的任务执行。后者的并行度等于作业并行度。单个监控任务的作用是扫描目录(定期或仅一次,取决于watchType),找到要处理的文件,将它们拆分,并将这些拆分分配给下游阅读器。读者是将阅读实际数据的人。每个 split 只能由一个 reader 读取,而一个 reader 可以一个一个读取多个 split。
重要笔记:
- 如果watchType设置为FileProcessingMode.PROCESS_CONTINUOUSLY,当文件被修改时,其内容将被完全重新处理。这可能会破坏“恰好一次”语义,因为在文件末尾附加数据将导致其所有内容都被重新处理。
- 如果watchType设置为FileProcessingMode.PROCESS_ONCE,则源将扫描路径一次并退出,无需等待读取器完成读取文件内容。当然,读者会继续阅读,直到所有文件内容都读完。关闭源会导致在那之后不再有检查点。这可能会导致节点故障后恢复速度变慢,因为作业将从最后一个检查点恢复读取。
下面分别演示每个数据源的加载方式。
批的方式读取文本文件
Flink的批处理可以直接通过readTextFile()方法读取文件来创建数据源,方法如下:
public class BatchFromFile{
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 8181); //设置webui的端口
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(configuration);
String path = "./data/input/wordcount.txt";
DataStreamSource<String> lines = env.readTextFile(path);
int parallelism = lines.getParallelism();
System.out.println("ReadTextFileDemo创建的DataStream的并行度为:" + parallelism);
lines.print();
env.execute();
}
}流的方式读取文件文件
Flink的批处理可以直接通过readFile()方法读取文件来创建数据源,方法如下:
//readFile创建的Source是一个多并行的Source,而且是一个无限的数据流,但是会重复读取数据
public class StreamFromFile {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.setInteger("rest.port", 8181); //设置webui的端口
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(configuration);
String path = "./data/input/wordcount.txt";
DataStreamSource<String> lines = env.readFile(new TextInputFormat(null), path,
FileProcessingMode.PROCESS_CONTINUOUSLY, 2000);
int parallelism = lines.getParallelism();
System.out.println("readFile创建的DataStream的并行度为:" + parallelism);
lines.print();
env.execute();
}
}基于Socket的Source
socketTextStream(String hostname, int port) 方法是一个非并行的Source,该方法需要传入两个参数,第一个是指定的IP地址或主机名,第二个是端口号,即从指定的Socket读取数据创建DataStream。该方法还有多个重载的方法,其中一个是socketTextStream(String hostname, int port, String delimiter, long maxRetry),这个重载的方法可以指定行分隔符和最大重新连接次数。这两个参数,默认行分隔符是”\n”,最大重新连接次数为0。
提示:
如果使用socketTextStream读取数据,在启动Flink程序之前,必须先启动一个Socket服务,为了方便,Mac或Linux用户可以在命令行终端输入nc -lk 8888启动一个Socket服务并在命令行中向该Socket服务发送数据。Windows用户可以在百度中搜索windows安装netcat命令。
//socketTextStream创建的DataStream,不论怎样,并行度永远是1
public class StreamSocketSource {
public static void main(String[] args) throws Exception {
//local模式默认的并行度是当前机器的逻辑核的数量
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
int parallelism0 = env.getParallelism();
System.out.println("执行环境默认的并行度:" + parallelism0);
DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);
//获取DataStream的并行度
int parallelism = lines.getParallelism();
System.out.println("SocketSource的并行度:" + parallelism);
SingleOutputStreamOperator<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(word);
}
}
});
int parallelism2 = words.getParallelism();
System.out.println("调用完FlatMap后DataStream的并行度:" + parallelism2);
words.print();
env.execute();
}
}自定义Source
基于随机生成DataSource
自定义实现SourceFunction接口
除了预定义的Source外,我们还可以通过实现SourceFunction来自定义Source,然后通过StreamExecutionEnvironment.addSource(sourceFunction)添加进来。
- 示例:
自定义数据源, 每1秒钟随机生成一条订单信息(订单ID、用户ID、订单金额、时间戳)
- 要求:
- 随机生成订单ID(UUID)
- 随机生成用户ID(0-2)
- 随机生成订单金额(0-100)
- 时间戳为当前系统时间
开发步骤:
- 创建订单实体类
- 创建自定义数据源
- 死循环生成订单
- 随机构建订单信息
- 上下文收集数据
- 每隔一秒执行一次循环
- 获取流处理环境
- 使用自定义Source
- 打印数据
执行任务
订单实体类
|
/** |
主代码
|
public class CustomerSourceWithoutParallelDemo { |
实现ParallelSourceFunction创建可并行Source
|
/** |
实现RichParallelSourceFunction:创建并行并带有Rich功能的Source
|
/** |
基于mysql的source操作
上面我们已经使用了自定义数据源和Flink自带的Kafka source,那么接下来就模仿着写一个从 MySQL 中读取数据的 Source。
- 示例
自定义数据源, 读取MySql数据库(test)表(user)数据
|
Id |
Username |
Password |
Name |
|
1 |
Zhangsan |
111111 |
张三 |
|
2 |
Lisi |
222222 |
李四 |
|
3 |
Wangwu |
333333 |
王五 |
|
4 |
Zhaoliu |
444444 |
赵六 |
|
5 |
Tianqi |
555555 |
田七 |
- 建表语句
|
DROP TABLE IF EXISTS `user`; CREATE TABLE `user` ( `id` int(11) NOT NULL, `username` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact; -- ---------------------------- -- Records of user -- ---------------------------- INSERT INTO `user` VALUES (10, 'dazhuang', '123456', '大壮'); INSERT INTO `user` VALUES (11, 'erya', '123456', '二丫'); INSERT INTO `user` VALUES (12, 'sanpang', '123456', '三胖'); SET FOREIGN_KEY_CHECKS = 1; |
- 相关依赖
|
<!-- 指定mysql-connector的依赖 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.48</version> </dependency> |
- 开发步骤
- 自定义Source,继承自RichSourceFunction
- 实现open方法
- 实现run方法
- 加载驱动
- 创建连接
- 创建PreparedStatement
- 执行查询
- 遍历查询结果,收集数据
- 使用自定义Source
- 打印结果
- 执行任务
参考代码
/**
* 自定义Mysql Source
*/
public class CustomerMysqlSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获得自定义Source对象
DataStreamSource<UserInfo> mysqlSource = env.addSource(new MyMysqlSource());
mysqlSource.print();
env.execute("CustomerMySQLSourceDemo");
}
/**
自定义Mysql Source实现类
*/
public static class MyMysqlSource extends RichSourceFunction<UserInfo> {
private Connection connection = null; // 定义数据库连接对象
private PreparedStatement ps = null; // 定义PreparedStatement对象
/*
使用open方法, 这个方法在实例化类的时候会执行一次, 比较适合用来做数据库连接
*/
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
// 创建数据库连接
String url = "jdbc:mysql://node01:3306/flinkdemo?useUnicode=true&characterEncoding=utf-8&useSSL=false";
this.connection = DriverManager.getConnection(url, "root", "123456");
// 准备PreparedStatement对象
this.ps = connection.prepareStatement("SELECT id, username, password, name FROM user");
}
/*
使用close方法, 这个方法在销毁实例的时候会执行一次, 比较适合用来关闭连接
*/
@Override
public void close() throws Exception {
super.close();
// 关闭资源
if (this.ps != null) this.ps.close();
if (this.connection != null) this.connection.close();
}
@Override
public void run(SourceContext<UserInfo> ctx) throws Exception {
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()) {
int id = resultSet.getInt("id");
String username = resultSet.getString("username");
String password = resultSet.getString("password");
String name = resultSet.getString("name");
ctx.collect(new UserInfo(id, username, password, name));
}
}
@Override
public void cancel() {
System.out.println("任务被取消......");
}
}
/**
数据定义类, POJO
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class UserInfo {
int id;
String username;
String password;
String name;
}
}3.1.3 Transformation
dataStream操作
dataStream包括一系列的Transformation操作:
Map
将DataStream中的每一个元素转换为另外一个元素
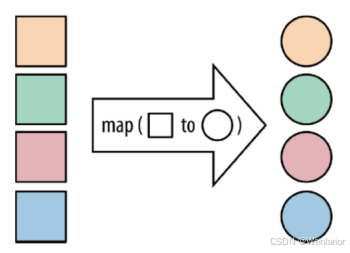
示例
使用map操作,读取apache.log文件中的字符串数据转换成ApacheLogEvent对象
如:
|
86.149.9.216 10001 17/05/2015:10:05:30 GET /presentations/logstash-monitorama-2013/images/github-contributions.png 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:06:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:07:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:08:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:09:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:10:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:16:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:26:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css |
步骤
- 获取ExecutionEnvironment运行环境
- 使用readTextFile读取数据构建数据源
- 创建一个ApacheLogEvent类
- 使用map操作执行转换
- 打印测试
参考代码
|
/** |
FlatMap
将DataStream中的每一个元素转换为0...n个元素
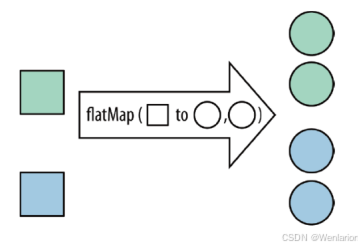
示例
读取flatmap.log文件中的数据
如:
|
张三,苹果手机,联想电脑,华为平板 |
转换为
|
张三有苹果手机 张三有联想电脑 张三有华为平板 李四有… … … |
思路
以上数据为一条转换为三条,显然,应当使用flatMap来实现分别在flatMap函数中构建三个数据,并放入到一个列表中
步骤
- 构建批流理运行环境
- 构建本地集合数据源
- 使用flatMap将一条数据经过处理转换为三条数据
- 使用逗号分隔字段
- 分别构建三条数据
- 打印输出
参考代码
|
/** |
过滤出来一些符合条件的元素
示例:
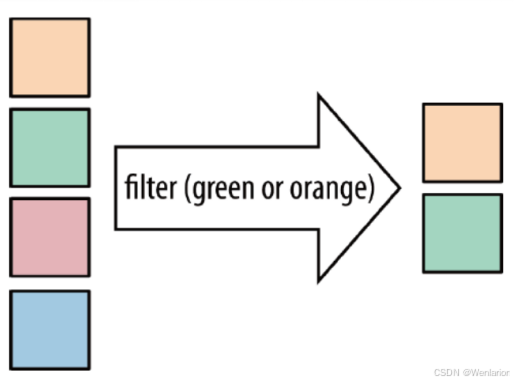
读取apache.log文件中的访问日志数据,过滤出来以下访问IP是83.149.9.216的访问日志。
|
86.149.9.216 10001 17/05/2015:10:05:30 GET /presentations/logstash-monitorama-2013/images/github-contributions.png 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:06:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:07:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:08:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:09:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:10:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:16:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:26:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css |
步骤
- 获取ExecutionEnvironment运行环境
- 使用fromCollection构建数据源
- 使用filter操作执行过滤
- 打印测试
参考代码
|
/** |
KeyBy
按照指定的key来对流中的数据进行分组,前面入门案例中已经演示过
注意:
流处理中没有groupBy,而是keyBy
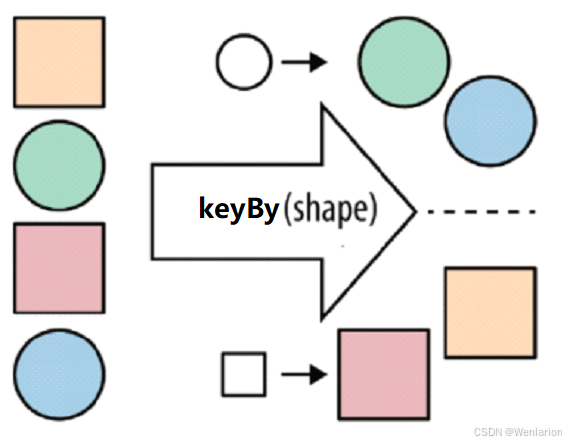
函数说明:
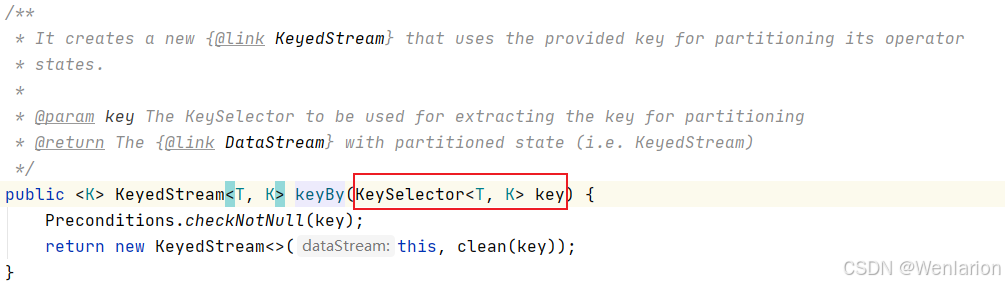
KeySelector对象可以支持元组类型,也可以支持POJO
- 元组类型
- 单个字段keyBy
|
//用字段位置(已经被废弃) |
- 多个字段keyBy
|
//用字段位置 |
|
上述可用lambda简化 |
|
wordAndOne.keyBy( |
2.POJO
|
public class PeopleCount { |
单个字段keyBy
|
source.keyBy(a -> a.getProvince()); |
多个字段keyBy
|
source.keyBy(new KeySelector<PeopleCount, Tuple2<String, String>>() { |
|
上述可用lambda简化 |
|
map.keyBy( |
- 示例
读取socket数据源, 进行单词的计数
- 开发步骤
- 获取流处理运行环境
- 设置并行度
- 获取数据源
- 转换操作
- 以空白进行分割
- 给每个单词计数1
- 根据单词分组
5.求和
6.打印到控制台
7.执行任务
参考代码
参
|
/** |
Reduce
可以对一个 dataset 或者一个 group 来进行聚合计算,最终聚合成一个元素
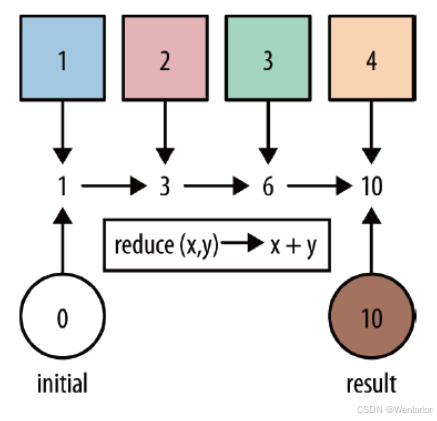
示例
读取apache.log日志,统计ip地址访问pv数量,使用 reduce 操作聚合成一个最终结果
|
86.149.9.216 10001 17/05/2015:10:05:30 GET /presentations/logstash-monitorama-2013/images/github-contributions.png 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:06:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:07:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:08:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:09:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:10:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:16:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css 10.0.0.1 10003 17/05/2015:10:26:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css |
结果类似:
(86.149.9.216,1)
(10.0.0.1,7)
(83.149.9.216,6)
步骤
- 获取 ExecutionEnvironment 运行环境
- 使用 readTextFile 构建数据源
- 使用 reduce 执行聚合操作
- 打印测试
参考代码
|
/** |
minBy和maxBy
获取指定字段的最大值、最小值
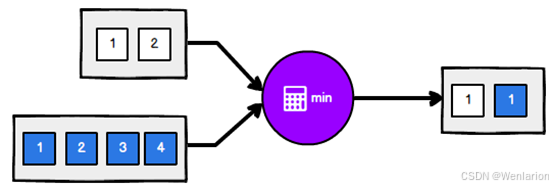
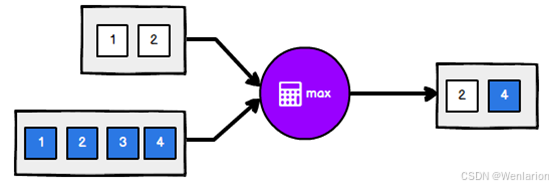
第一种场景
示例
编写Flink程序,接收socket的单词数据,并以逗号进行单词拆分打印。
|
spark,2 |
步骤
- 获取 ExecutionEnvironment 运行环境
- 使用 socketTextStream 构建数据源
- 使用 keyBy 按照单词进行分组
- 使用 maxBy、minBy对每个分组进行操作
- 打印测试
参考代码
|
//分组后,求组内最小值 |
第二种场景
示例
编写Flink程序,接收socket的单词数据,并以逗号进行单词拆分打印。
|
辽宁,沈阳,1000 |
步骤
- 获取 ExecutionEnvironment 运行环境
- 使用 socketTextStream 构建数据源
- 使用 keyBy 按照单词进行分组
- 使用 maxBy、minBy对每个分组进行操作
- 打印测试
参考代码
|
//分组后,求组内最小值 |
min max 和 minBy maxBy的区别
min 和 max 方式 对比minBy 和maxBy的区别在:
以min和minBy举例:
首先: min方法(aggregate方法的简写)只能用于元组, 而minBy可以用于集合数据(DataSet)
另外最重要的区别在于,计算逻辑不同,尽管都是求最小值,但是:
Min在计算的过程中,会记录最小值,对于其它的列,会取最后一次出现的,然后和最小值组合形成结果返回
minBy在计算的过程中,当遇到最小值后,将第一次出现的最小值所在的整个元素返回。
示例代码:
|
/** |
Union
将多个DataSet合并成一个DataSet
【注意】:union合并的DataSet的类型必须是一致的
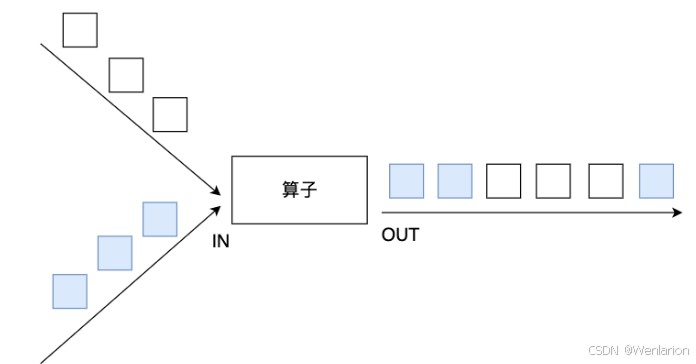
示例
将以下数据进行取并集操作
数据集1
|
"hadoop", "hive", "flume" |
数据集2
|
"hadoop", "hive", "spark" |
步骤
- 构建批处理运行环境
- 使用 fromCollection 创建两个数据源
- 使用 union 将两个数据源关联在一起
- 打印测试
注意:union可以取并集,但是不会去重。
参考代码
|
/** |
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被 Connect 之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立, 作为对比Union后是真的变成一个流了
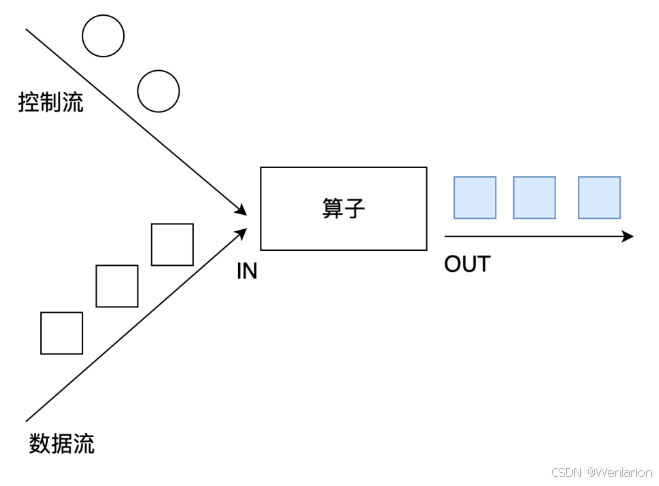
示例
读取两个不同类型的数据源,使用connect进行合并打印。

开发步骤
- 创建流式处理环境
- 添加两个自定义数据源
- 使用connect合并两个数据流,创建ConnectedStreams对象
- 遍历ConnectedStreams对象,转换为DataStream
- 打印输出,设置并行度为1
- 执行任务
参考代码
|
/** |
split、select和Side Outputs

Split就是将一个DataStream分成两个或者多个DataStream
Select就是获取分流后对应的数据
简单认为就是, Split会给数据打上标记
然后通过Select, 选择标记来划分出不同的Stream
效果类似KeyBy分流,但是比KeyBy更自由些,可以自由打标记并进行分流。
注意:split函数已过期并移除
Side Outputs:可以使用process方法对流中数据进行处理,并针对不同的处理结果将数据收集到不同的OutputTag中
示例
对流中的数据按照奇数和偶数进行分流,并获取分流后的数据
开发步骤
- 创建流处理环境
- 设置并行度
- 加载本地集合
- 数据分流,分为奇数和偶数
- 获取分流后的数据
- 打印数据
- 执行任务
参考代码
|
/** |
基本概念:在流中创建“反馈(feedback)”循环,通过将一个算子的输出重定向到某个先前的算子。这对于定义不断更新模型的算法特别有用。
迭代的数据流向:DataStream → IterativeStream → DataStream
参考代码
|
//Iterate迭代流式计算 |
物理分区
Flink 也提供以下方法让用户根据需要在数据转换完成后对数据分区进行更细粒度的配置。
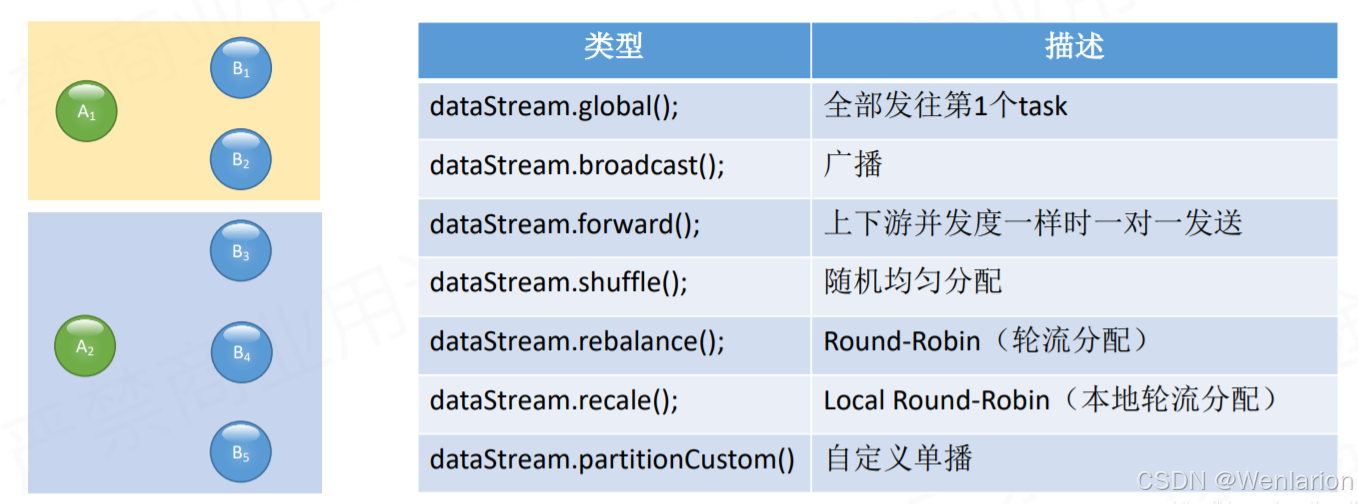
Global Partitioner
该分区器会将所有的数据都发送到下游的某个算子实例(subtask id = 0)
源码解读
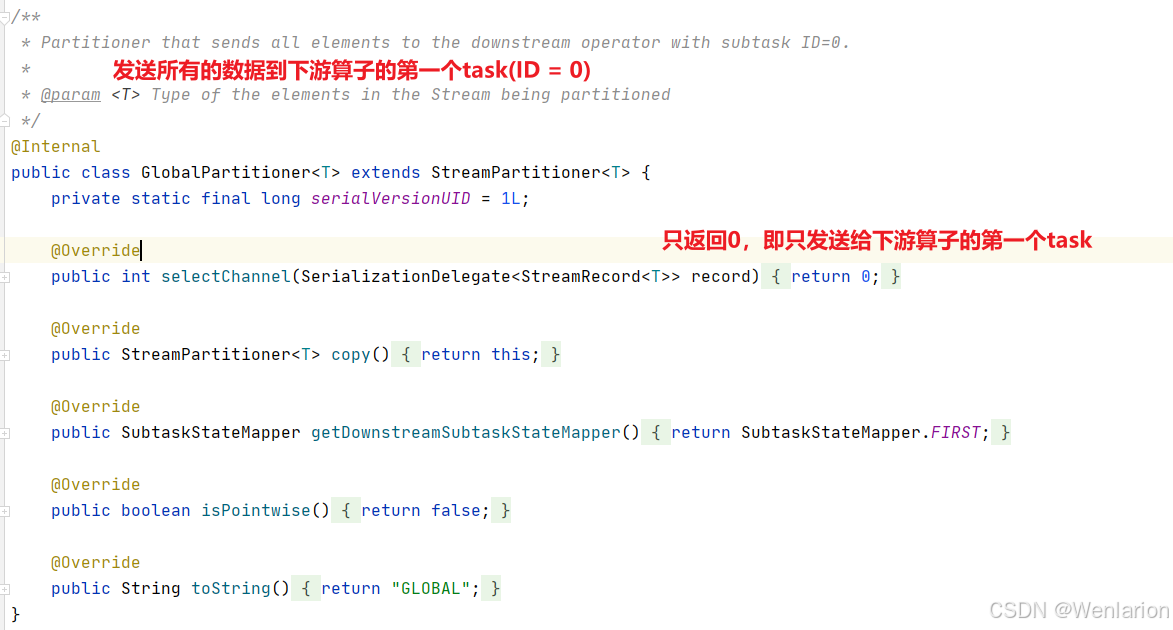
图解
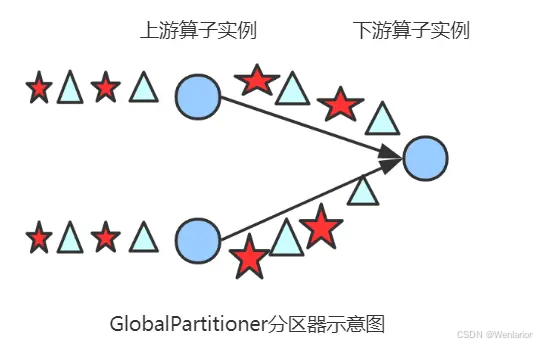
示例:
编写Flink程序,接收socket的单词数据,并将每个字符串均匀的随机划分到每个分区。
示例代码:
|
public class GlobalPartitioningDemo { |
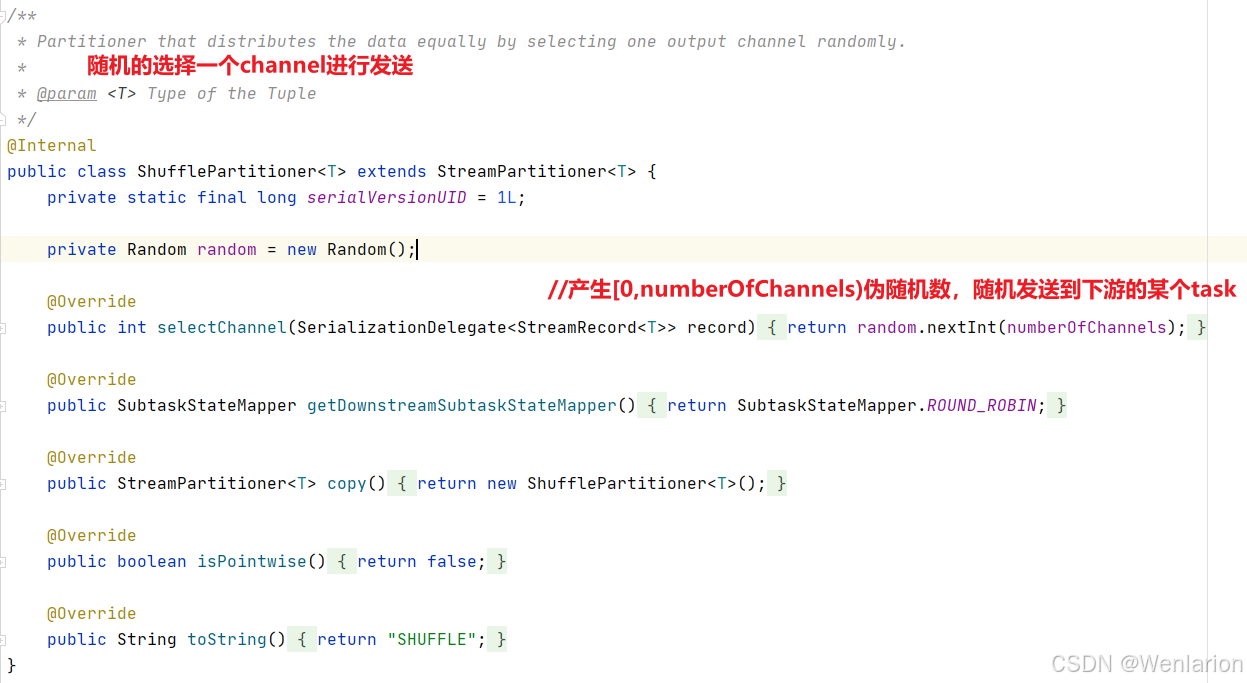
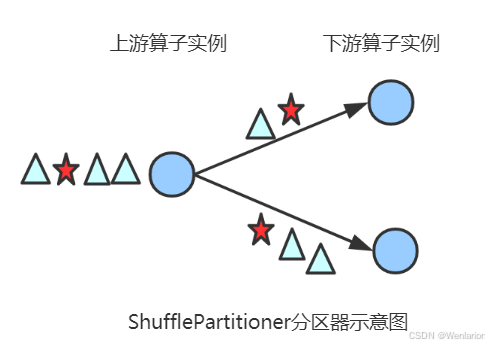
Shuffle Partitioner
根据均匀分布随机划分元素。
源码解读
图解
示例:
编写Flink程序,接收socket的单词数据,并将每个字符串均匀的随机划分到每个分区。
示例代码:
|
public class ShufflePartitioningDemo { |
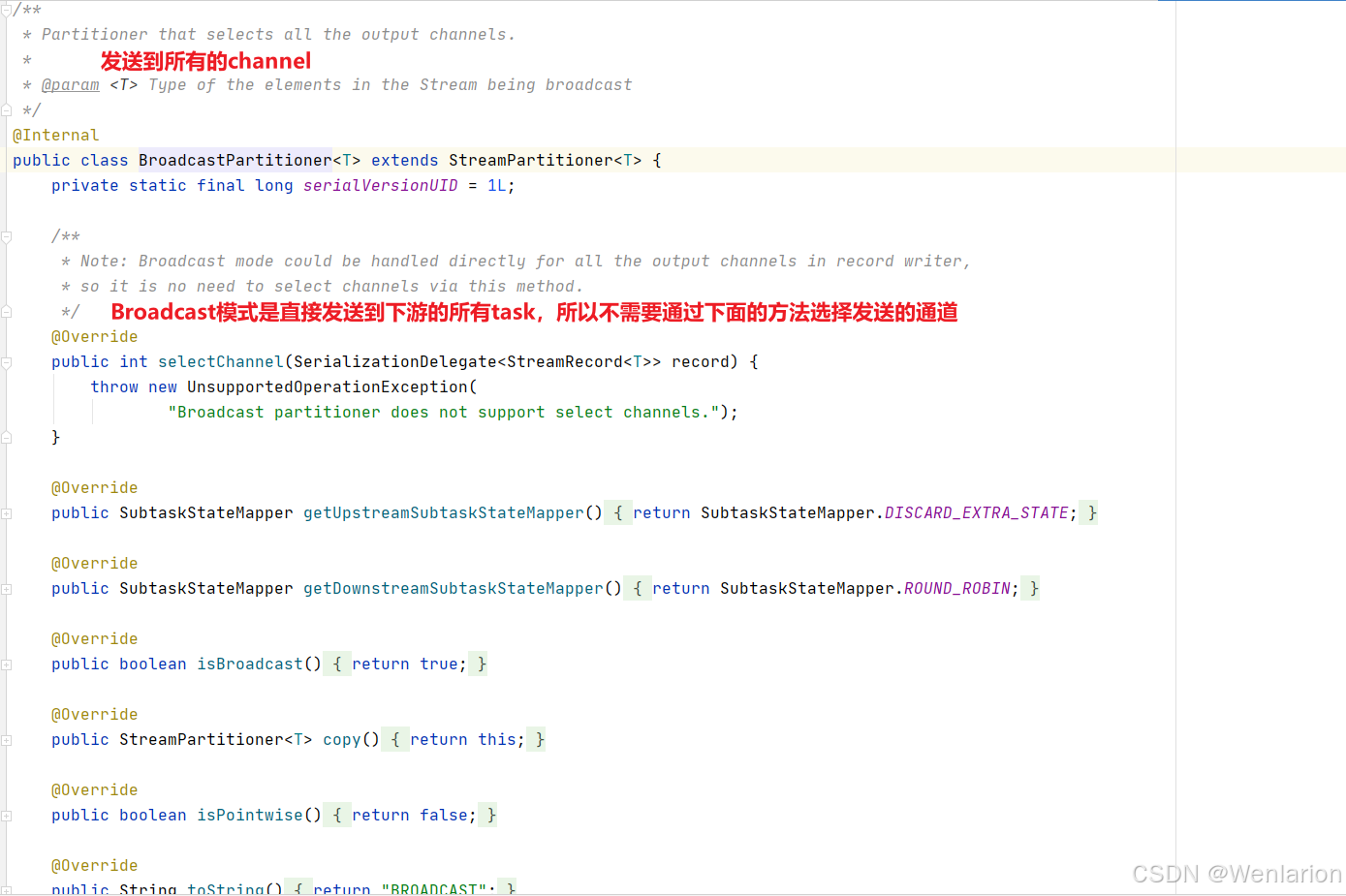
Broadcast Partitioner
发送到下游所有的算子实例
源码解读
图解
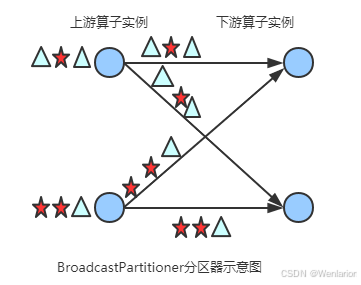
示例:
编写Flink程序,接收socket的单词数据,并将每个字符串广播到每个分区。
示例代码:
|
public class BroadcastPartitioningDemo { |
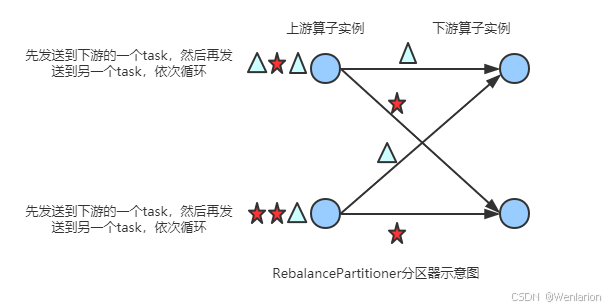
Rebalance Partitioner
通过循环的方式依次发送到下游的task
问题产生背景
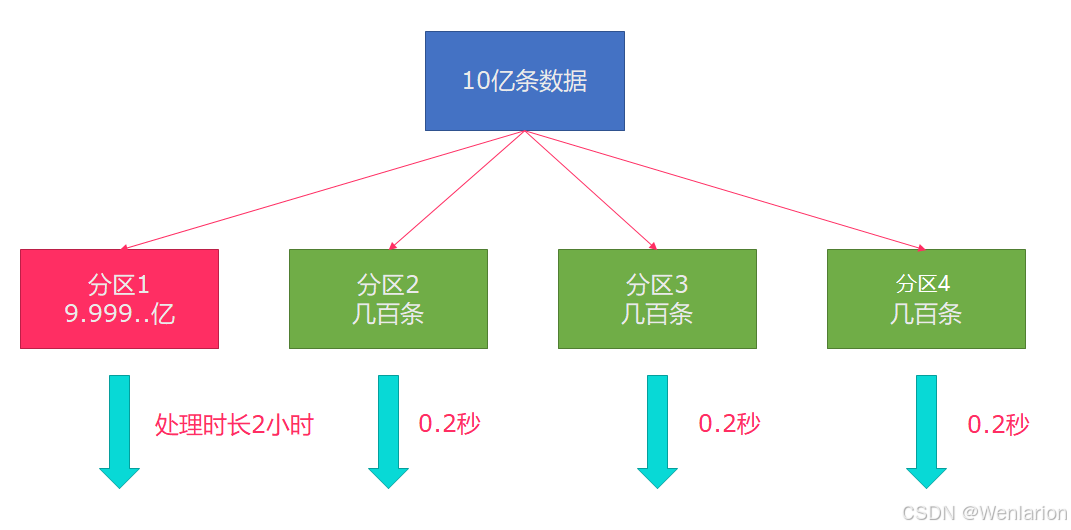
Flink也有数据倾斜的时候,比如当前有数据量大概10亿条数据需要处理,在处理过程中可能会发生如图所示的状况:
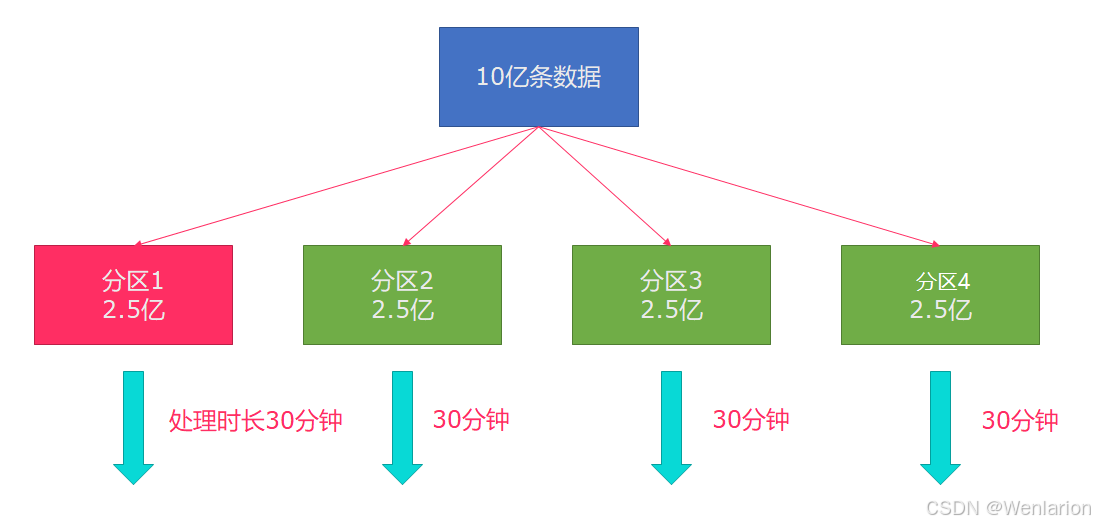
这个时候本来总体数据量只需要10分钟解决的问题,出现了数据倾斜,机器1上的任务需要4个小时才能完成,那么其他3台机器执行完毕也要等待机器1执行完毕后才算整体将任务完成;
所以在实际的工作中,出现这种情况比较好的解决方案就是本节课要讲解的—rebalance
源码解读
图解
步骤
- 构建批处理运行环境
- 使用 env.generateSequence 创建0-100的并行数据
- 使用 fiter 过滤出来 大于8 的数字
- 使用map操作传入 RichMapFunction ,将当前子任务的ID和数字构建成一个元组
- 在RichMapFunction中可以使用 getRuntimeContext.getIndexOfThisSubtask 获取子任务序号
- 打印测试
举例:
在不使用rebalance的情况下,观察每一个线程执行的任务特点
|
/** |
使用rebalance
|
/** |
Rescale Partitioner
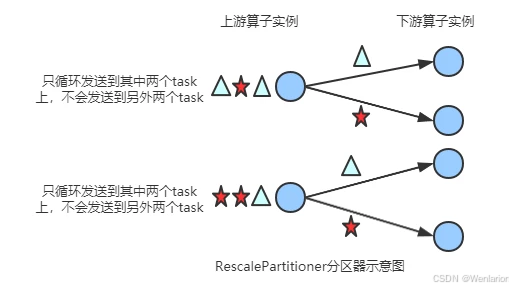
RescalePartitioner,RESCALE分区。基于上下游Operator的并行度,将记录以循环的方式输出到下游Operator的每个实例。举例: 上游并行度是2,下游是4,则上游一个并行度以循环的方式将记录输出到下游的两个并行度上;上游另一个并行度以循环的方式将记录输出到下游另两个并行度上。若上游并行度是4,下游并行度是2,则上游两个并行度将记录输出到下游一个并行度上;上游另两个并行度将记录输出到下游另一个并行度上。
源码解读

这个看起来也太简单了,并且与RebalancePartitioner的逻辑是相同的?实际上并不是。
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
而StreamingJobGraphGenerator就是StreamGraph转换为JobGraph。在这个类中,把ForwardPartitioner和RescalePartitioner列为POINTWISE分配模式,其他的为ALL_TO_ALL分配模式。代码如下:

粗略地讲,如果分区逻辑是RescalePartitioner或ForwardPartitioner(下面会说),那么采用POINTWISE模式来连接上下游的顶点,对于其他分区逻辑,都用ALL_TO_ALL模式来连接。看下面两张图会比较容易理解。
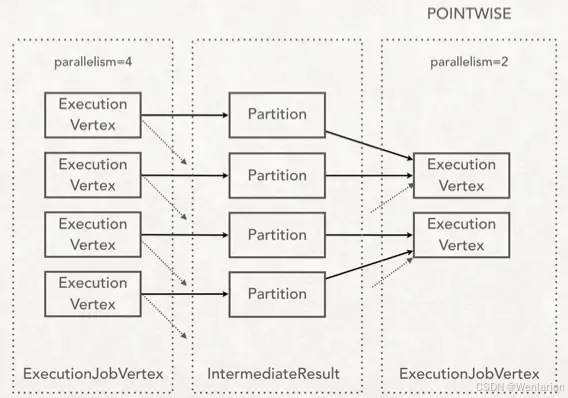
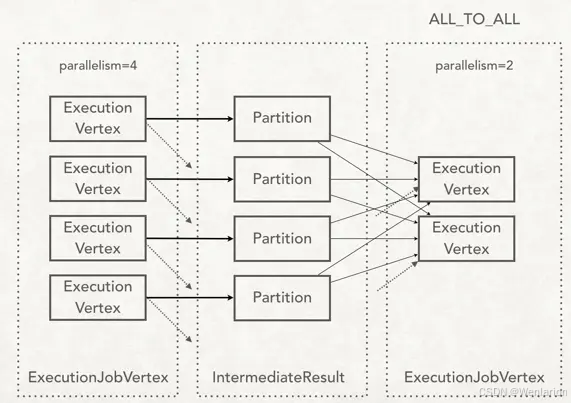
也就是说,POINTWISE模式的RescalePartitioner在中间结果传送给下游节点时,会根据并行度的比值来轮询分配给下游算子实例的子集,对TaskManager来说本地性会比较好。而ALL_TO_ALL模式的RebalancePartitioner是真正的全局轮询分配,更加均衡,但是就会不可避免地在节点之间交换数据,如果数据量大的话,造成的网络流量会很可观。
图解
示例:
编写Flink程序,接收socket的单词数据,并将每个字符串广播到每个分区。
示例代码:
|
public class RescalePartitioningDemo { |
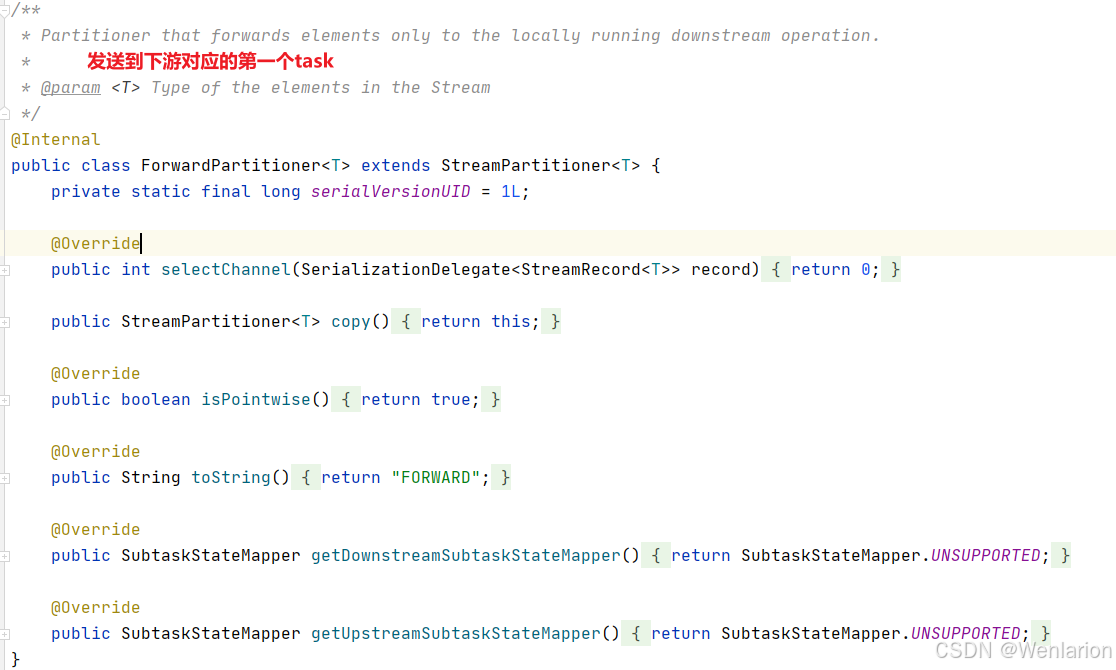
Forward Partitioner
发送到下游对应的第一个task,保证上下游算子并行度一致,即上有算子与下游算子是1:1的关系
源码解读
图解
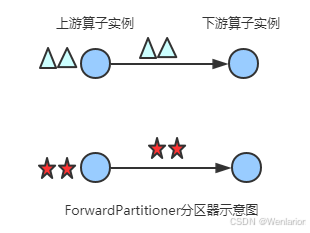
在上下游的算子没有指定分区器的情况下,如果上下游的算子并行度一致,则使用ForwardPartitioner,否则使用RebalancePartitioner,对于ForwardPartitioner,必须保证上下游算子并行度一致,否则会抛出异常
示例:
编写Flink程序,接收socket的单词数据,并将每个字符串广播到每个分区。
示例代码:
|
public class ForwardPartitioningDemo { |
Custom Partitioning
使用用户定义的 Partitioner 为每个元素选择目标任务。
示例:
编写Flink程序,接收socket的单词数据,并将每个字符串写入到指定的分区中。
|
hadoop spark flink |
示例代码:
|
public class CustomPartitioningDemo { |
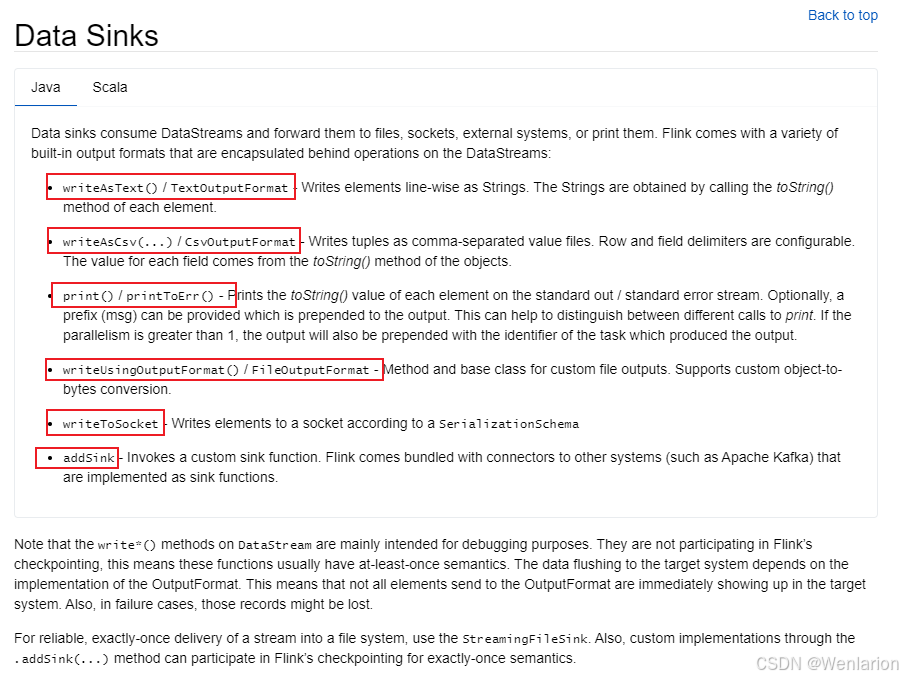
数据输出Data Sinks
经过一系列Transformation转换操作后,最后一定要调用Sink操作,才会形成一个完整的DataFlow拓扑。只有调用了Sink操作,才会产生最终的计算结果,这些数据可以写入到的文件、输出到指定的网络端口、消息中间件、外部的文件系统或者是打印到控制台。
flink在批处理中常见的sink
- print 打印
- writerAsText 以文本格式输出
- writeAsCsv 以csv格式输出
- writeUsingOutputFormat 以指定的格式输出
- writeToSocket 输出到网络端口
- 自定义连接器(addSink)
print 打印
打印是最简单的一个Sink,通常是用来做实验和测试时使用。如果想让一个DataStream输出打印的结果,直接可以在该DataStream调用print方法。另外,该方法还有一个重载的方法,可以传入一个字符,指定一个Sink的标识名称,如果有多个打印的Sink,用来区分到底是哪一个Sink的输出。
|
public class PrintSinkDemo { |
下面的结果是WordCount例子中调用print Sink输出在控制台的结果,细心的读者会发现,在输出的单词和次数之前,有一个数字前缀,我这里是1~4,这个数字是该Sink所在subtask的Index + 1。有的读者运行的结果数字前缀是1~8,该数字前缀其实是与任务的并行度相关的,由于该任务是以local模式运行,默认的并行度是所在机器可用的逻辑核数即线程数,我的电脑是2核4线程的,所以subtask的Index范围是0~3,将Index + 1,显示的数字前缀就是1~4了。这里在来仔细的观察一下运行的结果发现:相同的单词输出结果的数字前缀一定相同,即经过keyBy之后,相同的单词会被shuffle到同一个subtask中,并且在同一个subtask的同一个组内进行聚合。一个subtask中是可能有零到多个组的,如果是有多个组,每一个组是相互独立的,累加的结果不会相互干扰。
writerAsText 以文本格式输出
该方法是将数据以文本格式实时的写入到指定的目录中,本质上使用的是TextOutputFormat格式写入的。每输出一个元素,在该内容后面同时追加一个换行符,最终以字符的形式写入到文件中,目录中的文件名称是该Sink所在subtask的Index + 1。该方法还有一个重载的方法,可以额外指定一个枚举类型的参数writeMode,默认是WriteMode.NO_OVERWRITE,如果指定相同输出目录下有相同的名称文件存在,就会出现异常。如果是WriteMode.OVERWRITE,会将以前的文件覆盖。
|
public class WriteSinkDemo { |
writeAsCsv 以csv格式输出
该方法是将数据以csv格式写入到指定的目录中,本质上使用的是CsvOutputFormat格式写入的。每输出一个元素,在该内容后面同时追加一个换行符,最终以csv的形式(类似Excel的格式,字段和字段之间用逗号分隔)写入到文件中,目录中的文件名称是该Sink所在subtask的Index + 1。需要说明的是,该Sink并不是将数据实时的写入到文件中,而是有一个BufferedOutputStream,默认缓存的大小为4096个字节,只有达到这个大小,才会flush到磁盘。另外程序在正常退出,调用Sink的close方法也会flush到磁盘。
|
/** |
writeUsingOutputFormat 以指定的格式输出
该方法是将数据已指定的格式写入到指定目录中,该方法要传入一个OutputFormat接口的实现类,该接口有很多已经实现好了的实现类,并且可以根据需求自己实现,所以该方法更加灵活。writeAsText和writeAsCsv方法底层都是调用了writeUsingOutputFormat方法。
|
public class writeUsingOutputFormatSink { |
writeToSocket 输出到网络端口
该方法是将数据输出到指定的Socket网络地址端口。该方法需要传入三个参数:第一个为ip地址或主机名,第二个为端口号,第三个为数据输出的序列化格式SerializationSchema。输出之前,指定的网络端口服务必须已经启动。
|
public class WriteToSocketDemo { |
基于本地集合的sink
示例:
|
基于下列数据,分别 进行打印输出,error输出 |
|
(19, "zhangsan", 178.8), (17, "lisi", 168.8), (18, "wangwu", 184.8), (21, "zhaoliu", 164.8) |
目标:
数据可以输出到:Stdout,Stderr,采集为本地集合
代码:
|
/** |
Connectors
JDBC Connector
该连接器可以向 JDBC 数据库写入数据。
依赖
添加下面的依赖以便使用该连接器(同时添加 JDBC 驱动):
|
<dependency> |
案例演示
需求
从指定的socket读取数据,对单词进行计算,最后将结果写入到MySQL
Mysql创建表
|
CREATE TABLE `t_wordcount` ( |
参考代码
|
/** |
Apache Kafka Connector
在现实生产环境中,为了保证Flink可以高效地读取数据源中的数据,通常是跟一些分布式消息中件结合使用,例如Apache Kafka。Kafka的特点是分布式、多副本、高可用、高吞吐、可以记录偏移量等。Flink和Kafka整合可以高效的读取数据,并且可以保证Exactly Once(精确一次性语义)
依赖
Apache Flink 集成了通用的 Kafka 连接器,它会尽力与 Kafka client 的最新版本保持同步。该连接器使用的 Kafka client 版本可能会在 Flink 版本之间发生变化。 当前 Kafka client 向后兼容 0.10.0 或更高版本的 Kafka broker。 有关 Kafka 兼容性的更多细节,请参考 Kafka 官方文档。
|
<dependency> |
Kafka Consumer
Flink 的 Kafka consumer 称为 FlinkKafkaConsumer。它提供对一个或多个 Kafka topics 的访问。
构造函数接受以下参数:
- Topic 名称或者名称列表
- 用于反序列化 Kafka 数据的 DeserializationSchema 或者 KafkaDeserializationSchema
- Kafka 消费者的属性。需要以下属性:
- “bootstrap.servers”(以逗号分隔的 Kafka broker 列表)
- “group.id” 消费组 ID

