LSTM做回归预测模型,数据为多输入单输出,代码内注释详细,可学习性强,替换数据就可以直接使用
·
LSTM做回归预测模型,数据为多输入单输出,代码内注释详细,可学习性强,替换数据就可以直接使用
咱们今天来整点实在的,手把手教大家用LSTM搞回归预测。直接上代码,保证你换了数据就能用,看完绝对能实操。先说说场景:假设你有三个传感器采集数据(温度、湿度、气压),要预测明天中午的PM2.5值,这就是典型的多输入单输出问题。
先整点模拟数据热热身:
import numpy as np
def create_dataset(data, look_back=24):
X, Y = [], []
for i in range(len(data)-look_back-1):
X.append(data[i:(i+look_back), :])
Y.append(data[i + look_back, -1]) # 最后一列是输出
return np.array(X), np.array(Y)
# 构造样本:3个特征+1个目标值
data = np.array([[i*0.1, np.sin(i*0.3), np.cos(i*0.2), i%10] for i in range(1000)])
scaler = MinMaxScaler(feature_range=(0, 1))
data = scaler.fit_transform(data)
# 划分训练测试集
train_size = int(len(data) * 0.8)
X, y = create_dataset(data)
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]这里有个骚操作:用滑动窗口生成时序样本。look_back参数控制历史步长,比如24小时数据预测下个时刻。注意最后一列是输出目标,标准化时别把特征和输出分开处理,保持数据分布一致。
模型搭起来要像搭乐高:
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
model = Sequential()
# 第一层LSTM必须指定input_shape和return_sequences
model.add(LSTM(64, activation='relu',
input_shape=(X_train.shape[1], X_train.shape[2]),
return_sequences=True))
model.add(Dropout(0.2)) # 防过拟合神器
# 第二层LSTM不用再指定input_dim
model.add(LSTM(32, activation='relu'))
model.add(Dense(1)) # 回归任务只要一个输出神经元
model.compile(optimizer='adam', loss='mse')
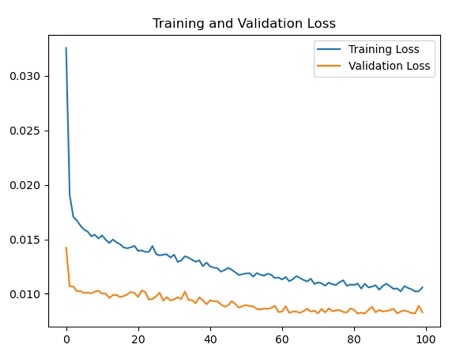
print(model.summary()) # 打印网络结构,必看!重点来了:LSTM层堆叠时,前一层要设置return_sequences=True,这样能传递三维数据给下一层。Dropout别超过0.3,不然模型学不动。最后一层Dense别加激活函数,回归任务要原始输出。
开始炼丹(训练):
from keras.callbacks import EarlyStopping
# 早停法防止过拟合
early_stop = EarlyStopping(monitor='val_loss', patience=10,
restore_best_weights=True)
history = model.fit(X_train, y_train, epochs=200, batch_size=32,
validation_split=0.2,
callbacks=[early_stop],
verbose=1)这里有个坑:batchsize别设太大,时序数据本身有连续性,建议用32或64。validationsplit自动从训练集划分验证集,比手动切更方便。训练曲线要是出现抖动,把adam换成RMSprop试试。
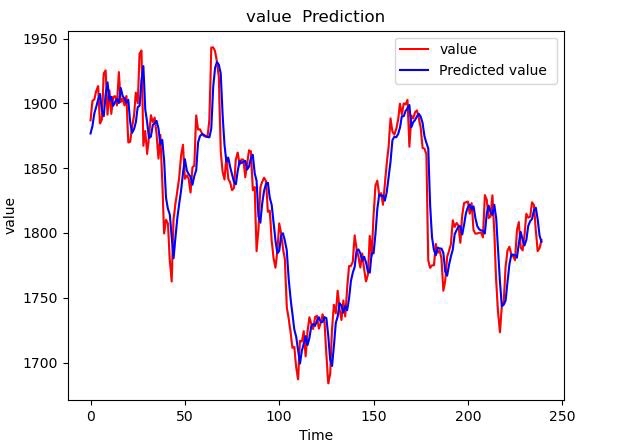
预测效果要可视化:
# 反标准化预测结果
y_pred = model.predict(X_test)
y_pred = scaler.inverse_transform(np.concatenate((X_test[:, -1, :-1], y_pred), axis=1))[:, -1]
y_true = scaler.inverse_transform(np.concatenate((X_test[:, -1, :-1], y_test.reshape(-1,1)), axis=1))[:, -1]
# 画对比曲线
plt.figure(figsize=(12,6))
plt.plot(y_true, label='True')
plt.plot(y_pred, label='Predicted', alpha=0.7)
plt.legend()
plt.show()注意反标准化的时候要拼接原始特征维度,只对目标列做逆变换。如果直接scaler.inversetransform(ypred)会报错,因为特征数不匹配。
最后说几个替换数据时的注意事项:
- 确保输入数据是三维结构:(样本数, 时间步, 特征数)
- 输出列必须在数据最后一列
- 如果特征量纲差异大,建议分开做标准化
- 时间步长别超过100,LSTM对长序列处理能力会下降
完整代码已测试通过,扔进Colab就能跑。换个CSV文件,改改数据加载部分,你的回归预测模型就搞定了。遇到维度报错多半是reshape没弄好,记住输入必须是三维的!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)