DeserializationSchema
Flink Kafka Consumer 需要知道如何将 Kafka 中的二进制数据转换为 Java 或者 Scala 对象。KafkaDeserializationSchema 允许用户指定这样的 schema,每条 Kafka 中的消息会调用 T deserialize(ConsumerRecord<byte[], byte[]> record) 反序列化。
为了方便使用,Flink 提供了以下几种 schemas:
- SimpleStringSchema:按照字符串方式序列化、反序列化
- TypeInformationSerializationSchema(和 TypeInformationKeyValueSerializationSchema) 基于 Flink 的 TypeInformation 创建 schema。 如果该数据的读和写都发生在 Flink 中,那么这将是非常有用的。此 schema 是其他通用序列化方法的高性能 Flink 替代方案。
- JsonDeserializationSchema(和 JSONKeyValueDeserializationSchema)将序列化的 JSON 转化为 ObjectNode 对象,可以使用 objectNode.get("field").as(Int/String/...)() 来访问某个字段。 KeyValue objectNode 包含一个含所有字段的 key 和 values 字段,以及一个可选的"metadata"字段,可以访问到消息的 offset、partition、topic 等信息。
- AvroDeserializationSchema 使用静态提供的 schema 读取 Avro 格式的序列化数据。 它能够从 Avro 生成的类(AvroDeserializationSchema.forSpecific(...))中推断出 schema,或者可以与 GenericRecords 一起使用手动提供的 schema(用 AvroDeserializationSchema.forGeneric(...))。此反序列化 schema 要求序列化记录不能包含嵌入式架构!
要使用此反序列化 schema 必须添加以下依赖:
|
<dependency> |
配置 Kafka Consumer 开始消费的位置
Flink Kafka Consumer 允许通过配置来确定 Kafka 分区的起始位置。
|
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
Flink Kafka Consumer 的所有版本都具有上述明确的起始位置配置方法。
- setStartFromGroupOffsets(默认方法):从 Kafka brokers 中的 consumer 组(consumer 属性中的 group.id 设置)提交的偏移量中开始读取分区。 如果找不到分区的偏移量,那么将会使用配置中的 auto.offset.reset 设置。
- setStartFromEarliest() 或者 setStartFromLatest():从最早或者最新的记录开始消费,在这些模式下,Kafka 中的 committed offset 将被忽略,不会用作起始位置。
- setStartFromTimestamp(long):从指定的时间戳开始。对于每个分区,其时间戳大于或等于指定时间戳的记录将用作起始位置。如果一个分区的最新记录早于指定的时间戳,则只从最新记录读取该分区数据。在这种模式下,Kafka 中的已提交 offset 将被忽略,不会用作起始位置。
- setStartFromSpecificOffsets:从指定的分区的offset位置开始读取,如指定的offsets中不存在某个分区,该分区从group offset位置开始读取
例子如下:为每个分区指定 consumer 应该开始消费的具体 offset:
|
Map<KafkaTopicPartition, Long> specificStartOffsets = new HashMap<>(); |
上面的例子中使用的配置是指定从 myTopic 主题的 0 、1 和 2 分区的指定偏移量开始消费。offset 值是 consumer 应该为每个分区读取的下一条消息。
请注意:如果 consumer 需要读取在提供的 offset 映射中没有指定 offset 的分区,那么它将回退到该特定分区的默认组偏移行为(即 setStartFromGroupOffsets())。
请注意:当 Job 从故障中自动恢复或使用 savepoint 手动恢复时,这些起始位置配置方法不会影响消费的起始位置。在恢复时,每个 Kafka 分区的起始位置由存储在 savepoint 或 checkpoint 中的 offset 确定(有关 checkpointing 的信息,请参阅下一节,以便为 consumer 启用容错功能)。
Kafka Consumer 和容错
伴随着启用 Flink 的 checkpointing 后,Flink Kafka Consumer 将使用 topic 中的记录,并以一致的方式定期检查其所有 Kafka offset 和其他算子的状态。如果 Job 失败,Flink 会将流式程序恢复到最新 checkpoint 的状态,并从存储在 checkpoint 中的 offset 开始重新消费 Kafka 中的消息。
因此,设置 checkpoint 的间隔定义了程序在发生故障时最多需要返回多少。
为了使 Kafka Consumer 支持容错,需要在 执行环境 中启用拓扑的 checkpointing。
如果未启用 checkpoint,那么 Kafka consumer 将定期向 Zookeeper 提交 offse
Kafka Consumer Topic 和分区发现
- 分区发现
Flink Kafka Consumer 支持发现动态创建的 Kafka 分区,并使用精准一次的语义保证去消耗它们。在初始检索分区元数据之后(即,当 Job 开始运行时)发现的所有分区将从最早可能的 offset 中消费。
默认情况下,是禁用了分区发现的。若要启用它,请在提供的属性配置中为 flink.partition-discovery.interval-millis 设置大于 0 的值,表示发现分区的间隔是以毫秒为单位的。
- Topic 发现
在更高的级别上,Flink Kafka Consumer 还能够使用正则表达式基于 Topic 名称的模式匹配来发现 Topic。请看下面的例子:
|
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
在上面的例子中,当 Job 开始运行时,Consumer 将订阅名称与指定正则表达式匹配的所有主题(以 test-topic 开头并以单个数字结尾)。
要允许 consumer 在作业开始运行后发现动态创建的主题,那么请为 flink.partition-discovery.interval-millis 设置非负值。这允许 consumer 发现名称与指定模式匹配的新主题的分区。
实际的生产环境中可能有这样一些需求,比如:
- 场景一:有一个 Flink 作业需要将五份数据聚合到一起,五份数据对应五个 kafka topic,随着业务增长,新增一类数据,同时新增了一个 kafka topic,如何在不重启作业的情况下作业自动感知新的 topic。
- 场景二:作业从一个固定的 kafka topic 读数据,开始该 topic 有 10 个 partition,但随着业务的增长数据量变大,需要对 kafka partition 个数进行扩容,由 10 个扩容到 20。该情况下如何在不重启作业情况下动态感知新扩容的 partition?
针对上面的两种场景,首先需要在构建 FlinkKafkaConsumer 时的 properties 中设置 flink.partition-discovery.interval-millis 参数为非负值,表示开启动态发现的开关,以及设置的时间间隔。此时 FlinkKafkaConsumer 内部会启动一个单独的线程定期去 kafka 获取最新的 meta 信息。
- 针对场景一,还需在构建 FlinkKafkaConsumer 时,topic 的描述可以传一个正则表达式描述的 pattern。每次获取最新 kafka meta 时获取正则匹配的最新 topic 列表。
- 针对场景二,设置前面的动态发现参数,在定期获取 kafka 最新 meta 信息时会匹配新的 partition。为了保证数据的正确性,新发现的 partition 从最早的位置开始读取。
Kafka Consumer 提交 Offset 的行为配置
Flink Kafka Consumer 允许有配置如何将 offset 提交回 Kafka broker 的行为。请注意:Flink Kafka Consumer 不依赖于提交的 offset 来实现容错保证。提交的 offset 只是一种方法,用于公开 consumer 的进度以便进行监控。
配置 offset 提交行为的方法是否相同,取决于是否为 job 启用了 checkpointing。
- 禁用 Checkpointing: 如果禁用了 checkpointing,则 Flink Kafka Consumer 依赖于内部使用的 Kafka client 自动定期 offset 提交功能。 因此,要禁用或启用 offset 的提交,只需将 enable.auto.commit 或者 auto.commit.interval.ms 的Key 值设置为提供的 Properties 配置中的适当值。
- 启用 Checkpointing: 如果启用了 checkpointing,那么当 checkpointing 完成时,Flink Kafka Consumer 将提交的 offset 存储在 checkpoint 状态中。 这确保 Kafka broker 中提交的 offset 与 checkpoint 状态中的 offset 一致。 用户可以通过调用 consumer 上的 setCommitOffsetsOnCheckpoints(boolean) 方法来禁用或启用 offset 的提交(默认情况下,这个值是 true )。 注意,在这个场景中,Properties 中的自动定期 offset 提交设置会被完全忽略。
Kafka Producer
Flink Kafka Producer 被称为 FlinkKafkaProducer。它允许将消息流写入一个或多个 Kafka topic。
构造器接收下列参数:
- 事件被写入的默认输出 topic
- 序列化数据写入 Kafka 的 SerializationSchema / KafkaSerializationSchema
- Kafka client 的 Properties。下列 property 是必须的:
“bootstrap.servers” (逗号分隔 Kafka broker 列表)
- 容错语义
|
DataStream<String> stream = ...; |
SerializationSchema
Flink Kafka Producer 需要知道如何将 Java/Scala 对象转化为二进制数据。
KafkaSerializationSchema 允许用户指定这样的 schema。它会为每个记录调用 ProducerRecord<byte[], byte[]> serialize(T element, @Nullable Long timestamp) 方法,产生一个写入到 Kafka 的 ProducerRecord。
用户可以对如何将数据写到 Kafka 进行细粒度的控制。你可以通过 producer record:
- 设置 header 值
- 为每个 record 定义 key
- 指定数据的自定义分区
Kafka Producer 和容错
启用 Flink 的 checkpointing 后,FlinkKafkaProducer 可以提供精确一次的语义保证。
除了启用 Flink 的 checkpointing,你也可以通过将适当的 semantic 参数传递给 FlinkKafkaProducer 来选择三种不同的操作模式:
- Semantic.NONE:Flink 不会有任何语义的保证,产生的记录可能会丢失或重复。
- Semantic.AT_LEAST_ONCE(默认设置):可以保证不会丢失任何记录(但是记录可能会重复)
- Semantic.EXACTLY_ONCE:使用 Kafka 事务提供精确一次语义。无论何时,在使用事务写入 Kafka 时,都要记得为所有消费 Kafka 消息的应用程序设置所需的 isolation.level(read_committed 或 read_uncommitted - 后者是默认值)。
注意事项
Semantic.EXACTLY_ONCE 模式依赖于事务提交的能力。事务提交发生于触发 checkpoint 之前,以及从 checkpoint 恢复之后。如果从 Flink 应用程序崩溃到完全重启的时间超过了 Kafka 的事务超时时间,那么将会有数据丢失(Kafka 会自动丢弃超出超时时间的事务)。考虑到这一点,请根据预期的宕机时间来合理地配置事务超时时间。
默认情况下,Kafka broker 将 transaction.max.timeout.ms 设置为 15 分钟。此属性不允许为大于其值的 producer 设置事务超时时间。 默认情况下,FlinkKafkaProducer 将 producer config 中的 transaction.timeout.ms 属性设置为 1 小时,因此在使用 Semantic.EXACTLY_ONCE 模式之前应该增加 transaction.max.timeout.ms 的值。
在 KafkaConsumer 的 read_committed 模式中,任何未结束(既未中止也未完成)的事务将阻塞来自给定 Kafka topic 的未结束事务之后的所有读取数据。 换句话说,在遵循如下一系列事件之后:
- 用户启动了 transaction1 并使用它写了一些记录
- 用户启动了 transaction2 并使用它编写了一些其他记录
- 用户提交了 transaction2
即使 transaction2 中的记录已提交,在提交或中止 transaction1 之前,消费者也不会看到这些记录。这有 2 层含义:
- 首先,在 Flink 应用程序的正常工作期间,用户可以预料 Kafka 主题中生成的记录的可见性会延迟,相当于已完成 checkpoint 之间的平均时间。
- 其次,在 Flink 应用程序失败的情况下,此应用程序正在写入的供消费者读取的主题将被阻塞,直到应用程序重新启动或配置的事务超时时间过去后,才恢复正常。此标注仅适用于有多个 agent 或者应用程序写入同一 Kafka 主题的情况。
注意:Semantic.EXACTLY_ONCE 模式为每个 FlinkKafkaProducer 实例使用固定大小的 KafkaProducer 池。每个 checkpoint 使用其中一个 producer。如果并发 checkpoint 的数量超过池的大小,FlinkKafkaProducer 将抛出异常,并导致整个应用程序失败。请合理地配置最大池大小和最大并发 checkpoint 数量。
注意:Semantic.EXACTLY_ONCE 会尽一切可能不留下任何逗留的事务,否则会阻塞其他消费者从这个 Kafka topic 中读取数据。但是,如果 Flink 应用程序在第一次 checkpoint 之前就失败了,那么在重新启动此类应用程序后,系统中不会有先前池大小(pool size)相关的信息。因此,在第一次 checkpoint 完成前对 Flink 应用程序进行缩容,且并发数缩容倍数大于安全系数 FlinkKafkaProducer.SAFE_SCALE_DOWN_FACTOR 的值的话,是不安全的。
-
-
-
- 代码实现-Kafka Consumer
-
-
|
/** |
代码实现-Kafka Producer
- 需求:
将Flink集合中的数据通过自定义Sink保存到Kafka
- 代码实现
|
/** |
Redis
API
该方法是将数据输出到Redis数据库中,Redis是一个基于内存、性能极高的NoSQL数据库,数据还可以持久化到磁盘,读写速度快,适合存储key-value类型的数据。Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。Flink实时计算出的结果,需要快速的输出存储起来,要求写入的存储系统的速度要快,这个才不会造成数据积压。Redis就是一个非常不错的选择。
https://bahir.apache.org/docs/flink/current/flink-streaming-redis/
RedisSink 核心类是RedisMapper 是一个接口,使用时我们要编写自己的redis 操作类实现这个接口中的三个方法,如下所示
1.getCommandDescription() :
设置使用的redis 数据结构类型,和key 的名称,通过RedisCommand 设置数据结构类型
2.String getKeyFromData(T data):
设置value 中的键值对key的值
3.String getValueFromData(T data);
设置value 中的键值对value的值
使用RedisCommand设置数据结构类型时和redis结构对应关系
|
Data Type |
Redis Command [Sink] |
|
HASH |
HSET |
|
LIST |
RPUSH, LPUSH |
|
SET |
SADD |
|
PUBSUB |
PUBLISH |
|
STRING |
SET |
|
HYPER_LOG_LOG |
PFADD |
|
SORTED_SET |
ZADD |
|
SORTED_SET |
ZREM |
需求
从指定的socket读取数据,对单词进行计算,将结果写入到Redis中
代码实现
|
/** |
扩展阅读:其他批处理API
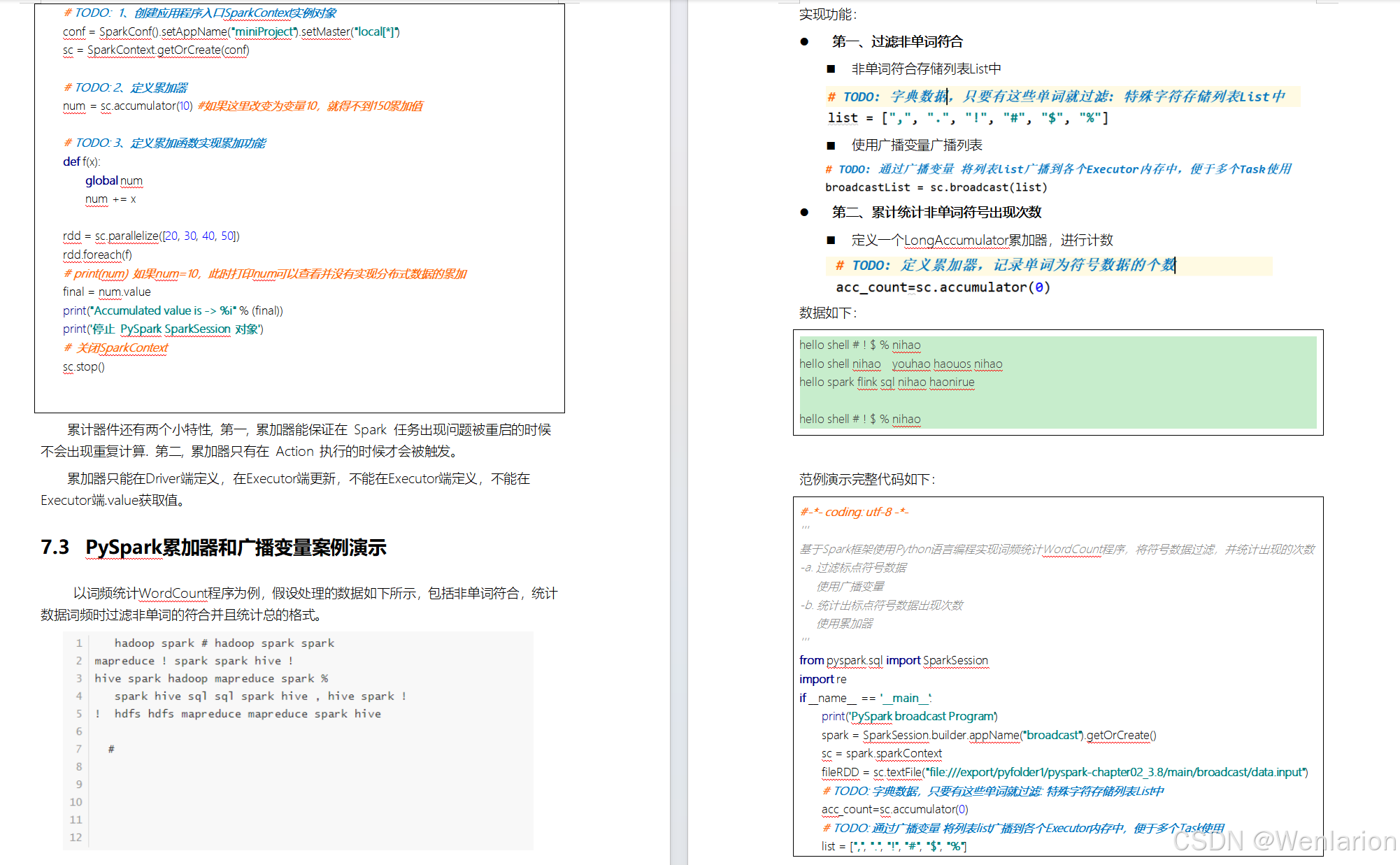
Flink的广播变量
Flink支持广播变量,就是将数据广播到具体的taskmanager上,数据存储在内存中,这样可以减缓大量的shuffle操作;
比如在数据join阶段,不可避免的就是大量的shuffle操作,我们可以把其中一个dataSet广播出去,一直加载到taskManager的内存中,可以直接在内存中拿数据,避免了大量的shuffle,导致集群性能下降;
广播变量创建后,它可以运行在集群中的任何function上,而不需要多次传递给集群节点。另外需要记住,不应该修改广播变量,这样才能确保每个节点获取到的值都是一致的。
一句话解释,可以理解为是一个公共的共享变量,我们可以把一个dataset 数据集广播出去,然后不同的task在节点上都能够获取到,这个数据在每个节点上只会存在一份。如果不使用broadcast,则在每个节点中的每个task中都需要拷贝一份dataset数据集,比较浪费内存(也就是一个节点中可能会存在多份dataset数据)。
注意:因为广播变量是要把dataset广播到TaskManager节点内存中,所以广播的数据量不能太大,否则会出现OOM这样的问题
- Broadcast:Broadcast是通过withBroadcastSet(dataset,string)来注册的
- Access:通过getRuntimeContext().getBroadcastVariable(String)访问广播变量
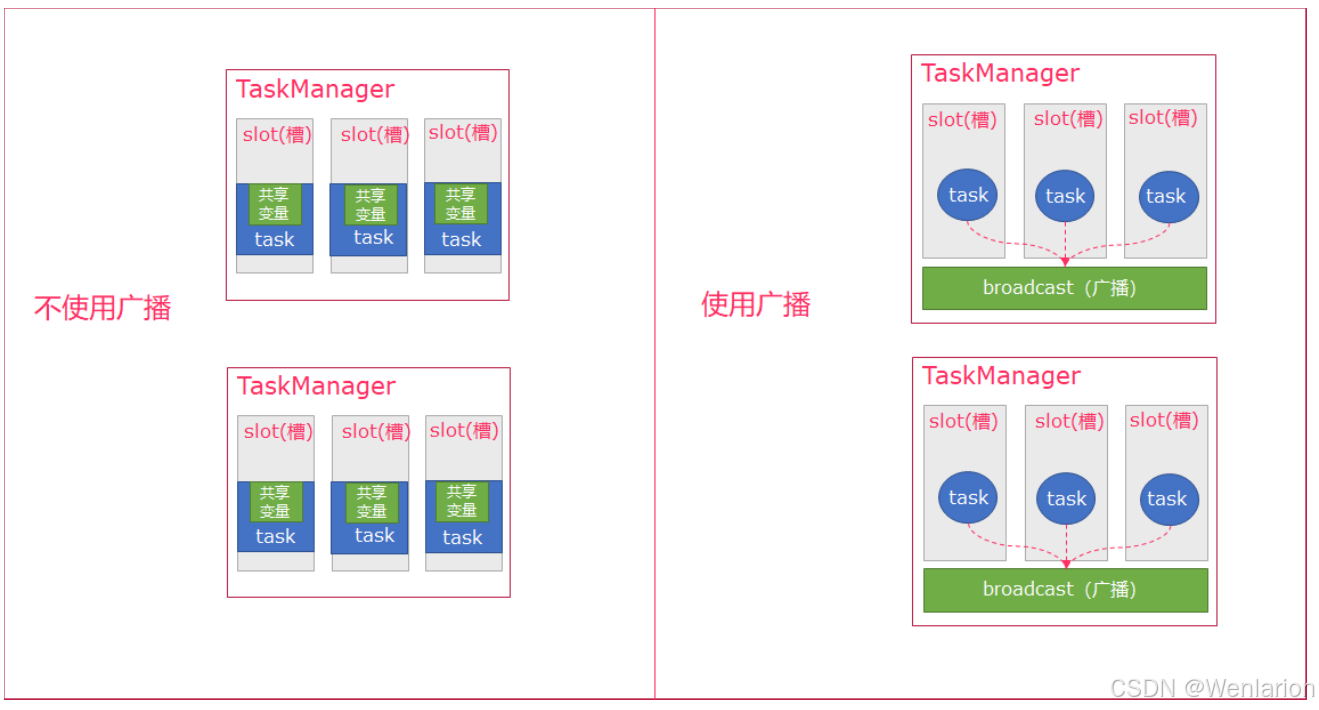
- 可以理解广播就是一个公共的共享变量
- 将一个数据集广播后,不同的Task都可以在节点上获取到
- 每个节点 只存一份
- 如果不使用广播,每一个Task都会拷贝一份数据集,造成内存资源浪费
用法
在需要使用广播的操作后,使用 withBroadcastSet 创建广播
在操作中,使用getRuntimeContext.getBroadcastVariable [广播数据类型] ( 广播名 )获取广播变量
示例
创建一个 学生 数据集,包含以下数据
|
|学生ID | 姓名 | |------|------| List((1, "张三"), (2, "李四"), (3, "王五")) |
将该数据,发布到广播。
再创建一个 成绩 数据集,
|
|学生ID | 学科 | 成绩 | |------|------|-----| List( (1, "语文", 50),(2, "数学", 70), (3, "英文", 86)) |
请通过广播获取到学生姓名,将数据转换为
|
List( ("张三", "语文", 50),("李四", "数学", 70), ("王五", "英文", 86)) |
步骤
获取批处理运行环境
分别创建两个数据集
使用 RichMapFunction 对 成绩 数据集进行map转换
在数据集调用 map 方法后,调用 withBroadcastSet 将 学生 数据集创建广播
实现 RichMapFunction
- 将成绩数据(学生ID,学科,成绩) -> (学生姓名,学科,成绩)
- 重写 open 方法中,获取广播数据
- 在 map 方法中使用广播进行转换
打印测试
参考代码
|
/** |
Flink Accumulators & Counters
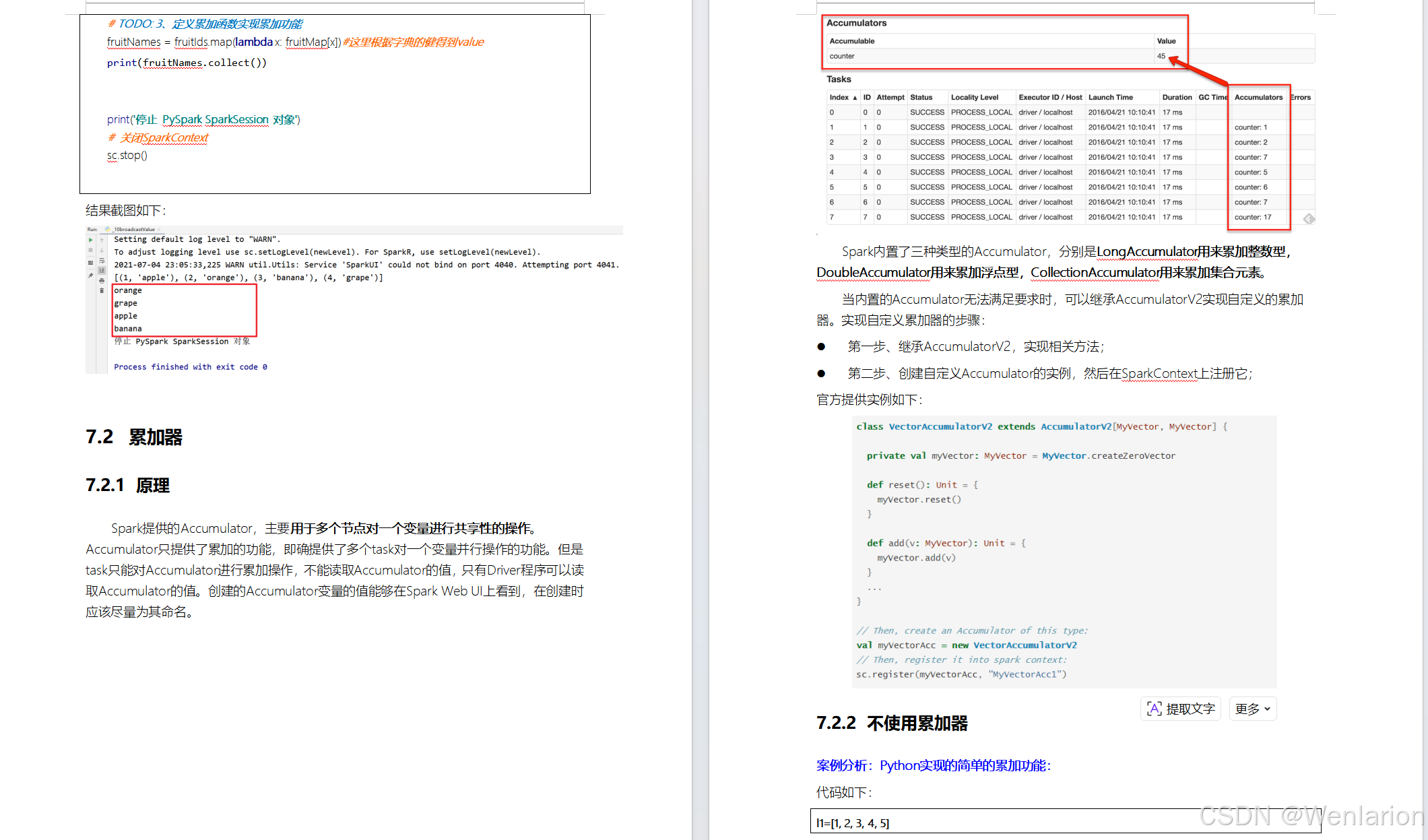
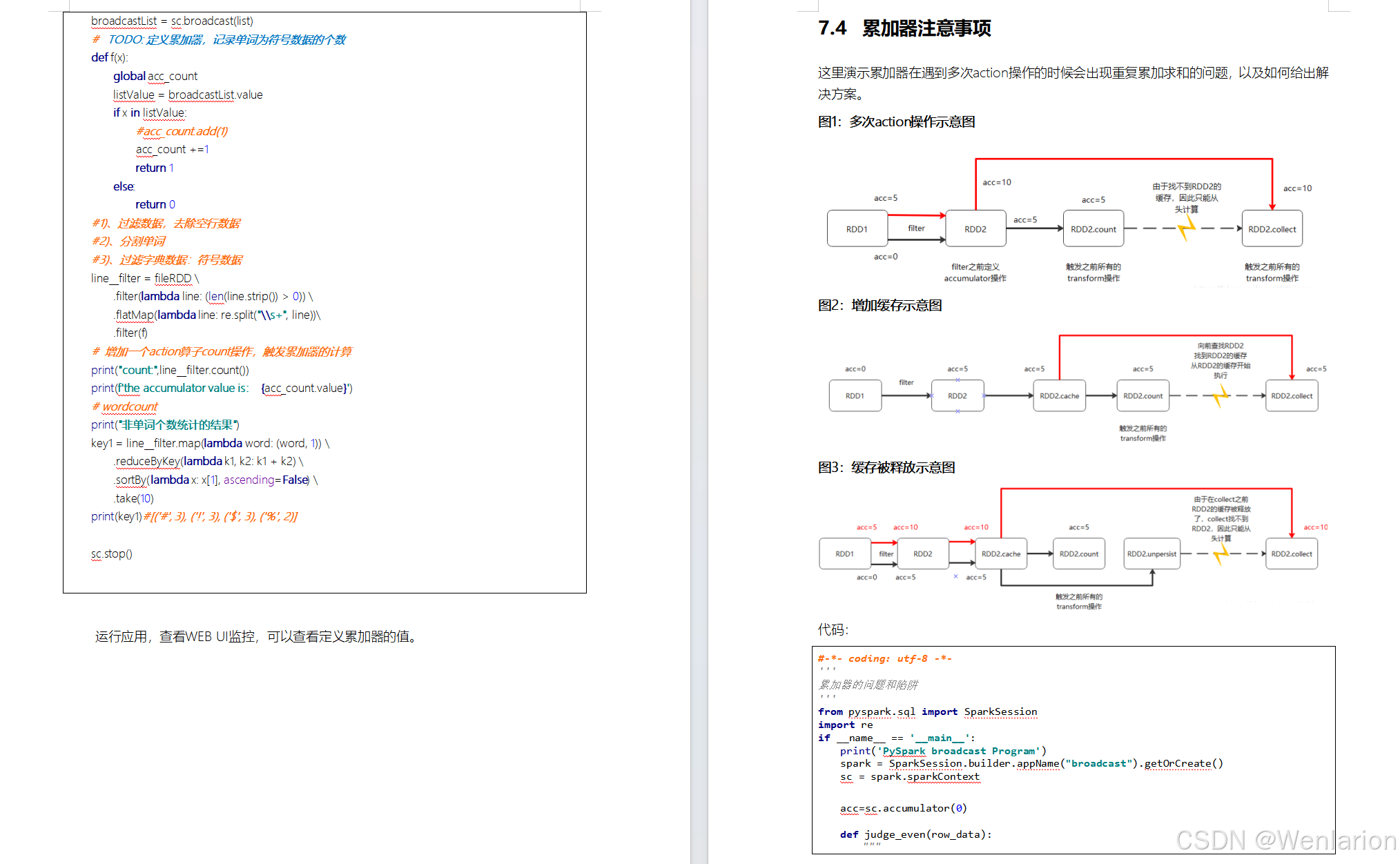
Accumulator即累加器,与Mapreduce counter的应用场景差不多,都能很好地观察task在运行期间的数据变化
可以在Flink job任务中的算子函数中操作累加器,但是只能在任务执行结束之后才能获得累加器的最终结果。
Flink现在有以下内置累加器。每个累加器都实现了Accumulator接口。
- IntCounter
- LongCounter
- DoubleCounter
步骤
|
创建累加器 |
|
private IntCounter numLines = new IntCounter(); |
|
注册累加器 |
|
getRuntimeContext().addAccumulator("num-lines", this.numLines); |
|
使用累加器 |
|
this.numLines.add(1); |
|
获取累加器的结果 |
|
myJobExecutionResult.getAccumulatorResult("num-lines") |
参考代码
未使用累加器:
|
/** |
使用累加器:
|
/** |
Flink Broadcast和Accumulators的区别
- Broadcast(广播变量)允许程序员将一个只读的变量缓存在每台机器上,而不用在任务之间传递变量。广播变量可以进行共享,但是不可以进行修改
- Accumulators(累加器)是可以在不同任务中对同一个变量进行累加操作(简单的说就是由Flink为我们实现线程安全)(对于分布式系统来说,不仅仅累加的各个Task会跨Slot,甚至会跨机器进行累加,所以,传统的累加不可用,需要用Flink提供的累加器才可以的哦)。
Flink的分布式缓存
Flink提供了一个类似于Hadoop的分布式缓存,让并行运行实例的函数可以在本地访问。这个功能可以被使用来分享外部静态的数据,例如:机器学习的逻辑回归模型等!
缓存的使用流程:
使用ExecutionEnvironment实例对本地的或者远程的文件(例如:HDFS上的文件),为缓存文件指定一个名字注册该缓存文件!当程序执行时候,Flink会自动将复制文件或者目录到所有worker节点的本地文件系统中,函数可以根据名字去该节点的本地文件系统中检索该文件!
和广播变量的区别:
- 广播变量广播的是程序中的变量(DataSet)数据,分布式缓存广播的是文件
- 广播变量将数据广播到各个TaskManager的内存中,分布式缓存广播到各个TaskManager的本地文件系统
用法
使用Flink运行时环境的 registerCachedFile 注册一个分布式缓存
在操作中,使用 getRuntimeContext.getDistributedCache.getFile ( 文件名 )获取分布式缓存
示例
创建一个 成绩 数据集
|
List( (1, "语文", 50),(2, "数学", 70), (3, "英文", 86)) |
请通过分布式缓存获取到学生姓名,将数据转换为
|
List( ("张三", "语文", 50),("李四", "数学", 70), ("王五", "英文", 86)) |
注: 资料\测试数据源\distribute_cache_student 文件保存了学生ID以及学生姓
操作步骤
- 将 distribute_cache_student 文件上传到HDFS / 目录下
- 获取批处理运行环境
- 创建成绩数据集
- 对 成绩 数据集进行map转换,将(学生ID, 学科, 分数)转换为(学生姓名,学科,分数)
- RichMapFunction 的 open 方法中,获取分布式缓存数据
- 在 map 方法中进行转换
- 实现 open 方法
- 使用 getRuntimeContext.getDistributedCache.getFile 获取分布式缓存文件
- 使用 Scala.fromFile 读取文件,并获取行
- 将文本转换为元组(学生ID,学生姓名),再转换为List
- 实现 map 方法
- 从分布式缓存中根据学生ID过滤出来学生
- 获取学生姓名
- 构建最终结果元组
- 打印测试
参考代码
|
/** |
3.2 Flink 高级API开发
1、 Flink 四大基石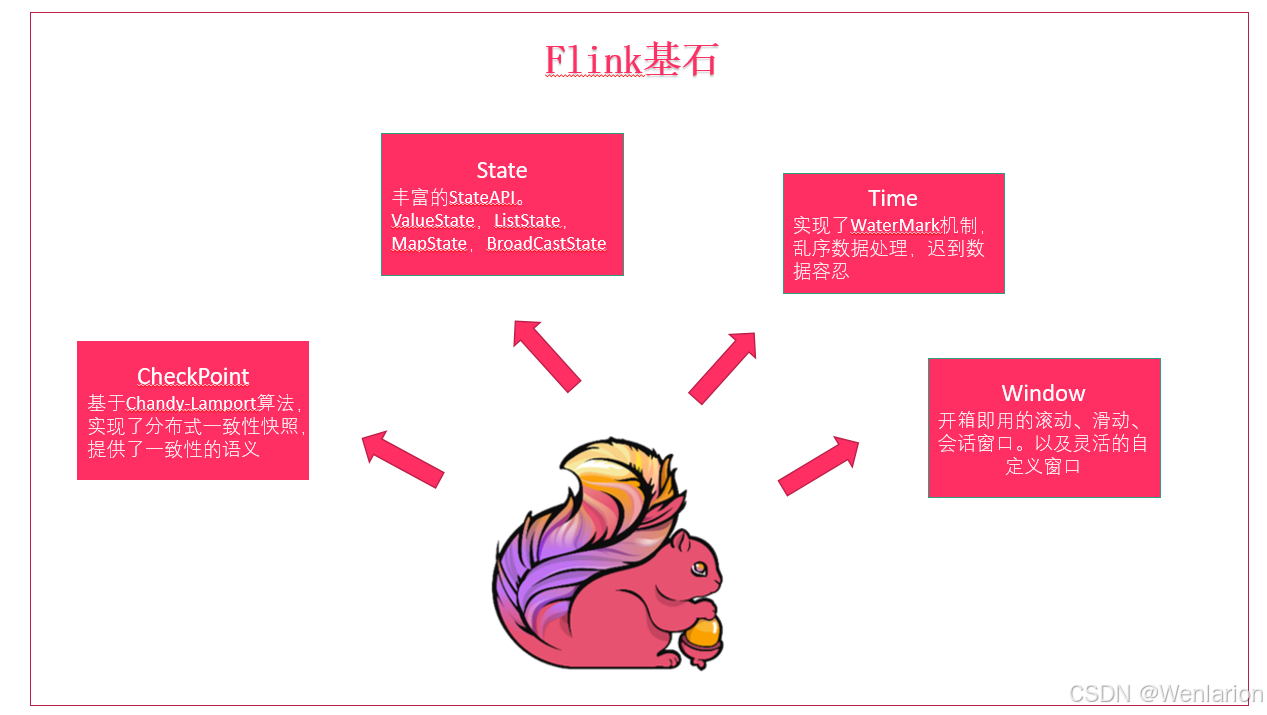
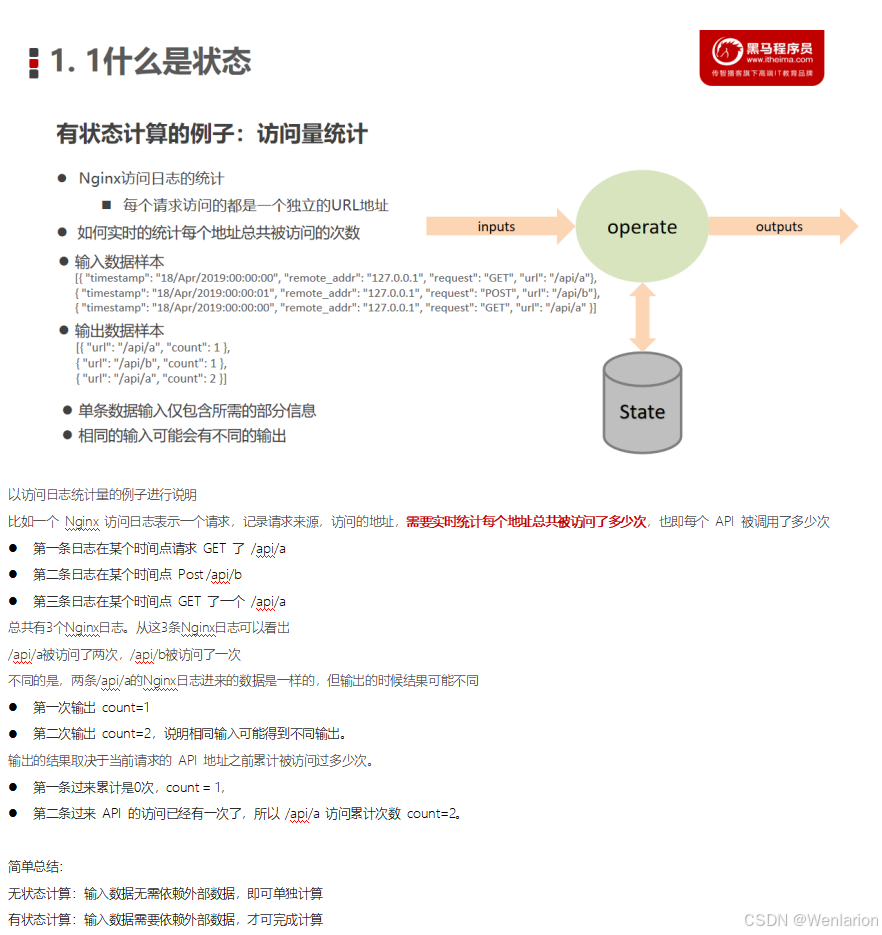
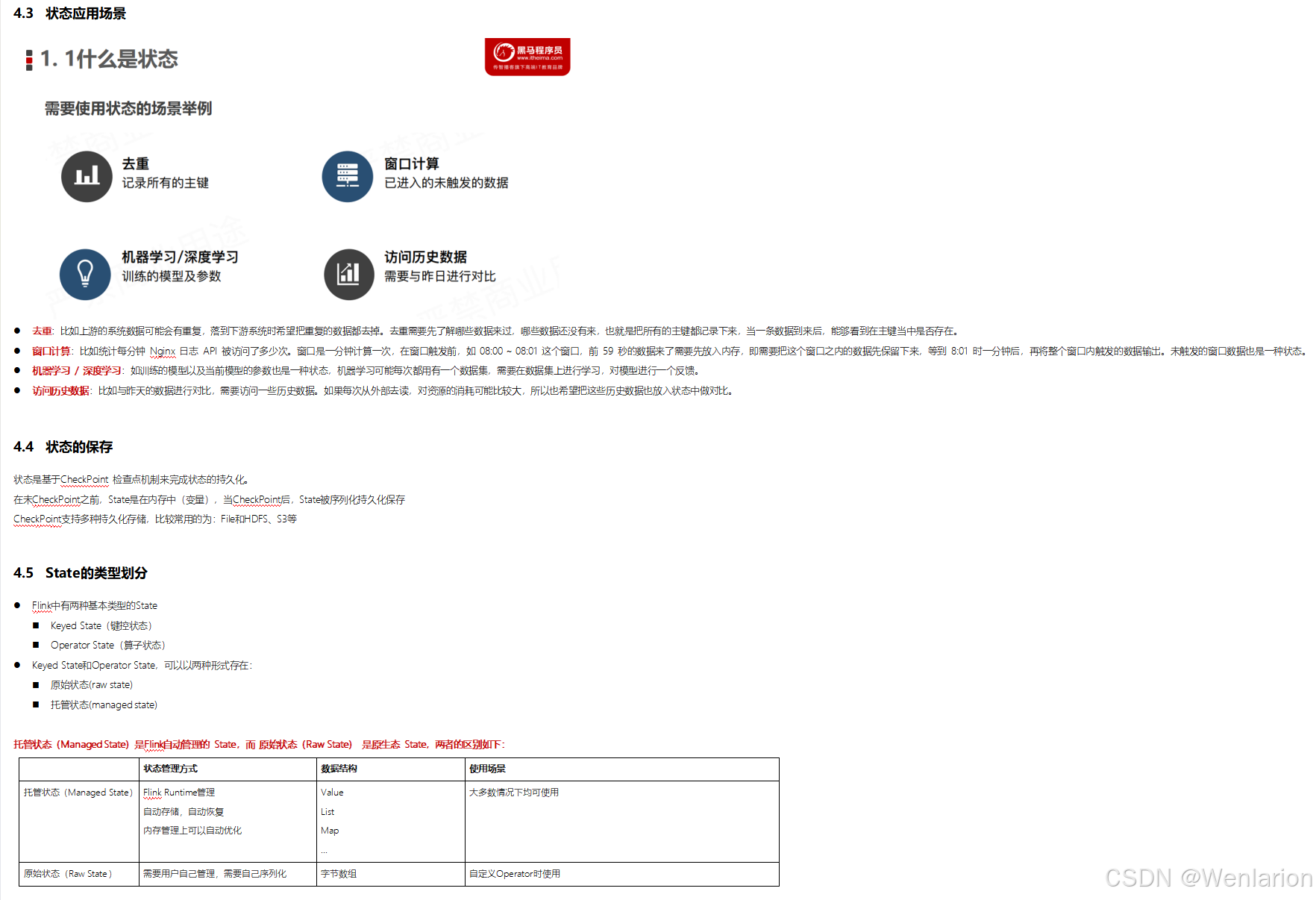
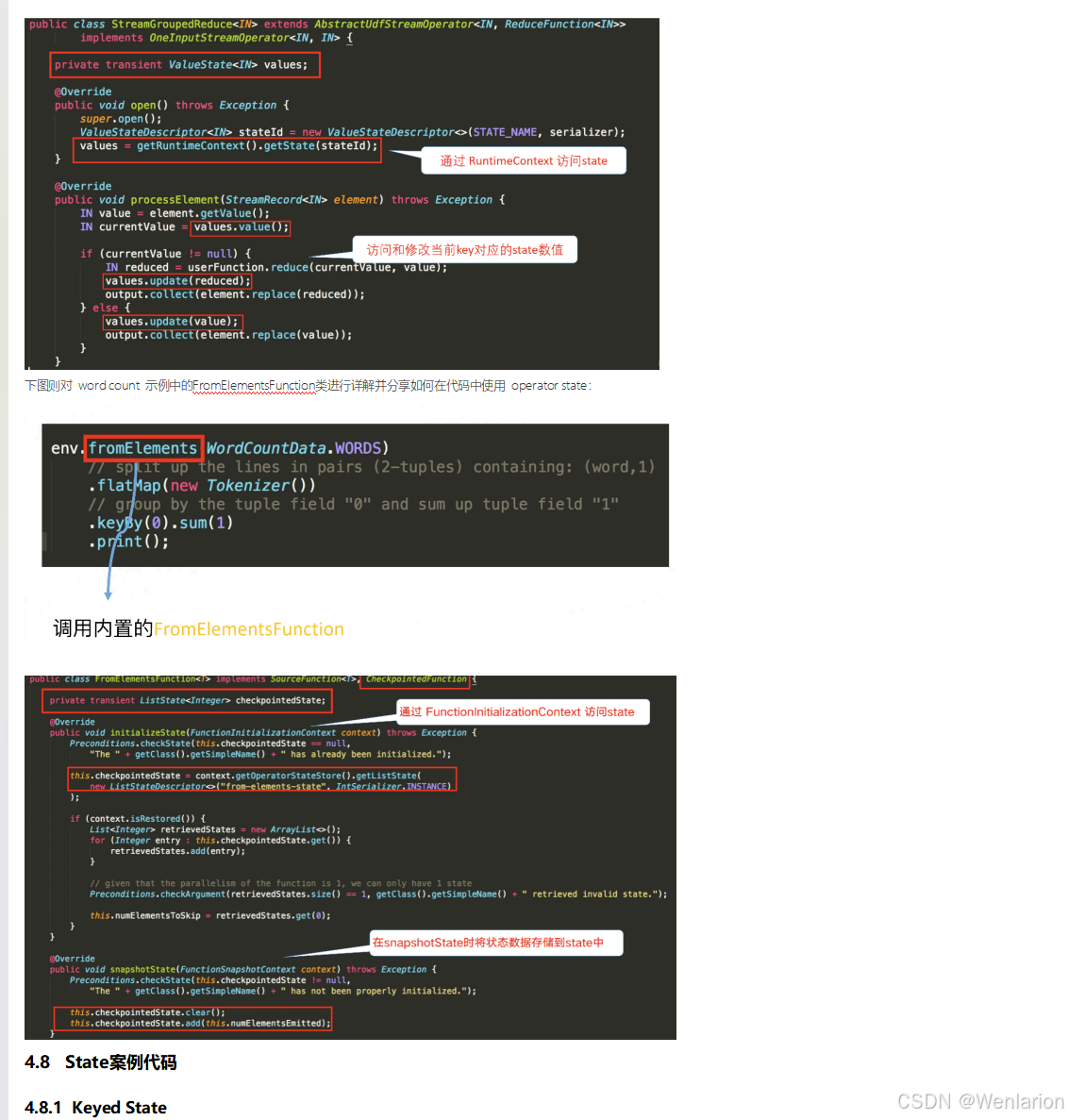
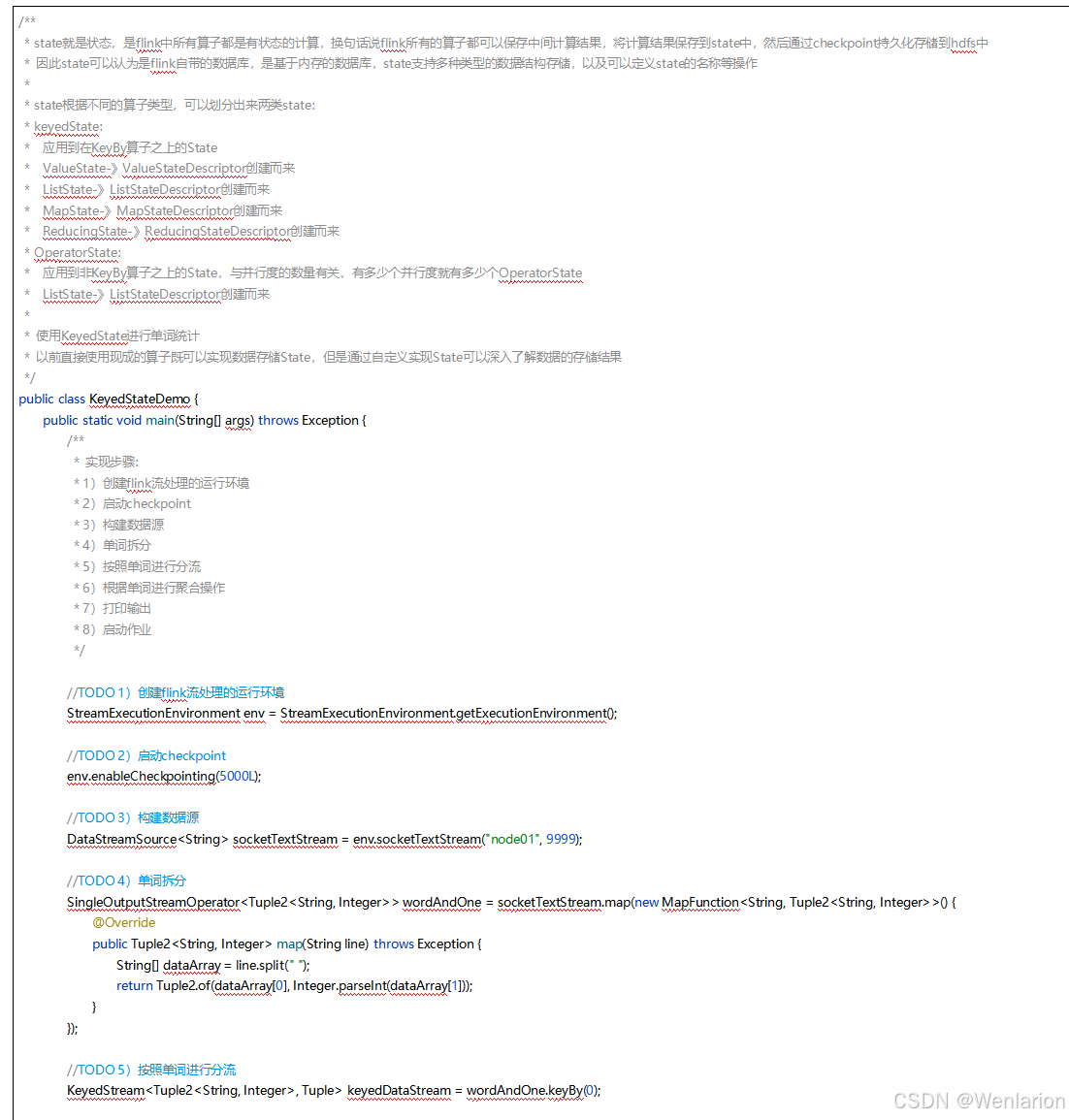
Flink 之所以能这么流行,离不开它最重要的四个基石:Checkpoint、State、Time、Window。
Checkpoint
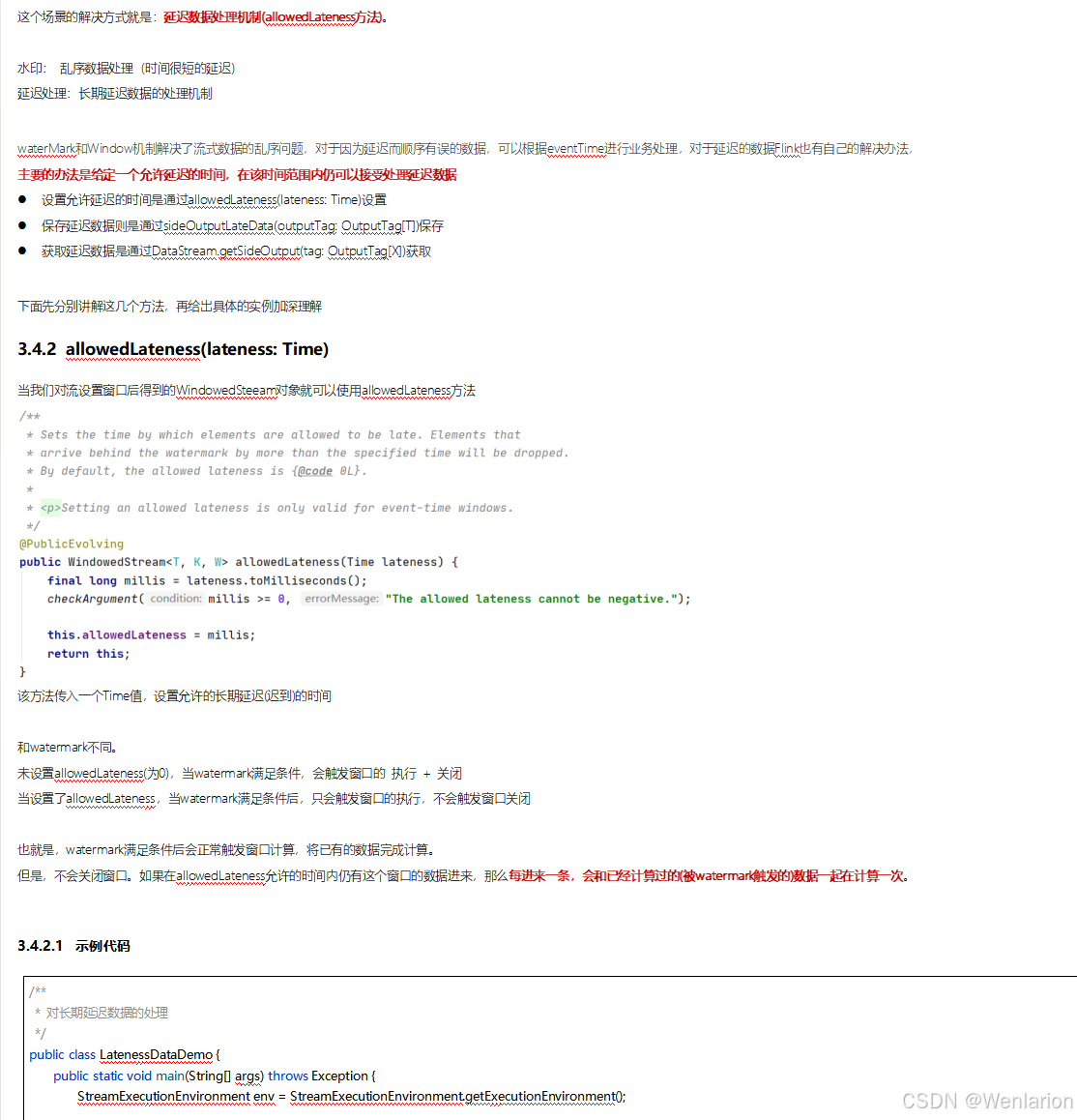
这是 Flink 最重要的一个特性。Flink 基于Chandy-Lamport 算法实现了一个分布式的一致性快照,从而提供了一致性的语义。Chandy-Lamport 算法实际上在 1985 年的时候已经被提出来,但并没有被很广泛的应用,而 Flink 则把这个算法发扬光大了。Spark 最近在实现 Continue streaming,Continue streaming 的目的是为了降低处理的延时,其也需要提供这种一致性的语义,最终也采用了 Chandy-Lamport 这个算法,说明 Chandy-Lamport 算法在业界得到了一定的肯定。https://zhuanlan.zhihu.com/p/53482103
State
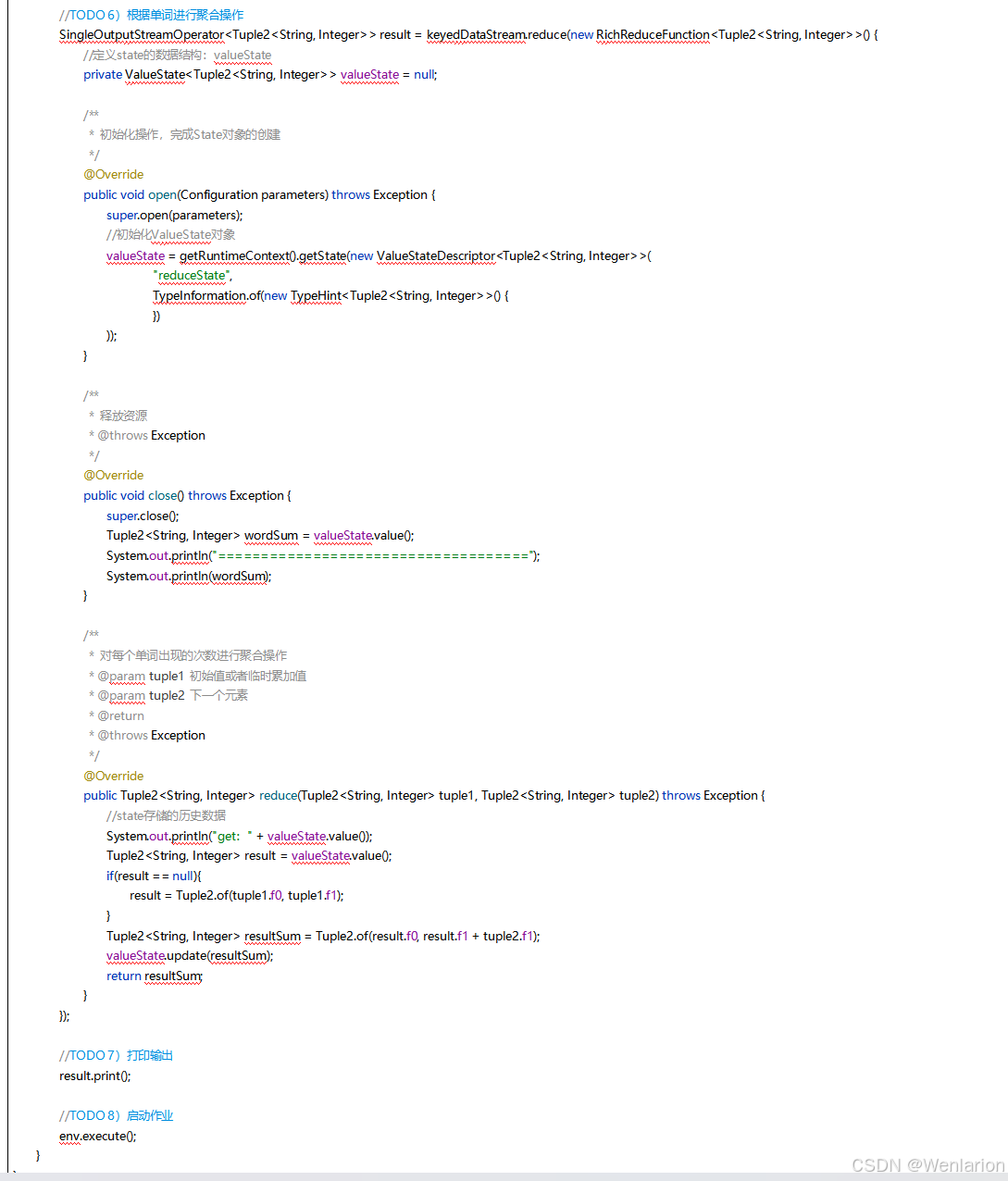
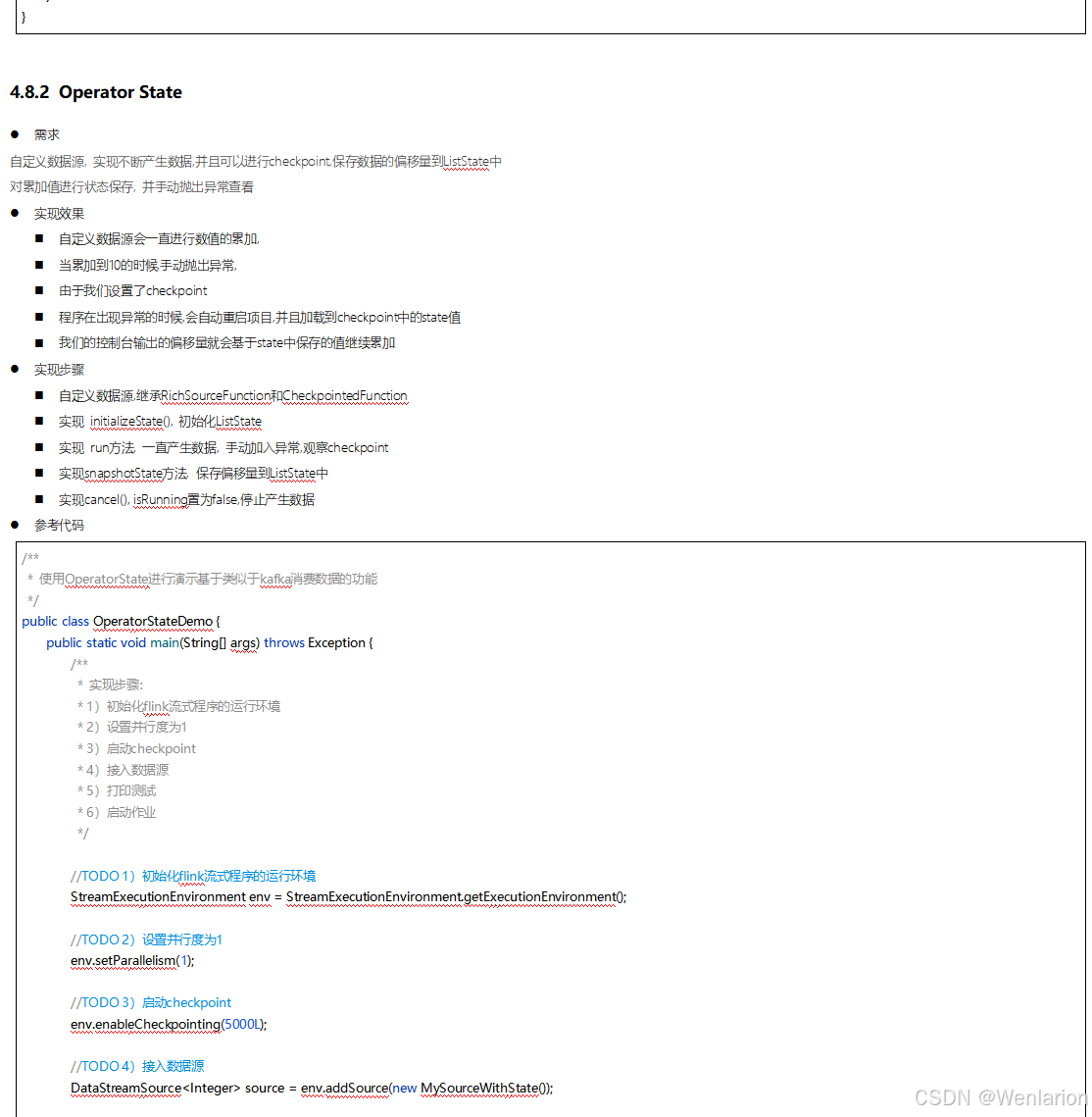
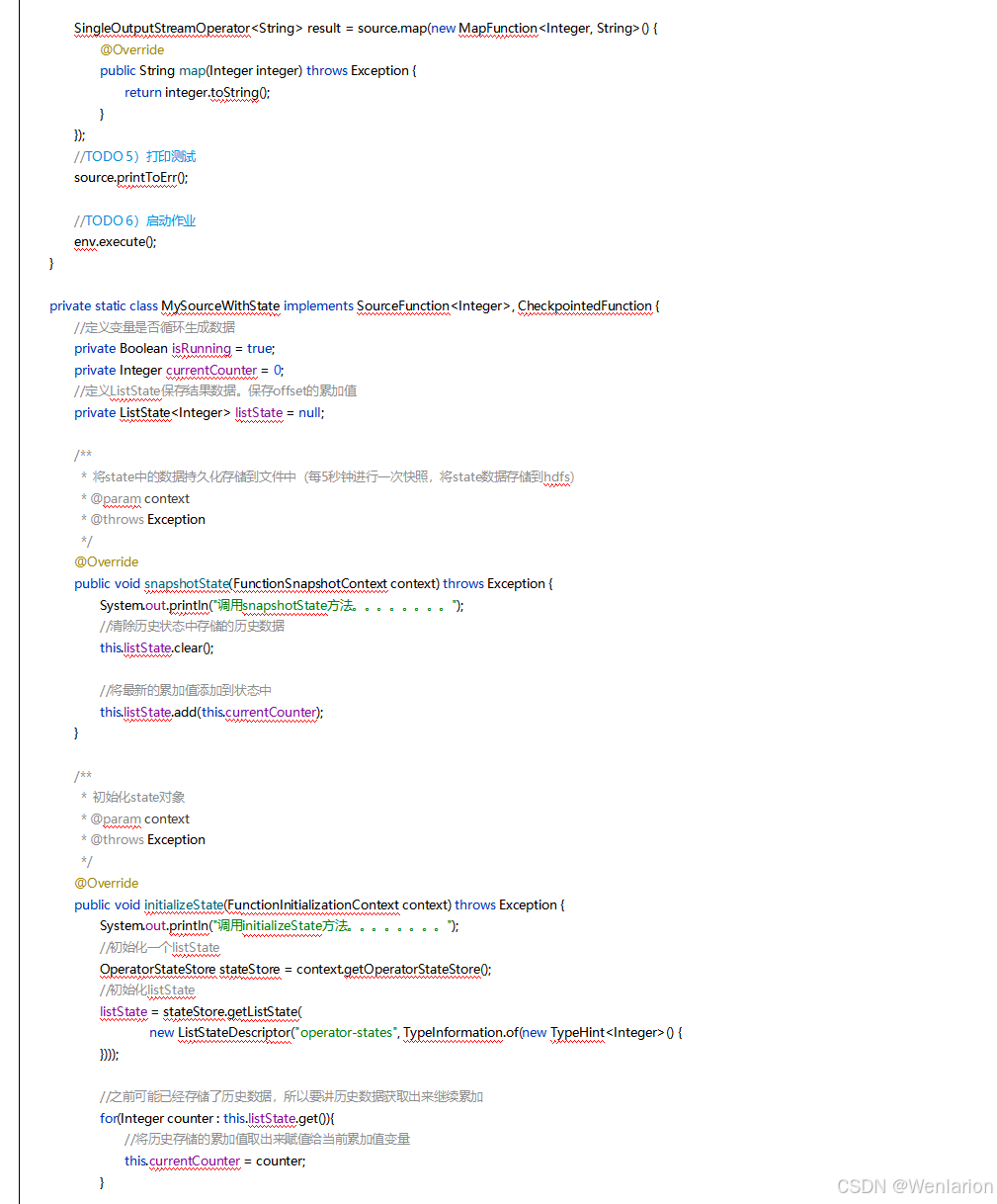
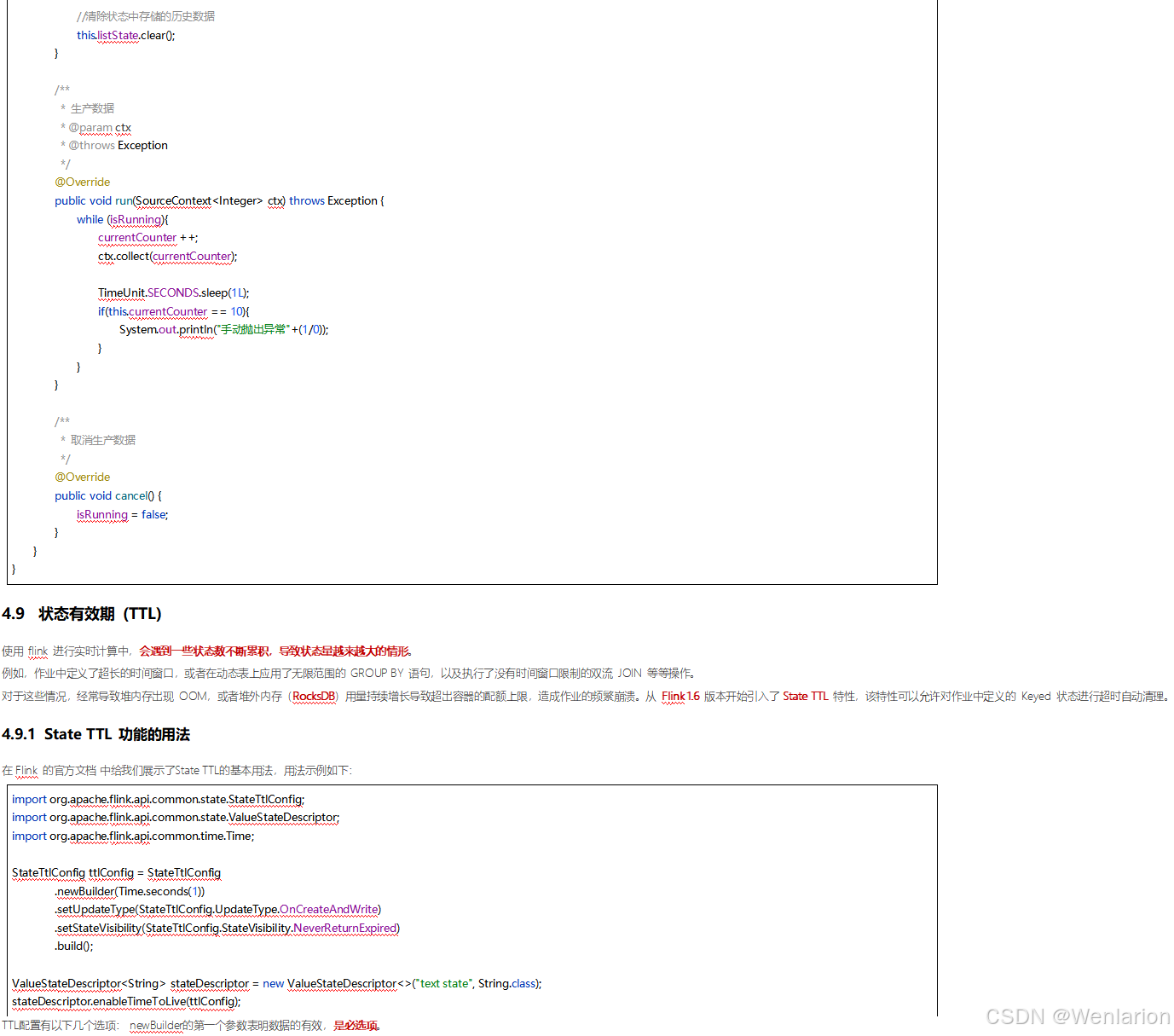
提供了一致性的语义之后,Flink 为了让用户在编程时能够更轻松、更容易地去管理状态,还提供了一套非常简单明了的State API,包括 ValueState、ListState、MapState、BroadcastState。
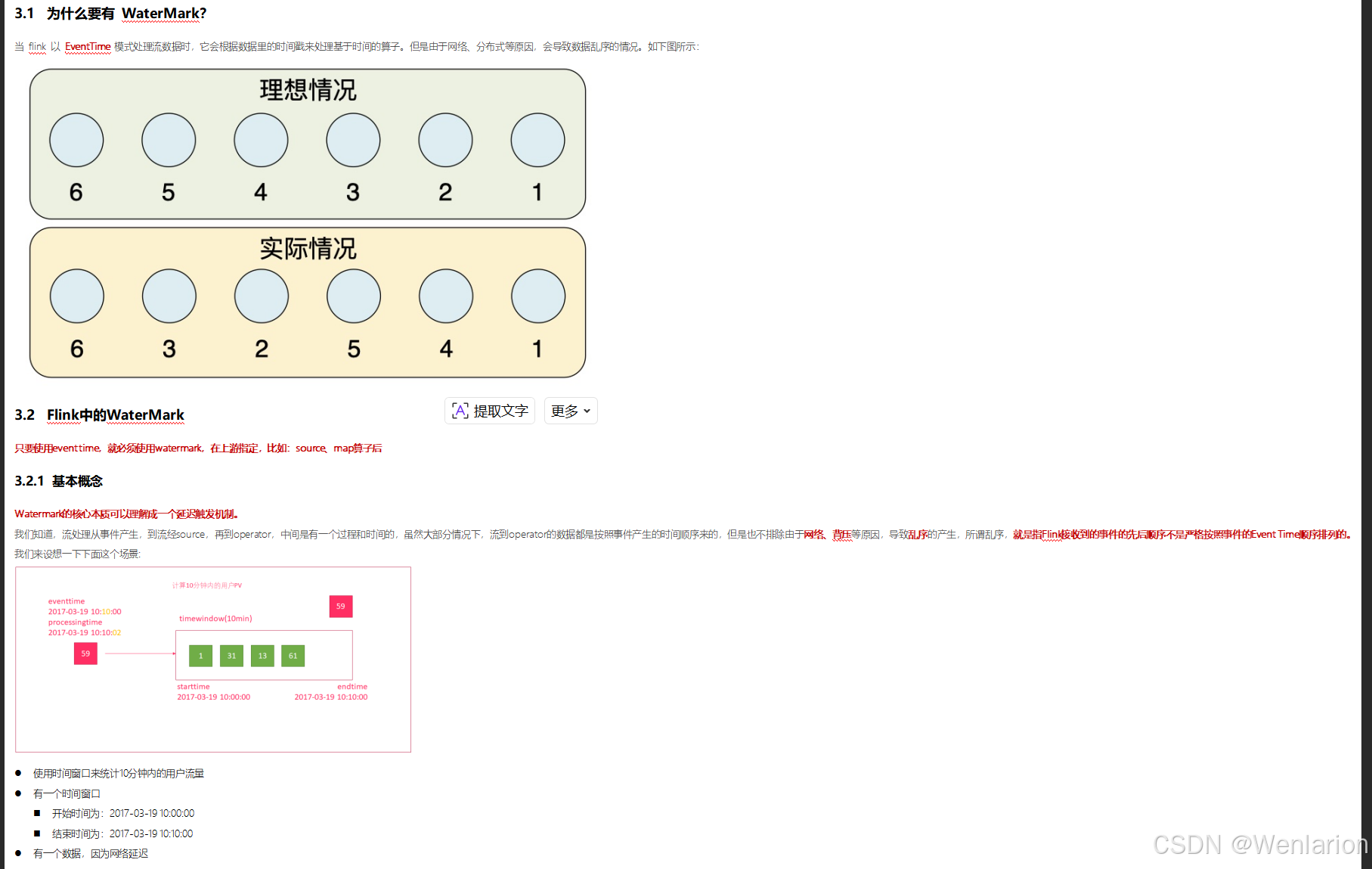
Time
除此之外,Flink 还实现了Watermark的机制,能够支持基于事件的时间处理,能够容忍迟到 / 乱序的数据。
Window
另外流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算。Flink 提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义窗口。
2、Flink 的 Window 操作
Flink 认为 Batch 是 Streaming 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。而窗口(window)就是从 Streaming 到 Batch 的一个桥梁。Flink 提供了非常完善的窗口机制。
2.1 为什么需要 Window
在流处理应用中,数据是连续不断的,有时我们需要做一些聚合类的处理,例如:在过去的 1 分钟内有多少用户点击了我们的网页。
在这种情况下,我们必须定义一个窗口(window),用来收集最近 1 分钟内的数据,并对这个窗口内的数据进行计算。
Windows 是处理无限流的核心。Windows 将流拆分为有限大小的 “桶”,我们可以对其进行计算。
2.2 Flink 窗口应用代码结构
Flink 的窗口算子为我们提供了方便易用的 API,我们可以将数据流切分成一个个窗口,对窗口内的数据进行处理。本文将介绍如何在 Flink 上进行窗口的计算。
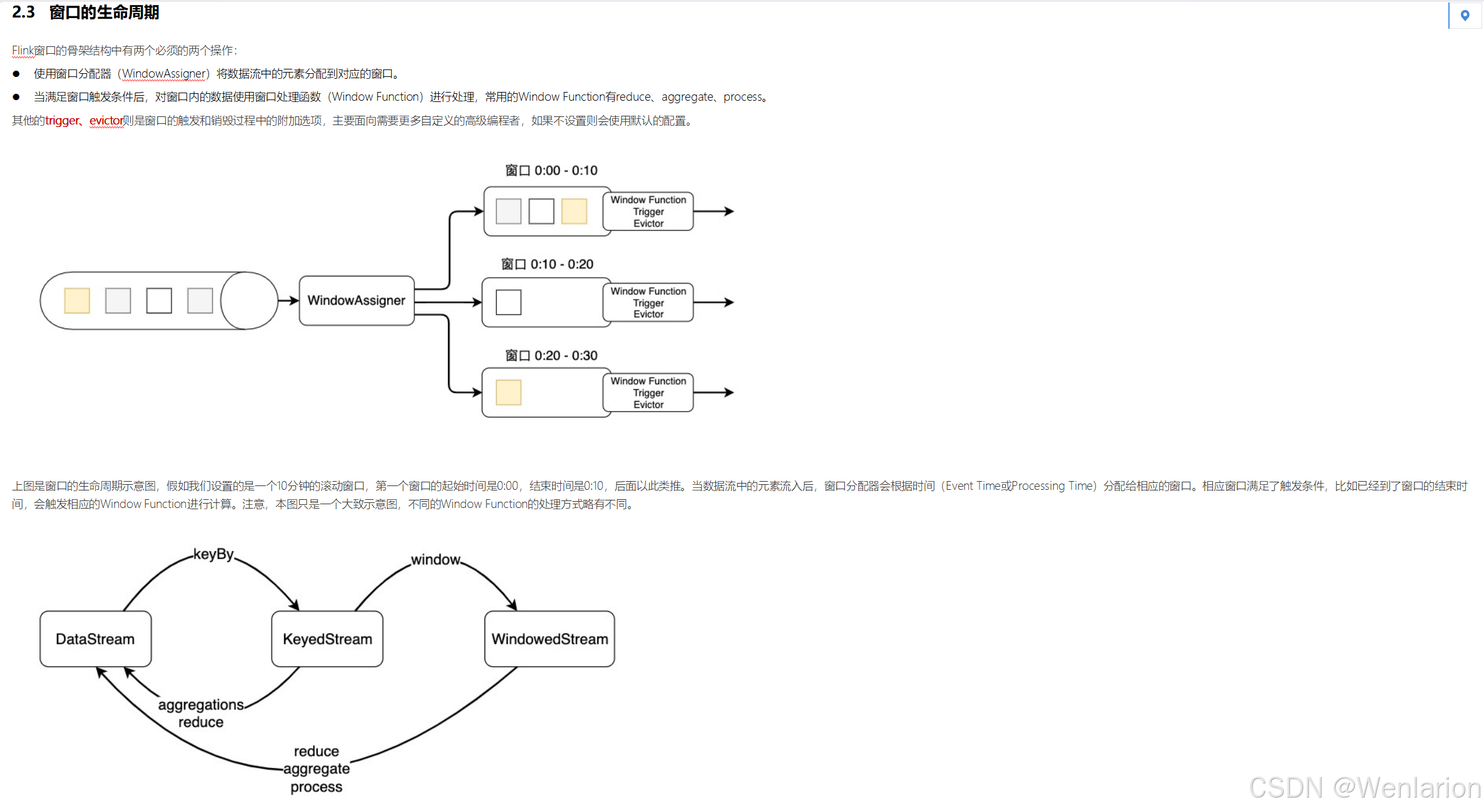
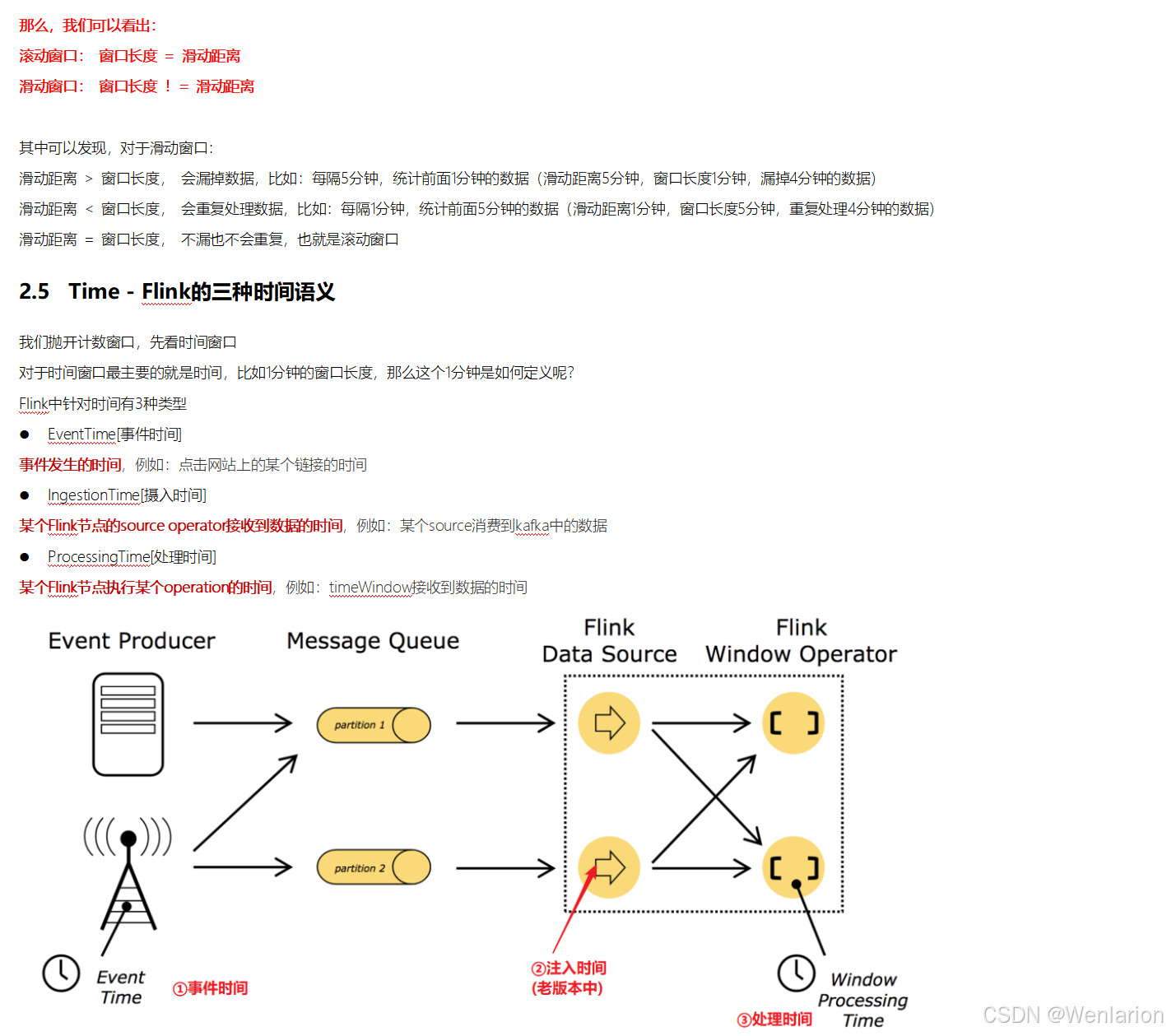
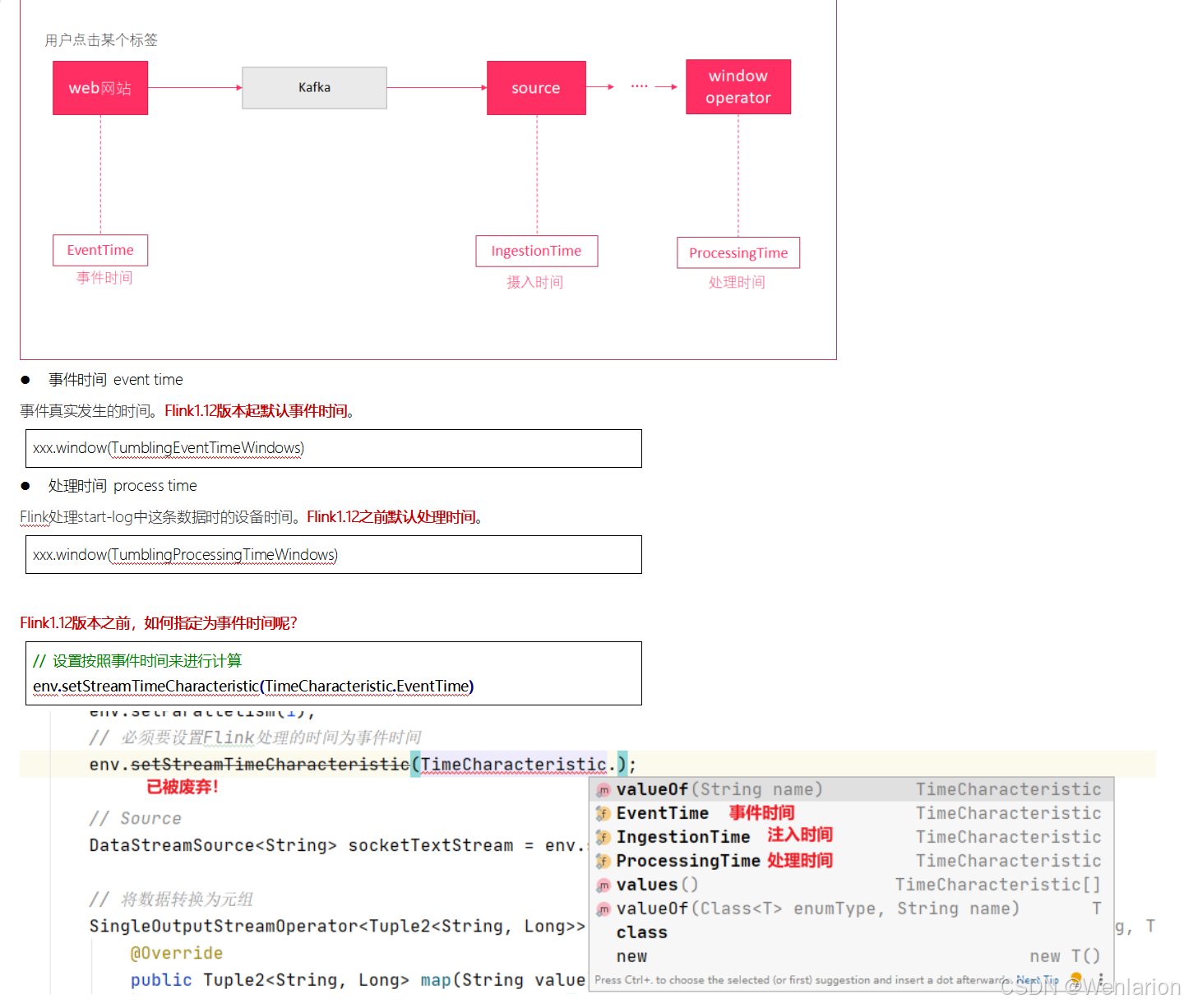
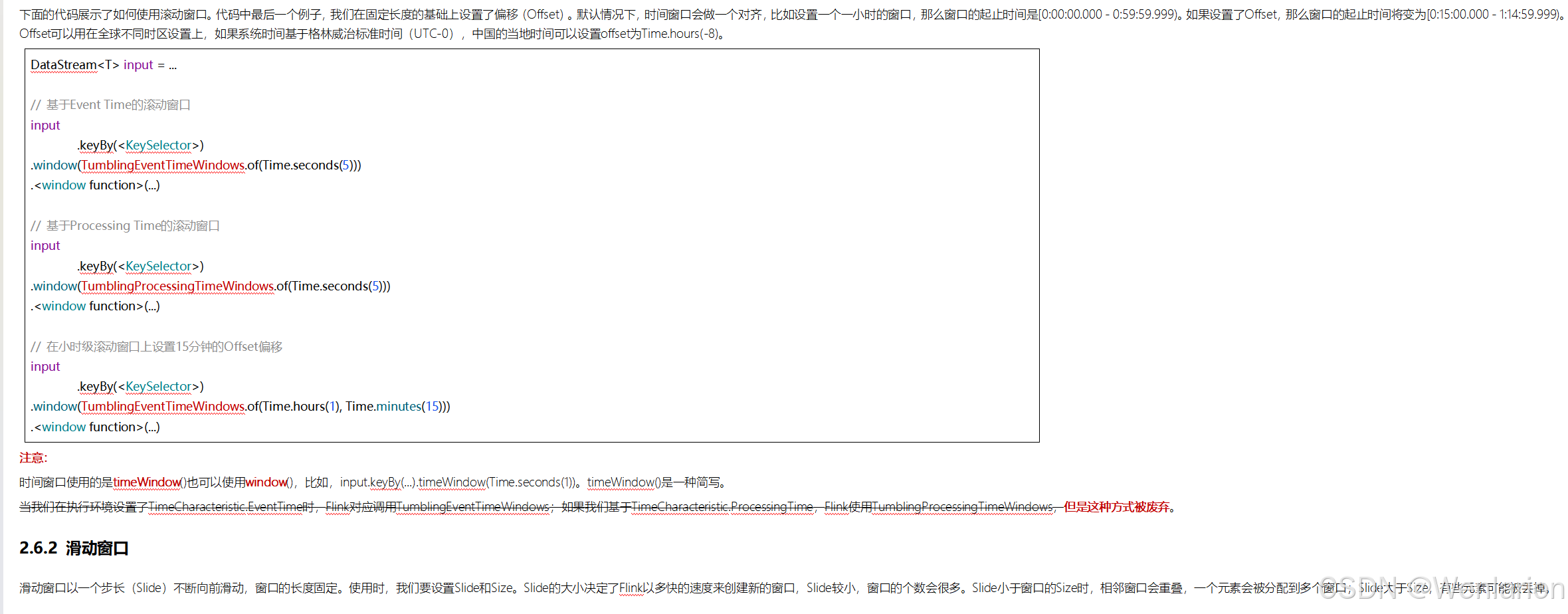
一个 Flink 窗口应用的大致骨架结构如下所示:
● Keyed Window
// Keyed Window
stream
.keyBy(...) <- 按照一个Key进行分组
.window(...) <- 将数据流中的元素分配到相应的窗口中
[.trigger(...)] <- 指定触发器Trigger(可选)
[.evictor(...)] <- 指定清除器Evictor(可选)
.reduce/aggregate/process() <- 窗口处理函数Window Function
● Non-Keyed Window
// Non-Keyed Window
stream
.windowAll(...) <- 不分组,将数据流中的所有元素分配到相应的窗口中
[.trigger(...)] <- 指定触发器Trigger(可选)
[.evictor(...)] <- 指定清除器Evictor(可选)
.reduce/aggregate/process() <- 窗口处理函数Window Function
在上面,方括号 [...] 中的命令是可选的。这表明 Flink 允许您以多种不同的方式自定义窗口逻辑,使其最适合您的需求。
首先:我们要决定是否对一个 DataStream 按照 Key 进行分组,这一步必须在窗口计算之前进行。经过keyBy()的数据流将形成多组数据,下游算子的多个实例可以并行计算。windowAll()不对数据流进行分组,所有数据将发送到下游算子单个实例上。决定是否分组之后,窗口的后续操作基本相同,经过windowAll()的算子是不分组的窗口(Non-Keyed Window),它们的原理和操作与 Keyed Window 类似,唯一的区别在于所有数据将发送给下游的单个实例,或者说下游算子的并行度为 1。









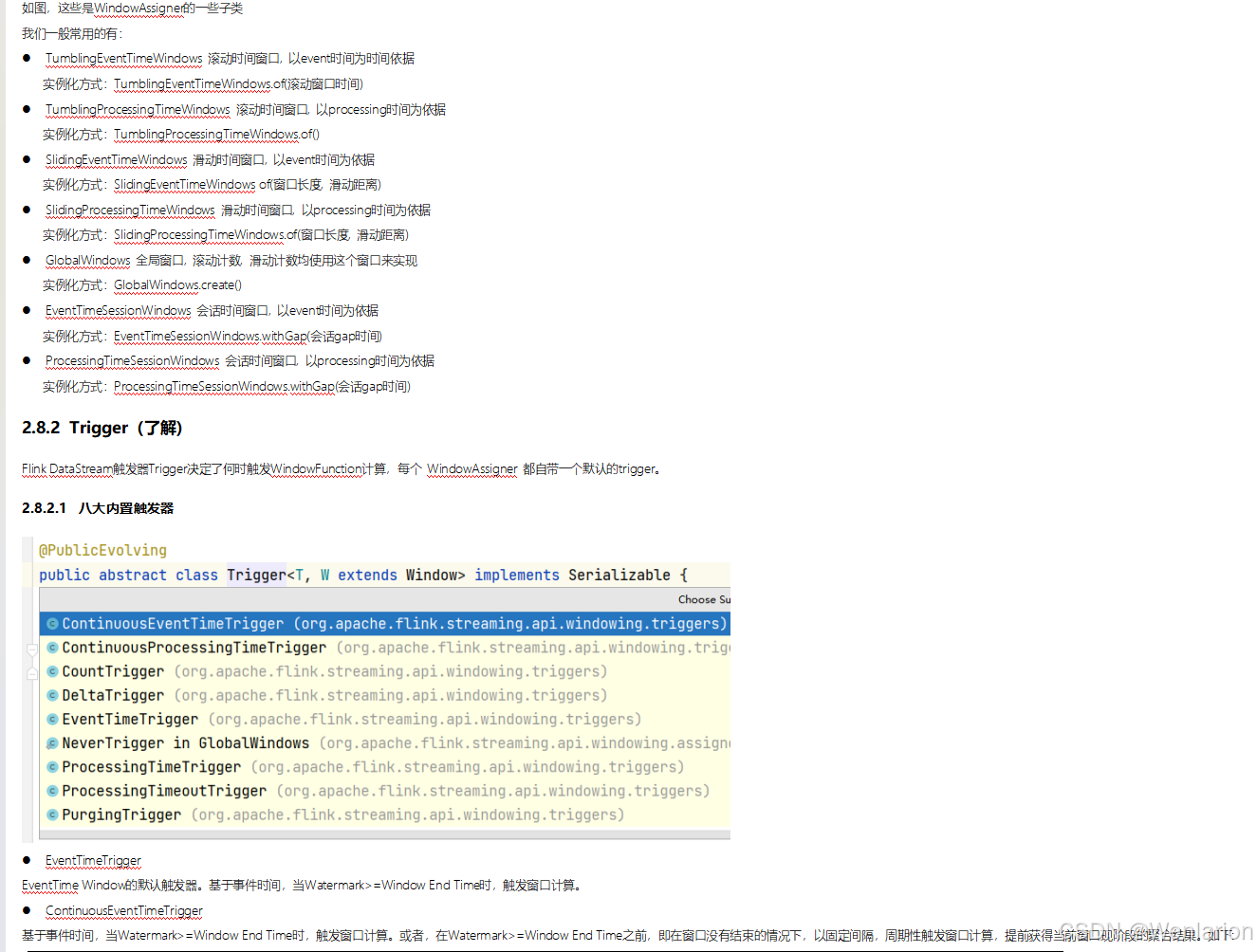
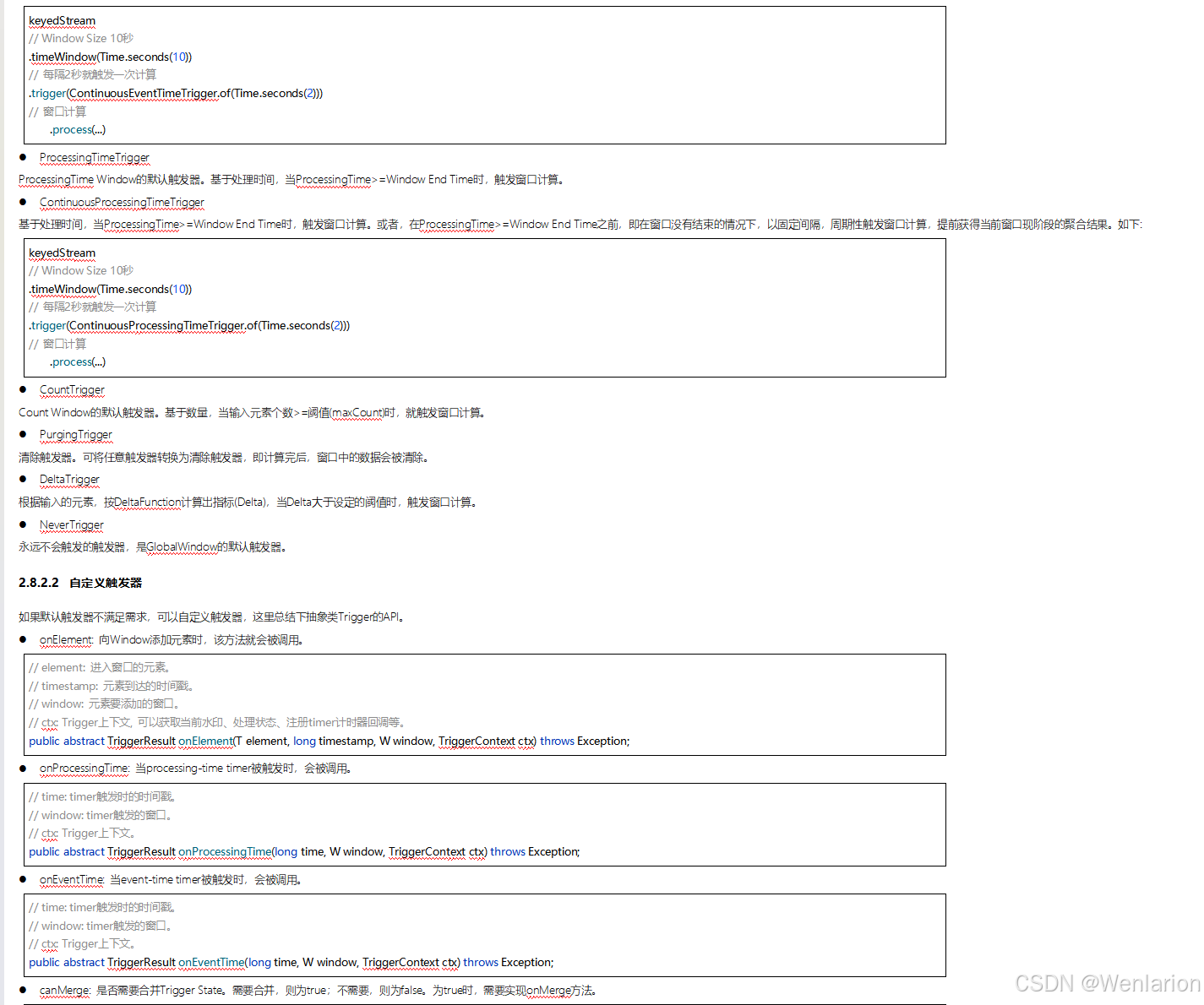
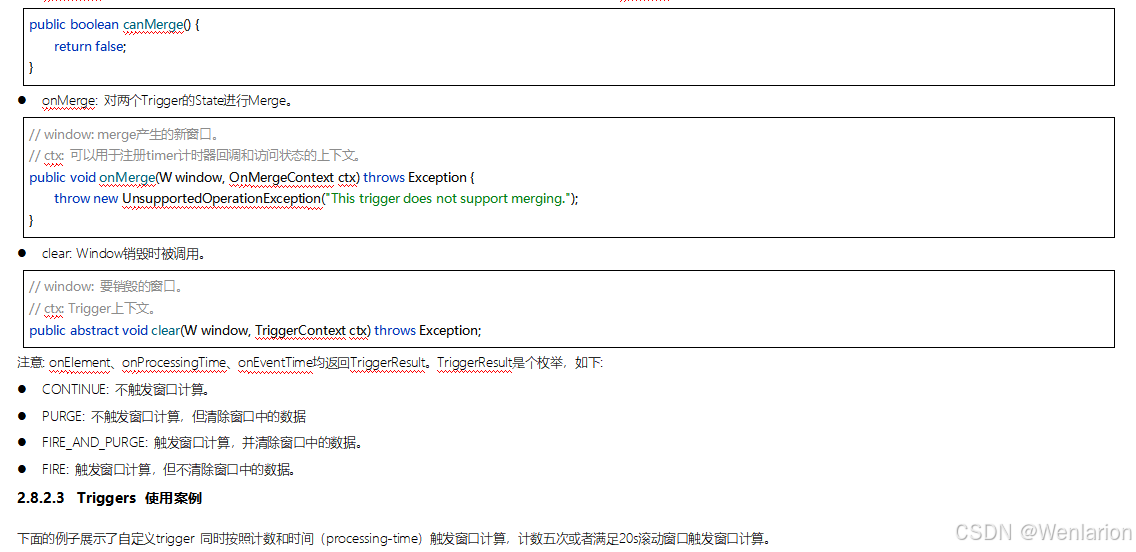

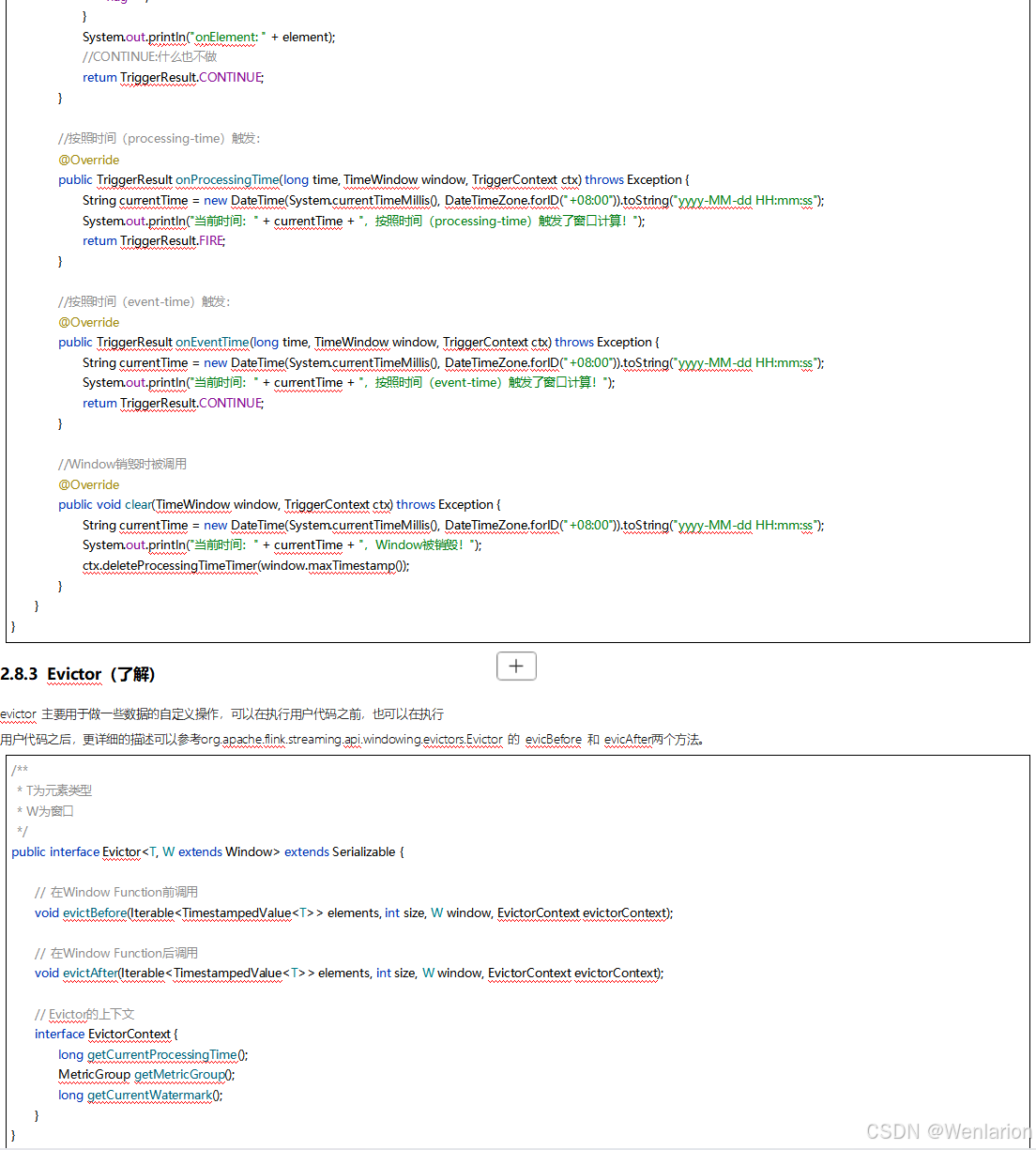
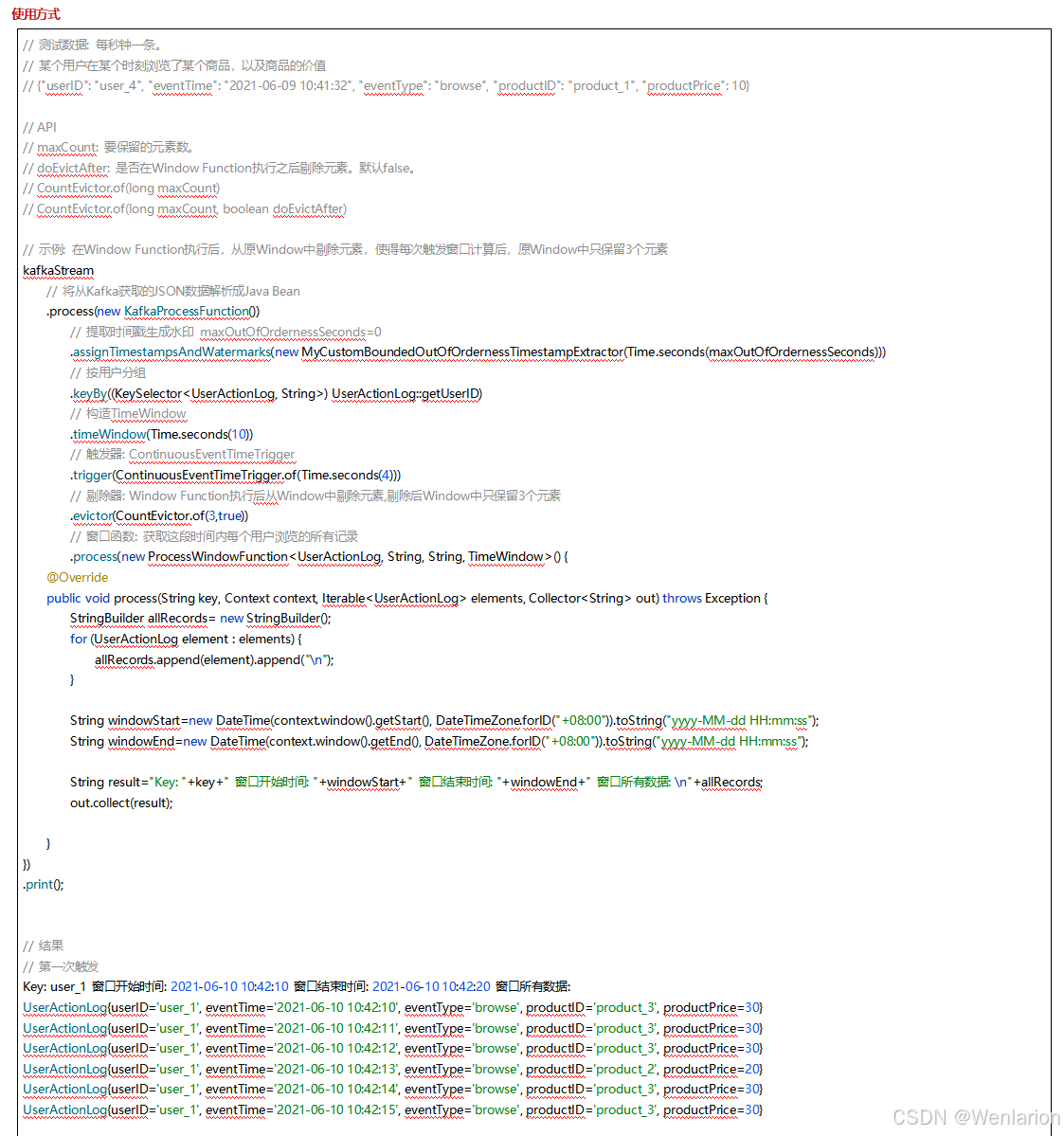
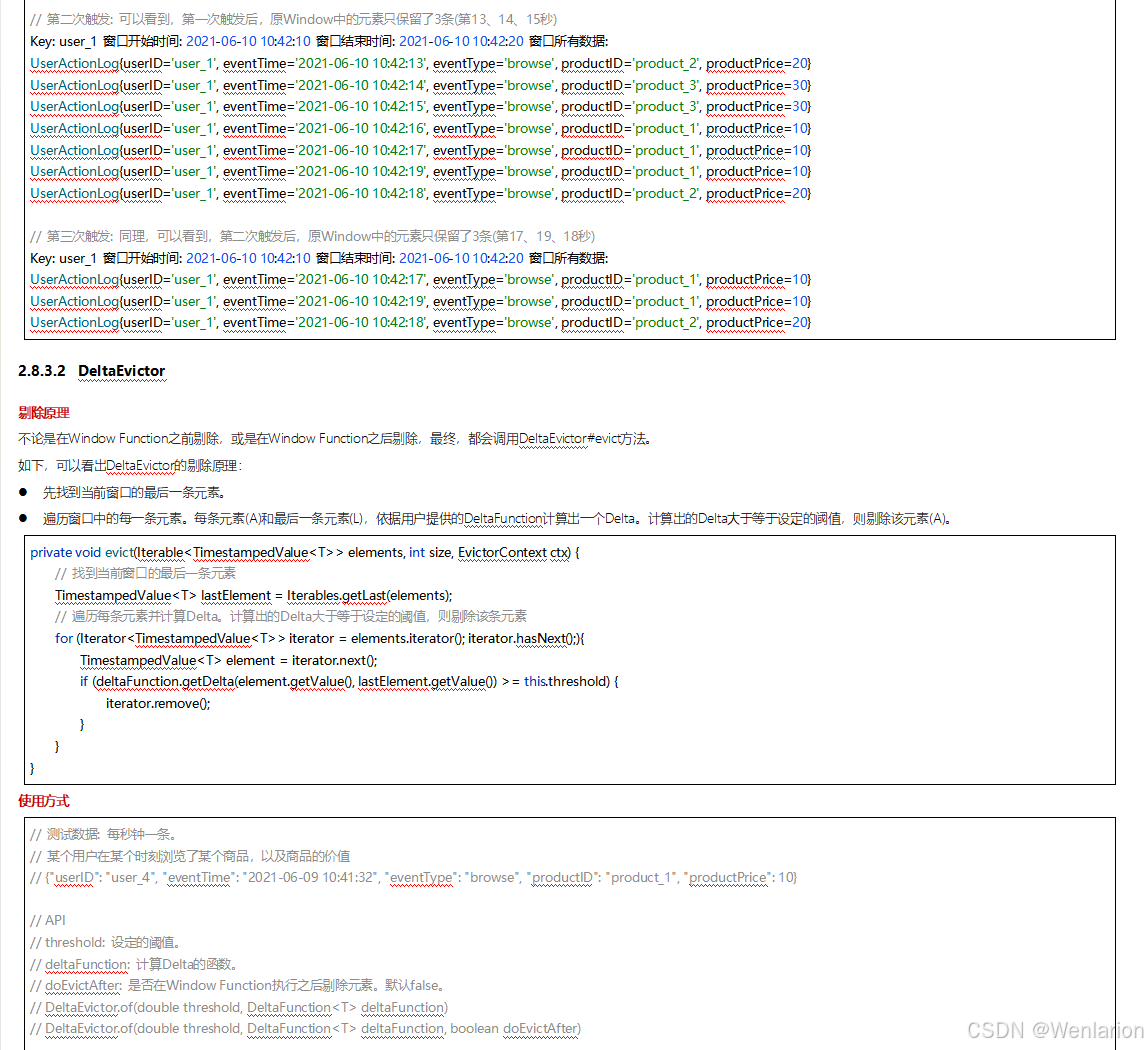
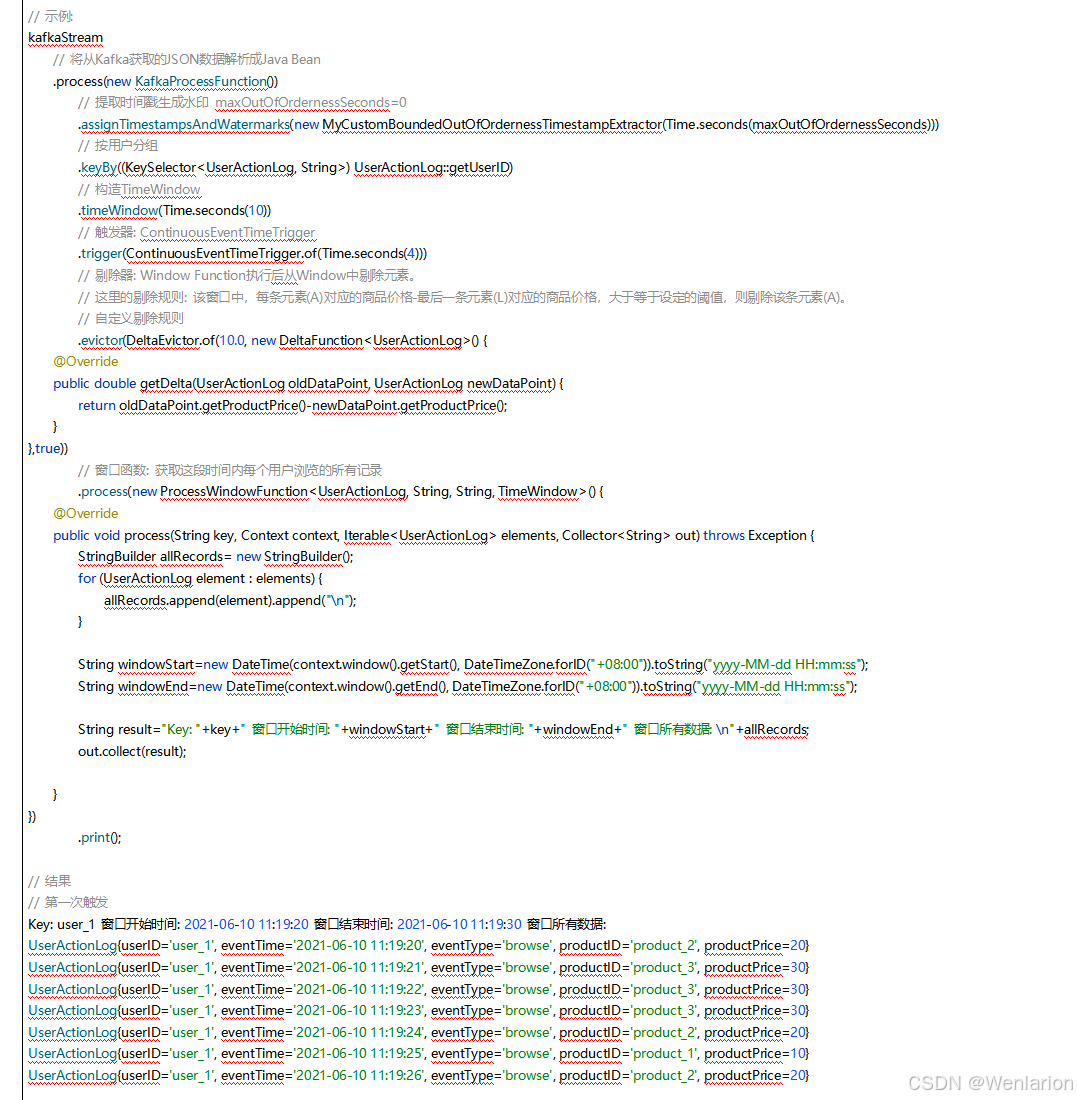
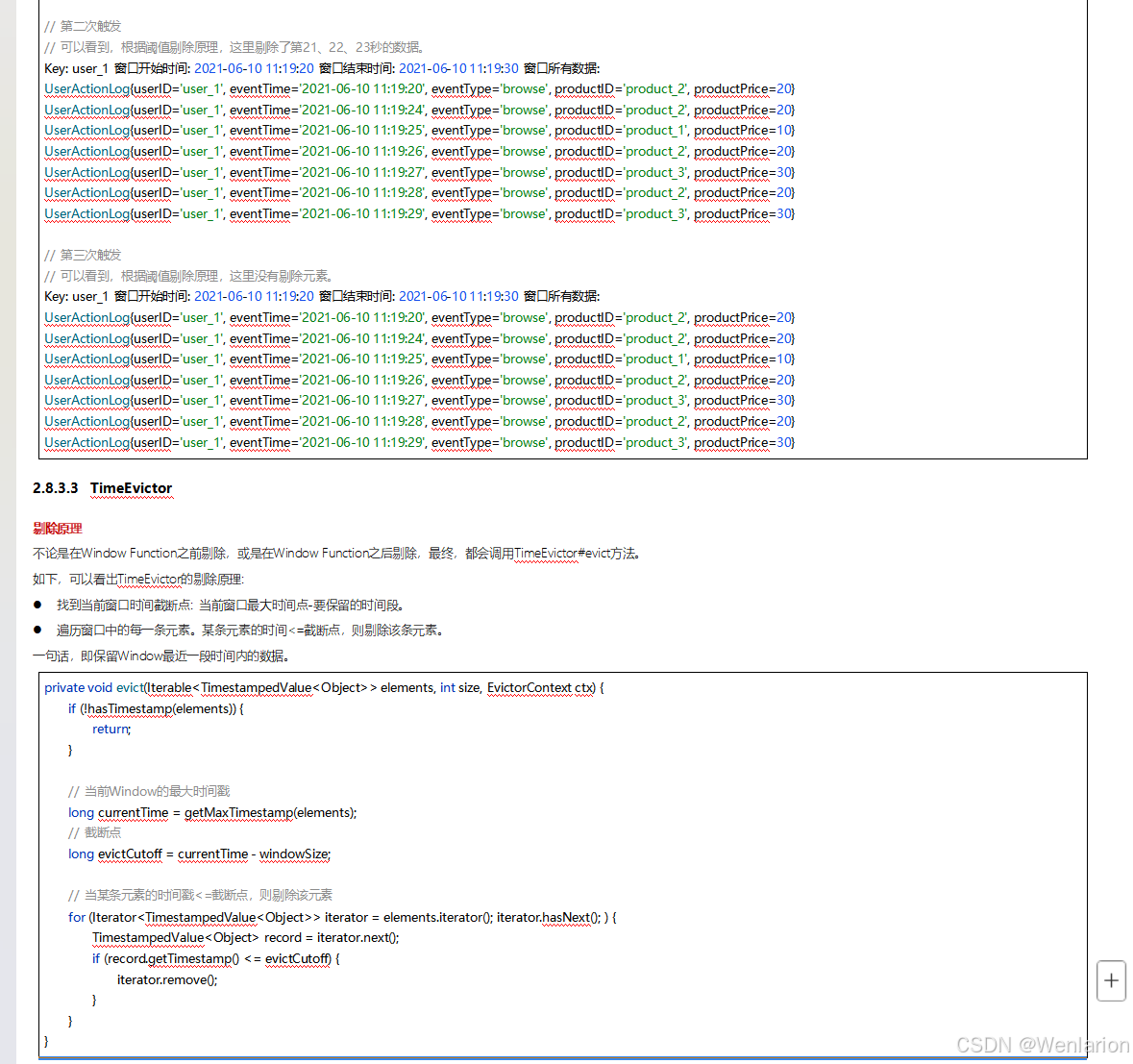
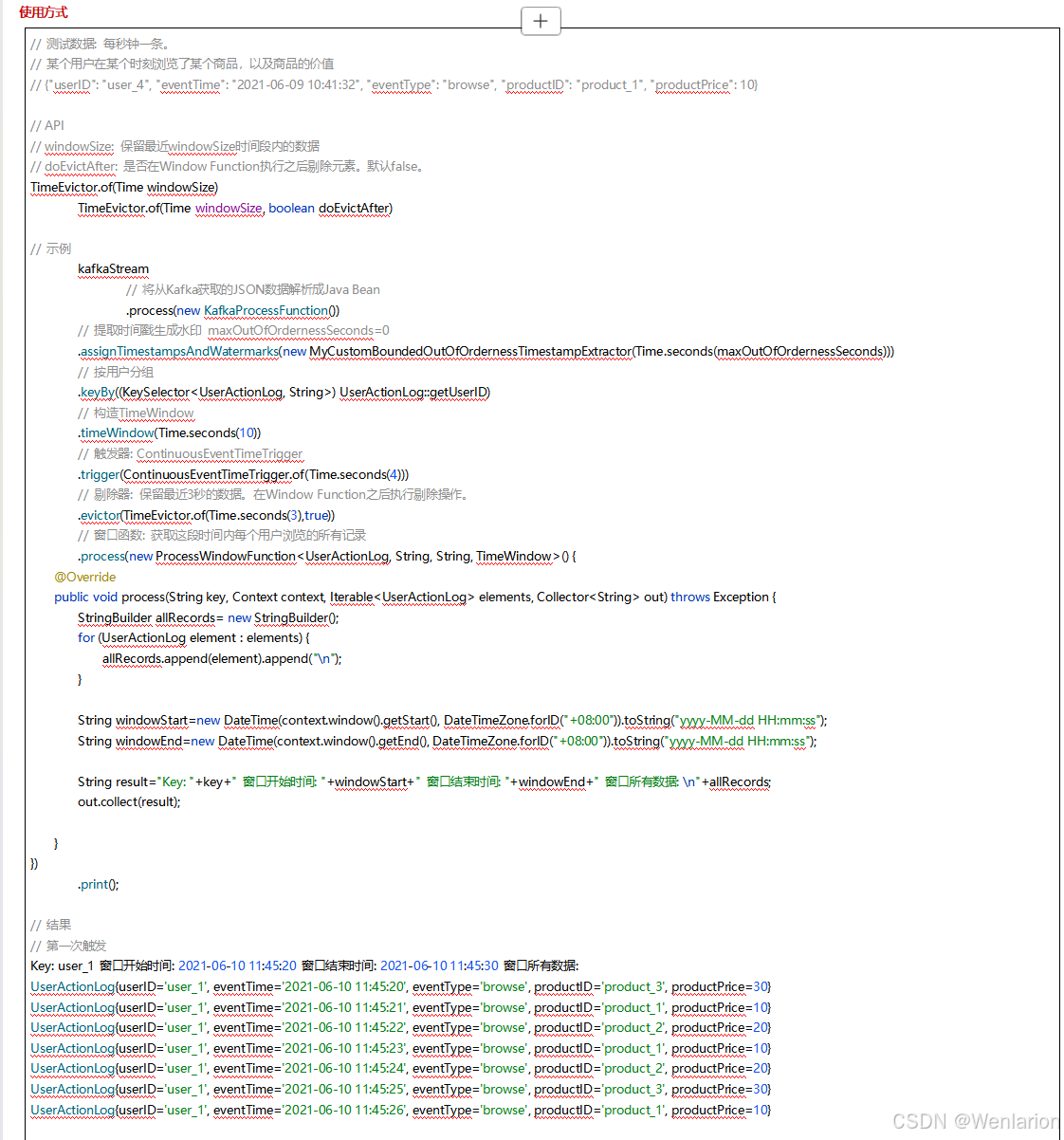
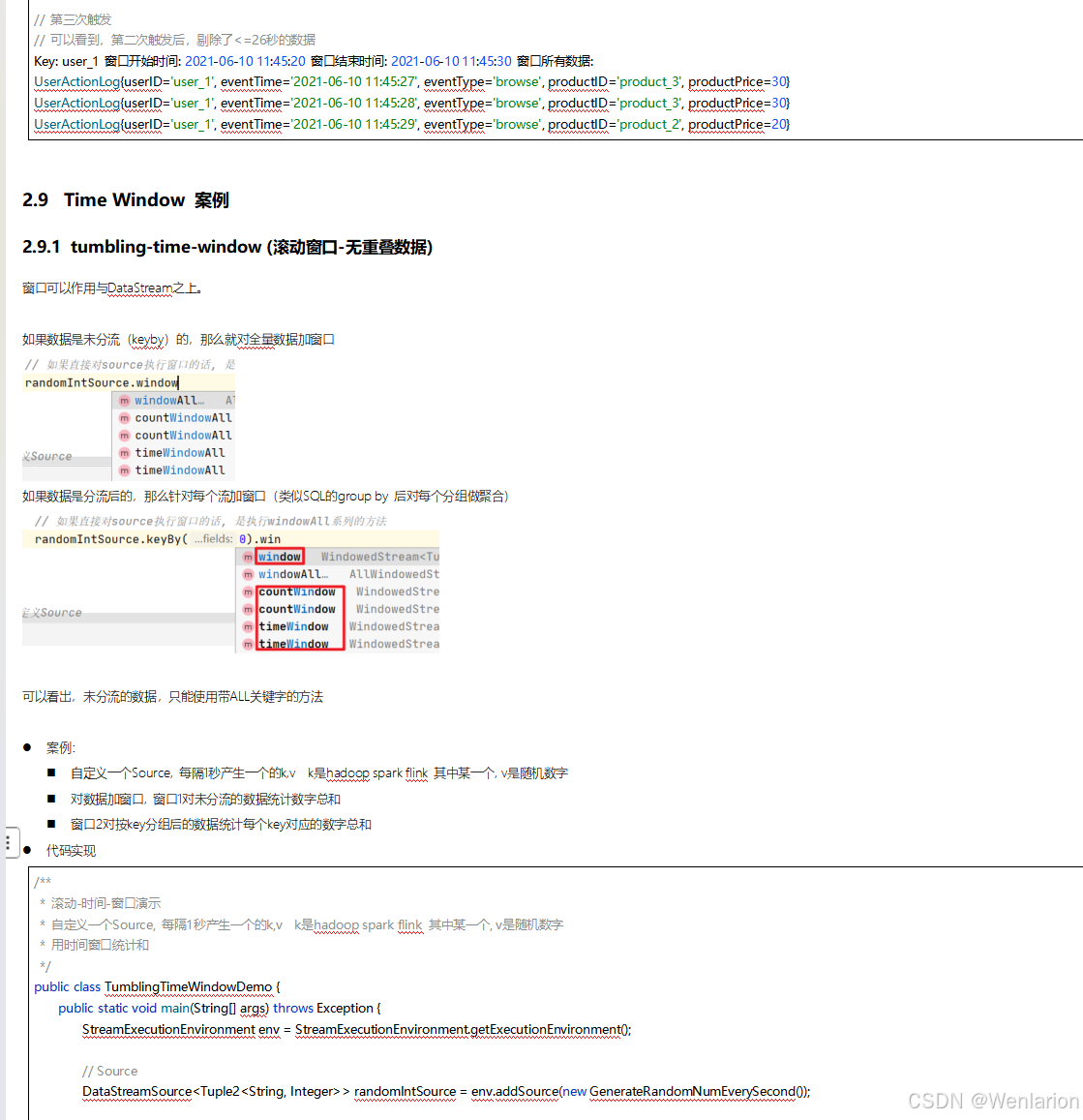
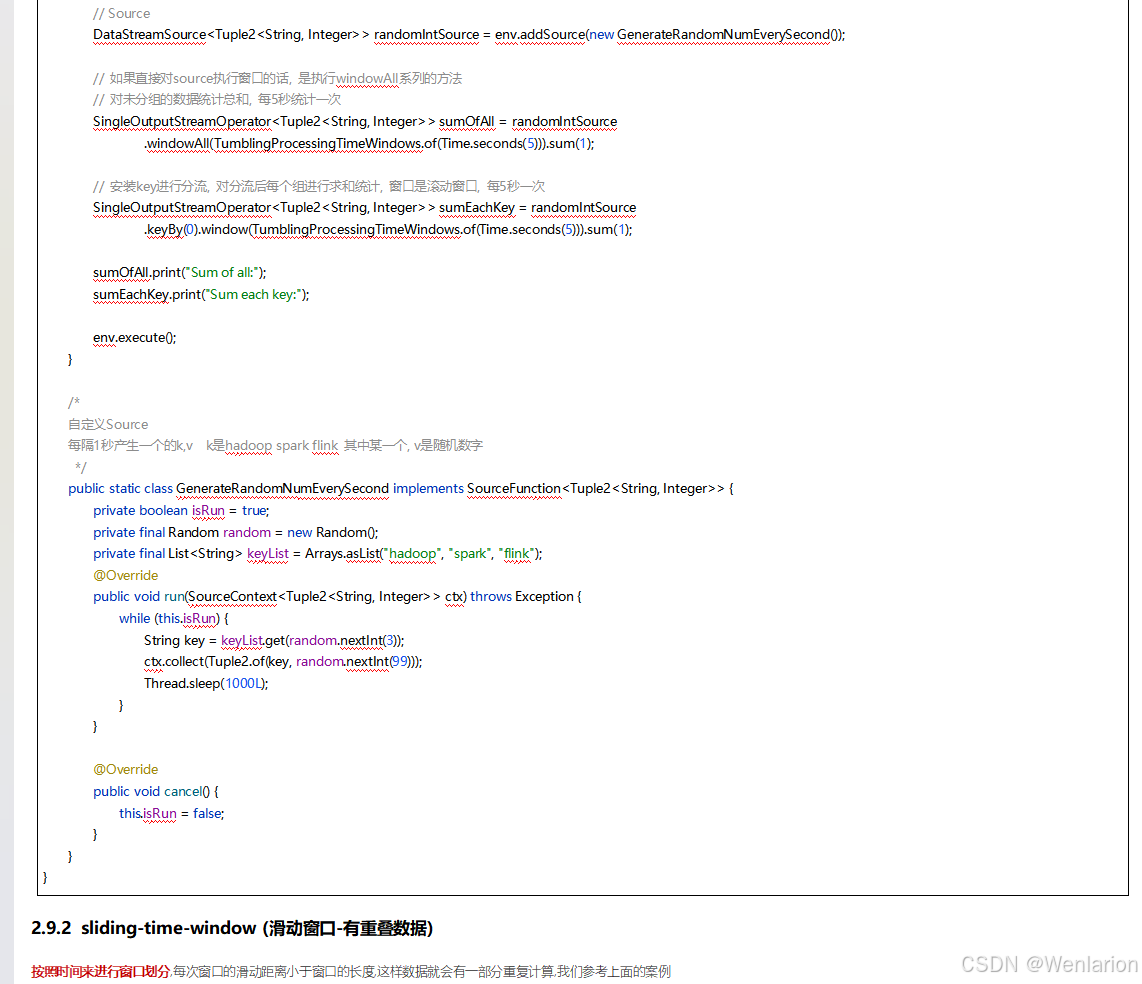
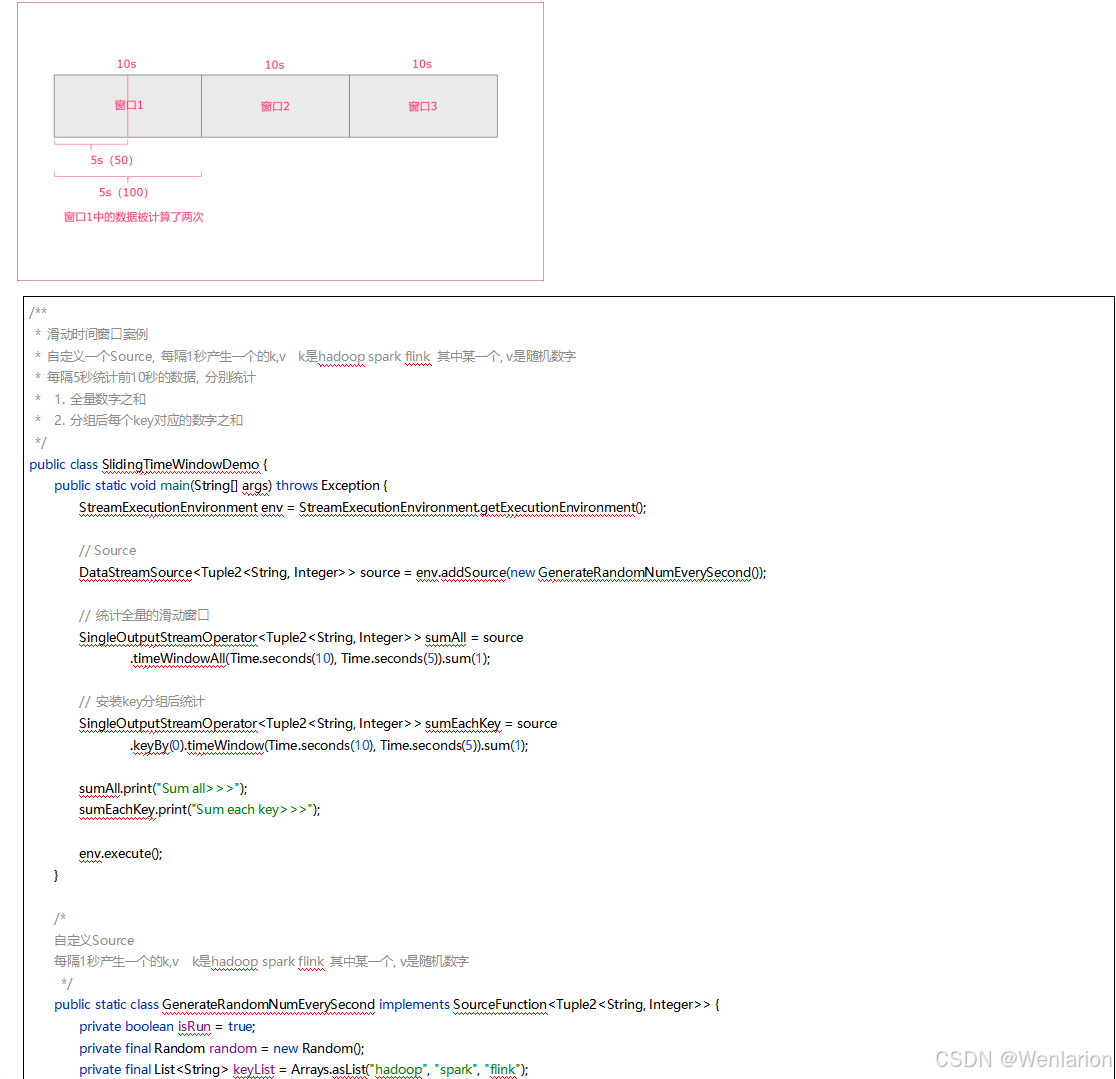
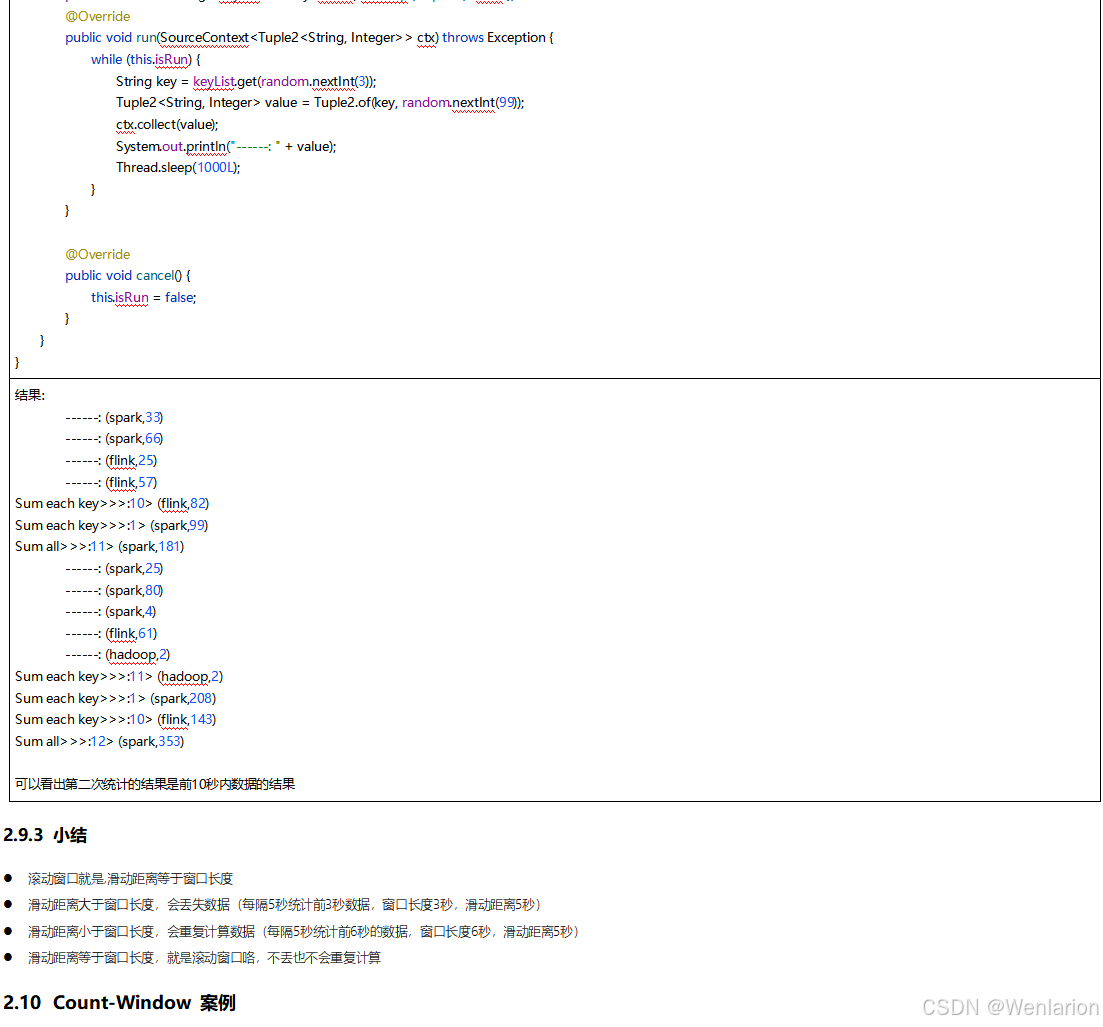
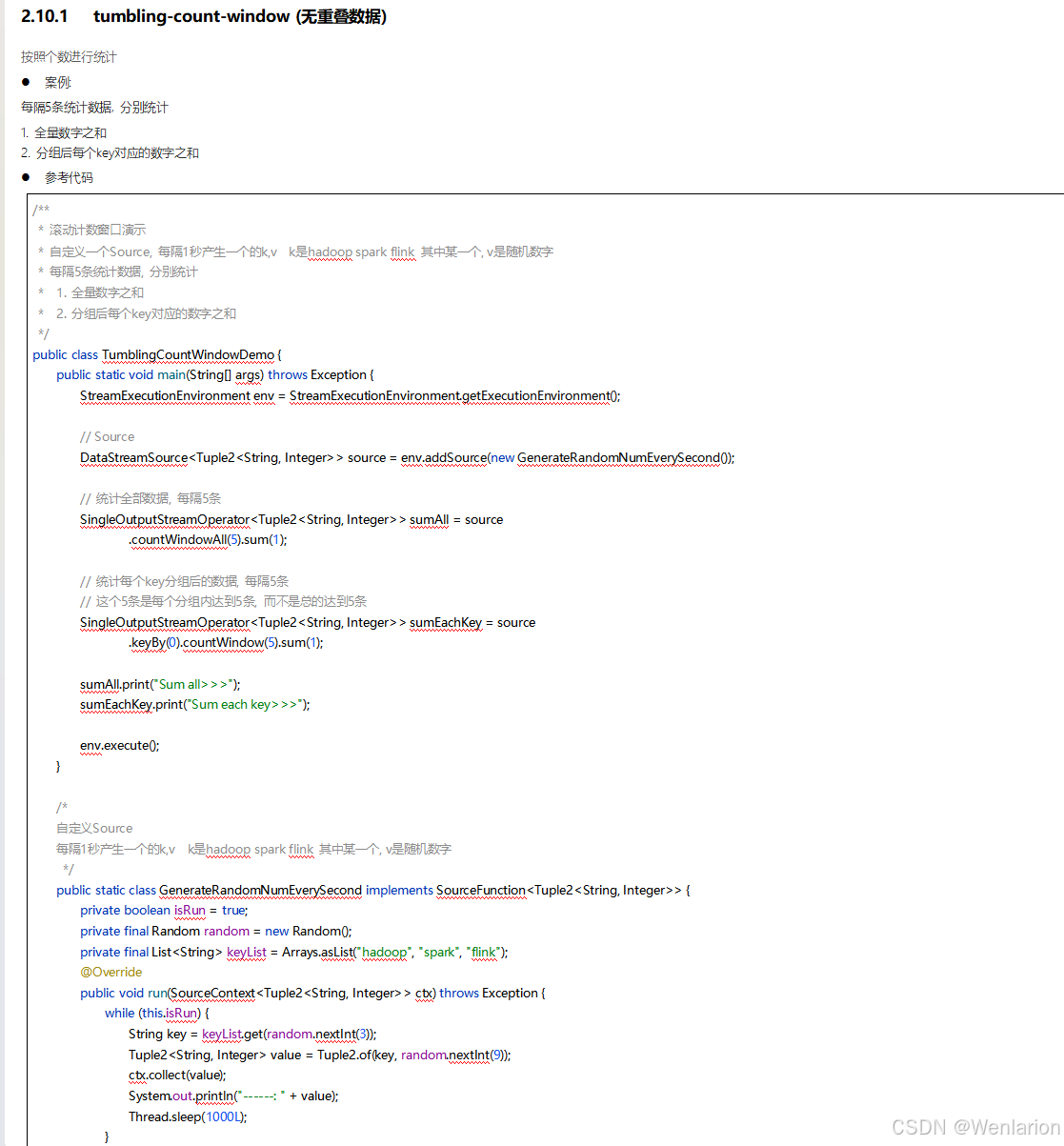
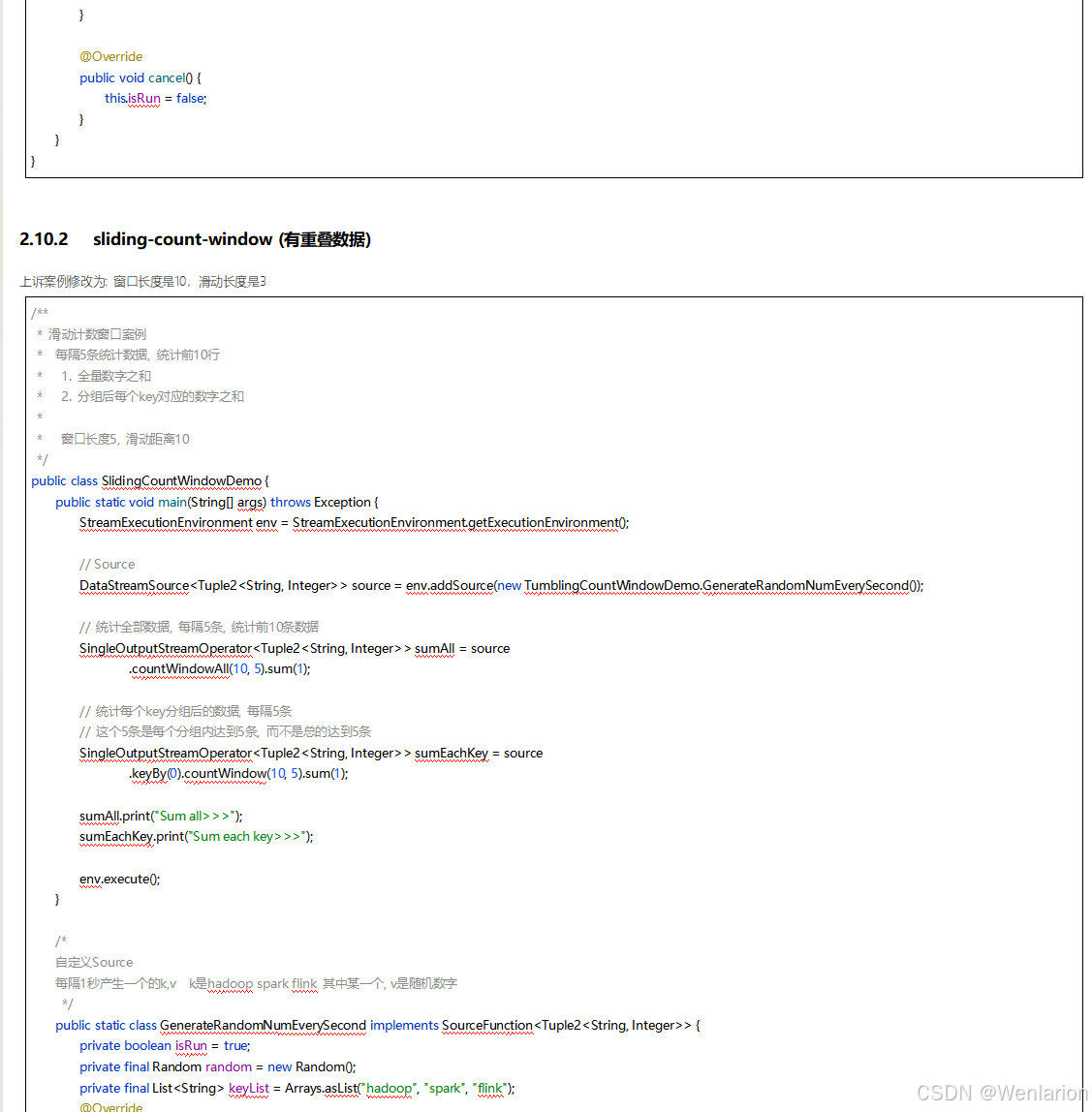

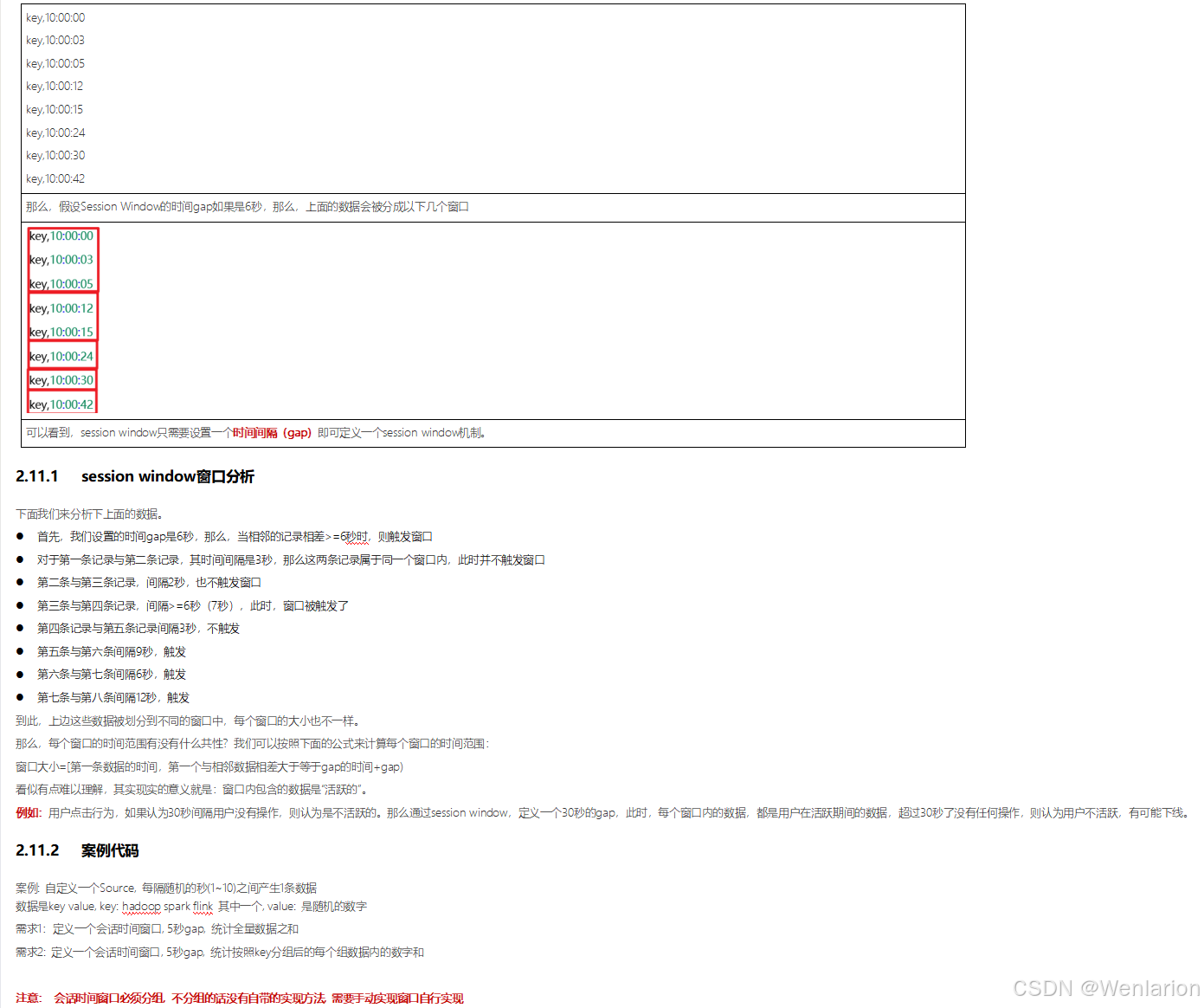
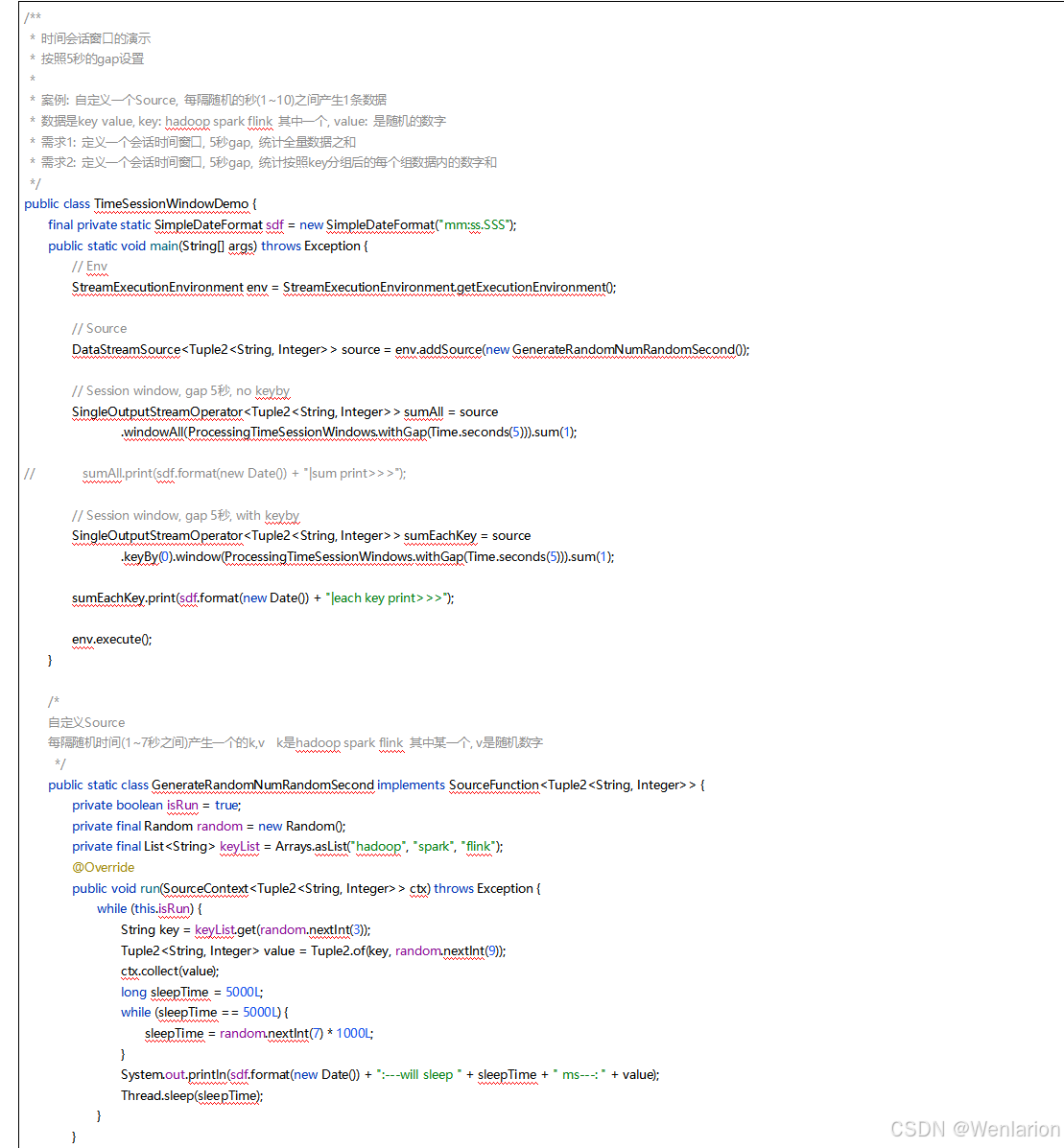

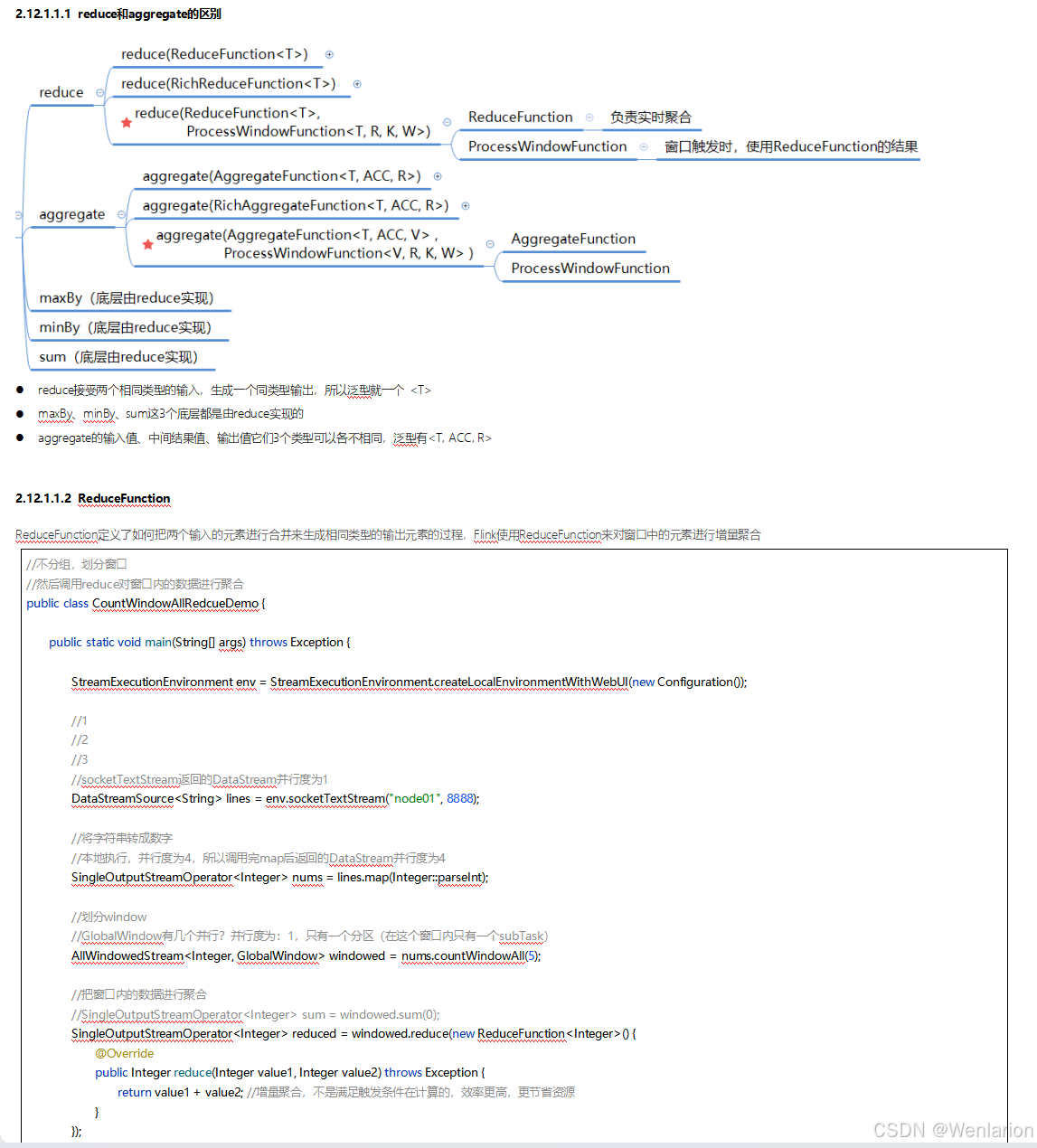
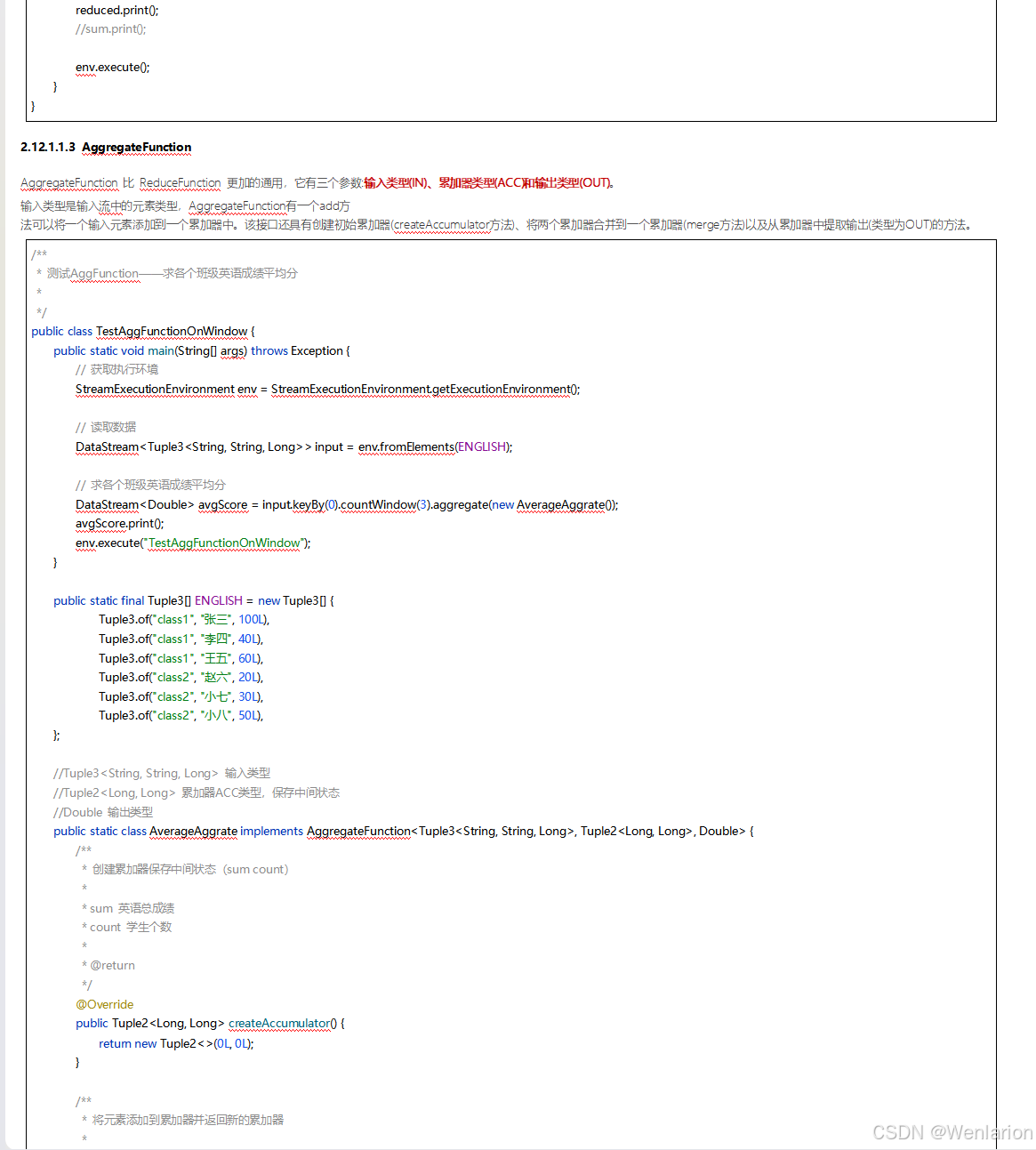
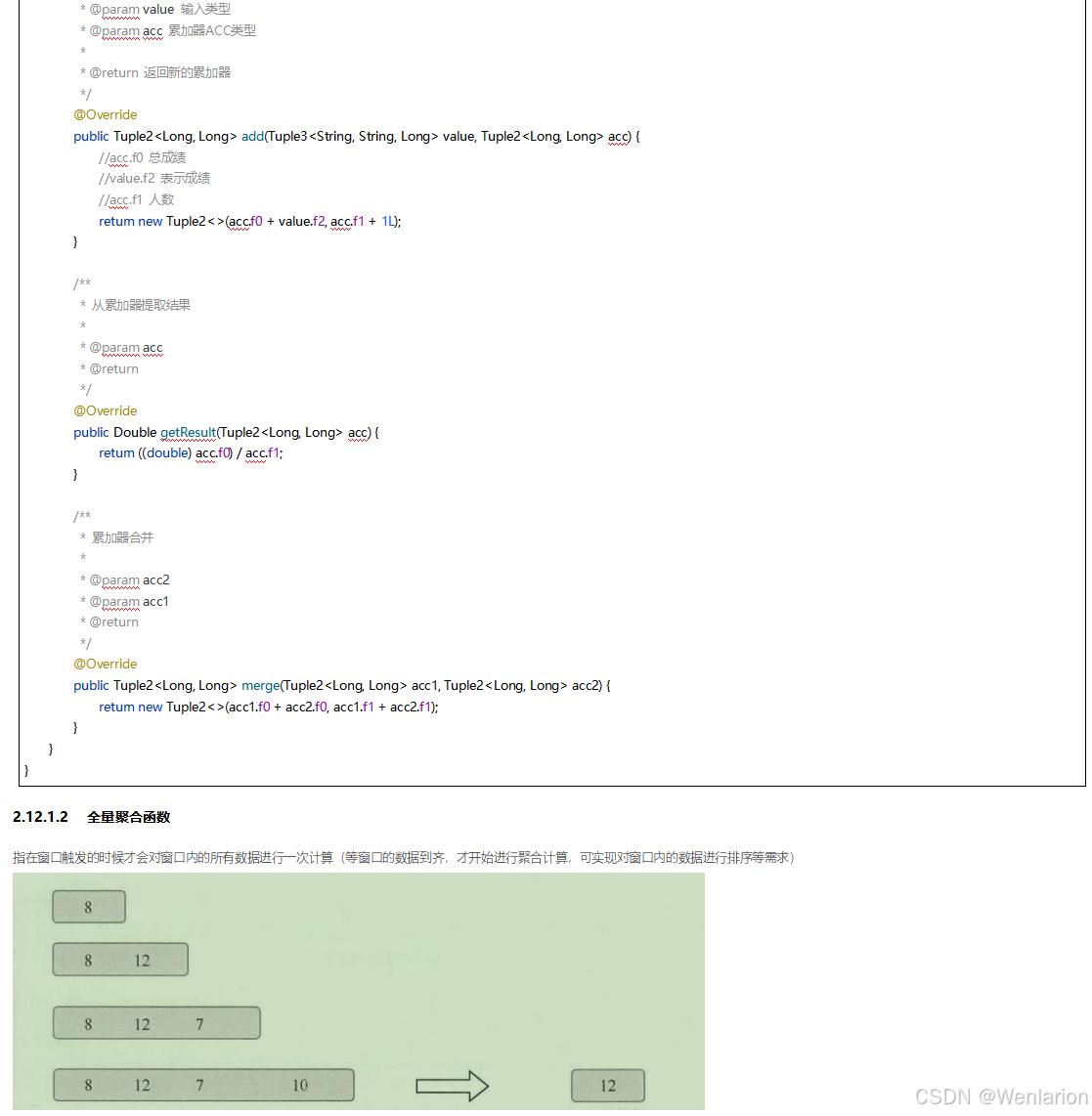
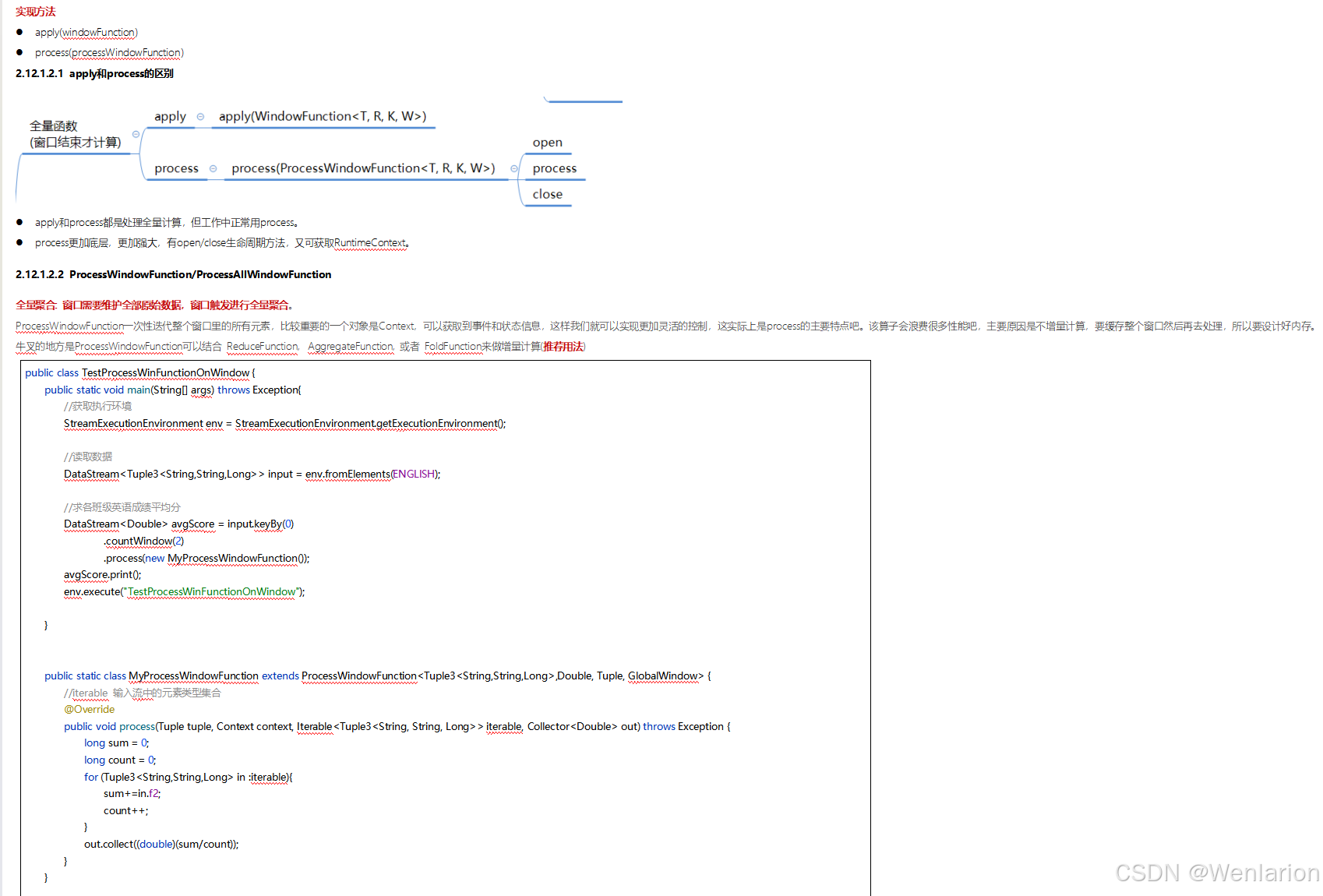
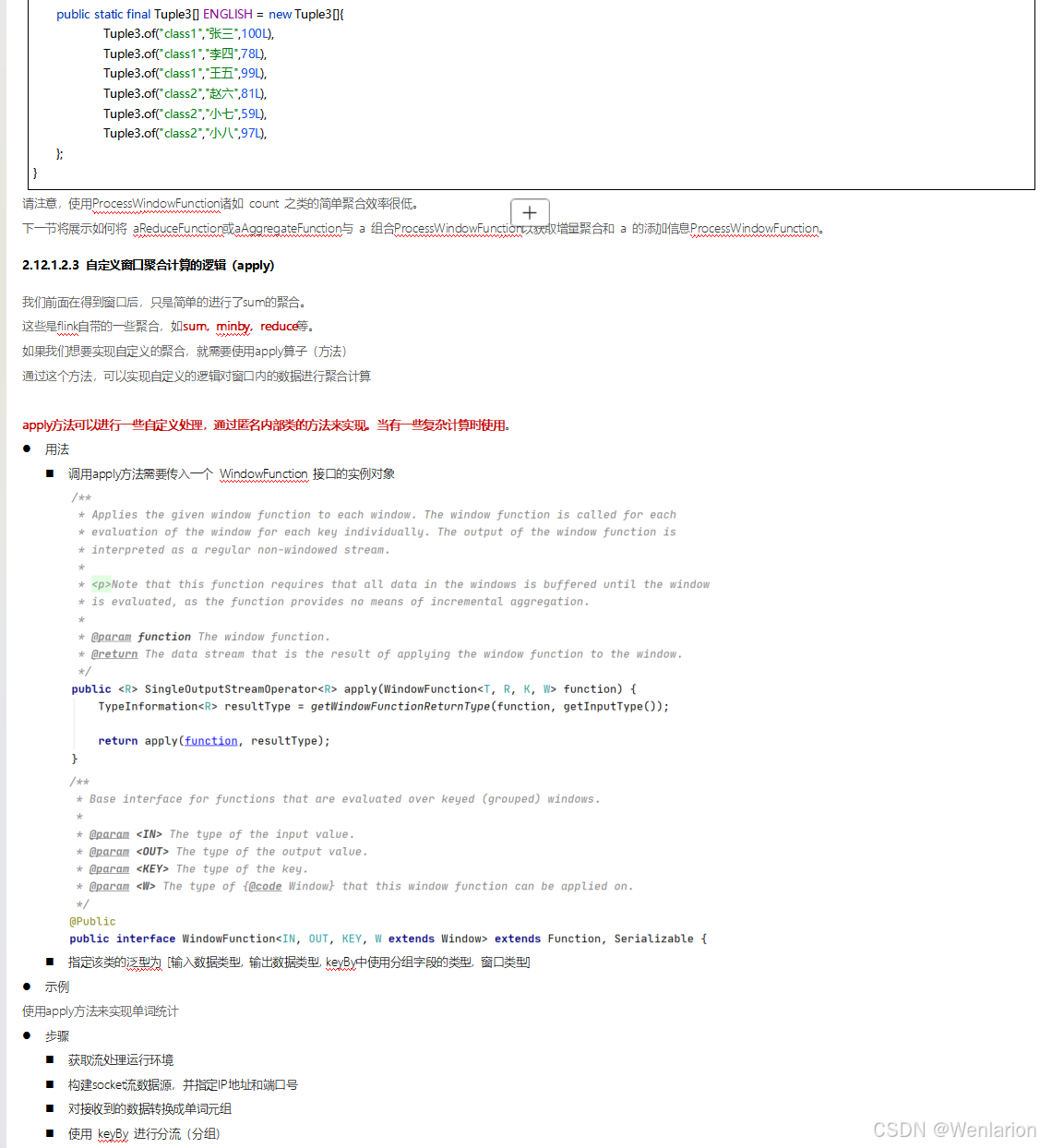
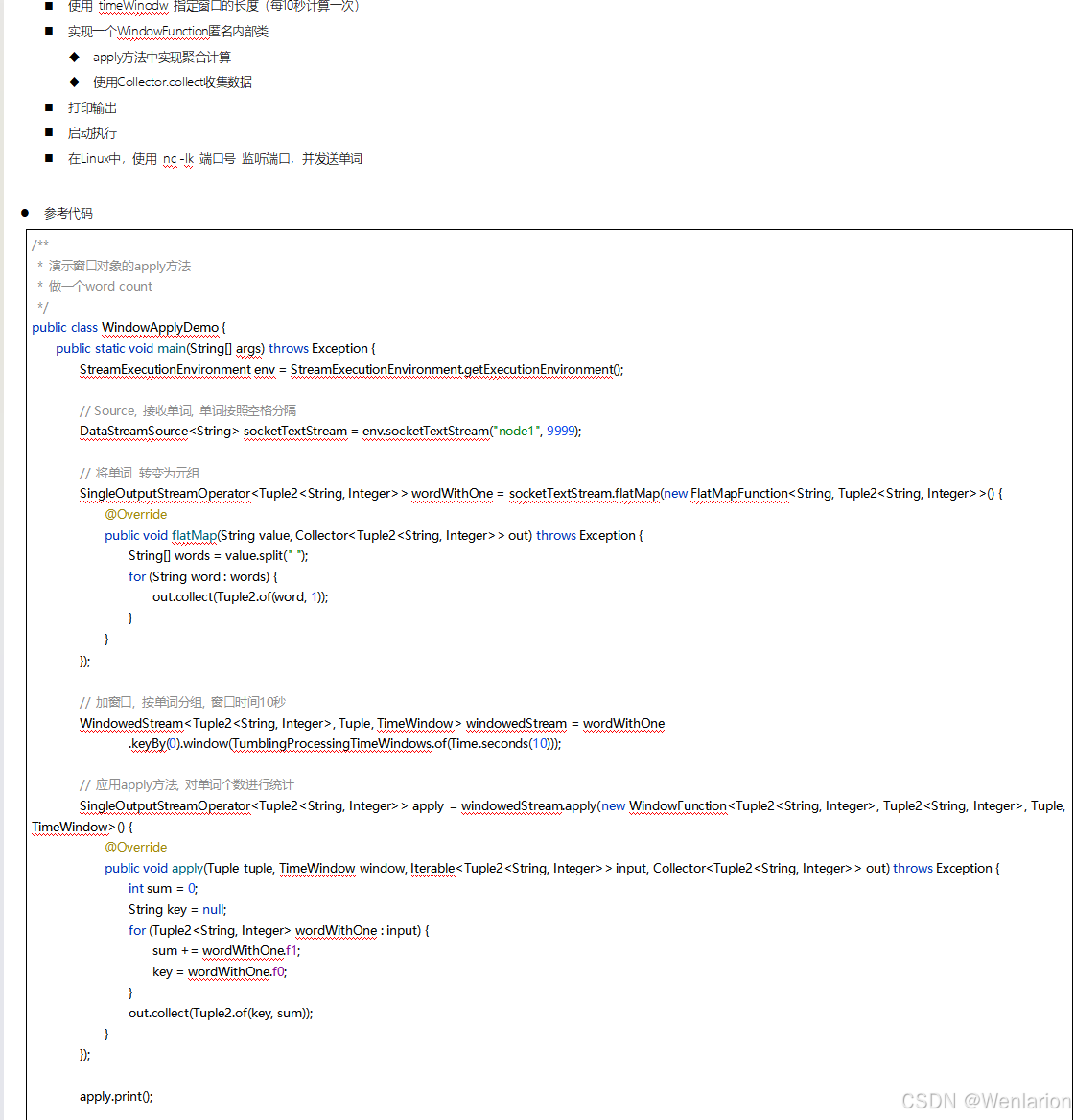

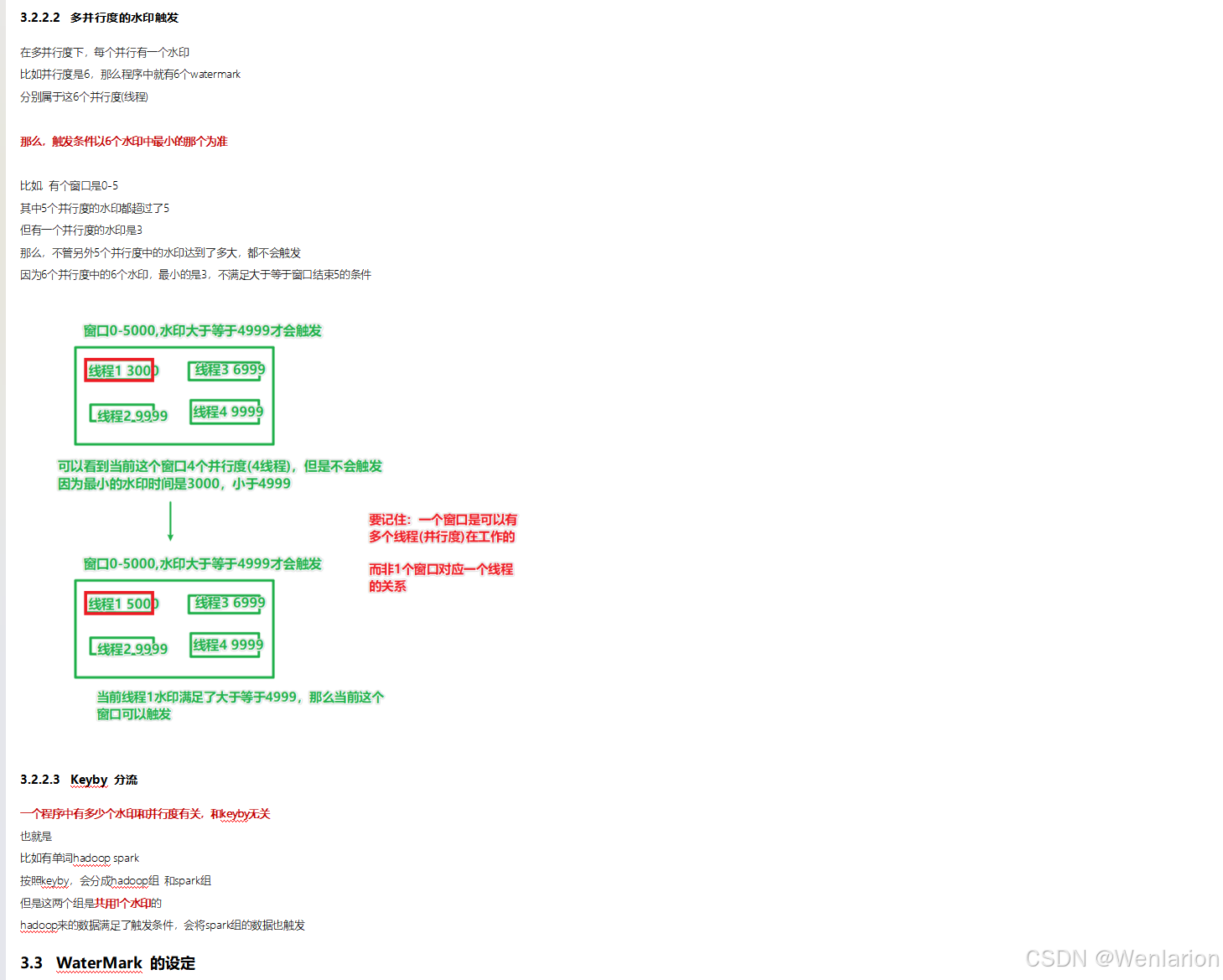
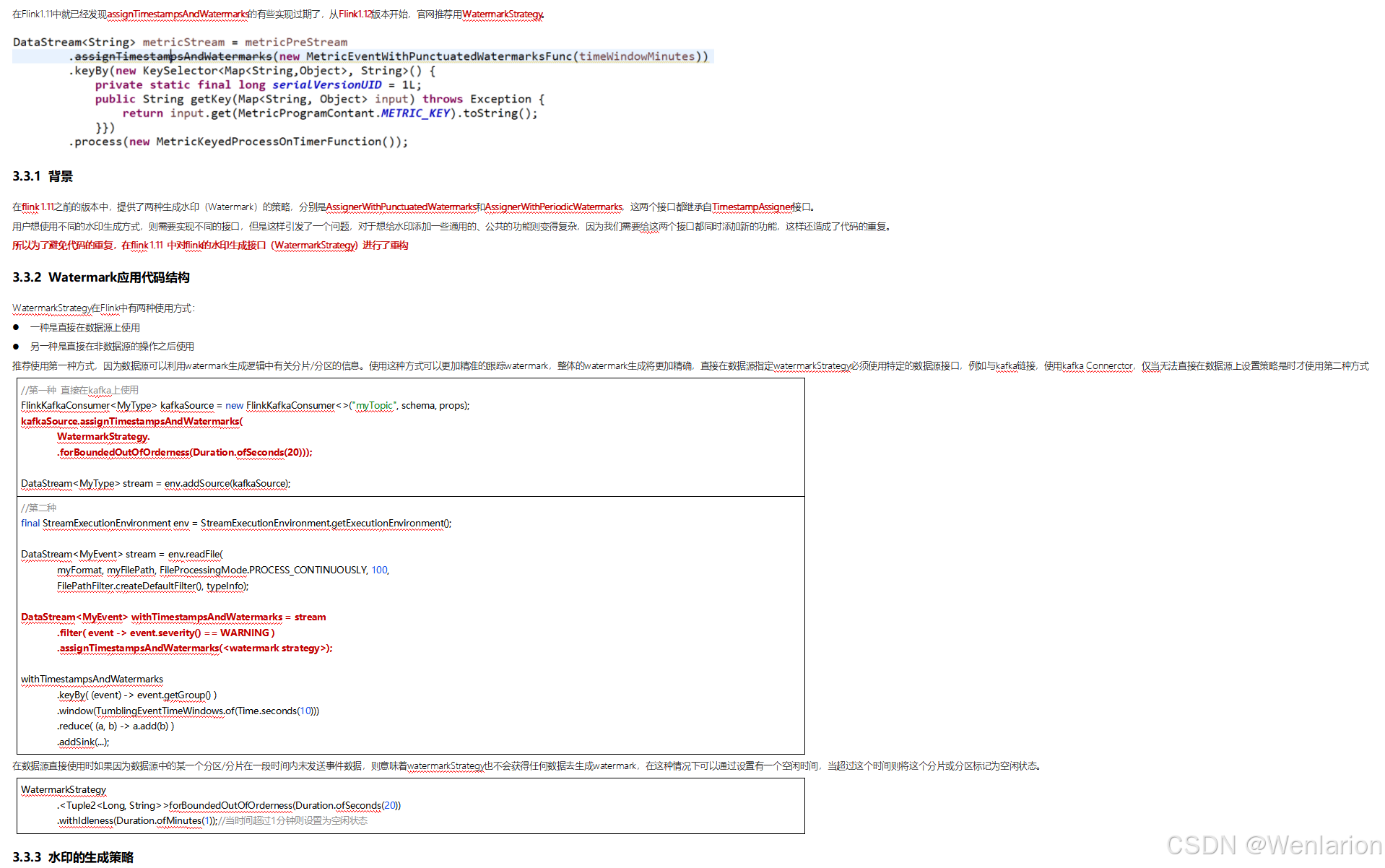
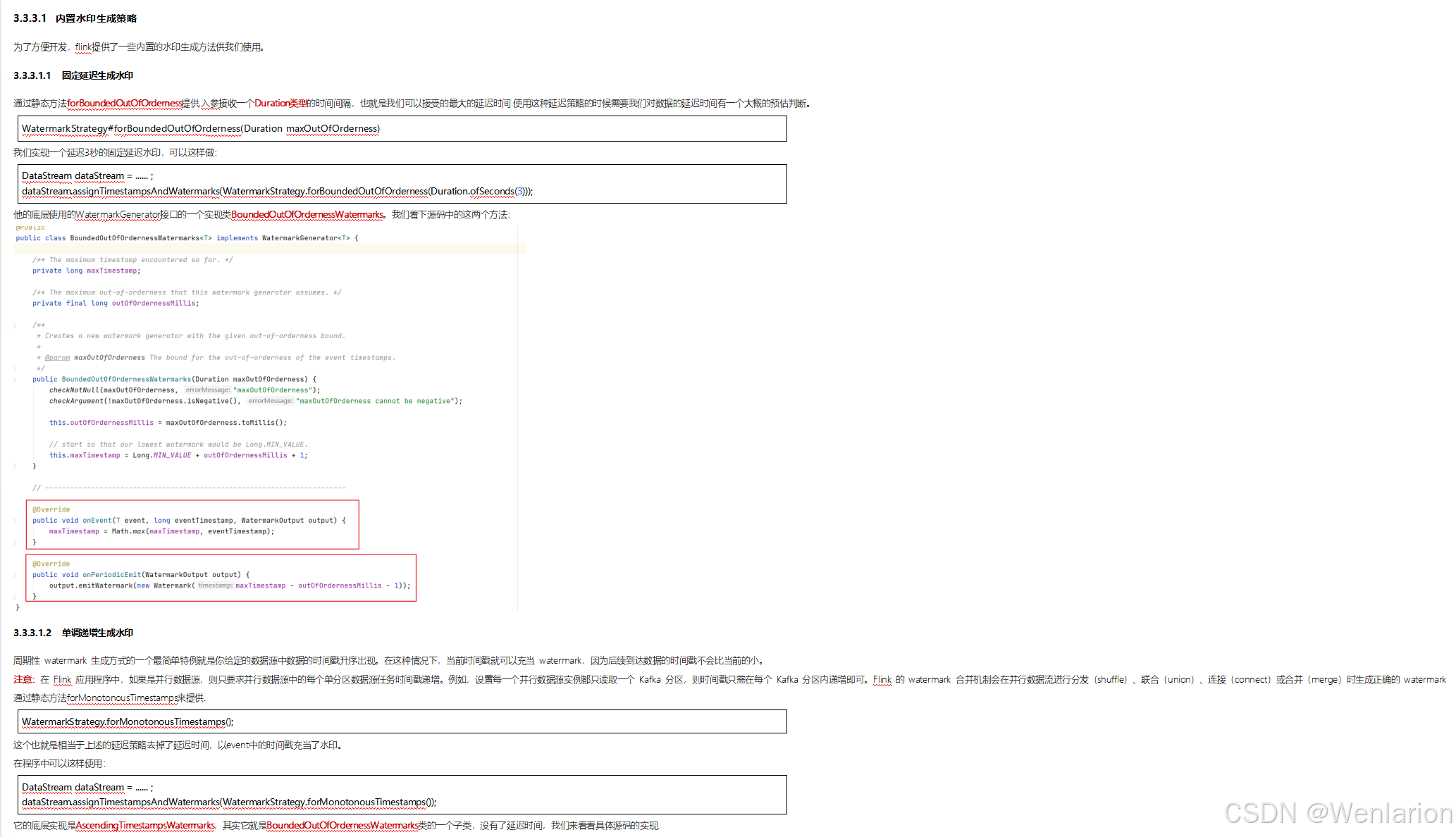
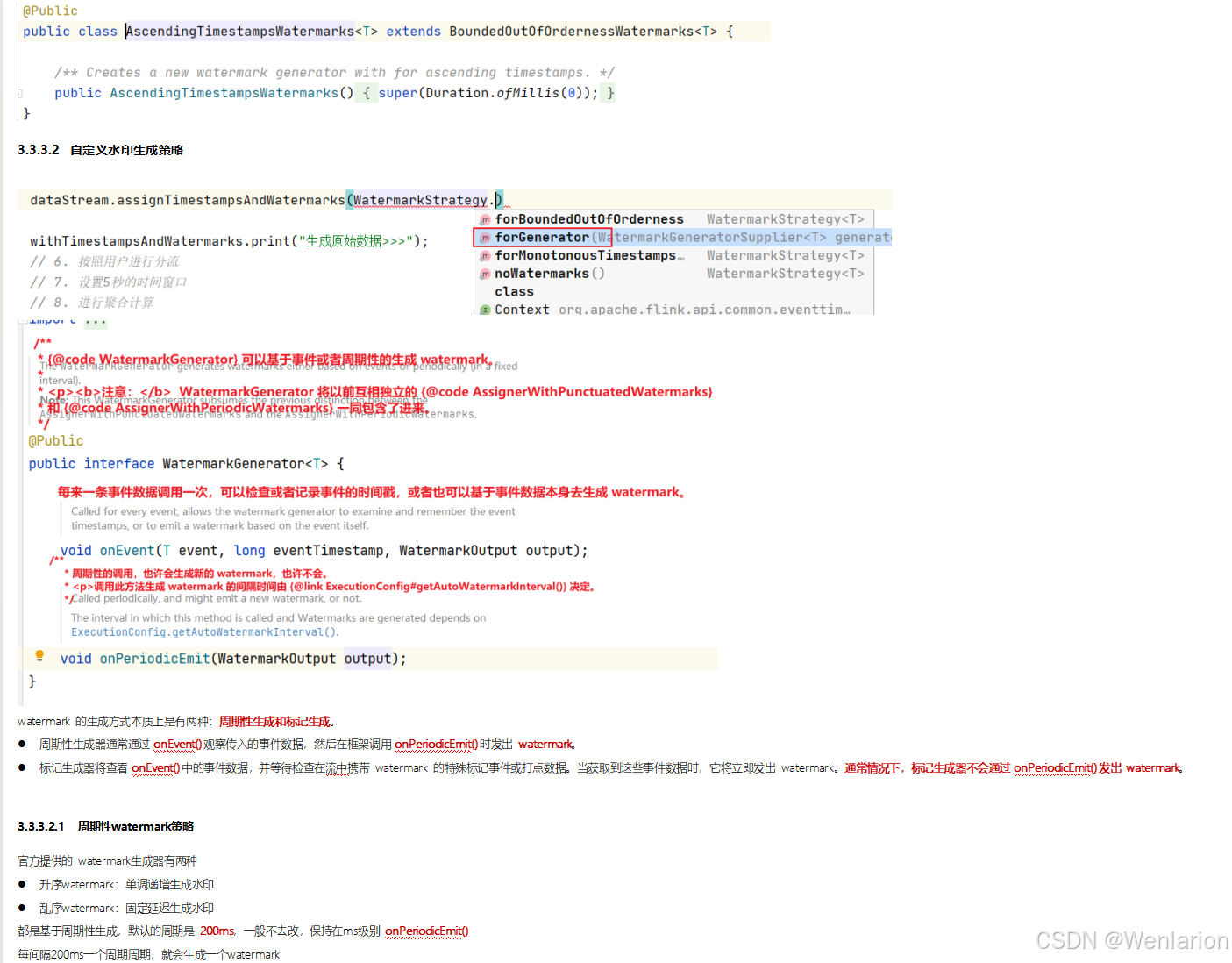
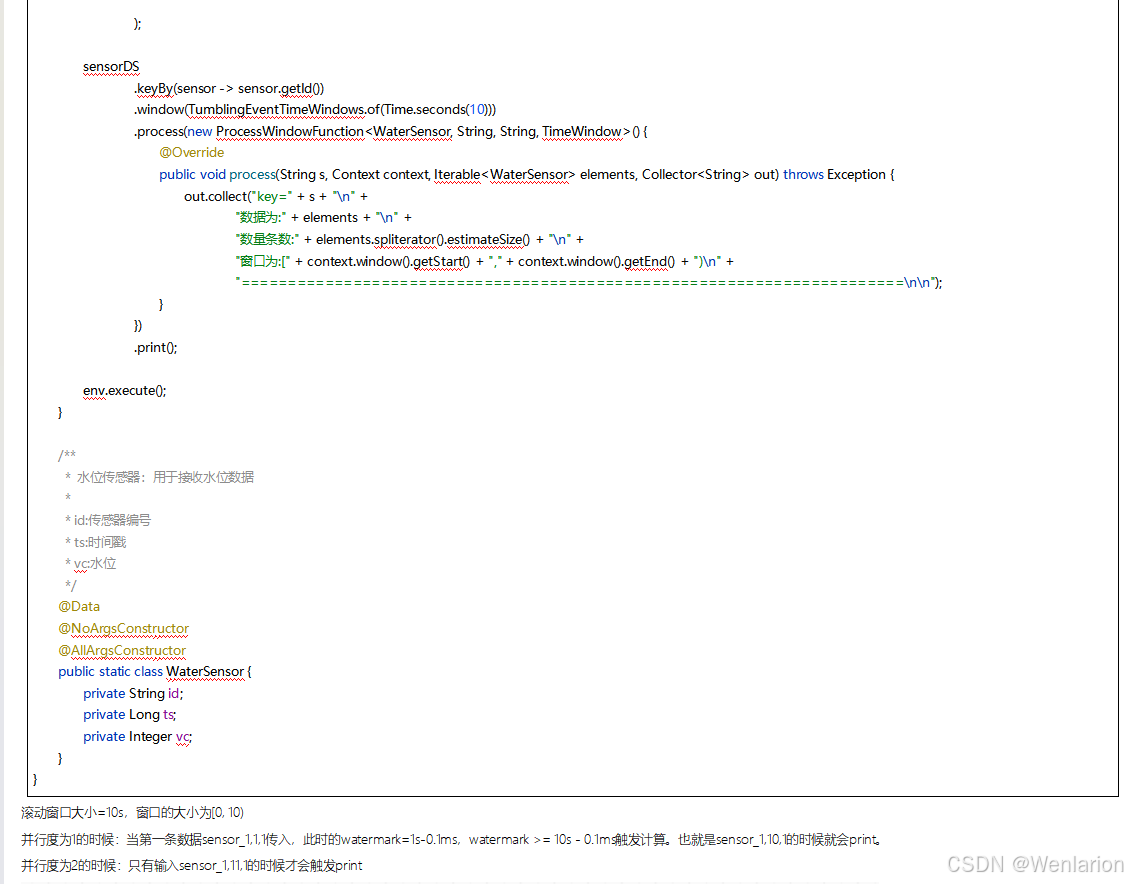
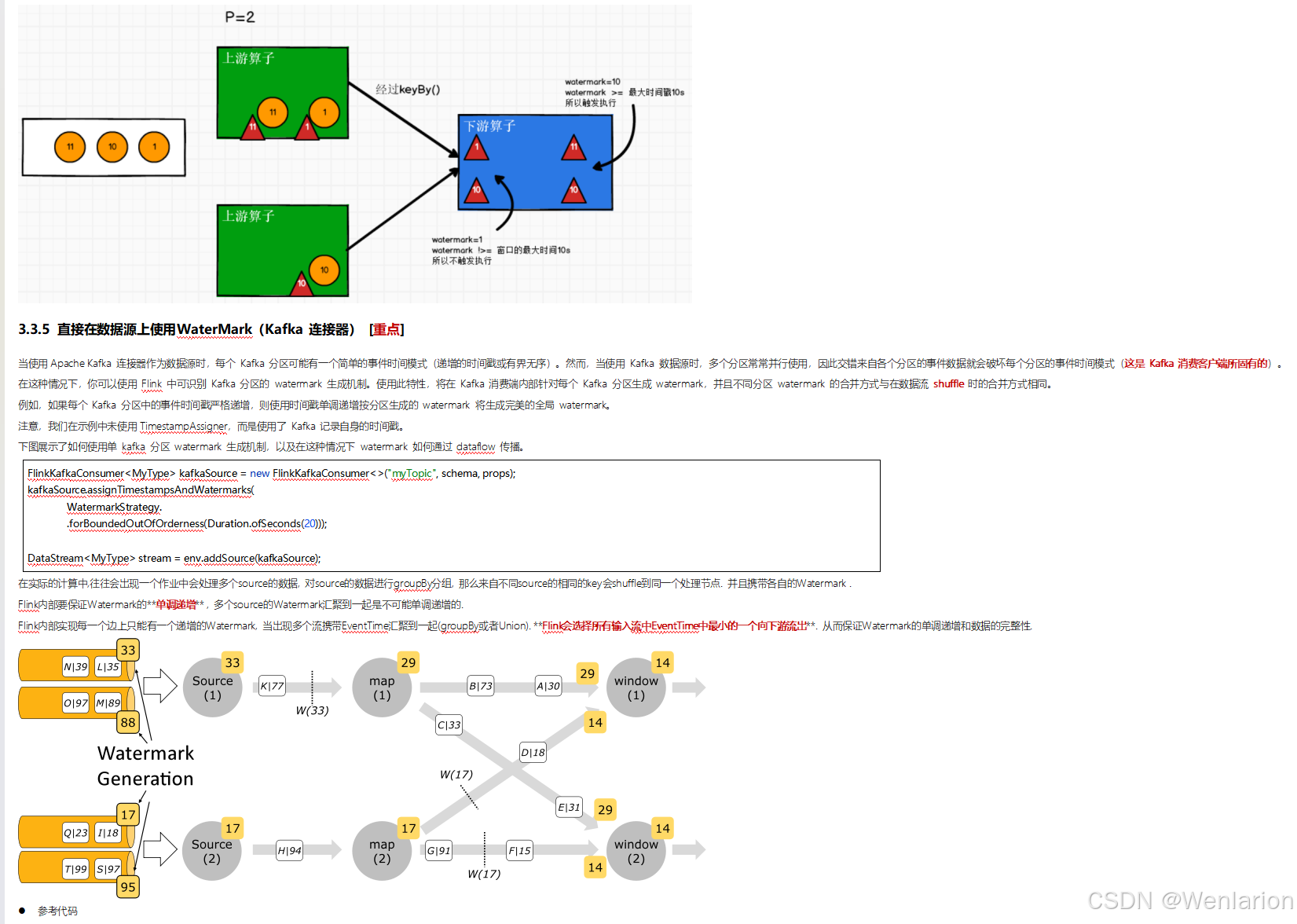
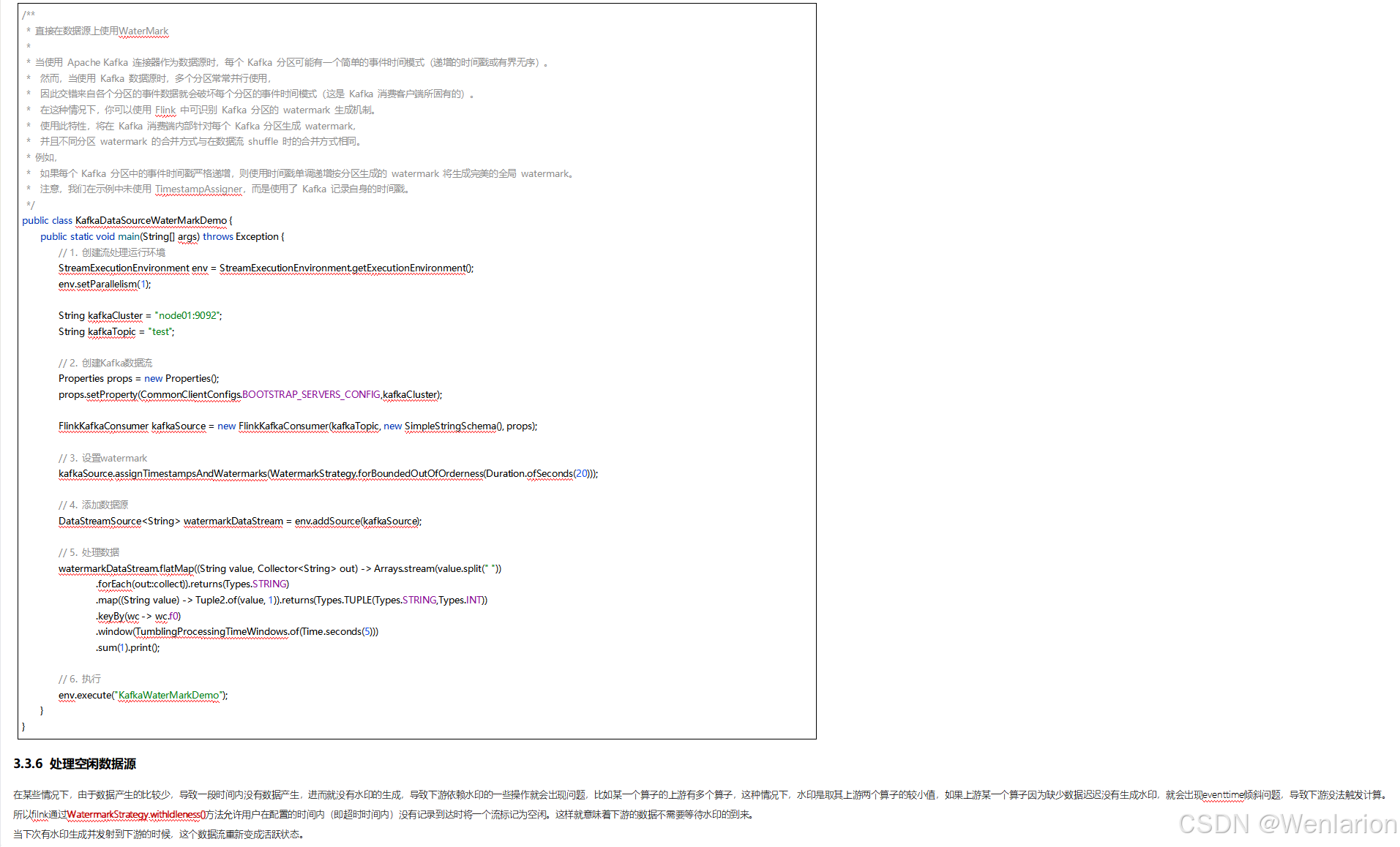
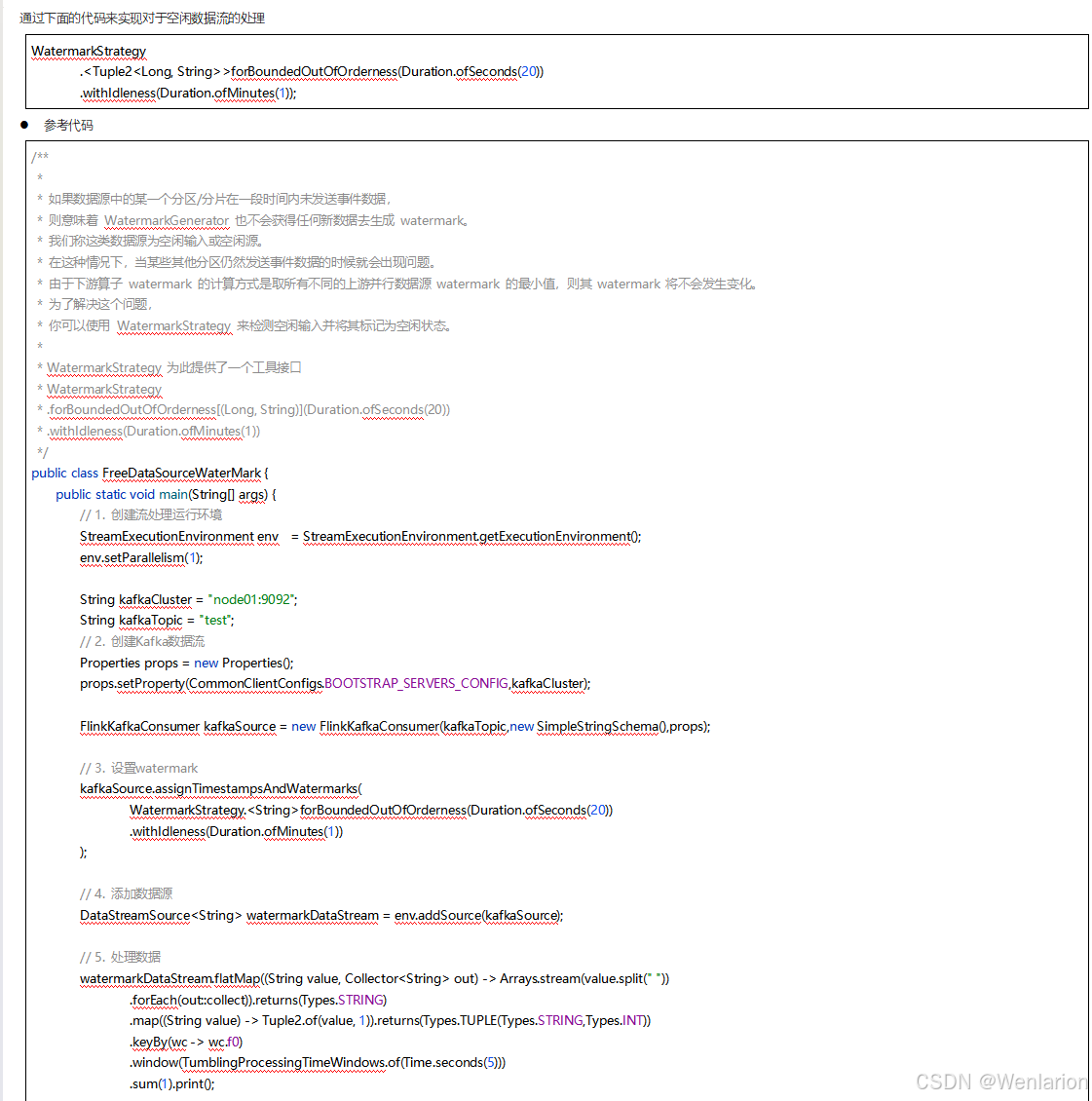
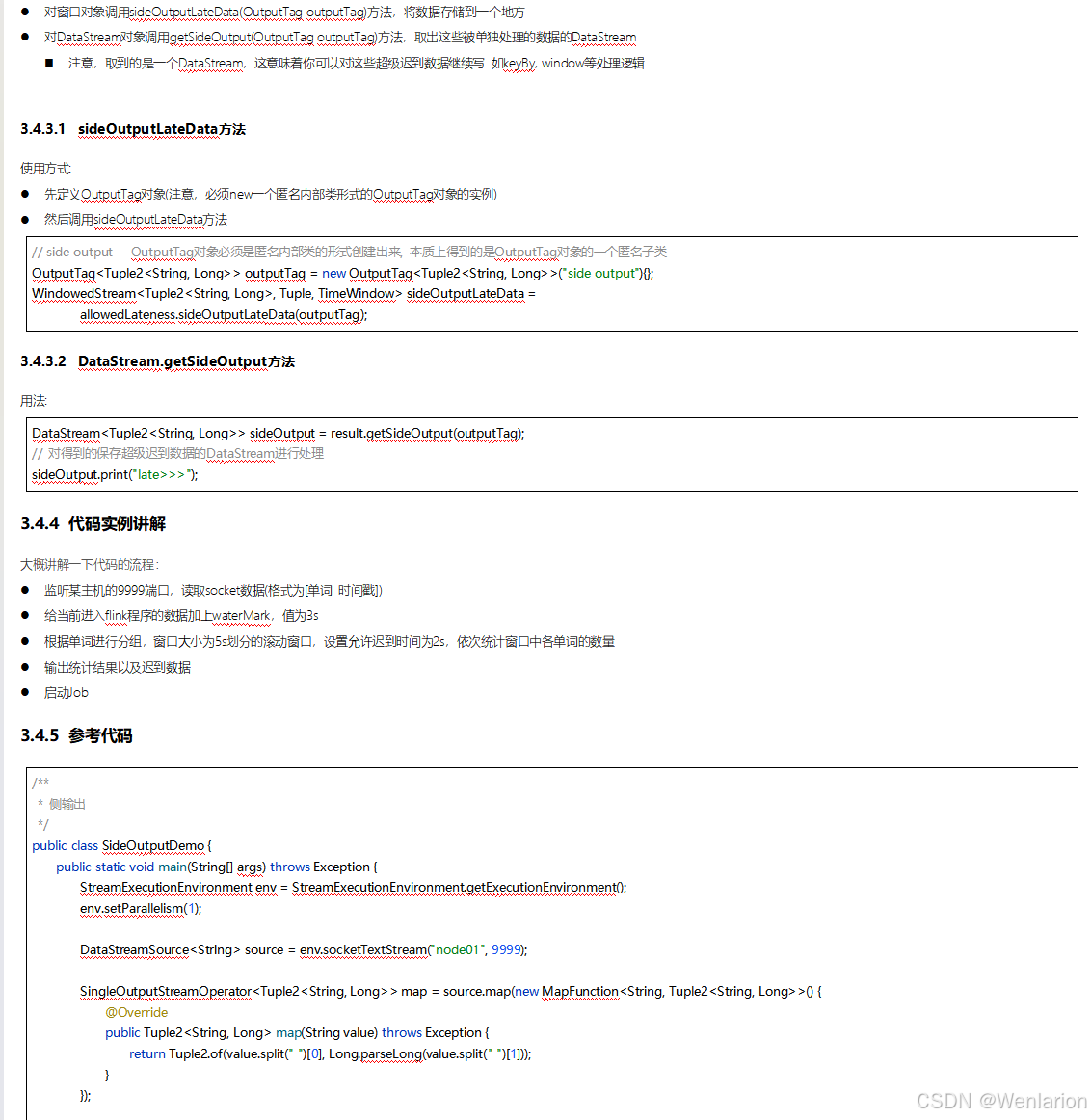
3、WaterMark


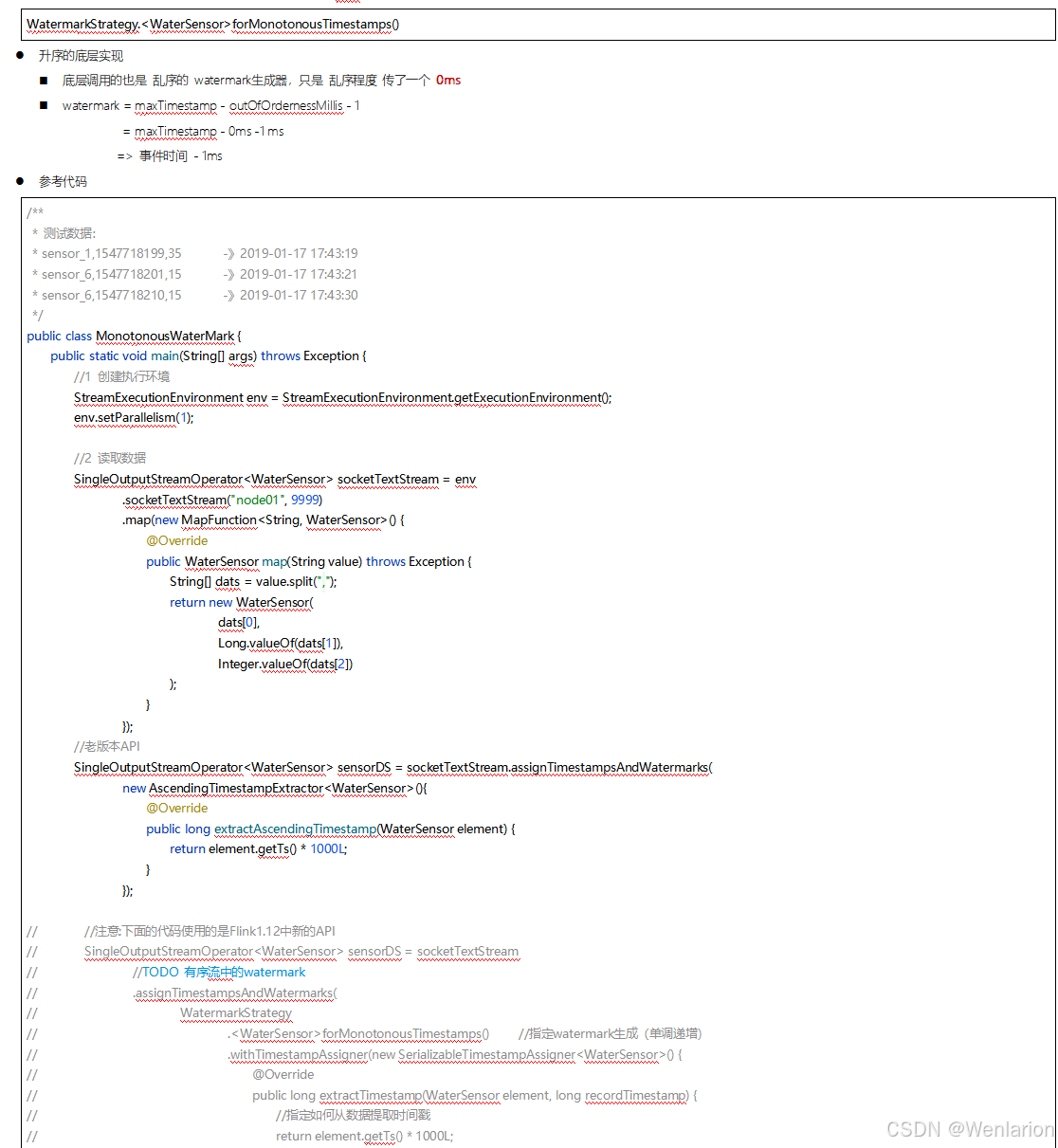
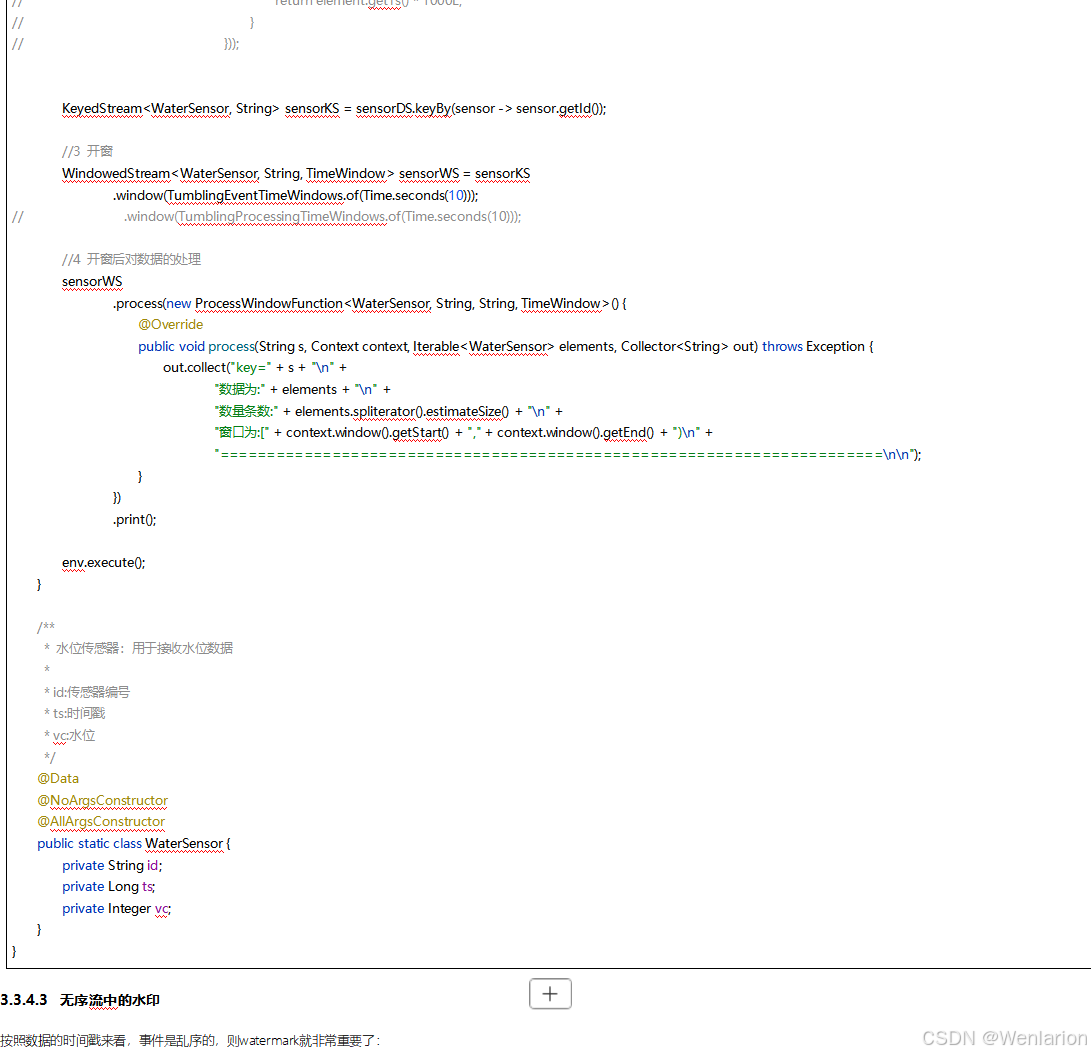
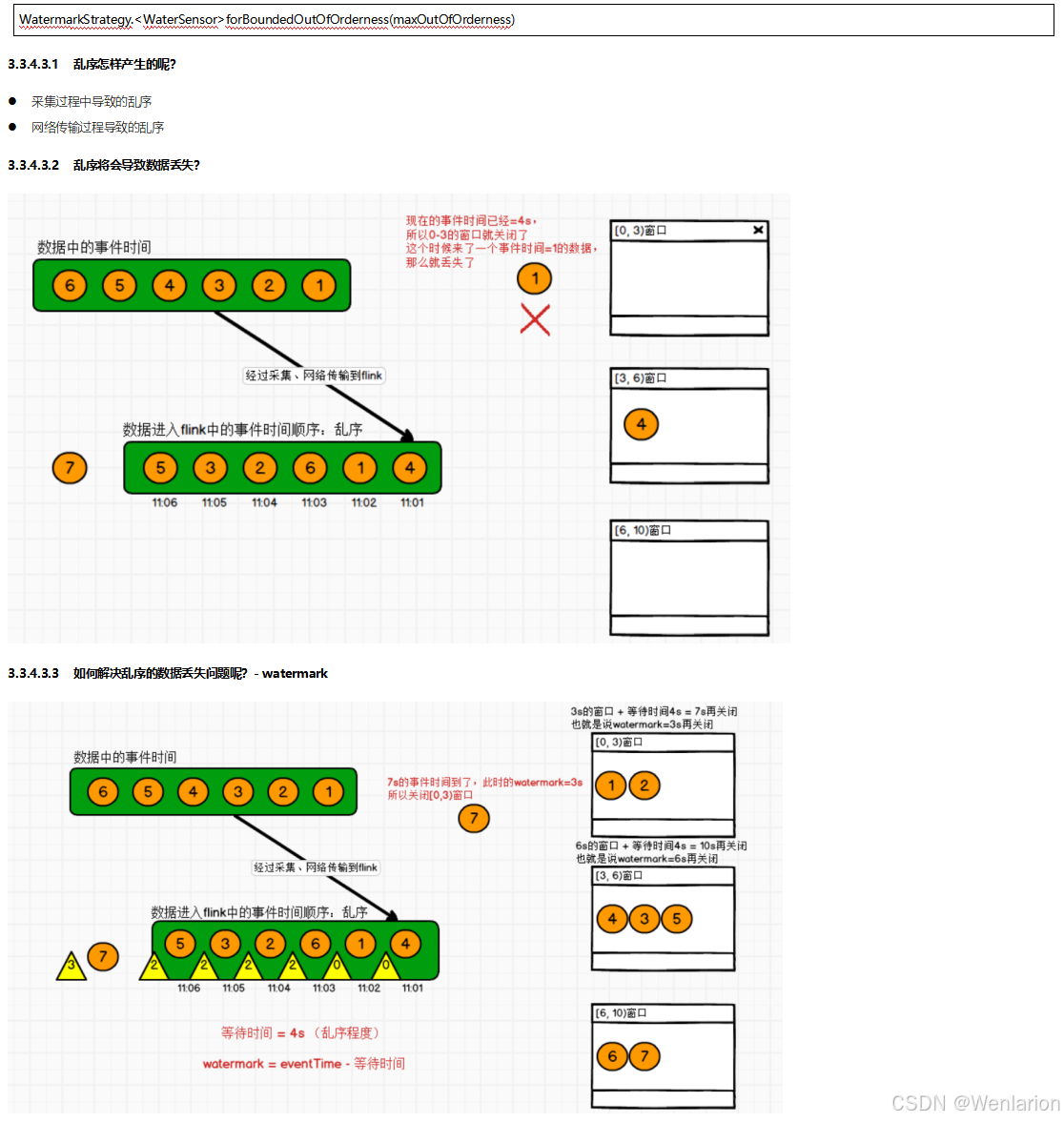
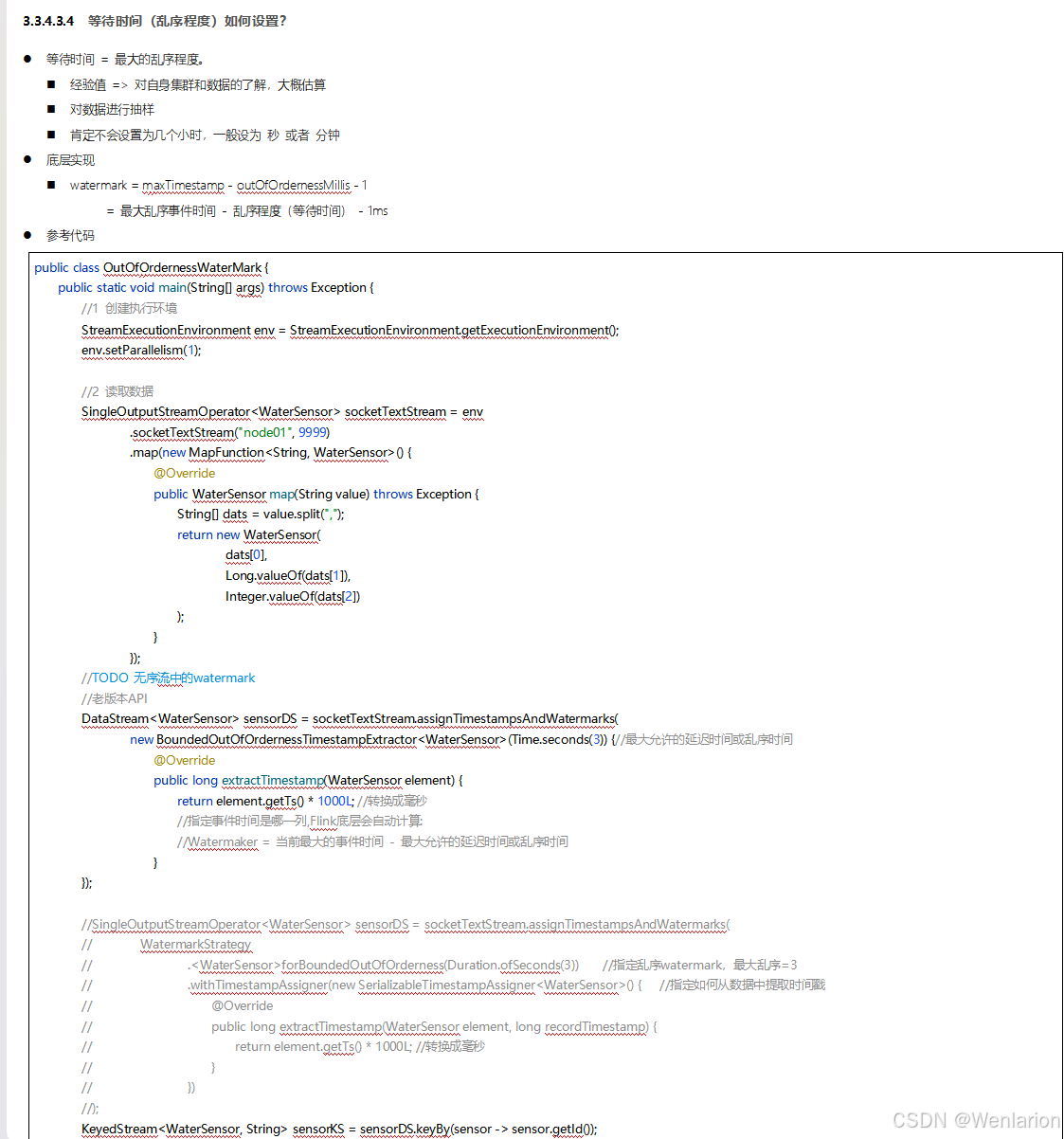


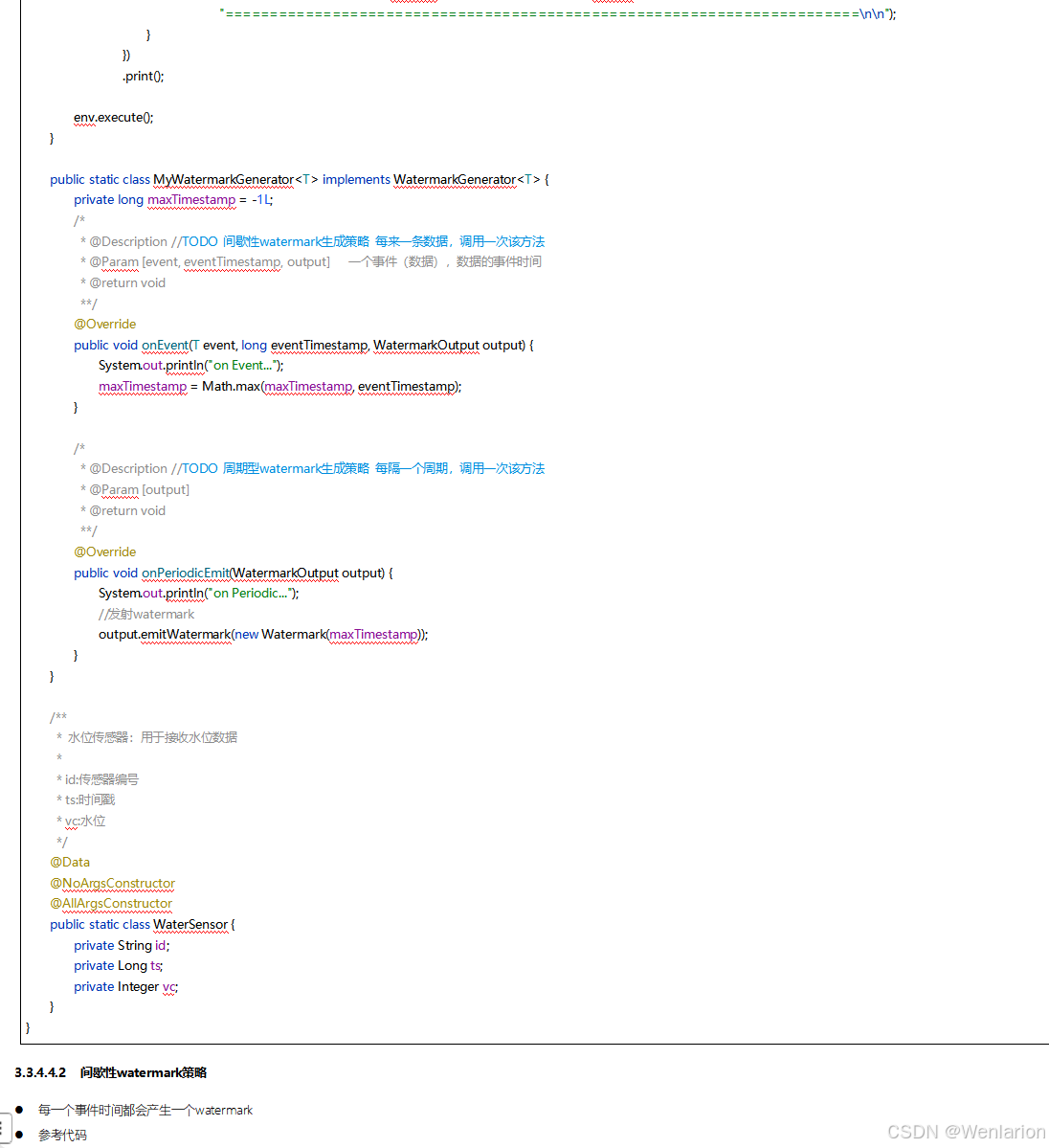
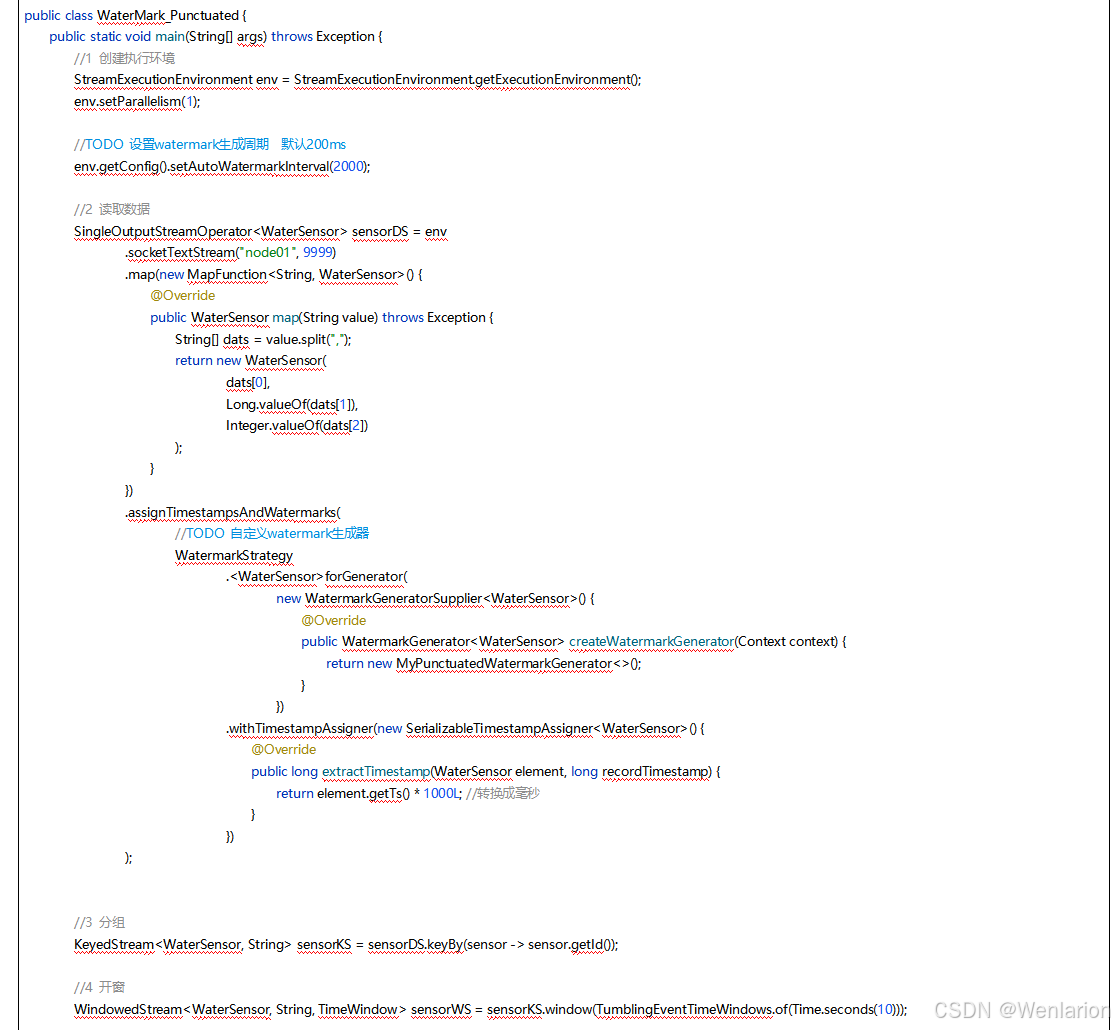
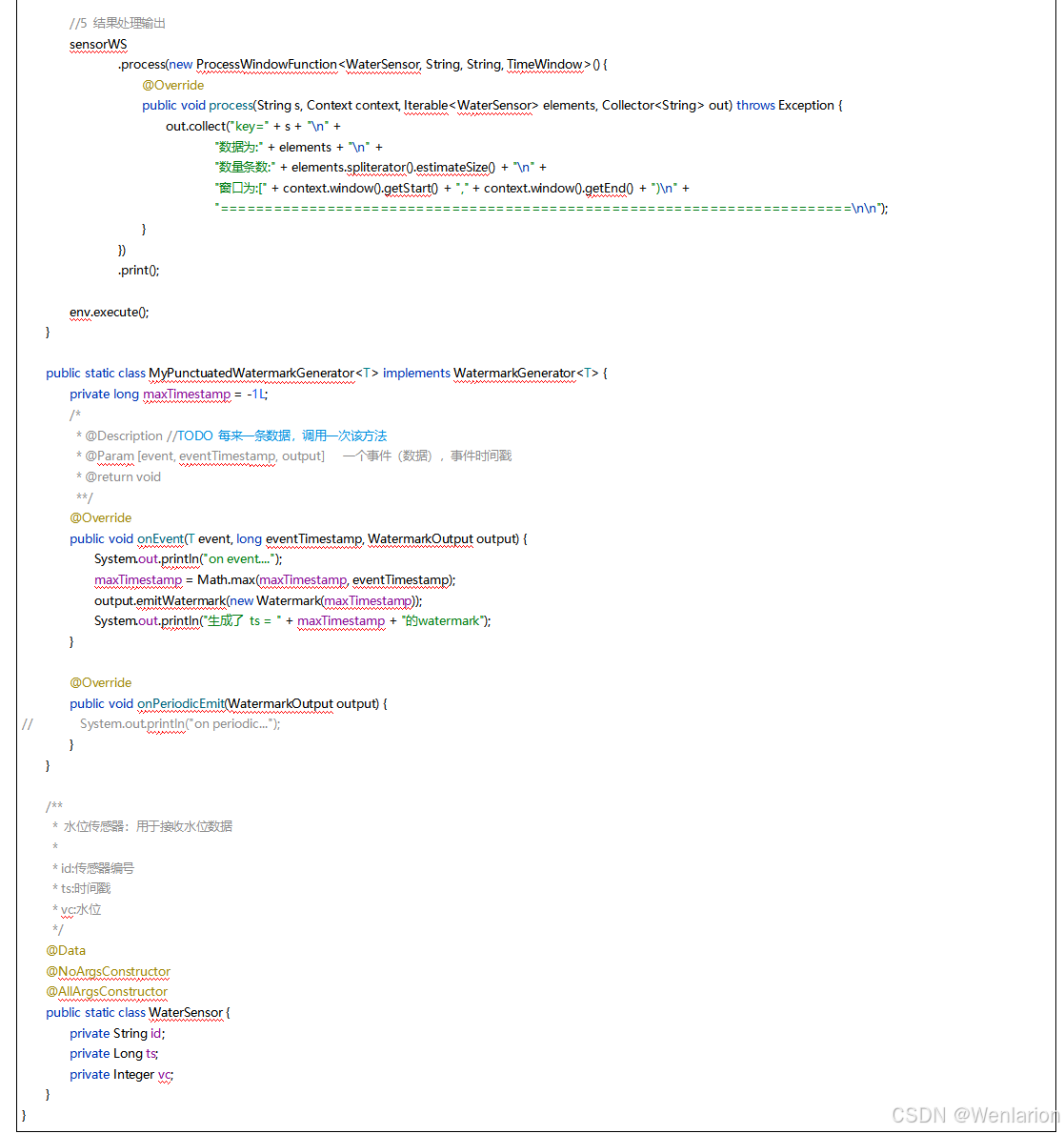
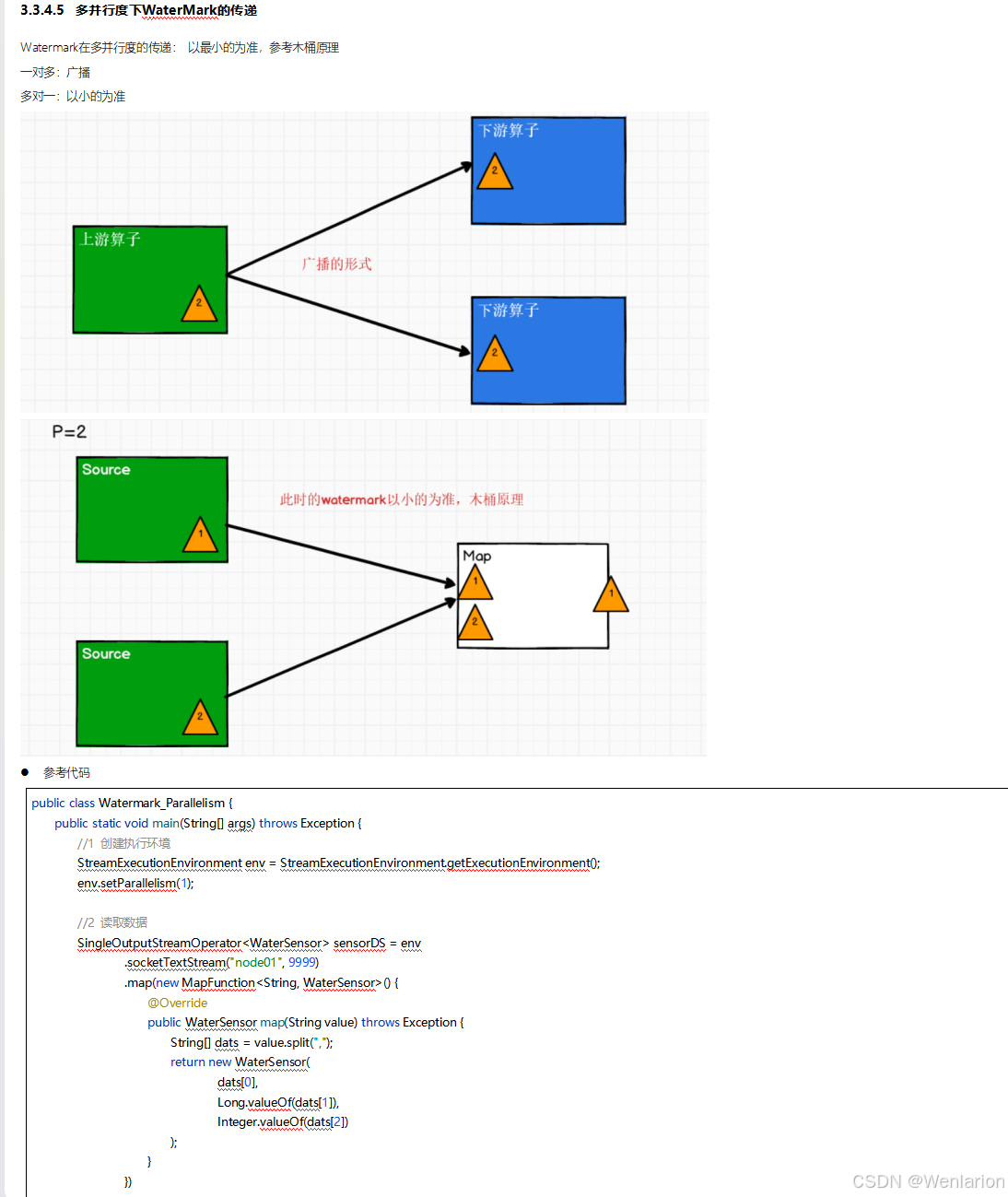




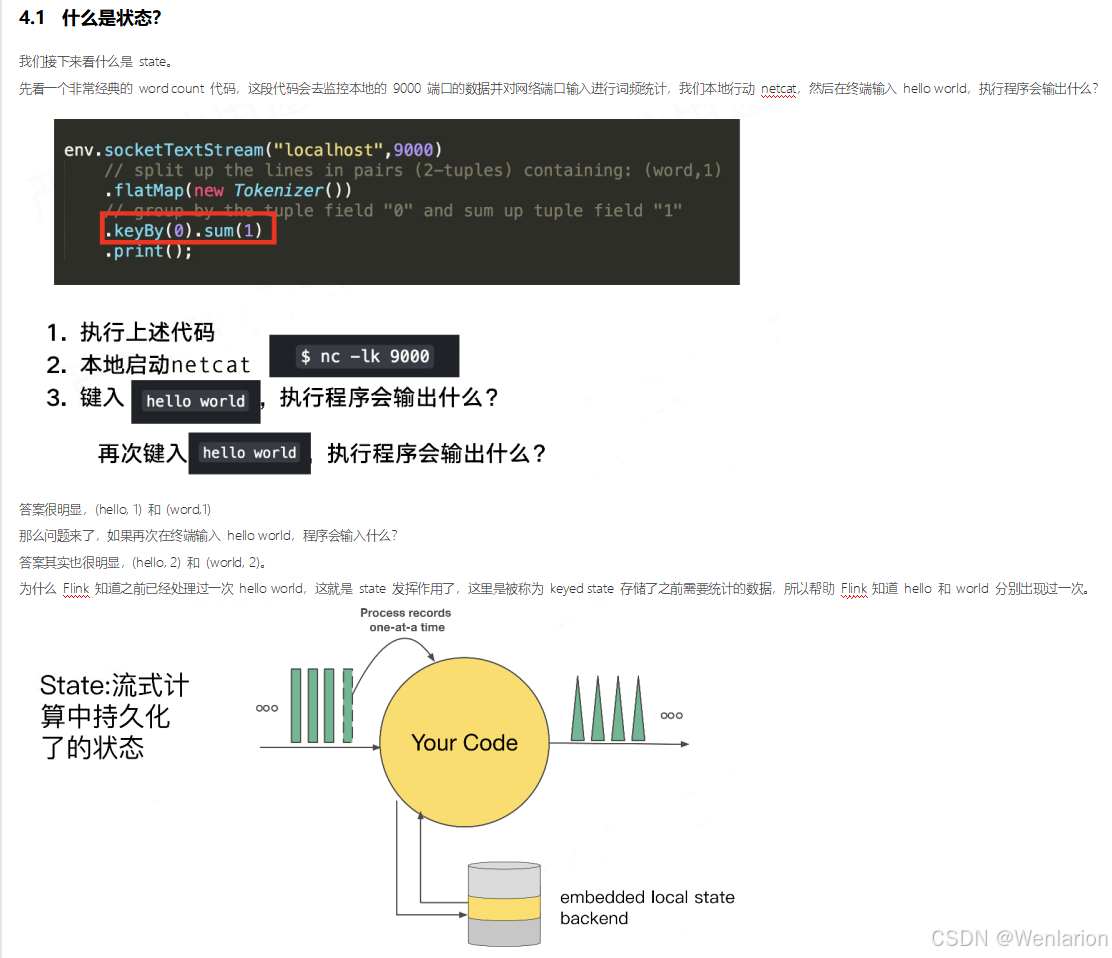
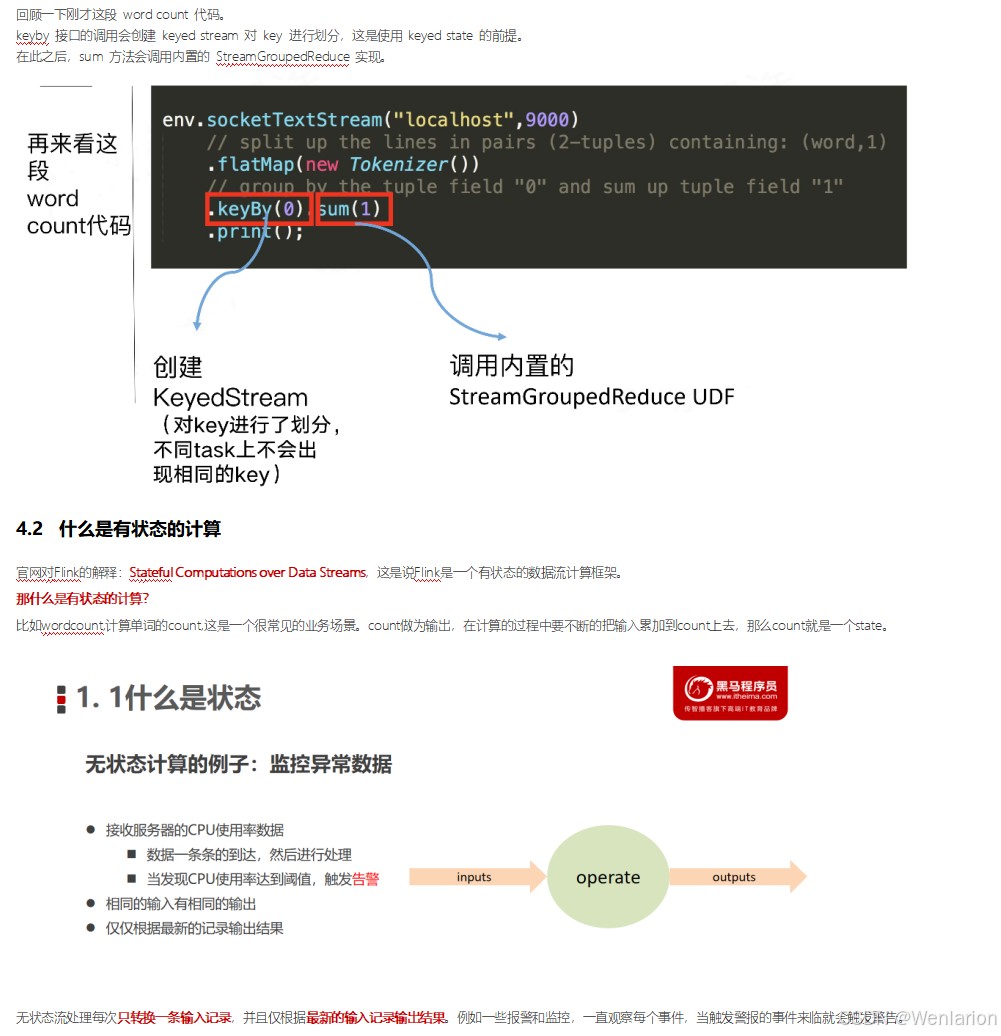
4、Flink的状态管理


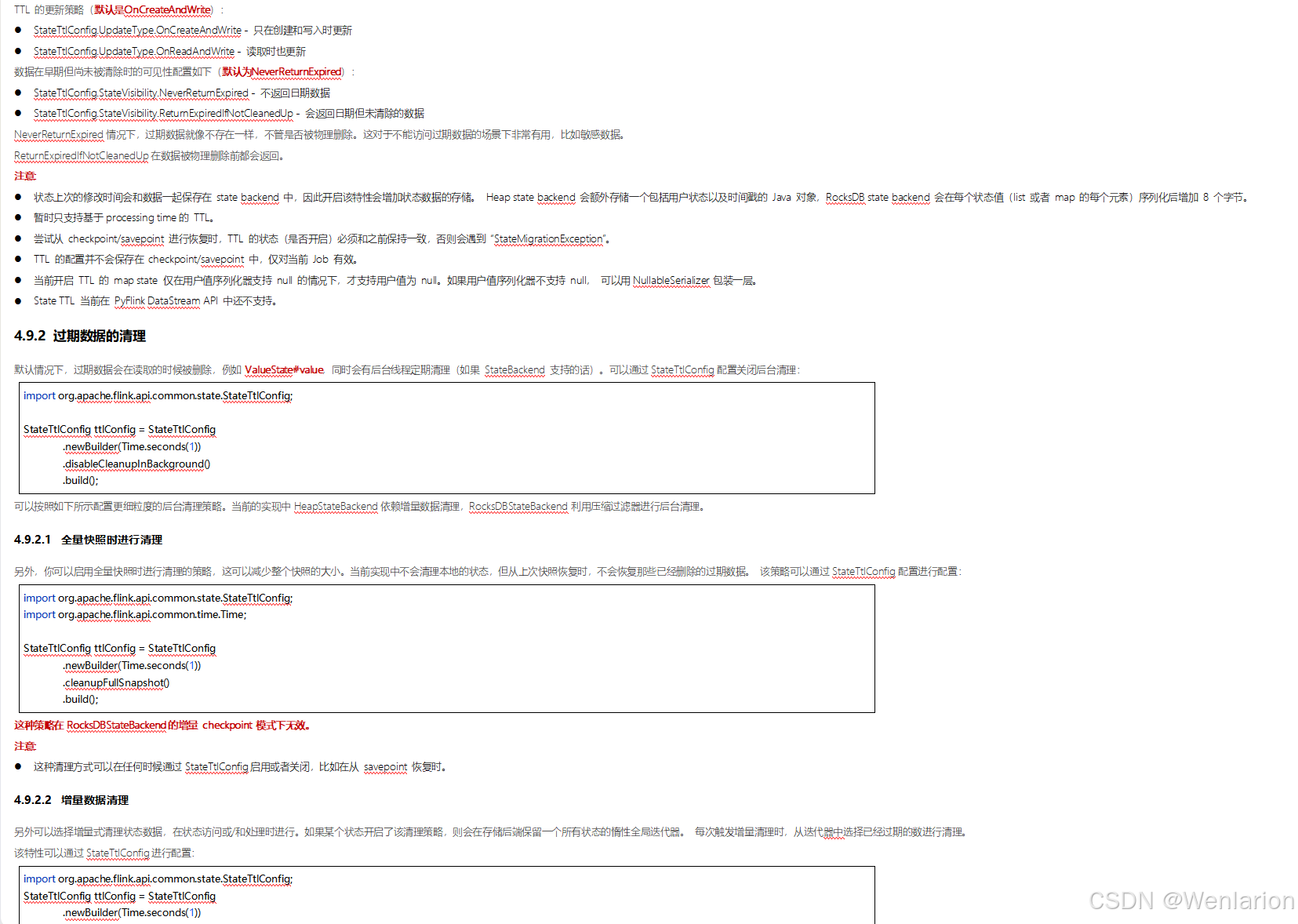

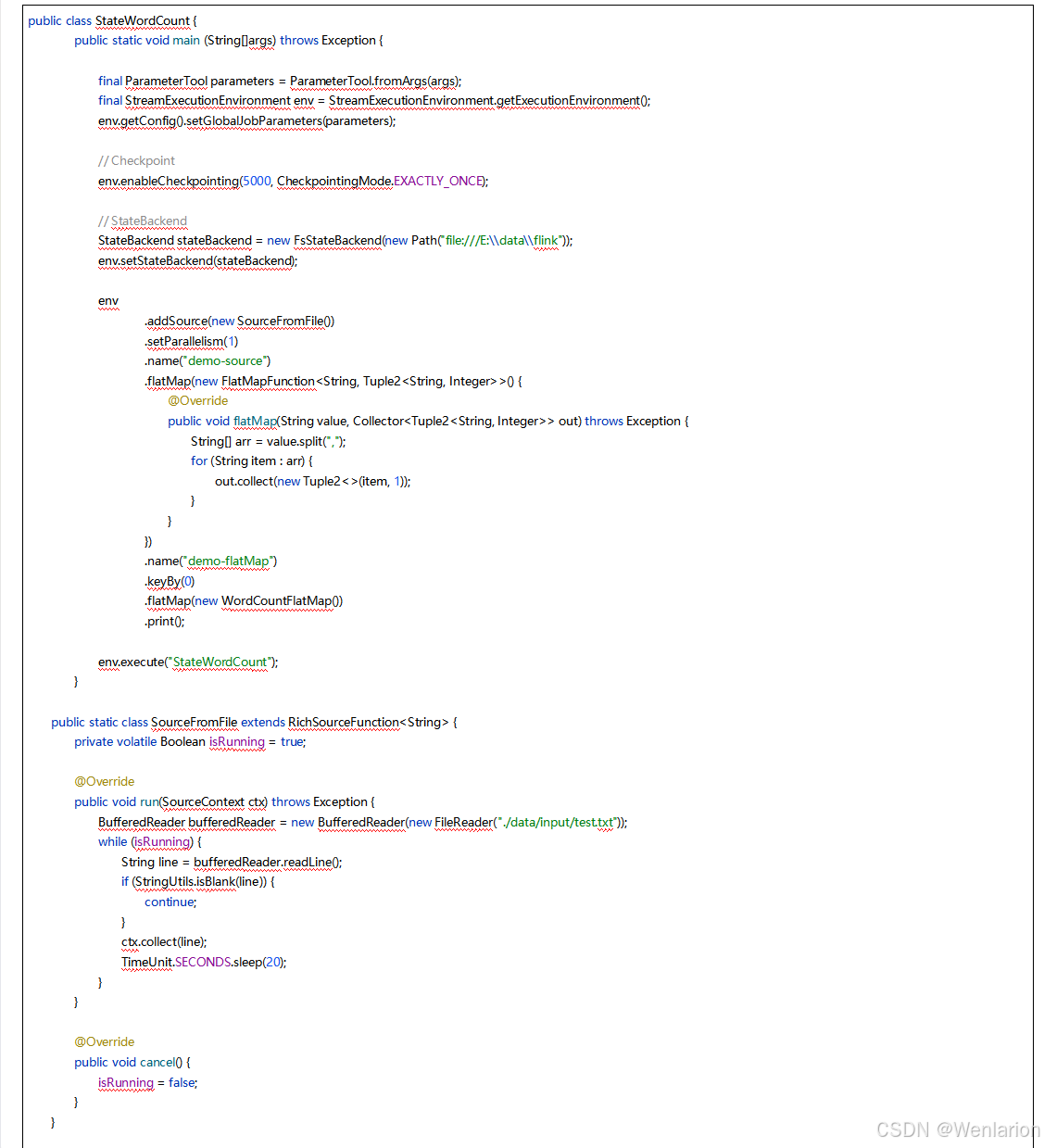


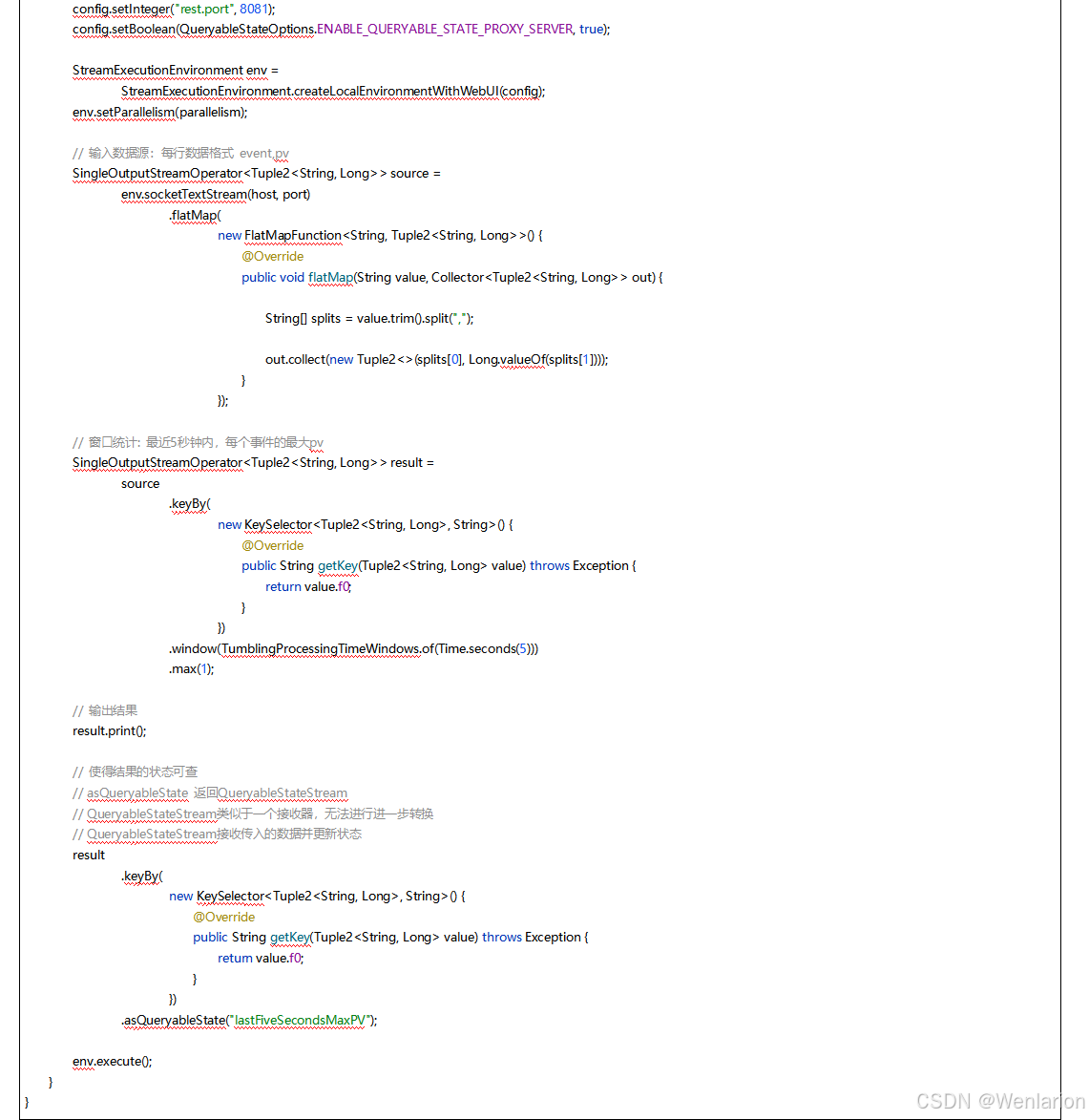
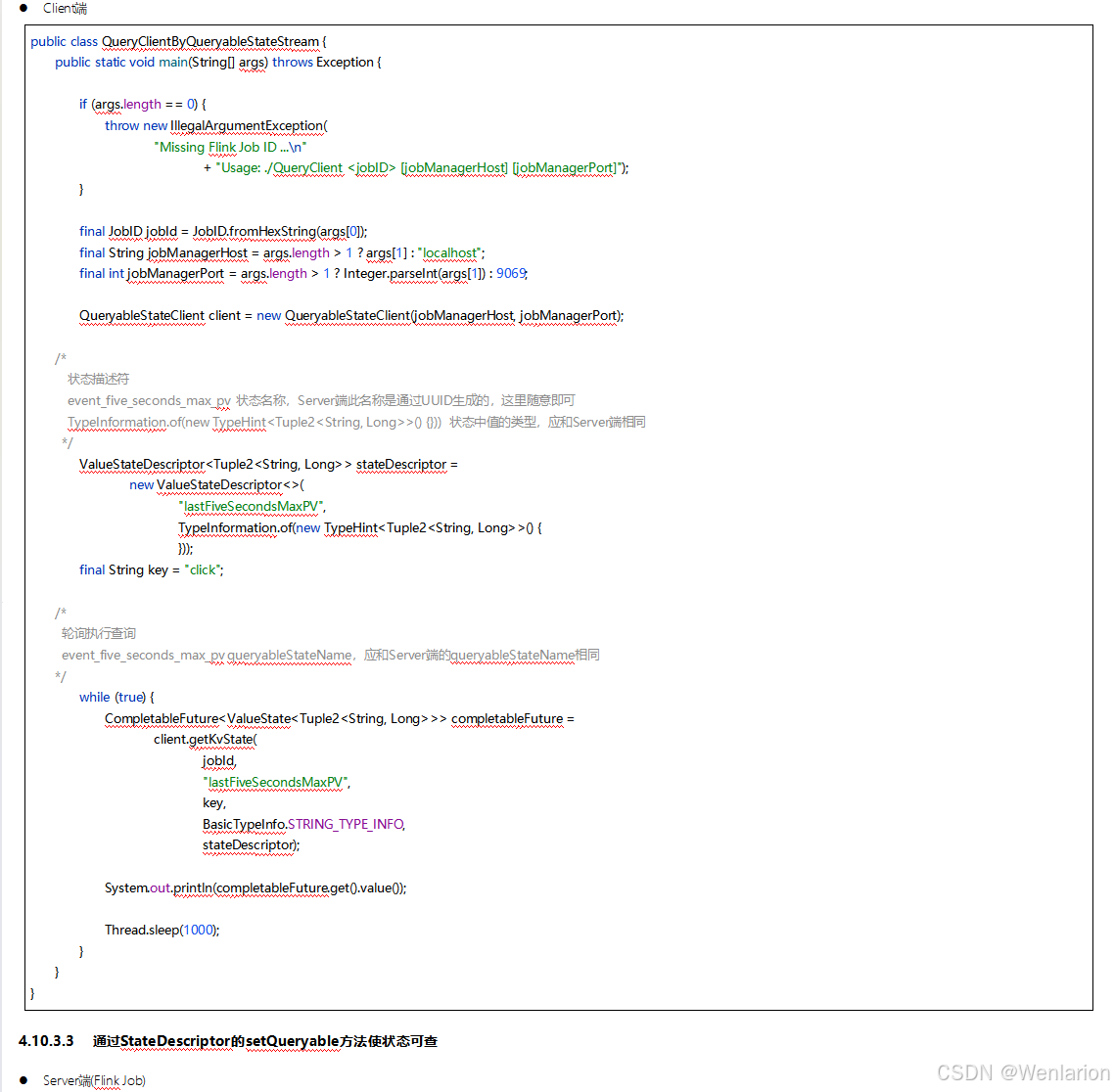
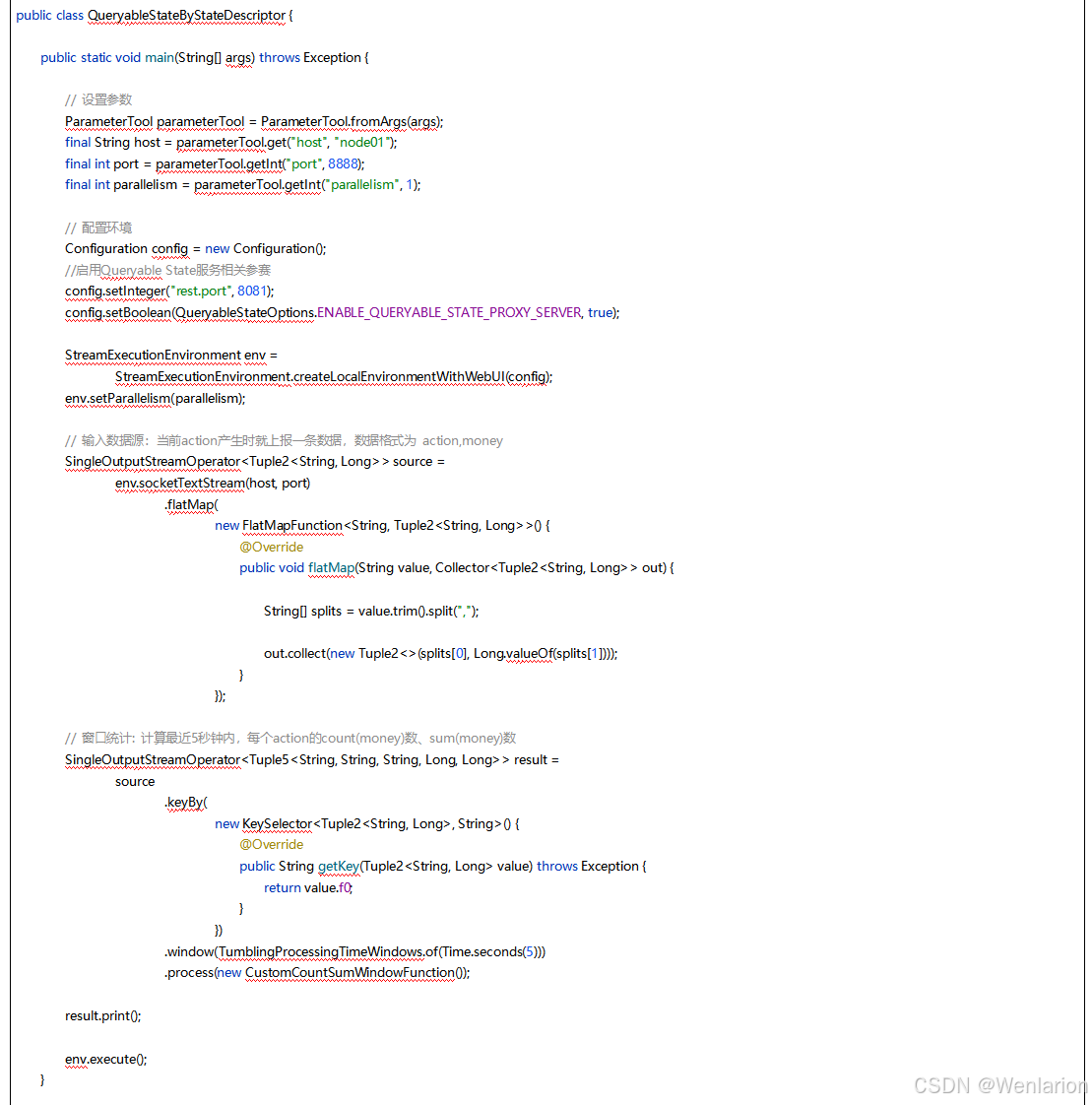
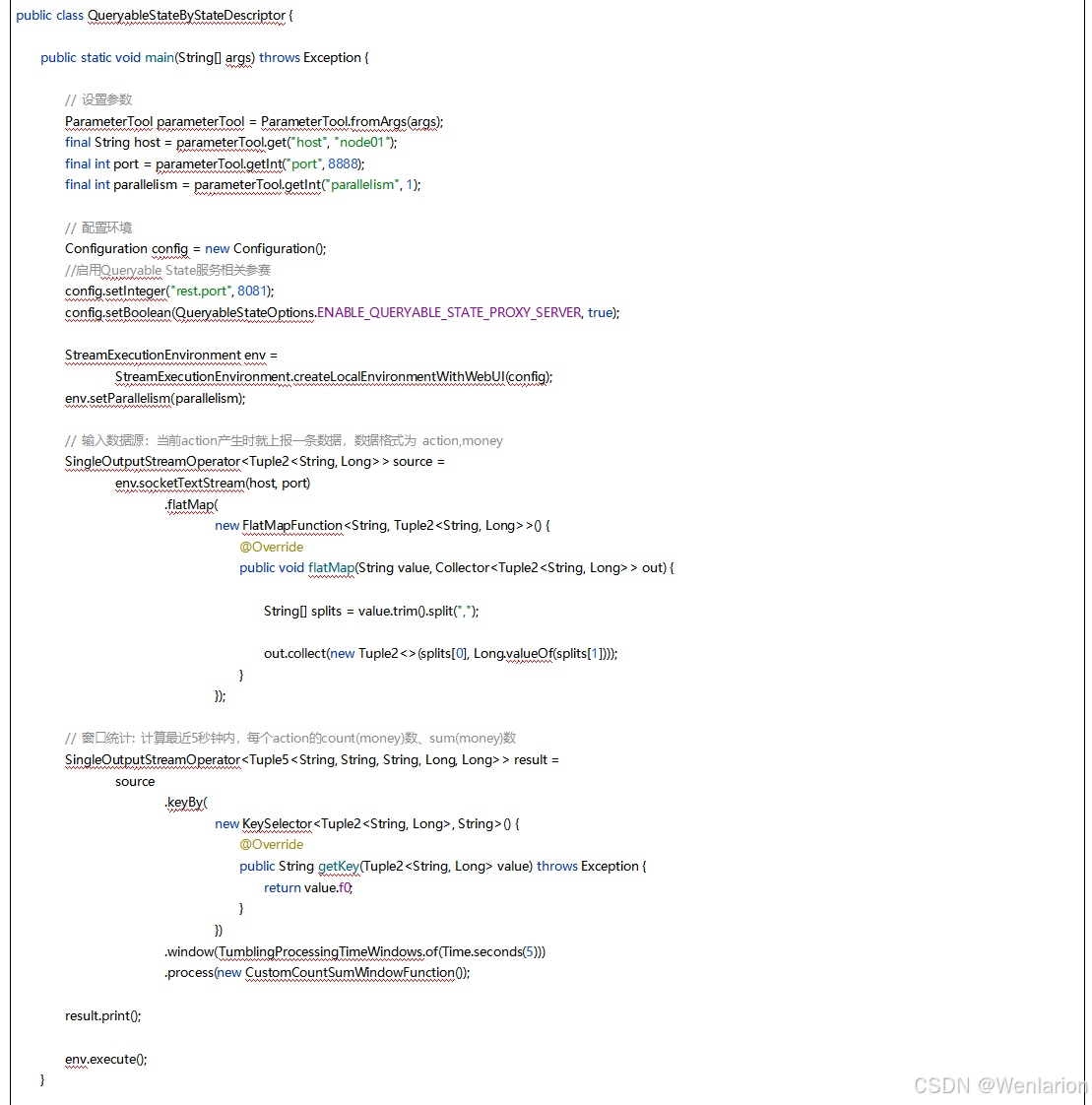
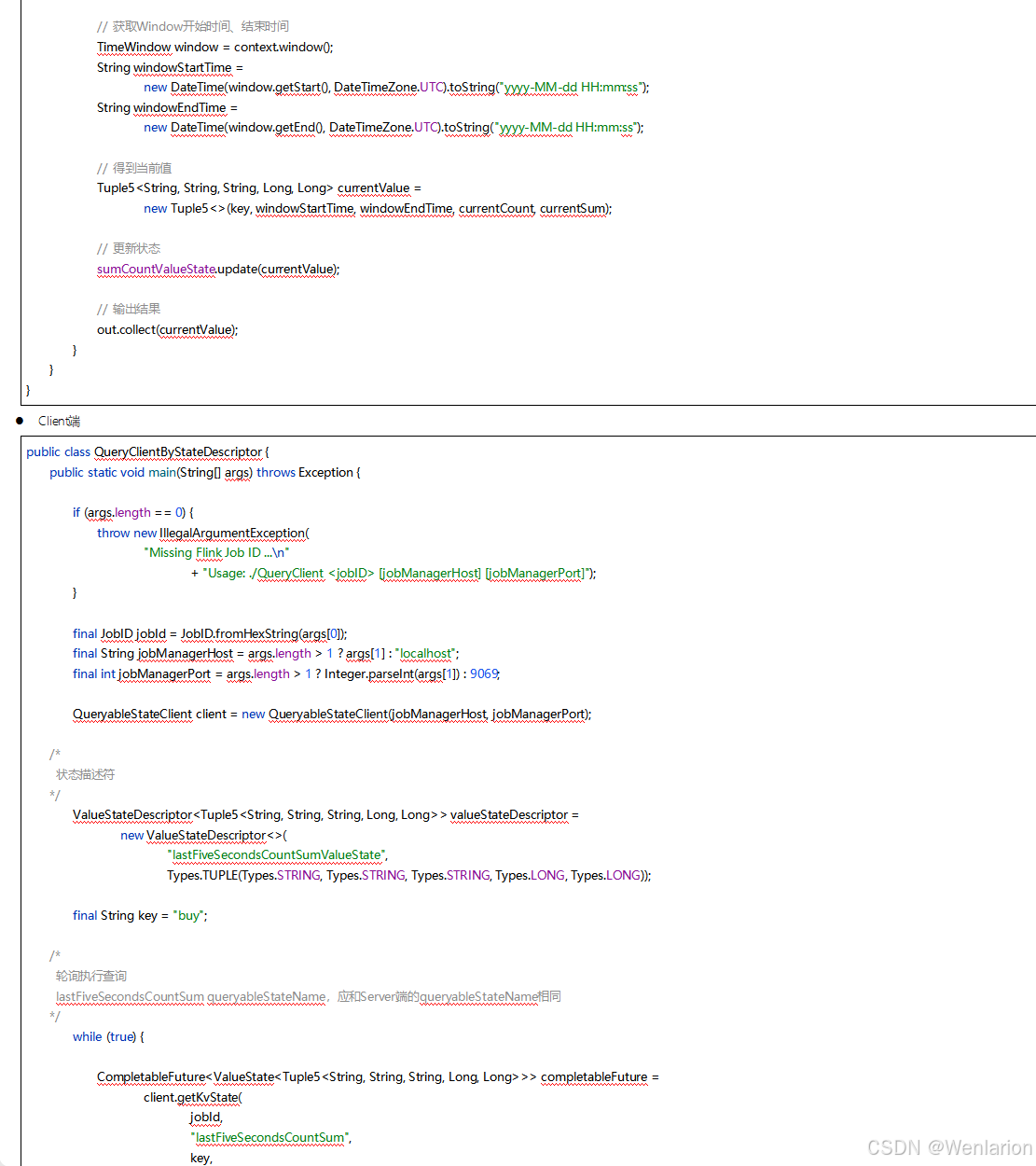
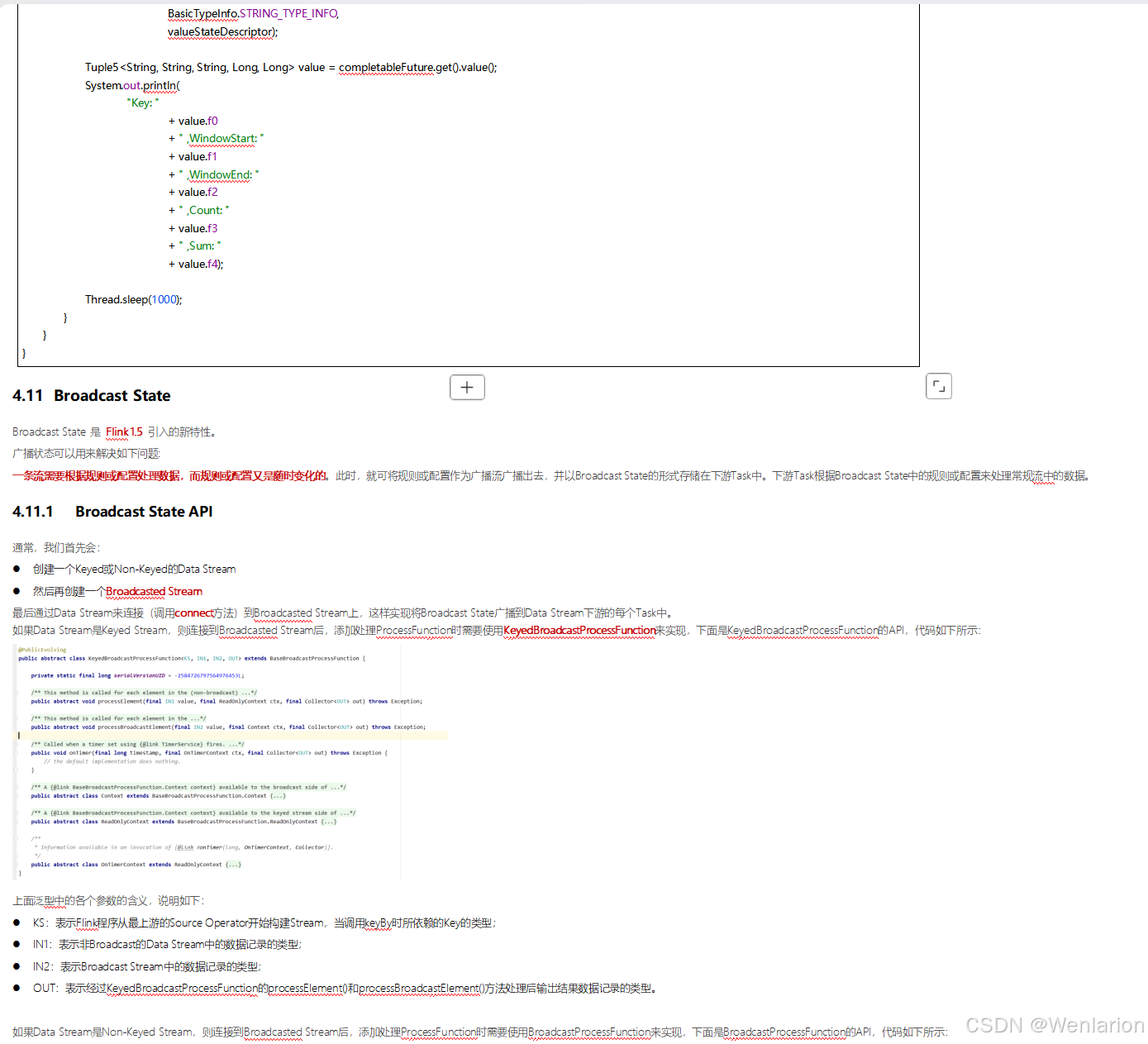
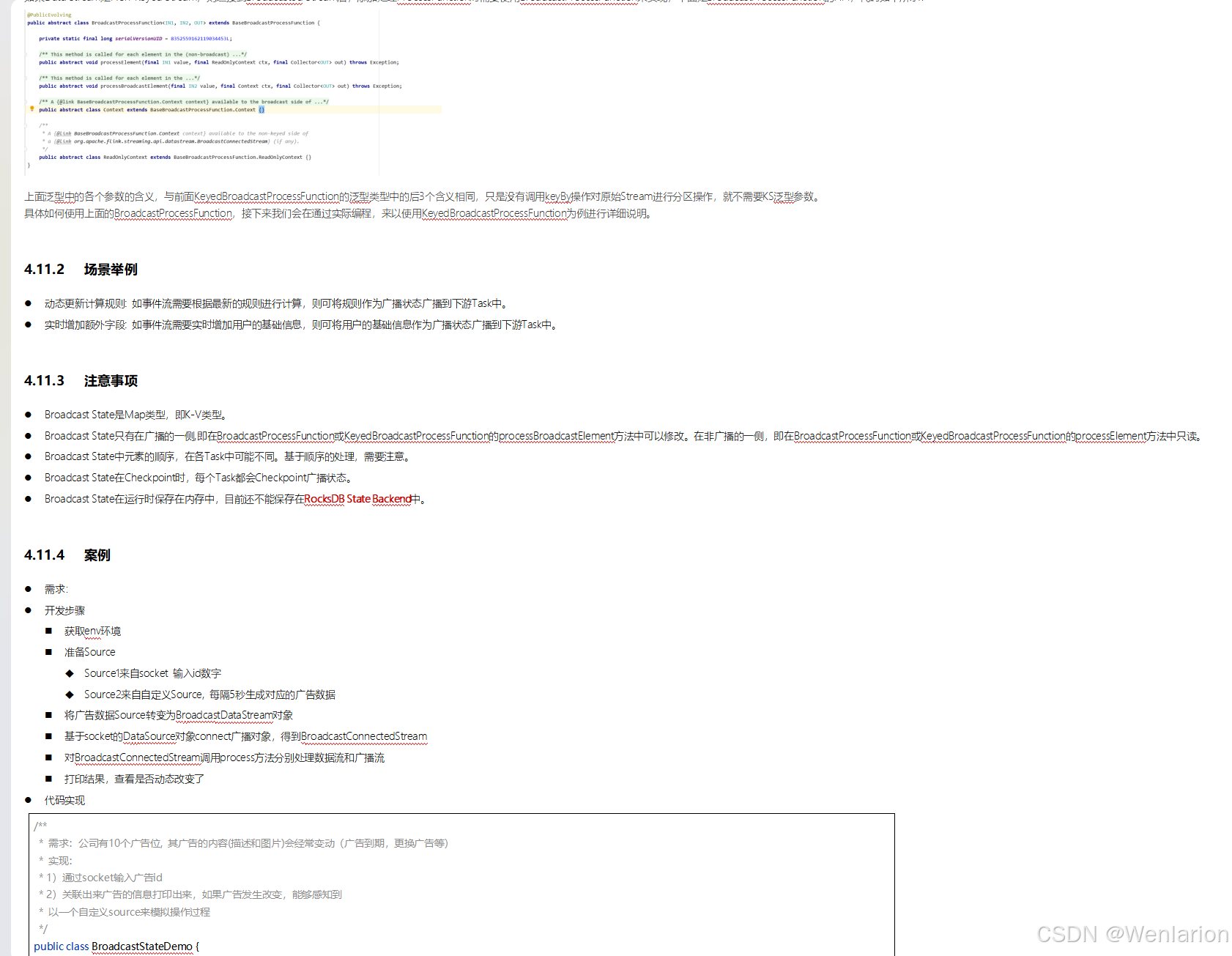
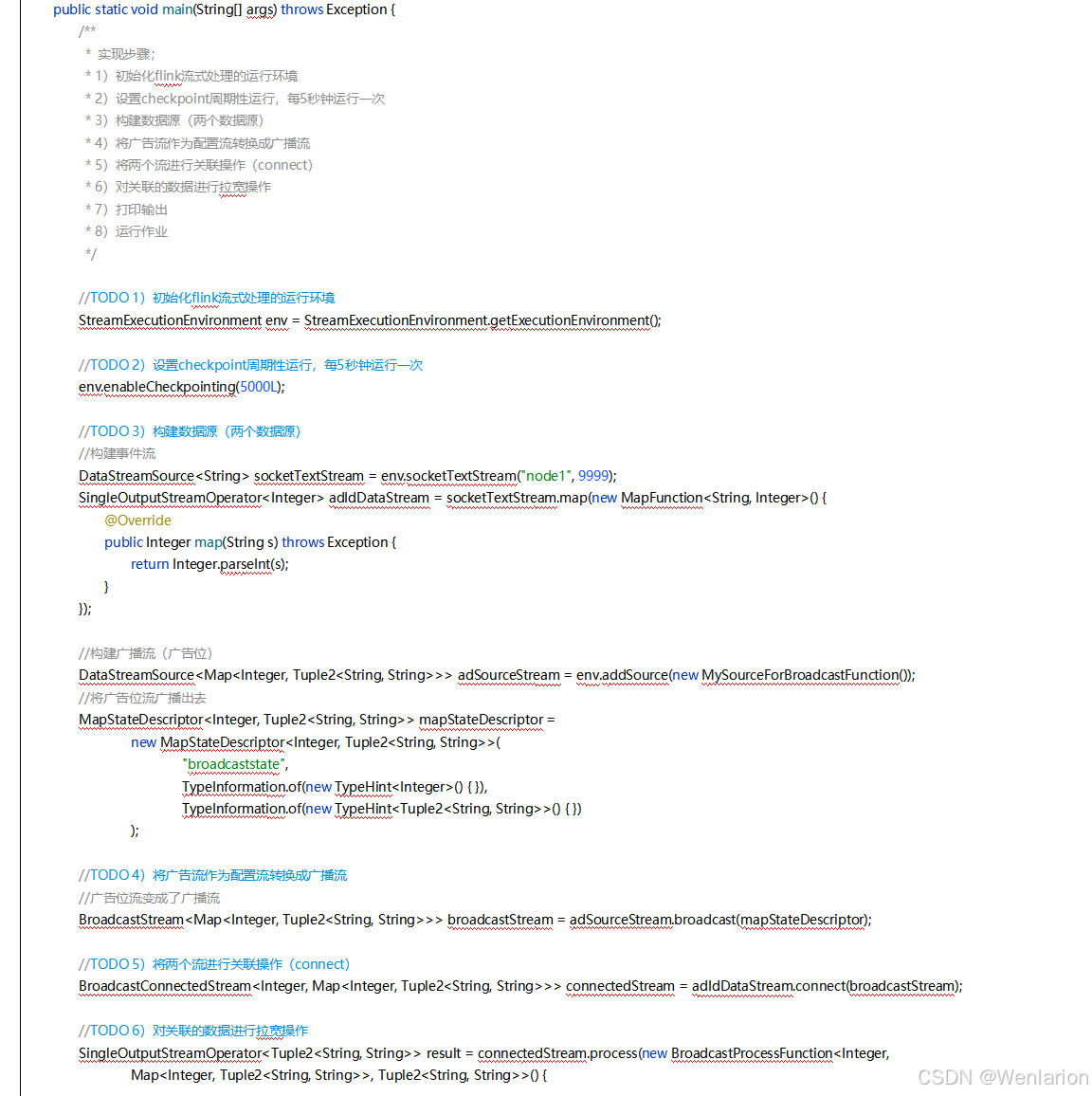
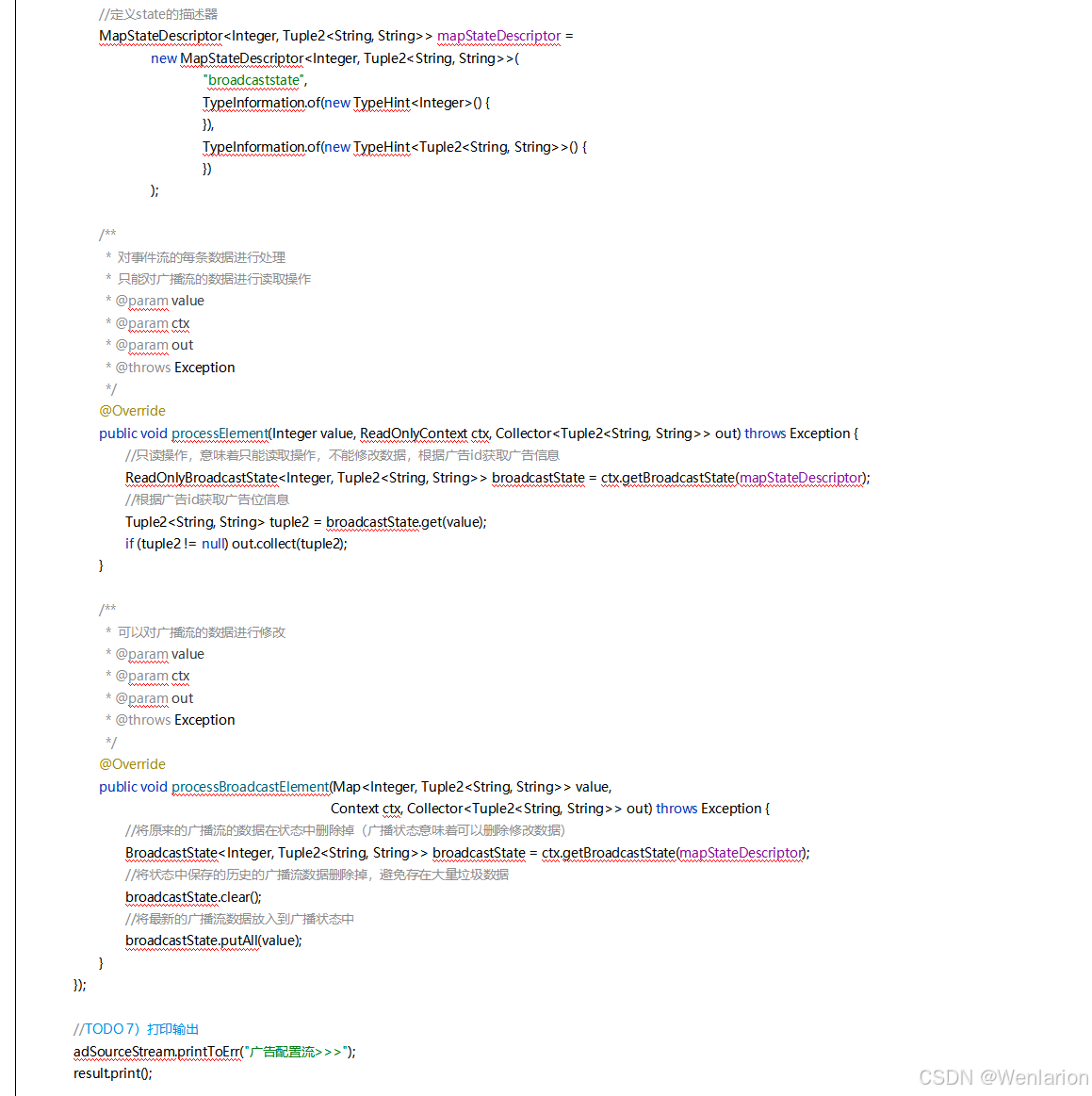
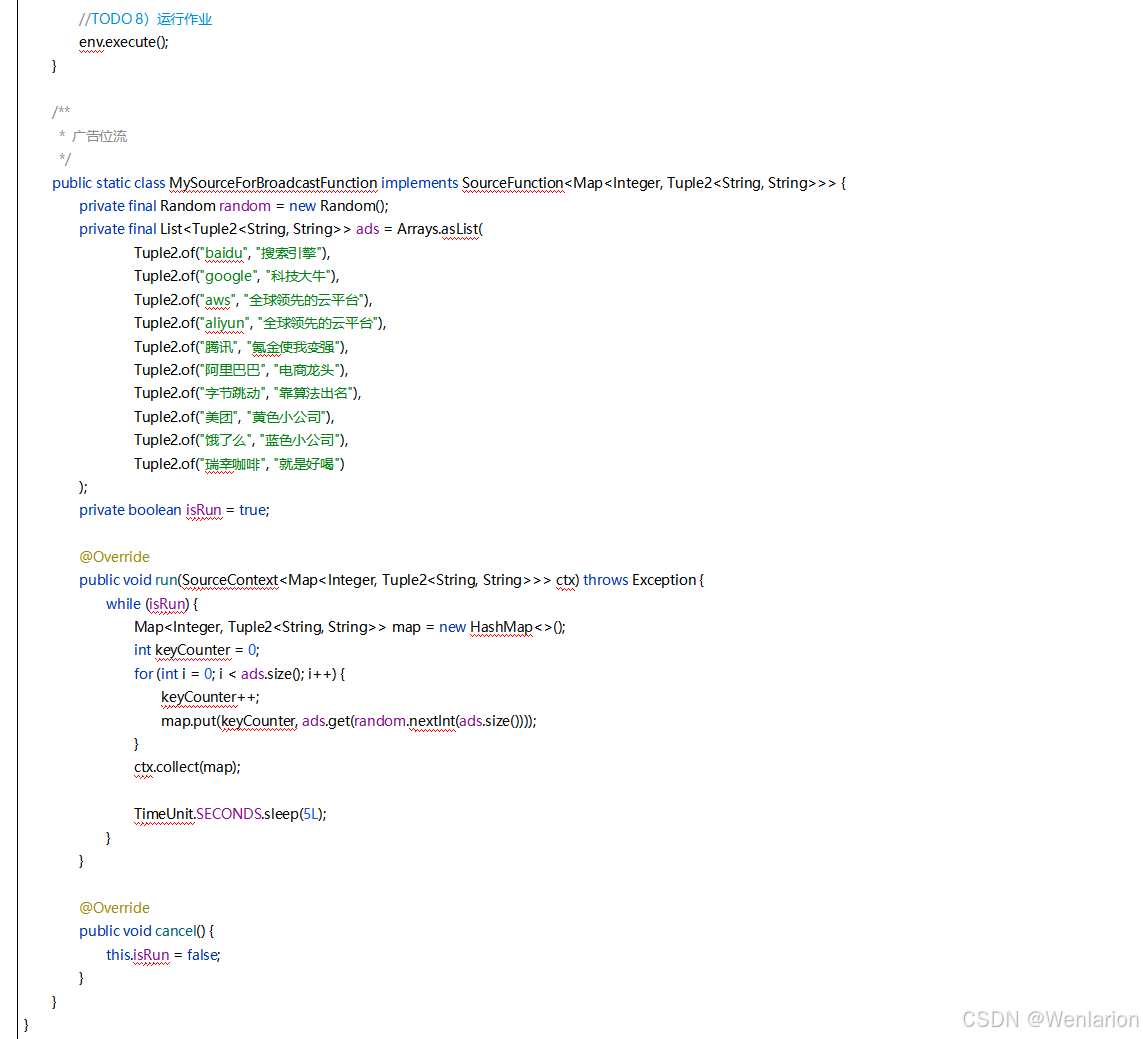
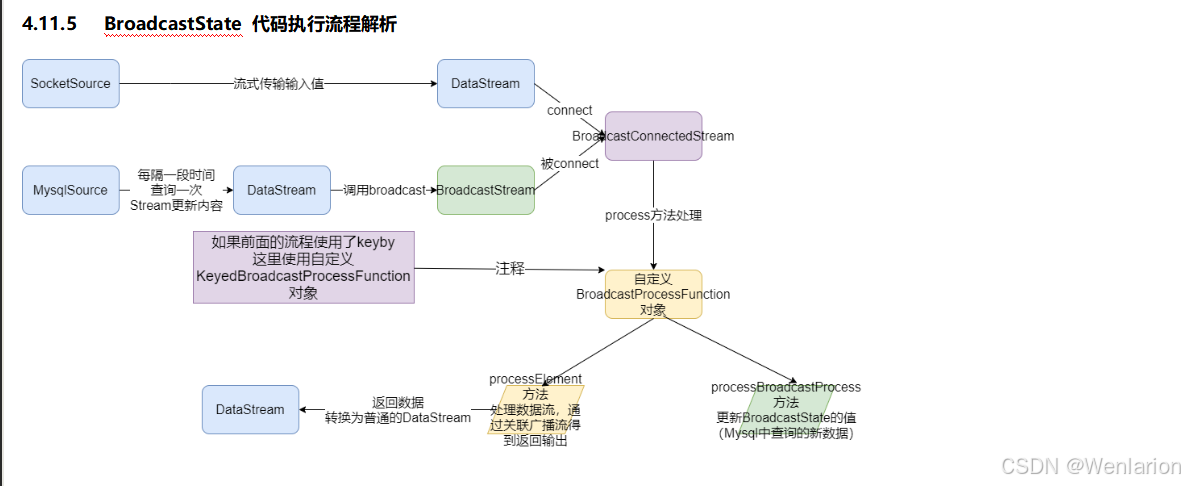
5、Flink的容错
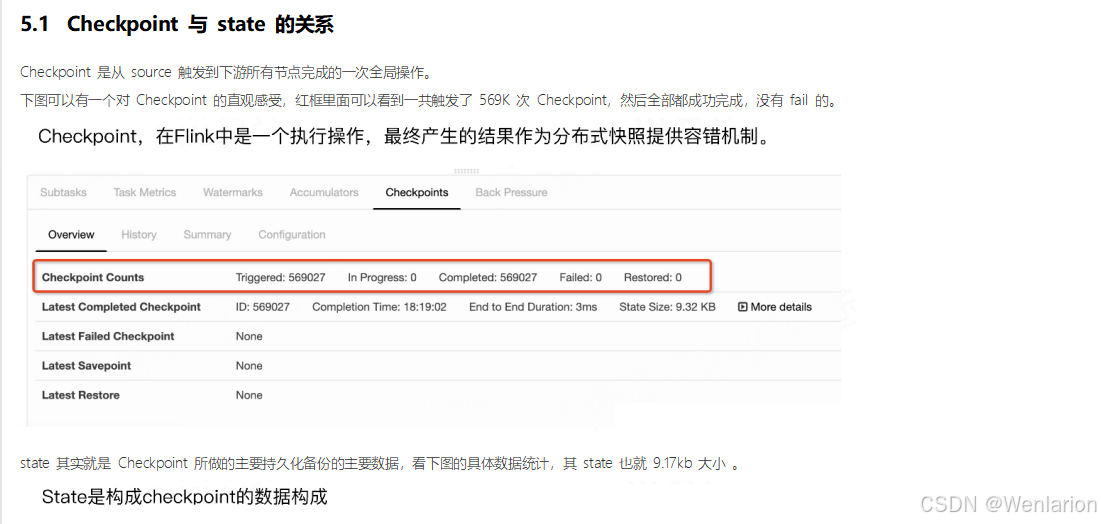

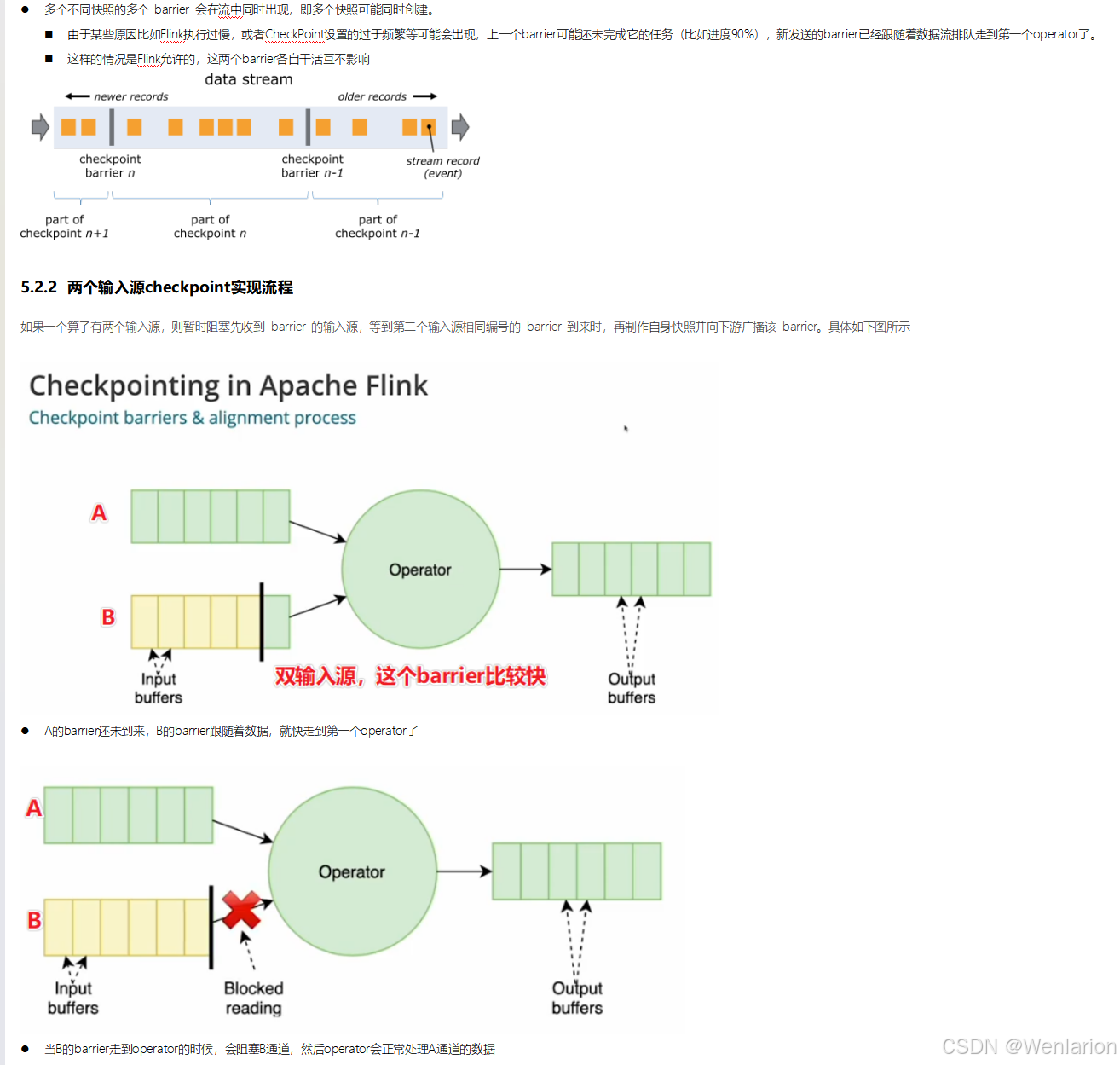
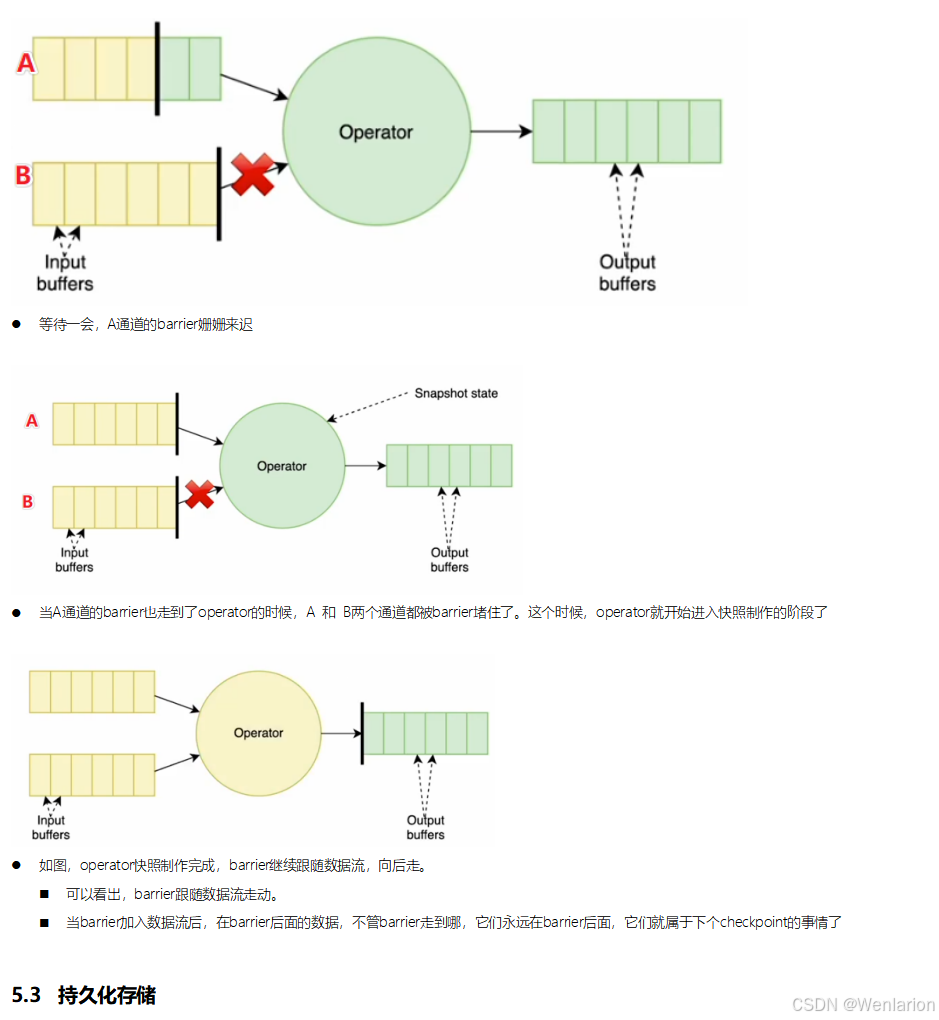



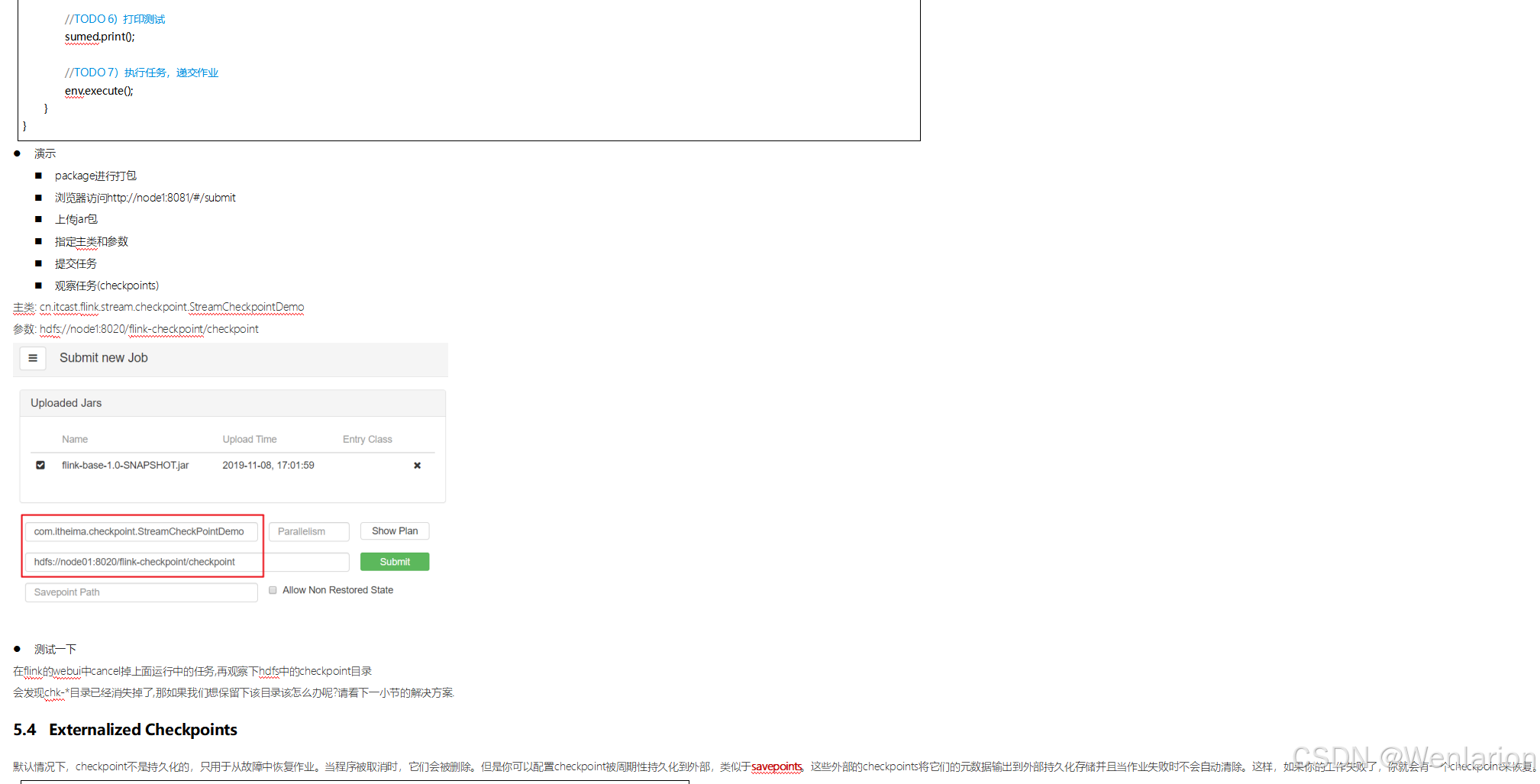
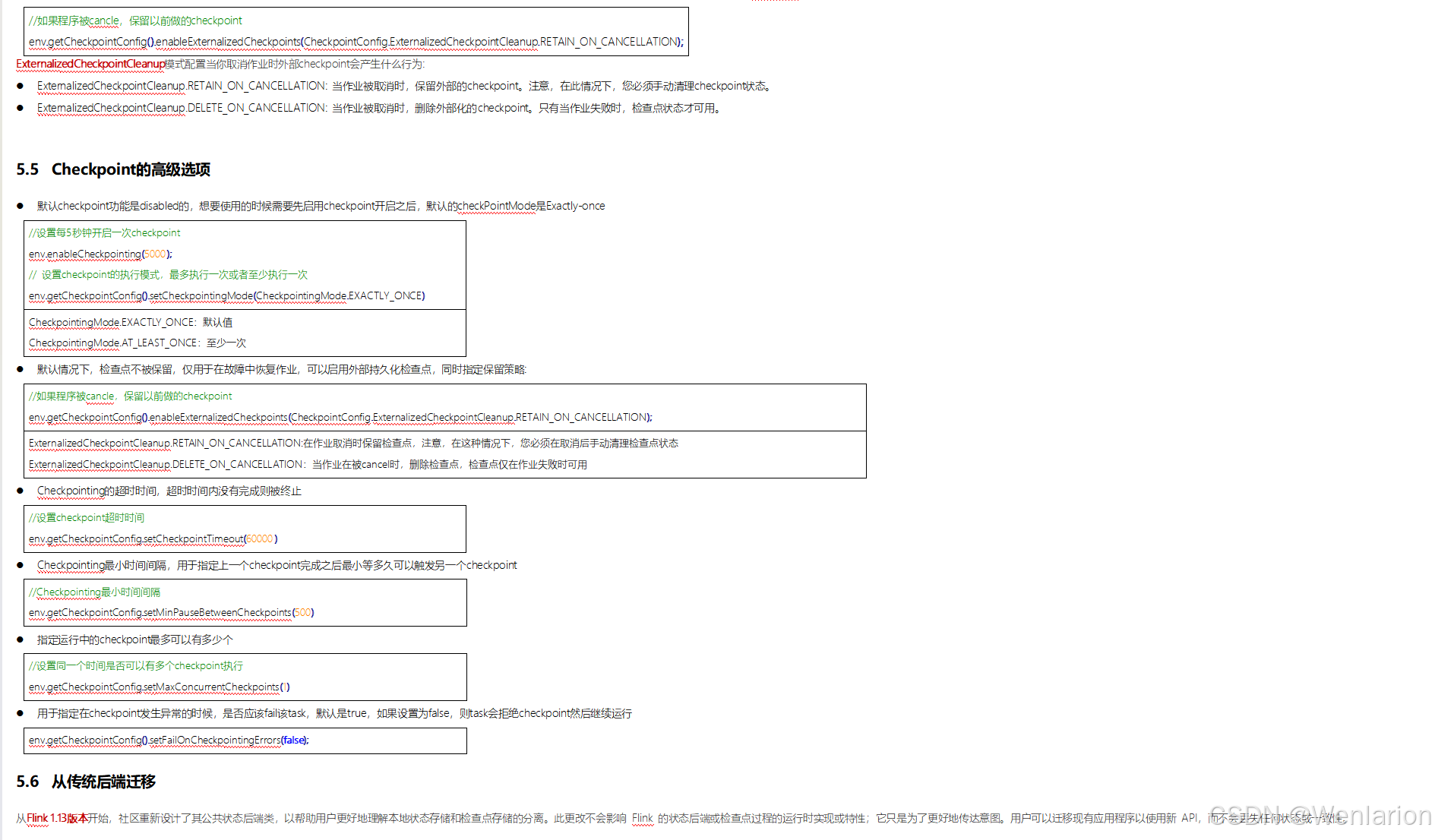

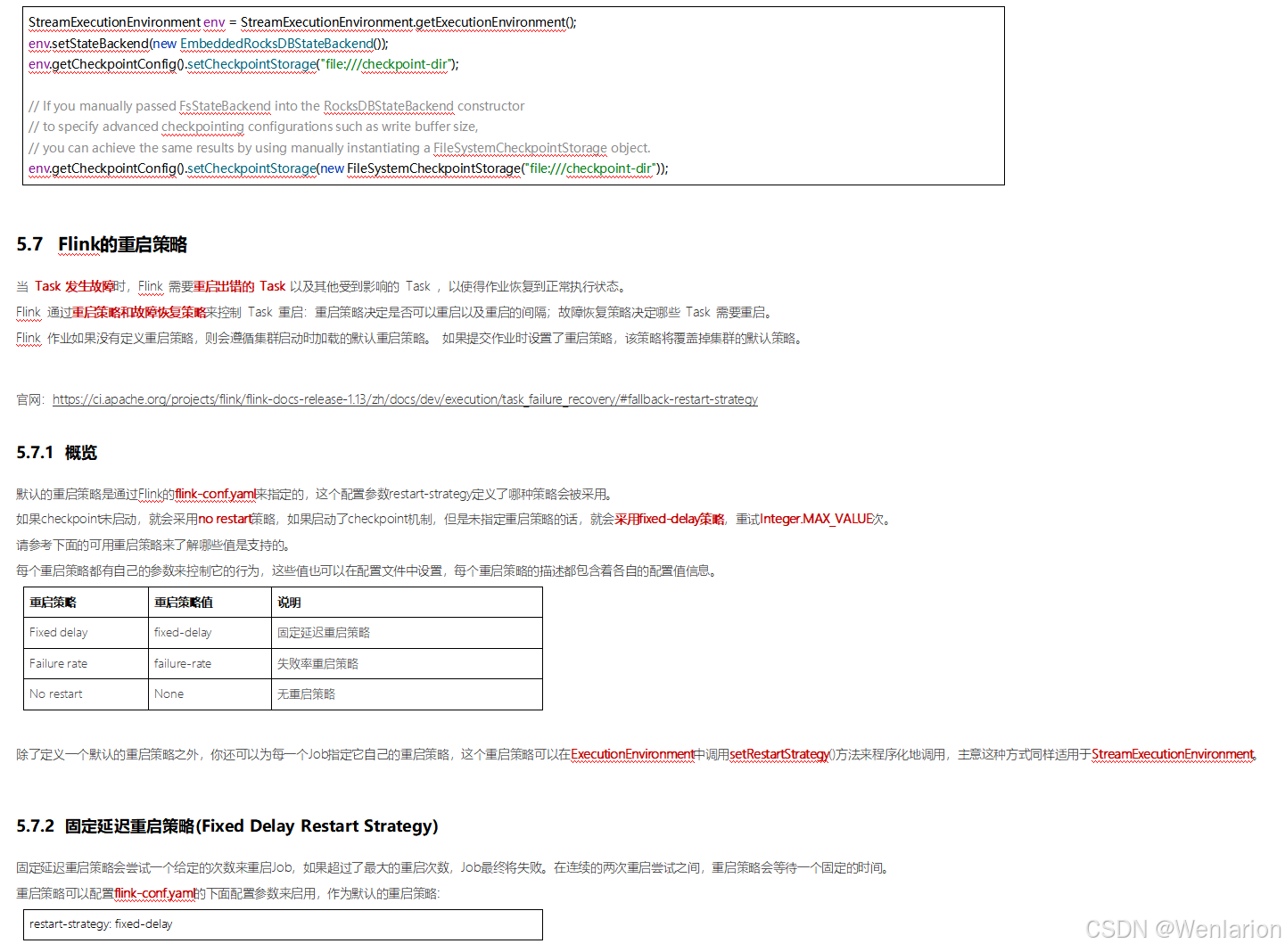

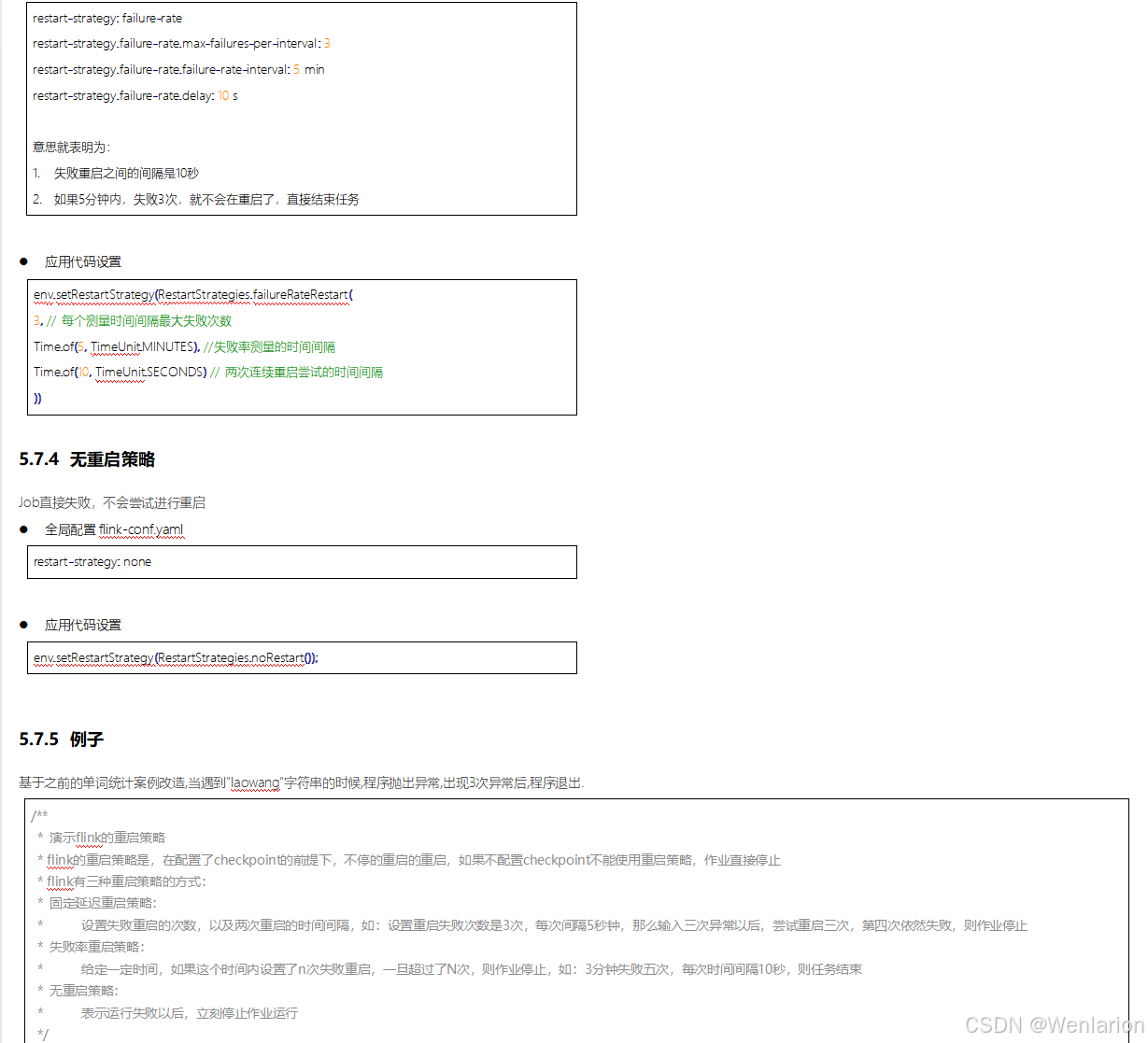
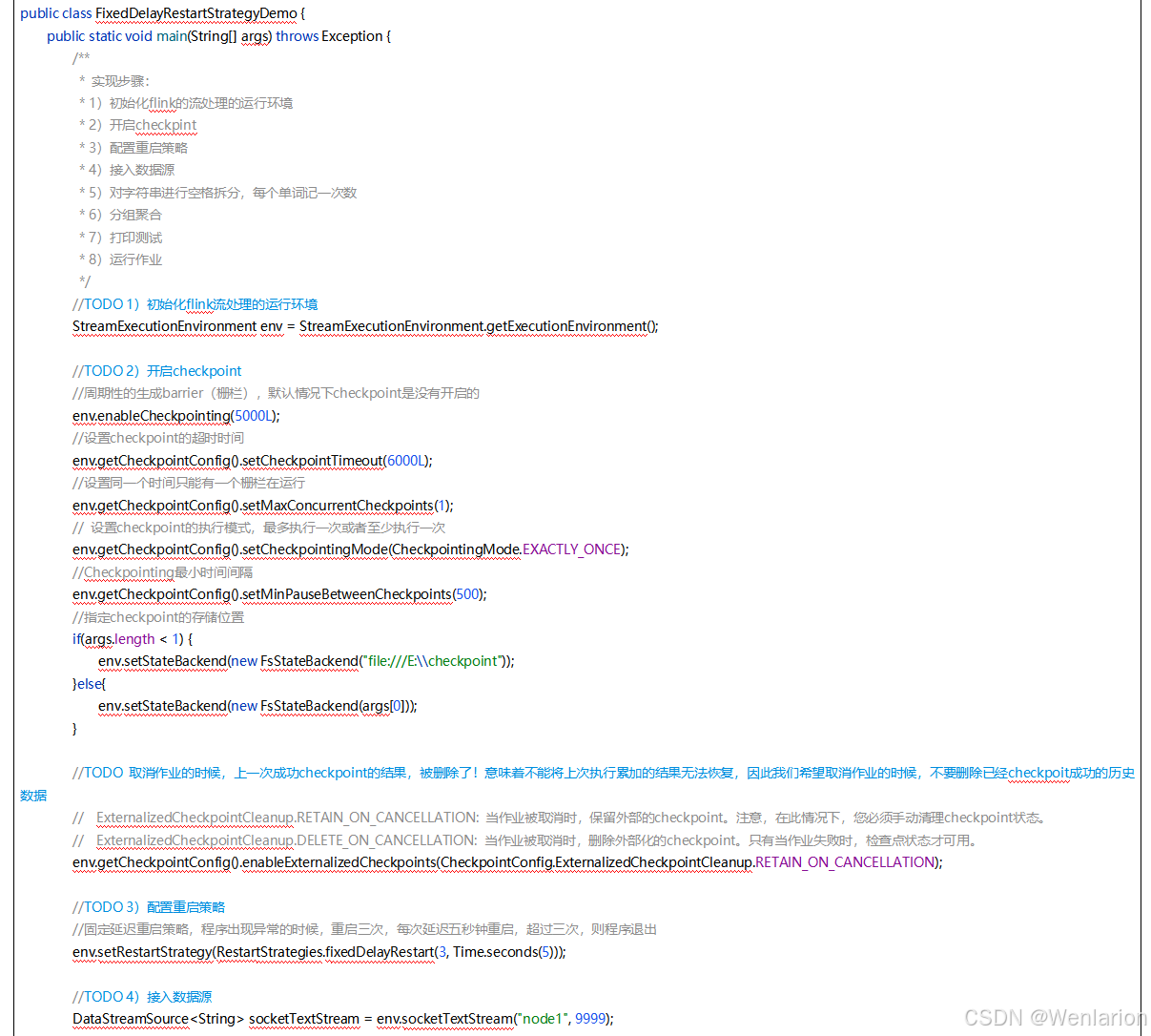
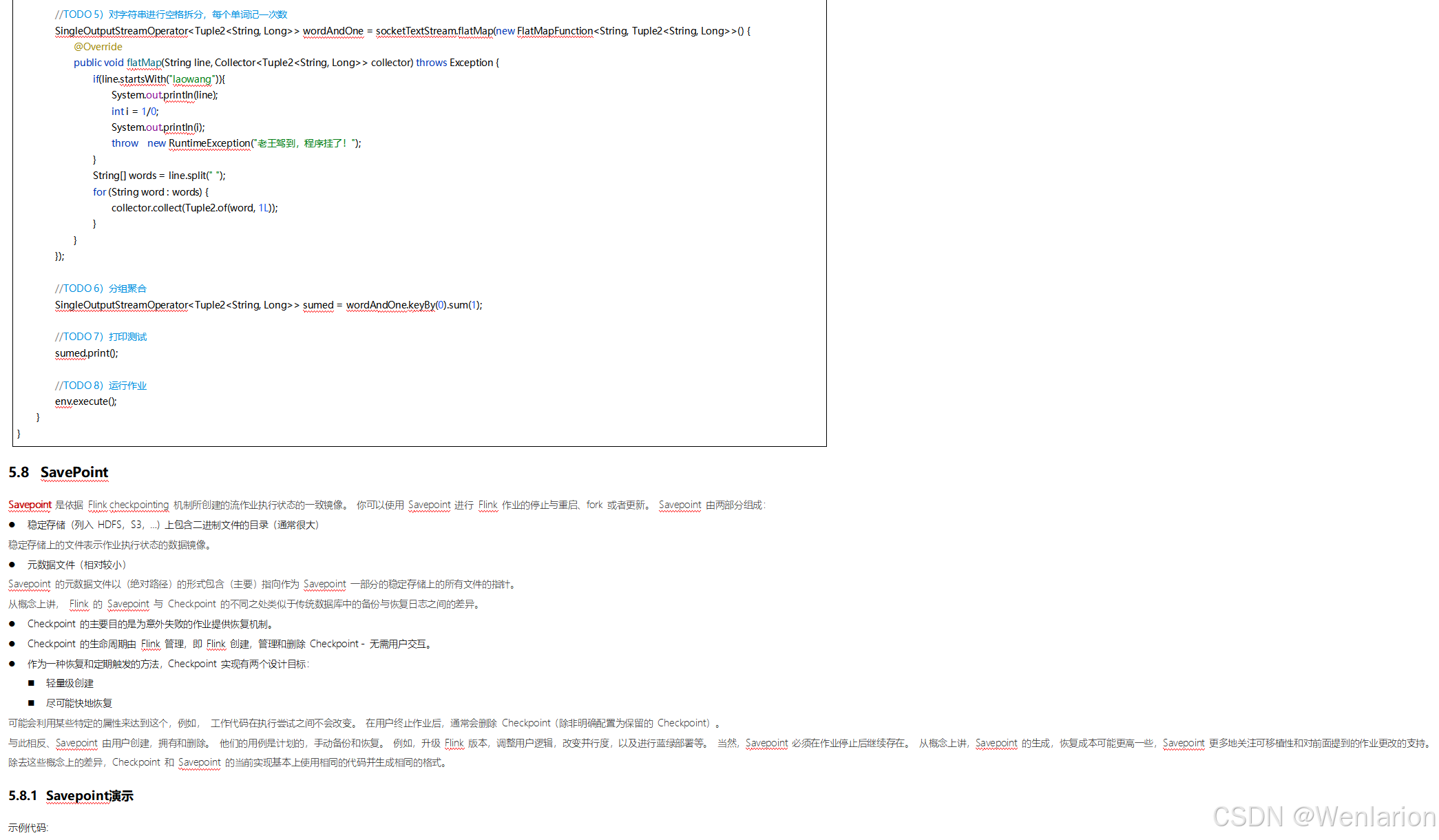
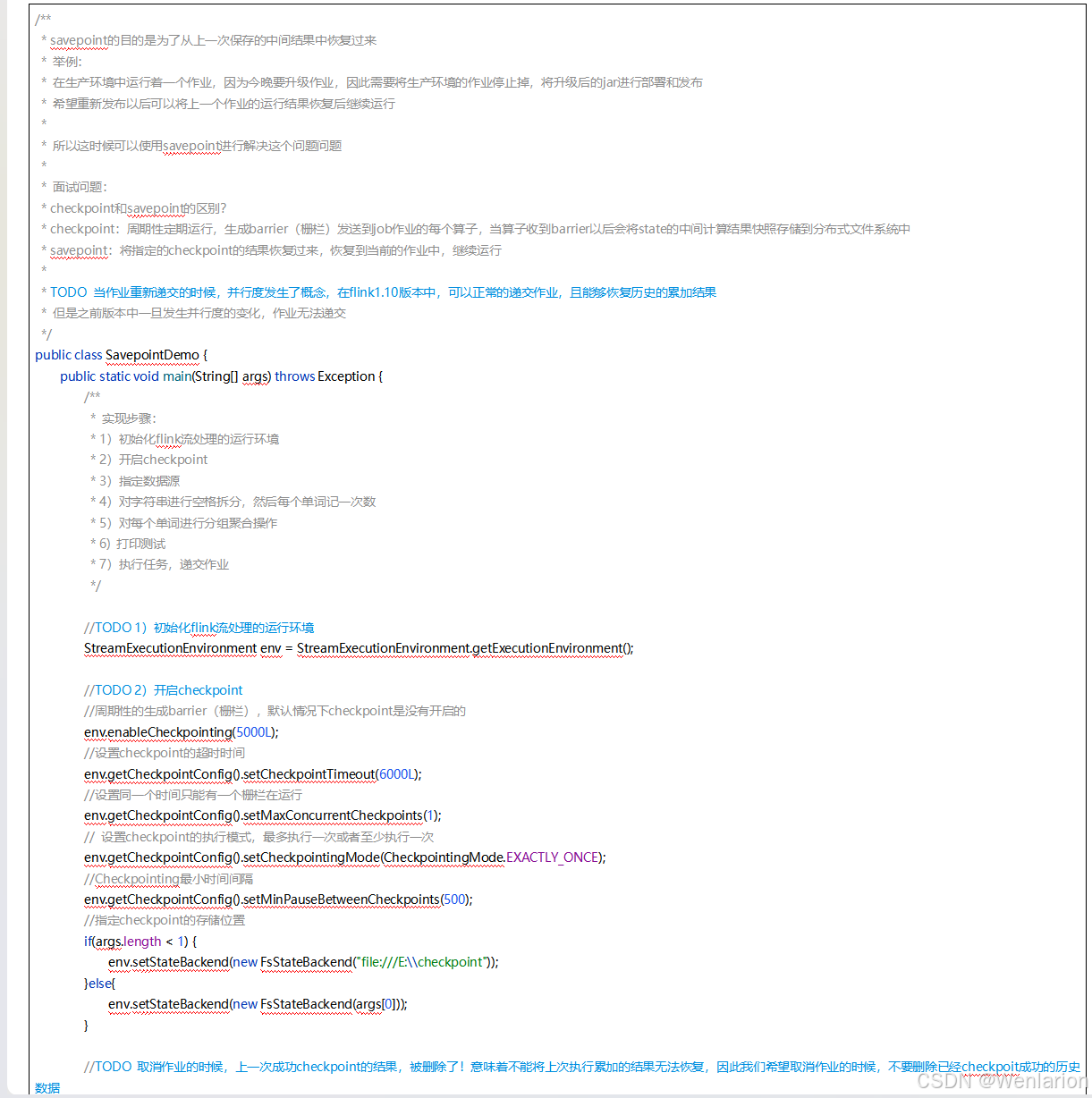
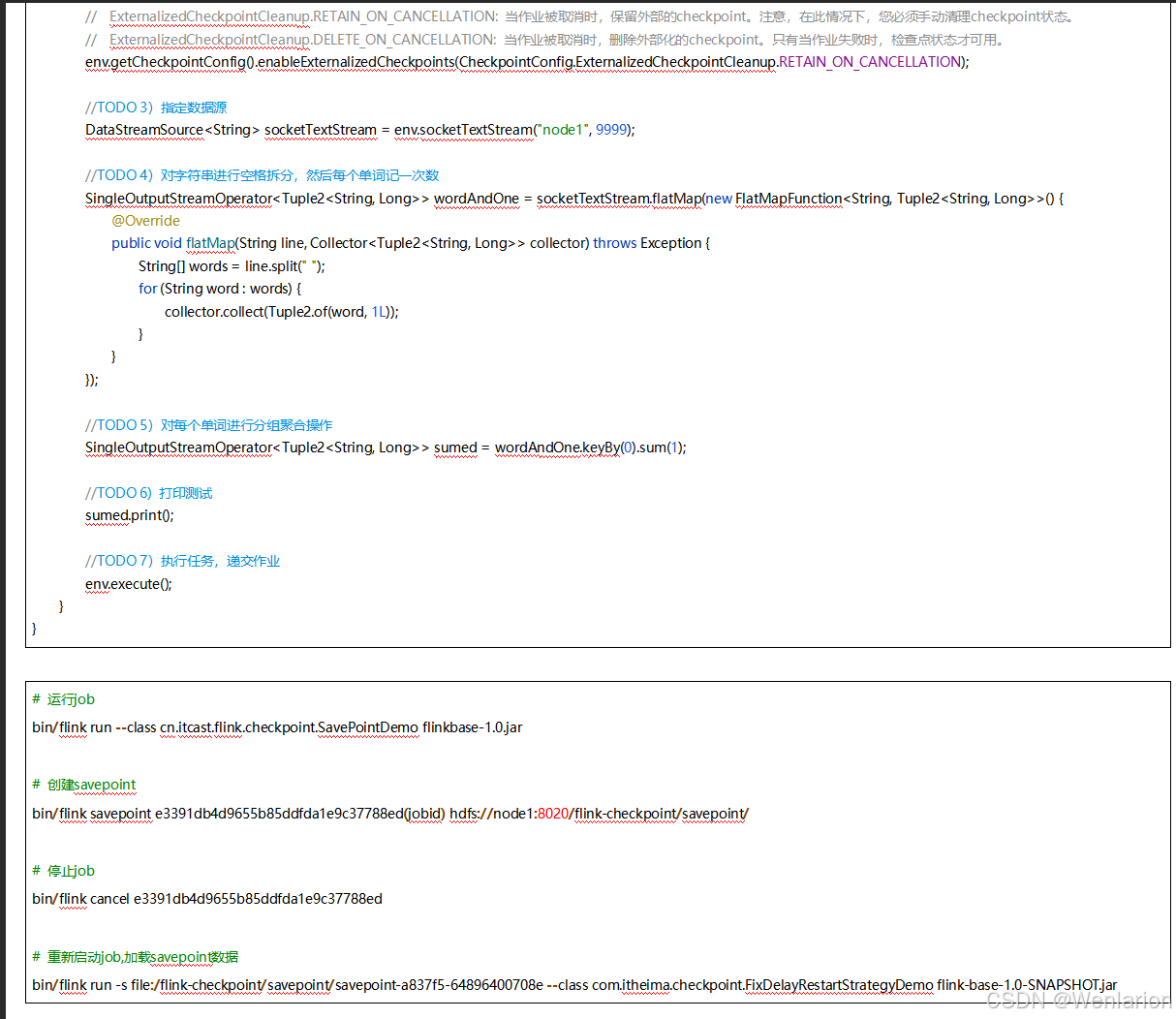
6、扩展阅读:Flink 的任务链
Flink 中的每个算子都可以设置并行度,每个算子的一个并行度实例就是一个 subTask。



腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)